
지난 "Spark, Mesos, Zeppelin, HDFS를 활용한 대용량 보안 데이터 분석" 글에 이어, 이번에는 LINE 게임 보안개발실에서 개발한, AirArmor1로부터 발생되는 탐지 정보를 실시간에 가까운 처리를 하기 위해 사용한 클라우드 기술과 스트리밍 처리 기법을 소개합니다.
1: LINE Game 보안개발실에서 개발하여 LINE 게임(LINE Game)에 적용 중인 모바일 게임보안 솔루션의 명칭
AirBorne DataCenter & Mesos (with DC/OS)
Apache Mesos를 기반으로 보안 데이터를 분석하는 전체적인 구성을 AirBorne DataCenter라고 부르고 있습니다. 구성에는 Big Data를 처리하기 위한 Kafka, Spark, Elasticsearch, Hadoop, Zeppelin, Spring 등의 오픈소스를 포함하고 있습니다.
도입 배경
2015년 초에 시작된 AirBorne은 Mesos 기반의 Spark를 주로 사용하며, 조회 및 시각화를 위해 Zeppelin과 Spring을 사용하여 대량의 데이터를 빠르게 조회하는 목적으로 만들었습니다. DBMS로 처리하기 어려운 대량의 데이터를 처리하는 용도, JSON 형식의 대량의 DB 데이터와 로그 데이터를 처리하는 용도 등 불가능하거나 어려웠던 부분을 해결할 수 있었고, 점차 사용성 및 분석 유형이 증가하여 물리적인 node의 확장과 각 endpoint의 모니터링과 같은 자동화의 필요성, 편리한 사용성, 안정성 등의 요구사항이 지속적으로 발생하였습니다.
특히, 주기적인 데이터의 처리 외에도 실시간 데이터 처리를 통해 즉각적인 알림을 받고 변화량을 관제할 수 있는 형태의 업무의 필요성이 발생하였습니다.
이러한 업무 환경의 변화로 AirBorne DataCenter의 구조를 추가 설계하였고 실시간 처리에 대한 새로운 영역을 추가하게 되었습니다.
Apache Mesos는 다수의 물리적인 node의 자원을 논리적으로 하나의 자원으로 제공할 수 있도록 framework를 제공합니다. Kafka, Elasticsearch와 같이 고정된 자원을 사용하는 경우와 Spark Executor와 같이 여유 자원을 순간적으로 최대한 활용하는 등 자원의 낭비를 줄이고 효율적으로 사용할 수 있도록 할 수 있습니다. Constraint와 Role, Quota 등의 설정으로 자원 예약에 대한 다양한 방법을 제공할 수 있습니다.
DC/OS는 Mesos framework를 지원하는 오픈소스 패키지를 제공하고 있습니다. Kafka, Elasticsearch, MySQL, Spark, Zeppelin 등 다양한 오픈소스가 패키지로 지원됩니다. 기본적으로 패키지의 설치와 운영을 위한 툴, 그리고 장애극복, 유연한 수평 확장 등의 추가적인 기능을 포함합니다. 일정 기간의 테스트와 시험 운영을 통해 사용성에 대한 검증을 마치고 일부 영역에서 사용하고 있습니다.
구조
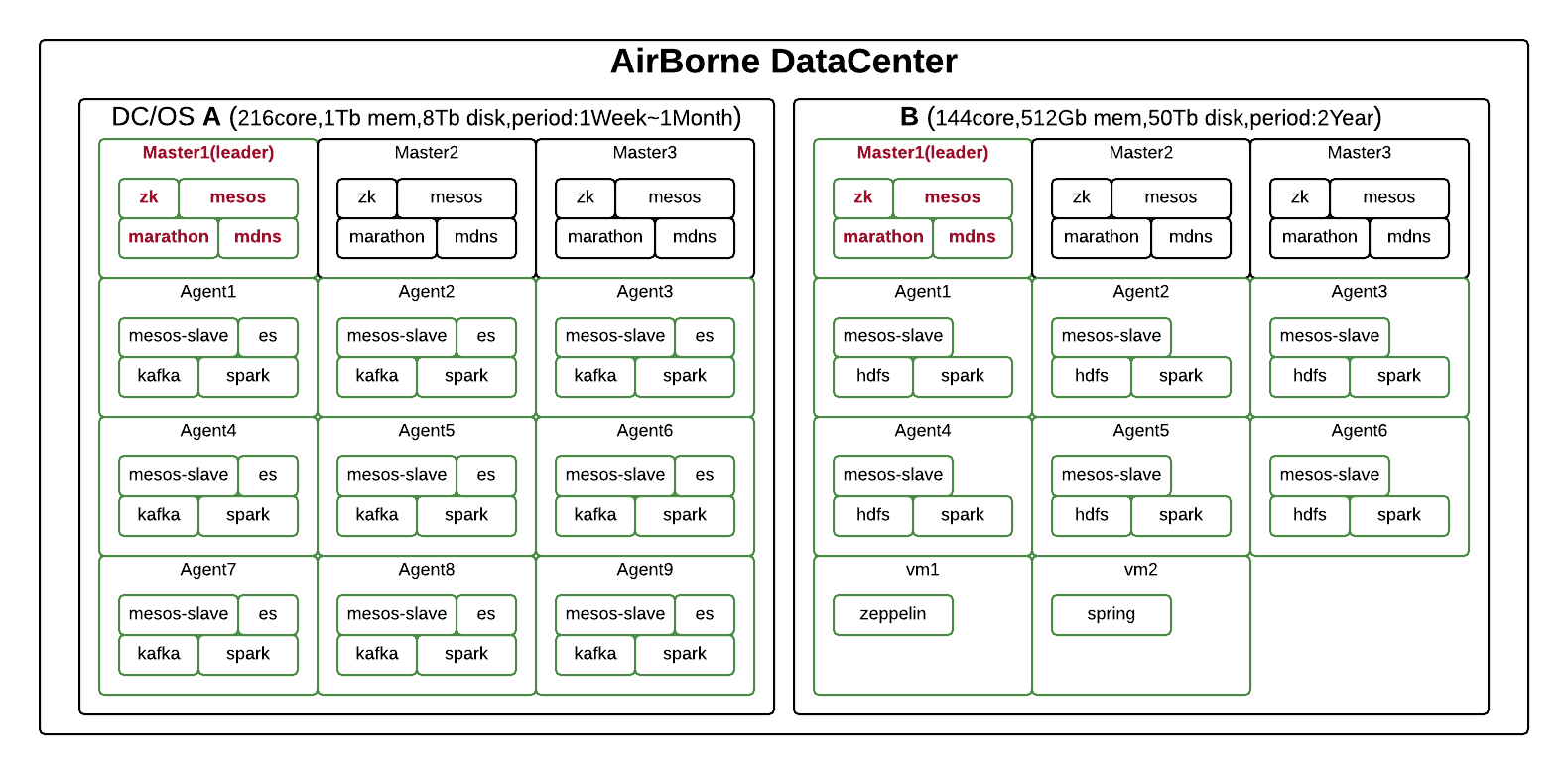
AirBorne DataCenter는 위 그림과 같이 구성하였으며 데이터 처리를 실시간과 비실시간으로 구분하고 있습니다. 데이터 처리에 있어서 자원을 예약하고 활용하는 방법과 대상이 되는 데이터의 보관 주기도 서로 다릅니다. 실시간 데이터 처리의 경우는 자원의 적당량을 고정적으로 예약하고 활용하는 방안이 필요하고, 비실시간 데이터 처리의 경우는 장기간의 데이터를 보관하는 시스템에서 여분의 CPU와 메모리 자원을 활용하도록 설계하였습니다.
DC/OS는 위와 같은 환경을 빠르게 구축할 수 있다는 장점이 있었지만, AirBorne DataCenter의 두 개의 영역 DC/OS A와 DC/OS B를 하나로 운영하기에는 디자인 컨셉 상 이 솔루션과 적합하지 않은 부분이 있었습니다. 이번 프로젝트에서는 실시간 데이터 처리 환경의 빠른 구축과, 유연한 확장, 모니터링의 자동화 부분 등에 대해서는 DC/OS의 역할이 컸습니다. 향후에는 자체 환경에 적합한, Mesos를 기반으로 하는 독자적인 개발 프로젝트를 준비할 예정입니다.
Big Data를 처리하기 위한 패키지로 구성된 클라우드 환경은 여러 명의 Multi User를 위한 시스템보다는 여분의 자원을 큰 작업에 활용하거나 고정된 자원을 작은 작업에 예약해두고 이런 자원의 조작을 자유롭게 할 수 있도록 한다는 점에서 일반 클라우드 환경과는 많이 다르다고 생각합니다. 실제로 실시간 처리의 경우는 대상이 1,000만 건이라고 해도 100개의 처리부로 병렬처리하면 1개의 처리부는 10만 건만을 담당하게 됩니다. 자원이 많은 큰 node를 사용하면 확장 시 자원이 남게 되지만, 적당한 자원을 가진 node를 사용하면 남는 자원을 최소화하면서 확장할 수 있습니다.
이렇듯 AirBorne DataCenter 구성에서 Mesos는 자원을 다양한 방법으로 예약해서 사용하는 데 중요한 역할을 하고 있습니다.
특징
AirBorne DataCenter는 다음과 같은 특징이 있습니다.
- Web UI를 통한 Cluster의 운영(패키지 설치, scale out)과 모니터링
- Mesos 기반의 다양한 Big Data 관련 오픈소스 패키지 지원
- 유연한 확장
- Quota, Constraint, Role의 설정에 따른 다양한 방법의 자원 예약
- OAuth를 통한 인증/인가 제공
- 장애극복
실시간 데이터 처리와 비실시간 데이터 처리의 비교
| DC/OS A | DC/OS B | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 용도 | 실시간 데이터 처리 | 비실시간 데이터 처리 | ||||||||||||||||||
| 성능 | 30만 EPS 처리 능력 | |||||||||||||||||||
| Mesos quota | Cluster:UNIQUE | |||||||||||||||||||
| Spark mode | Standalone mode | Mesos coarse mode | ||||||||||||||||||
| Business logic feature | ||||||||||||||||||||
| Tools | Zeppelin: data processing, view | |||||||||||||||||||
| 보안 업무 |
화면 소개
AirBorne DataCenter 화면에 대해 간단히 몇 가지 소개하겠습니다.
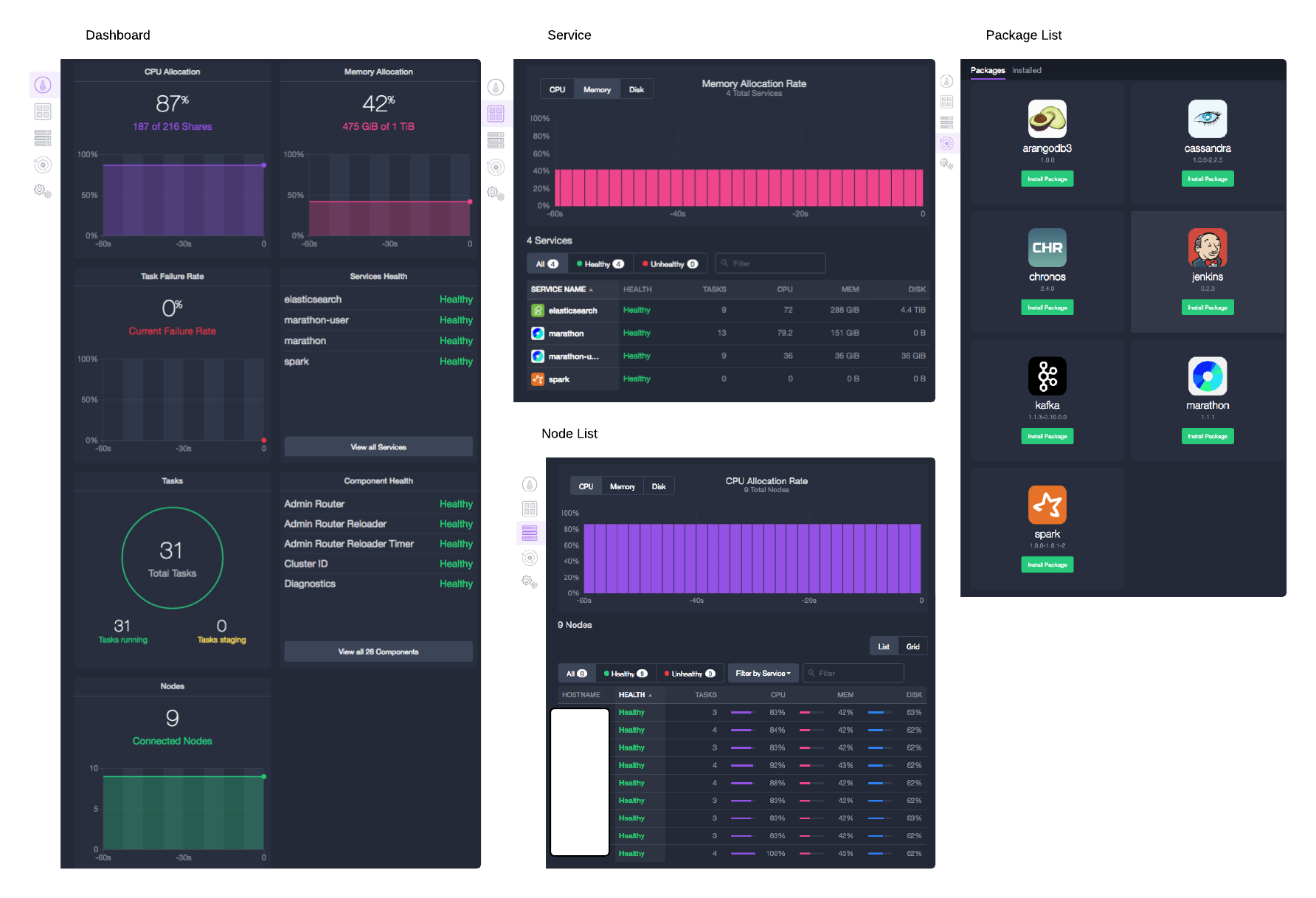
- DC/OS Dashboard에서는 Agent Node의 가용상태와 Health 정보를 확인할 수 있습니다.
- Service 화면에서는 기동 중인 각 서비스의 리소스 사용량과 Health 정보를 확인할 수 있습니다.
- Node List로는 각 Node의 여분의 리소스 및 전체 Node의 가용상태를 확인할 수 있습니다.
- Universe 화면에서는 제공되는 패키지 리스트를 확인할 수 있습니다.
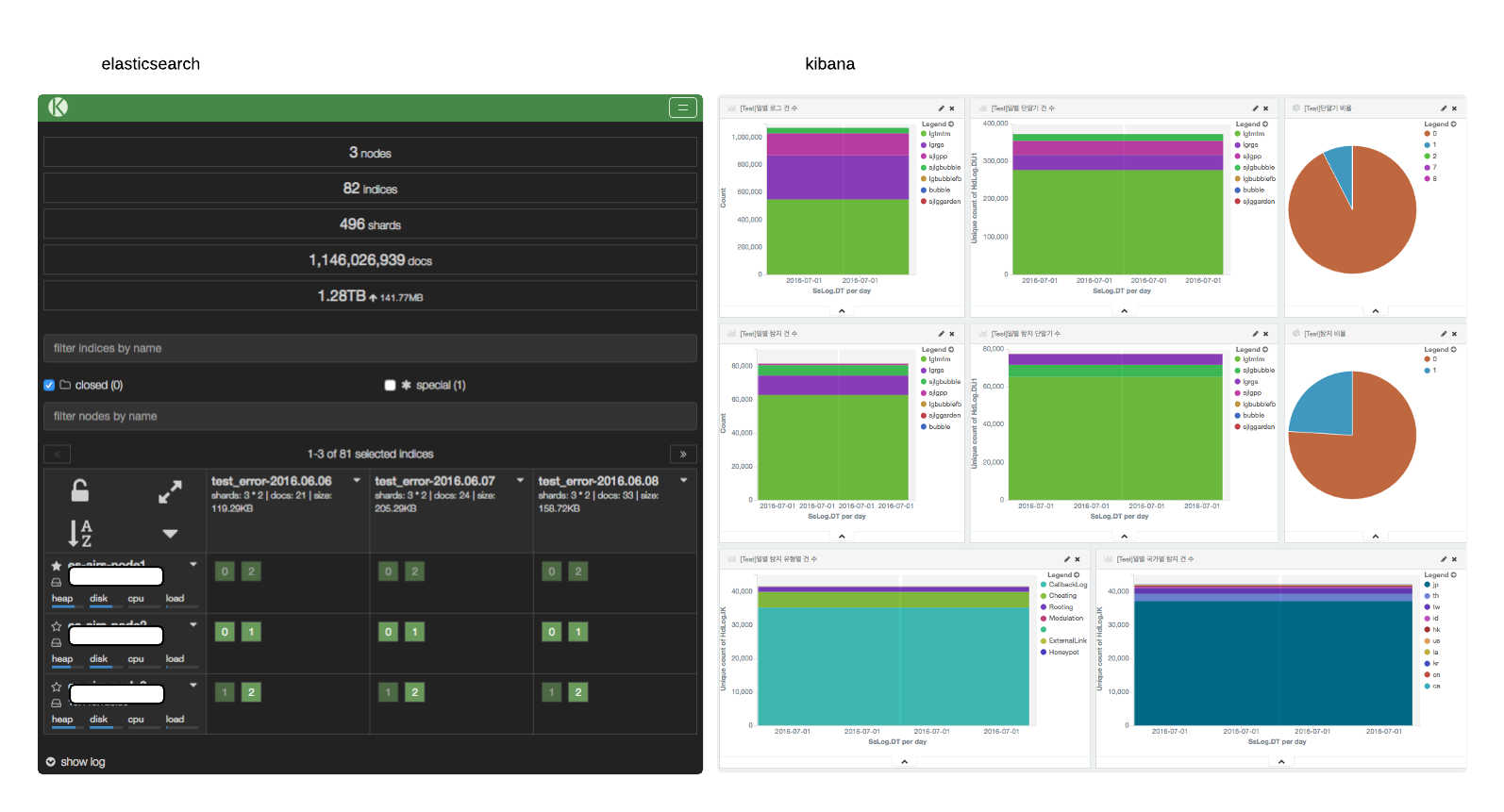
- Elasticsearch의 kopf 플러그인을 통해 각 node의 상태 정보를 확인할 수 있습니다.
- Kibana를 활용하여 요소별 dashboard를 구성하고 모니터링할 수도 있습니다.
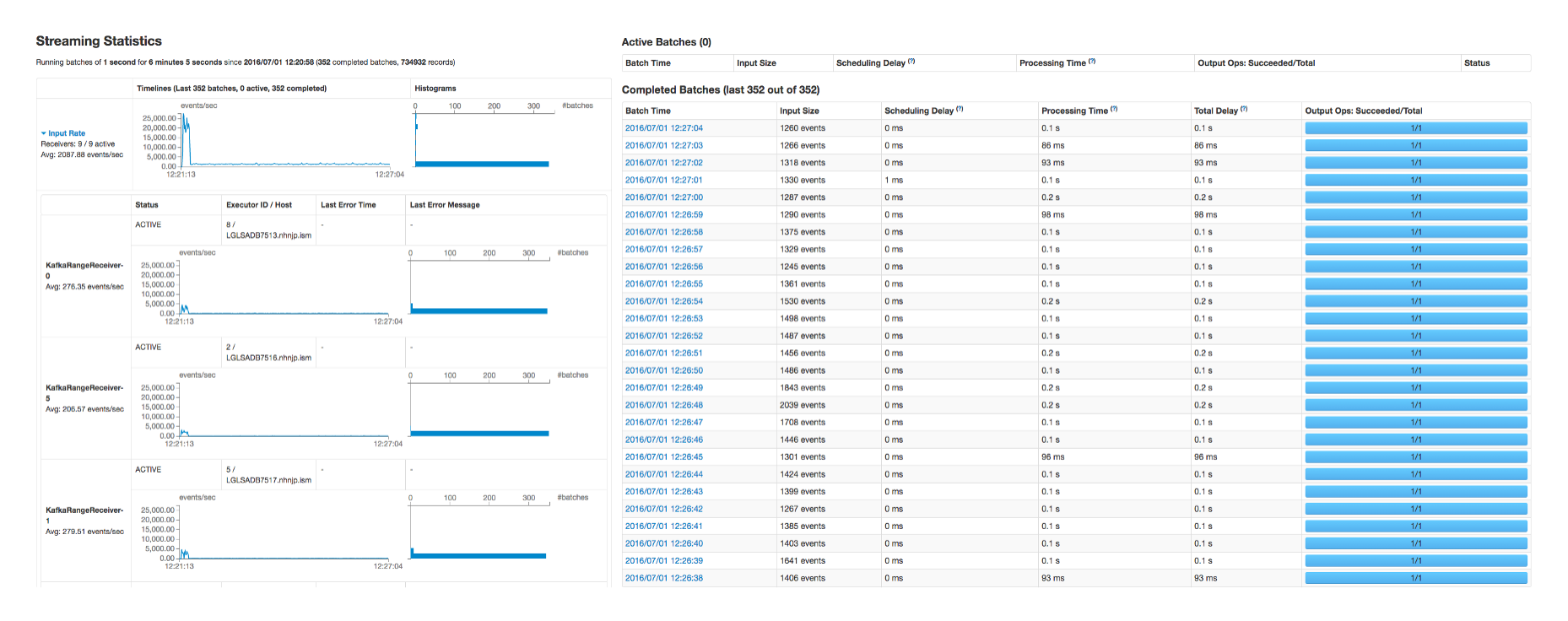
- Streaming Statistics는 Spark Streaming과 각각의 Task를 모니터링하고 디버깅할 수 있는 Spark의 Web UI입니다. Streaming의 지연 발생 시 또는 예외상황 발생 시 Web UI에서 제공하는 분산된 node의 예외 정보를 확인할 수 있습니다. 또한, task의 흐름이나 stage 단계를 시각적으로 표현하고 있어서, task 자체를 튜닝하는 용도로도 사용할 수 있습니다.
Near-Real-Time Security Log Analysis
이번 세션에서는 AirBorne Streaming 설계에 대해서 살펴보겠습니다.
구조
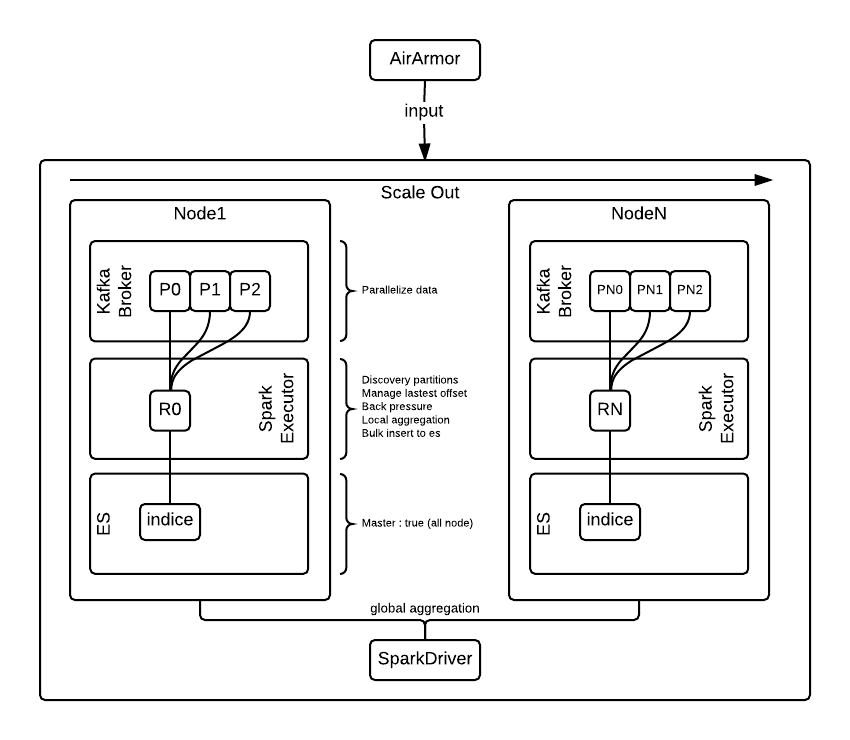
이 솔루션에서는 AirArmor로부터의 탐지 로그를 수집해서 transformation, action 등의 처리 후에 결과를 저장하며 Kibana, Zeppelin을 통해 모니터링 및 분석 작업을 합니다. 실시간 처리의 핵심요소로 각각의 node는 최대한의 성능을 얻기 위해 local aggregation과 write의 경우 local 통신을 하고, global aggregation은 node들의 결과를 driver에서 비동기로 merge해서 write하고 있습니다.
Kafka와 Elasticsearch는 장애에 대한 대비로 n개의 데이터를 복제하고 있고, node가 장애상황이 되더라도 신규 node를 투입하거나 node를 복구하면 자연스럽게 scale이 유지됩니다. 로그의 유입량 자체가 증가하는 경우(duration 1초가 processing time보다 큰 경우) scale out을 지향하며, 현재 구성으로 scale out에 소요되는 시간은 30분 미만으로 가능합니다. 향후에는 auto scale out, scale in 부분까지도 시도할 예정입니다.
AirBorne Streaming 설계
Kafka
Kafka는 대용량 실시간 로그에 특화된 분산 메시지 시스템으로 발행-구독(publish-subscribe) 모델을 기반으로 AirBorne에서 버퍼와 같은 역할을 합니다. Streaming에서는 정상적으로 처리한 마지막 offset을 배치할 때마다 ZooKeeper에 기록하도록 하여 데이터 유실을 방지하고 있습니다. 각각의 노드에 Kafka Broker를 1개 구성하였으며, 하나의 토픽에 n개의 파티션을 설정할 수 있습니다.
Kafka low level API를 통해 local Kafka broker에서 관리되는 파티션 정보를 획득하고 receiver는 해당 파티션에 연결됩니다. Spark에서 Kafka high level API를 사용할 때 처리되는 부분이지만, 성능 향상을 위해 이런 구성을 하게 되었습니다.
Spark Streaming
Kafka에 실시간으로 저장되어 있는 로그를 transformation, action 및 backup을 위해 Spark Streaming을 사용하고 있습니다.
Cluster 모드로 Standalone으로 동작하며, Mesos Endpoint인 reserve를 통해 node별 4 core, 4GB memory를 예약해두고 Mesos executor에 의해서 n개의 node에 해당 자원을 할당받고 있습니다. node별로는 scale out을 지향하지만, spark worker의 경우는 여유가 되는 CPU와 memory 자원만큼 scale up이 가능합니다. 이 부분은 상황에 따라 수치의 변경만으로도 배포될 수 있도록 설정되어 있습니다.
Spark worker에서 Kafka consumer 역할을 하는 receiver를 n개씩 생성하여, fetch message 작업을 병렬로 처리할 수 있습니다. Input이 되는 Kafka Broker와 Processing을 담당하는 Spark Worker, Output이 되는 Elasticsearch가 동일 노드에서 동작하기 때문에 locality가 우수하여 fetch message 작업 시간을 줄일 수 있습니다.
이러한 구성들은 duration 1초 내 처리를 보장하기 위해 자체적으로 고안한 방법입니다.
주요 설정
spark.streaming.backpressure.enabled=true #task의 지연 시 pid 조절
spark.serializer=org.apache.spark.serializer.KryoSerializer #serializer
spark.scheduler.mode=FAIR
Elasticsearch
저장된 보안 로그의 분석 업무는 검색과 간단한 통계를 구성해 보는 작업의 연속입니다.
Elasticsearch는 all master mode로 n개의 복제 데이터를 유지하도록 하고 있습니다. Daily로 indice를 생성하고 D-10일의 과거 데이터는 HDFS의 데이터를 Spark와 Zeppelin을 통해서 사용합니다. 각각의 노드에 data node를 구성하여 Elasticsearch에 Document(processed by Spark Streaming)를 저장할 때에도 네트워크 비용이 발생하지 않습니다. 각 노드에서 자신이 생성한 RDD를 Local Elasticsearch에 저장하는 것입니다. 기존 AirBorne 시스템을 운영할 때에 가장 지연이 많이 발생했던 부분입니다.
주요 설정
node.master=true #all node, node의 장애 또는 변경작업 시 모든 node가 master 역할을 수행
node.data=true
설계 장점
AirBorne DataCenter의 이점은 효율적인 리소스 운영, 성능, 확장성입니다.
- 효율적인 리소스 운영
- 일반적으로 node는 하나의 목적으로 운영되어 왔습니다. Big Data의 특성 상 필요할 때 여분의 자원을 모두 사용해야만 처리 능력을 극대화할 수 있습니다. Mesos의 기본 컨셉에도 해당되는 부분이며, 저희가 추구하는 목적에도 node의 여분의 자원을 최대한 활용하여 데이터를 처리하고 있습니다.
- 성능
- 시스템, OS, 오픈소스 패키지 등 어떤 구성을 사용하느냐에 따라 성능에 많은 영향을 주게 됩니다. Kafka, Elasticsearch, Cassandra, HDFS와 같은 오픈소스를 채택한 이유에도 포함되는 부분이지만, 기본적으로 데이터는 n개 이상 복제본을 가지고 있고 하나의 node가 장애인 상황에서도 데이터의 유실을 방지하고 서비스에 사용되는 데이터에도 영향이 없도록 하고 있습니다. 특히, Kafka와 Spark Streaming, Elasticsearch를 동일한 node에서 local로 통신하도록 구성한 부분은 locality 면에서 성능을 최대한 발휘하도록 고안한 방안입니다. 이 구성은 필요할 때마다 쉽게 scale out할 수 있고, 장애상황에서도 자동 복구가 될 수 있습니다.
- 확장성
- AirArmor는 Mobile 보안솔루션으로 LINE 주요 게임 보호에 확대 적용되는 상황이라, 로그의 양이 급속히 증가하고 있습니다. 보안 데이터 운영을 위해 투입된 인적 리소스가 적다보니 node를 유연하게 확장해 나가는 것은 AirBorne에서 점점 더 주요한 기능이 되고 있습니다. 현재는 최대 30분 내에 필요 node를 확장할 수 있는 상태를 확보하고 있습니다.
앞으로의 계획
AirBorne DataCenter의 이후의 진행 계획은 크게 다음 4가지입니다.
- AT 3.0
- Abuser Tracker 3.02을 계획 중이며, AirBorne에서 발생하는 보안 탐지 분석 결과의 실시간 현황을 서비스할 계획입니다.
- DNN for AirBorne
- Streaming 단계에 Abnormal을 탐지하기 위해 DNN(Deep Neural Network) 서비스를 적용할 계획입니다. 일부 게임로그를 사용하여 6개월 전부터 검증을 하고 있고, 서비스 적용을 통해 정확도를 확보할 계획입니다.
- AirBorne Universe Repository
- Scheduler, executor를 개발하여 AirBorne에서 사용 중인 패키지를 내부 용도에 맞게 개발하고 DC/OS의 Universe Repository로 내부에 제공할 수 있도록 할 계획입니다.
- AirBorne 2.0
- Mesos framework를 사용하는 Big Data 패키지 운영, 모니터링, 배포 환경을 자체 개발할 계획입니다. DC/OS를 대체할 예정이며, 회사 내부 환경에 맞도록 자체 구축할 예정입니다.
2: LINE 게임(LINE Game) 전체의 Abuser 추적과 관리
이 글은 LINE 게임 보안개발실에서 재직 중인 오왕진님이 작성했습니다. 오왕진님은 게임 보안 서버를 개발하며 문제를 해결하는 과정을 즐깁니다.
트위터에 의견을 남겨 주세요! LINE Security Twitter