
들어가며
안녕하세요. LINE Financial Data Platform을 운영하고 개발하고 있는 이웅규입니다. 이 글은 지난 NAVER DEVIEW 2020에서 발표했던 Kubernetes를 이용한 효율적인 데이터 엔지니어링 (Airflow on Kubernetes VS Airflow Kubernetes Executor) 세션에서 발표 형식 및 시간 관계상 설명하기 힘들었던 부분을 조금 더 자세하게 설명하고자 작성한 두 번째 글입니다(1부). 이번 글에서는 일반적인 Kubernetes Airflow 환경과 새로운 방식의 특징 및 장단점을 비교합니다. 그리고 새로운 방식인 Kubernetes Executor와 KubernetesPodOperator를 적용해 데이터 플랫폼을 어떻게 운영하고 개발하고 있는지 말씀드리고, 이를 통해 기존보다 확장성을 높였던 경험을 공유하겠습니다.
이 글은 기본적으로 Airflow를 알고 계신다는 가정 하에 작성했습니다. 이 글에 첨부한 코드와 설명은 Apache Airflow 1.10.12 기준이며, 최근 Apache Airflow 2.0이 개발되었지만 기본적인 원리 측면에서는 다르지 않다고 생각합니다.
Kubernetes X Airflow
Kubernetes 환경에서 Airflow를 사용하는 방법엔 두 가지가 있습니다. 첫 번째로 Kubernetes 위에 Airflow를 구성하는 일반적인 방법이 있고, 두 번째로는 Kubernetes Executor를 사용하는 방법이 있습니다. 각 방법은 무엇이 좋거나 나쁘다고 할 수 없이 각각 장단점이 있습니다. 두 방법의 동작 원리와 장점과 단점을 비교해보겠습니다.
일반적인 Airflow on Kubernetes

그림 5와 그림 6은 일반적으로 Kubernetes에 Airflow 환경을 구성하는 예시입니다. 첫 번째 글의 Airflow Executor 종류와 특징에서 설명드린 구조와 크게 다르지 않다는 것을 알 수 있습니다. 장비나 프로세스 형태로 존재하던 컴포넌트들이 POD 형태로 바뀌었다고 보면 됩니다. 위 구성은 예시로 든 것이고, 각 서비스 사정에 맞게 Local Executor의 POD를 하나로 구성한다든지 Redis를 단일 POD로 구성한다든지와 같이 자유롭게 변경할 수 있습니다. 이 부분이 Kubernetes를 활용했을 때의 장점이기도 하겠네요.
일반적인 Airflow on Kubernetes의 장단점
이 구성의 장단점을 사례를 들어 설명하겠습니다. 이 구성의 가장 큰 장점은 구성이 간단하고 템플릿화하기 쉽다는 점입니다. 이런 장점은 아래와 같은 관리형(managed) Airflow 서비스를 개발하려는 조직, 공용 데이터 조직이 있고 해당 조직에서 Airflow 서비스를 다양한 조직에 제공해야 할 때 유용합니다. 실제 상용 사례로는 GCP(Google Cloud Platform)의 Cloud Composer와 같은 서비스라고 할 수 있겠네요. 저희 LINE에서도 이와 유사한 서비스를 사내에 제공하는 프로젝트가 존재합니다. 하지만 아래와 같은 프로젝트나 서비스는 어느 정도 규모가 있는 조직이어야 수요가 있을 것이라고 생각합니다.

단점은 구성 자체가 POD로만 변환된 부분이기 때문에 Celery Executor 기준으로 마스터와 메시지 브로커, 워커 등이 Kubernetes 환경에 지속적으로 상주한다는 점입니다. 따라서 자원을 계속 점유하며 관리 포인트 또한 그대로 유지됩니다. 물론 기존과 달리 Kubernetes에서 오케스트레이션(orchestration)해주기 때문에 유지 보수 및 관리하기가 조금 더 수월하다고는 할 수 있습니다.
또 다른 단점으로는 컨테이너 확장성을 들 수 있는데요. 아래 그림을 예로 들어 설명하겠습니다.

실제 저희 사례이기도 하고 데이터 조직이라면 아마 한 번쯤은 겪어보셨을 내용이라고 생각합니다. 그림 8의 가장 좌측 Docker 컨테이너 구성을 보겠습니다. 일반적으로 Hadoop 기반의 데이터 조직에서 Airflow를 구성할 때 설치하는 기본 구성이라 할 수 있습니다. 이 환경에서 만약 신규 요구 사항이 발생해 다른 Hadoop 클러스터와 연계해야 한다고 하면 새로운 Airflow 환경에 신규 Hadoop 클라이언트를 설치하고 두 개의 Airflow를 운영하는 선택지가 하나 있을 것이고, 또 다른 선택지는 기존의 Airflow 환경에 새로운 Hadoop 클라이언트를 추가로 설치하는 방법일 것입니다. 대부분의 데이터 조직은 후자로 의사 결정할 것 같은데요. 그렇게 되면 테스트해야 하는 항목이 정말 많아집니다. 신규 Hadoop 클라이언트 설치 및 환경 변수 확인, 각 Hadoop ECO 컴포넌트 기능 확인, 라이브러리 의존성 확인, Python 버전 의존성 확인, 기존 서비스 코드와 연계했을 때 정상 작동 여부 확인 등등... 테스트해야 하는 항목이 정말 많습니다. 이 작업은 리서치부터 테스트까지 적어도 1주일은 걸릴 수 있는 작업이라고 생각합니다. 더군다나 저희는 하나의 Airflow에서 3개의 Hadoop 클러스터에 접근해야 하는 환경인데요. 그렇게 되면 환경 구성 문제도 있지만 Docker 이미지도 매우 커질뿐더러 유지 보수 및 관리도 정말 힘들어집니다.
KubernetesExecutor & KubernetesPodOperator
저희는 앞서 언급한 단점 때문에 Kuberntes Executor에서 KubernetesPodOperator를 사용하고 있는데요. Kubernetes Executor는 일반적인 Kubernetes 환경에서의 Airflow와 다르게 필요할 때만 Kubernetes 자원을 사용합니다. 또한 KubernetesPodOperator를 사용하면 개발자가 필요한 Docker 컨테이너만을 골라 POD로 실행시킬 수 있습니다. 여기서 KubernetesPodOperator는 Kubernetes Executor에 종속된 기능은 아닙니다. Kubernetes에 Airflow가 구성되어 있다면 사용할 수 있는 오퍼레이터입니다. 그럼 Kubernetes Executor가 어떻게 작동하는지 알아보겠습니다.
Kubernetes Executor의 동작 원리 및 특징
Kubernetes Executor의 동작은 오퍼레이터의 종류에 따라 두 가지로 나뉩니다. 오퍼레이터의 종류는 일반적인 오퍼레이터와 KubernetesPodOperator로 나눌 수 있습니다. 여기서 일반적인 오퍼레이터는 우리가 익히 알고 있는 PythonOperator와 BashOperator, ExternalTaskSensor 등과 같은 오퍼레이터와 센서를 의미합니다. 아래 그림 9는 일반적인 오퍼레이터를 사용했을 때 Kubernetes Executor의 동작 원리입니다.

위 그림을 보면, 수행해야 할 시점이 된 태스크를 스케줄러가 찾고, Executor가 동적으로 Airflow 워커를 POD 형태로 실행합니다. 해당 워커 POD에서 실제 개발자가 정의한 태스크를 수행하는 개념이라고 생각하시면 됩니다. 아래는 이에 해당하는 코드입니다.
class WorkerConfiguration(LoggingMixin):
def as_pod(self):
if self.kube_config.pod_template_file:
return PodGenerator(pod_template_file=self.kube_config.pod_template_file).gen_pod()
pod = PodGenerator(
image=self.kube_config.kube_image,
image_pull_policy=self.kube_config.kube_image_pull_policy or 'IfNotPresent',
image_pull_secrets=self.kube_config.image_pull_secrets,
volumes=self._get_volumes(),
volume_mounts=self._get_volume_mounts(),
init_containers=self._get_init_containers(),
labels=self.kube_config.kube_labels,
annotations=self.kube_config.kube_annotations,
affinity=self.kube_config.kube_affinity,
tolerations=self.kube_config.kube_tolerations,
envs=self._get_environment(),
node_selectors=self.kube_config.kube_node_selectors,
service_account_name=self.kube_config.worker_service_account_name or 'default',
restart_policy='Never'
).gen_pod()
pod.spec.containers[0].env_from = pod.spec.containers[0].env_from or []
pod.spec.containers[0].env_from.extend(self._get_env_from())
pod.spec.security_context = self._get_security_context()
return append_to_pod(pod, self._get_secrets())WorkerConfiguration 클래스에서 워커 POD를 정의합니다. airflow.cfg Kubernetes 세션에 기재된 컨테이너 정보와 DAG 볼륨, 로그 볼륨 등과 같은 정보가 Airflow 워커 POD의 설정 정보입니다.
AirflowKubernetesScheduler 클래스의 run_next 함수를 보시면 컨테이너에서 실행하는 명령어 또한 Airflow 기본 동작 원리에서 설명해 드린 것과 동일하게 airflow run으로 시작하는 명령어입니다. 해당 명령어가 전달되면 태스크를 실행합니다.
class AirflowKubernetesScheduler(LoggingMixin)
def run_next(self, next_job):
self.log.info('Kubernetes job is %s', str(next_job))
key, command, kube_executor_config = next_job
dag_id, task_id, execution_date, try_number = key
if command[0:2] != ["airflow", "run"]:
raise ValueError('The command must start with ["airflow", "run"].')
pod = PodGenerator.construct_pod(
namespace=self.namespace,
worker_uuid=self.worker_uuid,
pod_id=self._create_pod_id(dag_id, task_id),
dag_id=pod_generator.make_safe_label_value(dag_id),
task_id=pod_generator.make_safe_label_value(task_id),
try_number=try_number,
date=self._datetime_to_label_safe_datestring(execution_date),
command=command,
kube_executor_config=kube_executor_config,
worker_config=self.worker_configuration_pod
)
sanitized_pod = self.launcher._client.api_client.sanitize_for_serialization(pod)
json_pod = json.dumps(sanitized_pod, indent=2)
self.log.debug("Kubernetes running for command %s", command)
self.log.debug("Kubernetes launching image %s", pod.spec.containers[0].image)
self.launcher.run_pod_async(pod, **self.kube_config.kube_client_request_args)
self.log.debug("Kubernetes Job created!")아래 그림 10은 일반 오퍼레이터가 아닌 KubenretesPodOperator를 사용했을 때의 동작 원리입니다. 기본적인 원리는 일반적인 오퍼레이터를 사용했을 때와 동일합니다. 수행해야 할 시점이 된 태스크를 스케줄러가 찾고, Executor는 동적으로 Airflow 워커를 POD 형태로 실행합니다. 다만 해당 워커 POD에서 개발자가 직접 정의한 컨테이너 이미지를 POD 형태로 또다시 실행한다는 차이점이 있습니다. 이런 이유로 하나의 Airflow 환경에서 다양한 퍼블릭 클라우드에 접근할 수 있는 자유로운 환경이 마련됩니다.

아래 코드는 KubernetesPodOperator 클래스의 execute 함수와 create_new_pod_for_operator 함수입니다. execute 함수에서 Kubernetes API 클라이언트 객체를 생성하고 생성한 클라이언트를 이용해 Kubernetes API 서버에 POD 생성을 요청합니다.
class KubernetesPodOperator(BaseOperator)
def execute(self, context):
try:
if self.in_cluster is not None:
client = kube_client.get_kube_client(in_cluster=self.in_cluster,
cluster_context=self.cluster_context,
config_file=self.config_file)
else:
client = kube_client.get_kube_client(cluster_context=self.cluster_context,
config_file=self.config_file)
# Add combination of labels to uniquely identify a running pod
labels = self.create_labels_for_pod(context)
label_selector = self._get_pod_identifying_label_string(labels)
pod_list = client.list_namespaced_pod(self.namespace, label_selector=label_selector)
if len(pod_list.items) > 1 and self.reattach_on_restart:
raise AirflowException(
'More than one pod running with labels: '
'{label_selector}'.format(label_selector=label_selector))
launcher = pod_launcher.PodLauncher(kube_client=client, extract_xcom=self.do_xcom_push)
if len(pod_list.items) == 1:
try_numbers_match = self._try_numbers_match(context, pod_list.items[0])
final_state, result = self.handle_pod_overlap(labels, try_numbers_match, launcher, pod_list)
else:
final_state, _, result = self.create_new_pod_for_operator(labels, launcher)
if final_state != State.SUCCESS:
raise AirflowException(
'Pod returned a failure: {state}'.format(state=final_state))
return result
except AirflowException as ex:
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))생성하는 POD에 대한 정의는 create_new_pod_for_operator 함수에서 수행합니다. POD 설정 정보는 Airflow 워커를 생성했을 때와 다르게 개발자가 직접 정의한 컨테이너 image와 namespace, resource, affinity 등의 정보를 이용합니다. 따라서 개발자가 원하는 조건의 POD를 생성하는 것이 가능합니다.
class KubernetesPodOperator(BaseOperator)
def create_new_pod_for_operator(self, labels, launcher):
if not (self.full_pod_spec or self.pod_template_file):
self.labels.update(
{
'airflow_version': airflow_version.replace('+', '-'),
'kubernetes_pod_operator': 'True',
}
)
self.labels.update(labels)
pod = pod_generator.PodGenerator(
image=self.image,
namespace=self.namespace,
cmds=self.cmds,
args=self.arguments,
labels=self.labels,
name=self.name,
envs=self.env_vars,
extract_xcom=self.do_xcom_push,
image_pull_policy=self.image_pull_policy,
node_selectors=self.node_selectors,
annotations=self.annotations,
affinity=self.affinity,
image_pull_secrets=self.image_pull_secrets,
service_account_name=self.service_account_name,
hostnetwork=self.hostnetwork,
tolerations=self.tolerations,
configmaps=self.configmaps,
security_context=self.security_context,
dnspolicy=self.dnspolicy,
init_containers=self.init_containers,
restart_policy='Never',
schedulername=self.schedulername,
pod_template_file=self.pod_template_file,
priority_class_name=self.priority_class_name,
pod=self.full_pod_spec,
).gen_pod()
pod = append_to_pod(
pod,
self.pod_runtime_info_envs + # type: ignore
self.ports + # type: ignore
self.resources + # type: ignore
self.secrets + # type: ignore
self.volumes + # type: ignore
self.volume_mounts # type: ignore
)
self.pod = pod
try:
launcher.start_pod(
pod,
startup_timeout=self.startup_timeout_seconds)
final_state, result = launcher.monitor_pod(pod=pod, get_logs=self.get_logs)
except AirflowException as ex:
if self.log_events_on_failure:
for event in launcher.read_pod_events(pod).items:
self.log.error("Pod Event: %s - %s", event.reason, event.message)
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
finally:
if self.is_delete_operator_pod:
launcher.delete_pod(pod)
return final_state, pod, result
Kubernetes Executor의 장단점
Kubernetes Executor의 장단점을 살펴보겠습니다.
장점
- 가볍다 - Airflow는 라이브러리 의존성이 없는 GitHub 혹은 Docker Hub에서 받은 기본 이미지를 사용해도 무방합니다. 기존 방식대로 Hadoop 기반의 Airflow 장비 혹은 컨테이너를 운영한다고 하면 Airflow 내에 Hadoop 클라이언트와 Spark 클라이언트, Hive 클라이언트, Sqoop 클라이언트, Kerberos 설정 등이 모두 구성되어 있어야 합니다. 하지만 Kubernetes Executor와 KubernetesPodOperator를 사용하면 앞서 언급한 사항이 필요하지 않습니다.
- 유지 보수 비용 절감 - 컨테이너 이미지 기반으로 운영하기 때문에 태스크 간 독립성이 보장되어 라이브러리 간 의존성 확인과 같은 불필요한 작업을 수행하지 않아도 됩니다. 또한 다양한 데이터 플랫폼 환경에 자유롭게 접근할 수 있기 때문에 여러 환경에 맞춰 각각 구성했던 Airflow를 하나로 통합하는 것도 가능합니다.
- 효율적인 자원 관리 - 기존 Celery Executor를 Kubernetes에서 사용할 경우 마스터와 워커, 브로커가 지속적으로 자원을 점유하고 상주해 있지만 Kubernetes Executor의 경우 태스크가 실행될 경우에만 워커를 생성하고 태스크가 완료되면 자원을 반납하기 때문에 Kubernetes의 자원을 효율적으로 사용할 수 있습니다.
- 개발 효율성 - 대부분의 DAG를 KubernetesPodOperator만을 사용해 운영하면 Workflow DAG 코드를 템플릿화할 수 있습니다. 이를 통해 DAG를 개발하는 비 개발자(분석가, 데이터 사이언티스트)가 DAG를 작성하는데 많은 리서치와 시간을 투자하지 않고 자신의 코어 업무에만 집중할 수 있습니다.
단점
- 부족한 레퍼런스 - 최근에는 좀 많아졌지만, 아직 서비스 적용 사례나 관련 자료가 많지는 않아서 2019년, 저희 팀에서 처음 환경을 구성할 때 어려움이 많았습니다.
- 까다로운 구성 - 상대적으로 구성이 까다롭습니다. 워커 POD는 휘발성이기 때문에 POD가 종료되면 로그가 유실됩니다. 그렇기 때문에 Airflow에서는 외부 저장소인 GCS(Google Cloud Storage)와 Amazon S3, ES(Elastic Search) 등으로 로그를 저장하도록 가이드하고 있습니다. 아래 그림 11은 저희가 사용하고 있는 구성의 예입니다.

사례 소개
다음으로 몇 가지 사례를 공유하겠습니다.
Apache Airflow 성능 개선 사례
최근에 운영 중인 DAG가 점점 많아지면서 하루에 수행하는 태스크 또한 수천 개로 늘어났습니다. 그 결과 아래 그림 12처럼 전체적으로 DAG별 작업 시간이 서서히 증가하면서 결국 작업이 지연되는 이슈가 발생했습니다.
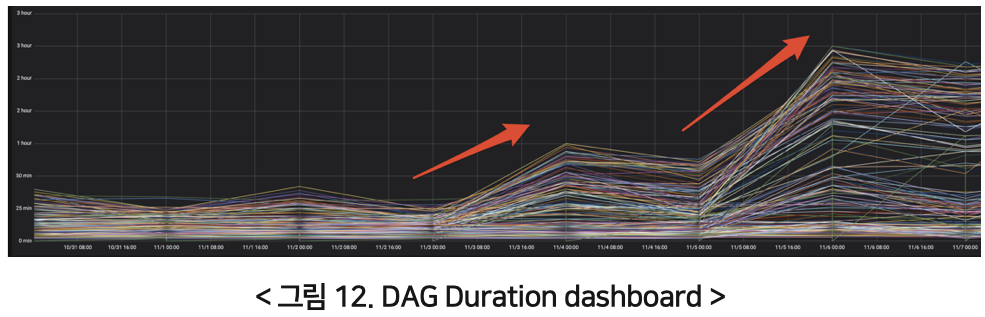
처음엔 DAG 실행과 태스크 실행의 병렬 설정(parallelism, dag_concurrency) 값을 증가시켜 보았지만 눈에 띄는 효과를 보지는 못했습니다. 그래서 작업 시간이 증가하는 각 DAG를 직접 확인해 봤고, 그 결과 특이한 사항을 발견했습니다. 아래 그림 13은 특정 DAG의 태스크별 작업 시간에 대한 간트 차트입니다.
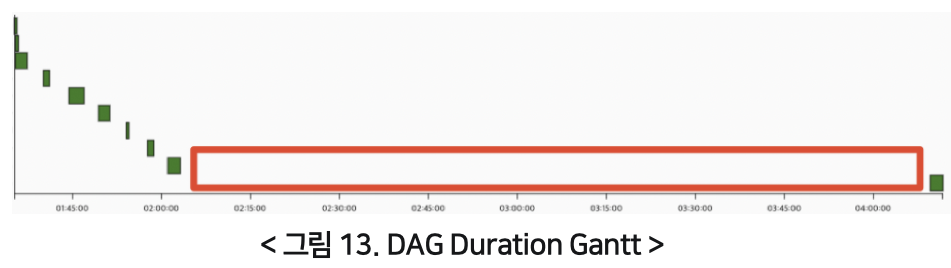
위 그래프를 보면 후순위 태스크가 많이 지연되고 있는 것을 확인할 수 있습니다. 위 그래프의 DAG뿐만 아니라 다른 DAG들도 전체적으로 후순위 태스크에서 대기가 길어지는 것을 확인했습니다. 이런 현상이 발생하는 이유는 태스크의 우선순위 때문입니다. Airflow에선 태스크의 우선순위를 지정할 수 있습니다. 지정 방법으로는 DOWNSTREAM과 UPSTREAM, ABSOLUTE의 세 가지 방법이 있습니다. 아래 코드는 태스크의 우선순위를 지정하는 코드로 weight_rule에 따라 태스크의 우선순위를 지정합니다. 디폴트 값이 DOWNSTREAM이기 때문에 후순위 태스크일수록 우선순위가 낮아집니다. 동시에 여러 DAG가 실행되고 있다고 가정했을 때, 높은 우선순위를 할당받은 각 DAG의 선순위 태스크들이 완료되지 못하고 지연되면, 우선순위가 낮은 후순위 태스크는 더더욱 지연되는 것이라고 보시면 되겠습니다.
class BaseOperator(LoggingMixin)
def priority_weight_total(self):
if self.weight_rule == WeightRule.ABSOLUTE:
return self.priority_weight
elif self.weight_rule == WeightRule.DOWNSTREAM:
upstream = False
elif self.weight_rule == WeightRule.UPSTREAM:
upstream = True
else:
upstream = False
return self.priority_weight + sum(
map(lambda task_id: self._dag.task_dict[task_id].priority_weight,
self.get_flat_relative_ids(upstream=upstream))
)
이 문제를 개선하기 위해 저희는 디폴트 weight_rule를 ABSOLUTE로 변경해 모두 공평하게 우선순위를 할당받도록 조정했습니다. 그 결과는 아래 그림 14와 같은데요. 후순위 태스크가 지연되는 현상은 개선됐지만 모든 태스크의 우선순위가 공평하게 1로 적용되면서 전체적으로 태스크 간에 지연이 발생하는 현상은 개선되지 않았습니다.

이를 해결하기 위해 Kubernetes의 POD 실행 상황을 모니터링했습니다. 그 결과 새벽 배치 작업 중 태스크 실행 수가 많은 경우에 특정 Kubernetes 워커 노드로 POD가 쏠려서 할당되는 현상을 발견했습니다. 아래 그림 15를 보시면 대부분의 POD가 1502 노드로 할당된 것을 확인할 수 있습니다.
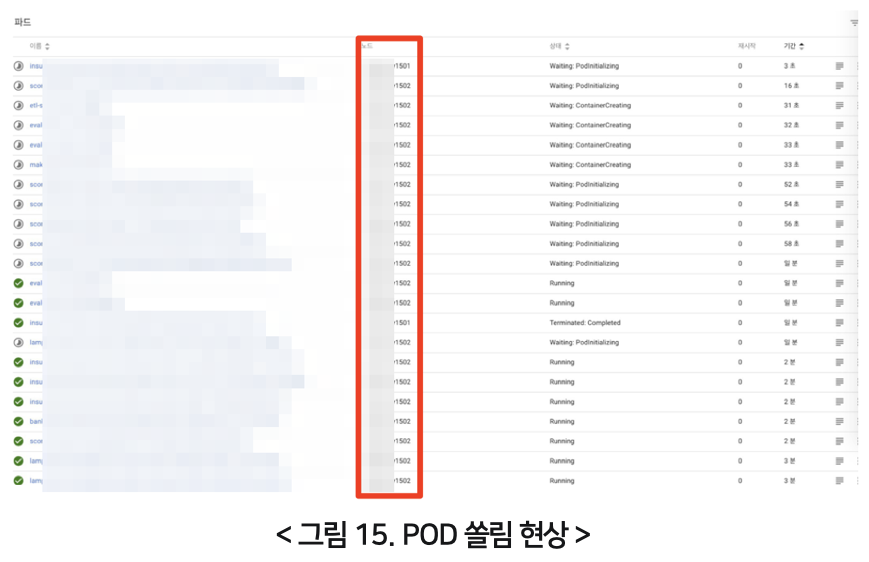
별도로 affinity 설정을 하지 않았는데도 이러한 현상이 발생한 이유는 Kubernetes scheduling policies 때문입니다. Airflow 1.10.12 기준으로 워커 POD 생성 시 별도 자원(CPU, 메모리)을 지정하지 않고 있습니다. 이 때문에 Kubertnetes 가용 환경에 따라 POD를 특정 노드에만 할당하는 경우가 발생할 수 있습니다. 이렇게 특정 노드에 POD 생성 요청이 몰리면서 Airflow 워커 POD와 태스크 POD 생성 및 수행이 지연되고, 그에 따라 전체적인 성능이 저하됐습니다. 이런 현상을 개선하기 위해서 아래 코드와 같이 airflow.cfg에 Airflow 워커 리소스 설정을 추가했습니다.
airflow.cfg
# Airflow Worker resoruce configuration
worker_request_cpu = {{ .Values.resource.worker.request_cpu }}
worker_request_memory = {{ .Values.resource.worker.request_memory }}
worker_limit_cpu = {{ .Values.resource.worker.limit_cpu }}
worker_limit_memory = {{ .Values.resource.worker.limit_memory }}또한 WorkerConfiguration 클래스에서 Airflow 워커 POD를 정의할 때 설정에서 읽은 리소스 정보를 이용해 워커 POD를 생성하도록 수정했습니다.
class WorkerConfiguration(LoggingMixin)
def as_pod(self):
"""Creates POD."""
if self.kube_config.pod_template_file:
return PodGenerator(pod_template_file=self.kube_config.pod_template_file).gen_pod()
resources = Resources(
request_memory=self.kube_config.worker_request_memory,
request_cpu=self.kube_config.worker_request_cpu,
limit_memory=self.kube_config.worker_limit_memory,
limit_cpu=self.kube_config.worker_limit_cpu
)
pod = PodGenerator(
resource=resources,
image=self.kube_config.kube_image,
image_pull_policy=self.kube_config.kube_image_pull_policy or 'IfNotPresent',
image_pull_secrets=self.kube_config.image_pull_secrets,
volumes=self._get_volumes(),
volume_mounts=self._get_volume_mounts(),
init_containers=self._get_init_containers(),
labels=self.kube_config.kube_labels,
annotations=self.kube_config.kube_annotations,
affinity=self.kube_config.kube_affinity,
tolerations=self.kube_config.kube_tolerations,
envs=self._get_environment(),
node_selectors=self.kube_config.kube_node_selectors,
service_account_name=self.kube_config.worker_service_account_name or 'default',
restart_policy='Never'
).gen_pod()
pod.spec.containers[0].env_from = pod.spec.containers[0].env_from or []
pod.spec.containers[0].env_from.extend(self._get_env_from())
pod.spec.security_context = self._get_security_context()
return append_to_pod(pod, self._get_secrets())
그 결과 Airflow 워커 POD가 모든 Kubernets 워커 노드로 적절하게 분산되어 실행됐고, 아래 그림 16처럼 전체적으로 Airflow DAG Duration 성능을 개선할 수 있었습니다.

Apache Airflow 오픈소스 수정
아래는 저희 팀에서 Airflow 오픈소스 코드를 수정한 내용입니다. 저희 상황에 맞게 수정한 내용이라 코드 기반으로는 설명하지 않고, 어떤 이유로 수정했는지를 중심으로 말씀드리겠습니다.
- UTC 타임존 → KST 타임존
- 최근 버전에는 이 기능이 적용된 것 같습니다. 개발하다 보면 UTC 기본 타임존을 신경 쓰느라 여러 가지 실수가 발생하는데요. 이런 불편함을 개선하기 위해 Airflow의 모든 시간 계산이 한국 시간을 기준으로 운영되도록 수정했습니다.
- Kubernetes 워커 SSH 시크릿(secret) 설정
- 내부적으로 WorkerConfiguration 클래스에서 SSH 시크릿 볼륨 명과 Git known 호스트 정보, SSH 시크릿 키에 관한 내용이 상수로 지정되어 있습니다. 이를 저희 상황에 맞게 구성하기 위해 수정해서 사용하고 있습니다.
- PodGenerator 복수 명령어
- Airflow POD 생성 시 컨테이너에서 실행되는 인수로 리스트 형태의 파라미터를 받는 것이 가능했지만 명령어는 불가능했습니다. 이에 명령어도 리스트 형태로 받을 수 있도록 변경했습니다. 이 부분은 1.10.11 버전에서 패치됐습니다.
- Kubernetes POD 명 밑줄(underscore)
- KubernetesPodOperator 생성 시 개발자가 지정한 이름으로 POD가 생성되는데요. 이름에 밑줄이 들어가 있을 경우 예외(exception)가 발생해 치환 처리했습니다.
- DAG LIKE 검색 기능
- 운영하는 DAG가 많다 보니 검색 편의를 위해 LIKE 검색 기능을 수정했습니다.
운영 사례
기본적으로 Hadoop 기반의 데이터 플랫폼 환경을 운영하고 있기 때문에 이에 맞는 운영 사례를 공유하겠습니다. 현재 위에서 설명한 바와 같이 Kubernetes Executor 환경에서 KubernetesPodOperator를 이용해 Airflow를 운영하고 있습니다. 이에 따라 필요한 환경의 Docker 이미지를 사전에 만들어 두고 필요한 비즈니스 요건에 따라 Docker 이미지를 선택해 Airflow를 통해 실행하고 있습니다. 추가로 비즈니스 요건에 따라 만들어진 Docker 이미지가 실행되면 각 사용자에 맞는 Kerberos 인증을 공통으로 수행하도록 구성했습니다. 금융 데이터 플랫폼을 다루고 있다 보니 Secure Hadoop 클러스터 형태로 운영하고 있고 이에 따라 인증 및 권한 처리를 먼저 수행합니다. 이 처리가 완료되면 실제 비즈니스 요건에 맞는 작업을 수행합니다.
Java 혹은 Scala Spark 애플리케이션
아래 코드는 저희가 실제로 사용하는 Spark 애플리케이션의 KubernetesPodOperator 예시입니다. 저희는 SparkSubmitCommandTool 클래스에서 spark-submit 명령어 문자열을 만들고 이를 spark_client_1:1.0 이미지에 인수 형태로 전달해 실행합니다. 추가로, 필요에 따라 실행되는 드라이버 POD의 리소스를 직접 지정해 사용하기도 합니다.
spark_submit_sample = KubernetesPodOperator(
task_id='spark_submit_sample',
name='spark_submit_sample',
namespace='airflow',
image='spark_client_1:1.0',
arguments=["spark", SparkSubmitCommandTool.getCommand(SparkSubmitCommandTool(),
class_name='com.linecorp.spark.application.SampleApplication',
master='yarn',
keytab='user.keytab',
principal='user@FINANCIAL.HADOOP.DATA.COM',
deploy_mode='cluster',
driver_cores='1',
driver_memory='2g',
executor_cores='2',
executor_memory='4',
num_executors='5',
jars='hdfs://line_financial/spark_app/spark-sample.jar',
args=[execution_date],
conf=["spark.dynamicAllocation.enabled=true",
"spark.shuffle.service.enabled=true",
"spark.dynamicAllocation.minExecutors=5",
"spark.dynamicAllocation.maxExecutors=10",
"spark.rpc.message.maxSize=256"])],
resources={ 'request_cpu': '1000m',
'request_memory': '2048Mi',
'limit_cpu': '2000m',
'limit_memory': '4095Mi'},
hostnetwork=True,
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=180,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
dag=dag)PySpark 애플리케이션
아래 코드는 PySpark 사용 예시입니다. 현재 저희는 Java Spark 애플리케이션을 PySpark로 전환하는 작업을 진행하고 있습니다. Spark 프로젝트를 Airflow 프로젝트와 병합하여 개발 생산성을 향상시키기 위해서입니다. 아래 예시 코드를 보면 Airflow 프로젝트 내에서 PySpark 애플리케이션과 Airflow DAG 개발을 같이 진행할 수 있으며, KubernetesPodOperator는 pyspark_sample.py라는 스크립트 파일을 실행 시점에 읽어서 실행하는 구조입니다. 즉 pyspark_sample.py 스크립트와 pyspark_dag.py 스크립트는 같은 프로젝트에 존재하게 됩니다.
pyspark_submit_sample = KubernetesPodOperator(
task_id='pyspark_submit_sample',
name='pyspark_submit_sample',
namespace='airflow',
image='spark_client_1:1.0',
arguments=["pyspark","pyspark_sample.py"],
hostnetwork=True,
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag
)Hadoop 제어
아래 코드는 Hadoop 제어 관련 작업입니다. 저희는 distcp와 mkdir, test, rm, ls 등과 같은 명령어를 아래와 같은 형식으로 생성해 필요할 때 실행하고 있습니다.
hadoop_distcp_sample = KubernetesPodOperator(
task_id='hadoop_distcp_sample',
name='hadoop_distcp_sample',
namespace='airflow',
image='hadoop_client_1:1.0',
arguments=["hadoop", HadoopDistcpCommandTool.getCommand(HadoopDistcpCommandTool(),
src='src_path',
dst='dst_path',
options={
'-Dmapred.job.queue.name=root.default',
'-overwrite',
'-strategy dynamic'},
args={
'YESTERDAY': execution_date})],
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag)Python 애플리케이션
아래 코드는 Python 애플리케이션 실행 부분입니다. 개발자는 원하는 Python 버전에 원하는 라이브러리가 설치된 이미지에서 애플리케이션을 실행합니다. PySpark과 같은 원리로 Airflow 프로젝트에 있는 Python 애플리케이션 스크립트를 원하는 컨테이너 POD에서 실행하는 구조입니다.
python2_app_sample = KubernetesPodOperator(
task_id='python2_app_sample',
name='python2_app_sample',
namespace='airflow',
image='python2:1.0',
arguments=["python2","python2_app_sample.py"],
hostnetwork=True,
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag
)
python3_app_sample = KubernetesPodOperator(
task_id='python3_app_sample',
name='python3_app_sample',
namespace='airflow',
image='python3:1.0',
arguments=["python2","python3_app_sample.py"],
hostnetwork=True,
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag
)Hive 혹은 Beeline
아래 코드는 Hive 쿼리 실행 예시입니다. 저희는 Hive와 Beeline 명령어를 상황에 맞게 실행하고 있습니다. BeelineCommandTool의 filename 파라미터인 SQL 파일을 실제로 -f 옵션으로 지정해 쿼리를 실행하는 구조입니다.
beeline_sample = KubernetesPodOperator(
task_id='beeline_sample',
name='beeline_sample',
namespace='airflow',
image='hive_clinet:1.0',
arguments=["beeline",BeelineCommandTool.getCommand(BeelineCommandTool(),
servicename='fintech_service',
filename='hv_daily_sample.sql',
conn_id='jdbc_conn_id',
args={
'YESTERDAY': execution_date})],
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag)Sqoop
아래 코드는 Sqoop 명령어 실행 예시입니다. 기본적인 구조는 앞서 설명드린 예시들과 유사합니다. Sqoop의 경우 filename 파라미터에 Sqoop을 통해 수집할 DB와 테이블, 칼럼, 맵리듀스(MapReduce) 정보를 정의해 놓은 YAML 파일을 지정하고 해당 YAML 파일의 정보를 이용해 Sqoop 명령어를 생성하고 실행합니다.
sqoop_sample = KubernetesPodOperator(
task_id='sqoop_sample',
name='sqoop_sample',
namespace='airflow',
image='sqoop_client:1.0',
arguments=["sqoop", ScoopCommandTool.getCommand(ScoopCommandTool(),
servicename='fintech_service',
filename='sqoop_info_definition.yml',
args={
'YESTERDAY': execution_date,
'FROM': from_date,
'TO': to_date})],
hostnetwork=True,
in_cluster=True,
is_delete_operator_pod=True,
startup_timeout_seconds=300,
execution_timeout=timedelta(minutes=120),
retries=2,
retry_delay=timedelta(minutes=2),
image_pull_policy='IfNotPresent',
service_account_name='airflow',
on_retry_callback=SlackTool.make_handler(slack_channel,
color='warning',
message="Retry Task"),
dag=dag)마치며
두 번에 걸쳐 설명드린 바와 같이 저희는 Kubernetes를 이용해 데이터 엔지니어링을 진행하고 있으며 조금씩 ML(Machine Learning) DevOps 방향으로 확장해 나가고 있습니다. 처음 프로젝트를 시작했을 때는 직접 네이티브 Kubernetes 환경을 구축하고 리서치를 진행하는 비용 때문에 많은 자원을 투입해야 했지만, 현재는 전체적으로 개발 생산성이 향상되고 유지 보수 비용이 감소하고 있어서 Kubernetes로 전환하길 잘했다고 생각하고 있습니다. 혹시 저희와 유사한 환경에서 작업하고 계신다면 한 번쯤 고려해 봐도 나쁘지 않을 것이라고 생각합니다. 긴 글 읽어주셔서 감사합니다.