
LINE Data Scienceセンター、ML Privacyチームのリュウと髙橋です。6月に世界トップレベルの国際会議、SIGMOD2022にて発表しました。
また、第43回先端的データベースとWeb技術動向講演会にて、SIGMOD2022国際会議報告を実施しました。
本ブログではその模様について報告いたします。
SIGMOD 2022について

Association for Computing Machinery主催のSIGMOD2022 (ACM SIGMOD/PODS Conference on Management of Data)は、データベース・データ工学分野におけるトップカンファレンスです。VLDBやICDEと並ぶデータベース系三大会議として知られています。本年度は、6月12日〜17日にかけてアメリカのペンシルベニアでオンラインと兼ねてハイブリットの形で開催されました。LINEからは、私たちリュウセンペイおよび髙橋翼と、京都大学大学院情報学研究科 吉川正俊教授および曹洋特定准教授との共同研究の成果が採択され、発表の機会を頂きました。
- (参考)プレスリリース「LINE、データ関連分野の国際学会 「SIGMOD2022」「VLDB2022」にて論文採択」
発表内容
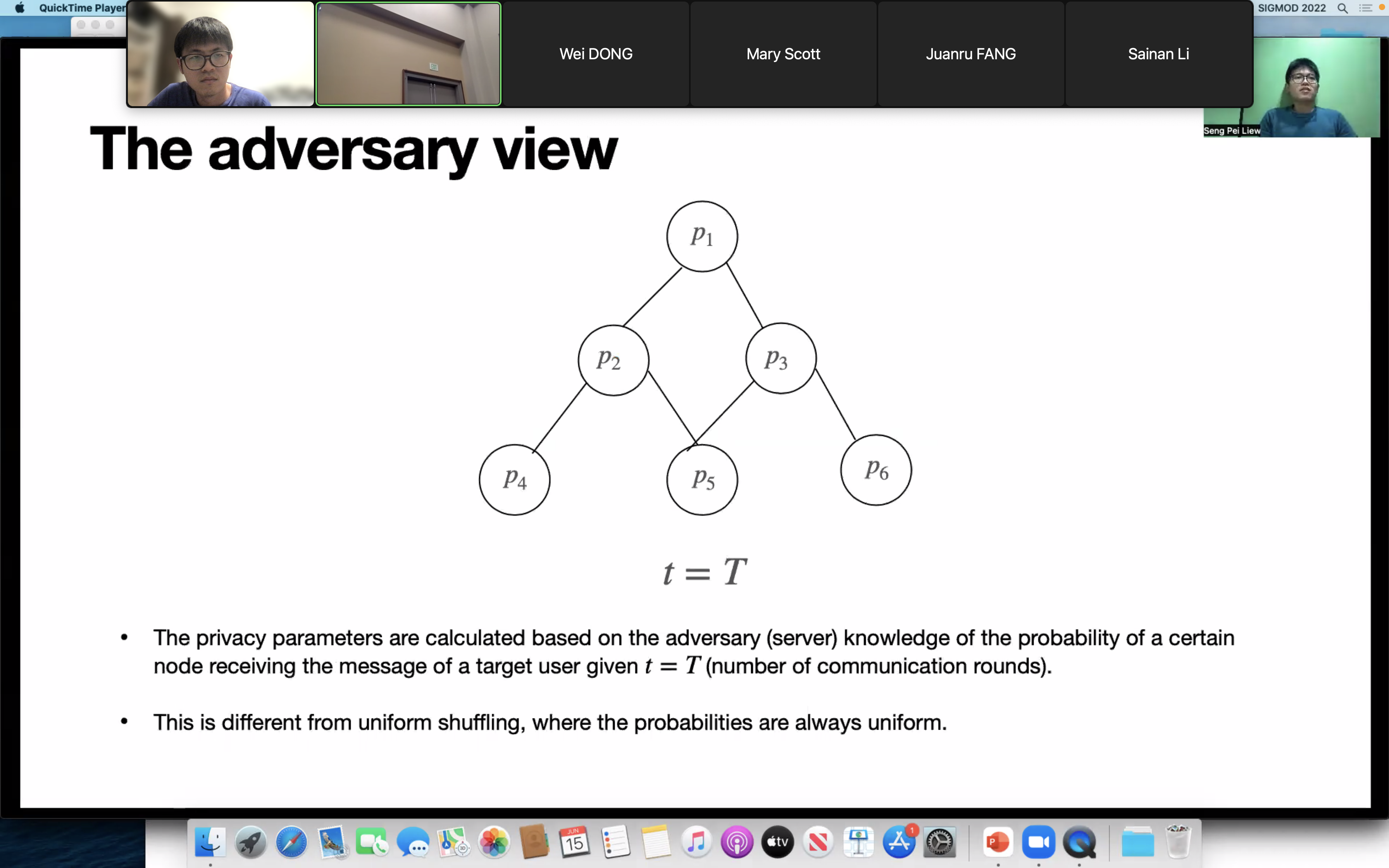
我々の発表内容は、プライバシー保護に関する新しいプロトコルの提案です。
クライアントからサーバーへのデータ収集時におけるプライバシー保護に関して、クライアント上で保証した差分プライバシーの強度を、クライアント間のセキュアなデータ交換によって増幅させる技術(プライバシー増幅)の新しい方式として「Network Shuffling」を提案しました。従来のプライバシー増幅は、送信元の匿名化処理であるシャッフリングを、中央集権的(Centralized)かつ信頼できる第三者によって実施する必要がありました。提案法「Network Shuffling」は、様々なクライアント間でデータを秘密裏に交換し合うことにより、第三者による中央集権的なサーバーを必要とせず、分散型(Decentralized)のシャッフリングを実現します。このクライアント間のデータ交換をグラフ上のランダムウォークとして定式化し、既存のシャッフリングと同様のプライバシー増幅効果が得られることを示しました。
詳細は以下の論文リンク、および発表アーカイブ動画をご参照ください。
発表論文
"Network Shuffling: Privacy Amplification via Random Walks"
- Seng Pei Liew, Tsubasa Takahashi, Shun Takagi, Fumiyuki Kato, Yang Cao, Masatoshi Yoshikawa
発表アーカイブ動画
今回の発表形式
今回のSIGMOD 2022はハイブリッド開催でしたが、LINEの発表はオンラインにて実施しました。発表者が事前に動画を収録し、当日は質疑応答のみを口頭で行う形式で、プレゼンテーションが進行しました。発表、質疑応答ともにリュウが担当しました。他の発表者や参加者からいくつか質問を頂きました。今後の研究の参考としたいと考えています。
第43回先端的データベースとWeb技術動向講演会
ACM SIGMOD 日本支部,日本データベース学会が主催の第43回先端的データベースとWeb技術動向講演会(ACM SIGMOD 日本支部第80回支部大会)にて、SIGMOD2022国際会議報告を実施する機会を頂戴しました。本講演会は、8月4日にオンラインにて開催されました。
髙橋からSIGMOD2022の概要や論文採択の傾向、パネル討論やキーノート、Best Paper Award受賞論文の紹介をしました。リュウからは上述の採択論文Network Shufflingについて紹介しました。詳細は以下の講演資料をご参照ください。
当日のQAでは、SIGMODの査読プロセスの他学会との違いや、Best Paper Award受賞論文の詳細について質問を頂きました。SIGMODのパネル討論の場でも、この2,3年で査読の質が向上したとの意見がありました。我々の実体験としても質の高い、前向きで建設的なレビューコメントを頂戴しています。学生の皆様に非常におすすめな論文投稿先であると感じます。SIGMOD2023は、米国シアトルで開催される予定です。
今後の講演予定
ML Privacyチームでは、以下の国際会議発表、国内会議での論文発表・講演を予定しています。こちらも是非ご参加ください。
- 9月5〜9日:VLDB2022採択論文、HDPViewの発表 (元インターンの加藤さん・髙橋)
- 9月13〜15日:FIT2022 トップコンファレンスセッション (リュウ)
LINEが注力するプライバシー保護技術の研究開発について
LINEでは、ユーザーデータを活用したパーソナライゼーションに力を入れており、同時にデータを扱う際のプライバシーへの配慮についても重要視しています。
近年、国際的な規制の整備も進み、プライバシー保護の技術や考え方もめざましい発展を遂げています。時流に即した最適なプライバシーモデルの追求と導入は、プラットフォーマーとしての重要な責任です。LINEでは、連合学習や差分プライバシー、秘密計算等の先端的なプライバシー保護型機械学習技術の検証や実装を推進し、十分なプライバシーへの配慮と多様なユーザーへ深いパーソナライズの両立を目指しています。
プライバシー保護に関する研究開発の成果として、これまでLINEとしては、「ICDE2021」や「ICLR2022」といった世界トップレベルの国際会議で、差分プライバシーに関する論文の採択実績があります。差分プライバシーはユーザーデータ収集・活用にあたって、所定のノイズやランダム性を追加することによって、あらゆる人と見分けがつかない出力結果とする際に用いられる、数学的に厳密なプライバシー基準です。現在、LINEでは差分プライバシーによるプライバシー保護型データ活用の実用化に向け、研究開発に取り組んでいます。
最後に
LINEでは、以下の職種にてプライバシーxデータサイエンス・機械学習の研究者ならびにエンジニアを積極的に採用しています。興味がございましたら応募をご検討ください!!