
Hello. I'm Woo-yeong Jeong, a data engineer from the LINE Plus Messaging Data Eng Dev (NP) team. Recently, I've been working on a task to migrate HiveQL (Hive SQL) jobs to Spark SQL. I primarily used the SQL statement INSERT OVERWRITE TABLE to load data. However, depending on the Spark settings, several issues occurred that did not happen in Hive. In this article, I will introduce what I learned in the process of finding the cause and solution.
This article will first introduce the background and work environment where I started the task, share the process of migrating from HiveQL to Spark SQL, and then examine the various issues that occurred depending on the Spark settings, and the reproduction methods, causes, and countermeasures for each issue.
Background
First, let me introduce the background of this project. The Data Platform Division at LINE has decided to gradually phase out the use of Hive, which we've been using for a while, and migrate to a Spark environment. This decision was made because the Hive community is gradually shrinking and the release cycle is getting longer, leading to Hive losing popularity. On the other hand, Spark, which has been the trend for a long time, is faster and more advantageous when integrating new technologies.
Many organizations within the company were already using Spark, but our team was still operating a lot of old legacy code, so a lot of code was still running on Hive. Our team, which was closely collaborating with the Data Platform Division, attempted to migrate to Spark before the Division announced the new direction to the entire company.
The issue
The Messaging Data Eng Dev (NP) team is responsible for the so-called ETL (Extract, Transform, Load) operations for various product data at LINE. We handle the production of data for various products, including some of LINE's core data like user information and user relationship data, messaging data, OpenChat data, and data from various company products in a unified form for company-wide analysis and KPI aggregation, as well as LINE User Activity Analytics and KPI framework data.
Since our data includes messaging data, which was the start of LINE, we have some code that we've been maintaining for over 10 years. Many data organizations are influenced by the data we produce, so we were looking for a way to consistently provide stable data at the promised time. Therefore, even if it wasn't required at the platform level, it was desirable to introduce Spark if we could provide data more quickly and stably. As a first step to achieve this goal, we carried out a small-scale task force to migrate all data production queries for the OpenChat product from HiveQL to Spark SQL.
There were about 100 queries for OpenChat written in HiveQL. Since this was a large number for all the team members involved in the project to handle, we prepared so that even team members not participating in the task force could mechanically migrate to Spark SQL while resolving issues that arise during the introduction of Spark SQL.
Our working environment
We create tasks in Airflow to run queries and manage the relationships between each task using a DAG (directed acyclic graph). Typically, one query is composed into one task, and we use a DAG to adjust the relationship between each task.
When running Spark SQL in Airflow, we typically use the SparkSqlOperator or SparkSubmitOperator provided by Airflow. However, for the following two reasons, we've developed and utilized a separate Operator that draws from SparkSubmitOperator:
-
We wanted to run queries in Spark's cluster mode because LINE's core data and messaging platform data are very large, making it desirable to use cluster mode.
-
We wanted to maintain compatibility with the interface used by our team. By maintaining compatibility, we could change the engine specification from Hive to Spark while using the same preprocessing and post-processing code to prevent data errors, as long as there were no problems with the query. As mentioned earlier, we needed help from team members not participating in the project, so we provided the same interface.
The separately developed Operator injects the query written in the specification into the Jinja template engine, dynamically generates a PySpark application, and submits it to the Spark cluster for execution. Users can execute queries as Spark apps without knowing about Spark as long as they write the specifications correctly.
One important thing we considered when setting up the execution environment was that all situations in which a task progresses should be visible in the Airflow UI. As I mentioned earlier, when using cluster mode, the app log doesn't stay on the node where the Airflow Task is running, but on a remote driver node. Because it would be inconvenient if there was no immediate way to check this log, we fetched the remotely stored app log after the Spark app finished, extracted the meaningful part, and output it to the Airflow log. This way, users can understand all situations just by looking at the Airflow UI, and if the Spark app terminates abnormally, the on-call team member can immediately understand the situation by interpreting the exceptions that occurred from the log. When Airflow stops a task, it remotely terminates the submitted Spark app and fetches the log for output to Airflow, so the Operator user can understand all situations just by checking the Airflow UI.
I will introduce in more detail what attempts were made and how they were optimized during the development of this separate Operator in another article if I have the opportunity.
Migrating to Spark SQL from HiveQL
Now, let's look at how we migrated from HiveQL to Spark SQL, how we evaluated the migration, and some cases where we had to change the query because simply switching engines wasn't enough.
How we migrated from HiveQL to Spark SQL
Since the environment to run Spark SQL was already set up, we first proceeded with the migration by just changing the engine, running it, and then checking if the data created by Hive matched the data created by Spark. If there were any problems, we adjusted the query accordingly. However, there weren't many cases where changes were needed.
Evaluation of results after the migration
We checked whether changing the engine to Spark produced the same results as Hive, and also evaluated its performance. This is because if it uses more resources or takes longer to produce the same results, it could be a problem.
Verification of data consistency
When verifying if the results matched, we used code to check if the difference set is an empty set and if both sides have the same count. Below is an example of the code. We check the difference set to confirm if the data created on both sides is identical, and we also check if the counts are the same to verify if there are any duplicates.
WITH tobe AS (
SELECT *
FROM spark_table
WHERE dt = '2023-01-01'
),
asis AS (
SELECT *
FROM hive_table
WHERE dt = '2023-01-01'
)
SELECT '1. asis_cnt' AS label, COUNT(*) AS cnt FROM asis
UNION ALL
SELECT '2. tobe_cnt' AS label, COUNT(*) AS cnt FROM tobe
UNION ALL
SELECT '3. asis - tobe cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM asis EXCEPT SELECT * FROM tobe) AS diff1
UNION ALL
SELECT '4. tobe - asis cnt' AS label, COUNT(*) AS cnt FROM (SELECT * FROM tobe EXCEPT SELECT * FROM asis) AS diff2Strictly speaking, the above query can't detect certain types of duplicates, such as when comparing the set {1, 2, 2, 3} with the set {1, 2, 3, 3}. However, due to the nature of our work, the likelihood of such duplicates occurring was low, so we used this verification method.
Verification of performance
We used execution time, vCore-seconds, and mb-seconds as metrics to evaluate performance. In YARN, vCore-seconds and mb-seconds are cumulative indicators of the amount of vCore and memory used per second to run the application, respectively. In other words, these are measures of the resources used to run the application. As the execution time can be influenced by the number of executors running the query, we thought it would be good to refer to vCore-seconds and mb-seconds as well.
After changing the engine to Spark, we found that the execution time was on average about 15% faster, and vCore-seconds and mb-seconds showed a decreasing pattern as the complexity of the query increased. In some cases, they were reduced by more than half.
Queries we had to change
Most of the simple queries could be migrated without major problems just by replacing the engine, and the UDFs (user-defined functions) we used in Hive were mostly compatible, both the built-in UDFs and the ones we implemented ourselves. Now, let's look at the cases where we explicitly changed the query.
Cases where temporary tables were used (CREATE TEMPORARY TABLE)
The concept of temporary tables that we used in Hive doesn't exist in Spark. There is a temporary view that can be used for similar purposes. Hive temporary tables were useful for temporarily storing filtered data or inserting completely new data into a temporarily defined schema, but the difference with Spark temporary views is that you can't insert data. Here are some alternatives we found.
- Use
CREATE TEMPORARY VIEWorCACHE TABLEstatements - Replace temporary tables with CTEs (Common Table Expressions)
- Create and use a physical table, then delete it afterwards
- Use DataFrame
CACHE TABLE can be seen as a temporary view where the execution results are cached (excerpt of Spark source code for reference). The temporary view created with CREATE TEMPORARY VIEW repeats the same calculations if used multiple times, so we selected it based on whether the data was being reused. CTEs, expressed with the WITH clause, are used to store intermediate results. There were very few cases in this project where it was impossible to switch to CTE. Therefore, if you're having similar considerations, we recommend trying to switch to CTE first.
Cases where implicit type conversion that violates the ANSI policy is used (Store Assignment Policy)
With the policy change in Spark 3.0, Spark SQL now blocks data type conversions that violate ANSI policy. For example, consider the case of inserting a string into a column defined as bigint. We resolved issues arising from such disallowed implicit type conversions by changing to explicit type conversions, like CAST (value AS BIGINT).
Cases where there was a problem with the UDF being used
As mentioned earlier, most UDFs were compatible, but there were problems with some of the built-in UDFs, as follows.
get_json_object- Neither Hive nor Spark had perfect built-in functions. Especially when dealing with nested JSON, the
JsonPathprocessing results varied depending on the implementation.
- Neither Hive nor Spark had perfect built-in functions. Especially when dealing with nested JSON, the
parse_url
Let's take a closer look at the get_json_object UDF issue with the example query below.
WITH sample_data AS (
SELECT
stack(3,
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}, {"users": [{"id": "c"}]},{"users": [{"id": "d"}]}]}',
'{"groups":[{"users": [{"id": "a"}, {"id": "b"}]}]}',
'{"groups":[{"users": [{"id": "a"}]}]}'
) AS (json_string)
)
SELECT
get_json_object(json_string, '$.groups[*].users[*].id')
FROM sample_dataWhen running the above example query, the values returned by each engine were different from the expected values, as shown below. The dimensions of the calculated values and the expected values differed in each engine. In Spark, a two-dimensional array was returned in the first row, while in Hive, a non-array value was returned in the third row (you can check the expected result run with JavaScript by clicking the Expected value link in the table below).
| Hive | Spark | Expected value | |
| 1 | ["a","b","c","d"] | [["a","b"],["c"],["d"]] | ["a","b","c","d"] |
| 2 | ["a","b"] | ["a","b"] | ["a","b"] |
| 3 | a | ["a"] | ["a"] |
Due to such issues, when we couldn't replace it with Spark's built-in UDF, we used Hive's built-in UDF by reading it through CREATE TEMPORARY FUNCTION.
Cases where a new UDF was introduced
Spark provides more built-in UDFs than Hive. I'll introduce a few of the newly introduced UDFs.
approx_count_distinct- Instead of calculating the high-volume cardinality (unique/distinct count), it computes a quick estimate of the cardinality.
count_if- A function that counts conditionally.
max_by/min_by- Finds the row with the maximum or minimum value in a specific column and retrieves other columns from that row.
timestamp_millis- It was useful when we frequently needed to switch between Unix time and timestamps.
Cases where set operations are used on map types
This is an issue reported as SPARK-18134. When using the map type, which allows for the free loading of key-value pairs, Spark doesn't allow the use of set operations to eliminate duplicates, unlike Hive. Set operations include DISTINCT, UNION, INTERSECT and so on. We were using the DISTINCT keyword to remove duplicates from the map<string, string> column. We resolved it by taking the following detour.
-- Hive
SELECT DISTINCT a, b, m FROM table
-- Spark
WITH to_array AS (
SELECT DISTINCT a, b, sort_array(map_entries(m)) AS entry FROM table
)
SELECT a, b, map_from_entries(entry) FROM to_arrayThe method above involves converting an unsortable map into a sortable array, removing duplicates, and then converting it back into a map. It might seem like unnecessary operations, but we couldn't find any other alternatives. By the way, it doesn't seem that this issue will be easily resolved, as the related fix has not been approved for seven years.
Also, when dealing with maps, there are cases where you might insert duplicate key-value pairs into the map. In Spark, an exception occurs in this case. If it's permissible, you can solve this problem by setting spark.sql.mapKeyDedupPolicy=LAST_WIN.
Cases where multiple partitions need to be deleted
This is an issue reported as SPARK-14922. You can't delete partitions by specifying a range with the ALTER TABLE statement. As a result, we can no longer use the following query that we were using to implement the concept of data retention period.
ALTER TABLE table DROP PARTITION (dt <= '2023-01-01') We solved this problem by implementing a separate interface that retrieves the list of partitions and deletes them one by one.
Results of migrating from HiveQL to Spark SQL
While migrating to Spark, we were able to review all queries, fix bugs, and optimize them. We also improved the system to produce results faster and use fewer resources. In some cases, we introduced new UDFs to reduce the amount of code.
Troubleshooting cases experienced while transitioning from Hive to Spark
After migrating from Hive to Spark, we noticed that certain data was missing in specific situations. To solve this problem, we set up a test environment to reproduce the issue and understand its cause. After identifying the cause, we didn't just stop at preventing the problem from occurring. We read the relevant Spark source code to understand the root cause. As a result, we were able to identify the fundamental cause that could explain not only the data omission issue but also a few other problems. Let's take a closer look at what happened.
Data loss occurred after migrating to Spark
One day, we received a query through our messenger that a specific daily KPI had dropped by 15% compared to usual. From our experience, this kind of data omission usually happens when a query is run before the preceding data is fully prepared. For instance, if you run a query using data from the past 24 hours, but only 22 hours of data is prepared, some data can be omitted, leading to a drop in the KPI.
However, this wasn't the issue since we had already prepared for such situations during the preprocessing stage. After reviewing from various angles, we found no other changes except for the use of the Spark engine. So, we first rolled back the engine to Hive to recover the data and traced the cause.
Investigation in a test environment
Upon tracing, we found that the cause was the missing data from a specific data mart table. Since such omissions didn't always occur, we set up a test environment to reproduce the phenomenon and conducted tests.
The table in question is created using three log sources to compose the data mart. It's made using the following query.
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_1')
SELECT ... FROM source_1;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_2')
SELECT ... FROM source_2;
INSERT OVERWRITE TABLE data_mart PARTITION (dt = 'YYYY-MM-DD', src = 'source_3')
SELECT ... FROM source_3;Each date and log source is composed as a partition. Since each log source doesn't affect each other, they can be run in parallel, and backfill tasks can also be performed independently. That's why we use this method to separate and store partitions.
While conducting tests in the experimental environment and analyzing cases where the problem was reproduced, we noticed that the content displayed in the SQL tab of the web UI and the actual number of files stored in the HDFS (Hadoop file system) were different.
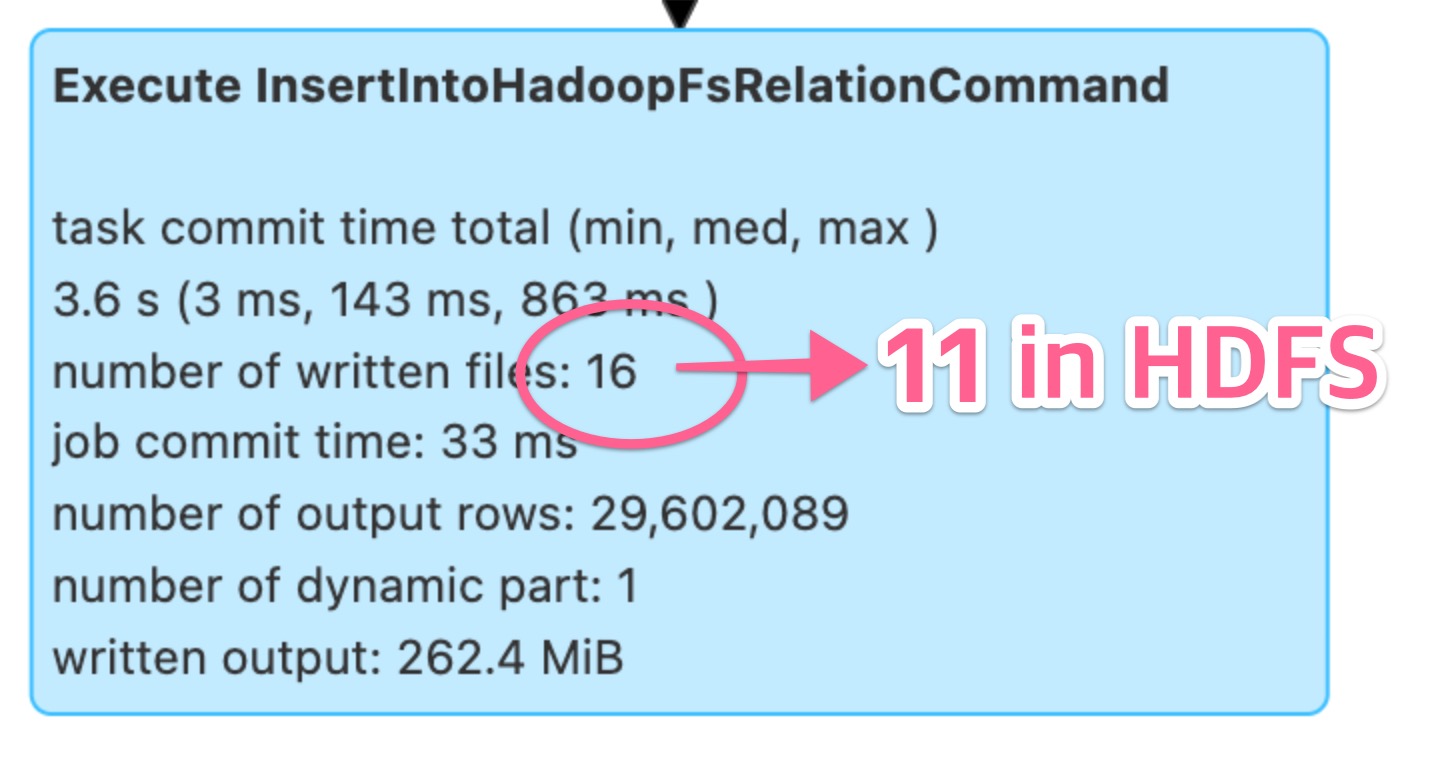
While the Spark UI recorded 16, only 11 were actually stored in the HDFS.
Upon analyzing the logs in detail, we discovered content indicating that the intermediate work files of the Spark app were deleted, and through searching, we found the MAPREDUCE-7331 issue. To summarize, if more than two Spark apps that insert into the same table run simultaneously, the first completed app can delete the intermediate work of other apps, potentially affecting the result.
Let's take a closer look at why this happens. In Spark, a workspace directory named _temporary/ is created under the directory where the table is located to store the intermediate work, and all apps share this workspace. The problem is that the app deletes the _temporary/ directory, which all apps share, to delete temporary files after completing the work. Therefore, if more than two insertion queries are running simultaneously on the same table, there's a possibility of data loss.
This workspace name, _temporary, is hard-coded as a constant (for reference) and cannot be modified with settings. Upon searching, we found a case where the problem was solved by changing the FileOutputCommitter source code where the name _temporary is hard-coded. We tried a similar method, which involved changing all parts where the variable PENDING_DIR_NAME, in which the value is defined, is used (creating independent directories for each app) and registering the newly created class in the spark.sql.sources.outputCommitterClass setting to run the Spark app.
Although this solved the problem in our tests, implementing and using individual classes like this makes management difficult and verification is not easy, which was a burden. So, we looked for another method, and the data platform team recommended using the spark.sql.hive.convertMetastoreOrc: false option. Upon using this setting, we found that an independent workspace directory is created for each app, preventing the problem from occurring.
Finding root causes in the Spark source code
As mentioned earlier, because the data we create can influence the entire company, it's necessary not just to ensure that "the problem simply doesn't occur", but to understand to the extent that we can explain "why such a phenomenon occurs". After reading the Spark code related to this setting, we realized that we could explain several phenomena that we'd been experiencing as one.
Explanation of relevant terms before introducing troubleshooting cases
Before I introduce the issues we've encountered, I'll first explain a few terms that I'll use in the description.
Static partition insert
In a table with partitions, it refers to inserting by specifying all partitions in the INSERT statement.
INSERT OVERWRITE TABLE user_table PARTITION (dt = '2023-01-01', region = 'JP')
SELECT ...Dynamic partition insert
In a table with partitions, it refers to not specifying the partition in the INSERT statement. In this case, you can't determine the partition just by looking at the query, you need to evaluate the values to know the partition value. Please note, there's an issue reported (SPARK-38230) in Spark currently that dynamic partition insertion could put a heavy load on the Hive Metastore, so it might be better to use static partition insertion if possible.
INSERT OVERWRITE TABLE user_table PARTITION (dt, region)
SELECT
...,
dt,
regionORC and Parquet
ORC and Parquet are projects supported by Apache and are types of columnar data storage methods. Using columnar data storage allows you to store data in a way that can be efficiently queried in a database.
The organizations that provide data to the entire company at LINE have mainly been using the ORC format, so my explanation uses the spark.sql.hive.convertMetastoreOrc option. If you're using the Parquet format, you can apply the spark.sql.hive.convertMetastoreParquet option.
Command
A Spark job is a unit of execution in Spark (for reference). In Spark, a single query is split into multiple commands and executed sequentially. As we're using a query to insert data into a Hive table, we're going to look at the differences between InsertIntoHadoopFsRelationCommand and InsertIntoHiveTable, both of which are types of DataWritingCommands.
Generally, an INSERT OVERWRITE TABLE query uses InsertIntoHadoopFsRelationCommand to load data. However, if the spark.sql.hive.convertMetastoreOrc option is set to false, it uses InsertIntoHiveTable. Both commands use SQLHadoopMapReduceCommitProtocol and FileOutputCommitter to load data.
Note that if you declare the table as a Data source type (for reference) rather than a Hive table, it doesn't use InsertIntoHiveTable.
Five types of errors we found while using SparkSQL
I'm going to introduce five issues that HiveQL users might encounter while using SparkSQL, such as a query not executing or the result being incorrect. I'll describe each issue, then explain how to reproduce it, its cause, how to address it, and share any reference materials.
Partial result loss after query execution
The content introduced earlier is also the reason for starting this investigation. The query runs normally, but some results are missing when loaded.
How to replicate
Set spark.sql.hive.convertMetastoreOrc to true and run two or more queries simultaneously that insert data into different partitions using static partition insertions. For example, perform the following two jobs at the same time (the more jobs, the higher the chance of reproduction).
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT ...Cause
The two jobs share a workspace called _tempoarary/. In this case, the job that finishes first deletes the shared workspace, the _temporary/ directory, removing the intermediate results of the other job. Consequently, there's a chance that the results of the job that finishes later could be lost.
Solutions
Apply one of the two methods below. Although the methods are different, both ensure that the jobs use independent workspaces, preventing any issues.
- Set
spark.sql.hive.convertMetastoreOrctofalse - Change the query to use dynamic partition insertion
When spark.sql.hive.convertMetastoreOrc is set to false, InsertIntoHiveTable creates a dedicated workspace directory starting with .hive-staging, which is different from InsertIntoHadoopFsRelationCommand.
In SQLHadoopMapReduceCommitProtocol, for dynamic partition insertion, a dedicated workspace directory starting with .spark-staging is created, and FileOutputCommiter then creates a _temporary directory.
References
Unable to read data when there are subdirectories under the partition directory
If there are subdirectories under the partition directory of HDFS, you can't read the files located in the subdirectories.
How to replicate
This issue occurs when loading results using UNION ALL in Hive, which stores data under the subdirectories. If you set spark.sql.hive.convertMetastoreOrc to true and run a query targeting data with subdirectories under the partition directory, you'll encounter this problem.
SELECT * FROM target_table WHERE dt = '2023-01-01'
-- readable
-- viewfs://hive/target_table/dt=2023-01-01/file.orc
-- unable to read
-- viewfs://hive/target_table/dt=2023-01-01/_part1/file.orcCause
This bug was reported as SPARK-28098, but it hasn't been fixed yet.
Solution
Setting spark.sql.hive.convertMetastoreOrc to false as it uses Hive's reader instead of Spark's Native ORC Reader.
References
Query failing due to a partition being deleted by a job
If you backfill a specific partition, the partition directory is deleted when the job starts, making it unavailable until the job is completed.
How to replicate
This issue occurs if you set spark.sql.hive.convertMetastoreOrc to true, run a backfill job using static partition insertion, and then attempt to read the partition where the job is writing data. For instance, you could run Job 1 with a specific query and then immediately run Job 2.
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
SELECT COUNT(*) FROM target_table WHERE dt = '2023-01-01'Cause
This happens because InsertIntoHadoopFsRelationCommand deletes the partition directory before running the job when it's executed in static partition insertion mode. For example, in the figure below, Job 1 deletes data when it starts, and if Job 2 tries to read data at the point of the arrow, it fails.

Solutions
By applying one of the two methods below, you can always read the data because the partition directory is overwritten after the data writing is complete.
- Set
spark.sql.hive.convertMetastoreOrctofalse - Change the query to use dynamic partition insertion
References
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L127-L132
- https://github.com/apache/spark/blob/3985b91633f5e49c8c97433651f81604dad193e9/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala#L220-L224
AnaylsisException("Cannot overwrite a path that is also being read from")
At LINE, we create and utilize snapshot tables loaded daily. We combine the previous day's snapshot and the events of the day to load a new snapshot into a different partition. However, we encountered a problem where an AnaylsisException occurred.
How to replicate
This issue occurs if you set spark.sql.hive.convertMetastoreOrc to true, read data from one partition using static partition insertion, and write to another partition of the same table.
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-02')
SELECT * FROM target_table WHERE dt = '2023-01-01'Cause
This happens because InsertIntoHadoopFsRelationCommand checks if the read address includes the write address before execution when it's run with static partition insertion. This verification logic seems to have been implemented to prevent it from deleting itself due to the previously mentioned implementation of "deleting the partition directory when the job runs".
Solutions
Applying one of the two methods below prevents the issue, as they don't perform the aforementioned address-related check.
spark.sql.hive.convertMetastoreOrc: false설정- Change the query to use dynamic partition insertion
References
Results being duplicated and loaded twice
There were instances where data was duplicated and loaded exactly twice in a specific table. We couldn't immediately identify the cause when the problem occurred, but we were able to find it while tracing the causes of other issues.
How to replicate
When spark.sql.hive.convertMetastoreOrc is set to true run the same query as below at similar times using static partition insertion..
-- Job 1:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...
-- Job 2:
INSERT OVERWRITE TABLE target_table PARTITION (dt='2023-01-01')
SELECT ...Cause
This occurs because InsertIntoHadoopFsRelationCommand doesn't overwrite at the point of loading the results when it's run with static partition insertion.

This issue is linked to the previously mentioned "deleting the partition directory when the job runs". It appears that it's designed not to overwrite at the point of loading results because the data was initially deleted. In general, there's no reason to run a query this way. But if it happens by mistake, it's not immediately obvious that this would result in duplicated results.
Solutions
Choose one of the following three methods to address this issue.
- Set
spark.sql.hive.convertMetastoreOrctofalse - Change the query to use dynamic partition insertion
- Don't make this mistake 😊
References
Our solution
As a response to the five issues mentioned earlier, we mostly guided you with the following two methods.
- Set
spark.sql.hive.convertMetastoreOrctofalse - Change the query to use dynamic partition insertion
We chose to use the spark.sql.hive.convertMetastoreOrc: false setting among the two methods. It was a choice to ensure backwards compatibility, as we needed to be able to read files created in Hive without any problems. However, it seems that Spark does not recommend this setting. This is because there are significant complaints about Hive code in the comments of the InsertIntoHiveTable Command code used when this setting is applied. Please keep this in mind.
Conclusion
We started our journey to achieve the significant goal of removing Hive by migrating OpenChat product queries from Hive to Spark. We successfully moved over 100 queries to Spark. Our team, made up of Spark beginners, came together to analyze unusual behaviors and trace their roots to solve various issues that cropped up during the project. Through this process, we managed to gain a partial understanding of how Spark operates internally.
As I mentioned earlier, our team handles a lot more than just OpenChat. In fact, we're planning to migrate all queries across the many domains we handle, hundreds in total, to Spark within this year. Alongside this, we're also working on introducing new technologies like Iceberg. If the opportunity arises, we'd love to share more about these topics in future blog posts.
We genuinely hope this article can be of help to anyone who might be encountering similar issues while using Spark. Thank you so much for taking the time to read this lengthy article.