
들어가며
안녕하세요. LINE에서 Financial Data Platform을 개발하는 이웅규입니다. 이번 글은 'MLOps를 위한 BentoML 기능 및 성능 테스트 결과 공유' 2편입니다. 1편에서는 BentoML을 선택한 이유와 서비스에 적용하기 위해 필요한 기능을 설명하고 예시를 보여드렸는데요. 이어서 이번 글에서는 BentoML을 서비스에 적용하기 위한 아키텍처와 Kubernetes 기반으로 서빙 API를 서비스에 적용하려면 꼭 필요한 기능인 무중단 배포 방법 네 가지를 말씀드리겠습니다. 또한 BentoML의 성능을 개선하기 위해 실시한 여러 실험과 개선 결과를 공유드리고 최종적으로 어떤 결론을 내렸는지 말씀드리겠습니다. 글은 두 편에 걸쳐서 아래와 같은 순서로 진행합니다.
BentoML 서비스 적용(BentoML in Native Kubernetes)
먼저 Kubernetes를 이용해 BentoML을 서비스하기 위한 아키텍처를 설명하고, 이어서 무중단 배포 방법 네 가지를 설명하겠습니다.
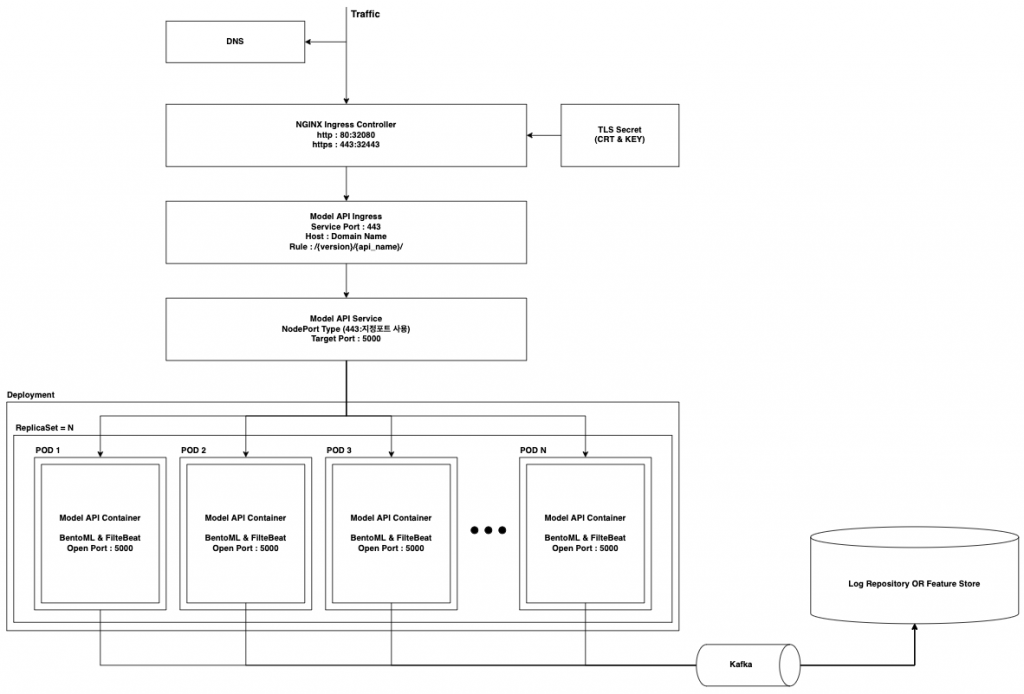
아키텍처
아래 아키텍처는 Kubernetes에서는 일반적으로 사용하는 구조입니다. 서비스의 확장성과 안정성을 확보하기 위해 아래와 같은 구조로 서빙 API를 구성했습니다. 저희 팀은 자체 구축한 Native Kubernetes를 사용하고 있기 때문에 NGINX-Ingress Controller를 사용하고 있습니다.
무중단 배포 방법
무중단 배포 방법은 BentoML과 직접적으로 관련된 내용은 아니지만, Kubernetes 기반으로 서빙 API를 서비스에 적용하려면 꼭 필요한 기능이라고 생각합니다. 잦은 배포를 통한 모델 갱신 및 개선이 BentoML 적용의 큰 목적 중 하나이자 서비스를 발전시킬 수 있는 수단이기 때문입니다. 배포를 자주 하기 위해서는 무중단 배포가 필수라고 할 수 있습니다. Kubernetes에서 무중단 배포를 하는 방법에는 여러 가지가 있습니다. 이번 글에서 여러 배포 방법의 과정을 자세하게 설명하지는 않겠습니다. 관련 내용은 Kubernetes의 배포 관련 자료에서 확인하시는 게 더 좋습니다. 대신 서빙 API 관점에서 롤링 업데이트, 블루/그린, 카나리(canary), 인그레스 라우팅(ingress routing) 배포 방법에 대해 간략하게 설명하고 무중단 배포 시의 제약 사항 및 장단점에 관해 설명하겠습니다.
배포 방법을 설명하기에 앞서 두 가지를 말씀드리겠습니다. 먼저 저희는 내부적으로 서빙 API 업데이트의 종류를 다음과 같이 두 가지로 나누고 있습니다.
- 마이너 업데이트 - 인풋 피처는 변경되지 않고 모델 혹은 API 내부 로직만 변경되어 서빙 API만 배포하는 경우
- 메이저 업데이트 - 인풋 피처부터 모델까지 모두 변경되면서 서빙 API를 호출하는 클라이언트까지 배포하는 경우
다음으로 아래 YAML 파일들은 앞서 말씀드린 아키텍처의 기본 구조를 형성하는 파일입니다. 이후 아래 YAML 파일을 기반으로 설명하겠습니다.
| deployment.yaml | service.yaml | ingress.yaml | secret.yaml |
|---|---|---|---|
|
|
|
|
롤링 업데이트
롤링 업데이트를 쉽게 설명하면, API 파드(pod)가 여러 개일 때 특정 파드 개수 혹은 비율만큼 순차적으로 신규 API 파드로 전환한다는 의미입니다. 위 deployment.yaml 파일의 .spec.strategy.type : RollingUpdate 구문으로 적용 가능하며, maxSurge, maxUnavailable 값을 이용해 제어할 수 있습니다.
위 deployment.yaml 파일 예시는 하나의 파드씩 신규 버전의 API로 전환하면서, 동시에 사용 불가능한 상태의 파드는 허용하지 않겠다는 의미를 담고 있습니다. 예를 들어 기존에 API 파드가 세 개 배포된 경우, 하나의 신규 API가 먼저 배포되어 총 네 개의 파드가 기동되다가, 신규 API가 정상적으로 기동 완료되면 기존 API 파드를 하나씩 종료하는 구조입니다.
이 구조의 단점은 신규 서빙 API와 기존 서빙 API가 서비스에 공존한다는 것입니다. 메이저 업데이트의 경우 파라미터가 바뀔 수 있기 때문에 무중단 배포가 어려울 수 있지만, 마이너 업데이트의 경우에는 클라이언트 별도 배포 없이 무중단 배포가 가능합니다. 만약 API 버저닝이 되어 있는 구조라면 메이저 업데이트도 가능할 수 있습니다. 이때 엔드포인트 URL 변경 및 인풋 피처 변경에 따른 클라이언트 배포가 불가피합니다.
추가로 API를 버저닝한 구조는 배포 방법과 관계 없이 공통적으로 코드를 관리하지 않는다면 레거시 API와 신규 API가 공존하며 가독성을 떨어트리는 단점이 발생합니다.
# 신규 버전 Serving API 배포 방법(Docker Image 교체)
kubectl set image deployment {deployment name} {container name}={model_api_docker_image}:{new_model_api_docker_image_tag}
# deployment rollout 상태
kubectl rollout status deployment {deployment name}
# deployment rollout 히스토리
kubectl rollout history deployment {deployment name}
# 특정 과거 버전 deployment 롤백
$ kubectl rollout undo deployment {deployment name} --to-revision={target revision}블루/그린
블루/그린은 신규 서빙 API 디플로이먼트(deployment)를 추가로 배포한 상태에서 기존 서빙 API 디플로이먼트를 바라보고 있던 서비스를 신규 버전으로 전환하는 방법입니다. 즉 앞서 말씀드린 아키텍처에서 NodePort Type의 서비스를 신규 서빙 API 디플로이먼트로 전환한다고 이해하시면 됩니다. 해당 방법은 디플로이먼트가 두 벌 배포돼야 하기 때문에 자원 관리에서 문제가 될 수 있지만, 배포 시 서비스만 교체하면 된다는 점에서는 매우 효율적인 배포 방법입니다. 또한 이슈 발생 시 서비스만 변경하면 되는 구조라 롤백도 편리합니다. 블루/그린 배포 방법은 마이너 업데이트 시에는 클라이언트 배포 없이 무중단 배포가 가능합니다만, 메이저 업데이트 시에는 클라이언트 배포가 필수이며 클라이언트와 서빙 API 배포 시점을 조율해야 합니다. API 버저닝을 진행할 경우 신규 서빙 API가 배포된 이후 클라이언트 배포를 진행합니다.
# 기존 버전 Serving API (color - blue)
# 신규 버전 Serving API Deployment 배포 (color - green)
kubectl apply -f patch-deployment.yaml
# 신슈 버전 Serving API 상태 확인
kubectl get deployment
kubectl get pod
# service 전환 방법
patch-service.yaml
spec:
selector:
color: green
# 신규 Deployment(color - green)로 서비스 전환
kubectl patch service {service name} -p "$(cat patch-service.yaml)"카나리
카나리 배포 방법은 신규 서빙 API를 특정 비율만큼만 배포해 테스트를 진행하다가 문제가 없으면 점진적으로 전체 서빙 API를 신규 버전으로 전환하는 방법입니다. 이 방법은 마이너 업데이트 시 적용 가능하며 기존 서빙 API와 A/B 테스트까지 가능하다는 장점이 있습니다. 하지만 메이저 업데이트 시에는 적절하지 않은 방법이라고 생각합니다. 동일한 엔드포인트지만 신규와 기존 API의 인풋 피처가 다를 수 있기 때문입니다.
카나리 배포를 구현하는 방법은 다양합니다. 배포되는 파드의 비율을 조정하는 방법도 존재하고, 단순하게 신규 디플로이먼트에 레플리카셋(replica set) 값을 적게 설정해 같은 서비스에 연동하고, 문제가 없다면 기존 디플로이먼트의 레플리카셋의 수는 줄이면서 신규 디플로이먼트 레플리카셋은 늘리는 구조로 구현할 수 있습니다. 또한 문제가 있다면 롤백을 위해 신규 버전의 디플로이먼트를 제거해 서비스에서 제외하는 구조로 만들 수 있습니다.
# 신규 버전 Deployment 배포 및 scale 조정
kubectl apply -f new-deployment.yaml
kubectl scale deployment {new deployment} --replicas={increasse replica set number}
# 기존 버전 Deployment 배포 및 scale 조정
kubectl scale deployment {old deployment} --replicas={decrease replica set number}인그레스 라우팅
이 방법은 어떻게 보면 전통적인 배포 방법이라고 할 수 있으며 블루/그린이나 카나리와 크게 다르지 않습니다. 차이가 있다면 신규와 기존 서빙 API의 디플로이먼트와 서비스가 모두 배포된 상태에서 인그레스의 라우팅 정보만 수정하여 각 서비스로 라우트하는 구조라는 것입니다. 인그레스 라우팅 방법을 사용하면 마이너와 메이저 업데이트 모두 효율적으로 배포할 수 있습니다. 신규와 기존 서빙 API에 동시에 접근이 가능한 구조라서 문제가 있다면 클라이언트에서 엔드포인트 URL만 변경하면 되기 때문입니다. 다만 디플로이먼트와 서비스 모두 두 벌씩 배포하는 구조라서 자원 관리에 문제가 발생할 수 있습니다.
# 신규 버전 Deployment 배포
kubectl apply -f new_version_deployment.yaml
# 신규 버전 Service 배포
kubectl apply -f new_version_service.yml
# 수정된 Ingress 파일
patch-ingress.yaml
spec:
rules:
- host: {{ include "ingress.host" . }}
http:
paths:
- path: /v1 # API Version에 따라 Routing
pathType: Prefix
backend:
serviceName: {{ include "service.name" . }}
servicePort: 443
- path: /v2 # API Version에 따라 Routing
pathType: Prefix
backend:
serviceName: {{ include "service.name.new_version" . }}
servicePort: 443
# 신규 버전 Ingress
kubectl patch ingress {service_name} -p "$(cat patch-ingress.yaml)"지금까지 다양한 배포 방법을 설명드렸는데요. 말씀드린 것처럼 각각의 배포 방법마다 장/단점이 존재해서 서비스에 적용할 때는 각각의 비즈니스에 맞게 배포 방법을 선택하면 될 것 같습니다. 구조를 변경하면 카나리 배포 방법도 서빙 API 메이저 업데이트에 대응할 수 있는 구조가 될 수 있습니다. 저희는 여러 상황을 고려해 롤링 업데이트와 인그레스 라우팅 방법을 조합해서 사용하는 것이 좋다고 판단했습니다(참고로 Argo 같은 배포 도구를 활용하면 보다 효율적인 CD(continuous deployment)를 구성할 수 있습니다).
BentoML 성능 테스트
처음에 무작정 BentoML 성능을 측정했는데요. 매우 낮은 성능 결과(TPS 50)를 얻었습니다. 이를 개선하기 위해 어느 구간이 병목이고 어느 부분을 개선할 수 있을지, 최적의 리소스 분배는 어떤 것일지 하나씩 확인하는 작업을 수행했습니다. 아래는 각 실험에 대한 결과입니다.
실험 환경
- Native Kubernetes Worker VM 15EA (8core, 16GB)
- 테스트 대상 서빙 API
- HTTPS 통신
- Deep Neural Network Model, XGBoost Model
- 전처리, 후처리 존재
- 인풋 피처 개수 - 431개
- base-docker 이미지 - model-server:0.12.0-py36
- 테스트 환경
- 사내 nGrinder
성능 저하 원인 파악 및 성능 테스트
실험 1. 비즈니스 로직에 따른 성능 저하 여부
- 가설: 서빙 API의 성능이 BentoML 서비스 클래스 내의 예측 및 비즈니스 로직에 따라 결정되는 것인가? Python 기반 BentoML 서버 자체의 한계가 존재하는 것은 아닌가?
- 검증 방법
- 비교 대상 - 요청 즉시 응답을 반환하는 비즈니스 로직과 예측 부분이 제거된 BentoML 애플리케이션
- 기준이 되는 서빙 API와 비교 대상의 성능을 동일 환경에서 비교
- 절대적인 비교를 위해 최대 부하는 넣지 않음
- 결과
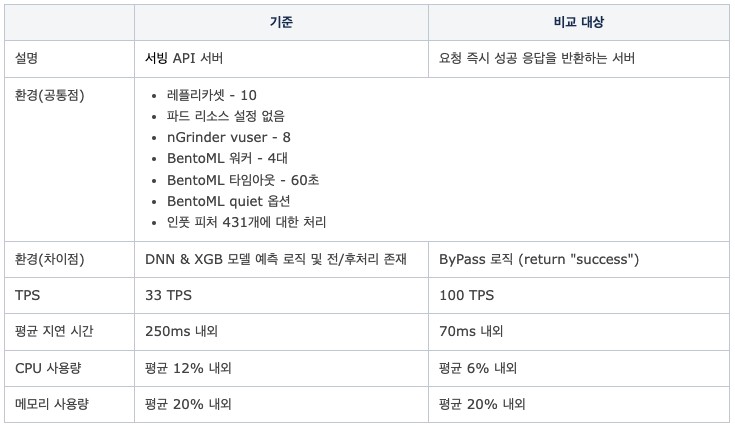
- 결론
- Python 기반 BentoML 서버 성능에는 크게 문제가 없다고 판단
- 비즈니스 로직과 예측 부분에서 병목 현상이 발생하는 것으로 추정
- 다음 단계: BentoML 자체의 성능을 개선할 방안 모색 필요
실험 2. 모델의 복잡도에 따른 성능 저하 여부
- 가설: 서빙 API의 성능이 모델의 복잡도에 따라 결정되는 것인가?
- 검증 방법
- 비교 대상 - BentoML의 공식 예제 모델인 Iris Classifier 모델 사용(인풋 피처 4개)
- 기준이 되는 서빙 API와 비교 대상의 성능을 동일 환경에서 비교
- 별도의 전/후처리 로직 없이 모델 예측 결괏값을 바로 반환하도록 수정 후 비교
- 결과
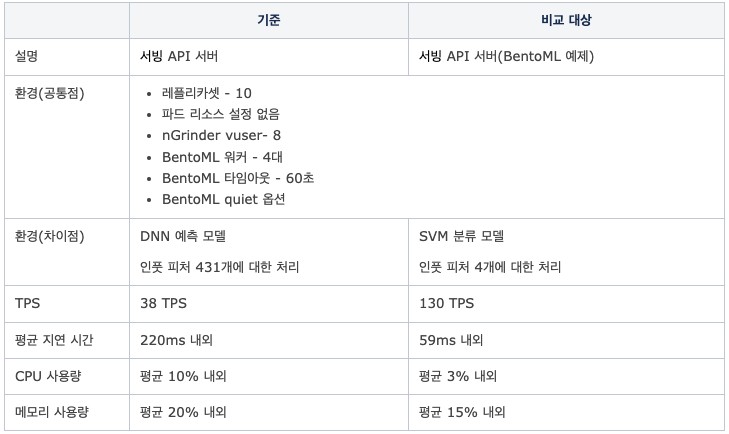
- 결론
- 모델의 프레임워크 및 모델 자체의 복잡도에 따라 성능이 결정되는 것으로 확인
- DNN 모델의 경우 히든 레이어가 깊이 쌓여 있어 상대적으로 복잡도가 더 높음
- 인풋 피처의 수도 성능에 영향을 줄 수 있다고 판단(네트워크, CPU 사용량의 차이를 보임)
- 다음 단계: BentoML 자체의 성능을 개선할 방안 모색 필요
실험 3. 마이크로 배치 설정값에 따른 성능 저하 여부
- 가설: 서빙 API의 성능이 마이크로 배치 설정값에 따라 결정되는 것인가?
- 검증 방법
- BentoML은 성능 향상 목적으로 마이크로 배치 기능을 기본적으로 제공
- 마이크로 배치의 성능을 조절하는 설정
- mb_max_batch_size - 마이크로 배치의 최대 사이즈
- mb_max_latency - 마이크로 배치의 최대 지연 시간
- 두 설정은 처리량(throughput)과 지연 시간(latency)를 조절할 수 있는 설정이며 트레이드오프 관계
- 기본 설정 - mb_max_batch_size : 1000, mb_max_latency : 10,000ms
- 두 설정의 변화에 따른 성능을 측정
- 결과
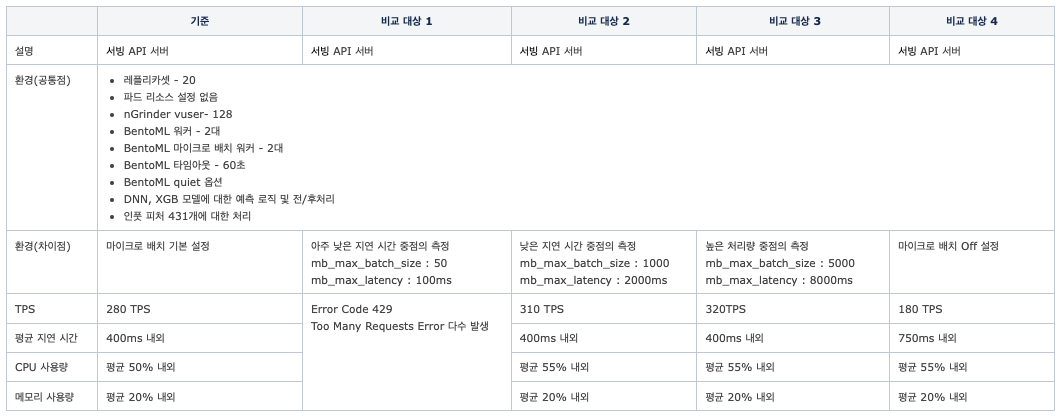
- 결론
- 마이크로 배치의 유무에 따라 성능 차이가 크게 발생
- 지연 시간을 너무 낮게 설정하면 클라이언트에서 429 에러가 많이 발생
- 모델과 비즈니스 로직에 따라 적절하게 튜닝하면 되는 값이라 판단
- 드라마틱한 개선 효과는 아니라고 판단
- 다음 단계: BentoML 워커 및 마이크로 배치 워커 수에 따른 성능 측정
실험 4. 워커 수에 따른 성능 여부
- 가설: 서빙 API의 성능이 BentoML 워커와 마이크로 배치 워커 수에 의해 결정되는가?
- 검증 방법
- 마이크로 배치 크기와 지연 시간은 실험 3의 결과 중 가장 성능이 좋았던 설정으로 고정(mb_max_batch_size-5000, mb_max_latency-8,000ms)
- BentoML 워커와 마이크로 배치 워커 수의 변경에 따른 성능 측정
- 결과
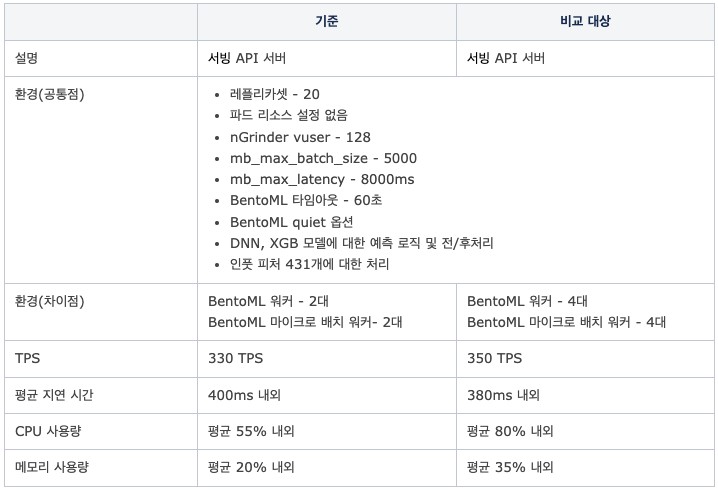
- 결론
- BentoML 워커와 배치 워커 수가 많을수록 개선된 성능을 얻을 수 있음
- 워커 수가 많을 수록 CPU 사용량 증가
- 드라마틱한 개선 효과는 아니라고 판단
- 다음 단계: 스케일 아웃에 따른 성능 테스트
실험 5. 스케일 아웃에 따른 성능 테스트
- 가설: 절대적인 서빙 API 서버의 수에 의해 성능이 결정되는가?
- 검증 방법
- 동일 환경 서빙 API 설정에 nGrinder vuser와 Kubernetes 레플리카셋의 변화에 따라 테스트
- 결과
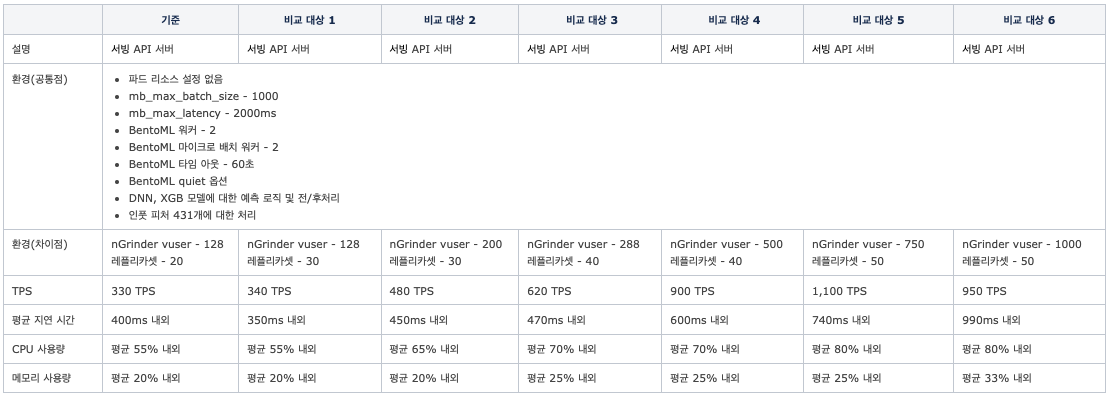
- 결론
- 물리적인 서빙 서버가 늘어날수록 선형적으로 개선된 성능을 얻을 수 있음
- Kubernetes 워커 수와 장비 스펙에 따라 개선된 성능을 얻을 수 있을 것이라 판단
최종 결론
기대했던 것만큼 성능 결과가 좋지는 못했지만, Python이라는 것을 고려했을 때는 준수한 성능이라는 생각도 들었습니다. 또한 패키징한 모델의 복잡도와 내부 로직에 따라 성능이 결정되는 것이기 때문에 각 서비스에 맞게 충분히 개선할 수 있는 영역이라고 판단했습니다. 성능보다는 모델의 빠른 CI/CD와 모델 서빙을 위한 커뮤니케이션이 감소한다는 관점에서 실보다는 득이 더 많을 것 같다고 판단했습니다. 각자의 서비스 스펙에 맞춰 결정하면 될 것 같습니다.
추가로 BentoML 서빙 API는 메모리보다는 CPU가 머신 선택의 기준이 될 것 같습니다. 또한 마이크로 배치 튜닝을 통해 드라마틱한 성능 개선은 불가능하지만, 온라인 서빙에서는 필수 기능이라고 생각합니다. 제 생각에 배치 기능은 BentoML보다는 각 회사에서 사용하고 있는 스케줄러를 통해 별도 Job 형태로 제공하는 게 효율적일 것 같습니다. 이런 부분이 관리 포인트가 추가되는 이슈라고 생각한다면 추론(inference)을 수행하는 클라이언트 측에서 요청 양을 스로틀링(throttling) 한다면 보다 효율적일 것이라고 생각합니다. BentoService 클래스의 템플릿을 잘 만들어두고 재사용한다면 모델러가 손쉽게 API 개발 및 테스트까지도 가능할 것이라고 생각합니다만, 전문 엔지니어의 코드 리뷰 및 피드백은 필수라고 생각합니다.
마치며
현재 저희는 서비스와 환경에 맞춰 MLOps 환경을 한 단계씩 개선해 나가고 있습니다. 이번 글에서 설명한 BentoML 또한 개선 포인트 중 하나입니다. 이번 글이 같은 업무를 진행하시는 분들에게 참고할 만한 기준이 되어 조금이나마 도움이 되었으면 좋겠습니다. 기회가 된다면 GPU 환경에서의 BentoML에 대한 글을 작성해 보겠습니다. 긴 글 읽어주셔서 감사합니다.