
안녕하세요. LINE+ ABC Studio 팀에서 백엔드 개발을 하는 박원영, 박제희입니다. 현재 일본에서 운영하는 배달 서비스 '데마에칸(Demaecan, 出前館)' 프로덕트에서 점포 목록을 제공하는 서비스를 개발하고 있습니다. 이번 글에서는 점포 목록 제공 서비스를 개발하는 과정에서 Kubernetes 환경에서 작동하는 JVM 애플리케이션에 웜업을 적용했던 경험을 소개해 보려고 합니다.
웜업(warm up) 적용 배경
저희가 개발하는 서비스는 아래와 같이 데마에칸 앱 혹은 웹의 첫 화면에 표시되는 가게 목록을 제공하는 API 서비스입니다. 그동안 ElasticSearch를 이용해 구성하고 있었는데 비용과 성능을 개선하고자 Spring Boot와 MongoDB, Kubernetes 조합으로 기술 세트를 바꾸고 있습니다.
이 서비스는 메인 화면에 목록을 제공하기 때문에 사용자를 위해서 안정적이고 빠르게 응답할 책임이 있습니다. 서비스 스케일을 조정하거나 배포하는 시나리오에서도 서비스를 안정적으로 운영할 수 있도록 충분히 준비해야 합니다. 이를 위해 성능 측면에서 서비스 품질이 일정 수준 이하로 떨어지지 않도록 지속적으로 부하 테스트를 진행하고 있는데요. 얼마 전 부하 테스트를 진행하면서 요청 처리량이 순간적으로 낮아지는 현상을 발견했고, 이 현상이 콜드 스타트(cold start)의 영향일 것이라고 판단했습니다.
콜드 스타트란 실행 속도를 높이기 위해 애플리케이션을 처음 가동할 때 최소한의 기능만 로딩해서 시작하는 방법을 의미합니다. 이 때문에 최초에 서버에 접근하는 사용자는 서버에서 추가로 필요한 기능을 로딩하는 시간만큼 지연이 발생하기도 합니다.
이 문제를 해결하는 방법 중 하나로 서버를 네트워크에 연결해서 트래픽을 받기 전에, 가상의 사용자를 시뮬레이션해서 필요한 기능과 라이브러리를 미리 로딩하는 전략을 사용하기도 합니다. 이 작업이 마치 자동차의 예열과 비슷하기에 웜업이라고 부릅니다. 문제 현상이 의도치 않게 배포 프로세스가 작동하면서 새로 교체된 애플리케이션에서 관측되고 있었고, 지연 시간이 평균 응답 속도의 약 6배에 달했기에 웜업을 적용해 개선해 보기로 결정했습니다.
웜업 구현 전 사전 준비
요구 사항 정리
웜업을 적용하기 전에 Spring Boot 프레임워크 기반으로 Kubernetes 환경에서 작동하는 애플리케이션의 환경을 고려해 아래와 같이 간단하게 요구 사항을 정리했습니다.
- 요구 사항 1: 웜업 기능이 완료된 후 트래픽을 받을 수 있어야 한다.
- 요구 사항 2: 로컬 환경에서는 웜업 기능이 작동할 필요가 없으므로 선택해서 실행할 수 있어야 한다.
- 요구 사항 3: 프레임워크를 지원하는 구조로 구현한다.
- 요구 사항 4: 웜업은 한 번만 실행한다.
- 요구 사항 5: 새로운 웜업을 쉽게 추가할 수 있어야 한다.
Kubernetes 프로브 소개
웜업 완료 전까지 네트워크 트래픽을 차단하려면 Kubernetes의 프로브를 활용해야 합니다. 프로브는 파드 내 컨테이너의 상태를 확인하고 작동 여부를 진단하는 데 사용하며, 다음과 같이 세 종류가 있습니다.
| 프로브 | 설명 |
| 활성 프로브(livenessProbe) | 활성 프로브를 통과하지 못하면 kubelet은 컨테이너를 종료하고, 해당 컨테이너는 재시작 정책의 대상이 됩니다. |
| 준비성 프로브(readinessProbe) | 준비성 프로브를 통과하지 못하면 엔드포인트 컨트롤러는 파드와 연관된 모든 서비스의 엔드포인트에서 파드의 IP 주소를 제거합니다. |
| 스타트업 프로브(startupProbe) | 스타트업 프로브가 시작되면 스타트업 프로브를 통과하기 전까지 다른 프로브는 활성화되지 않습니다. 만약 스타트업 프로브를 통과하지 못하면 kubelet은 컨테이너를 종료하고 해당 컨테이너는 재시작 정책의 대상이 됩니다. |
아래는 파드의 생애 주기를 따라가며 파드가 거치는 각 프로브를 실행 순서에 따라 간단히 표현한 다이어그램입니다.
파드의 생애 주기와 프로브에 대한 보다 구체적인 내용이 궁금하시다면 아래 문서를 참고하시기 바랍니다.
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
- https://kubernetes.io/ko/docs/concepts/workloads/pods/pod-lifecycle/
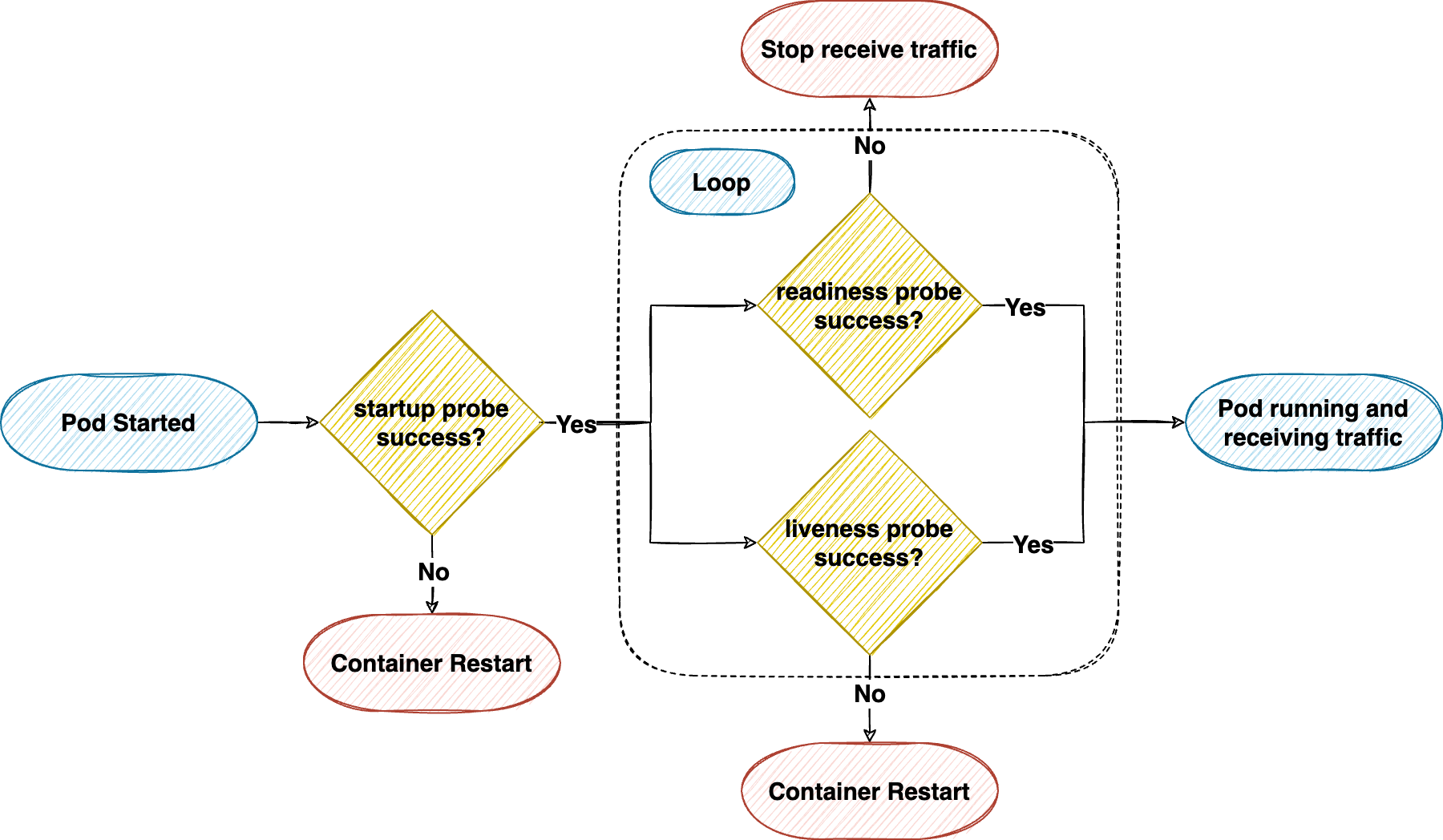
다이어그램을 보면 먼저 스타트업 프로브에서 컨테이너 상태를 진단하고, 이어서 준비성 프로브와 활성 프로브에서 컨테이너 상태를 감시하며 파드 상태를 결정한다는 것을 알 수 있습니다. 즉 스타트업 프로브와 준비성 프로브를 활용하면 웜업이 완료되기 전까지 네트워크 트래픽을 차단해 애플리케이션을 보호할 수 있으며, 이번 글에서는 간단히 준비성 프로브만 활용하는 방법을 소개하겠습니다.
준비성 프로브를 활용해 웜업을 진행하려면 준비성 프로브에서 준비성 상태를 진단할 때 사용할 기능을 사전에 준비해야 하는데요. Spring Boot는 애플리케이션 가용성을 진단하고, Kubernetes 환경을 감지해 프로브를 위한 진단 기능을 HTTP API로 노출하는 것까지 지원하고 있기 때문에 비교적 쉽게 진행할 수 있습니다(물론 웜업 상태를 검사하는 기능을 통합하기 위해서는 약간의 수고가 더 필요하긴 합니다).
웜업 구현
Spring Boot는 다양한 환경을 지원하기 위해 가용성 진단이나 런타임 플랫폼 감지와 같은 기능을 잘 분리해서 높은 수준으로 자동화해 놓았습니다. 이와 같은 프레임워크를 활용해서 다음과 같은 순서로 작업을 진행했습니다.
- 웜업 기능 구현
- 웜업 상태 진단 기능 구현
- 프레임워크에 내장된 애플리케이션 상태 진단과 직접 구현한 웜업 상태 진단 기능 통합
- 파드 리소스 설정 변경
워머(warmer) 구현
앞서 말씀드린 요구 사항 중 아래 두 가지 요구 사항은 플랫폼에서 기능을 제공하고 있었지만 만족할 만한 수준이 아니어서 직접 인터페이스와 구현체를 구현했습니다.
- 요구 사항 4: 웜업은 한 번만 실행한다.
- 요구 사항 5: 새로운 웜업을 쉽게 추가할 수 있어야 한다.
// 웜업 인터페이스 선언
interface Warmer {
suspend fun run()
val isDone: Boolean
}
// 웜업을 한 번만 실행하도록 강제하는 클래스
abstract class ExactlyOnceRunWarmer : Warmer {
override var isDone = false
private val mutex = Mutex()
override suspend fun run() {
if (!isDone && mutex.tryLock()) {
try {
doRun()
setDone()
} finally {
mutex.unlock()
}
}
}
protected fun setDone() {
this.isDone = true
}
abstract suspend fun doRun()
}
// 구현 예시
@Component
class Example1 : ExactlyOnceRunWarmer() {
override suspend fun doRun() {
delay(1_000) // 실제로 웜업을 위한 코드를 작성하면 됩니다.
}
}
// 구현 예시
@Component
class Example2 : ExactlyOnceRunWarmer() {
override suspend fun doRun() {
delay(5_000)
}
}
// 구현 예시
@Primary
@Component
class CompositeWarmer(
private val warmers: Collection<Warmer>,
) : ExactlyOnceRunWarmer() {
override suspend fun doRun() {
withContext(NonCancellable) { // 이미 실행된 워머는 취소하지 않습니다.
warmers.map {
async { it.run() }
}.awaitAll()
if (warmers.all { it.isDone }) {
setDone()
}
}
}
}Spring Actuator 커스텀 HealthIndicator 추가
다음으로 '요구 사항 3: 프레임워크를 지원하는 구조로 구현한다'라는 요구 사항을 만족하기 위해 앞서 구현한 워머와 Spring Actuator를 통합했습니다.
아래 코드와 같이 HealthIndicator 또는 ReactiveHealthIndicator 인터페이스를 구현하는 Spring Bean을 구현하고, 워머 실행 결과에 따라 health 상태를 변경하는 로직을 추가했습니다(AbstractReactiveHealthIndicator는 에러 처리를 캡슐화한 추상 클래스입니다). 이를 통해 웜업 상태 정보를 제공합니다.
// AbstractReactiveHealthIndicator를 상속해 웜업 상태 정보를 제공합니다.
@Component
class WarmupHealthIndicator(
private val warmer: Warmer,
) : AbstractReactiveHealthIndicator() {
override fun doHealthCheck(builder: Health.Builder): Mono<Health> {
return mono {
warmer.run() // 편의상 실행과 검사를 인디케이터에서 처리합니다.
val health = builder.also {
if (warmer.isDone()) { // 웜업이 완료되면 상태를 UP으로 노출합니다.
it.up()
} else { // 웜업이 아직 완료되지 않았으면 상태를 DOWN으로 노출합니다.
it.down()
}
}.build()
return@mono health
}
}
}마지막으로 Spring Actuator 설정을 아래와 같이 변경해 준비성 상태 진단 기능에 웜업 상태 진단 기능을 통합했습니다.
management:
endpoint:
health:
group:
readiness:
show-components: always
liveness:
show-components: always
exclude:
- warmup # 활성 그룹에서 warmup HealthIndicator를 제외합니다.구현을 완료한 뒤에는 애플리케이션 진단 기능을 지원하는 각 API가 상황에 따라서 어떻게 응답하는지 아래와 같이 확인했습니다.
| 엔드포인트 | 설명 |
/actuator/health/liveness |
활성 그룹 인디케이터 설정에서 |
/actuator/health/readiness |
웜업이 아직 완료되지 않은 상태에서는 웜업이 완료되면 |
Kubernetes 프로브 설정
웜업 상태를 포함한 애플리케이션 준비성 상태 진단을 위한 기능을 준비한 뒤 파드 설정을 변경해 모든 작업을 완료했습니다.
apiVersion: apps/v1
kind: Deployment
# 생략
spec:
template:
spec:
containers:
- name: example
image: example
ports: # 컨테이너가 사용할 포트를 지정합니다.
- name: http
containerPort: 8080
protocol: TCP
- name: actuator
containerPort: 8081 # 외부에 Actuator 엔드포인트를 노출하지 않기 위해 별도 포트로 관리합니다.
protocol: TCP
livenessProbe:
httpGet:
path: "/actuator/health/liveness"
port: actuator
readinessProbe:
httpGet:
path: "/actuator/health/readiness"
port: actuator위 작업으로 '요구 사항 1: 웜업 기능이 완료된 후 트래픽을 받을 수 있어야 한다'를 해결했습니다. 또한 로컬 환경에서는 Kubernetes 기반으로 애플리케이션을 구동하지 않기 때문에 워머가 실행되지 않는데요. 이를 통해 자연스럽게 '요구 사항 2: 로컬 환경에서는 웜업 기능이 작동할 필요가 없으므로 선택해서 실행할 수 있어야 한다'도 만족하면서 모든 요구 사항을 충족했습니다.
웜업 유무 비교 테스트
웜업 적용 여부에 따라 발생하는 차이점을 확인하기 위해 처음에는 웜업을 제거하고, 다음에는 웜업을 적용한 상태에서 아래와 같은 방법으로 초기 응답 지연을 재현했습니다.
- n개의 레플리카로 구성된 디플로이먼트 그룹을 재시작
다음은 테스트를 진행하며 평균 응답 시간을 기록한 그래프입니다.
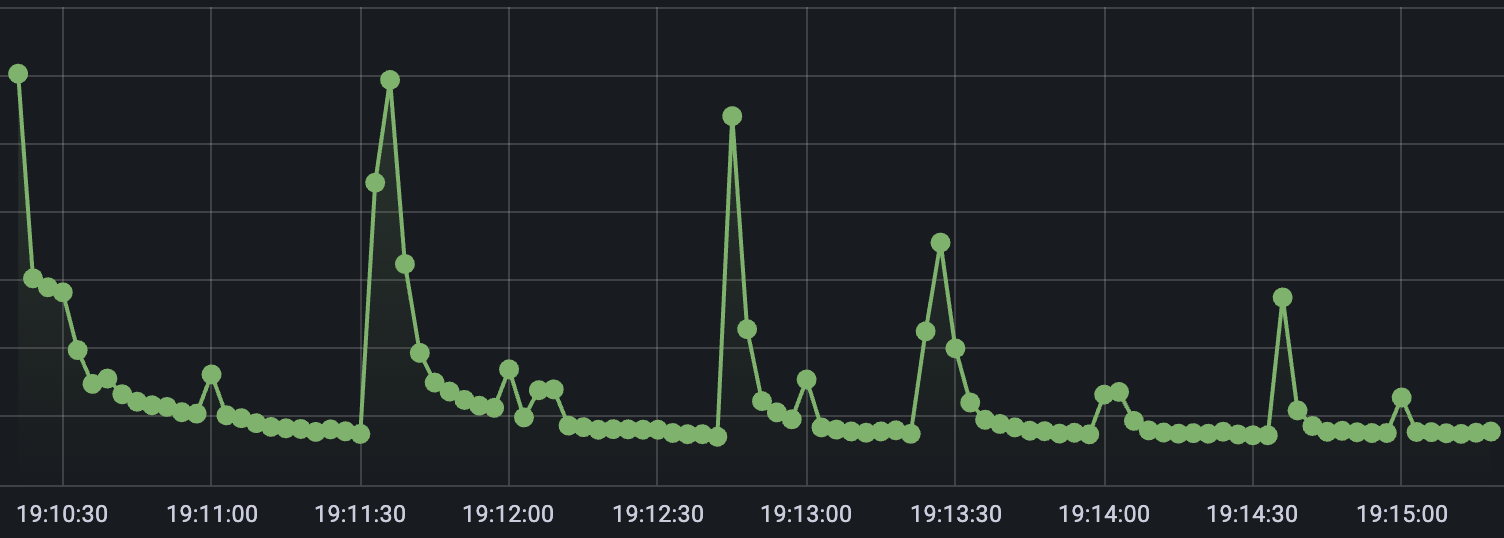
웜업 미적용 시 평균 응답 시간
웜업 적용 시 평균 응답 시간
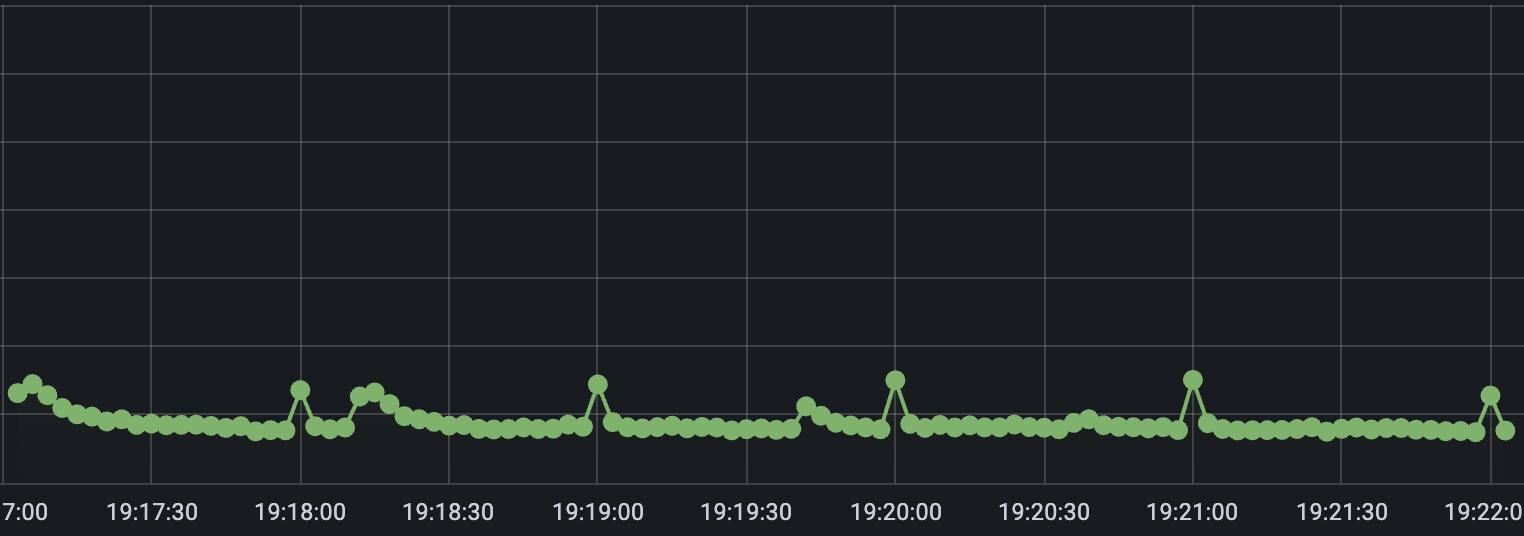
웜업을 제거하면 애플리케이션이 교체되는 과정에서 새로 시작된 애플리케이션에서 초기 응답 지연이 발생하면서 평균 응답 시간이 비정상적으로 많이 증가합니다. 반면 웜업을 적용하면 이와 같은 현상이 크게 개선되는 것을 확인할 수 있습니다.
웜업으로 초기 지연 현상이 개선되는 이유
일반적으로 JVM 애플리케이션은 JVM의 구조나 구현 특징 때문에 실행 초기에 실행되는 코드는 평소보다 처리 속도가 느려질 수 있는데요. 웜업 유무에 따라 이와 같은 차이가 발생하는 이유가 무엇이고 웜업이 어떻게 성능 개선에 기여하는지 살펴보겠습니다.
클래스 로드 사전 진행
JVM은 실행될 때 부트스트랩 클래스 로더와 확장 클래스 로더, 시스템 클래스 로더를 이용해 클래스를 로드하는데 이때 모든 클래스를 로드하지는 않습니다. 로드하지 않은 클래스는 추후 필요할 때 로딩을 수행하는데요. 이는 코드 실행 시간에 영향을 줄 수 있습니다.
실제로 어떻게 영향을 주는지 확인하기 위해 아래와 같은 예제 코드를 만들었습니다.
// Demo.kt
fun main() {
println("starting")
val elapsedNanoTime1 = measureNanoTime { ExampleClass.run() }
println("1st: $elapsedNanoTime1")
val elapsedNanoTime2 = measureNanoTime { ExampleClass.run() }
println("2nd: $elapsedNanoTime2")
println("done")
}
object ExampleClass {
init {
// do something
Thread.sleep(100)
}
fun run() {
println("ExampleClass.run()")
}
}위 코드가 어떻게 작동하는지 확인하기 위해 클래스 로딩 정보를 출력하는 옵션을 활성화해서 실행했습니다. 아래 실행 로그를 살펴보면 첫 번째 실행 시간(1st: 104052250 ns)과 두 번째 실행 시간(2nd: 12458 ns)의 차이를 확인할 수 있습니다.
kotlinc Demo.kt && java -verbose:class DemoKt
# 여기부턴 실행 로그의 일부입니다
# ...
starting
[0.064s][info][class,load] demo.ExampleClass source: file:/Users/user/demo/src/main/kotlin/demo/
ExampleClass.run()
1st: 104052250 ns
ExampleClass.run()
2nd: 12458 ns
done
# ...극단적인 예시이긴 하지만, 아직 로드되지 않은 클래스를 처음 호출할 때 클래스 로딩이 발생하면서 클래스 수준에 존재하는 코드가 실행되며 애플리케이션 실행 시간에 어떤 영향을 주는지 확인할 수 있습니다(클래스 로더 사양은 Oracle에서 제공하는 문서에서 확인할 수 있습니다).
프로파일링 정보 사전 생성
JIT 컴파일러가 바이트 코드를 네이티브 코드로 컴파일하기 위해서는 바이트 코드 실행에 대한 프로파일링 정보가 필요합니다. 이 정보를 기반으로 최적화한 코드를 생성한 뒤 코드 캐시에 저장하며, 이를 이용해 이후 바이트 코드를 빠르게 실행할 수 있습니다.
반면 컴파일되지 않은 바이트 코드는 인터프리터 기반으로 실행되기 때문에 상대적으로 느릴 수 밖에 없는데요. 이때 웜업으로 바이트 코드 실행에 대한 프로파일링 정보를 인위적으로 생성하면 네이티브 코드 컴파일을 유도해서 초기에 발생하는 실행 지연을 완화할 수 있습니다.
I/O 연결 설정 사전 진행
구현 요구 사항에 따라 다르겠지만 대부분의 애플리케이션은 기능을 작동하기 위해 I/O 연결을 설정해야 하고, 최초 I/O 연결을 설정할 때는 시간이 오래 걸릴 수 있습니다(JVM의 특징은 아닙니다). 애플리케이션 시작 과정에서 적절히 I/O 연결을 설정할 수 있는 기능을 제공하는 라이브러리도 있지만, 그렇지 않다면 요구 사항에 따라서 직접 최적화 수단을 찾아야 하는데요. 웜업을 적용하면 오래 걸리는 최초 I/O 연결 설정을 웜업 과정에서 사전에 진행할 수 있습니다.
웜업을 적용할 때 고려해야 할 점
웜업은 기능을 시뮬레이션하기 때문에 논리적 결함이 발생할 수 있습니다. 또한 애플리케이션의 일부로 존재하기 때문에 작동 과정에서 시간과 컴퓨터 자원을 소비하며, 이는 생산성에 영향을 미칠 수 있습니다. 따라서 애플리케이션 생명 주기에 웜업이라는 과정을 추가하면 자연스레 다음과 같은 고민 거리가 함께 추가됩니다.
웜업에 실패하는 경우
보통 웜업은 애플리케이션 생명 주기의 시작 과정에서 수행됩니다. 따라서 예외 케이스를 잘 정의해서 대비해 놓지 않으면 오히려 배포와 스케일아웃, 재실행 같은 오퍼레이션을 방해할 수 있습니다. 웜업 기능을 잘 관리하지 않으면 실제 기능은 정상 작동하는데 웜업 기능이 정상 작동하지 않아 배포가 정상적으로 진행되지 않는 경우가 발생할 수 있습니다.
웜업에서 외부 시스템을 호출하는 경우
만약 웜업이 외부 시스템을 반복해서 호출하는 형태라면 만약의 경우에 어떤 영향이 발생할 수 있는지 미리 파악해 놓아야 합니다. 일반적인 시나리오에서는 괜찮을 수 있지만 특수한 시나리오에서는 외부 시스템까지 망가트리는 요소가 될 수 있는데요. 예를 들어 동시에 수십 대의 애플리케이션이 재실행될 때 웜업이 동시에 외부 시스템을 호출하면 자체적으로 DDoS 공격을 가하는 현상이 발생할 수 있습니다.
웜업 때문에 애플리케이션 준비 시간이 늘어나는 경우
일반적으로 웜업은 애플리케이션을 실행할 때 더 오래 걸리게 만듭니다. 따라서 웜업 소요 시간을 파악하고 적절한 전략을 세워야 합니다.
마치며
이번 글에서는 Kubernetes 환경에서 실행되는 Spring Boot 기반 웹 애플리케이션에 웜업을 적용하는 방법을 살펴봤습니다. 실제로 서비스 개발 과정에서 초기 지연 현상을 확인하고 성능 최적화 전략 중 하나인 웜업을 적용해 품질을 개선한 경험에 기반해 작성했는데요. 이 글이 비슷한 문제를 해결해야 하는 분들께 도움이 되길 바라며 이만 글을 마치겠습니다. 읽어주셔서 감사합니다.