
안녕하세요. LINE 미디어 플랫폼 개발과 운영 업무를 담당하고 있는 하태호입니다. 지난 글(4편)에선 앞서 블로그(서버 사이드 테스트 자동화 여정 1편, 2편, 3편)를 통해 소개했던 자동화 시스템에 이어서 성능 테스트를 자동화하게 된 계기와 목표, 구성한 환경에 대해 소개했는데요. 이번 글에선 자동화된 성능 테스트의 리포트를 생성한 방법과 자동화된 성능 테스트를 실제로 적용하면서 겪었던 일을 공유하겠습니다.
리포트 생성하기
시스템과 JVM 지표 시각화하기
미디어 플랫폼 조직에선 각종 지표를 좀 더 정밀하게 모니터링하면서 쉽게 분석하기 위해 기본적으로 제공되는 전사 모니터링 플랫폼 외에도 Grafana와 Prometheus를 이용해 다양한 시스템 지표를 수집하고 모니터링하고 있습니다. Prometheus가 제공하는 대표적인 익스포터(exporter) 중 하나인 노드 익스포터를 사용하면 CPU와 메모리, 로드, swap, 디스크와 같은 기본적인 시스템 자원 지표를 확인할 수 있는 대시보드를 쉽게 만들 수 있습니다. 또한 JVM 지표는 Spring Boot 2.0부터 기본 탑재된 Micrometer를 이용하면 모니터링 시스템을 위한 코드를 별도로 작성하지 않아도 여러 지표를 쉽게 확인할 수 있는데요. Spring Boot Actuator에서 제공하는 Prometheus Endpoint를 활용하면, GC와 힙 메모리 상태, 스레드 블로킹 정보, 다이렉트 메모리 사용률, 열려있는 파일 지시자(file descriptor) 수 등을 확인할 수 있는 대시보드를 만들 수 있습니다.

애플리케이션 지표 시각화하기
애플리케이션 영역의 지표는 문제가 발생할 경우 추적할 수 있어야 하기 때문에 단순히 시각화만 가능한 도구를 사용하는 것은 좋지 않겠다고 생각했습니다. 일반적으로 APM(Application Performance Management) 도구를 사용하면 요청을 추적할 수 있는데요. 여러 APM 도구 중 NAVER Pinpoint를 검토했습니다.1 Pinpoint는 트레이싱(tracing) 기능을 제공하고, 성능에 문제가 되는 지점의 메서드 명까지 알려주는 강력한 기능을 갖추고 있으며, 무엇보다 Pinpoint 개발 팀에서 직접 운영하는 사내 Pinpoint 서비스가 있기 때문에 사용하고 싶었습니다. 어디가 문제인지까지 알려주는 Pinpoint의 기능은 성능 테스트 리포트에 포함하고 싶은 정보를 제공할 수 있었습니다. 하지만 아쉽게도, 미디어 플랫폼에서 운영하는 서버 모듈이 Netty 기반으로 개발되어 완전하게 추적할 수 없거나 혹은 아예 추적이 불가능해서 사용할 수 없었습니다.2 Pinpoint와 같은 강력한 APM 도구를 사용하지 못하는 아쉬움은 있지만, 접속 로그를 기반으로 문제를 추적해 나가는 것도 충분히 가능하기 때문에 ELK를 사용하기로 결정했습니다. Kibana가 제공하는 강력한 시각화 기능과 Elasticsearch의 조건 검색 기능을 활용하면, 문제가 되는 요청이나 패턴을 쉽게 찾을 수 있어서 테스트 자동화를 진행하기 전과 비교할 때 문제를 추적하는 데 소요되는 시간을 획기적으로 줄일 수 있습니다.

Kibana를 선택한 또 다른 중요한 이유 중 하나는 Kibana가 시간의 경과에 따른 성능 패턴이나 이상치를 쉽게 확인할 수 있는 산포도(scatter plot)를 지원하기 때문입니다(사실 쉽게 도입할 수 있는 다른 선택지가 없기도 합니다). Kibana는 6.2 버전부터 시각화 라이브러리 중 하나인 'Vega'를 기반으로 새로운 형태의 시각화 방법을 제공합니다. 이를 통해 기존 Kibana 시각화가 지원하지 못했던 형태의 인터랙티브 시각화가 가능해졌습니다.3 Vega 방식의 시각화는 마우스 클릭으로 그래프를 그릴 수 있는 Kibana의 다른 시각화와 비교할 때 다소 불편한 것은 사실이지만, Hjson 문법에 맞춰서 Elasticsearch에 저장된 데이터 값과 차트에 표시할 값을 매핑하면, 고품질의 인터랙티브 차트를 단기간에 그릴 수 있다는 장점이 있습니다. 또한 기존에 Kibana를 사용해 봤다면 그리는 것도 크게 어렵지 않습니다. 다만, Vega는 6.2 버전부터 'experimental feature'로 지원되기 시작했는데요. 7.6 버전까지 출시된 현시점에서도 여전히 experimental feature로 제공되고 있다는 점이 조금 아쉽습니다.
아래는 Hjson 문법으로 정의한 코드와 그 결과 그래프의 예시입니다. 몇 가지를 설정하는 것만으로도 높은 수준의 시각화 결과물을 생성할 수 있습니다.
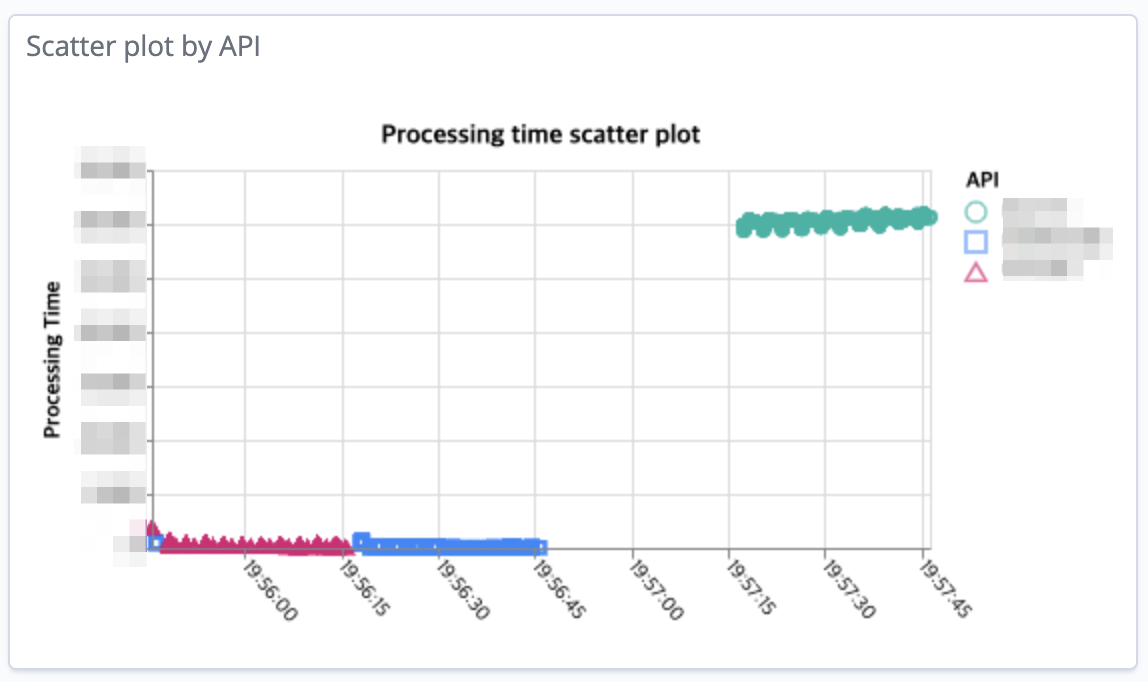
일부 요청의 처리 시간이 다른 요청 대비 오래 걸렸다는 것을 산포도를 통해 쉽게 인지할 수 있는 예
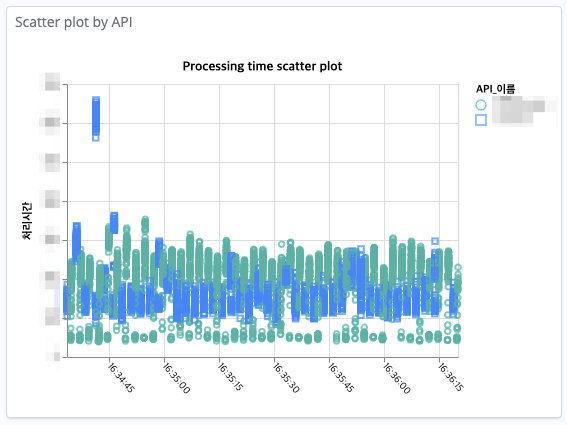 |
|
지표 캡처하기
웹 브라우저에 표시된 화면을 그대로 캡처하고 싶을 땐 GUI 없이 구동되는 헤드리스(headless) 브라우저를 사용합니다. Puppeteer는 Chrome DevTools 개발 팀이 직접 개발하고 유지 보수하는 헤드리스 브라우저 라이브러리 중 하나인데요. 사용법이 간단합니다. 아래는 Puppeteer GitHub 공식 가이드에서 안내하고 있는 화면 캡처 코드입니다. API가 직관적이어서 어떤 동작을 하는지 쉽게 이해할 수 있을 것이라고 생각합니다. Puppeteer를 통해 캡처된 이미지를 정적(static) 리소스 저장소에 업로드한 뒤 리포트에 첨부합니다.
// https://github.com/puppeteer/puppeteer/blob/master/README.md
// https://example.com에 접속하면 보이는 화면을 example.png라는 파일 이름으로 저장한다.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();리포트 생성하기
성능 테스트 자동화의 목적 중 하나가 개발 단계에서 성능과 관련된 문제를 발견하고 개선하는 데 도움이 될만한 유의미한 인사이트를 제공하는 것이었습니다. 따라서 리포트를 개발자의 시선이 자주 닿는 곳에 위치시켜야겠다고 생각했는데요. 미디어 플랫폼의 개발자는 코드 리뷰에 상당히 많은 시간을 투자하고 있고, 성능 테스트 리포트는 코드 변경에 따른 성능 변화를 측정한 리포트이기 때문에 풀 리퀘스트의 댓글로 리포트를 제공하면 좋을 것 같았습니다. 이전 글에서 말씀드렸듯, 이미 다른 테스트의 수행 결과도 GitHub 댓글로 제공하고 있었기 때문에 개발자가 업무 방식을 바꾸지 않아도 리포트를 볼 수 있도록 제공할 수 있었습니다. 리포트는 아래와 같은 형태로 제공합니다.
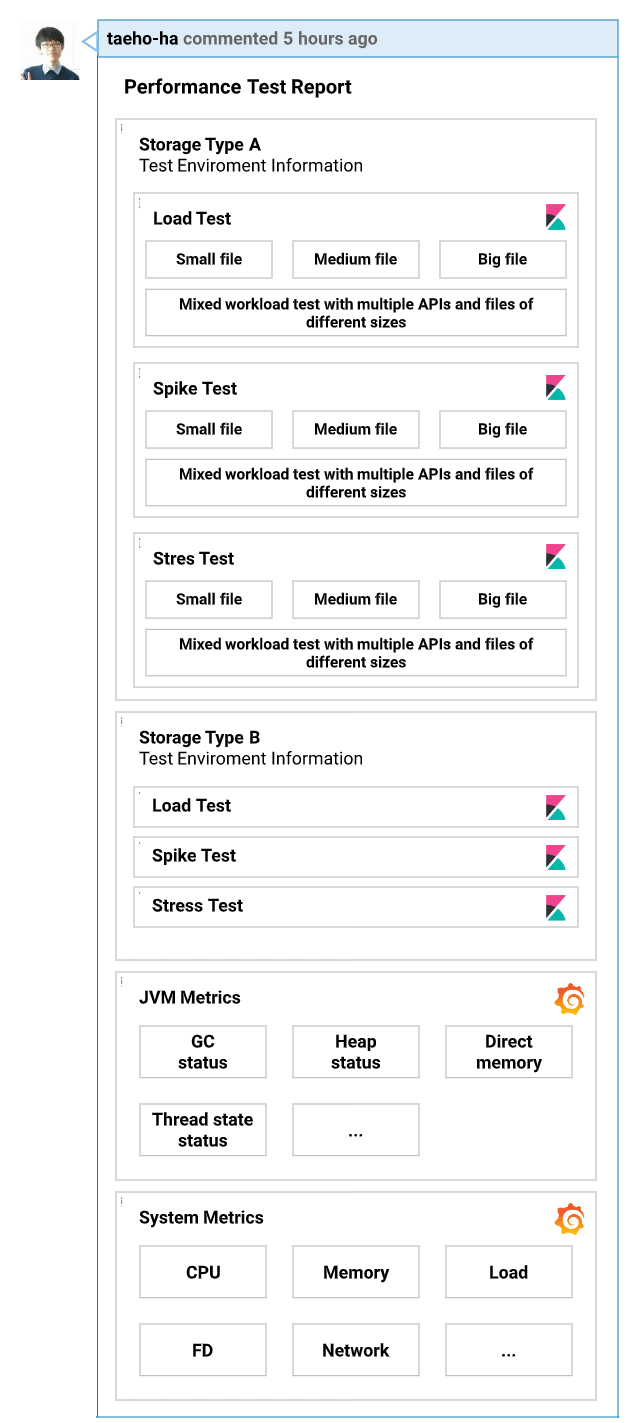
성능에 민감한 코드가 수정된 풀 리퀘스트를 리뷰할 때 위와 같은 성능 테스트 리포트를 미리 참고한다면 리뷰어가 좀 더 정밀하게 리뷰할 수 있을 것으로 기대하고 있습니다.
자동화된 성능 테스트 환경의 구성과 리포트를 생성하기 위한 데이터 흐름
자동화된 성능 테스트 및 성능 테스트 리포트를 생성하기 위한 구성은 아래와 같습니다. 여러 개의 IDC에서 수행되는 테스트는 서로 다른 IDC 간에 트래픽을 발생시키지 않으며, 하나의 마스터 Jenkins로 관리하므로 관리 부담이 적습니다. 테스트 수행 결과로 수집된 데이터는 차트로 시각화하여 정적(static) 리소스 저장소에 업로드한 후 리포트에 첨부합니다.
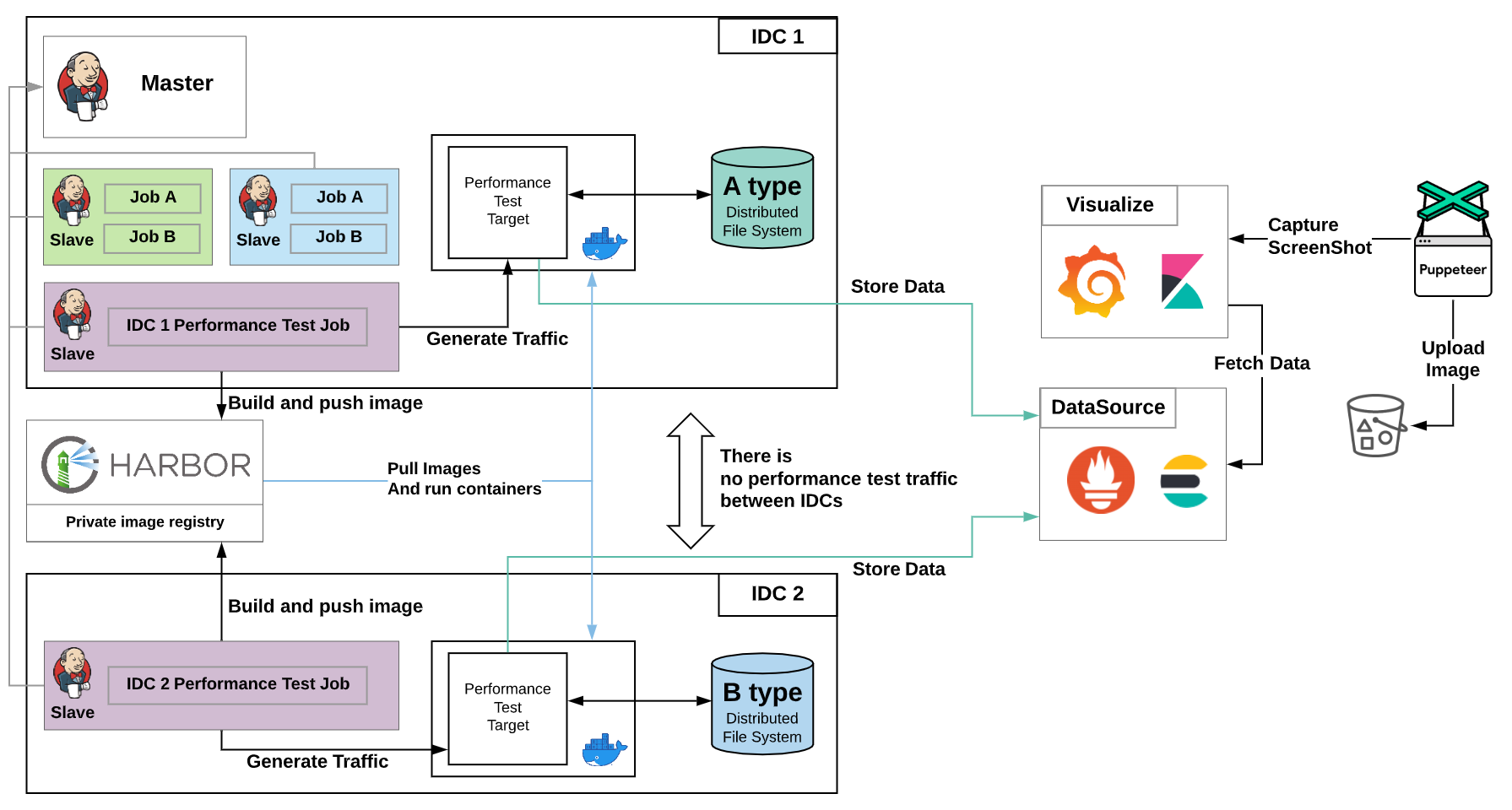
성능 테스트 자동화 시스템 적용 결과
시험 적용 첫날 발견된 이슈
서버 기동 직후 순간적으로 많은 요청이 유입되면 수백 개의 스레드가 블록된(blocked) 상태에 머무르는 문제가 발견됐습니다. 원인은 실행하는 데 오래 걸리는 초기화 작업이 중복으로 진행되는 것을 막기 위해 사용한 락(lock) 때문이었습니다. 정상적인 배포 시나리오에서는 서버 기동 직후 한꺼번에 수백 개의 요청이 유입되지는 않기 때문에 이런 현상이 관측되지 않았습니다. 따라서 일반적인 상황에서는 큰 문제가 되지 않을 수도 있었습니다. 하지만 만약 대규모 장애가 발생해 모든 서버가 다운된 뒤 이를 복구하는 과정에서 소수의 서버가 다수의 서버가 처리하던 규모의 요청을 받게 되는 상황이 발생한다면, 실제 서비스에서도 아래 그래프와 같이 장애를 복구하기 위해 서버를 재기동해도 정상적인 서비스가 불가능한 상황이 발생할 수 있는 사례였습니다. 이 문제에 대한 1차 개선은 완료한 상태입니다. 또한 코드 리뷰 중, 요청 처리 과정에서 락 경합이 아예 발생하지 않도록 만드는 아이디어가 나와 수정할 예정입니다.
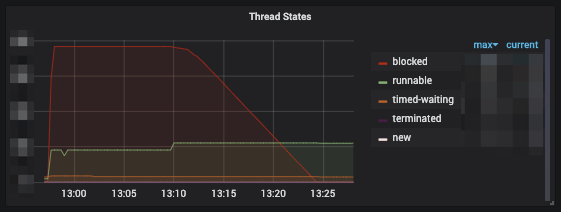
회귀(regression) 테스트에서 검출되지 않았던 이슈 발견
성능 테스트 리포트에서 특정 API에 대해 지속적으로 높은 응답 지연 현상이 발생하는 문제가 발견됐습니다. 성능 테스트 클라이언트에는 모든 요청에 대해 읽기 타임아웃이 발생했다는 로그가 기록되어 있었습니다. 문제는 논-블로킹(non-blocking) I/O가 가능하도록 구현됐어야 할 API 내부가 'FIXME: Non-Blocking 구현으로 변경 필요'라는 주석이 기재된 채 블로킹 함수 호출을 포함하고 있어서 가용한 스레드가 부족해지며 발생한 것이었습니다. 이 문제를 해결하는 과정에서 저희가 예상하지 않았던 스레드 풀에서 요청이 처리되고 있다는 점도 추가로 발견해 올바른 스레드 풀을 사용하도록 수정했습니다.
스토리지 레이어 성능 이슈 발견
스파이크 테스트와 로드 테스트 리포트에서 이상 징후가 발견됐습니다. 스파이크 테스트의 경우 순간적으로 이전 대비 6배 정도 많은 트래픽을 발생시키기 때문에 응답 지연이 발생할 수 있다고 생각했고, 클라이언트 측에서 읽기 타임아웃 임계치 값을 넘기지는 않았기 때문에 큰 문제는 아니라고 생각했습니다. 기대했던 만큼의 성능이 나오지 않는다는 생각이 들어 찜찜하긴 했지만 성능 테스트 자동화 작업을 진행하던 시기가 성능 최적화 작업을 진행해야 할 시점은 아니었기 때문에 자세히 분석해서 최적화 작업을 진행하지는 않았습니다. 하지만 로드 테스트 리포트에서도 독특한 상어 지느러미 모양의 지표가 자주 발생하는 것을 보며 이상하다고 생각했습니다. 함께 수집한 지표들에서는 성능 저하를 발생시킬 만한 요소가 보이지 않았고, 상어 지느러미 형태의 리포트가 생성되기 전에 수만 번의 요청 처리 테스트를 진행한 상황이었기 때문에 애플리케이션 로직에서 자원을 동적으로 초기화한다거나 JVM에서 추가로 최적화 작업을 진행하는 등의 요소가 성능에 영향을 줄 것 같지 않았습니다.
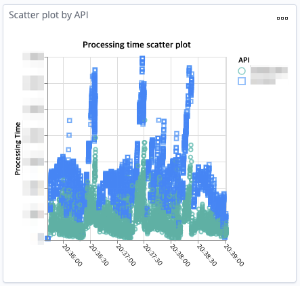
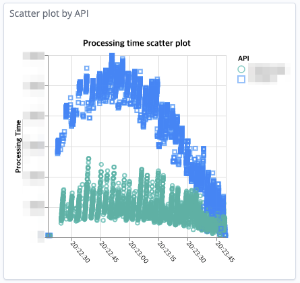
이 현상의 원인은 테스트 대상 모듈 입장에서는 외부 시스템인 스토리지 레이어 자체의 모니터링 지표를 확인하면서 파악할 수 있었습니다. 스토리지 레이어의 응답성 지표가 성능 테스트 대상 모듈과 동일하게 상어 지느러미 형태를 띠고 있었기 때문입니다. 이 리포트를 기반으로 스토리지 레이어 담당자와 이야기를 나누었습니다. 제보 당일 분석 결과를 공유해 주셨는데요. 문제가 된 시점에 스토리지 레이어 자체의 동적 최적화 작업이 수행되었다는 것을 알게 되었고, 이를 통해 실제 사용자가 사용하는 서비스 환경에서 스토리지 레이어를 운영할 때 유의해야 할 사항에 대해 팀이 인지할 수 있었습니다.
이처럼 항상 동일한 조건으로 성능 테스트가 수행되는 자동화 시스템을 업무에 적용했기 때문에, 향후 트래픽 패턴에 영향받지 않고 일관된 응답을 제공할 수 있도록 개선하는 데 투입되는 시간이 많이 줄어들 것으로 기대하고 있습니다.
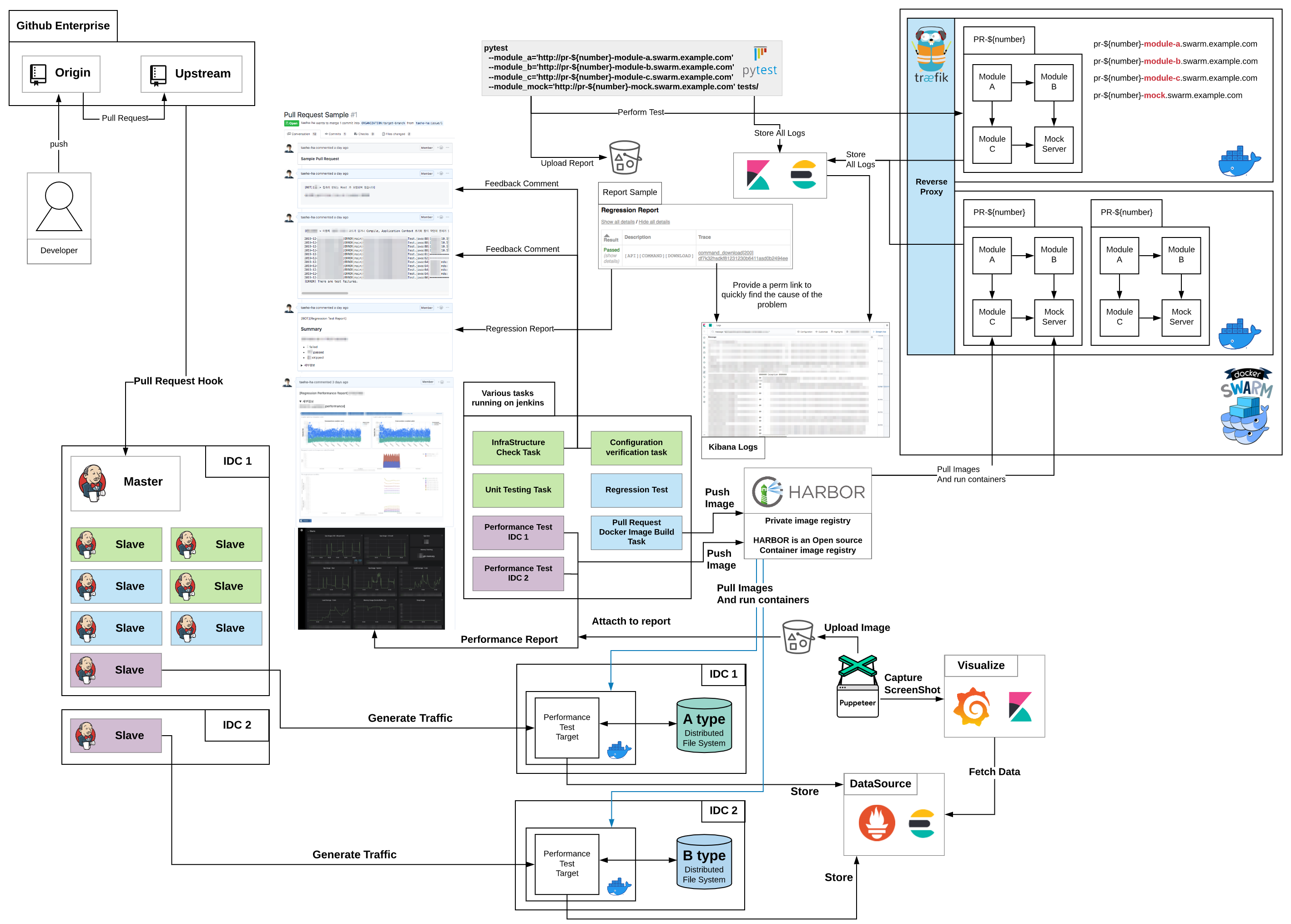
성능 테스트를 추가한 테스트 자동화 시스템의 구조
이전 블로그에서 소개했던 테스트 자동화 시스템 구조(참고)에 성능 테스트가 더해진 최종 구조를 간략하게 표현하면 아래 그림과 같습니다.
성능 테스트 자동화 여정을 돌아보며
LINE 메신저는 수많은 사용자의 일상과 밀접하게 닿아 있기 때문에 메신저로 유통되는 모든 형태의 미디어 파일을 처리하는 서버 개발 업무가 때로는 무겁게 느껴지기도 합니다. 하지만 LINE이 수많은 사용자가 다양한 방식으로 이야기를 나누기 위해 사용하는 도구의 역할을 잘 감당하고 있는 것을 볼 때, 사용량이 급증해도 큰 문제 없이 원활하게 서비스가 제공되는 것을 볼 때 서버 개발자로서 뿌듯함을 느낍니다.
이번 성능 테스트 자동화는 업무 우선순위 혹은 투입 공수의 문제로 자주 수행하지 못했던 테스트를 저렴한 비용으로 자주 수행할 수 있게 되었다는 것에 의의가 있다고 생각합니다. 아직 일부는 수동으로 진행해야 한다는 한계가 있긴 하지만, 코드 리뷰 단계에서 파악하기 어려운 GC나 스레드 관련 문제를 확인할 수 있게 되었다는 점과, 자주 발생하진 않지만 서비스가 중단되면 안 되는 상황에 대한 테스트가 추가되면서 더욱 안정적인 서비스를 개발하는 데 도움이 될 것으로 기대합니다. 비록 기능 회귀 테스트와 같이 PR이 생성된 후 10~20분 만에 결과가 나오는 것은 아니지만 1~2시간 내로 성능 테스트 수행 결과가 댓글로 달린다니 즐거운 일 아니겠습니까? 또한 성능 테스트 자동화와 함께 진행한 기능 테스트 개선 작업을 통해 여러 IDC에서 동작하는 DR(disaster recovery) 관련 시스템을 테스트하기 위한 기반도 갖추었습니다.
메신저로서의 기능을 넘어 사용자에게 즐거움을 주는 서비스, 생활 전반에 도움을 주는 생활 밀접형 서비스로 확장해 나가는 LINE 서비스 생태계를 지탱하고 있는 미디어 플랫폼은 자동화된 테스트 시스템을 기반으로 안정성을 잃지 않으면서도 더욱 빠르게 새로운 기능을 추가할 준비가 되었습니다. LINE 메시징 서비스와 LINE 패밀리 서비스를 통해 전 세계의 사용자가 발생시키는 막대한 규모의 트래픽을 안정적으로 처리하는 경험을 함께 해보고 싶지 않으신가요? 대규모 트래픽을 안정적으로 처리하는 일에 관심이 있다면 적극 지원해 주세요! We are hiring!
- LINE 미디어 플랫폼 채용 공고
- LINE 미디어 플랫폼 관련 블로그
- LINE의 인프라 비용을 절감한 6가지 사례
- Antman 프로젝트 개발기
- 서버 사이드 테스트 자동화 여정
- https://engineering.linecorp.com/ko/blog/server-side-test-automation-journey-1/
- https://engineering.linecorp.com/ko/blog/server-side-test-automation-journey-2/
- https://engineering.linecorp.com/ko/blog/server-side-test-automation-journey-3/
- https://engineering.linecorp.com/ko/blog/server-side-test-automation-4/
- LINE Transcoding Server 아키텍처
- Pinpoint 외에도 scouter 혹은 elastic APM과 같은 오픈소스 도구가 있습니다.
- Pinpoint는 Netty 기반으로 개발된 다양한 서버 프레임워크와 클라이언트 구현체를 지원합니다. 다만, 미디어 플랫폼의 서버 모듈의 경우 잘 알려진 서버 프레임워크를 사용하지 않고 직접 Netty를 기반으로 개발한 내부 프레임워크와 스레딩(threading) 모델을 사용하기 때문에 Pinpoint를 이용해서 자세히 추적하기가 어렵습니다. 이는 Pinpoint뿐 아니라 다른 APM 도구를 사용한다고 해도 비슷합니다. Pinpoint는 별도 옵션을 통해 자체 개발한 애플리케이션을 트레이싱하는 것을 지원하는데요. 관련 사항은 https://naver.github.io/pinpoint/faq.html#my-custom-jar-application-is-not-being-traced-help에서 확인할 수 있습니다. Pinpoint에서 지원하는 모듈이 궁금하다면 https://github.com/naver/pinpoint에서 확인할 수 있습니다.
- 더 자세한 소개는 elastic 블로그(https://www.elastic.co/blog/getting-started-with-vega-visualizations-in-kibana, https://www.elastic.co/blog/custom-vega-visualizations-in-kibana)에서 확인하시기 바랍니다.