
들어가며
안녕하세요. LINE Plus Messaging Data Eng Dev (NP) 팀에서 데이터 엔지니어로 일하는 정우영입니다. 최근 HiveQL(Hive SQL) 작업을 Spark SQL로 이전하는 과제를 진행했습니다. 주로 INSERT OVERWRITE TABLE이란 SQL 구문을 이용해 데이터를 적재했는데요. Spark 설정에 따라 Hive에서는 발생하지 않던 여러 현상이 발생했습니다. 이번 글에서는 그 원인과 해결 방법을 찾는 과정에서 알게 된 점을 소개하겠습니다.
글은 먼저 작업을 시작한 배경과 작업 환경을 소개하고, HiveQL에서 Spark SQL으로 이전한 과정을 공유한 뒤, Spark 설정에 따라서 발생한 여러 현상과 각 현상의 재현 방법 및 원인과 대응 방법을 살펴보는 순으로 진행하겠습니다.
작업 배경과 대상 및 환경
작업 배경
먼저 이번 작업을 시작한 배경을 소개하겠습니다. LINE의 데이터 환경을 관리하는 데이터 플랫폼 실에서 그동안 사용해 온 Hive 사용을 점진적으로 중단하고 Spark 환경으로 이전한다는 방향을 설정했습니다. Hive 커뮤니티가 점차 줄어들고 배포 주기도 길어지며 점점 비활성화되고 있는 반면, 이미 오래전 대세로 자리 잡은 Spark는 실행 속도도 빠르고 새로운 기술을 연동하기에도 더 유리하기 때문입니다.
이미 사내에서도 많은 조직이 Spark를 활용하고 있었지만, 저희 팀은 개발한 지 오래된 레거시 코드를 많이 운영하고 있어서 아직도 많은 코드가 Hive로 작동하고 있었는데요. 데이터 플랫폼 실과 가깝게 협업하고 있던 저희 팀은 데이터 플랫폼 실에서 전사적으로 새로운 방향을 공지하기 전에 먼저 Spark로 이전을 시도했습니다.
작업 대상
Messaging Data Eng Dev (NP) 팀은 LINE의 다양한 제품 데이터에 대한 소위 ETL(Extract, Transform, Load) 작업을 담당합니다. 사용자 정보나 사용자 간 관계 정보와 같은 LINE 핵심 데이터 일부와 메시징 데이터, 오픈챗 데이터, 회사의 다양한 제품을 전사적인 관점에서 공통화한 형태로 분석하고 KPI를 집계하는 LINE 사용자 행동 데이터나 KPI 프레임워크 데이터 등 다양한 제품의 데이터 생산을 책임지고 있습니다.
담당하는 데이터에 LINE의 시작이었던 메시징 데이터가 포함되기 때문에 10년 넘게 유지 보수하고 있는 오래된 코드도 있는데요. 상당수 데이터 조직이 저희가 생산하는 데이터에 영향을 받기 때문에 일관된 데이터를 약속된 시간에 안정적으로 제공하기 위한 방법을 찾고 있었습니다. 따라서 비단 플랫폼 차원에서 요구하지 않았더라도 데이터를 더 빠르고 안정적으로 제공할 수 있다면 Spark를 도입하는 것이 바람직했고, 이 목표를 달성하기 위한 첫 번째 단계로 오픈챗 제품에 대한 모든 데이터 생산 쿼리를 HiveQL에서 Spark SQL로 이전하는 과제를 소규모 TF로 진행했습니다.
오픈챗을 위한 쿼리 중 HiveQL로 작성된 것은 100여 개였는데요. 과제에 참여한 팀원이 전부 처리하기에는 많은 개수였기 때문에 Spark SQL를 도입하는 과정에서 발생하는 이슈를 해결하며 TF에 참여하지 않는 팀원도 기계적으로 Spark SQL로 이전할 수 있도록 준비했습니다.
작업 환경
저희는 Airflow로 Task를 만들어 쿼리를 실행하고 각 Task 사이 관계를 DAG(Directed Acyclic Graph)로 만들어 관리합니다. 보통 한 쿼리를 하나의 Task로 구성하며, 각 Task 간 선후 관계를 조정하기 위해 DAG을 사용합니다.
Airflow에서 Spark SQL을 실행할 때에는 Airflow에서 제공하는 SparkSqlOperator나 SparkSubmitOperator를 사용하는데요. 저희는 아래 두 가지 이유로 SparkSubmitOperator를 차용한 별도 Operator를 개발해 사용했습니다.
- LINE의 핵심 데이터와 메시징 플랫폼의 데이터는 크기가 매우 크기 때문에 클러스터 모드를 사용하는 것이 바람직했기에 쿼리를 Spark의 클러스터 모드로 실행하길 원했습니다.
- 팀에서 사용하는 인터페이스와의 호환성을 유지하고 싶었습니다. 호환성을 유지하면, 쿼리에 문제만 없다면 데이터 오류를 방지하기 위한 전처리 및 후처리 코드를 그대로 사용하면서 실행할 엔진에 대한 명세만 Hive에서 Spark로 변경하는 것으로 엔진 이전이 가능했습니다. 앞서 말씀드렸듯 과제에 참여하지 않는 팀원의 도움을 받아야 해서 동일한 인터페이스를 만들어 제공했습니다.
별도로 개발한 Operator는 명세에 적힌 쿼리를 Jinja 템플릿 엔진에 주입해 PySpark 애플리케이션을 동적으로 생성한 뒤 Spark 클러스터에 제출해 실행합니다. 사용자는 명세만 잘 작성하면 Spark에 대한 지식이 없어도 Spark 앱으로 쿼리를 실행할 수 있습니다.
실행 환경을 구성하면서 중요하게 생각했던 것은 Task가 진행되는 모든 상황을 Airflow UI에서 확인할 수 있어야 한다는 점이었습니다. 앞서 말씀드린 클러스터 모드를 사용하면 앱 로그가 Airflow Task가 실행되는 노드에 남지 않고 원격에 위치한 드라이버 노드에 남는데요. 이 로그를 바로 확인할 수단이 없으면 불편하기 때문에 Spark 앱이 종료되면 원격지에 저장된 앱 로그를 가져와서 유의미한 부분을 추출한 뒤 Airflow 로그로 출력했습니다. 이를 통해 사용자는 Airflow UI만 보고 모든 상황을 파악할 수 있고, Spark 앱이 비정상으로 종료될 경우 로그를 보고 발생한 예외를 해석해 문제 원인을 추출해서 온 콜(on-call) 담당 팀원이 즉시 상황을 파악할 수 있도록 만들었습니다. Airflow에서 Task를 중단할 때에는 제출된 Spark 앱을 원격으로 종료시킨 뒤 로그를 가져와서 Airflow로 출력하기 때문에 Operator 사용자는 어떤 상황에서도 Airflow UI만 확인하면 모든 상황을 파악할 수 있습니다.
이와 같이 별도 Operator를 개발하면서 어떤 시도를 했고 어떻게 최적화했는지에 대해서 추후 기회가 된다면 다른 글에서 보다 자세히 소개하겠습니다.
HiveQL에서 Spark SQL로 이전하기
이제 HiveQL에서 Spark SQL로 이전한 방법과 이전 작업 후 평가 방법을 소개하고, 단순 엔진 교체로는 부족해 쿼리를 변경해야 했던 몇 가지 사례를 살펴보겠습니다.
HiveQL에서 Spark SQL로 이전한 방법
Spark SQL을 실행할 환경은 이미 구축돼 있었기 때문에 우선 엔진만 변경해서 실행한 뒤 Hive에서 만든 데이터와 Spark에서 만든 데이터가 일치하는지 확인하는 방식으로 이전 작업을 진행했습니다. 만약 문제가 있으면 그에 맞춰 쿼리를 변경했는데요. 변경이 필요한 경우는 그렇게 많지 않았습니다.
이전 작업 후 결과 평가 - 데이터 동일 여부 확인 및 실행 성능 비교
Spark로 엔진을 변경했을 때 Hive와 동일한 결과물을 만들어 내는지 확인했고, 추가로 실행 성능도 확인했습니다. 만약 동일한 결과물을 만들어 내는 데 자원을 더 많이 사용하거나 시간이 더 오래 걸린다면 문제가 될 수 있기 때문입니다.
데이터 동일 여부 확인 방법
결과물이 일치하는지 확인할 때는 차집합이 공집합이면서 양쪽 개수가 동일한지 확인하는 코드를 사용했습니다. 아래는 예제 코드입니다. 차집합을 확인해 양쪽에서 만든 데이터가 동일한지 확인하고, 중복 발생 여부를 확인하기 위해 개수가 동일한지 확인합니다.
WITH tobe AS (
SELECT *
FROM spark_table
WHERE dt = '2023-01-01'
),
asis AS (
SELECT *
FROM hive_table
WHERE dt = '2023-01-01'
)
SELECT '1. asis_cnt' AS label, COUNT(*) AS cnt FROM asis
UNION ALL
SELECT '2. tobe_cnt' AS label, COUNT(*) AS cnt FROM tobe
UNION ALL
SELECT '3. asis - tobe cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM asis EXCEPT SELECT * FROM tobe) AS diff1
UNION ALL
SELECT '4. tobe - asis cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM tobe EXCEPT SELECT * FROM asis) AS diff2엄밀히 말하면 위 쿼리는 집합 {1, 2, 2, 3}과 집합 {1, 2, 3, 3}를 비교할 때와 같이 서로 다른 유형의 중복이 있을 때에는 해당 중복을 발견할 수 없습니다. 다만 업무 특성상 이와 같은 중복이 발생할 가능성이 낮았기 때문에 위 검증 방법을 사용했습니다.
실행 성능 확인 방법
실행 성능을 평가하는 지표로는 수행 시간과 'vCore-seconds', 'mb-seconds'를 사용했습니다. YARN에서 vCore-seconds와 mb-seconds는 각각 애플리케이션을 실행하기 위해 사용한 초당 vCore와 초당 메모리 사용량을 누적한 지표입니다. 다른 말로 표현하면 애플리케이션을 실행하기 위해 사용한 자원의 양인데요. 수행 시간은 쿼리를 실행하는 executor 개수에 영향을 받을 수 있기 때문에 vCore-seconds와 mb-seconds와 같이 참조하는 게 좋을 것 같다고 판단했습니다.
Spark로 엔진을 변경한 뒤 수행 시간을 살펴보니 평균 15% 정도 빨라졌고, vCore-seconds와 mb-seconds는 쿼리가 복잡할수록 감소하는 패턴이 나타났습니다. 절반 이상 줄어든 경우도 있었습니다.
쿼리를 변경한 사례
단순히 실행하는 쿼리는 엔진을 교체하는 것으로 대부분 큰 문제 없이 이전할 수 있었으며, Hive에서 사용하던 UDF(user-defined function) 또한 내장 UDF와 직접 구현한 UDF 모두 대부분 호환됐습니다. 그 외 명시적으로 쿼리를 변경한 경우를 살펴보겠습니다.
임시 테이블을 사용한 경우(CREATE TEMPORARY TABLE)
Spark에서는 Hive에서 사용했던 임시 테이블(temporary table)이란 개념이 존재하지 않습니다. 비슷한 용도로 사용할 수 있는 임시 뷰(temporary view)가 존재하는데요. Hive 임시 테이블은 데이터를 필터링해 임시로 저장하거나 아예 새로운 데이터를 임시로 정의한 스키마에 삽입할 때 유용하게 쓸 수 있었지만, Spark 임시 뷰는 데이터를 삽입할 수 없다는 차이가 있었습니다. 이에 찾아본 대안은 다음과 같습니다.
CREATE TEMPORARY VIEW혹은CACHE TABLE구문 사용- 임시 테이블을 사용하는 대신 Common Table Expression(CTE)로 변경
- 물리 테이블을 생성해 사용 후 삭제
- DataFrame 사용
CACHE TABLE은 실행 결과가 캐시되는 임시 뷰로 볼 수도 있습니다(참고). CREATE TEMPORARY VIEW로 생성한 임시 뷰는 여러 번 사용하면 동일한 계산을 반복하기 때문에 데이터가 재사용되는지 확인해 용도에 맞춰 선택했습니다. WITH 절로 표현되는 CTE는 중간 결과를 저장하기 위해 사용하는데요. 이번 프로젝트를 진행하면서 CTE로 변경이 불가능한 경우는 손에 꼽았습니다. 따라서 비슷한 고민을 하고 계신다면 먼저 CTE로 변경해 보시는 걸 권해드립니다.
ANSI 정책을 위반하는 묵시적 형 변환을 사용한 경우(Store Assignment Policy)
Spark 3.0 버전에서 정책이 변경되면서 Spark SQL이 ANSI 정책을 위반하는 데이터 형 변환을 차단합니다. 예를 들어, bigint로 정의된 열에 string을 삽입하는 사례를 생각해 볼 수 있는데요. 이와 같이 허용되지 않는 묵시적 형 변환으로 발생하는 에러는 CAST(value AS BIGINT)와 같은 명시적 형 변환으로 변경해 문제를 해결했습니다.
사용하던 UDF에 문제가 있는 경우
앞서 대부분의 UDF가 호환된다고 말씀드렸지만 아래와 같은 일부 내장 UDF에서는 문제가 있었습니다.
get_json_object- Hive와 Spark 모두 내장 함수가 완벽하지 않았습니다. 특히 중첩된 JSON을 처리할 때 구현체마다
JsonPath처리 결과가 달랐습니다.
- Hive와 Spark 모두 내장 함수가 완벽하지 않았습니다. 특히 중첩된 JSON을 처리할 때 구현체마다
parse_url
아래 예제 쿼리와 함께 get_json_object UDF 문제를 조금 더 살펴보겠습니다.
WITH sample_data AS (
SELECT
stack(3,
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}, {"users": [{"id": "c"}]},{"users": [{"id": "d"}]}]}',
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}]}',
'{"groups":[{"users": [{"id": "a"}]}]}'
) AS (json_string)
)
SELECT
get_json_object(json_string, '$.groups[*].users[*].id')
FROM sample_data위 예제 쿼리를 실행하면 각 엔진에서 반환되는 값이 아래와 같이 기댓값과 달랐습니다. 각 엔진에서 계산된 값과 기댓값의 차원이 서로 달랐는데요. Spark에서는 첫 번째 행에서 이차원 배열을 반환했고, Hive에선 세 번째 행에서 배열이 아닌 값을 반환했습니다(아래 표에서 '기대값' 링크를 클릭하면 JavaScript로 실행한 기댓값 결과를 확인할 수 있습니다).
| Hive | Spark | 기댓값 | |
| 1 | ["a","b","c","d"] | [["a","b"],["c"],["d"]] | ["a","b","c","d"] |
| 2 | ["a","b"] | ["a","b"] | ["a","b"] |
| 3 | a | ["a"] | ["a"] |
이와 같은 문제 때문에 Spark 내장 UDF로 대체할 수 없는 경우에는 Hive 내장 UDF를 CREATE TEMPORARY FUNCTION으로 읽어서 사용했습니다.
새로운 UDF를 도입한 경우
Spark는 Hive보다 더 많은 내장 UDF를 제공합니다. 새로 도입한 UDF 일부를 소개하겠습니다.
approx_count_distinct- 계산량이 많은 카디널리티(cardinality, unique/distinct count)를 구하는 대신 빠르게 구할 수 있는 카디널리티 추정치를 구합니다.
count_if- 조건부로 개수를 세는 함수입니다.
max_by/min_by- 특정 열에서 최댓값 혹은 최솟값인 행을 찾아서 그 행의 다른 열을 가져옵니다.
timestamp_millis- Unix 시간과 타임스탬프 사이에 변경할 일이 잦았는데 그때 유용하게 사용했습니다.
맵 타입에 집합 연산을 사용한 경우
SPARK-18134로 보고된 이슈로, 키-값을 자유롭게 적재할 수 있는 맵(map) 타입을 사용할 때 Spark에서는 Hive와는 다르게 중복을 제거하는 집합(set) 연산을 사용할 수 없습니다. 집합 연산에는 DISTINCT, UNION, INTERSECT 등이 있으며, 저희는 map<string, string> 열의 중복을 제거하기 위해 DISTINCT 키워드를 사용하고 있었는데요. 다음과 같이 우회해서 해결했습니다.
-- Hive
SELECT DISTINCT a, b, m FROM table
-- Spark
WITH to_array AS (
SELECT DISTINCT a, b, sort_array(map_entries(m)) AS entry FROM table
)
SELECT a, b, map_from_entries(entry) FROM to_array위 방법은 정렬이 불가능한 맵을 정렬할 수 있는 배열로 만든 뒤 중복을 제거하고 다시 맵으로 변경하는 방법입니다. 불필요한 연산이 발생하는 것 같지만 다른 대안을 찾지 못했습니다(참고로 이 이슈와 관련된 수정은 7년째 승인되지 않는 것으로 보아 쉽게 반영될 것 같지 않습니다).
또한 맵을 다루다 보면 이미 맵에 들어간 키-값 쌍을 중복으로 삽입하는 경우가 있습니다. Spark에서는 이때 예외가 발생하는데요. 만약 허용해도 된다면 spark.sql.mapKeyDedupPolicy=LAST_WIN으로 설정하면 이 문제를 해결할 수 있습니다.
여러 개의 파티션을 삭제해야 하는 경우
SPARK-14922로 보고된 이슈로 ALTER TABLE 구문으로 범위를 지정해 파티션을 삭제할 수 없습니다. 이에 따라 데이터 저장 기한이란 개념을 구현하기 위해서 사용하고 있던 아래와 같은 쿼리를 더 이상 사용할 수 없게 됐습니다.
ALTER TABLE table DROP PARTITION (dt <= '2023-01-01') 이 문제는 파티션 목록을 조회한 뒤 순회하면서 하나씩 삭제하는 별도 인터페이스를 구현하는 것으로 해결했습니다.
HiveQL에서 Spark SQL로 이전한 결과
Spark로 이전하면서 모든 쿼리를 다시 리뷰하며 버그를 수정하고 최적화할 수 있었습니다. 또한 결과물을 보다 빠르게 생산해서 자원을 덜 사용할 수 있도록 개선했으며, 새로운 UDF를 도입해 코드량을 줄인 사례도 있었습니다.
Hive에서 Spark로 이전하면서 겪은 트러블 슈팅 사례
Hive에서 Spark로 이전한 뒤 특정 상황에서 특정 데이터가 누락되는 현상이 발생했습니다. 이 문제를 해결하기 위해 실험 환경을 구축해서 현상을 재현해 보며 원인을 파악했는데요. 원인을 파악한 후 단순히 문제가 발생하지 않도록 조치하는 것에서 멈추지 않고, 근본 원인을 파악하기 위해 관련 Spark 코드를 읽어보았습니다. 그 결과 데이터 누락 이슈뿐 아니라 그 외 몇 가지 문제를 아울러 설명할 수 있는 근본 원인을 파악할 수 있었습니다. 어떤 사례였는지 자세히 살펴보겠습니다.
Spark로 이전 후 데이터 누락 발생
어느 날 메신저를 통해 특정 일별 KPI 수치가 평소보다 15% 감소했다는 문의가 들어왔습니다. 경험상 이런 식으로 데이터가 빠지는 현상은 선행 데이터가 완성되기 전에 쿼리를 실행했을 때 주로 발생했는데요. 예를 들어 앞선 24시간 동안의 데이터를 이용해 쿼리를 실행해야 하는데 22시간 동안의 데이터만 준비됐을 때 쿼리를 실행한 경우 일부 데이터가 누락돼 이런 식으로 KPI가 감소하는 현상이 발생할 수 있습니다.
하지만 저희는 이미 전처리 과정에서 이런 상황이 발생하지 않도록 대비해 놓았기 때문에 이 문제는 아니었습니다. 여러 방면으로 검토한 결과 Spark 엔진을 사용한 것 외에는 다른 변경 사항이 없어서 우선 엔진을 Hive로 롤백해 데이터를 복구하고 원인을 추적했습니다.
실험 환경 구축 후 데이터 누락 발생 원인 조사
추적 결과 원인은 특정 데이터 마트 테이블의 데이터가 누락된 것이었는데요. 이와 같은 누락이 항상 발생하는 것은 아니어서 현상을 재현하기 위해 실험 환경을 구축하고 테스트를 진행했습니다.
해당 테이블은 데이터 마트를 구성하기 위해 세 가지 로그 원천을 이용하는데요. 다음과 같은 쿼리로 만듭니다.
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_1')
SELECT ... FROM source_1;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_2')
SELECT ... FROM source_2;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_3')
SELECT ... FROM source_3;각 날짜와 로그 원천을 파티션으로 구성한 것인데요. 각 로그 원천이 상호 간에 영향을 주지 않아 병렬로 실행할 수 있고, 백필(backfill) 작업도 독립적으로 진행할 수 있어 위와 같이 파티션을 분리해서 저장하는 방법을 사용합니다.
실험 환경에서 테스트를 진행하며 문제가 재현되는 경우를 분석해 보니, 웹 UI의 SQL 탭에 표시된 내용과 HDFS(Hadoop file system)에 실제로 저장된 파일 개수가 다르다는 점이 눈에 띄었습니다.
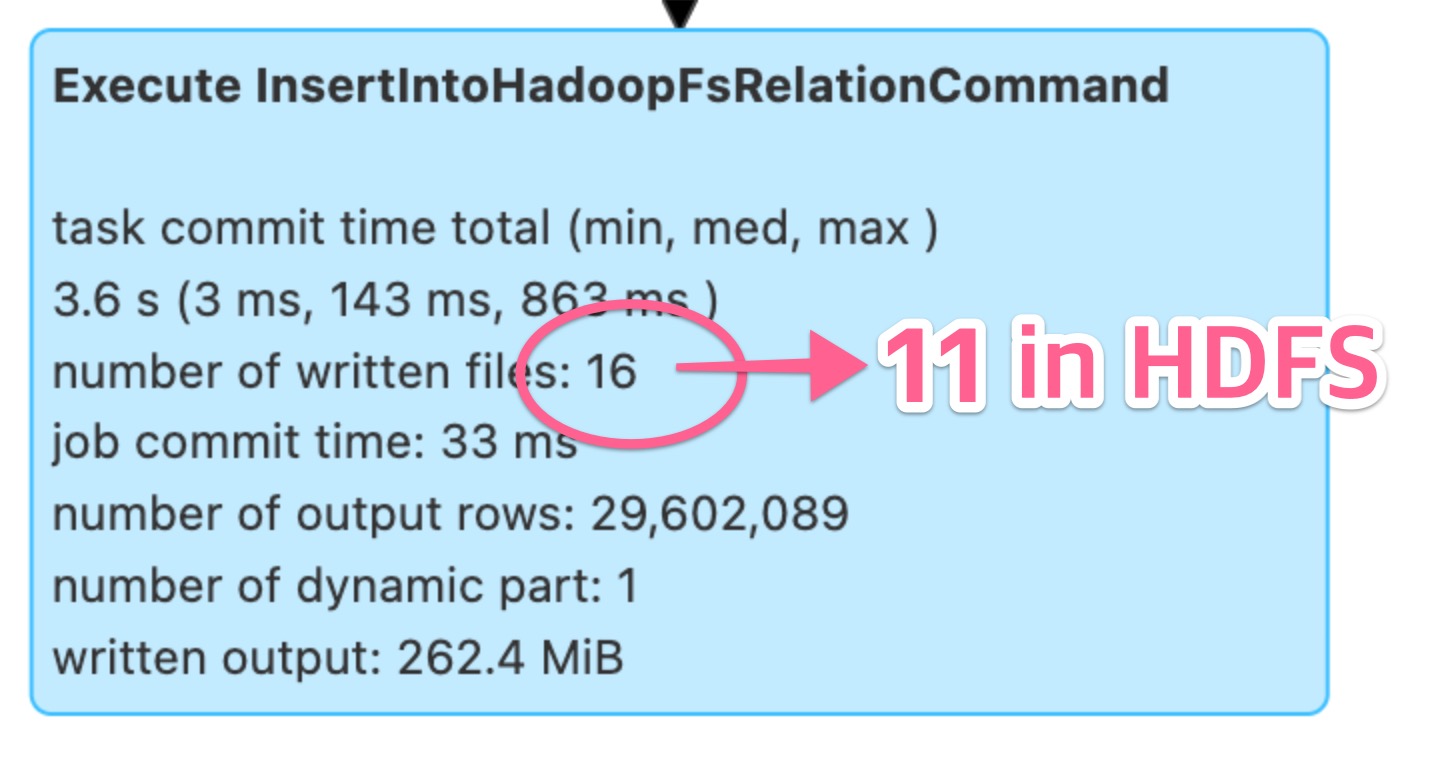
로그를 자세히 분석해 보니 Spark 앱의 중간 작업 파일이 삭제됐다는 내용을 발견했고, 검색을 통해서 MAPREDUCE-7331 이슈를 발견했습니다. 내용을 간단히 요약하면, 같은 테이블에 삽입하는 Spark 앱이 동시에 두 개 이상 실행될 경우 처음 완료된 앱이 다른 앱의 중간 작업물도 지워 결과에 영향을 줄 수 있다는 것입니다.
왜 이런 현상이 발생하는지 조금 더 자세히 살펴보겠습니다. Spark에서는 테이블이 위치한 디렉터리 아래에 _temporary/라는 작업 영역 디렉터리를 만들어 중간 작업물을 저장하고, 모든 앱이 이 작업 영역을 공유합니다. 문제는 앱이 작업을 완료하고 임시 파일을 삭제하기 위해 모든 앱이 공유하는 _temporary/ 디렉터리를 삭제한다는 것입니다. 따라서 같은 테이블에 동시에 두 개 이상의 삽입 쿼리가 실행되는 경우 데이터 유실이 발생할 가능성이 있습니다.
이 _temporary라는 작업 영역 이름은 상수로 하드 코딩(참고)돼 있고, 설정으로는 수정할 수 없는데요. 검색해 보니 _temporary라는 이름이 하드 코딩돼 있는 FileOutputCommitter 소스 코드를 변경해 이 문제를 해결했다는 사례를 찾았습니다. 이를 참고해 비슷한 방법을 시도해 봤는데요. 해당 값이 정의된 변수인 PENDING_DIR_NAME이 사용되는 부분을 전부 적절히 변경하고(앱마다 독립적인 디렉터리 생성) 새로 만든 클래스를 spark.sql.sources.outputCommitterClass 설정에 등록해 Spark 앱을 실행하는 방법이었습니다.
테스트해 본 결과 위 문제는 해결됐지만, 이렇게 개별 클래스를 구현해 이용하면 관리하기 어렵고 검증 또한 쉽지 않아 부담이었습니다. 이에 또 다른 방법을 찾아봤고, 데이터 플랫폼 팀에서 spark.sql.hive.convertMetastoreOrc: false 옵션을 이용해 보라고 권했습니다. 이 설정을 사용해 보니 앱마다 독립적인 작업 디렉터리가 생겨 문제가 발생하지 않는다는 사실을 알게 됐습니다.
Spark 코드를 읽으며 문제의 근본 원인 파악
앞서 설명드린 것처럼 저희가 만든 데이터는 전사적으로 영향을 줄 수 있다 보니 데이터 장애를 방지하기 위해 '단순히 문제가 발생하지 않는다'에서 멈추는 게 아니라 '왜 이런 현상이 발생하는지'까지 설명할 수 있을 정도로 이해할 필요가 있었습니다. 이에 이 설정과 관련된 Spark 코드를 읽어보니 저희가 그동안 겪었던 몇 가지 현상을 하나로 묶어서 설명할 수 있다는 것을 알게 됐습니다.
트러블 슈팅 사례 소개 전 관련 용어 설명
어떤 현상들이 있었는지 소개하기 전에 설명에서 사용할 몇 가지 용어를 먼저 설명하겠습니다.
정적 파티션 삽입(static partition insert)
파티션이 존재하는 테이블에서, INSERT 구문에 모든 파티션을 지정해 삽입하는 것을 말합니다.
INSERT OVERWRITE TABLE user_table PARTITION (dt = '2023-01-01', region = 'JP')
SELECT ...동적 파티션 삽입(dynamic partition insert)
파티션이 존재하는 테이블에서, INSERT 구문에서 파티션을 결정하지 않는 것을 말합니다. 이런 경우 쿼리만 봐서는 파티션을 결정할 수 없고 값을 평가해 봐야 파티션 값을 알 수 있습니다. 참고로 현재 Spark에서 동적 파티션 삽입 시 Hive Metastore에 큰 부담을 줄 수 있다는 내용의 이슈(SPARK-38230)가 보고돼 있으니 가능하면 정적 파티션 삽입을 사용하는 편이 좋을 것 같습니다.
INSERT OVERWRITE TABLE user_table PARTITION (dt, region)
SELECT
...,
dt,
regionORC와 Parquet
ORC와 Parquet는 Apache에서 지원하는 프로젝트로 열 기반(columnar) 데이터 저장 방식의 일종입니다. 열 기반 데이터 저장 방식을 이용하면 데이터베이스에서 효율적으로 질의할 수 있도록 데이터를 저장할 수 있습니다.
LINE에서 전사에 데이터를 제공하는 조직은 주로 ORC 포맷을 사용해 오고 있었기에 spark.sql.hive.convertMetastoreOrc 옵션을 설명했는데요. Parquet 포맷을 사용하신다면 spark.sql.hive.convertMetastoreParquet 옵션을 적용하시면 됩니다.
Command
Spark 작업 실행 단위입니다(참고). Spark에서는 하나의 쿼리가 여러 개의 Command로 나뉘어 순차적으로 실행되는 방식으로 쿼리가 수행됩니다. 저희는 Hive 테이블에 데이터를 삽입하는 쿼리를 사용하다 보니 데이터를 작성하는 DataWritingCommand의 일종인 InsertIntoHadoopFsRelationCommand와 InsertIntoHiveTable, 이 두 가지 Command의 차이를 살펴볼 예정입니다.
일반적으로 INSERT OVERWRITE TABLE 쿼리는 InsertIntoHadoopFsRelationCommand를 사용해 적재하는데요. spark.sql.hive.convertMetastoreOrc 옵션이 false로 설정된 경우 InsertIntoHiveTable을 사용합니다. 두 Command 모두 SQLHadoopMapReduceCommitProtocol 및 FileOutputCommitter를 이용해 데이터를 적재합니다.
참고로 테이블을 Hive 테이블이 아니라 Data source 형태로 선언(참고)하면 InsertIntoHiveTable을 이용하지 않습니다.
SparkSQL 사용 시 쿼리가 실행되지 않거나 결과가 잘못 나오는 다섯 가지 현상 소개
SparkSQL을 사용하면서 쿼리가 실행되지 않거나 결과가 잘못 나오는 등 HiveQL 사용자가 이상하다고 생각할 수 있는 다섯 가지 현상을 소개하겠습니다. 설명은 각 현상을 소개하고 재현 방법과 원인, 대응 방법, 참조 자료를 공유하는 순으로 진행합니다.
쿼리 실행 후 일부 결과 누락 현상
앞서 소개한 내용으로 이 조사를 시작한 계기이기도 합니다. 정상적으로 쿼리가 실행됐지만 일부 결과가 누락돼 적재됩니다.
재현 방법
spark.sql.hive.convertMetastoreOrc: true로 설정하고 정적 파티션 삽입으로 서로 다른 파티션에 데이터를 삽입하는 쿼리를 동시에 두 개 이상 실행합니다. 예를 들어 아래 두 가지 잡을 동시에 수행합니다(잡 개수가 많아질수록 재현 가능성이 높아집니다).
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT ...원인
두 잡은 _tempoarary/라는 작업 영역을 공유합니다. 이때 먼저 작업을 끝낸 잡이 공유 작업 영역인 _temporary/ 디렉터리를 삭제해서 다른 잡의 중간 결과물을 삭제합니다. 이에 따라 나중에 끝나는 잡의 결과가 유실될 가능성이 발생합니다.
대응 방법(택 1)
아래 두 가지 방법 중 하나를 적용합니다.
spark.sql.hive.convertMetastoreOrc: false로 설정- 동적 파티션 삽입으로 쿼리 변경
spark.sql.hive.convertMetastoreOrc: false 설정 시 사용하는 InsertIntoHiveTable은 InsertIntoHadoopFsRelationCommand와 다르게 .hive-staging으로 시작하는 전용 작업 영역 디렉터리를 생성합니다.
SQLHadoopMapReduceCommitProtocol에서는 동적 파티션 삽입의 경우 .spark-staging으로 시작하는 전용 작업 영역 디렉터리를 생성하고, FileOutputCommiter는 그 이후 _temporary 디렉터리를 생성합니다.
방법은 다르지만 둘 중에 하나 이상을 적용하면 잡별로 독립적인 작업 영역이 생성되기 때문에 문제가 발생하지 않습니다.
참조
파티션 디렉터리 밑에 서브 디렉터리가 존재할 때 데이터를 읽을 수 없는 현상
HDFS의 파티션 디렉터리 하위에 서브 디렉터리가 존재하는 경우 서브 디렉터리에 위치한 파일을 읽을 수 없습니다.
재현 방법
Hive에서 UNION ALL을 이용해 결과를 적재하면 서브 디렉터리 아래에 데이터를 저장합니다. 이때 spark.sql.hive.convertMetastoreOrc: true로 설정하고 파티션 디렉터리 아래 서브 디렉터리가 존재하는 데이터를 대상으로 쿼리를 실행하면 이 현상이 발생합니다.
SELECT * FROM target_table WHERE dt = '2023-01-01'
-- readable
-- viewfs://hive/target_table/dt=2023-01-01/file.orc
-- unable to read
-- viewfs://hive/target_table/dt=2023-01-01/_part1/file.orc원인
SPARK-28098로 버그가 보고됐지만 아직 수정되지 않았습니다.
대응 방법
spark.sql.hive.convertMetastoreOrc: false로 설정하면 Spark의 Native ORC Reader를 사용하지 않고 Hive의 reader를 사용하기 때문에 문제가 발생하지 않습니다.
참조
잡이 실행될 때 파티션 디렉터리를 삭제해서 해당 파티션을 이용하는 쿼리가 실패하는 현상
특정 파티션을 백필하면 잡이 시작하는 시점에 파티션 디렉터리가 삭제돼 잡이 완료될 때까지 해당 파티션을 이용할 수 없습니다.
재현 방법
spark.sql.hive.convertMetastoreOrc: true로 설정하고, 정적 파티션 삽입으로 백필 잡을 실행한 뒤, 해당 잡이 데이터를 쓰는 파티션을 읽으려고 시도하면 이 현상이 발생합니다. 예를 들어 아래와 같은 쿼리로 Job 1을 실행하고 바로 Job 2를 실행합니다.
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
SELECT COUNT(*) FROM target_table WHERE dt = '2023-01-01'원인
InsertIntoHadoopFsRelationCommand가 정적 파티션 삽입 모드로 실행될 때 잡을 실행하기 전에 파티션 디렉터리를 삭제하기 때문입니다. 예를 들어 아래 그림을 보면 Job 1이 시작하면서 데이터를 삭제했는데 Job 2가 화살표 시점에서 데이터를 읽으려고 시도하면 실패합니다.

대응 방법(택 1)
아래 두 가지 방법 중 하나를 적용하면 데이터 작성이 완료된 후 파티션 디렉터리에 덮어쓰기 때문에 항상 데이터를 읽을 수 있습니다.
spark.sql.hive.convertMetastoreOrc: false로 설정- 동적 파티션 삽입으로 쿼리 변경
참조
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L127-L132
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L220-L224
한 파티션에서 데이터를 읽어 같은 테이블의 다른 파티션에 쓸 때 AnaylsisException("Cannot overwrite a path that is also being read from") 발생
LINE에서는 일별로 적재한 스냅숏 테이블을 만들어 활용합니다. 전날 스냅숏과 그날 발생한 이벤트를 합쳐 새로운 스냅숏을 다른 파티션으로 적재하는데요. 이때 AnaylsisException이 발생하는 문제가 있었습니다.
재현 방법
spark.sql.hive.convertMetastoreOrc: true로 설정하고 정적 파티션 삽입으로 한 파티션에서 데이터를 읽어 같은 테이블의 다른 파티션에 쓰면 이 현상이 발생합니다.
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT * FROM target_table WHERE dt = '2023-01-01'원인
InsertIntoHadoopFsRelationCommand가 정적 파티션 삽입으로 실행될 때 실행 전에 읽는 주소가 쓰는 주소를 포함하는지 확인하기 때문입니다. 이 확인 로직은 앞서 소개한 '잡이 실행될 때 파티션 디렉터리를 삭제'한다는 구현 때문에 자기 자신을 지우지 않도록 예방하기 위해 구현해 놓은 것 같습니다.
대응 방법(택 1)
아래 두 가지 방법 중 하나를 적용하면 앞서 말한 주소 관련 검사를 하지 않기 때문에 문제가 발생하지 않습니다.
spark.sql.hive.convertMetastoreOrc: false설정- 동적 파티션 삽입으로 쿼리 변경
참조
결과가 중복돼 두 배로 적재되는 현상
특정 테이블에 데이터가 중복돼 정확히 두 배로 적재된 경우가 있었습니다. 문제가 발생했을 때에는 원인을 바로 찾지 못했지만 다른 문제들의 원인을 추적하다가 원인을 발견할 수 있었습니다.
재현 방법
spark.sql.hive.convertMetastoreOrc: true 설정일 때 정적 파티션 삽입으로 아래와 같이 동일한 쿼리를 비슷한 시간에 실행합니다.
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...원인
InsertIntoHadoopFsRelationCommand가 정적 파티션 삽입으로 실행될 때 결과를 적재하는 시점에 덮어쓰지 않아서 이런 현상이 발생합니다.

앞서 소개한 '잡 실행될 때 파티션 디렉터리를 삭제'하는 이슈와 연결해 보면, 먼저 데이터를 삭제했기 때문에 결과를 적재하는 시점에 덮어쓰지 않도록 구현한 것 같습니다. 보통 이렇게 쿼리를 실행할 일은 없을 텐데요. 혹시 실수로 수행했다면 그 상황에서 결과가 중복 적재될 것이라고 예상하긴 어렵습니다.
대응 방법(택 1)
아래 세 가지 방법 중 하나를 선택해 대응합니다.
spark.sql.hive.convertMetastoreOrc: false로 설정- 동적 파티션 삽입으로 쿼리 변경
- 이런 실수를 저지르지 않기 😊
참조
저희가 선택한 대응 방법
앞서 다섯 가지 현상에 대응하는 방법으로 대부분 아래 두 가지 방법을 안내해 드렸습니다.
spark.sql.hive.convertMetastoreOrc: false설정 사용- 동적 파티션 삽입으로 쿼리 변경
저희는 두 방법 중 spark.sql.hive.convertMetastoreOrc: false 설정 사용을 선택했습니다. 이전에 Hive에서 생성된 파일도 문제없이 읽을 수 있어야 하기 때문에 하위 호환성을 보장하기 위한 선택이었는데요. Spark에서는 이 설정을 권장하지는 않는 것 같습니다. 이 설정을 사용할 때 이용하는 InsertIntoHiveTable Command 코드의 주석을 보면 Hive 코드에 대한 상당한 불만이 적혀 있기 때문입니다. 이 점 참고하시기 바랍니다.
마치며
Hive 제거라는 큰 목표를 달성하기 위한 첫걸음으로 오픈챗 제품 쿼리를 Hive에서 Spark로 전환하는 과제를 진행했고, 100개가 넘는 쿼리를 Spark로 옮겼습니다. Spark 초보들이 모여서 과제 중 발생하는 각종 문제를 해결하기 위해 이상 현상을 분석하고 원인을 추적했는데요. 그 과정에서 Spark 내부 동작을 일부 이해할 수 있었습니다.
앞서 작업 시작 배경을 설명하며 팀에서 다루는 도메인이 오픈챗 외에도 많다고 말씀드렸습니다. 저희는 오픈챗 외에도 현재 담당하고 있는 여러 도메인의 수백 개에 달하는 모든 쿼리를 연내 전부 Spark로 이전할 계획입니다. 동시에 Iceberg와 같은 새 기술을 도입하는 과제도 진행하고 있는데요. 향후 기회가 된다면 관련 내용을 다시 블로그에서 소개하겠습니다.
이 글이 혹시 Spark를 이용하면서 비슷한 문제를 겪고 계신 분들께 도움이 되면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.