
はじめに
こんにちは。LINE Plus Messaging Data Eng Dev (NP)チームのデータエンジニア Jeong Woo-Yeongです。HiveQL(Hive SQL)プロセスをSpark SQLに移行する課題に取り組んでいます。主に、INSERT OVERWRITE TABLEというSQL文を使ってデータを格納しましたが、Sparkの設定によって、Hiveではみられなかったさまざまな現象が発生しました。この記事では、その原因と解決方法を探す過程で分かったことを紹介します。
まず、作業を始めることになった背景と作業環境を紹介し、HiveQLからSpark SQLに移行した過程を共有し、Sparkの設定によって発生したさまざまな現象と各現象の再現方法や原因と対応方法について説明します。
作業の背景、対象、および環境
作業の背景
まず、今回の作業を始めることになった背景を紹介します。LINEのデータ環境を管理するデータプラットフォーム室では、これまで使用してきたHiveの使用を段階的に停止してSpark環境に移行するという方針となりました。Hiveのコミュニティが徐々に縮小してデプロイのサイクルも長くなり次第に非アクティブになっている一方で、以前から定着したSparkは実行スピードも速く新しい技術とも連携させやすいという特徴があります。
すでに社内でも多くの組織でSparkを使っていましたが、私たちのチームは開発してからかなり時間が経過しているレガシーコードをたくさん運用していたため、多くのコードがHiveで動いていました。データプラットフォーム室と協業していた私たちのチームは、データプラットフォーム室が新たな方針を全社向けに告知する前に先にSparkへの移行を試みました。
作業の対象
Messaging Data Eng Dev (NP)チームはLINEのさまざまな製品のデータに対する、いわゆるETL(Extract, Transform, Load)作業を担当しています。ユーザー情報やユーザー間の関係情報といったLINEコアデータの一部や、会社のさまざまな製品を全社的な観点から共通化した形で分析してKPIを集計するLINE ユーザーの行動データやKPIフレームワークデータなど多様な製品のデータ作成の責任を担っています。
担当するデータにはLINEが提供開始となった当初からのコアデータが含まれるため、10年以上メンテナンスしている古いコードもあります。多くの組織が私たちが作成するデータの影響を受けるため、一貫したデータであることを決められた時間で安定的に提供する方法を探していました。したがって、プラットフォームレベルで要求されなくてもデータをより迅速かつ安定的に提供できるのであれば、Sparkの導入が望ましく、この目標を達成するための第一段階としてオープンチャット製品に対するすべてのデータ作成クエリをHiveQLからSpark SQLに移行する課題に小規模のTFで取り組みました。
オープンチャットのクエリのうち、HiveQLで作成されたのは100個余りでしたが、課題に参加したチームメンバーがすべてを処理するには数が多かったため、Spark SQLを導入する過程で発生するイシューを解決しながら、TFに参加していないチームメンバーも機械的にSpark SQLに移行できるように準備しました。
作業の環境
私たちはAirflowでTaskを作ってクエリを実行し、各Task間の関係をDAG(Directed Acyclic Graph)を作って管理します。通常1つのクエリを1つのTaskとして構成し、各Task間の前後関係を調整するためにDAGを使用します。
AirflowでSpark SQLを実行する際には、Airflowが提供するSparkSqlOperatorやSparkSubmitOperatorを使用しますが、私たちは、以下の2つの理由でSparkSubmitOperatorを用いて別途のOperatorを開発して使用しました。
- LINEのコアデータとメッセージングプラットフォームのデータはサイズが非常に大きいため、クラスターモードを使用することが望ましく、クエリをSparkのクラスターモードで実行したい。
- チームで使用するインターフェイスとの互換性を保ちたかった。互換性を保てば、クエリに問題さえなければデータのエラーを防ぐための前処理と後処理のコードをそのまま使用し、実行するエンジンの明細だけをHiveからSparkに変更するだけでエンジンの移行ができるため。前述のとおり課題に参加していないチームメンバーの助けが必要なため、同じインターフェースを作って提供した。
別途開発したOperatorは、明細に書かれたクエリをJinjaテンプレートエンジンに注入し、PySparkアプリケーションを動的に作成した後、Sparkクラスターに提出して実行します。ユーザーは明細さえきちんと作成すれば、Sparkに関する知識がなくてもSparkアプリでクエリを実行できます。
実行環境を構成する際に重要視していたのは、Taskが行われるすべての状況をAirflow UIから確認できるようにすることでした。クラスターモードを使用すると、アプリのログがAirflow Taskの実行されるノードに残らず、遠隔のドライバーノードに残ります。このログをすぐに確認する手段がないと不便なので、Sparkアプリが終了すると遠隔地に保存されたアプリのログを取得して有意な部分を抽出した後、Airflowログに出力しました。これにより、ユーザーはAirflow UIを見るだけですべての状況が把握でき、Sparkアプリが異常終了した場合、ログを見て発生した例外を分析して問題の原因を抽出することで、オンコール(on-call)担当者が直ちに状況を把握できるようにしました。AirflowでTaskを中断する際には、提出されたSparkアプリを遠隔で終了した後、ログを取得してAirflowに出力するため、Operatorユーザーはどんな状況であっても、Airflow UIを確認するだけですべての状況が把握できます。
このように、別途のOperatorを開発しながら、どんな試みをしてどのように最適化したのかについて機会があれば別の記事でより詳しく紹介します。
HiveQLからSpark SQLへの移行
それでは、HiveQLからSpark SQLへの移行方法と移行作業後の評価方法を紹介し、単純にエンジン交換では足りずクエリを変更することになったいくつかの事例を見てみましょう。
HiveQLからSpark SQLへの移行方法
Spark SQLを実行する環境はすでに構築されていたため、まずはエンジンだけを変更して実行した後、Hiveで作成したデータとSparkで作成したデータが一致するかどうかを確認する方式で移行作業を進めました。問題がある場合はそれに合わせてクエリを変更しましたが、変更を必要とすることはそれほど多くありませんでした。
移行作業後の結果評価ーデータが同一であるかの確認と実行性能の比較
エンジンをSparkに変更したとき、Hiveと同じ成果物を作り出しているか確認しさらに実行性能も確認しました。同じ成果物を作り出すのにより多くのリソースを使用したり、時間が長くかかったりすると問題になることがあるからです。
データが同一であるか確認する方法
成果物が一致するかどうかを確認する際は差集合が空集合であり、かつ両方の個数が同一であるかを確認するコードを使用しました。以下は、サンプルコードです。差集合を確認して両方で作成したデータが同一であるかを確認し、重複の発生有無を確認するために個数が同一であるかを確認します。
WITH tobe AS (
SELECT *
FROM spark_table
WHERE dt = '2023-01-01'
),
asis AS (
SELECT *
FROM hive_table
WHERE dt = '2023-01-01'
)
SELECT '1. asis_cnt' AS label, COUNT(*) AS cnt FROM asis
UNION ALL
SELECT '2. tobe_cnt' AS label, COUNT(*) AS cnt FROM tobe
UNION ALL
SELECT '3. asis - tobe cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM asis EXCEPT SELECT * FROM tobe) AS diff1
UNION ALL
SELECT '4. tobe - asis cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM tobe EXCEPT SELECT * FROM asis) AS diff2厳密に言うと、上記のクエリは集合{1、2、2、3}と集合{1、2、3、3}を比較するときのように互いに異なるタイプの重複がある場合は、当該重複を見つけることができません。ただし、業務の特性上、このような重複が発生する可能性が低かったため、上記の検証方法を使用しました。
実行性能を確認する方法
実行性能を評価する指標としては、実行時間と「vCore-seconds」、「mb-seconds」を使用しました。YARNにおけるvCore-secondsとmb-secondsは、それぞれのアプリケーションを実行するために使用した1秒あたりのvCoreと1秒あたりのメモリー使用量を累積した指標です。言い換えると、アプリケーションを実行するために使用したリソースの量です。実行時間はクエリを実行するexecutorの数の影響を受ける可能性があるため、vCore-secondsとmb-secondsを共に参照する方が良いと判断しました。
エンジンをSparkに変更してから、実行時間を見ると平均15%ほど速くなり、vCore-secondsとmb-secondsはクエリが複雑になるほど減少するパターンが現れました。半分以上減ったケースもありました。
クエリを変更した事例
単純に実行するクエリは、エンジンを交換することでほとんど大きな問題なく移行でき、Hiveで使用していたUDF(user-defined function)も組み込みのUDFと直接実装したUDFいずれもほとんど互換性がありました。その他、明示的にクエリを変更したケースを見てみましょう。
一時テーブルを使用したケース(CREATE TEMPORARY TABLE)
SparkではHiveで使用していた一時テーブル(temporary table)という概念が存在しません。似たような用途で使用できる一時ビュー(temporary view)が存在します。Hiveの一時テーブルはデータをフィルタリングして一時的に保存したり、最初から新しいデータを一時的に定義したテーブルに挿入したりする時に使うことができましたが、Sparkの一時ビューはデータを挿入できないという違いがありました。そこで、探した代案は次の通りです。
- CREATE TEMPORARY VIEWまたはCACHE TABLE文を使用
- 一時テーブルを使用する代わりにCommon Table Expression(CTE)に変更
- 物理テーブルを作成して使用後に削除
- DataFrameを使用
CACHE TABLEは、実行結果がキャッシュされる一時ビューとして見ることもできます(参考)。CREATE TEMPORARY VIEWで作成された一時ビューは複数回使用すると同じ計算を繰り返すため、データが再利用されるかを確認して用途に合わせて選択しました。WITH節で表現されるCTEは中間結果を保存するために使用されますが、今回のプロジェクトを進める中で、CTEに変更できないケースは数えるほどしかありませんでした。このため、似たような悩みをお持ちでしたら、まずCTEに変更してみることをお勧めします。
ANSIポリシーに違反する暗黙的な型変換を使用したケース(Store Assignment Policy)
Spark 3.0バージョンでポリシーが変更され、Spark SQLがANSIポリシーに違反するデータ型変換をブロックします。たとえば、bigintで定義された列にstringを挿入する事例を見てみましょう。このように許されない暗黙的な型変換で発生するエラーは、CAST(value AS BIGINT)のように明示的な型変換に変更して問題を解決しました。
使用していたUDFに問題があるケース
ほとんどのUDFに互換性があると説明しましたが、以下のように一部の組み込みのUDFでは問題がありました。
- get_json_object
- HiveとSparkいずれも組み込み関数が完璧ではありませんでした。特に重複したJSONを処理するとき、エンジンごとにJsonPath処理結果が異なっていました。
- parse_url
以下のサンプルクエリと共にget_json_object UDFの問題をもう少し見てみましょう。
WITH sample_data AS (
SELECT
stack(3,
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}, {"users": [{"id": "c"}]},{"users": [{"id": "d"}]}]}',
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}]}',
'{"groups":[{"users": [{"id": "a"}]}]}'
) AS (json_string)
)
SELECT
get_json_object(json_string, '$.groups[*].users[*].id')
FROM sample_data| Hive | Spark | 期待値 | |
| 1 | ["a","b","c","d"] | [["a","b"],["c"],["d"]] | ["a","b","c","d"] |
| 2 | ["a","b"] | ["a","b"] | ["a","b"] |
| 3 | a | ["a"] | ["a"] |
この問題のためSparkの組み込みUDFに置き換えることができない場合は、Hiveの組み込みUDFをCREATE TEMPORARY FUNCTIONで読み込んで使用しました。
新たなUDFを導入したケース
SparkはHiveよりも多くの組み込みUDFを提供します。新たに導入したUDFの一部を紹介します。
- approx_count_distinct
- 計算量の多いカーディナリティ(cardinality, unique/distinct count)を求める代わりに、迅速に計算できるカーディナリティ推定値を求めます。
- count_if
- 条件付きで個数を数える関数です。
- max_by/min_by
- 特定の列から最大値または最小値の行を見つけて、その行の別の列を取得します。
- timestamp_millis
- Unix時間とタイムスタンプとの間で変更が頻繁にありましたが、その時に役立ちました。
- Unix時間とタイムスタンプとの間で変更が頻繁にありましたが、その時に役立ちました。
マップタイプに集合演算を使用したケース
SPARK-18134で報告されたイシューで、キーの値を自在に格納できるマップ(map)タイプを使用する場合、SparkではHiveとは違って重複を削除する集合(set)演算は使用できません。集合演算には、DISTINCT、UNION、INTERSECTなどがあり、私たちはmap<string, string>列の重複を削除するためにDISTINCTキーワードを使用していましたが、次のように迂回して解決しました。
-- Hive
SELECT DISTINCT a, b, m FROM table
-- Spark
WITH to_array AS (
SELECT DISTINCT a, b, sort_array(map_entries(m)) AS entry FROM table
)
SELECT a, b, map_from_entries(entry) FROM to_arrayまた、マップを扱っていると、すでにマップに入っているキー値ペアを重複して挿入する場合があります。Sparkではこの時に例外が発生しますが、許容できる場合は、spark.sql.mapKeyDedupPolicy=LAST_WINで設定すると、この問題を解決できます。
複数のパーティションを削除すべきケース
SPARK-14922で報告されたイシューで、ALTER TABLE文で範囲を指定してパーティションを削除できません。これにより、データの保存期限という概念を実装するために使用していた以下のようなクエリが使用できなくなりました。
ALTER TABLE table DROP PARTITION (dt <= '2023-01-01') この問題は、パーティションのリストを照会した後、巡回しながら一つずつ削除する別途インターフェイスを実装することで解決しました。
HiveQLからSpark SQLに移行した結果
Sparkへの移行によって、すべてのクエリを再レビューし、バグを修正して最適化することができました。また、成果物をより迅速に作ってリソースを削減できるように改善し、新たなUDFを導入してコード量を減らした事例もありました。
HiveQLからSparkへの移行中に遭遇したトラブルシューティング事例
HiveからSparkに移行してから、特定の状況で特定のデータが欠落する現象が発生しました。この問題を解決するために、実験環境を構築して現象を再現しながら原因を把握しました。原因を把握した後、単に問題が発生しないように措置するだけでなく、根本的な原因を把握するために関連するSparkコードを読み解いてみました。その結果、データの欠落イシューだけでなく、それ以外のいくつかの問題を説明できる根本的な原因を見つけることができました。どんな事例だったのか詳しくみてみましょう。
Spark移行後にデータの欠落が発生
ある日、メッセンジャーを通じて特定の日別KPI数値が普段より15%減少したという問い合わせが入ってきました。経験上、このようにデータが欠落する現象は、主に先行データが完成する前にクエリを実行した時に発生していました。たとえば、前の24時間のデータを利用してクエリを実行すべきところ、22時間のデータのみ用意された時にクエリを実行した場合、一部のデータが欠落し、このようにKPIが減少する現象が発生することがあります。
しかし、私たちはすでに前処理の過程でこのような状況が発生しないように備えていたので、この問題はありませんでした。いろいろと検討した結果、Sparkエンジンを使用したこと以外に変更事項はなかったため、ひとまずエンジンをHiveにロールバックしてデータを復元し、原因を追跡しました。
実験環境構築後にデータの欠落発生の原因を調査
追跡の結果、原因は特定データのマートテーブルのデータが欠落していることでした。このような欠落が常に発生するわけではないので、現象を再現するために実験環境を構築し、テストを行いました。
当該テーブルはデータマートを構成するために3つのログソースを利用しますが、次のクエリで作成します。
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_1')
SELECT ... FROM source_1;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_2')
SELECT ... FROM source_2;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_3')
SELECT ... FROM source_3;実験環境でテストを行いながら問題が再現されるケースを分析したところ、ウェブUIのSQLタブに表示された内容とHDFS(Hadoop file system)に実際に保存されているファイル数が異なることが分かりました。
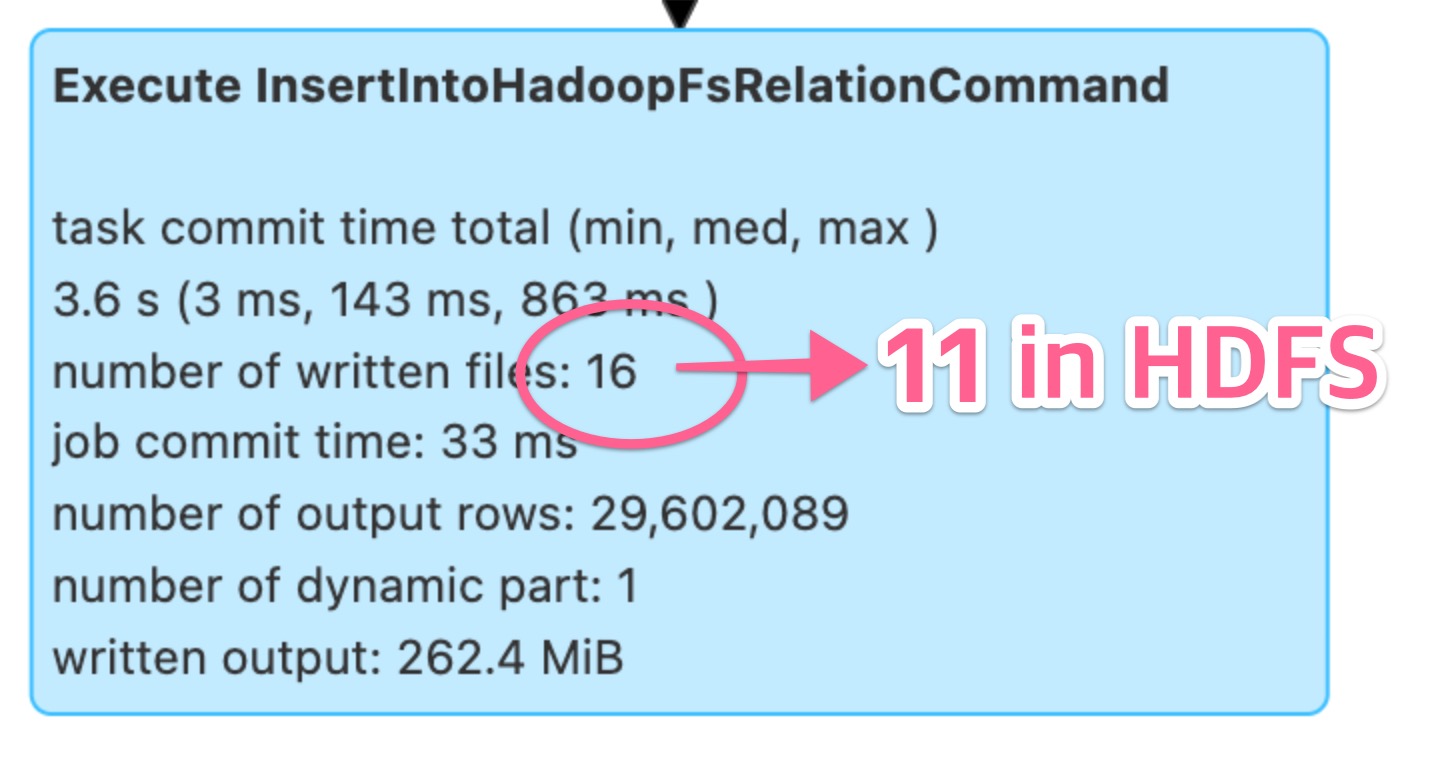
Spark UIには16個と記録されていますが、実際にHDFSには11個だけ保存されていました。
ログを詳しく分析してみると、Sparkアプリの中間作業ファイルが削除されたという内容が見つかり、検索してMAPREDUCE-7331イシューを見つけました。内容を要約すると、同じテーブルに挿入するSparkアプリが同時に2つ以上実行された場合、先に完了したアプリが他のアプリの中間作業物も消してしまい、結果に影響を及ぼす可能性があるというものです。
なぜこのような現象が起きるのかもう少し詳しく見てみましょう。Sparkではテーブルが位置するディレクトリの下に_temporary/という作業領域ディレクトリを作って中間作業物を保存し、すべてのアプリがこの作業領域を共有します。問題はアプリが作業を完了し、一時ファイルを削除するために、すべてのアプリが共有する_temporary/ディレクトリを削除してしまいます。したがって同じテーブルに2つ以上の挿入クエリが同時に実行される場合、データ損失が発生する可能性があります。
この_temporaryという作業領域名は定数としてハードコーディング(参考)されていて、設定では修正できません。検索してみると、_temporaryという名前がハードコーディングされているFileOutputCommitterソースコードを変更してこの問題を解決したという事例が見つかりました。これを参考にして、似たような方法を試してみました。当該値が定義された変数であるPENDING_DIR_NAMEが使用される部分をすべて適切に変更し(アプリごとに独立したディレクトリを作成)、新しく作ったクラスをspark.sql.sources.outputCommitterClass設定に登録してSparkアプリを実行する方法でした。
テストしてみた結果、上記の問題は解決されましたが、このように個別クラスを実装して利用すると管理が難しく検証も簡単ではないため負担になりました。そこで、別の方法を探していたところ、データプラットフォームチームからspark.sql.hive.convertMetastoreOrc:オプションを利用することを勧められました。この設定を使ってみると、アプリごとに独立した作業ディレクトリができて問題が発生しないことが分かりました。
Sparkコードを読み解いて問題の根本的な原因を把握
前述のとおり、私たちが作成したデータは全社に影響を及ぼす可能性があるため、データ障害を防ぐために「単に問題が発生しない」ことに留まらず、「なぜこのような現象が発生するのか」までを説明できる程度まで理解する必要がありました。このため、この設定に関するSparkコードを読み解いてみると、私たちがこれまでに経験したいくつかの現象を一つにまとめて説明できることが分かりました。
トラブルシューティング事例紹介の前に関連用語の説明
どんな現象があったのか紹介する前に、説明で使ういくつかの用語を先に説明します。
静的パーティション挿入(static partition insert)
パーティションが存在するテーブルで、INSERT文にすべてのパーティションを指定して挿入することをいいます。
INSERT OVERWRITE TABLE user_table PARTITION (dt = '2023-01-01', region = 'JP')
SELECT ...動的パーティション挿入(dynamic partition insert)
パーティションが存在するテーブルで、INSERT文でパーティションを決定しないことをいいます。この場合、クエリだけではパーティションを決定できず、値を評価すればパーティションの値が分かります。ちなみに、現在Sparkで動的パーティションを挿入する際、Hive Metastoreに大きな負荷をかける可能性があるという内容のイシュー(SPARK-38230)が報告されているので、できれば静的パーティション挿入を使う方がよいと思います。
INSERT OVERWRITE TABLE user_table PARTITION (dt, region)
SELECT
...,
dt,
region
ORCとParquet
ORCとParquetはApacheがサポートするプロジェクトで、列ベース(columnar)のデータ保存方式の一種です。列ベースのデータ保存方式を使用すると、データベースで効率的に問い合わせできるようにデータを保存できます。
LINEで全社向けのデータを提供する組織は主にORCフォーマットを使用してきたので、spark.sql.hive.convertMetastoreOrcオプションを説明しましたが、Parquetフォーマットを使用している場合は、spark.sql.hive.convertMetastoreParquetオプションを適用してください。
Command
Sparkのタスク実行単位です(参考)。Sparkでは、1つのクエリを複数のCommandに分けて順次実行する方式でクエリが実行されます。私たちは、Hiveテーブルにデータを挿入するクエリを使用しているため、データを作成するDataWritingCommandの一種であるInsertIntoHadoopFsRelationCommandとInsertIntoHiveTable、この2つのCommandの違いについて調べる予定です。
一般的にINSERT OVERWRITE TABLEクエリはInsertIntoHadoopFsRelationCommandを使って格納しますが、 spark.sql.hive.convertMetastoreOrcオプションがfalseに設定されている場合はInsertIntoHiveTableを使用します。どちらのommandもSQLHadoopMapReduceCommitProtocolおよびFileOutputCommitterを使ってデータを格納します。
ちなみに、テーブルをHiveテーブルではなく、Data sourceの形で宣言(参考)すると、InsertIntoHiveTableを使用しません。
SparkSQL使用の際、クエリが実行されなかったり誤った結果が出たりする5つの現象を紹介
SparkSQLを使用する際にクエリが実行されなかったり誤った結果が出たりするなど、HiveQLユーザーがおかしいと思う可能性のある5つの現象を紹介します。各現象を紹介してから、再現方法と原因、対応方法、参照資料の共有という順で説明します。
クエリ実行後に一部の結果が欠落する現象
先ほど紹介した内容でこの調査を始めたきっかけでもあります。クエリは正常に実行されましたが、一部の結果が欠落して格納されます。
再現方法
spark.sql.hive.convertMetastoreOrc: trueに設定し、静的パーティション挿入で相互に異なるパーティションにデータを挿入するクエリを同時に2つ以上実行します。たとえば、以下の2つのジョブを同時に実行します(ジョブ数が多くなるほど再現可能性が高くなります)。
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT ...
原因
2つのジョブは、_tempoarary/という作業領域を共有します。このとき、先に作業を終えたジョブが共有作業領域である_temporary/ディレクトリを削除して、他のジョブの中間成果物を削除します。これにより、後で終わるジョブの結果が損失する可能性が発生します。
対応方法(1つを選択)
以下の2つの方法のいずれかを適用します。方法は異なりますが、どちらもジョブが独立した作業領域を使用するようにするため、問題は発生しません。
- spark.sql.hive.convertMetastoreOrc: falseに設定
- 動的パーティション挿入にクエリ変更
spark.sql.hive.convertMetastoreOrc: false設定時に使用するInsertIntoHiveTableは、InsertIntoHadoopFsRelationCommandと違って .hive-stagingで始まる専用の作業領域ディレクトリを作成します。
SQLHadoopMapReduceCommitProtocolでは動的パーティション挿入の場合、.spark-stagingで始まる専用の作業領域ディレクトリを作成し、FileOutputCommiterはその後、_temporaryディレクトリを作成します。
参照
パーティションディレクトリの下にサブディレクトリが存在する場合、データを読み込むことができない現象
HDFSのパーティションディレクトリ下位にサブディレクトリが存在する場合、サブディレクトリに位置するファイルを読み込むことができません。
再現方法
HiveでUNION ALLを使って結果を格納すると、サブディレクトリの下にデータを保存します。このとき、spark.sql.hive.convertMetastoreOrc: trueに設定して、パーティションディレクトリの下にサブディレクトリが存在するデータを対象にクエリを実行すると、この現象が発生します。
SELECT * FROM target_table WHERE dt = '2023-01-01'
-- readable
-- viewfs://hive/target_table/dt=2023-01-01/file.orc
-- unable to read
-- viewfs://hive/target_table/dt=2023-01-01/_part1/file.orc
原因
SPARK-28098でバグが報告されましたが、まだ修正されていません。
対応方法
spark.sql.hive.convertMetastoreOrc: falseに設定すると、SparkのNative ORC Readerを使用せずにHiveのreaderを使用するので、問題が発生しません。
参照
ジョブ実行時にパーティションディレクトリを削除してしまい、当該パーティションを利用するクエリが失敗する現象
特定のパーティションをバックフィルすると、ジョブの開始時点でパーティションディレクトリが削除され、ジョブが完了するまで当該パーティションを利用できません。
再現方法
spark.sql.hive.convertMetastoreOrc: trueに設定して、静的パーティション挿入でバックフィルジョブを実行した後、当該ジョブがデータを書き込むパーティションを読もうとすると、この現象が発生します。たとえば、以下のクエリでJob 1を実行し、すぐにJob 2を実行します。
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
SELECT COUNT(*) FROM target_table WHERE dt = '2023-01-01'
原因
InsertIntoHadoopFsRelationCommandが静的パーティション挿入モードで実行される時、ジョブを実行する前にパーティションディレクトリを削除するからです。たとえば、下図を見ると、Job 1が開始されてデータを削除したのに、Job 2が矢印の時点でデータを読み取ろうとして失敗します。

対応方法(1つを選択)
以下の2つの方法のいずれかを適用すると、データ作成が完了した後、パーティションディレクトリに上書きするため、常にデータを読み取ることができます。
- spark.sql.hive.convertMetastoreOrc: falseに設定
- 動的パーティション挿入にクエリ変更
参照
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L127-L132
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L220-L224
1つのパーティションでデータを読み取り、同じテーブルの別のパーティションに書き込む時にAnaylsisException(「Cannot overwrite a path that is also being read from」)発生
LINEでは日別に格納したスナップショットのテーブルを作って活用します。前日のスナップショットと当日に発生したイベントを合わせて、新しいスナップショットを別のパーティションに格納します。このとき、AnaylsisExceptionが発生する問題がありました。
再現方法
spark.sql.hive.convertMetastoreOrc: trueに設定して、静的パーティションの挿入で、あるパーティションからデータを読み取り同じテーブルの別のパーティションに書き込むと、この現象が発生します。
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT * FROM target_table WHERE dt = '2023-01-01'
原因
InsertIntoHadoopFsRelationCommandが静的パーティション挿入で実行されるとき、実行前に読み込むアドレスが書き込むアドレスを含むかどうかを確認するからです。この確認ロジックは、先ほど紹介した「ジョブ実行時にパーティションディレクトリを削除」するという実装のため、自分自身を消さないよう予防するために実装しているようです。
対応方法(1つを選択)
以下の2つの方法のいずれかを適用すると、前述したアドレス関連検査を行わないため、問題は発生しません。
- spark.sql.hive.convertMetastoreOrc: false設定
- 動的パーティション挿入にクエリ変更
参照
結果が重複して2倍で格納される現象
特定のテーブルにデータが重複して、ちょうど2倍で格納されたケースがありました。問題が発生した時はすぐに原因を見つけることができませんでしたが、他の問題の原因を追跡していると原因が見つかりました。
再現方法
spark.sql.hive.convertMetastoreOrc: true設定時に静的パーティション挿入で、以下のように同じクエリを近い時間に実行します。
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
原因
InsertIntoHadoopFsRelationCommandが静的パーティション挿入で実行される時に結果を格納する時点で上書きしなかったため、このような現象が発生します。

先ほど紹介した「ジョブ実行時にパーティションディレクトリを削除」するイシューと関連付けてみると、先にデータを削除したため、結果を格納する時点で上書きしないように実装したようです。通常、このようにクエリを実行することはないと思いますが、万一、誤って実行した場合、その状況で結果が重複格納されると想定するのは難しいです。
対応方法(1つを選択)
以下の3つの方法のいずれかを選択して対応します。
- spark.sql.hive.convertMetastoreOrc: falseに設定
- 動的パーティション挿入にクエリ変更
- こんな間違いを犯さないこと
参照
私たちが選択した対応方法
前述のとおり、5つの現象に対応する方法として、ほとんどの場合で以下2つの方法を案内しました。
- spark.sql.hive.convertMetastoreOrc: false設定の使用
- 動的パーティション挿入にクエリ変更
私たちは、2つの方法のうちspark.sql.hive.convertMetastoreOrc: false設定の使用を選択しました。以前にHiveで作成されたファイルも問題なく読み取る必要があるため、下位互換性を確保する選択でしたが、Sparkではこの設定を推奨していないようです。この設定を使用する際に利用するInsertIntoHiveTable Commandコードの注釈を見ると、Hiveコードに対する相当な不満が書かれているからです。この点をご参考ください。
おわりに
Hive依存性の除去という大きな目標を達成するための第一歩として、オープンチャット製品のクエリをHiveからSparkに切り替える課題に取り組み、100個以上のクエリをSparkに移しました。Spark初心者が集まり、課題中に発生する各種問題を解決するために、異常現象を分析して原因を追跡しましたが、その過程でSparkの内部動作を一部理解できました。
作業の開始背景を説明した際、チームで扱うドメインがオープンチャット以外にも多いとお話しました。私たちはオープンチャットの他にも、現在担当しているさまざまなドメインの数百個に達するすべてのクエリを年内にSparkへ移行する計画です。同時に Icebergのような新しい技術を導入する課題も進めています。今後、機会があれば関連内容をまたブログで紹介します。
この記事がSparkを利用しながら同じような問題を抱えてる方の助けになればと思います。長い記事を読んでいただき、ありがとうございました。