
안녕하세요. LINE 미디어 플랫폼 개발과 운영 업무를 담당하고 있는 하태호입니다. LINE 내 수많은 서비스가 사용하는 미디어 플랫폼은 앞서 블로그(서버 사이드 테스트 자동화 여정 1편, 2편, 3편)를 통해 소개했던 자동화 시스템을 이용해 지속적으로 테스트하고 있습니다. 개발자들은 자동화 시스템에 계속 추가되는 테스트 케이스 덕분에 단순한 API 호출과 관련된 문제만 확인하는 것이 아니라, 실제 서비스에서 API를 호출하는 흐름 중에 발생하는 문제도 코드 리뷰 시작 전부터 확인하는 등 많은 도움을 받고 있는데요. 이번 글에서는 더 나아가 성능 테스트를 자동화하며 겪은 일들을 공유하고자 합니다.
성능 테스트 자동화를 시작한 이유
개발 업무 환경에 테스트 자동화가 적용된 후 팀원 분들이 업무를 진행하는 방식이 조금씩 변화하기 시작했다는 것을 알게 되었습니다. 이전엔 변경 사항을 테스트하기 위해 로컬 개발 환경에 변경 사항을 다운로드해서 여러 모듈을 기동시키며 테스트했는데요. 이젠 PR(Pull Request) 단위로 프로비저닝되는 각 모듈의 도메인을 이용해 테스트를 진행하기 때문에 PR을 검증하기 위한 테스트 환경을 준비하는 시간이 단축되었습니다. 또한 동시성 이슈를 사전에 탐지하기 위해서, 소량의 트래픽을 생성하기 위해 작성해 두었던 테스트 케이스를 대량의 트래픽을 생성할 수 있도록 수정하여 본인의 작업 내역을 검증한 것과 같은 응용 사례도 나타났습니다. 테스트 자동화 활동이 단순히 서비스 운영의 안정성과 업무 생산성을 향상시키는 효과만 가져온 것이 아니라, 업무 방식을 변화시키며 관련 응용 사례를 창출해 팀에 새로운 변화를 불어넣은 것인데요. 이를 보니 모듈의 성능 측면에서 발생하는 병목 현상을 개선하고 한계 상황을 자동으로 평가하는 작업을 더 이상 미루고 싶지 않았습니다. 마침 2편에서 소개했던 서로 다른 DFS(Distributed File System)를 사용할 수 있도록 개선하는 프로젝트에 성능 테스트가 필요한 시점이 다가오고 있었기 때문에, 주 개발 업무를 수행하면서 미리 성능 테스트 자동화 작업을 조금씩 해둔다면 잘 사용할 수 있겠다는 생각이 들어 작업을 시작했습니다.
성능 테스트 자동화 목표 세우기
성능 테스트 결과로 무엇을 확인하고 싶은가?
성능 테스트 자동화 작업을 진행하기에 앞서 성능 테스트를 통해 어떤 결과를 확인하고 싶은지 정의할 필요가 있었습니다. 그래서 성능 테스트 결과에서 확인해야 하는 기본적인 항목을 아래와 같이 정리했습니다.
- 기본적인 시스템 자원 지표 (CPU 사용량, 메모리 사용량, 로드(load), 스왑(swap) 사용량, 디스크 I/O 등)
- 초당 요청 처리 건수
- 처리 시간
- 처리량
그런데 정리하고 나니 이런 지표들이 개발 단계에서 성능과 관련된 문제를 발견하고 개선하는 데 유의미한 인사이트를 제공할 수 있을지 의문이 들었습니다. 이런 지표를 통해 '성능에 문제가 있다 혹은 없다'라는 사실은 확인할 수 있지만, '무엇이 문제인지' 또는 '어디가 문제인지'와 같은 정보는 얻을 수 없다고 생각했기 때문입니다. 성능 저하 문제가 발견됐을 때, 자동화 시스템이 제공하는 데이터를 통해 문제의 범위를 좁히지 못한다면 개발자는 문제를 확인하기 위해 상황을 재현해야 합니다. 그런데 일반적으로 성능과 관련된 문제를 재현하는 데는 많은 시간이 소요되고 문제를 진단하기 위한 데이터를 수집하기 위한 시간도 추가로 필요하기 때문에, 성능 테스트를 자동화하면서 무엇이 문제인지 파악할 수 있는 실마리를 제공하지 못한다면 개발자에게 크게 도움이 되지 못할 것 같다는 생각이 들었습니다. 그래서 어떻게 해야 문제 해결의 실마리를 함께 제공할 수 있을지 고민했는데요. 해답은 생각보다 간단했습니다. 성능과 관련된 문제가 발생했을 때 확인할 필요가 있는 애플리케이션 상태 관련 지표를 모두 함께 수집해 두는 것이었습니다.
JVM에서 동작하는 시스템에선 아래와 같은 정보를 수집한다면 성능과 관련된 문제를 파악하면서 해결의 실마리도 찾을 수 있습니다.
- GC(Garbage Collection) 및 힙(heap) 메모리 상태
- 스레드(thread) 상태 정보
- 다이렉트 메모리 사용률
- 스레드 개수
- 열려있는 파일 지시자(file descriptor)의 수
- 발행되는 로그양
성능 테스트를 수행한 후 위 지표들을 리포트로 제공할 수 있다면, '문제가 있다'는 사실과 함께 어떤 부분에 중점을 두고 추적하면 되는지 단서도 제공할 수 있겠다고 생각했습니다.
자동화 테스트 범위 정하기
정확한 성능 테스트를 수행하기 위해서는 테스트 환경을 실제 서비스 환경과 최대한 유사한 환경으로 구성할 필요가 있습니다. 하지만 규모가 큰 시스템에서는 실제 서비스 환경과 유사한 테스트 환경을 구성하는 게 쉽지 않습니다. 서비스를 무중단으로 운영하기 위해서 대부분의 구성 요소를 고가용성이 보장되도록 개발하고 구성하다 보니 최소한으로 구성한다고 해도 필요한 서버의 개수가 많기 때문입니다. 특히 사용자의 체감 성능을 향상시키고 코어 시스템의 부하를 낮추기 위해 겹겹이 쌓아둔 캐시 레이어는 멀티 티어(tier)로 구성되고 캐싱(caching) 전략이 동적으로 변하기 때문에, 테스트하기 위해 이를 모방하는 구성을 자동화하는 것은 까다로울 뿐만 아니라 비용도 많이 듭니다. 또한 실제 서비스는 전 세계의 사용자가 불편함 없이 사용할 수 있도록 다수의 PoP(Point of Presense)을 이용하여 구성하는데요. 각 PoP별로 운용 가능한 서버 사양이나 구성이 상이하기 때문에 '실제 서비스 환경과 유사한 구성'이 무엇인지 정의하기가 쉽지 않습니다.
이런 점들을 고민하다 보니 실제 서비스 환경을 모방하는 것보다는, 우리 시스템에 맞는 표준 테스트 환경을 정의 및 구성한 뒤 표준 테스트 환경에서 생성된 테스트 결과를 참조하여 각 PoP별 상황에 맞게 튜닝하는 게 좋겠다고 생각했습니다. 모든 서비스 환경의 구성을 동일하게 설정할 수 없다는 것을 감안하고 성능 테스트를 수행해야 한다면, 성능 문제가 발생할 가능성이 가장 높고 변화가 가장 잦은 모듈을 일관된 환경에서 테스트해야 한다고 생각했습니다. 그래서 아래와 같이 '표준 테스트 환경'과 '테스트 범위'를 정의했습니다.
- 표준 테스트 환경
- 테스트 대상 모듈이 현재 서비스에서 사용 중이거나, 앞으로 사용하게 될 사양과 비슷한 수준의 서버 중 사내에서 가장 수급이 원활한 서버와 유사한 네트워크 환경으로 구성(추후 해당 장비와 동일한 장비를 구할 수 없다면 유사한 사양으로 준비 가능한 서버를 선택)
- 테스트 범위
- 로직이 가장 자주 변하거나 스토리지 입출력을 전담하기 때문에 병목 구간이 될 수 있는 단일 모듈(캐시 레이어를 모두 비활성화한 상태로 테스트)
조금 특이한 점은 캐시 레이어를 모두 비활성화한 상태로 테스트한다는 부분인데요. 캐시 레이어가 동작하지 못하는 상태에서도 모듈이 어느 정도의 성능을 보장할 수 있는지 평가하고, 동적으로 변경되는 캐싱 전략 때문에 테스트를 반복할 때 재현 가능성이 보장되지 않는 문제를 제거하기 위해서 모든 캐시 레이어를 제거한 상태로 테스트하기로 결정했습니다. 물론 실제 서비스에서는 캐시 레이어의 역할이 굉장히 중요하기에 테스트 범위에서 제외한다는 게 마음에 걸리긴 했습니다. 하지만 캐시 레이어를 비활성화한 상태로 진행하는 것은 자동화된 테스트에 한정된 내용으로, 실제로 서비스에 투입하기 전에 추가로 진행하는 테스트에서는 캐시 레이어가 포함된 상황에서 검증하고 있고, 캐시 자체에 대한 성능 테스트도 별개로 진행하고 있기 때문에 자동화 테스트에서는 캐시 레이어를 비활성화해도 큰 문제가 없다고 판단했습니다.
어떤 형태의 성능 테스트를 진행할 것인가?
테스트 자동화를 도입하는 것도 물론 중요한 일이지만, 새로운 기능 개발과 기능 개선, 혹은 플랫폼에 연동된 서비스를 지원하는 것이 더욱 우선순위가 높은 일이기에 테스트 환경을 개선하는 데 단번에 많은 시간을 투자하는 것은 어렵다고 판단했습니다. 따라서 테스트 환경에 기능을 조금씩 추가한 뒤 그 피드백을 기반으로 발전시켜 나가야겠다고 생각했습니다. 이런 과정을 통해 단순한 테스트를 넘어 시스템을 보다 폭넓게 이해할 수 있도록 도와주는 테스트가 될 것으로도 기대했습니다.
이런 생각을 바탕으로 다양한 성능 테스트 방법 중 로드(load) 테스트와 스트레스 테스트, 그리고 스파이크(spike) 테스트를 먼저 적용하기로 결정했습니다. 이중 스파이크 테스트는 1차 작업 범위에 포함시킬지 말지 고민했는데요. 돌이켜 보면 미디어 플랫폼 사용량의 많은 부분을 차지하는 LINE 메신저 서비스의 특성상 속보가 들어오거나 대형 이벤트 혹은 재난 상황이 발생한 것과 같은 경우에 트래픽이 순간적으로 폭증하는 경우가 종종 있었습니다. 특히 매년 각 국가가 속한 시간대별로 1월 1일 0시 0분 즈음에는 새해맞이 덕담을 나누며 미디어 파일을 송수신하는 사용자가 순간적으로 폭증하기 때문에 스파이크 테스트는 반드시 포함해야겠다고 판단했습니다.
반면 내구(endurance) 테스트는 고민 끝에 포함시키지 않는 걸로 결정했습니다. 한 번 배포가 된 코드는 최소 몇 시간에서 길게는 며칠간 안정적으로 동작할 수 있어야 하기 때문에 내구 테스트를 통해 이를 판단할 수 있게 된다면 좋겠지만, 테스트 목적 자체가 오랜 시간 부하를 가하며 시스템을 평가하는 것이기 때문에 개발자에게 빠른 피드백을 제공하기 어려웠습니다. 본 연재 1편부터 3편까지의 내용에서 테스트 결과를 빠르게 제공할 수 있도록 많은 노력을 기울이고 있다고 말씀드렸는데요. 저희는 빠른 피드백이 업무 생산성을 높이는 데 큰 역할을 한다고 생각하기 때문에 내구 테스트는 우선순위가 낮다고 판단했습니다. 또한 실제 서비스 배포 전에 카나리(canary) 배포를 통해 실 환경에서의 안정성도 평가하고 있어서 제외해도 큰 문제가 없다고 판단했습니다.
테스트는 어떻게 수행할 것인가?
테스트 범위와 수행할 테스트의 종류를 정하고 나니 이제 어떻게 부하를 생성할지 결정해야 했습니다. 사내에서는 nGrinder를 주요 IDC(Internet Data Center)마다 설치해 서비스 형태로 제공하고 있으며, nGrinder에서 REST API를 제공하고 있기도 한데요. 기존의 테스트 자동화 시스템과 연동하는 관점에서 검토해 보았을 때 자동화하기 어려운 부분이 있어 사용하기 어렵다고 판단했습니다.
20년이 넘는 기간 동안 많은 개발자가 사용하고 있는 JMeter도 검토했지만 적합하지 않았습니다. JMeter는 그 역사와 명성에 걸맞게 다양한 기능을 지원하고 있었는데요. CLI(Command Line Interface)를 제공하는 것은 물론, RPS(Requests Per Second)와 처리량(throughput), 지연 속도(latency), 응답 시간(response time) 등을 확인할 수 있는 리포트도 제공하고 있어서 테스트 자동화 시스템에 적용하기에 편리해 보였습니다. 널리 사용되는 도구인 만큼 향후 유지 보수가 용이하고 새로 참여하는 개발 인력이 업무를 빠르게 파악할 수 있다는 점도 장점이었습니다. 하지만 assert 수행 시 특정 로직을 실행하는 게 필요했고, 조건이 복잡해지면 테스트를 수행하는 게 어려워질 수도 있었습니다. 또한 JMeter CLI를 이용해 테스트를 수행할 때도 테스트 플랜 파일을 작성하고 수정하는 건 GUI(Graphic User Interface)를 이용해야 했고, 스레드 개수를 늘려서 부하량을 높이는 방식이어서 저희가 원하는 양의 트래픽을 생성하는 게 어려울 것 같다고 판단했습니다. 물론 JMeter가 여러 개의 장비에서 대량의 트래픽을 생성하는 분산(distributed) 테스트 기능을 제공하긴 하지만, 시스템을 복잡하게 만들고 싶지 않았고 장비도 너무 많이 필요했습니다.
결국 여러 고민 끝에 Python으로 직접 부하 생성기를 만들기로 결정했습니다. 최신 Python 버전부터 공식 지원되는 async, await 키워드를 활용한 코루틴과 함께 asyncio 라이브러리를 활용하면 Python으로도 비동기 처리가 쉽게 가능하기 때문에 대량의 HTTP 요청을 동시에 생성할 수 있습니다. 또한 이전 블로그 글에서 언급했던 기능 테스트에서 사용한 평가 대상 모듈의 클라이언트 구현체가 이미 있었고, 이 구현체는 일부 고성능 처리가 필요한 API에 대해서 비동기로 처리할 수 있도록 개발되어 있었습니다. 덕분에 부하 생성 및 패턴을 결정할 수 있는 부분만 구현하면 되니 많은 시간이 필요하지 않을 것 같았습니다. 또한 스파이크 트래픽을 생성할 때 추가 공수 없이 비동기로 실행할 작업의 개수만 늘려주면 되는 등 자유롭게 원하는 형태와 수준의 트래픽을 생성할 수 있고, Python으로 직접 코드를 작성하니 테스트와 관련된 변경 사항을 Git으로 추적할 수 있으며, 이미 구성되어 있는 자동 배포도 활용할 수 있어서 테스트 환경을 최신 상태로 업데이트하는 시간도 줄일 수 있기 때문에 나쁘지 않은 선택이라고 판단했습니다.
결과 리포트는 어떻게 생성할 것인가?
직접 만든 부하 생성기를 이용하니 자유도가 높아서 좋기는 했지만 결과 리포트를 생성하는 게 문제였습니다. 이미 잘 만들어져 있는 외부 솔루션을 사용하면 해당 솔루션에서 제공하는 결과 리포트를 그대로 사용하면 되지만, 직접 만드는 바람에 결과 리포트도 스스로 해결해야 했습니다. 처음에는 차트 라이브러리를 이용해서 직접 시각화를 진행해 볼까 생각했는데요. 검토하다 보니 복잡하게 표현될지도 모를 다양한 차트를 생성하기 위해서 코드를 일일이 작성하는 건 시간도 많이 필요하고 유지 보수 관점에서도 좋지 않다는 생각이 들었습니다. 그래서 고민 끝에 코딩 없이 시각화가 가능한 도구를 이용하여 시각화를 진행한 후 결과 이미지를 캡처해서 보고서에 첨부하는 방법을 선택했습니다.
성능 테스트 자동화 환경 구성하기
성능 테스트를 하기 위한 빌드 결과물 배포는 기존의 자동화 테스트 파이프라인을 조금 수정해서 쉽게 구성할 수 있었습니다. 테스트 자동화 환경을 구성하던 초기부터 테스트 파이프라인이 복잡하게 변화해 나갈 것을 예상하고 Jenkins에서 제공하는 Pipeline 기능을 이용하여 테스트 파이프라인을 구성해 두었기 때문입니다. Jenkins Pipeline은 여러 Jenkins 노드와 잡(job)이 엮인 작업을 정의할 때 유용한데요. Blue Ocean UX를 이용하면 현재 구성되어 있는 파이프라인의 흐름을 쉽게 이해할 수 있고 확장도 간단하게 진행할 수 있습니다.
아래는 테스트 파이프라인을 변경하기 전과 후의 예시입니다. Jenkins는 파이프라인을 정의한 파일을 Git에서 읽어오는 것을 허용하기 때문에 필요하다면 Jenkins Pipeline의 정의에 대해서도 Github PR을 통해 코드를 리뷰할 수 있습니다.
| BEFORE | AFTER |
|---|---|
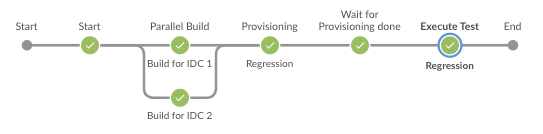 |
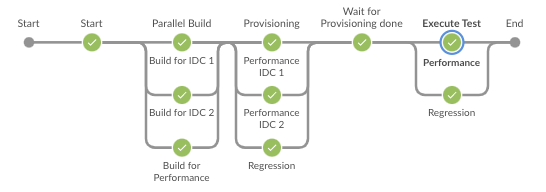 |
|
|
성능 테스트 목적의 빌드 결과물은 위 Pipeline을 통해 Docker 이미지로 배포되는데요. 빌드 결과물을 이미지로 만들어 두면 문제를 재현하고 싶을 때 쉽게 재현할 수 있다는 장점이 있기 때문에 Docker를 활용했습니다. 다만, 미디어 플랫폼의 서버 모듈은 대부분 고성능의 네트워크 I/O가 보장되어야 하는데 Docker를 사용하면 성능 테스트 결과가 왜곡되지 않을까 걱정했습니다. 그래서 네트워크 대역폭과 성능을 측정할 때 사용하는 iPerf 같은 도구로 성능을 측정해 보았습니다. 그 결과 약간의 성능 저하가 관측됐지만, 실제 서비스 운영 형태를 고려해 볼 때 허용 가능한 수치여서 큰 문제 없겠다고 판단했습니다. 또한 모든 성능 테스트를 Docker를 이용해서 진행한다면 모두 같은 수준의 성능 저하가 나타날 것이기 때문에 다른 빌드 버전과 성능 테스트 리포트를 비교할 때도 별문제가 되지 않을 거라고 생각했습니다.
성능 테스트 자동화 환경을 만들기 위한 배포 파이프라인 구성에서 조금 특이한 요구 사항이 있다면, 서로 다른 IDC에서 운용되는 서로 다른 분산 파일 시스템 구현체에 대해서 테스트를 진행해야 했다는 점입니다. 성능 테스트를 위한 트래픽을 서로 다른 IDC 간에 발생시키는 것은 실제 서비스 환경에서 발생하는 트래픽 흐름과 다를뿐더러, 불필요하게 네트워크 인프라를 사용하게 되기 때문에 동일한 IDC 내에서 트래픽을 발생시켜야 했습니다. 이 부분은 Jenkins의 라벨 기능을 활용해 해결할 수 있었습니다. 성능 테스트를 진행할 각 IDC에 슬레이브(slave) 노드를 배치하고 잡이 실행돼야 하는 노드를 라벨로 지정하면 동일한 IDC 내에서 트래픽이 발생하도록 구성할 수 있습니다.
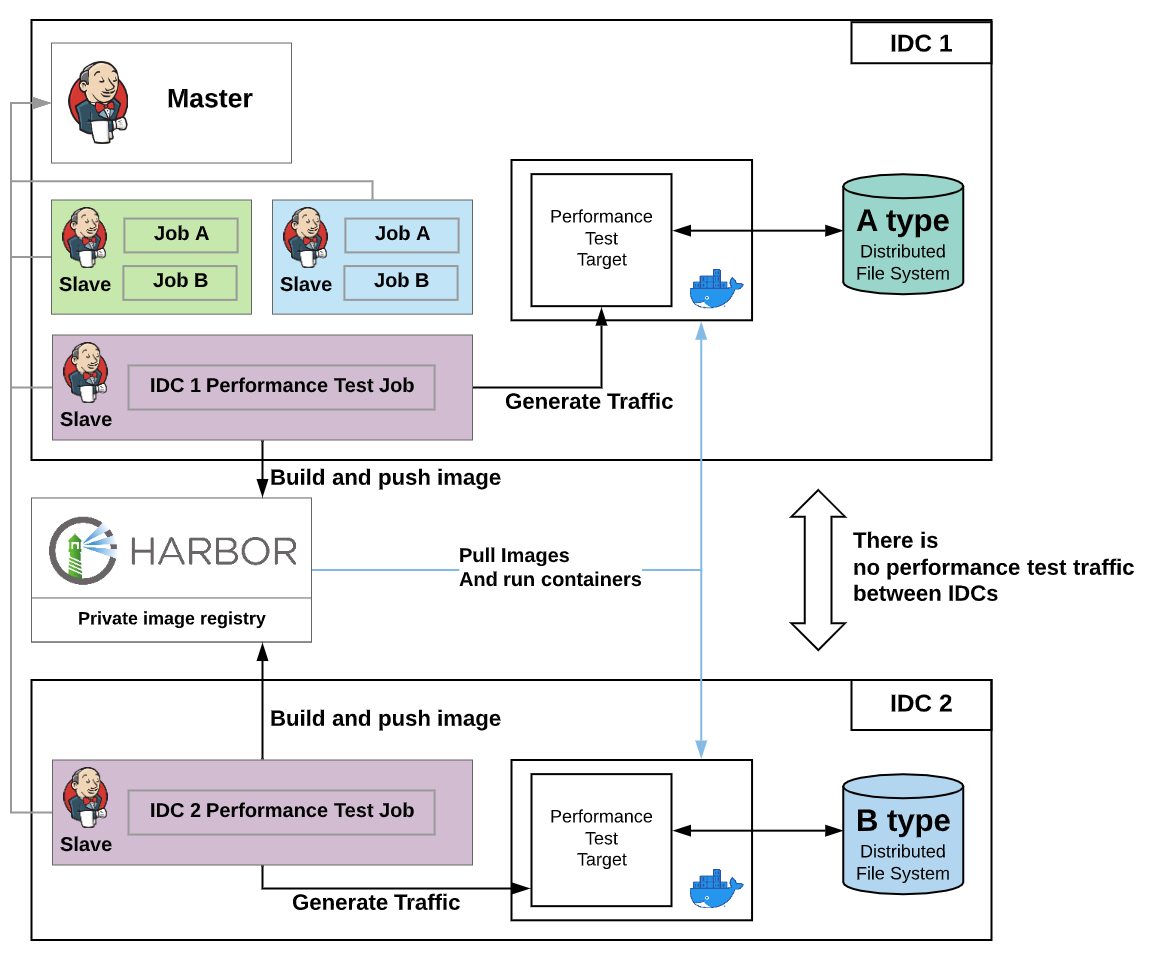
마치며
이번 글에서는 성능 테스트를 자동화한 이유와 어떻게 하면 좀 더 개발자에게 도움이 될 수 있을지 고민하며 세웠던 목표를 공유하고, 저희가 구성한 성능 테스트 자동화 환경에 대해 설명했습니다. 다음 글에서는 성능 테스트의 리포트를 어떻게 생성했는지와 자동화된 성능 테스트를 실제로 적용하면서 겪었던 문제와 해결한 방법에 대해 말씀드리겠습니다. 많은 기대 부탁드립니다.
LINE 메시징 서비스와 LINE 패밀리 서비스를 통해 전 세계의 사용자가 발생시키는 막대한 규모의 트래픽을 안정적으로 처리하는 경험을 함께 해보고 싶지 않으신가요? 대규모 트래픽을 안정적으로 처리하는 일에 관심이 있다면 적극 지원해 주세요! We are hiring!
- LINE 미디어 플랫폼 채용 공고
- LINE 미디어 플랫폼 관련 블로그
- LINE의 인프라 비용을 절감한 6가지 사례
- Antman 프로젝트 개발기
- 서버 사이드 테스트 자동화 여정
- LINE Transcoding Server 아키텍처