
들어가며
안녕하세요. LINE에서 Financial Data Platform을 개발하는 이웅규입니다. 2021년 초에 작성한 글(Airflow on Kubernetes VS Airflow Kubernetes Executor - 2) 마지막에 Kubernetes를 데이터 엔지니어링뿐 아니라 ML 기반 서비스에도 확장하고 있다고 말씀드렸는데요. 이번 글은 이전 글의 후속편으로써 ML 기반 서비스에 적용하고 있는 MLOps의 한 부분인 모델 서빙과 관련된 이야기를 하고자 합니다.
저는 MLOps가 어떤 솔루션이나 툴이 아니라 방법론이라고 생각합니다. 따라서 이를 구현하는 방법 또한 비즈니스의 성격이나 환경에 따라 다양할 수 있다고 생각합니다. MLOps는 여러 구성 요소를 포함하는데요. 사람마다 견해가 조금씩 다르지만 저는 크게 데이터 수집, 데이터 검증 및 전처리, 피처(feature) 추출 및 전처리, 지속적인 학습, 인프라 관리, 모델 관리, 모델 배포, 모델 서빙, 모델 평가 및 검증, 모니터링으로 구성되어 있다고 생각합니다.
이러한 여러 구성 요소 중 모델 서빙 요소를 구현한 도구 중 하나가 이번 글에서 설명드릴 BentoML이라는 오픈소스입니다. BentoML은 자신들을 "From trained ML models to production-grade prediction services with just a few lines of code"라고 설명합니다. 쉽게 표현하면 모델을 더 쉽고 빠르게 배포하는 도구라고 할 수 있습니다.
모델러는 자신이 만든 모델을 빠르게 배포해서 더 많은 피드백을 받아 더 많이 개선하고자 합니다. 그래야 더 좋은 모델을 만들어 더 좋은 서비스를 만들 수 있겠죠. 과거에는 이와 같은 모델 서빙 과정이 서버 엔지니어링과 결합되어 있어서 배포가 까다로웠고 배경지식도 많이 필요했습니다. 이에 따라 모델의 갱신 주기가 길어지고 전문적으로 서빙해야 하는 엔지니어들과 커뮤니케이션하는 비용도 늘어났습니다. BentoML은 이런 단점을 해결하기 위해 탄생했다고 생각합니다. 즉 모델을 서빙하고 배포해야 하는 서버 엔지니어의 업무 부담을 줄여 서버 엔지니어가 자신의 비즈니스에 더욱 집중할 수 있게 도우면서, 동시에 모델 API를 손쉽게 개발하고 배포해 모델을 자주 갱신하고자 하는 모델러의 니즈를 충족하기 위해서입니다.
현재 다양한 서빙 도구들이 나타나 빠르게 생태계를 구축하고 있으며 BentoML 역시 빠르게 성장하고 있습니다. 자연스럽게 BentoML과 관련된 자료들이 많이 발간되고 있는데요. 내용을 살펴보면 실질적으로 프로덕션에 쓰기 위한 자료보다는 PoC(proof of concept) 관련 자료가 많은 것 같습니다. 저는 실제 서비스에 적용하기 위해 제 나름의 기준을 두고 깊이 고민하며 BentoML의 기능과 성능을 테스트했고, 저와 비슷한 고민을 하고 계신 엔지니어들에게 조금이나마 도움이 되었으면 하는 바람으로 테스트 내용을 정리해 이 글을 작성하게 되었습니다. 글은 두 편에 걸쳐 아래와 같은 순서로 진행합니다.
BentoML을 선택한 이유
위에서 MLOps는 방법론이라고 말씀드렸고 여러 가지 방법론과 도구가 존재한다고 말씀드렸습니다. 당연히 모델 서빙과 관련된 도구들도 여럿 존재합니다. 저희가 그중 BentoML을 선택한 이유는 최근 업계에서 많이 사용하며 빠르게 생태계를 확장해 나가고 있다는 점과 더불어, 사내 ML 플랫폼에서 정말 편리하고 손쉽게 BentoML 환경을 구성할 수 있다는 장점 때문입니다. 특히 두 번째 장점이 의사 결정에 큰 영향을 미쳤습니다.
BentoML 기능 테스트
BentoML에는 모델 서빙을 위해 다양한 기능을 제공하고 있습니다. 이번 글에서는 BentoML을 실제 서비스에 적용하는 데 필요한 기능들을 설명하고 예시를 보여드리겠습니다.
기능 테스트를 진행한 항목은 아래와 같습니다.
- MLflow와 연동
- 멀티 모델 기능
- 커스텀 URL 기능
- 커스텀 인풋 전처리와 배치 지원 기능
- 인풋 명세 기능
- 배치 기능
- 패키징 및 Dev 환경 테스트 기능
- 패키지 파일의 구성 및 설명
- 로깅
- 모니터링 기능
MLflow와 연동
MLflow는 모델을 관리하기 위해 사용하는 여러 도구 중 하나입니다. LINE 사내 ML 플랫폼에서는 MLflow를 사용하기 편리한 형태로 제공하고 있습니다. 저희 팀은 MLflow를 모델러 간 커뮤니케이션 용도로 사용하면서, 동시에 ML 파이프라인의 모델 저장소로 사용하고 있습니다. MLflow는 BentoML의 기능은 아니지만, 저희 팀에서는 아래와 같은 방식으로 사용하고 있습니다. 기술적인 용도가 아니라 파이프라인을 구성하기 위한 정책 용도에 더 가깝다고 할 수 있습니다.
모델러는 비즈니스 문제를 해결하기 위해 여러 알고리즘을 적용해 수십 혹은 수백 번의 실험을 수행합니다. 이 실험 내역을 MLflow를 이용해 관리할 수 있고, 최종 모델이 확정되면 이를 리포지터리에 등록할 수 있습니다. 이 단계는 모델러가 직접 수작업으로 진행할 수도 있고, 자동화해서 특정 기준이 충족될 경우 자동으로 모델이 리포지터리에 등록되게 할 수도 있습니다. 이렇게 등록된 모델은 여러 테스트와 QA를 거치며 세 가지 단계(Production, Staging, Archived)로 구분되는데요. 팀 내 정책에 따라 적합한 단계의 모델을 서비스에 적용하면 됩니다.
아래 코드는 MLflow 공식 문서의 내용을 참고해 변형한 코드입니다.
# MLflow client 생성
import mlflow
from mlflow.tracking import MlflowClient
client = MlflowClient(tracking_uri=mlflow_endpoint)
# 모델 이름 정의
model_name="{model_name}"
# 모델 repository 검색 및 조회
filter_string = "name='{}'".format(model_name)
results = client.search_model_versions(filter_string)
for res in results:
print("name={}; run_id={}; version={}; current_stage={}".format(res.name, res.run_id, res.version, res.current_stage))
# Production stage 모델 버전 선택
for res in results:
if res.current_stage == "Production":
deploy_version = res.version
# MLflow production 모델 버전 다운로드 URI 획득
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = client.get_model_version_download_uri(model_name, deploy_version)
# 모델 다운로드
download_path = "{local_download_path}"
mlflow_run_id = "{run_id}"
mlflow_run_id_artifacts_name = "{artifacts_model_name}"
client.download_artifacts(mlflow_run_id, mlflow_run_id_artifacts_name, dst_path=download_path)
# 다운로드 모델 load & predict 예시
reconstructed_model = mlflow.{framework}.load_model("{download_path}/{model_name}".format(download_path=download_path,model_name=mlflow_run_id_artifacts_name))
output = reconstructed_model.predict(input_feature)위 코드를 이용해 다운로드한 Production 단계의 모델은 그대로 BentoML 서빙 API 개발에 사용할 수 있습니다.
멀티 모델 기능
BentoML은 여러 ML 프레임워크와 연동할 수 있다는 장점이 있습니다. Scikit-Learn, PyTorch, Tensorflow, Keras, FastAI, XGBoost, LightGBM, CoreML 등 주요 프레임워크와 연동해 모델을 서빙할 수 있습니다. 저희의 경우에도 비즈니스 특성 혹은 모델러의 배경 및 조직에 따라 하나의 API에서 여러 프레임워크를 사용해야 했고, 각각의 프레임워크에서 산출된 모델의 결과를 별도로 조합해 최종 결과물을 뽑아내야 했습니다. 그렇기에 멀티 모델 기능은 저희에게 필수였습니다.
아래 코드는 멀티 모델을 구현하는 방법으로 사용한 코드의 일부입니다. 코드와 같이 @artifacts 데코레이터에서 사용할 프레임워크별로 모델 이름을 지정할 수 있습니다. 해당 모델은 self.artifact.{model_artifact_name}.{framework_api} 형태로 자유롭게 사용할 수 있습니다.
import xgboost as xgb
import pandas as pd
import torch
import logging
from bentoml import BentoService, api, artifacts, env
from bentoml.frameworks.keras import KerasModelArtifact
from bentoml.frameworks.xgboost import XgboostModelArtifact
from bentoml.frameworks.pytorch import PytorchModelArtifact
from bentoml.adapters import JsonInput, JsonOutput
from model_api_input_validator import ModelApiInputValidator
@env(infer_pip_packages=True)
@artifacts([ # Framework별 모델 이름 지정
KerasModelArtifact('keras_model'),
XgboostModelArtifact('xgb_model'),
PytorchModelArtifact('pytorch_model')
])
class ModelApiService(BentoService):
@api(input=ModelApiInputValidator())
def predict(self, df: pd.DataFrame):
# API 인증 처리
# Input Feature 전처리
# keras_model 예측
keras_output = self.artifacts.keras_model.predict(df)
# xgb_model 예측
xgb_output = self.artifacts.xgb_model.predict(xgb.DMatrix(df))
# pytorch_model 예측
pytorch_output = self.artifacts.pytorch_model(torch.from_numpy(df))
# 예측 결과 후처리
# Logging
# 결과 Return
return result조금 다른 이야기지만, BentoML은 위 코드와 같이 서빙 API를 만들기 위한 템플릿을 손쉽게 만들 수 있습니다. 이에 따라 서버 엔지니어링 혹은 컴퓨터 사이언스를 잘 알지 못하는 모델러도 손쉽게 API를 작성해서 타 조직과 커뮤니케이션할 수 있습니다. 즉 위 코드처럼 BentoService 클래스를 상속받는 사용자 정의 ModelApiService 클래스를 각 서비스 상황에 맞게 템플릿으로 잘 만들어 두고 재사용한다면 모델 CI/CD의 주기를 대폭 감소시킬 수 있다는 의미입니다.
커스텀 URL 기능
배포한 서빙 API에 의미가 있으려면 사업에 기여할 수 있도록 서비스에 녹아들어야 합니다. 비즈니스 로직을 담당하는 조직과 협업이 돼야 한다는 말인데요. 그렇기 때문에 API 관리가 필요하며, 여기서 API 관리란 API 네이밍과 버저닝이라고 생각합니다. 이는 타 조직과의 약속과도 같기 때문에 중요한 요소입니다.
아래 코드는 커스텀 URL을 적용하는 방법입니다. api_name 파라미터로도 변경할 수 있지만, 버저닝 기능을 적용하려면 route 파라미터를 사용하는 편이 더 좋다고 생각합니다.
@env(infer_pip_packages=True)
@artifacts([
...
])
class ModelApiService(BentoService):
@api(input=ModelApiInputValidator(),
output=JsonOutput(),
route="v1/service_name/predict",
mb_max_latency=200,
mb_max_batch_size=500,
batch=False
)
def predict_v1(self, df: pd.DataFrame):
...
return result
@api(input=ModelApiInputValidator(),
output=JsonOutput(),
route="v1/service_name/batch",
batch=True
)
def predict_v1_batch(self, df: pd.DataFrame):
...
return [result]
@api(input=ModelApiInputValidator(),
output=JsonOutput(),
route="v2/service_name/predict",
mb_max_latency=300,
mb_max_batch_size=1000,
batch=False
)
def predict_v2(self, df: pd.DataFrame):
...
return result아래 이미지는 BentoML에서 기본적으로 제공하는 Swagger 화면을 캡처한 것입니다. 지정한 이름으로 API URL이 생성된 것을 확인할 수 있습니다.
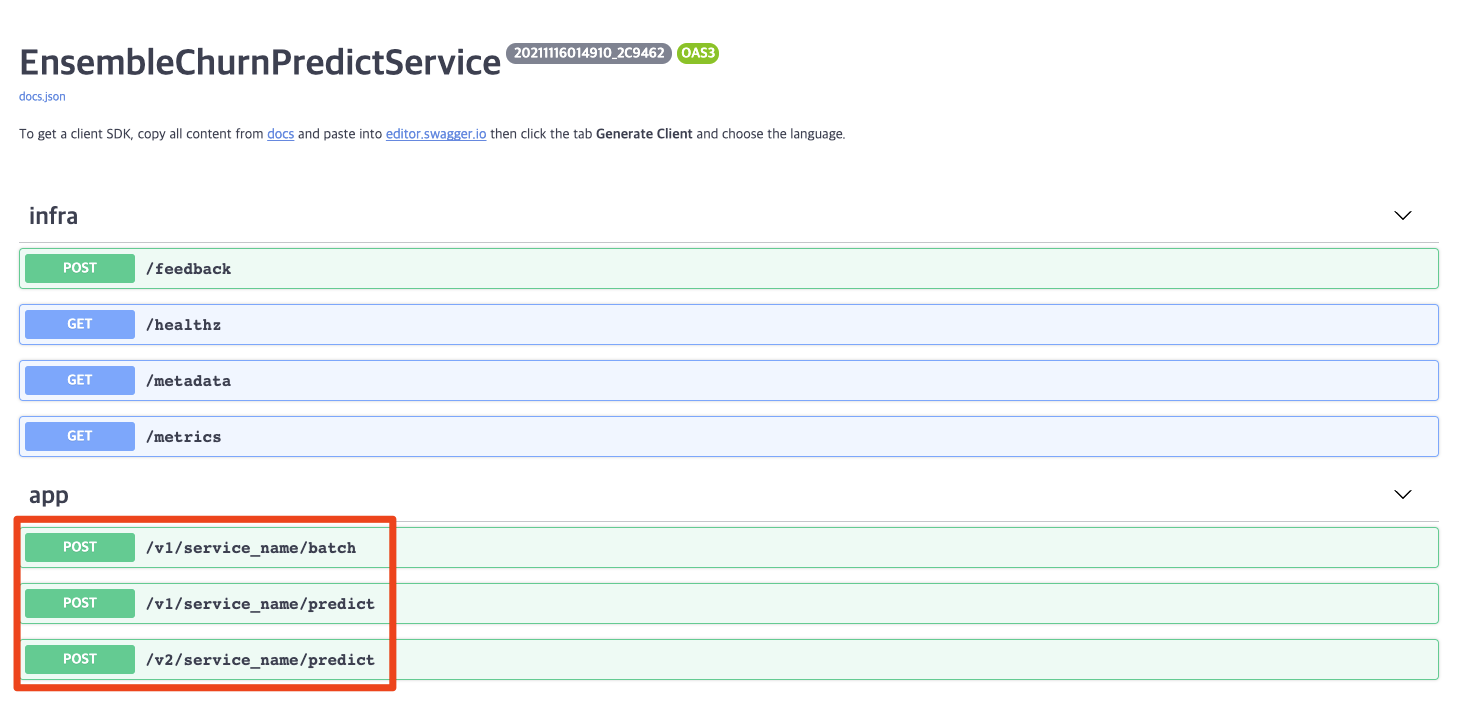
커스텀 인풋 전처리와 배치 지원 기능
BentoML은 데이터 프레임, JSON, Tensor, 이미지, 문자열, 파일 등 다양한 유형의 인풋을 지원합니다. 다만 추가로 커스터마이징하거나 세밀한 인풋 처리 혹은 검증이 필요할 수 있으며, 인풋 검증 과정에서 발생한 문제를 known error로 처리하고 응답 코드를 200으로 송신해 비즈니스 로직에서 재처리해야 하는 경우도 있습니다.
아래 코드는 커스터마이징한 인풋 처리 예시입니다. 문자열로 받은 request body 데이터를 JSON 리스트로 변환하고, 이를 데이터 프레임으로 재변환하는 구조입니다. 아래 예시처럼 필요에 따라 사전에 정의한 에러 코드로 예외 처리하는 것도 가능합니다.
import json
import traceback
import pandas as pd
from enum import Enum
from typing import Iterable, Sequence, Tuple
from bentoml.adapters.string_input import StringInput
from bentoml.types import InferenceTask, JsonSerializable
ApiFuncArgs = Tuple[
Sequence[JsonSerializable],
]
# 사용자 정의 ERROR CODE
class ErrorCode(Enum):
INPUT_FORMAT_INVALID = ("1000", "Missing df_data")
def __init__(self, code, msg):
self.code = code
self.msg = msg
# 사용자 정의 Exception Class
class MyCustomException(Exception):
def __init__(self ,code, msg):
self.code = code
self.msg = msg
class MyCustomDataframeInput(StringInput):
def extract_user_func_args(self, tasks: Iterable[InferenceTask[str]]) -> ApiFuncArgs:
json_inputs = []
# tasks 객체는 Inference로 들어온 요청
for task in tasks:
try:
# task.data는 request body 데이터를 의미
parsed_json = json.loads(task.data)
# 예외 처리 예시
if parsed_json.get("df_data") is None:
raise MyCustomException(
msg=ErrorCode.INPUT_FORMAT_INVALID.msg, code=ErrorCode.INPUT_FORMAT_INVALID.code
)
else:
# batch 처리를 위한 부분
df_data = parsed_json.get("df_data")
task.batch = len(df_data)
json_inputs.extend(df_data)
except json.JSONDecodeError:
task.discard(http_status=400, err_msg="Not a valid JSON format")
except MyCustomException as e:
task.discard(http_status=200, err_msg="Msg : {msg}, Error Code : {code}".format(msg=e.msg, code=e.code))
except Exception:
err = traceback.format_exc()
task.discard(http_status=500, err_msg=f"Internal Server Error: {err}")
# Dataframe 변환
df_inputs=pd.DataFrame.from_dict(json_inputs, orient='columns')
return (df_inputs,)
from my_custom_input import MyCustomDataframeInput
@env(infer_pip_packages=True)
@artifacts([
...
])
class ModelApiService(BentoService):
# Custom Input Class 사용 방법
@api(input=MyCustomDataframeInput(),
route="v1/json_input/predict",
batch=True
)
def predict_json_input(self, df: pd.DataFrame):
...
return resultBentoML은 위 예시와 같이 자유롭게 인풋을 전처리할 수 있다는 장점이 있습니다. 상황에 맞게 위 예시 코드에 로직을 추가해서 사용해도 좋을 것 같습니다. 한 가지 부연 설명을 드리자면, 커스텀 인풋 처리는 Input Adaptor의 추상 클래스인 BaseInputAdapter의 extract_user_func_args()를 오버라이딩하는 개념입니다. 각 Input Adapter의 내부를 살펴보면 데이터 프레임 인풋의 경우 수신한 request body를 Pandas Dataframe으로 만들고, 이미지 인풋의 경우 수신한 request body를 imageio 라이브러리를 이용해 이미지 객체로 만드는 것을 확인할 수 있습니다(관련 클래스들은 BentoML GitHub에서 확인할 수 있습니다).
또한 BentoML은 성능 향상을 위해 Micro Batching 기능을 제공합니다. 주의할 점은 마이크로 배치나 배치 기능을 사용할 때, 인풋에 대한 배치 처리도 추가해야 한다는 것입니다. 추가하지 않으면 트래픽이 많지 않을 때는 괜찮지만 트래픽이 증가할 경우 마이크로 배치가 정상 작동하지 않고 에러가 발생할 수 있습니다. 여러 요청에 대한 태스크를 한 번에 묶어서 처리하는 과정에서 요청한 태스크와 반환하고 싶은 결과가 각각 매칭이 되지 않아 발생하는 에러입니다. 얼마 전 이와 관련된 커스텀 인풋 처리 예시 내용을 BentoML GitHub에 Pull Request를 요청했고, 현재 master 브랜치에 머지된 상태입니다.
인풋 명세 기능
BentoML은 메타데이터를 통해 인풋 피처가 무엇이고 각각의 데이터 타입이 무엇인지 알 수 있으며, 자체 Swagger를 통해 해당 인풋과 관련된 예시와 정보를 획득할 수 있습니다. 따라서 BentoML에서 인풋에 대해 잘 명세해 놓는다면 타 조직과의 커뮤니케이션 비용을 줄일 수 있습니다. 인풋 명세는 인풋 타입에 따라 방식이 상이합니다. 아래 코드는 커스텀 인풋과 데이터 프레임 인풋 명세의 예시입니다.
from model_api_json_input_validator import ModelApiJsonInputValidator
from model_api_json_validator import ModelApiInputValidator
from bentoml.adapters import DataframeInput
@env(infer_pip_packages=True)
@artifacts([
...
])
class ModelApiService(BentoService):
# 커스텀 인풋 명세 예시
@api(input=ModelApiInputValidator(
http_input_example=[{"feature1":0.0013,"feature2":0.0234 ... }],
request_schema= {
"application/json": {
"schema": {
"type": "object",
"required": ["feature1", "feature2", ... ],
"properties": {
"feature1": {"type": "float64"}, "feature2": {"type": "float64"}, ...
},
},
}
}),
output=JsonOutput(),
route="v1/custom_input/predict",
mb_max_latency=200,
mb_max_batch_size=500,
batch=False
)
def predict_custom_input(self, df: pd.DataFrame):
...
return result
# 데이터 프레임 인풋 명세 예시
@api(input=DataframeInput(
orient = "records",
colums = ['feature1','feature2', ... ],
dtype = {"feature1":"float64", feature2":"float64", ... }),
output=JsonOutput(),
route="v1/dataframe_input/predict",
mb_max_latency=200,
mb_max_batch_size=500,
batch=False
)
def predict_dataframe_input(self, df: pd.DataFrame):
...
return result아래 Swagger를 보면 인풋 명세에 따라 Example Value와 Schema가 정의된 것을 확인할 수 있습니다.
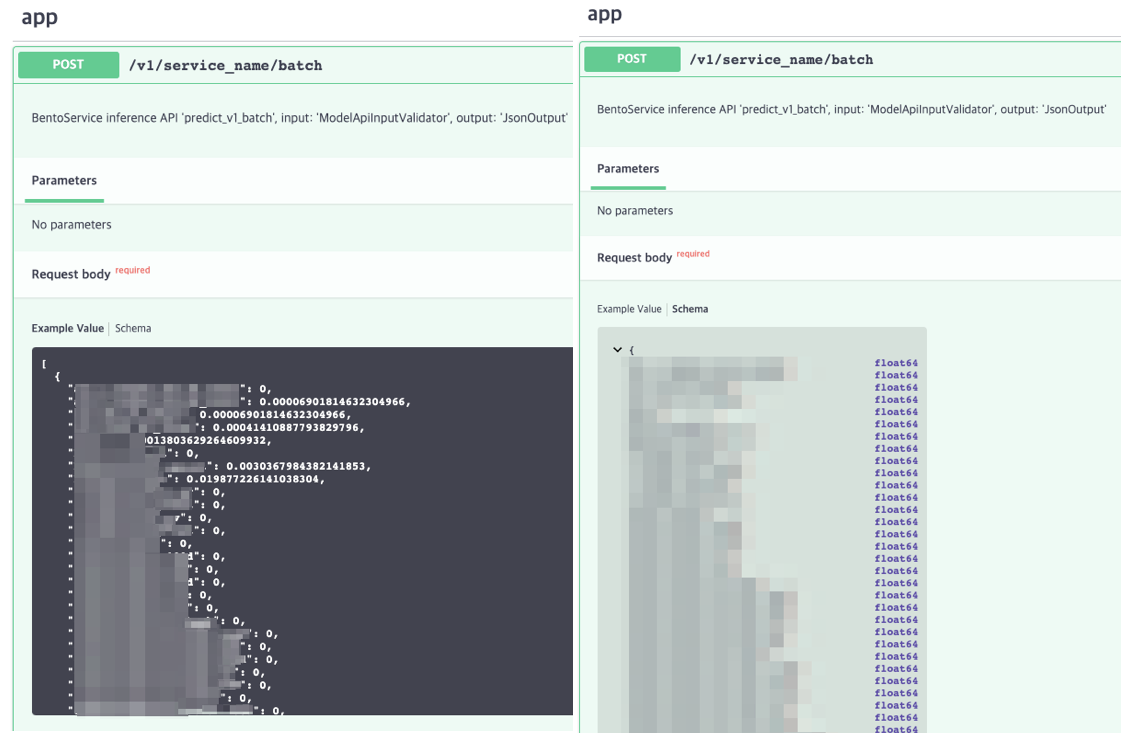
배치 기능
BentoML은 온라인 서빙 외에 배치 기능도 적용할 수 있습니다. 쉽게 말해 인풋 피처를 100개 송신하면 아웃풋을 100개 반환하는 개념입니다. 결국 내부에서 ML 프레임워크의 예측 API를 사용하기 때문에 기본적으로 배치 기능을 제공하는 건 당연한 내용이라고 할 수 있습니다. 앞서 보여드린 예시 코드에도 나왔지만, 기본적으로 @api 데코레이터의 batch 파라미터를 이용해 관리합니다. 마이크로 배치는 mb_max_batch_size, mb_max_latency, 두 파라미터를 이용해 조절할 수 있습니다.
@env(infer_pip_packages=True)
@artifacts([
KerasModelArtifact('keras_model'),
XgboostModelArtifact('xgb_model'),
PytorchModelArtifact('pytorch_model')
])
class ModelApiService(BentoService):
@api(input=ModelApiInputValidator(),
output=JsonOutput(),
route="v1/service_name/batch",
mb_max_latency=200, # micro batch 관련 설정
mb_max_batch_size=500, # micro batch 관련 설정
batch=True # batch 관련 설정
)
def predict_v1_batch(self, df: pd.DataFrame):
...
# keras_model 예측
keras_output = self.artifacts.keras_model.predict(df)
# xgb_model 예측
xgb_output = self.artifacts.xgb_model.predict(xgb.DMatrix(df))
# pytorch_model 예측
pytorch_output = self.artifacts.pytorch_model(torch.from_numpy(df))
# 예측 결과 후처리( 최소 O(n)의 작업 )
# 결과 Return
return result서비스의 특성에 따라 오프라인 서빙이 필요한 경우가 많습니다. 온라인 서빙이 무조건 효율적이지는 않기 때문입니다. 하지만 이런 배치 기능을 꼭 BentoML을 통해 사용해야 하는지 의구심이 들었습니다. BentoML의 배치 처리의 경우 반환할 때 리스트 형태로 반환해야 하며, 인풋 개수만큼 아웃풋이 반환돼야 합니다. 위 예시를 보면 예측 결과가 각 프레임워크별로 다른 데이터 타입으로 반환되고, 이 결과를 후처리 단계에서 조합하기 위해 O(n)만큼의 반복문 수행이 필수입니다. 지연 시간이 중요한 서비스에서는 비효율적인 부분이라고 생각합니다. 아주 간단한 서빙 API라면 상관없겠지만 조금 복잡한 로직을 추가한 경우, 온라인과 오프라인을 같은 API에서 사용하면 불필요한 로직이 추가되기 때문에 분리해서 관리하는 게 좋지 않을까 생각합니다(단, 마이크로 배치 기능을 사용하기 위해서 반복문은 필수입니다). 더 나아가 성능 관점에서 대용량 배치는 Airflow와 같은 스케줄러가 더 효율적이라고 생각합니다.
패키징 및 Dev 환경 테스트 기능
이제 API 개발을 완료했으니 패키징이 필요합니다. 저는 처음에 패키징이라는 개념이 한 번에 와닿지 않았기 때문에 조금 쉬운 개념으로 설명하겠습니다. 서빙 API를 구성하기 위해서는 지금까지 예시로 들었던 Python 스크립트들, MLflow에서 다운로드한 학습된 모델 파일, 서빙 API의 명세를 담고 있는 메타데이터 혹은 프레임워크 및 Python 패키지 버전 정보 등 여러 정보가 필요합니다. 이런 여러 정보를 하나의 파일로 압축하는 과정이 패키징이라고 이해하시면 됩니다. 실제로 BentoML에서도 *.tar.gz로 압축합니다. 이런 과정을 BentoML에서는 아주 쉽게 진행할 수 있습니다. 또한 패키징한 서빙 API의 단위 테스트 역시 쉽게 할 수 있도록 지원합니다. 테스트를 수행하는 방법은 매우 다양한데요. 이번 글에서는 경험해 본 결과 가장 간편한 방법을 공유하겠습니다.
아래 코드를 보면 예시로 만들었던 BentoML Python 스크립트를 import하고, 객체를 생성하고, pack API를 이용해 다운로드했거나 로컬에 존재하는 모델을 패키징합니다. 또한 ML 파이프라인에서 사용하기 위해 패키징된 압축 파일을 BentoML의 모델 관리 컴포넌트인 yatai 서버에 업로드할 수 있습니다.
# BentoML service packaging
from model_api_service import ModelApiService
model_api_service = ModelApiService()
model_api_service.pack("keras_model", {"model": keras_reconstructed_model, "custom_objects": custom_objects})
model_api_service.pack("xgb_model", xgb_reconstructed_model)
model_api_service.pack("pytorch_model", pytorch_reconstructed_model)
# BentoML Package Upload to yatai server
saved_path = ensemble_churn_predict_service.save()
# dev server start
ensemble_churn_predict_service.start_dev_server(port=5000)
# dev server stop
ensemble_churn_predict_service.stop_dev_server()
# Send test request to dev server
import requests
response = requests.post("http://127.0.0.1:5000/v1/service_name/predict", data='[{"feature1":0.0013803629264609932,"feature2":0.023466169749836886, ... }]')
print(response)
print(response.text)단위 테스트 방법으로는 start_dev_server()를 이용한 방법을 적어 두었습니다. 이 방법은 개발하는 로컬 환경 혹은 Jupyter notebook 환경에서 BentoML을 패키징하고 별도 처리 없이 구현한 API를 바로 테스트할 수 있다는 장점이 있습니다. Docker 개념이나 서버 개념을 잘 모르는 모델러에게 유용한 방법이라고 생각합니다.
패키지 파일 구성 및 설명
패키지의 압축을 풀면 아래와 같은 파일로 구성되어 있습니다.
| 이름 | 타입 | 설명 |
|---|---|---|
| bentoml-init.sh | 파일 | BentoML API 서버를 구성하기 위한 스크립트(conda 환경을 구성하거나 관련 Python 패키지를 설치하며 Docker가 빌드될 때 수행) |
| bentoml.yml | 파일 | BentoML API 서버를 구성하기 위한 메타데이터 정의 파일(인풋 피처, 인풋 피처 스키마 등) |
| docker-entrypoint.sh | 파일 | BentoML API 서버 Docker의 entrypoint 파일 |
| Dockerfile | 파일 | BentoML API 서버 Docker 파일(Docker CMD에서 $bentoml serve-gunicorn 명령어를 실행, 베이스 이미지를 변경할 수 있지만 패키지 의존성 관리를 직접 해야 하기 때문에 디폴트 그대로 사용하는 것을 추천) |
| environment.yml | 파일 | BentoML API 서버의 환경 정보 |
| MANIFEST.in | 파일 | MANIFEST 정보 |
| User Define Class Name | 디렉토리 | 사용자가 작성한 서빙 API BentoML 서비스 클래스와 .pack()를 통해 패키징한 모델 파일들로 구성 |
| python_version | 파일 | Python 버전 정보 |
| READ.md | 파일 | 설명 문서 |
| requirements.txt | 파일 | 필요한 Python 패키지 버전 정보 (BentoML @env에서 infer_pip_packages=True일 경우 개발을 수행한 환경의 버전을 따라감) |
| setup.py | 파일 | setup.py 파일 |
로깅
실제 서비스로 서빙 API를 배포하고 운영하려면 로그 관리는 필수입니다만, BentoML에서는 별도로 로그를 관리하지 않습니다. 이에 저희는 Filebeat를 이용해 별도로 로그를 수집하는 구조를 선택했습니다. Filebeat를 선택한 이유는 경량이면서 손쉽게 로그를 수집할 수 있어야 한다고 판단했기 때문입니다. BentoML에서는 아래와 같은 로그를 도커 컨테이너 내의 /home/bentoml/logs/* 하위에 남깁니다.
- active.log - BentoML CLI 로그 혹은 Python 자체에서 남기는 로그
- prediction.log - 인풋 요청에 대해 추론한 결과 로그(몇 시에, 어떤 request_id로, 어떤 인풋과 어떤 아웃풋이 나갔는지 로깅)
- feedback.log - 추론 결과에 대한 피드백 로그
비즈니스와 연관된 추가 로깅을 원한다면 서빙 API BentoService 클래스에 아래와 같이 코드를 작성하면 됩니다. getLogger("bentoml")의 경우 active.log 파일에 남습니다.
import logging
bentoml_logger = logging.getLogger("bentoml")
bentoml_logger.info("****** bento ml info log *******")추가로 Filebeat 기반 로그 수집 환경을 구성하기 위해 Dockerfile에 아래와 같은 명령어를 추가했고, docker-entrypoint.sh에서 Filebeat 프로세스를 실행하는 명령어를 추가하여 컨테이너 기동 시 무조건 구동되도록 구성했습니다. 이 과정은 CI 단계에서 자동화해서 처리할 수 있다고 생각합니다. Filebeat의 아웃풋은 여러 저장소가 될 수 있기 때문에 상황에 맞는 아웃풋을 선정하면 될 것 같습니다.
...
# 기존 DocekerFile 내용
# logging process를 위한 추가 된 부분
RUN wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-{version}-linux-x86_64.tar.gz -O /home/bentoml/filebeat.tar.gz
RUN tar -zxvf /home/bentoml/filebeat.tar.gz
RUN mv filebeat-{version}-linux-x86_64 filebeat
COPY --chown=bentoml:bentoml filebeat_to_secure_kafka.yml ../
# 기존 DocekerFile 내용
USER bentoml
RUN chmod +x ./docker-entrypoint.sh
ENTRYPOINT [ "./docker-entrypoint.sh" ]
CMD ["bentoml", "serve-gunicorn", "./"]모니터링 기능
BentoML은 자체적으로 프로메테우스 metrics API를 제공합니다. 프로메테우스 환경만 구성되어 있다면 손쉽게 대시보드를 구성할 수 있습니다. 아래는 BentoML에서 제공하는 지표를 가시화한 화면입니다. 범례를 endpoint와 http_response_code로 구분하면 총 유입된 요청과 마이크로 배치로 요청된 양, 에러 비율 등을 편리하게 확인할 수 있습니다.
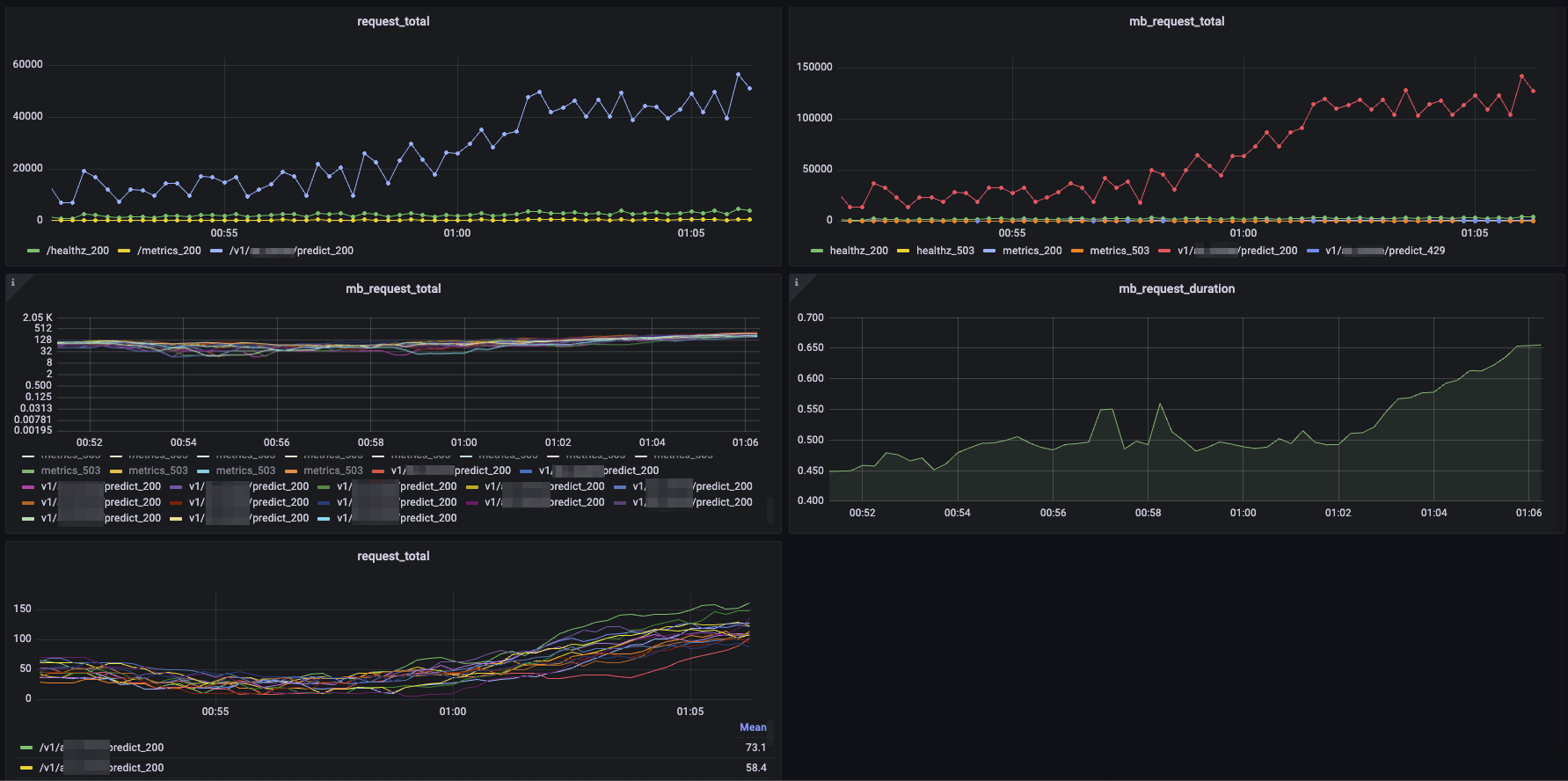
마치며
이번 글에서는 MLOps 모델 서빙 도구로 왜 BentoML을 선택했는지 말씀드리고, 실제 서비스에 적용하는 데 필요한 기능들을 설명하고 예시를 보여드렸습니다. 이어서 다음 편에서는 Kubernetes를 이용해 BentoML을 서비스하기 위한 아키텍처를 설명하고, 무중단 배포 방법 네 가지를 설명하겠습니다. 또한 성능을 테스트한 후 결과를 개선하기 위해 진행했던 여러 실험과 개선 결과를 공유드리겠습니다. 긴 글 읽어주셔서 감사합니다.