
以前の記事「Spark、Mesos、Zeppelin、HDFSを活用した大容量セキュリティデータの解析」に続き、今回はAirArmor※注1から得られる検知情報をほぼリアルタイムで処理するために使用したクラウド技術とストリーミング処理方式についてご紹介します。
※注1: LINEのゲームセキュリティ開発室で開発し、LINE Gameに適用しているモバイル向けゲームセキュリティソリューションの名称
AirBorne DataCenter & Mesos (with DC/OS)
Apache Mesosをベースにセキュリティデータを解析する全体的な仕組みをAirBorne DataCenterと称しています。この仕組みには、ビックデータを処理するためのKafka、Spark、Elasticsearch、Hadoop、Zeppelin、Springなどのオープンソースが含まれています。
導入の背景
2015年初頭にスタートしたAirBorneは、大量のデータを迅速に照会することを目的に作られたものです。MesosベースのSparkを主に使用しており、データの照会およびビジュアライズ(可視化)のためにZeppelinとSpringを採用しています。これにより、DBMSで対応しにくい大量のデータの処理やJSON形式の大量のDBデータとログデータの処理など、これまで不可能または困難だった処理が可能になりました。なお、ユーザビリティの改善と解析タイプの増加に伴い、物理的なノードの拡張や各エンドポイントのモニタリングといった業務の自動化、高いユーザビリティ、安定性などへのニーズが継続的に発生しました。
特に、定期的にデータを処理する業務だけでなく、リアルタイムでデータを処理してその都度通知を受け取り、変化量をコントロールできるようにする業務も必要となってきました。
このような業務環境の変化を受け、AirBorne DataCenterの構造の設計を見直し、リアルタイム処理に対応する新しい領域を追加しました。
Apache Mesosは、多数の物理的なノードのリソースを論理的に一つのリソースとして提供できるように、フレームワークを提供しています。Kafka、Elasticsearchのように固定されたリソースを使用するケースもあれば、Spark Executorのように余分のリソースを瞬間的に最大限に活用するケースもあるなど、リソースの無駄を省き、効率的な使用を図ることができます。なお、Constraint、Role、Quotaなどを設定することで、様々な方法でリソースを予約できるようになります。
DC/OSは、Mesosフレームワークに対応するオープンソースパッケージを提供しています。Kafka、Elasticsearch、MySQL、Spark、Zeppelinなど多様なオープンソースがパッケージでサポートされます。基本的には、パッケージのインストールと運営のためのツール、障害対応、柔軟な水平拡張などの追加機能が含まれています。一定期間のテストと試験運営を経てユーザビリティの検証を終え、一部の領域に導入しています。
ストラクチャー
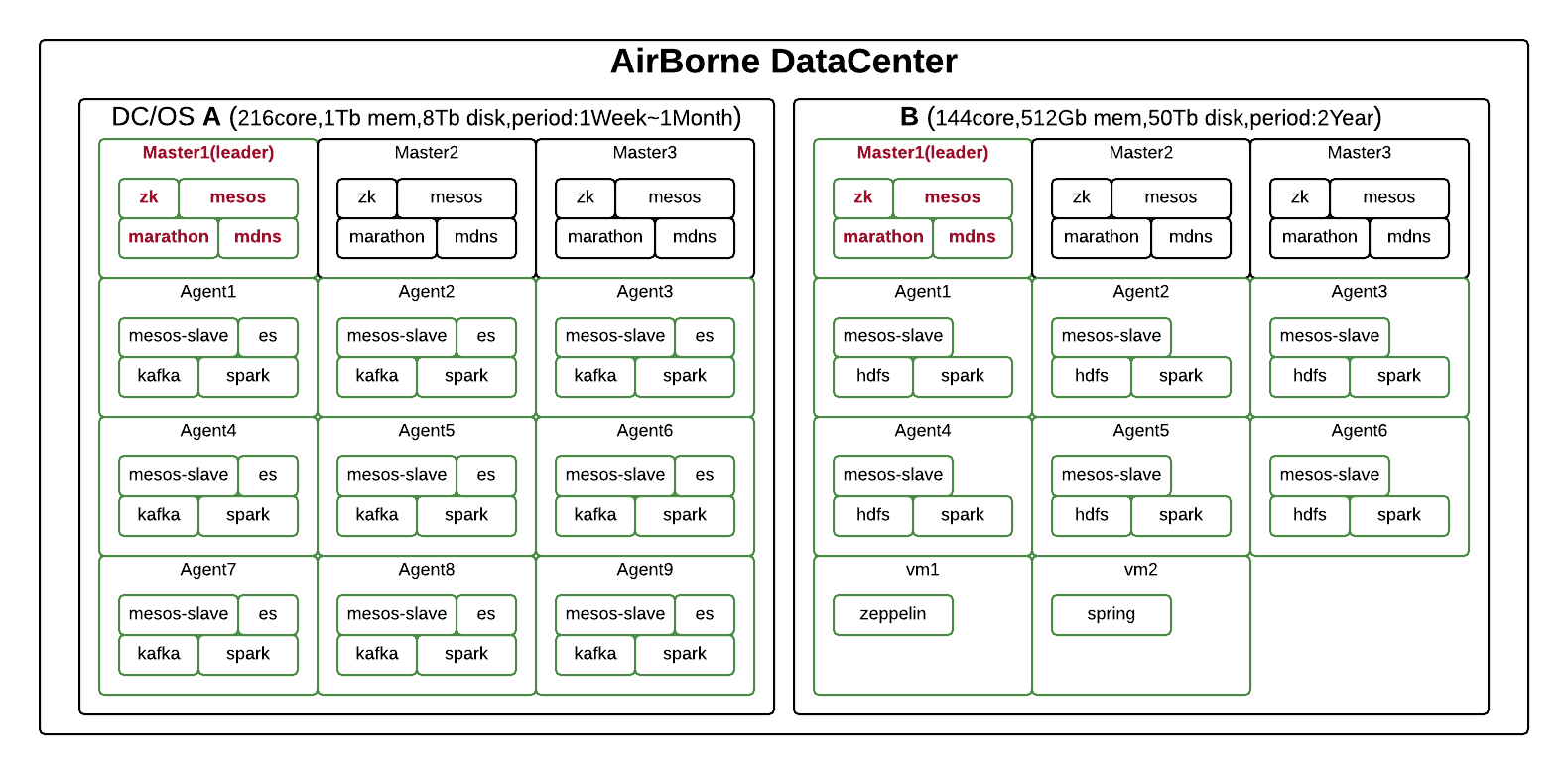
AirBorne DataCenterは上図のような構成となっており、データ処理をリアルタイムと非リアルタイムに区分しています。データ処理においてリソースを予約・活用する方法、対象となるデータの保存期間もそれぞれ異なります。そのため、リアルタイムデータ処理については、適切な量のリソースを固定的に予約・活用するようにしました。一方、非リアルタイムデータ処理については、長期間のデータを保存するシステムで余分のCPUとメモリリソースを活用するように設計しました。
DC/OSは、上記のような環境を迅速に構築できるというメリットを持っていますが、DC/OS一つでAirBorne DataCenterの二つの領域(DC/OS AとDC/OS B)を運営するには、設計コンセプト上まだこのソリューションに適していない部分がありました。ただ、今回のプロジェクトでは、リアルタイムデータ処理環境の早期構築や柔軟な拡張、モニタリングの自動化などにおいてはDC/OSが大きく貢献しました。今後、独自の環境に適したMesosベースの開発プロジェクトを準備する予定です。
ビックデータを処理するためのパッケージで構成されているクラウド環境は、マルチユーザーのためのシステムというよりは、余分のリソースを大きな作業に活用したり、固定されたリソースを小さな作業に予約しておいたりと、リソースを自由に操作できるという観点から通常のクラウド環境とは大きく異なるといえます。実際、リアルタイム処理の場合は、対象が1,000万件あるとしても100個の処理部で並列処理すれば、一つの処理部が担当するのは10万件のみとなります。リソースが多い大きいノードを使用して拡張するとリソースが余ってしまいますが、適量のリソースを持つノードを使用するとリソースの余剰を最小限に抑えて拡張することができます。
このように、AirBorne DataCenterの構成におけるMesosは、多様な方法でリソースを予約して使用するための重要な役割を果たしています。
特徴
AirBorne DataCenterは、次のような特徴があります。
- Web UIを用いたクラスタの運営(パッケージのインストール、スケールアウト)とモニタリング
- Mesosベースの多様なビックデータ関連オープンソースパッケージに対応
- 柔軟な拡張
- Quota、Constraint、Roleの設定よる多様なリソース予約方法
- OAuthによる認証/認可の提供
- 障害対応
リアルタイムデータ処理と非リアルタイムデータ処理との比較
| DC/OS A | DC/OS B | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 用途 | リアルタイムデータ処理 | 非リアルタイムデータ処理 | ||||||||||||||||||
| 性能 | 30万EPSの処理能力 |
|
||||||||||||||||||
| Mesos quota | Cluster:UNIQUE |
|
||||||||||||||||||
| Spark mode | Standalone mode | Mesos coarse mode | ||||||||||||||||||
| Business logic feature |
|
|
||||||||||||||||||
| Tools |
|
Zeppelin: data processing, view | ||||||||||||||||||
| セキュリティ業務 |
|
|
画面の紹介
AirBorne DataCenterの画面を簡単にご紹介します。
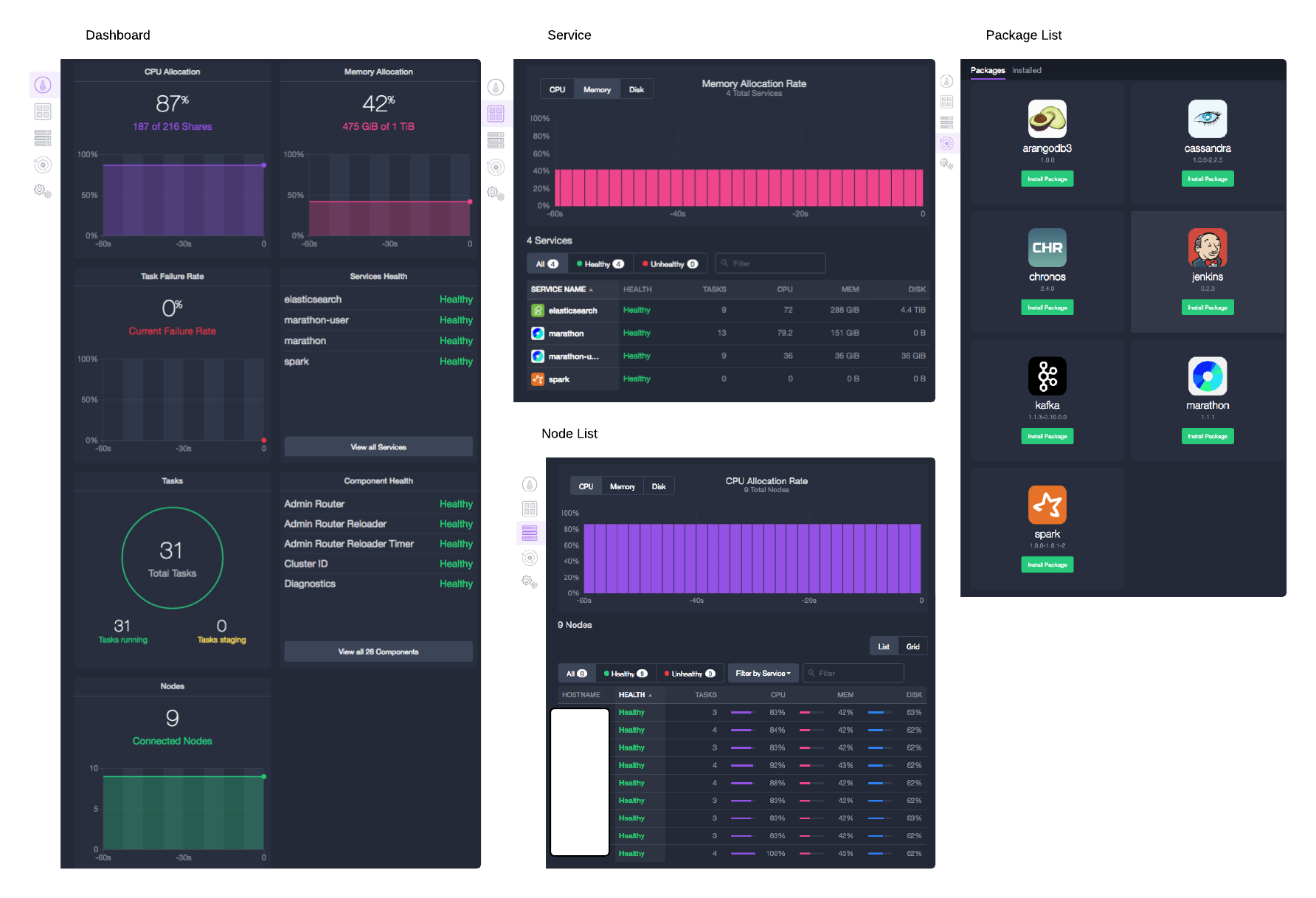
- DC/OS Dashboardでは、エージェントノードの使用状況とHealth情報を確認できます。
- Service画面では、起動中の各サービスのリソース使用量とHealth情報を確認できます。
- Node Listでは、各ノードの余分のリソースと全ノードの使用状況を確認できます。
- Universe画面では、提供しているパッケージのリストを確認できます。
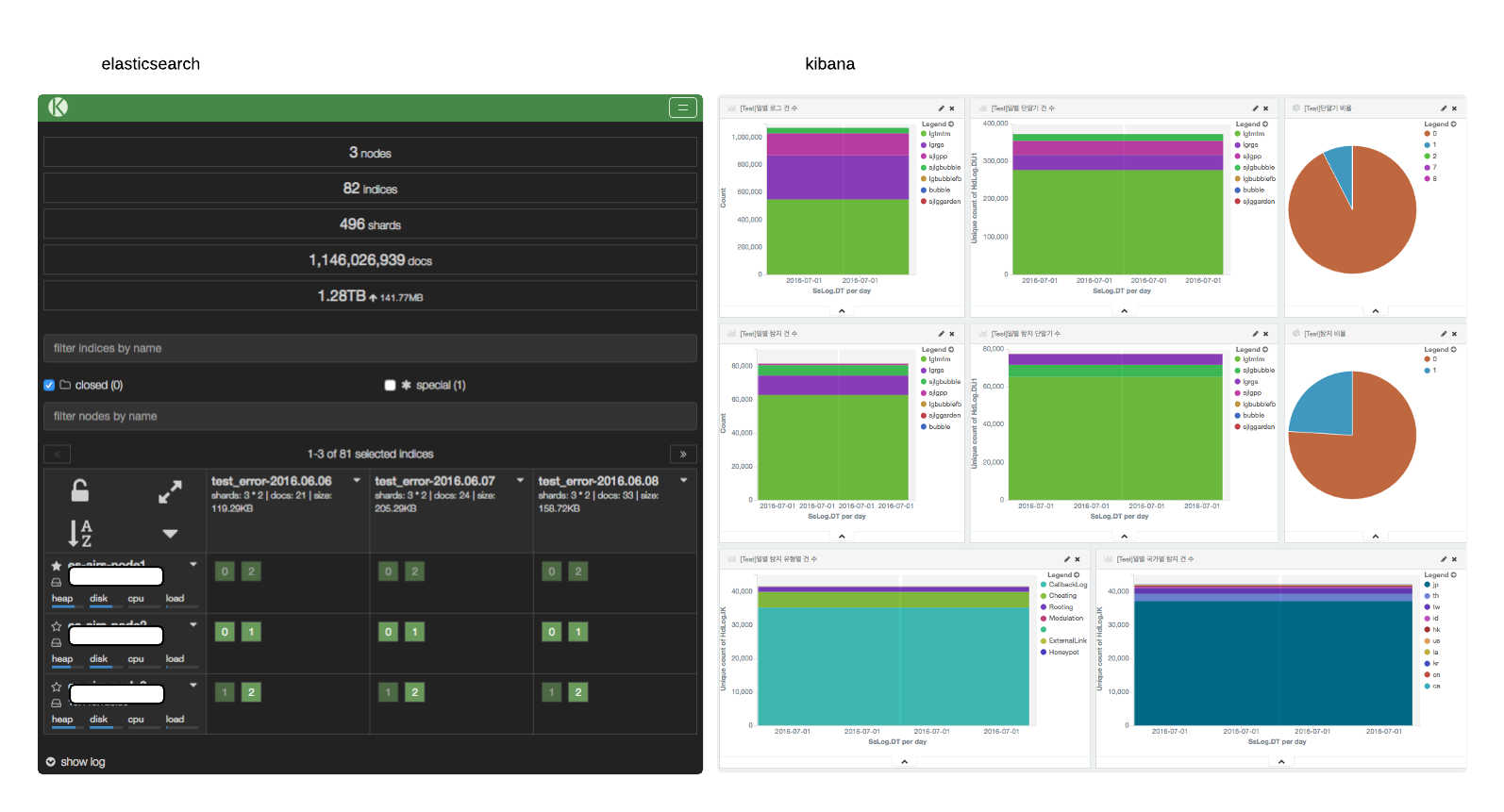
- Elasticsearchのkopfプラグインで各ノードのステータス情報を確認できます。
- なお、Kibanaを活用して各項目のダッシュボードを作成し、モニタリングすることもできます。
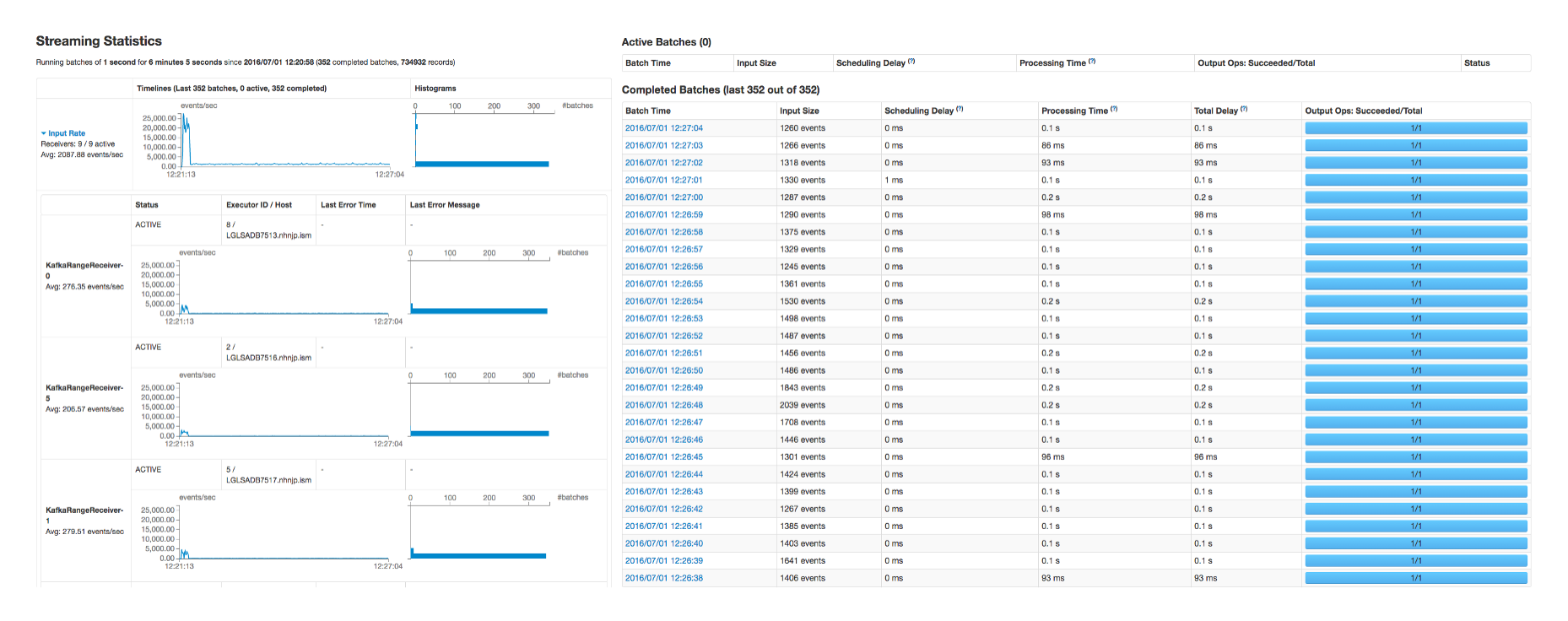
- Streaming Statisticsは、Spark Streamingと各タスクをモニタリング・デバッグできるSparkのWeb UIです。ストリーミングの遅延または例外的な状況が発生した場合は、このWeb UIから分散されたノードの例外情報を確認できます。なお、タスクの流れやステージを視覚的に表現しているので、タスク自体をチューニングする用途としても使用できます。
Near-Real-Time Security Log Analysis
次に、AirBorne Streamingの設計についてご紹介します。
ストラクチャー
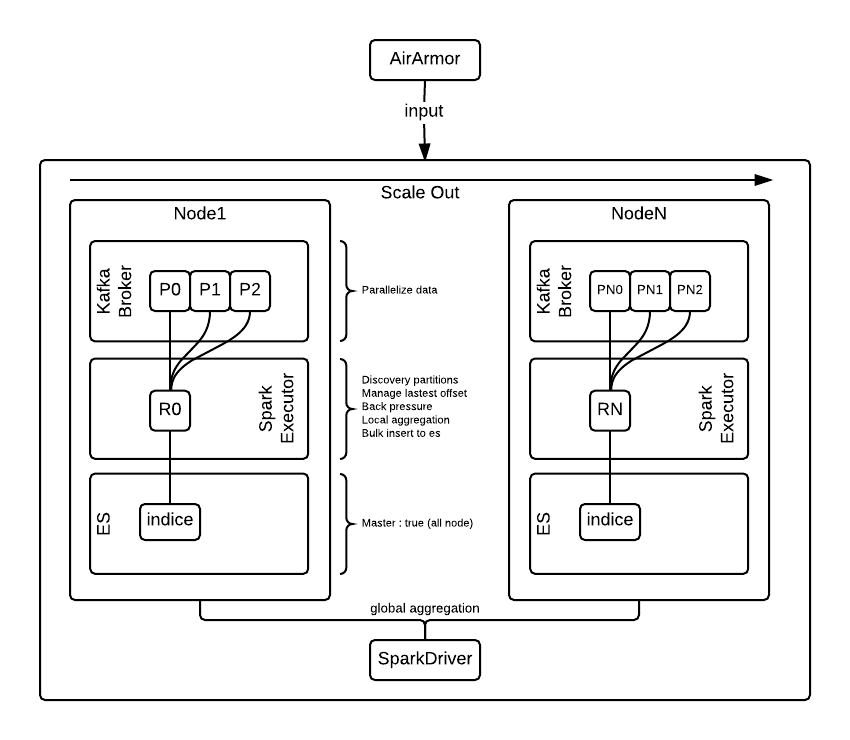
このソリューションでは、AirArmorからの検知ログを収集してtransformation、actionなどの処理を行い、その結果を保存します。そして、Kibana、Zeppelinでモニタリングおよび解析作業を行います。リアルタイム処理の中核的な要素となりますが、各ノードは最大の性能を得るためにlocal aggregationとwriteの場合はローカル通信を行い、global aggregationの場合は各ノードの結果をdriverで非同期でマージしてwriteしています。
KafkaとElasticsearchは、障害対策としてn個のデータをコピーしています。ノードが障害状態になっても、新規ノードの投入またはノードの復元を行うことで自然にスケールが維持されます。ログの流入量自体が増加する場合(所要時間1秒が処理時間より長い場合)、スケールアウトを目指します。現在の構成では30分未満でスケールアウトが可能です。今後はオートスケールアウト、スケールインまで試してみる予定です。
AirBorne Streamingの設計
Kafka
Kafkaは、大容量のリアルタイムログに特化した分散メッセージングシステムであり、パブリッシュ-サブスクライブ(publish-subscribe)モデルに基づいてAirborneでバッファーのような役割を果たします。ストリーミングでは、正常に処理した最後のoffsetを配置する度にZooKeeperに記録するようにし、データ消失を防止しています。各ノードにKafka Brokerを一つずつ構成し、一つのTopicにn個のパーティションを設定できます。
Kafka low-level APIを使ってローカルのKafka brokerで管理されるパーティションの情報を取得し、receiverは当該パーティションに接続されます。こうした処理はSparkでKafka high-level APIを使用する際に行われるものですが、性能アップのためにこのように構成しました。
Spark Streaming
Kafkaにリアルタイムで保存されるログをtransformation、action、backupするためにSpark Streamingを使用しています。
クラスタモードでスタンドアローンで動作するもので、Mesosエンドポイントであるreserveで4コア、4GBメモリを各ノードに予約しておきます。そのリソースは、Mesos executorによってn個のノードに割り当てられます。各ノードではスケールアウトを目指しますが、spark workerの場合はCPUとメモリリソースに余裕がある分だけスケールアップすることができます。この部分は、状況に応じて数値を変更するだけでもデプロイできるように設定されています。
Spark workerでKafka consumerの役割を担うreceiverをn個ずつ作成し、fetch message作業を並列処理できます。InputとなるKafka Broker、プロセッシングを担当するSpark Worker、OutputとなるElasticsearchが同じノードで動作するので、ローカリティに優れ、fetch messageの作業時間を短縮できます。
このような構成は、1秒以内の処理を保証するために独自で考案した方法です。
主な設定
spark.streaming.backpressure.enabled=true #タスクの遅延時にpid調整
spark.serializer=org.apache.spark.serializer.KryoSerializer #serializer
spark.scheduler.mode=FAIRElasticsearch
保存されているセキュリティログを解析する業務は、検索と簡単な統計を取る作業の連続です。
Elasticsearchは、all masterモードでn個のコピーされたデータを保持するようにしています。毎日indiceを作成し、10日前の過去のデータについてはHDFSのデータをSparkとZeppelinを通じて使用します。各ノードにデータノードを構成しているので、Elasticsearchにドキュメント(processed by Spark Streaming)を保存するときにもネットワークコストがかかりません。つまり、各ノードにおいて自分で生成したRDDをローカルのElasticsearchに保存するのです。これは、既存のAirBorneシステムを運営する際に遅延が最も多く発生していた部分でした。
主な設定
node.master=true #全ノード、ノードの障害または変更作業時に、すべてのノードがmasterの役割を遂行
node.data=true設計の利点
Airborne DataCenterの利点としては、効率的なリソース運営、性能、拡張性が挙げられます。
- 効率的なリソース運営
- 通常、ノードは一つの目的で運営されてきましたが、ビックデータの特性上、必要時に余分のリソースをすべて活用してこそ処理能力を最大化できます。このような運営方法はMesosの基本コンセプトであり、私たちが追求する目的にも合致しているため、ノードの余分のリソースを最大限活用してデータを処理しています。
- 性能
- システム、OS、オープンソースパッケージなど、どのような構成を使用するかによって性能が大きく左右されます。Kafka, Elasticsearch, Cassandra, HDFSといったオープンソースを採用した理由にもなりますが、基本的にデータはn個以上のコピーを持っており、一つのノードに障害が発生してもデータの消失を防止でき、サービスに使われるデータにも影響が出ません。特に、ローカリティの面で性能を最大限発揮できるようにするため、KafkaやSpark Streaming、Elasticsearchを同じノードでローカル通信するように構成しました。この構成は、必要時に簡単にスケールアウトでき、障害が発生しても自動的に復元できます。
- 拡張性
- AirArmorは、モバイルセキュリティソリューションとしてLINEの主要ゲームに適用拡大されつつあるので、ログの量が急増しています。セキュリティデータの運営のために投入されている人的リソースが少ないため、ノードを柔軟に拡張していくことはAirBorneにおいてさらに重要な機能となっています。現在は最大30分で必要なノードを拡張できるようになっています。
今後の計画
AirBorne DataCenterの今後の計画は次の4つです。
- AT 3.0
- Abuser Tracker 3.0※注2を計画しており、AirBorneで発生するセキュリティ検知の解析結果をリアルタイムで提供する予定です。
- DNN for AirBorne
- ストリーミング段階でAbnormalを検知するために、DNN(Deep Neural Network)サービスを適用する予定です。一部のゲームログを使用して6ヵ月前から検証を進めており、サービスに適用して精度を確保する計画です。
- AirBorne Universe Repository
- Scheduler、executorを開発してAirBorneで使用しているパッケージを内部の用途に合わせて開発し、DC/OSのUniverseリポジトリで内部に提供できるようにする予定です。
- AirBorne 2.0
- Mesosフレームワークを用いたビックデータパッケージの運営、モニタリング、デプロイ環境を独自開発する計画です。DC/OSの代替として社内の環境に合わせて構築する予定です。
※注2: LINE Game全体におけるアビューザーの追跡と管理
この記事は、LINEのゲームセキュリティ開発室のオ・ワンジンさんが作成しました。オさんはゲームセキュリティサーバの開発を担当している、問題を解決する過程を楽しむエンジニアです。
ご意見やご感想はこちらから!
LINE Security Twitter