
LINE 개발자라면 한 번쯤은 꼭 사용하게 되는 LINE Verda 플랫폼을 아시나요? Verda는 LINE 내 다양한 개발 팀에서 인프라 리소스를 쉽고 빠르게 사용할 수 있도록 제공하고 있는 프라이빗 클라우드 서비스입니다. Verda를 사용하면 언제든 간편하고 빠르게 인프라를 준비할 수 있기 때문에 서비스 개발자는 인프라에 구애받지 않고 서비스 개발에만 집중할 수 있습니다. 한 마디로 개발자를 위한 플랫폼이라고 할 수 있겠죠?
안녕하세요. Redis와 MySQL, Elasticsearch와 같은 제품을 클라우드 서비스로 제공하는 Verda 클라우드 서비스 개발 팀의 강인배, 문현균, 유동균입니다. 2020년 하반기에 입사했으니 어느덧 2년이 다 됐는데요. 개발자를 돕는 소프트웨어를 만드는 게 참 보람찬 일이라서 적성에 잘 맞는다고 할까요? 🙂
이번 글에서는 지난 11월 1일에 열렸던 OpenInfra & Cloud Native Days Korea에 발표자로 참석한 후기를 전해 드리겠습니다.

OpenInfra & Cloud Native Days Korea 소개
OpenInfra & Cloud Native Days Korea는 Verda의 근간인 OpenStack과 쿠버네티스, Ceph 등의 오픈 소스 소프트웨어 커뮤니티가 한자리에 모여 스몰 토크를 나누고 기술과 노하우를 공유하는 자리입니다. 오픈 소스 기반 인프라 구성이나 개발에 관심 있는 분들이 모여 세션을 진행하고 기술을 공유하는 정말 뜻깊은 행사라고 할 수 있습니다. 코로나 이후 3년 만에 서울 코엑스 그랜드 볼룸에서 오프라인으로 진행된 이 행사에 발표자로 참여했는데요. 저희가 들려드리는 후기와 함께 OpenInfra & Cloud Native Days Korea로 떠나볼까요?

인상 깊었던 세션과 발표한 세션 소개
이번 행사에서 인상 깊게 들었던 세션과 발표한 세션을 소개하겠습니다.
'Let’s make Kubernetes Boring', SKT 안재석 님
먼저 오전에 들었던 키노트 세션 중 가장 인상 깊었던 SKT 안재석 님의 'Let’s make Kubernetes Boring' 세션 후기를 공유하겠습니다.
세션 주제는 '쿠버네티스는 더 이상 컨테이너 오케스트레이션 도구가 아니라 선언적 시스템을 관리하는 플랫폼이다'였습니다. 세션 제목과 연결해 보면, 쿠버네티스 그 자체는 'boring'하지 않지만 선언적 시스템으로 인프라와 클라우드 영역을 신경 쓰지 않아도 되도록 'boring'하게 만들자는 것이었습니다.
Cluster API를 관리하는 주체인 Cluster Lifecycle SIG(Special Interest Group)도 최종 사용자가 인프라 관련 지식이 없어도 리소스가 잘 유지 보수되도록, 즉 'make the cluster life cycle boring'이 목표라고 합니다. 많은 리소스를 컨트롤러로 관리하는 것으로 쿠버네티스를 선언적으로 운영할 수 있으며, 이를 통해 사용자가 실제로 그 리소스가 어떻게 구성되는지 알 필요가 없게 만들 수 있습니다. 참고로, LINE 클라우드 서비스 개발 팀에서도 Redis와 Elasticsearch 등의 서비스를 쿠버네티스 커스텀 리소스로 정의하고 컨트롤러로 관리하는 방안을 채택했습니다.
평소에 쿠버네티스에 대해 생각했던 내용을 쉽게 이해할 수 있도록 설명해 주셔서 인상 깊게 들었던 세션이었습니다.
LINE 클라우드 서비스 개발 팀 발표 세션
오후에는 LINE 클라우드 서비스 개발 팀에서 발표하는 세션이 두 개 있었습니다. 각 발표 내용을 소개하기에 앞서 어떻게 발표를 준비하게 됐는지 말씀드리고 싶습니다.
이번에 저희가 발표하게 된 배경에는 팀에 단단하게 자리 잡은 개발 문화가 있습니다. 클라우드 서비스 개발 팀의 가장 큰 장점으로 자유로운 분위기에서 진행하는 기술 토론을 꼽을 수 있는데요. 더 좋은 결론에 도달할 수 있도록 수평적인 분위기에서 누구나 의견을 제시하고 서로 비판적 사고를 견지하면서 많은 피드백을 주고받으며 활발하게 토론을 진행하고 있습니다. 이와 같은 토론 방식은 문제를 새로운 시각에서 바라보면서 생각을 논리적으로 전개하는 데 많은 도움을 줍니다. 또한 업무로 습득한 지식과 그 외 유용한 정보를 서로 공유하는 문화도 잘 자리 잡고 있는데요. 이런 개발 문화가 서로를 통해 함께 발전하는 선순환의 발판이 됐고, 그 덕분에 공유하는 게 매우 자연스러운 일이 되다 보니 회사 밖으로 나가 오픈 소스 생태계에도 조금이나마 기여하고 싶은 마음이 들어서 발표를 결심하게 됐습니다.
저희는 다음 두 가지 주제로 지식과 경험을 공유했습니다.
- LINE에서 선언형 DB as a Service를 개발하며 얻은 쿠버네티스 네이티브 프로그래밍 기법 공유
- Elasticsearch as a Service on Private Cloud
LINE에서 선언형 DB as a Service를 개발하며 얻은 쿠버네티스 네이티브 프로그래밍 기법 공유
쿠버네티스 기반으로 컨트롤러를 개발하다 보면 컨트롤러 특성 때문에 문제가 발생하는 경우가 종종 있습니다. 이번 세션에서는 이런 문제들이 왜 발생하고 어떻게 해결할 수 있는지 발표했습니다. 세션에 참석하신 분들이 발표를 들으며 쿠버네티스를 더 깊이 이해하고 저희의 경험과 노하우를 쿠버네티스 네이티브 프로그래밍에 적용할 수 있는 기회가 될 수 있다면 좋겠다고 생각했습니다.
먼저 쿠버네티스 리소스를 변경하는 올바른 방법을 공유했습니다.

클라우드 서비스 개발 팀에서 만드는 제품에서는 컨트롤러가 쿠버네티스의 리소스를 변경합니다. 이때 다른 REST API 서버가 그렇듯 쿠버네티스 API 서버에서도 리소스를 변경하는 방법으로 PUT과 PATCH, 두 종류가 있습니다. 각각을 짧게 설명하자면 PUT은 바꾸고 싶은 모든 표현을 페이로드에 담아서 보내는 방식이고, PATCH는 수정하고 싶은 부분만 페이로드에 담아서 보내는 방식입니다.
쿠버네티스에서는 수정할 때마다 'resourceVersion'이라는 것을 하나씩 증가시키고, 이것이 일치하지 않으면 충돌(conflict)이 발생하는 낙관적 잠금 방식으로 버전을 관리합니다. 그래서 아래와 같이 리소스 버전을 포함한 모든 표현을 페이로드에 담아서 PUT으로 보내면 충돌이 발생합니다.
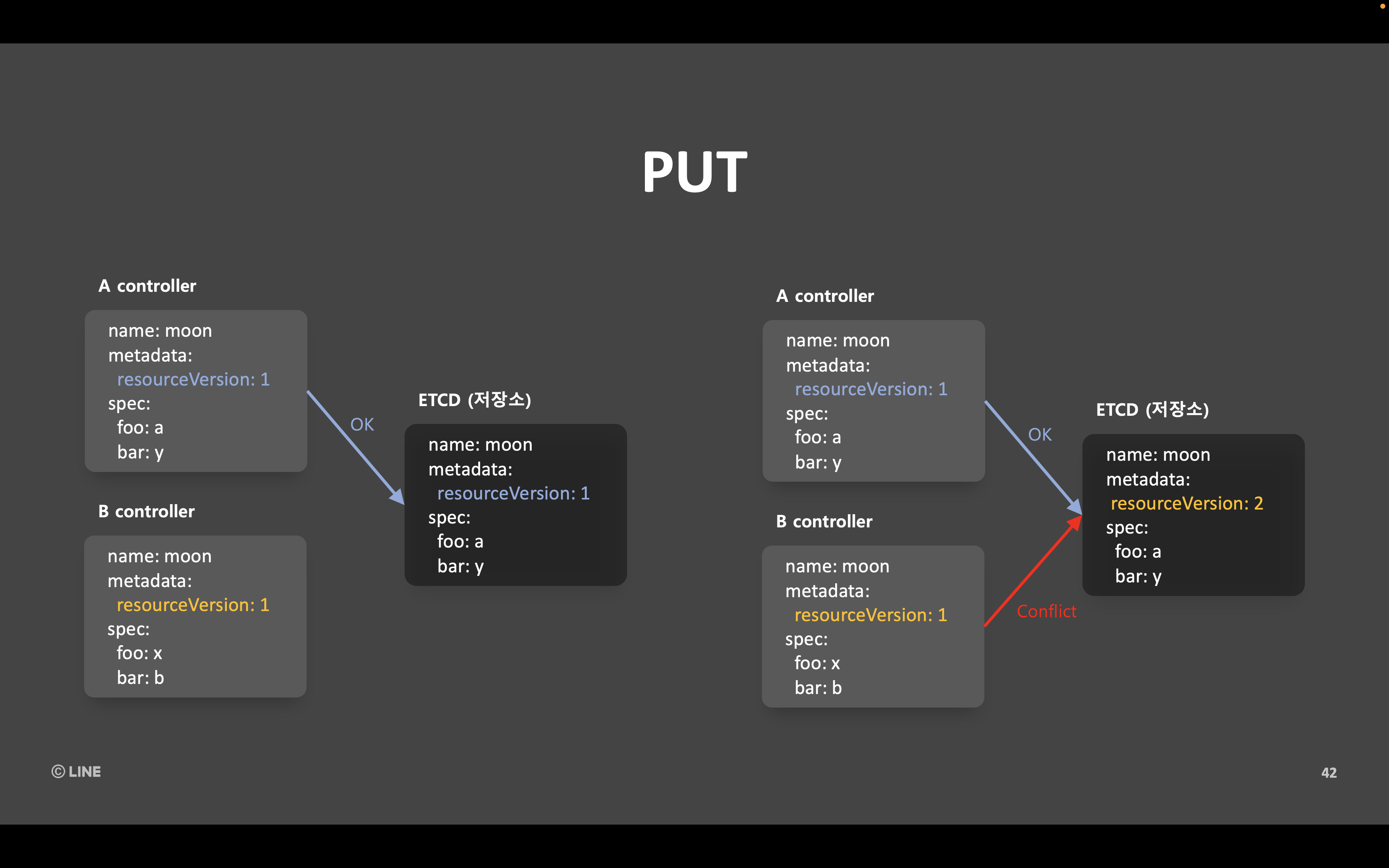
이때 아래와 같이 변경하고자 하는 부분만 PATCH로 보내면 충돌이 발생하지 않습니다.
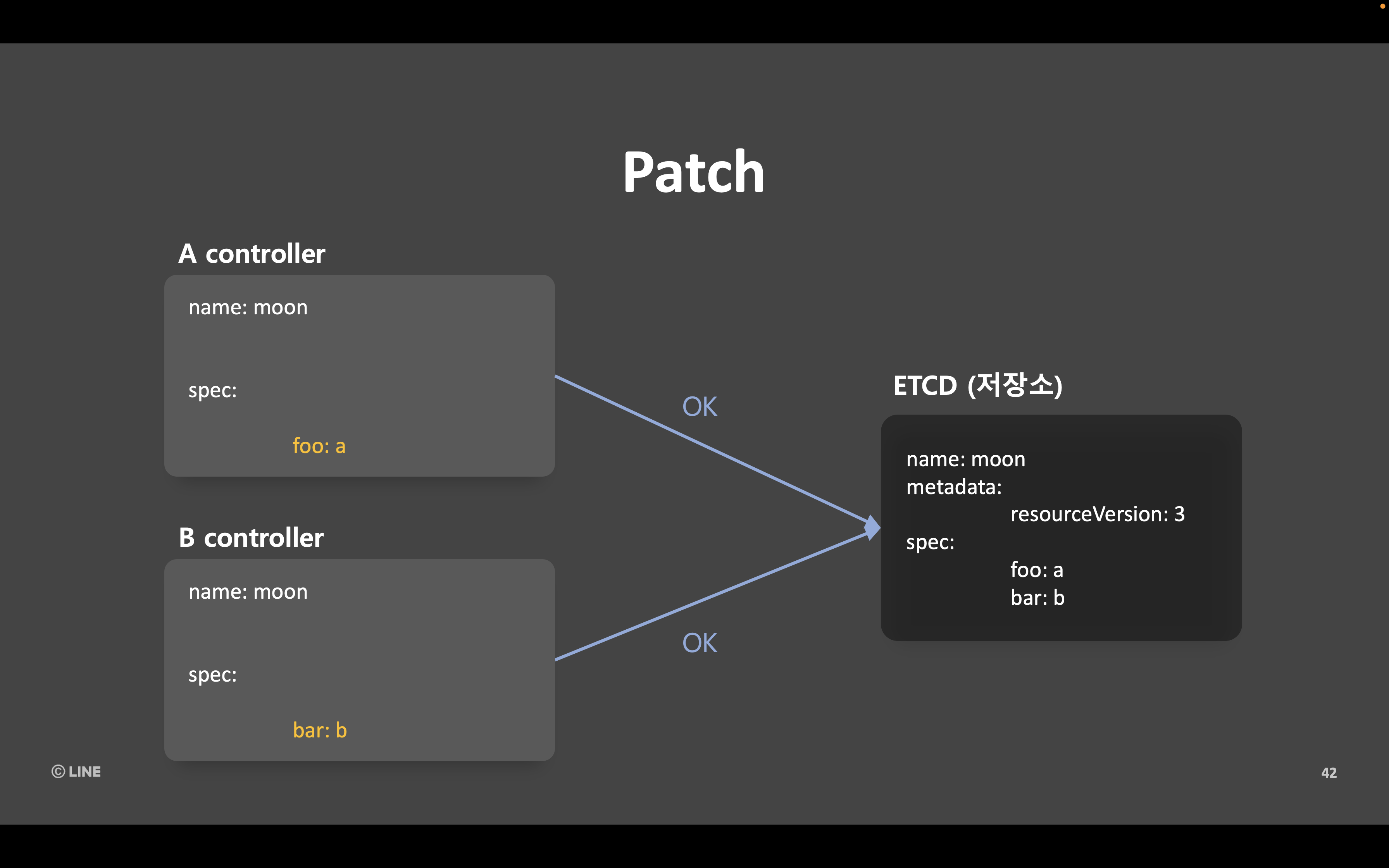
두 컨트롤러 각각에서 수정하고자 하는 항목이 같다면 정말 수정할 수 있는지 확인하기 위해 충돌 발생이 가능한 PUT을 사용해야 합니다. 하지만 두 컨트롤러가 각각 수정하고자 하는 항목이 다르다면 충돌이 발생하지 않는 PATCH를 사용해도 되는데요. 충돌 에러가 발생하면 로그양이 많아지고 동기화 루프가 한 번 더 실행되는 등의 문제가 발생하기 때문에 충돌이 필요하지 않다면 PATCH를 적용해 에러를 최소화할 수 있다는 점을 공유했습니다.
두 번째로 캐시 동기화와 관련된 문제를 발표했습니다.

쿠버네티스에서는 리소스를 조회할 때 직접 API 서버에서 GET하지 않고 WATCH를 통해 동기화된 캐시를 이용합니다. 캐시를 이용하기 때문에 리소스 상태를 관찰해서 이에 기반해 작동하는 컨트롤러를 작성할 때는 조회한 정보가 최신 정보가 아니라는 것을 염두에 둬야 하는데요. 쿠버네티스에서는 궁극적 일관성이라는 일관성 모델을 사용하기 때문에 보통 캐시 정보 업데이트가 조금 느려도 문제가 되지 않지만, 멱등성이 없는 작업을 컨트롤러에서 수행할 때는 작업이 여러 번 수행될 수 있기 때문에 문제가 될 수 있습니다. 예를 들어 필요한 개수만큼 파드(pod)를 생성해야 하는데 의도한 것보다 더 많이 실행돼 필요 이상으로 많이 생성되면 안 되겠죠?
이 문제를 해결하기 위해서는 캐시 동기화를 기다려 주는 로직이 필요하며, 쿠버네티스에서는 'Expectation'이라는 것을 사용해서 이를 해결합니다. Expectation은 간단히 말해서 예측값에 해당하는 정수 변수를 설정해 두고, 예측값만큼 행동이 관찰될 때까지 기다리는 컴포넌트입니다.
if 예측값 != 관찰값 {
나중에_하기_위해_종료
}
작업()
예측값_설정()이 Expectation 아이디어를 확장해서 '아비터'라는 새로운 컴포넌트를 만들었습니다. 아비터에서는 단순히 정수 변수를 이용하는 것이 아니라 예상되는 상황을 검사할 수 있는 함수를 직접 등록하도록 만들어 더욱 유연하게 사용할 수 있도록 구성했습니다.
if 등록한_검사_함수() == true {
나중에_하기_위해_종료
}
작업()
검사_함수_등록()그렇기 때문에 쿠버네티스에서 사용한 Expectation은 생성이나 삭제 같은 부분에서만 사용할 수 있었던 반면에 아비터는 더욱 다양한 상황에서 상태를 검사할 수 있습니다.
Elasticsearch as a Service on Private Cloud

초창기 Elasticsearch Service는 Elasticsearch 클러스터를 제어하는 컨트롤 플레인과 실제 데이터를 가지고 있는 데이터 플레인이 한 쿠버네티스 클러스터에 존재했습니다. 이와 같이 컨트롤 플레인과 데이터 플레인이 한 쿠버네티스 클러스터에 존재할 경우 쿠버네티스 클러스터에 장애가 발생하면 Elasticsearch 클러스터를 사용할 수 없는 상태가 되는 문제가 있습니다. 이 문제를 해결하면서 동시에 리소스 일관성을 확보하는 쿠버네티스의 선언형 프레임워크를 유지하고 싶었습니다. 이에 아래와 같이 컨트롤 플레인은 쿠버네티스로 유지하면서 데이터 플레인을 VM으로 변경해 안정성을 확보할 수 있는 아키텍처를 설계했습니다.
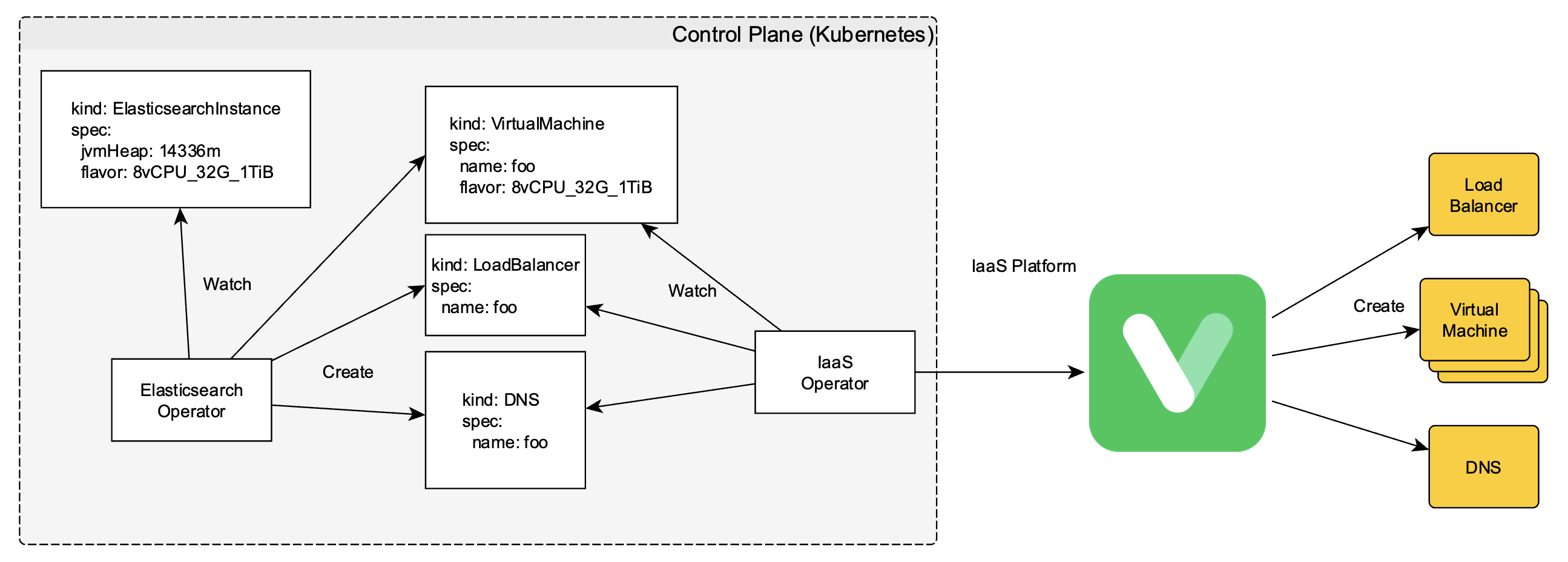
하지만 위 아키텍처에서는 데이터 플레인이 VM으로 변경되면서 Elasticsearch 클러스터의 저장과 검색 성능이 크게 저하되는 문제가 발생했습니다. 성능을 개선하기 위해 하이퍼바이저와 리버스 프록시 튜닝을 진행했고, 그 결과 아래와 같이 대부분의 Elasticsearch 클러스터를 감당할 수 있을 정도로 상당히 성능이 개선됐습니다.
| 일반 VM | 튜닝된 VM | 개선율 | |
| 저장에 걸린 시간 | 5h 32m | 2h 41m | 51% 감소 |
| 검색에 걸린 시간 | 45.6ms | 19.1ms | 58% 감소 |
LINE의 가장 큰 레거시인 Elasticsearch 클러스터 또한 Elasticsearch Service에서 수용하기 위해 지속적으로 성능을 개선해 나가고 있습니다. 성능을 높이면서 안정성도 확보하기 위해 '사람이 해야 하는 일'을 믿고 맡길 수 있는 신뢰할 수 있는 컨트롤 플레인(오퍼레이터)을 만드는 것을 주 목표로 삼았습니다. 이를 위해 데이터 플레인을 안정적으로 유지해 나갈 수 있는 자동 힐링 프로세스를 비롯한 여러 기능을 갖춘 단단한 Elasticsearch as a Service를 만들어 나가고 있습니다.

두 세션에서 발표한 내용을 간단히 정리해서 소개했습니다. 자세한 발표 내용은 아래 사이트에 업로드된 발표 슬라이드 및 추후 업로드될 영상을 참고해 주세요. 🙂
- LINE에서 선언형 DB as a Service를 개발하며 얻은 쿠버네티스 네이티브 프로그래밍 기법 공유
- Elasticsearch as a Service on Private Cloud
행사 참석 소감
이번 행사에 참석한 소감을 말씀드리겠습니다.
강인배 님
저에게는 이번 경험이 매우 특별하게 다가왔습니다. 학부 시절 클라우드에 관심을 두고 공부하면서 많이 참고하고 도움을 받았던 커뮤니티가 바로 이 행사를 주최한 커뮤니티였기 때문입니다. 커뮤니티에서 받았던 많은 도움을 바탕으로 커리어를 시작해서 발전해 다시 그 생태계에 공헌한다는 것은 너무나도 뜻깊은 경험이었습니다. 또한 발표를 준비하면서 발표 주제에 대해 보다 깊이 생각하고 배우게 돼 스스로 성장할 수 있는 좋은 기회가 됐습니다.
문현균 님
그동안 밋업부터 콘퍼런스까지 다양한 외부 활동에 참여하면서 '나도 언젠가 발표자가 되어 기술을 공유하며 다른 개발자에게 도움이 될 수 있는 사람이 되고 싶다'라는 꿈이 있었습니다. 오랜 꿈이었던 만큼 더욱 완벽하게 준비하고 싶은 마음에 밤낮없이 발표 자료를 수정하며 조금 힘들기도 했지만, 그때마다 리허설을 도와주고 피드백해 주는 팀원들이 있었기 때문에 감사하게도 무사히 발표를 마칠 수 있었습니다. 또한 준비 과정에서 발표 주제에 대해 공부하며 다소 모호하게 알고 있었던 부분을 정확하게 알게 돼 저 자신도 한층 더 성장할 수 있었습니다. 클라우드 서비스 개발 팀이 저를 성장할 수 있게 도와준 만큼 앞으로도 더욱 발전해서 많은 기술을 공유하며 팀과 업계에 기여하고 싶습니다.
유동균 님
Verda의 Elasticsearch Service는 단순히 Elasticsearch을 제공하는 것을 넘어서 Elasticsearch 클러스터를 운영할 때 발생할 수 있는 위협 요소나 방해 요소로부터 사용자 서비스를 보호하고 인프라 리소스를 더욱 효율적으로 사용할 수 있도록 구조를 점차 발전시켜 나가고 있습니다. 단순한 프로비저닝이 아니라 위험 요소를 감지하고 회피할 수 있는 현재의 똑똑한 Elasticsearch Service를 만들어 내기까지 많은 시행착오를 겪었고 경험을 쌓았습니다. 이 값진 경험을 세션에 참석하신 분들께 공유하면서 저 자신도 보람을 느꼈고 즐거웠습니다. 다음에 또 기회가 된다면 관심 있는 분들과 깊이 있는 대화를 더 많이 나눠 보고 싶습니다.
마치며
여담으로, 발표 주제가 평소에 이 분야를 많이 접해본 분이 아니라면 다소 생소할 수 있는 주제였기 때문에 최대한 많은 분이 쉽게 이해할 수 있도록 준비하려고 노력했습니다. 그 과정에서 수많은 토론을 거치며 팀원분들의 열정적인 피드백을 받아 천신만고 끝에 '최종_오브_최종의_진짜_최종 발표 자료'가 탄생했는데요. 다행히도 이렇게 열심히 준비한 발표에 많은 분이 참석하셔서 큰 관심을 보이며 질문도 많이 해주셔서 뿌듯했습니다.
이번 발표는 앞으로 더욱 많은 분들이 저희와 같은 경험을 할 수 있도록 클라우드 서비스 개발 팀의 훌륭한 개발 문화를 지속해서 발전시키며 대외로도 적극적으로 기여해야겠다고 다짐하는 계기가 됐습니다. 모두 함께 성장하는 내일을 그리며 이만 마치겠습니다.