
Last time I posted an article titled, "Analyzing Large Amounts of Security Data with Spark, Mesos, Zeppelin, and HDFS." Today I will introduce how LINE applies cloud and stream processing technology to perform near-real-time processing on game data detected by AirArmor1.
1: AirArmor is a security solution for mobile games developed by LINE.
AirBorne DataCenter & Mesos (with DC/OS)
To analyze security data, we built our own system named AirBorne DataCenter. The system uses Apache Mesos as its base framework. And to process big data efficiently, the system implements open source components such as Kafka, Spark, Elasticsearch, Hadoop, Zeppelin, and Spring.
Background
Launched in early 2015, AirBorne runs Spark on a Mesos framework, along with other tools like Zeppelin and Spring for querying and visualization. The goal of AirBorne is to query large amounts of data as quickly as possible. Traditional DBMS are not fit for large amounts of data. Likewise, it was difficult, or even impossible, to process large amounts of DB data or log data in JSON format. With AirBorne, we were able to overcome such difficulties. Also, as usability and analysis capability gradually evolved, it became necessary to automate the way we scale out physical nodes or monitor endpoints. The demand for enhanced usability and stability increased as well.
Most importantly, in addition to analyzing data on a regular basis, we wanted to process data in real-time, receive alerts immediately, and be able to monitor and control changes accordingly.
These new circumstances ultimately led us to re-design the existing AirBorne DataCenter and apply real-time processing.
Apache Mesos provides a framework where resources across multiple physical nodes can be combined and offered as a single logical resource. It can instantly allocate more resources on Spark executors when necessary while keeping the fixed amount of resources reserved for Kafka and Elasticsearch. This means we can improve the resource utilization by using otherwise idle resources. Also, Apache Mesos provides various ways to schedule resources using features such as Constraint, Role, and Quota.
DC/OS is a platform consisting of open source packages for the Mesos framework. Supported packages include Kafka, Elasticsearch, MySQL, Spark, Zeppelin, and more. You can easily install these packages and use various running tools that come with the platform. It has features for fault tolerance and horizontal scaling as well. We checked whether it would fit our purposes by conducting some trial tests and decided to bring it into our system.
Structure
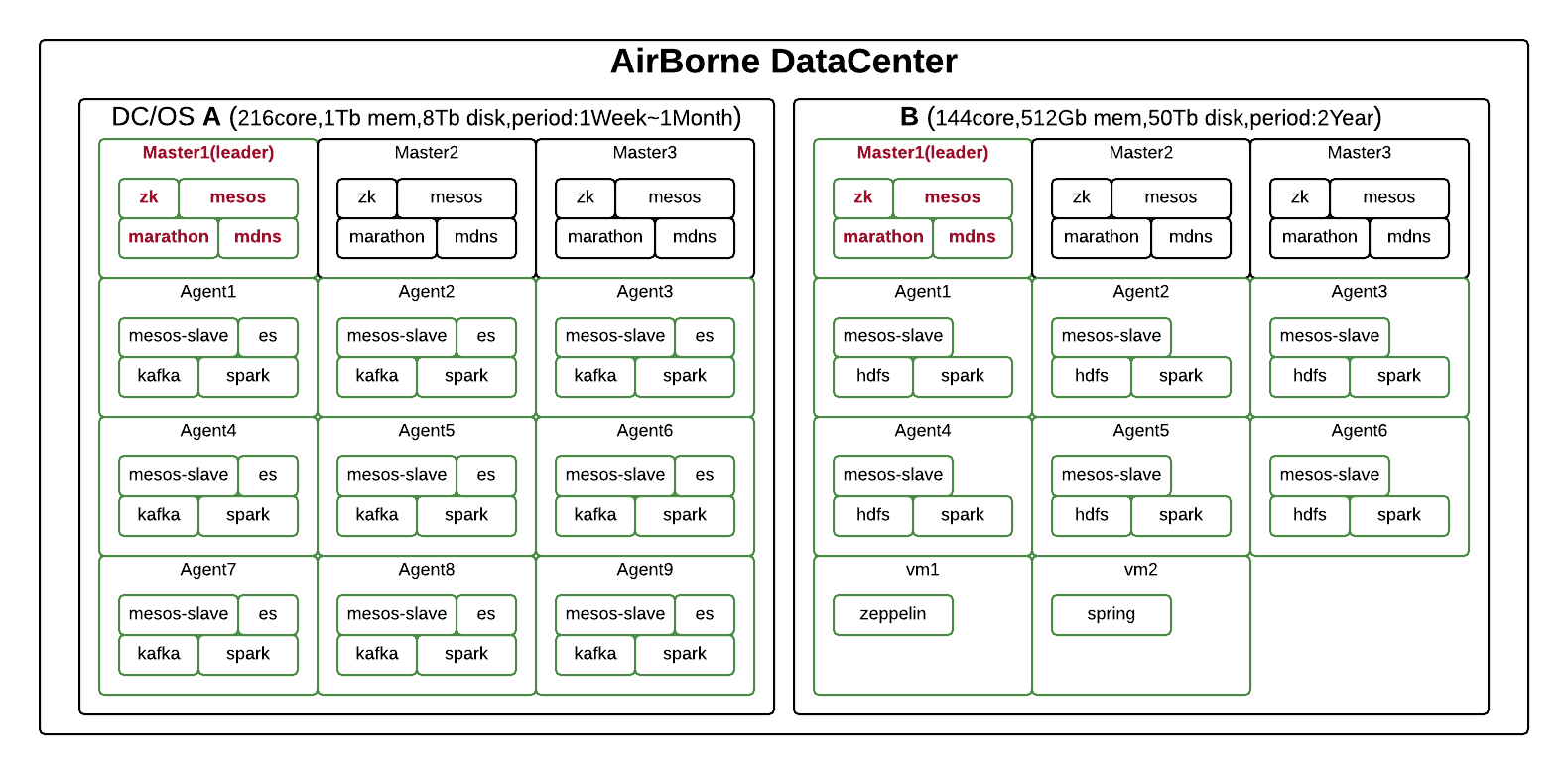
The above figure depicts how AirBorne DataCenter is structured. We are taking a mixed approach to data processing: real-time and non-real-time. This distinction determines how resources should be scheduled and utilized, or how data retention cycle should be managed. For real-time processing, we've implemented a static resource scheduling technique with which a certain portion of resources can be reserved. For non-real-time processing, on the other hand, we leverage unused system resources, that is, CPU or memory resources sitting idle in the storage systems for long-term data retention.
The structure of AirBorne DataCenter is separated into two parts, DC/OS A and DC/OS B. Although DC/OS is powerful in that it helps you build an environment quickly, the solution is not fully fit for running our two-part system. Having said that, DC/OS did play a part in building a system capable of real-time data processing, flexible scaling, and automated monitoring. For our next step, we plan to launch a new development project to build our own Mesos-based system completely customized for the LINE environment.
When setting up a cloud environment for big data processing, we allow high-volume tasks to use free resources while allocating fixed resources on small tasks. The fact that resources can be run dynamically is what makes it different from an ordinary cloud system, which is more focused on servicing a large number of users. Let's assume you are processing 10 million records of data in real-time. If you run 100 processing units, it means only 100,000 records need to be processed by each unit. If you scale out a node with a large resource pool, the node may become under-utilized as some resources will be left idle. But if the node has a moderate size of resources, the remaining resources will be the slightest.
As you can see, Mesos plays a key role in AirBorne DataCenter by allowing the system to schedule or utilize resources more flexibly.
Features
AirBorne DataCenter provides diverse features as follows.
- Offers a web UI to manage (install packages, scale out) and monitor clusters
- Supports various Mesos-based open source packages for big data
- Supports flexible scalability
- Supports resource scheduling in various ways by configuring Quota, Constraint, and Role
- Supports OAuth authorization and verification
- Provides failure recovery
Comparison of data processing in real-time and non-real-time
| DC/OS A | DC/OS B | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Purpose | Real-time data processing | Non-real-time data processing | ||||||||||||||||||
| Performance | 300,000 EPS capacity |
|
||||||||||||||||||
| Mesos quota | Cluster:UNIQUE |
|
||||||||||||||||||
| Spark mode | Standalone mode | Mesos coarse mode | ||||||||||||||||||
| Business logic feature |
|
|
||||||||||||||||||
| Tools |
|
Zeppelin: data processing, view | ||||||||||||||||||
| Security tasks |
|
|
A brief look at AirBorne DataCenter
Let me show you what AirBorne DataCenter looks like.
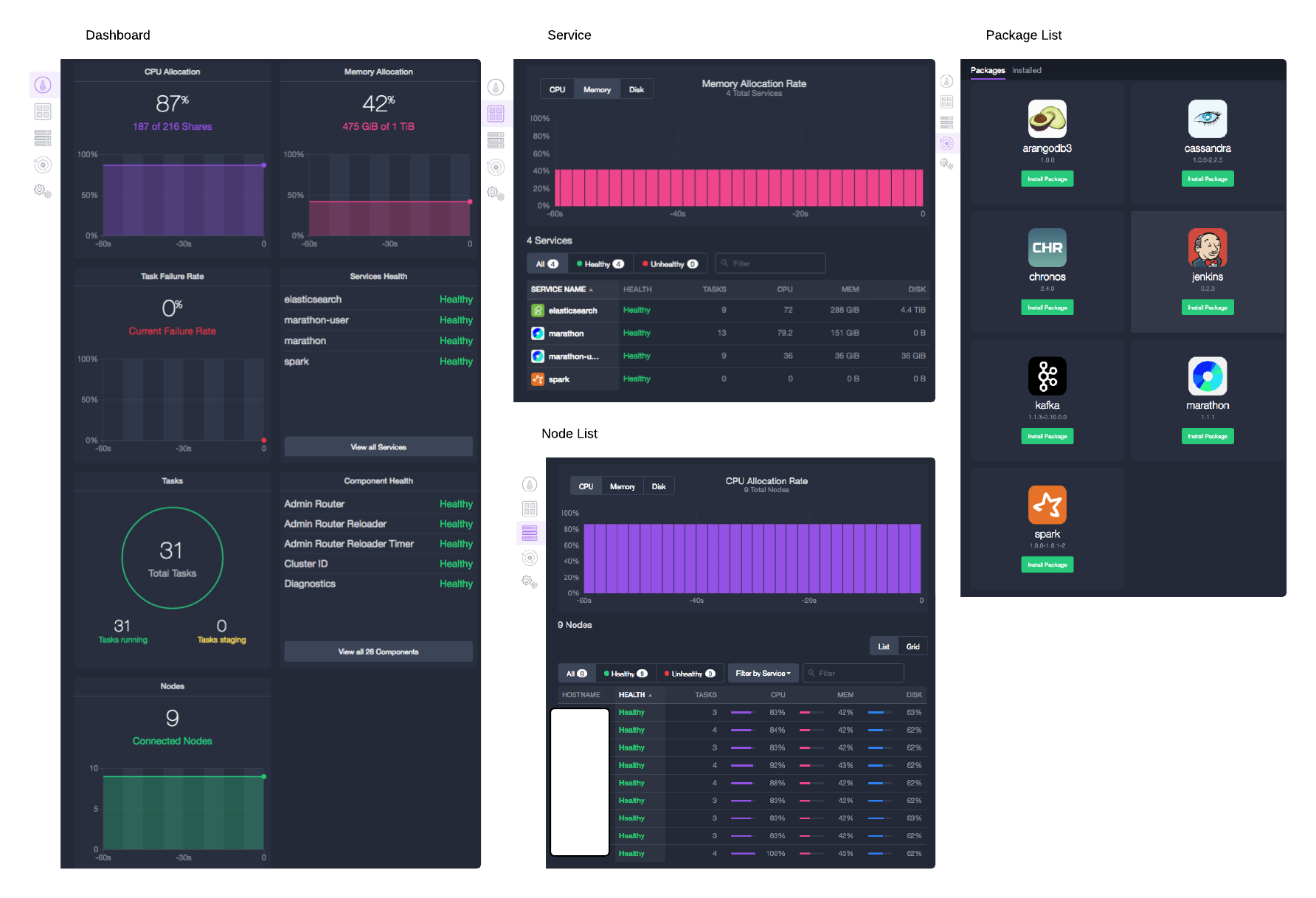
- DC/OS Dashboard: You can view how many agent nodes are running and check their health status.
- Service: You can view resource usage for each running service and its health status.
- Node List: You can view available resources for each node and the overall availability of the entire nodes.
- Universe: You can view the list of the packages provided.
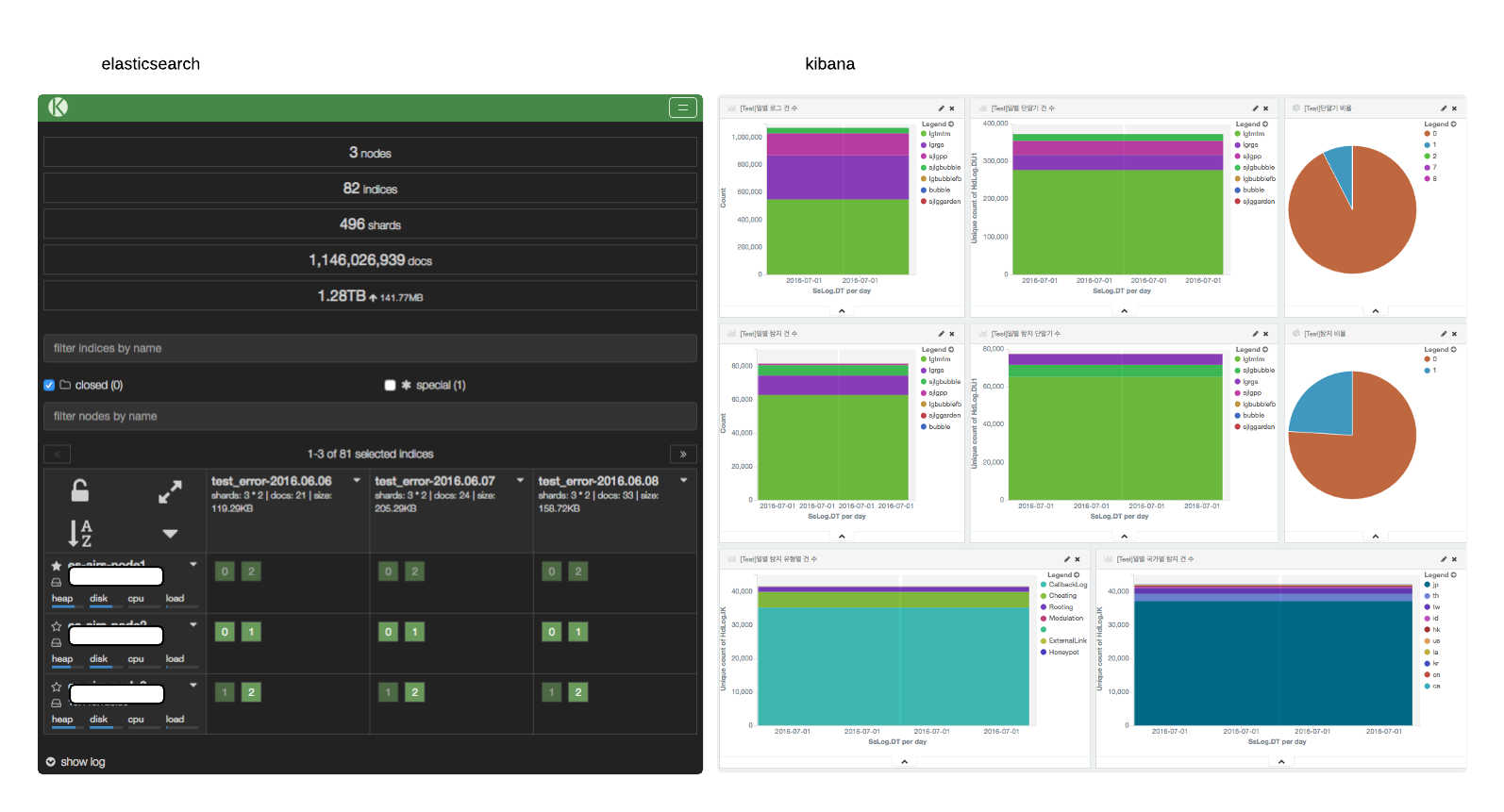
- Elasticsearch kopf plugin lets you view the status information of each node.
- For monitoring purposes, you may use Kibana to customize dashboards for each component.
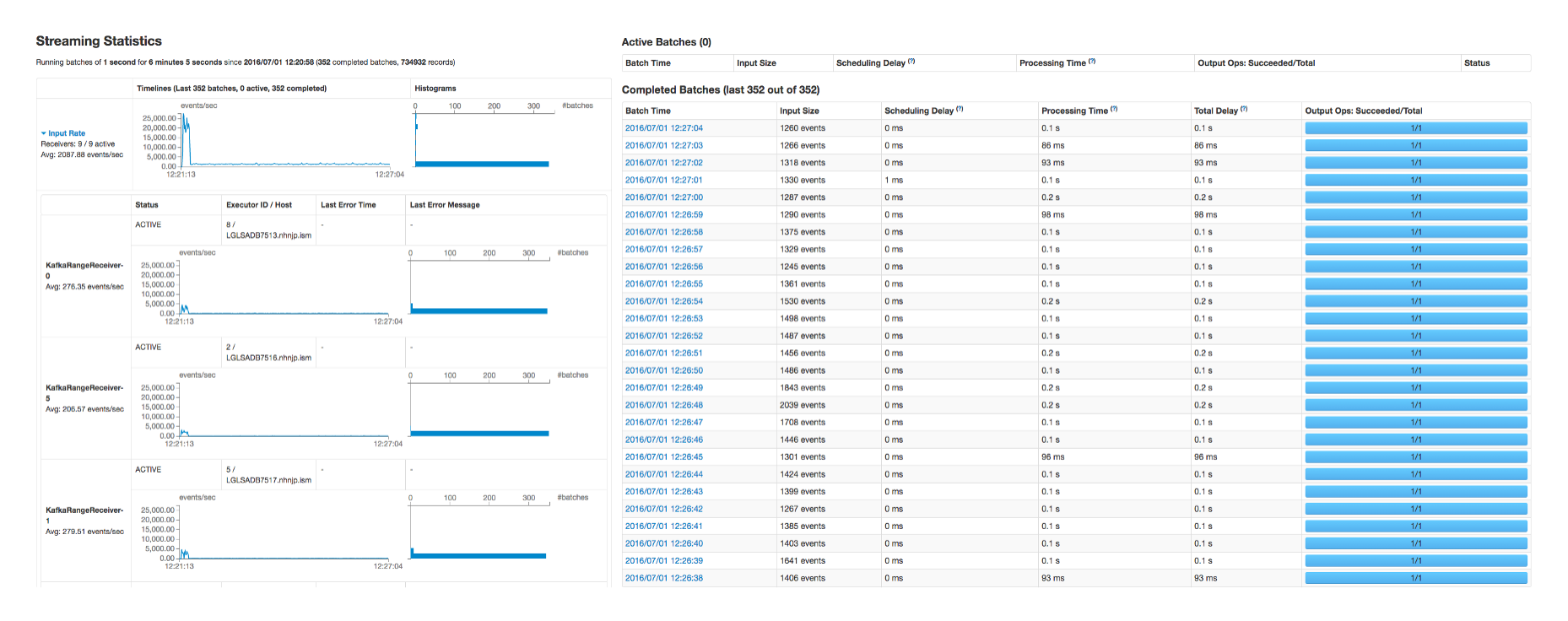
- Streaming Statistics displays Spark web UI with which you can monitor and debug data or tasks as they are processed by Spark Streaming. You can check which node is throwing an exception or having a latency delay issue. It also provides a visual view of the flow or stage for a task, allowing you to fine-tune the task itself.
Near-Real-Time Security Log Analysis
Now let's take a look how AirBorne Streaming is designed.
Structure
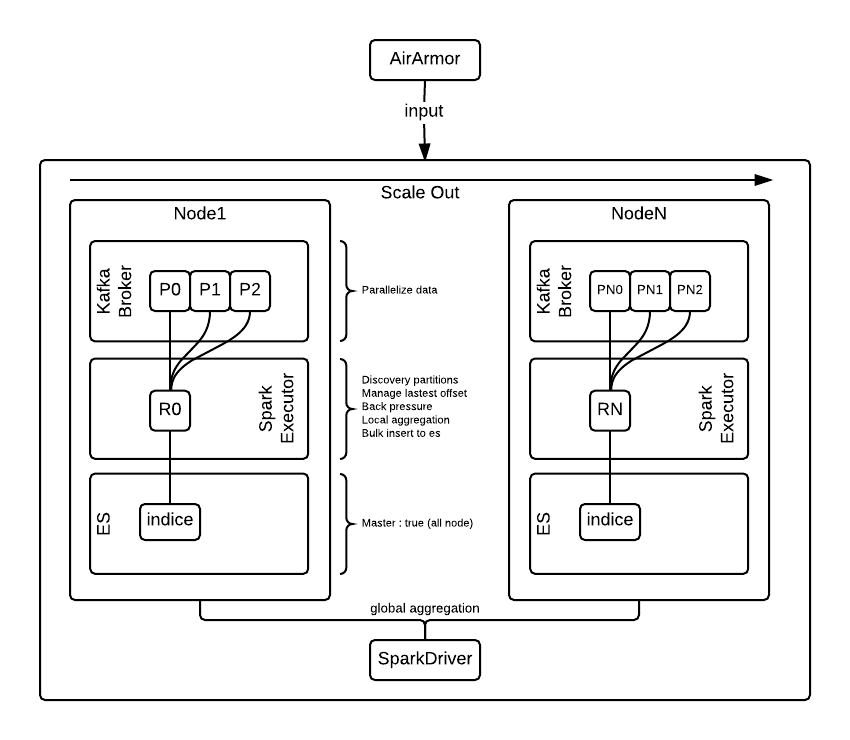
Once log data is detected and collected by AirArmor, it goes through some processing operations like transformation and action. The results are then stored and submitted to Kibana and Zeppelin for further monitoring and analysis. In the real-time processing process, nodes are the key element. To guarantee maximum performance, each node performs aggregation and writes locally. For global aggregation, both the merge and write are done asynchronously by Driver.
Kafka and Elasticsearch replicate N copies of data so that you can always maintain node scalability either by adding new nodes or by recovering the existing nodes when there are node failures. When incoming log feeds increase, in other words, when the duration time (1 sec) becomes longer than the processing time, we usually choose to scale out the nodes. Currently, our system can scale out in less than 30 minutes. We are hoping to add automated scale-out and scale-in in the future.
The Design of AirBorne Streaming
Kafka
Kafka is a high-throughput, distributed, publish-subscribe messaging system. It is some sort of buffer in AirBorne. Once the last offset is properly processed and stored in Streaming, the offset is written to ZooKeeper to prevent any data loss. Each node has a single Kafka broker and a single topic can be assigned N number of partitions.
We are using the Kafka Low-Level API to allow a local Kafka broker to manage and fetch partition information and link the partition with a receiver. In Spark, this process is usually handled by the Kafka High-Level API. But we use the Low-Level API for higher performance.
Spark Streaming
Spark Streaming runs transformation, action, and backup operations on the logs as they are being stored in Kafka in real-time.
We run Spark in a standalone mode on the cluster. Using the Reserve option for Mesos endpoints, each node is reserved 4 core CPUs and 4GB memory. A Mesos executor allocates those resources on N number of nodes. We allow individual nodes to scale out whereas Spark workers are allowed to scale up only as much as CPU and memory resources are available. When necessary, we can change the deployment configuration by simply adjusting some numbers.
A Spark worker creates N number of receivers. It takes the role of a Kafka consumer and processes fetch message jobs in parallel. All three elements - a Kafka broker which provides input, a Spark worker which processes the input, and Elasticsearch which produces output - run on the same node. This ensures strong data locality and helps reduce the time to complete the fetch message jobs.
Everything was set up to make sure that the whole operation can be completed within the specified duration time of 1 second.
Main configuration
spark.streaming.backpressure.enabled=true #Adjust pid when a task is delayed
spark.serializer=org.apache.spark.serializer.KryoSerializer #serializer
spark.scheduler.mode=FAIR
Elasticsearch
Once security logs are stored, the next thing to do is analysis on the log data, running searches and statistical analytics.
Elasticsearch maintains N number of replicated data, all in master mode. Indices are created on a daily basis. It can access historical data of up to D-10 days old stored in HDFS through Spark and Zeppelin. Every node is configured as a data node so that documents can be processed by Spark Streaming and stored by Elasticsearch without causing any network cost. Each node stores its own RDD locally in Elasticsearch. In the old AirBorne system, this was the part where delays would happen most frequently.
Main configuration
node.master=true #all node, all nodes can become master when there are node failures
#or some changes
node.data=true
The Advantages of AirBorne DataCenter
AirBorne DataCenter provides advantages in three aspects: efficient resource management, high performance, and scalability.
- Efficient resource management
- Traditionally, a node used to serve a single purpose. However, to maximize throughput on the big data platform, you have to use as much of the available resources as you can. This is the basic concept of Mesos and what we seek to achieve. Our goal is to use the node resources to their maximum capacity.
- Performance
- Performance is affected by various factors. It depends on how you configure systems, OS, open source packages, and so on. That is why we chose open sources such as Kafka, Elasticsearch, Cassandra, and HDFS. Even when nodes have failed, we can prevent data loss and minimize the impact on our services by keeping N number of replicated data. Also, in an effort to improve locality, we put in a lot of hard work to make Kafka, Spark Streaming and Elasticsearch communicate locally on the same node. This configuration allows us to scale out with ease when necessary and to recover from failures automatically.
- Scalability
- We are broadening the use of AirArmor, our mobile security solution, with LINE Games. As a result, the volume of logs we have to deal with is increasing rapidly. As we have limited manpower to put into data security management, node scalability has become more important in the AirBorne system. The current AirBorne system is capable of scaling out nodes within 30 minutes.
Future Plans
We have plans to upgrade AirBorne DataCenter as follows.
- AT 3.0
- We will release Abuser Tracker 3.02, which will receive security data from AirBorne and report analytics results in real-time.
- DNN for AirBorne
- We will launch a DNN (Deep Neural Network) service, which will detect abnormal behaviors during the Streaming phase. We've been testing this service using actual game logs to improve accuracy for about six months now.
- AirBorne Universe Repository
- We will develop a scheduler and an executor, customize AirBorne packages to better meet our needs, and make DC/OS Universe Repository provide those packages to our internal system.
- AirBorne 2.0
- We will build our own Mesos-based platform that will include everything from big data packages, monitoring services to deployment environments. The platform will be tailored to our internal environment and replace DC/OS.
2: Tracks and monitors abusers across all LINE Games
Written by Oh Wang-jin. Wang-jin is a game security developer at LINE. He enjoys every step of problem solving.
Send your comments to our Twitter account.LINE Security Twitter