
시작하기 전에
안녕하세요. LINE VOOM 서버 개발자 박찬우입니다. 최근 쿠버네티스 환경에서 Confluent Platform을 사용해 한 단계 진보한 데이터 파이프라인을 구축하는 프로젝트를 진행했습니다. 그 과정에서 쿠버네티스와 Confluent Platform, 그리고 데이터 파이프라인에 대해 모든 면에서 배운 점이 많았습니다. 가능하다면 이 경험을 최대한 자세히 공유드리고 싶지만, 지면의 한계와 더불어 글이 장황하게 늘어지지 않고 꼭 전달해야 할 부분을 독자 여러분께서 제대로 전달할 수 있도록 이번 글에서는 아래 두 가지 주제에 집중하려고 합니다.
- Confluent Platform을 쿠버네티스 환경에 구축하고 연관 시스템과 통합하는 과정
- 구축 후 기존 데이터 파이프라인과 비교해 어떤 면에서 나아졌는지 소개
'커스텀 Connector 및 컨버터 개발과 활용'과 관련해서도 공유드리고 싶은 내용이 많은데요. 이 주제는 추후 다른 분께서 별도 포스팅으로 자세히 소개해 주실 예정입니다.
개발 배경
LINE VOOM은 글로벌 메신저 LINE의 주력 서비스 중 하나입니다. 주요 서비스 국가에서 LINE 앱 하단에 별도 탭으로 자리 잡고 있으며, 수많은 사용자가 콘텐츠를 게시하고 구독하고 있습니다. LINE 앱도 그렇지만 VOOM 서비스는 특히 데이터 중심 서비스의 성격이 강한데요. 얼마나 더 안정적이고 효율적으로 사용자 데이터를 수집하고 가공해서 제공하느냐에 따라 사용자에게 제공할 수 있는 서비스 경험의 질이 달라집니다.
제가 속한 VOOM 서버 개발 조직은 VOOM 서비스 초기부터 이런 데이터를 처리하는 시스템을 구축하고 발전시켜 왔는데요. 시스템을 운용하다가 아래와 같은 한계에 부딪쳤습니다.
- 새로운 파이프라인이 필요할 때마다 매번 API를 새로 개발해야 했습니다.
- 개발한 API 수가 증가할수록 전체 시스템을 파악하는 게 힘들어졌습니다. 시스템을 파악하기 위해서는 코드를 읽으며 문서와 비교해야 했고, 일부 API는 히스토리를 알아야 구현 이유를 이해할 수 있었습니다.
- 데이터 소유자가 API를 이용해 데이터를 푸시 방식으로 전송하기 때문에 API 프로토콜 정의와 관리에 신경 써야 했습니다.
- 푸시 방식 API에서는 수신 시스템의 수용량을 넘어서는 요청은 장애를 의미했고, 네트워크 이슈 등으로 타임아웃이 발생하면 데이터를 재처리해야 했습니다.
- 데이터를 API로 수신하는 방식에서는 데이터가 순서대로 처리된다고 보장할 수 없었습니다. 서버에 따라 처리 시간이 미묘하게 다르기 때문입니다.
- 쿠버네티스가 아닌 환경에서 구축했기 때문에 확장과 관리가 불편했고 셀프 힐링(self-healing)이 어려웠습니다.
이런 한계를 극복하기 위해 데이터 수집과 처리 방식을 완전히 새롭게 바꾼 데이터 허브를 구축했습니다.
Confluent Platform이란?
Kafka를 한 번도 사용해 보지 않았거나 아예 들어보지도 못한 개발자는 드물 겁니다. 그렇지만 Confluent Platform은 조금 다를 것 같습니다. Confluent Platform은 여러 소스 데이터를 이용하는 실시간 데이터 파이프라인과 스트리밍 애플리케이션을 쉽게 구축할 수 있는 Kafka 기반 플랫폼입니다. Confluent Platform의 작동 원리를 이해하려면 먼저 이해해야 할 개념과 용어가 있습니다.
CDC(Change Data Capture)
상태 변화분을 모두 적용하면 결국 최종 상태에 이른다는 원리가 있습니다. 이를 그림으로 표현하면 아래와 같습니다.
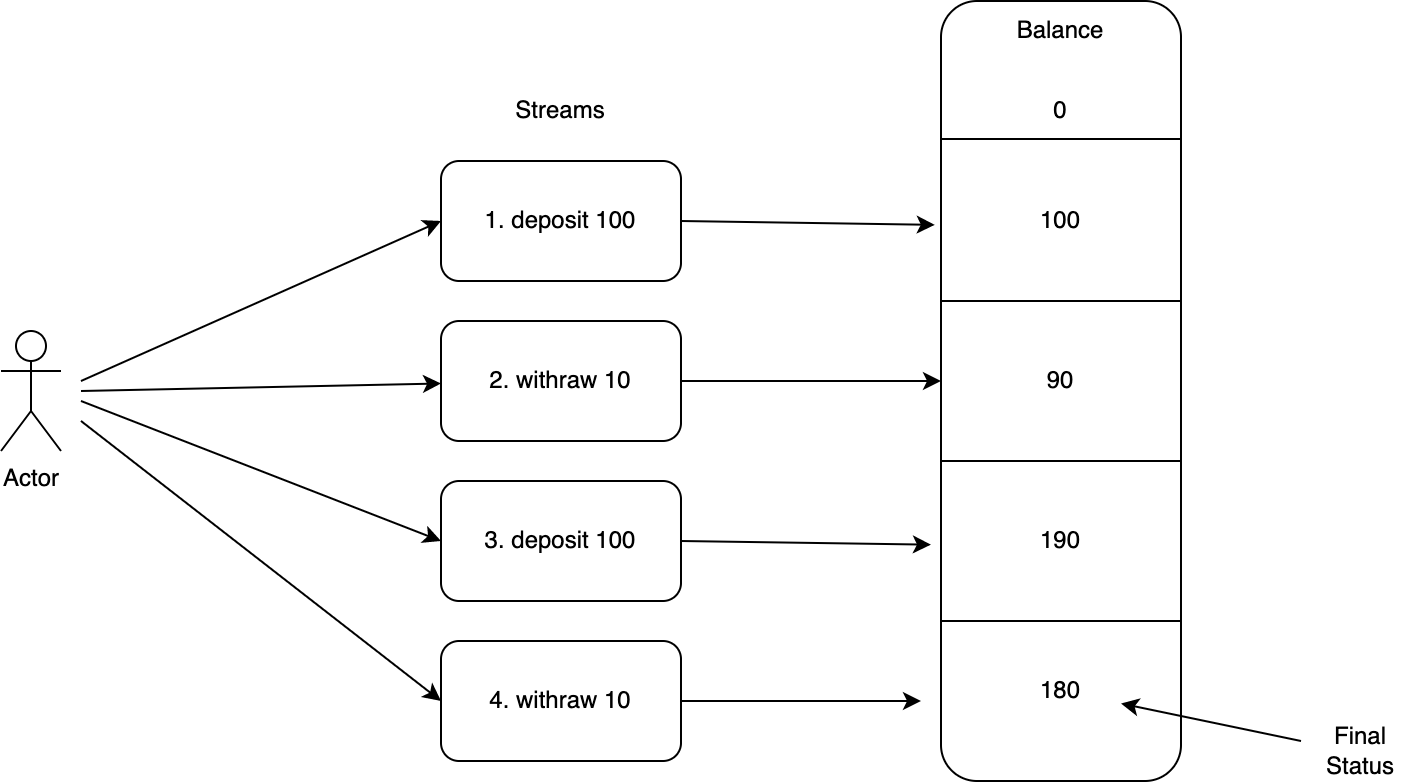
위 그림에서 액터의 개별 트랜잭션을 스트림으로 볼 수 있습니다. 이 스트림을 모두 적용한 결과는 결국 상태로 표현됩니다. 이 원리를 이용하면 아래 두 가지 기능을 구현할 수 있습니다.
소스 DB의 변경분을 스트림으로 캡처해서 이벤트화
MongoDB와 Redis, MySQL 등 대부분의 DB는 Oplog나 Binary Log 등 부르는 이름은 달라도 모두 리플리케이션(replication)을 위해서 데이터 변경 로그를 남깁니다. 데이터 변경 로그는 위 그림에서 스트림에 해당하기 때문에 접근할 수 있는 권한과 수집할 수 있는 방법이 있다면 데이터 스트리밍 파이프라인을 구축하는 용도로 사용할 수 있는데요. Kafka Connect는 Connector라는 이름으로 각 DB에 맞는 수집 방법을 제공합니다. Connector는 작동 방식에 따라 크게 두 가지로 나뉘며, 이렇게 DB나 기타 소스에서 데이터를 수집하는 Connector를 Source Connector라고 합니다. 만일 원하는 Connector가 없을 경우 커스텀 Connector를 제작해 사용할 수도 있습니다.
스트림 데이터를 타깃에 반영해 상태를 변경
앞서 설명한 기능과 반대 방향으로 작동하는 경우입니다. 수집한 스트림 데이터가 Kafka 토픽에 저장돼 있는 경우 이 스트림을 타깃에 저장할 수 있습니다. Kafka Connect의 Sink Connector가 바로 이렇게 작동합니다. 이때 타깃이 반드시 DB일 필요는 없습니다. 예를 들어 HTTP Sink Connector는 스트림 데이터를 HTTP로 전송합니다.
ETL(Extract, Transform and Load)
ETL은 '데이터를 추출해서(extract), 변환한 후(transform), 적재한다(load)'는 개념입니다. 데이터 허브뿐 아니라 우리가 개발하는 대부분의 애플리케이션은 ETL 과정을 거쳐 데이터를 처리한 후 서비스에 사용합니다. 전통적인 방식으로 ETL 시스템을 구축한다면 쿼리를 사용해 DB에서 데이터를 추출한 후 애플리케이션에서 변환해 연동 시스템에 전송하거나 다시 쿼리를 사용해서 DB에 저장하는 방식으로 구축합니다.
Confluent Platform을 사용하면 보다 효과적이고 효율적인 방법으로 ETL 시스템을 구축할 수 있습니다. 앞서 CDC를 설명하면서 Confluent Platform에서 데이터를 추출(Source Connector)하고 적재(Sink Connector)하는 방식을 설명드렸습니다. 이제 데이터 변환(transform)을 설명할 차례인데요. Confluent Platform에서 데이터 변환을 처리하는 방법은 세 가지가 있습니다. Kafka Connect와 ksqlDB, Kafka Streams을 이용해 처리하는 것입니다.
Kafka Connect
SMTs(Single Message Transformations)가 KIP(Kafka Improvement Proposals)-66을 통해 도입되면서 Kafka Connect를 사용한 메시지 변환이 가능해졌습니다. 주로 데이터에서 키를 추출하거나 필드명을 바꾸고 필터링하는 등의 용도로 사용합니다. KIP-585 등의 제안이 뒤이어 채택되는 등 SMTs는 기능적으로 확장되고 있습니다.
ksqlDB
ksqlDB는 Confluent Platform에서 Community 라이선스로 제공합니다. DB 쿼리처럼 선언형으로 데이터를 조작할 수 있습니다.
ksql> select * from example_voom_view emit changes;Kafka Streams
소스 토픽에 저장된 데이터를 읽어서 실시간으로 변환한 후 타깃 토픽으로 전송하는 스트림 프로세싱 기능을 개발하기 위해 Kafka에서 지원하는 라이브러리입니다. Kafka Connect나 ksqlDB와는 다르게 라이브러리 형태이기 때문에 Spring Boot 등을 사용해 애플리케이션으로 구현해서 사용합니다.
설계
설계 단계에서는 먼저 라이선스를 검토하고 구축 환경을 결정한 뒤 데이터 파이프 라인별로 적용할 기술과 구현 방법을 결정했습니다. 이어서 운영 수준에서 필요한 요소들(인증과 로깅, 모니터링)을 어떻게 효율적으로 적용할지 결정하고 세부 파이프라인을 설계하면서 파일럿 프로젝트를 간단히 진행해 설계 리스크를 줄이고 시행 착오를 겪지 않도록 진행했습니다.
Confluent Platform 라이선스 검토
아래는 라이선스 검토 결과를 나타낸 그림입니다. 대부분 무료로 사용할 수 있었지만 일부 Connector(Kafka to Kafka, HTTP Sink)와 Control Center는 라이선스 문제가 있었습니다. 이에 Connector는 자체 개발하고 Control Center는 대체할 수 있는 오픈소스를 찾기로 결정했습니다. 참고로 아래 그림에서 Apache2 라이선스 구성 요소를 하나로 모아서 표기한 이유는 실제로 프로젝트 소스가 하나로 통합돼 있기 때문입니다.
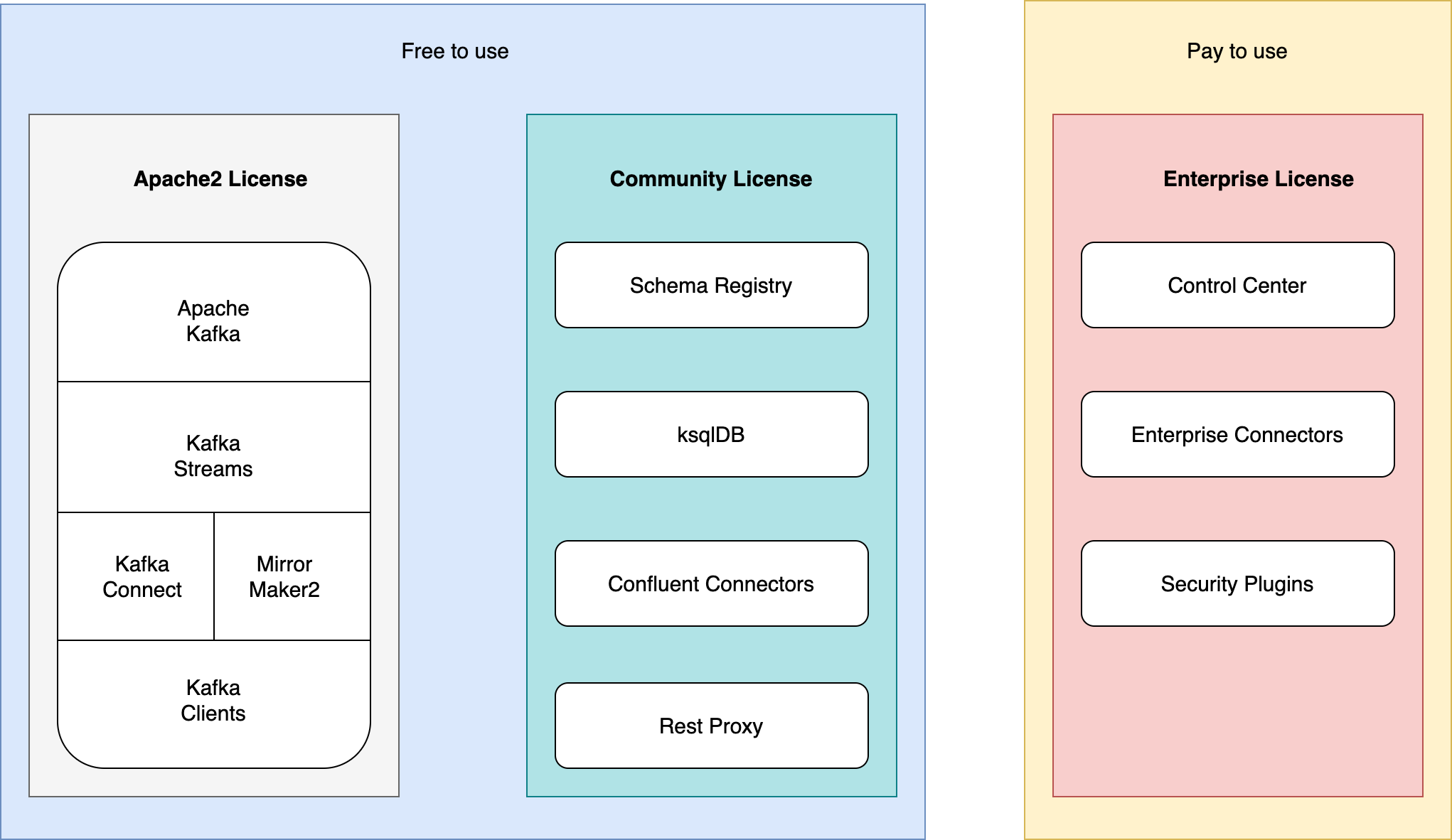
모든 것을 쿠버네티스 환경에서 구축
Confluent Platform은 네이티브 쿠버네티스 프로젝트가 아닙니다. 쿠버네티스가 아닌 환경에서도 얼마든지 구축할 수 있고 실제로 그렇게 사용하고 있는 경우도 많을 것이라고 생각합니다. 하지만 저는 새로운 데이터 허브 프로젝트를 시작하면서 파이프라인 구축과 변경이 쉽고 트래픽 변화에 따라 쉽게 확장할 수 있도록 개발하고자 했습니다.
Confluent Platform은 이런 요구 사항을 충족시킬 수 있는 기술적 특징을 가지고 있었습니다. 예를 들어 Kafka Streams나 Kafka Connect, ksqlDB 모두 토픽 파티션 수를 늘리고 스레드(또는 프로세스) 수를 늘려서 처리량을 늘릴 수 있습니다. 또한 ksqlDB는 선언형 스트리밍 처리에 특화돼 있고 Kafka Connect 역시 설정만으로 작동을 변경하고 구성할 수 있기 때문에 이를 이용해 파이프라인을 구축하고 변경하기가 쉬운 편입니다.
다만 이런 Confluent Platform의 특성을 최대한 살리기 위해서는 인프라 환경이 유연해야 했습니다. 구축한 파이프라인이 더 많은 트래픽을 처리할 필요가 있다면 더 많은 서버를 즉시 투입할 수 있어야 했고, 구축한 파이프라인이 더 이상 필요없다면 즉시 서버를 반납할 수 있어야 했습니다. 이런 면을 고려할 때 IaC(Infrastructure as Code)를 지향하는 쿠버네티스가 최적의 답이라고 생각했습니다.
어떤 Kafka를 사용할 것인가?
설계 과정에서 끝까지 고민하게 만든 것은 Kafka였습니다. 선택할 수 있는 Kafka는 세 종류가 있었고 각각 장단점이 있었습니다.
| 종류 | 장점 | 단점 |
|---|---|---|
| 사내 공용 Kafka |
|
|
| PM 장비에 Kafka 설치 |
|
|
| 쿠버네티스에 Kafka 설치 |
|
|
고심 끝에 Kafka를 포함한 전체 구성 요소를 쿠버네티스 클러스터에 구성하는 것으로 결정했습니다. 이에 따라 브로커의 안정성과 성능을 높이기 위한 파라미터도 직접 설정하기로 결정했는데요. 저는 2015년에 Kafka를 자체 구축해 서비스에 도입해 본 경험이 있었고, Kafka에 설정할 수 있는 파라미터가 공개돼 있기 때문에 성능 및 안정성 테스트를 거쳐 사용한다면 이슈가 발생하지 않을 것이라고 판단했습니다(아래 Kafka 설정에서 주요 파라미터 중 일부를 소개하겠습니다).
데이터 파이프라인 설계 - 추출과 적재
이번 프로젝트에서는 다양한 형태의 파이프라인이 필요했습니다. 파이프라인 ETL 구성 중 데이터 추출과 적재 설계를 소개하겠습니다.
Kafka to Kafka(추출)
데이터 소유자가 Kafka에 데이터를 보유하고 있고 이를 데이터 허브 쪽 Kafka로 가져와야 하는 경우입니다. 이런 경우에 라이선스 부담 없이 사용할 수 있는 Source Connector가 없었습니다. 자체 제작을 생각해 봤지만 개발 일정을 고려해 Mirror Maker2를 사용하는 것으로 선회했습니다. 원본 데이터가 특수한 형식으로 직렬화돼 있는 경우가 있었고, 또 원본 데이터중에서 필요한 데이터만을 선별해 가져올 필요가 있었기 때문에 커스텀 컨버터를 제작해 Mirror Maker2에 탑재했습니다.

글 마지막 향후 과제에서 다시 설명하겠지만 Mirror Maker2는 이슈가 있어서 추후 자체 제작 Connector로 대체할 예정입니다.
Mongo Source(추출)와 Mongo Sink(적재)
MongoDB를 Source로 쓰는 경우와 Sink로 쓰는 경우가 모두 있어서 Source와 Sink Connector가 모두 필요했습니다. MongoDB는 두 가지 방식으로 스트림을 캡처할 수 있습니다. Oplog를 수집하는 방법과 Mongo Change Stream을 수집하는 방법입니다. Source Connector는 Debezium connector for MongoDB를 사용했고 Oplog 수집 방식을 채택했습니다. Sink Connecotor는 MongoDB에서 제공하는 Connector를 사용했습니다.
HTTP Sink(적재)
Rest API로만 데이터 수신이 가능한 시스템과 연동하기 위해서 HTTP Sink Connector가 필요했고, 라이선스 문제로 자체 제작해야 했습니다. 커스텀 Connector 제작과 사용에 관한 이야기는 다른 분이 포스팅해 주실 예정입니다. 그 글에서 이 Connector 제작과 관련해 자세하게 말씀드리겠습니다.
Redis Sink(적재)
Redis Sink Connector는 오픈소스를 사용했습니다.
하나의 데이터 파이프라인을 구성할 때에는 이와 같은 추출과 적재 방법을 비롯해 선택할 수 있는 여러 방법 중 n개를 선택해서 조합해 구성합니다. Connector는 설정만으로 소스와 타깃을 변경할 수 있기 때문에 보유한 Connector가 많을수록 더 다양한 입출력 방식을 지원하는 데이터 허브를 구성할 수 있습니다.
데이터 파이프라인 설계 - 변환
데이터 변환 기능을 수행하는 변환 단계는 작동 위치와 순서에 주의해서 데이터 파이프라인에 배치해야 합니다. 특히 필터 작동 위치는 파이프라인 효율에 큰 영향을 미칠 수 있습니다. 이번 프로젝트에서는 Confluent Platform의 핵심 구성 요소인 Kafka Connect와 ksqlDB, 저수준 처리에 적합한 Kafka Streams까지 총 세 가지 방식을 사용해서 각각 아래와 같이 기능하도록 설계했습니다.
Kafka Connect
후속 파이프라인의 부담을 덜 수 있도록 Connector에서 데이터를 추출할 때 데이터 변환과 1차 필터링을 수행합니다. 또한 특별한 데이터를 처리하기 위해서 커스텀 컨버터를 Connector에 탑재하기도 합니다.
Kafka Streams
시스템 외부 API 호출이 필요한 경우나 로직이 복잡하고 부하가 많이 발생하는 작업을 처리합니다. 이런 작업은 Connector보다는 Kafka Streams에서 처리하는 게 좋습니다. 예를 들어 외부 API를 호출할 때마다 100ms가 걸리다고 가정하면, 이를 Source Connector에서 처리하면 데이터를 추출하는 작업 자체도 매 건마다 100ms 이상으로 느려져 후속 파이프라인 전체에 영향을 줍니다. 따라서 Connector에는 부하가 많이 걸리지 않고 작업 순서 관점에서 가장 먼저 처리해야 효율이 좋은 변환 작업을 배치하고, Kafka Streams에는 이후 추출된 데이터 집합을 변환하는 작업을 수행하도록 구성해야 합니다.
ksqlDB
ksqlDB는 선언형 명령문으로 쉽게 데이터를 조작할 수 있어서 통계나 시스템 모니터링에 활용합니다.
모니터링 및 인증 시스템과 통합
인증과 로깅, 모니터링은 서비스 릴리스를 위해서 꼭 필요한 부분입니다. 이미 관련 툴을 표준으로 제공하고 있는 플랫폼들이 있기 때문에 기존 플랫폼과 어떻게 통합하느냐가 과제였습니다. 이번 프로젝트에서는 모든 구성 요소를 단일 쿠버네티스 클러스터 환경에서 구성하기로 결정했으므로 그 장점을 최대한 살리는 방향으로 통합했습니다. 모든 과정을 Confluent Platform 소스 코드를 직접 수정하지 않는 방법으로 처리해 향후 업그레이드와 같은 유지 보수 부담도 줄였습니다.
인증
인증은 인증 전용 사이드카를 제작해 인증 체계를 통합 적용했습니다.
로깅
로깅은 공식 Docker 이미지 레이어에 로깅 구현체를 추가하고 이를 사용하도록 설정했습니다.
모니터링
JMX Exporter를 각 Confluent Platform 구성 요소와 동일한 파드(pod)에서 작동하는 별개 사이드카로 설정했고 공용 Prometheus가 이를 수집하도록 설정했습니다.
개발
개발은 크게 세 단계 과정으로 진행했습니다.
- Confluent Platform 구축
- Confluent Platform을 구축할 쿠버네티스를 구성하고, 필요한 확장 요소를 설치한 후, Circle CI와 Harbor, Argo CD 등을 사용해 배포 파이프라인을 구성
- Confluent Platform을 구축하고 최적화하기 위한 Helm 차트들을 만들어 배포 파이프라인을 통해 적용하고 확인
- Confluent Platform을 어드민/인증/로깅/모니터링 시스템과 통합하기 위해 필요한 모듈들을 제작해 Confluent Platform Docker 원본 이미지에 추가 레이어로 올리거나 별도 애플리케이션으로 만든 후 사이드카 컨테이너로 Confluent Platform의 각 구성 요소들과 동일한 파드에 함께 배포
- 파이프라인 구축
- 오픈소스 Connector 외에 추가로 필요한 커스텀 Connector와 컨버터를 제작해 Confluent Platform의 기능을 확장하고 Kakfka Streams을 구현한 애플리케이션을 만들어 배포해서 데이터 파이프라인 구성 요소 갖추기
- 어드민을 통해 개별 데이터 파이프라인을 구성하고 작동 확인
- 운영을 위한 준비
- 성능 테스트
- 시스템 장애 상황 시뮬레이션
- 레거시 시스템 데이터를 새로 구축한 데이터 허브로 마이그레이션
각 과정을 보다 자세히 살펴보겠습니다.
Confluent Platform 구축
쿠버네티스 노드 풀 구성
노드 풀을 구성하기 위해서는 Confluent Platform 각 구성 요소와 함께 사용할 애플리케이션에 적합한 장비 스펙을 계산해야 합니다. 이번 프로젝트에서는 세 가지 스펙으로 장비군을 준비하고 노드풀을 생성했습니다.
| 장비군 | 설명 |
|---|---|
|
12코어 / 64GB 메모리 / 1TB 스토리지 대용량 장비군 |
|
|
8코어 / 32GB 메모리 장비군 |
|
|
8코어 / 16GB 메모리 장비군 |
|
쿠버네티스 워크로드 리소스 타입 정하기
데이터 허브를 구성하는 각 컴포넌트의 특성을 고려해서 아래와 같이 쿠버네티스 워크로드 리소스 타입을 정했습니다.
| 애플리케이션 | 워크로드 리소스 유형 | 비고 |
|---|---|---|
| Kafka | StatefulSets | |
| Zookeeper | ||
| ksqlDB | 일부 기능 미사용시 디플로이먼트 형태로도 가능 | |
| Kafka Connect | Deployment | |
| Schema Reigstry | ||
| Kafka Streams |
스토리지 선택하기 - 로컬 스토리지 VS 블록 스토리지
스테이트풀셋(StatefulSets)으로 배포하는 Kafka와 Zookeeper, ksqlDB는 스토리지가 필요하며, 선택할 수 있는 스토리지에는 아래 세 가지 형태가 있었습니다.
- 호스트패스(hostPath): 호스트패스 볼륨은 호스트 노드의 파일 시스템에서 파드로 파일 또는 디렉터리를 마운트합니다. 따라서 어떤 이유로 파드가 다시 시작되고 다른 노드에 파드가 새로 할당되면 동일한 경로에 이전 데이터가 존재하지 않습니다. 이는 보안 관점에서 위험하기 때문에 일반적으로 쿠버네티스 환경에서 권장하지 않습니다.
- 로컬 스토리지: 호스트패스의 단점을 극복할 수 있습니다. 볼륨을 프로비저닝해서 사용하기 때문에 파드가 다시 시작돼도 재부팅 전에 남아 있던 상태의 데이터 스토리지를 찾을 수 있습니다.
- 블록 스토리지: 로컬 스토리지가 모든 데이터를 서버에 로컬로 유지하는 반면, 블록 스토리지는 해당 데이터를 고속 중앙 집중식 스토리지 클러스터로 분리해 제공합니다. 스토리지만 별도로 확장할 수 있기 때문에 Kafka에 대용량 데이터를 장기간 보존해야 된다면 좋은 솔루션이지만 I/O 성능에 제약이 있습니다(10,000 IOPS(Input/Output Operations Per Second) 정도가 한계로 일반적인 용도로는 큰 제약이 아닐 수도 있습니다).
위 세 가지 스토리지 중 호스트패스는 서비스 용도로는 부적합하기 때문에 로컬 스토리지와 블록 스토리지 중에서 고민했습니다. 로컬 스토리지의 IOPS 성능이 블록 스토리지에 비해 10배 이상 우수하고 블록 스토리지가 단일 장애 지점으로 작용할 수 있다는 우려 때문에 로컬 스토리지를 선택했습니다. 이미 Kafka가 분산 환경에서 작동하고 내장애성을 갖추고 있는 상황에서 새로운 단일 장애 지점을 만드는 것은 부담이었습니다.
동적 프로비저너 설치
로컬 스토리지를 선택했으니 프로비저닝을 어떻게 할 것인지 선택해야 합니다. 프로비저닝에는 두 가지 방식이 있습니다.
- 정적 프로비저닝: 필요한 스토리지 볼륨을 미리 생성한 후 스토리지 클래스를 통해 사용합니다.
- 동적 프로비저닝: 스토리지 클래스를 정의해 놓으면 이 스토리지 클래스 스펙에 따라 필요할 때 자동으로 스토리지가 생성됩니다.
IaC(Infrastructure as Code) 장점을 최대한 살리려는 이번 프로젝트의 취지를 고려할 때 동적 프로비저닝이 적합하다고 판단했습니다. 다만 현재 쿠버네티스 클러스터에서 동적 프로비저닝을 기본 지원하지 않기 때문에 직접 솔루션을 찾아 설치해야 했는데요. 오픈 소스인 rancher/local-path-provisioner를 Helm 차트를 만들어 설치한 후 스토리지 클래스를 아래와 같이 정의했습니다.
StorageClass.yaml
{{ if .Values.storageClass.create -}}
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: {{ .Values.storageClass.name }}
labels:
app: {{ template "local-path-provisioner.name" . }}
release: {{ .Values.projectName }}
{{- if .Values.labels }}
{{ toYaml .Values.labels | nindent 4 }}
{{- end }}
provisioner: {{ template "local-path-provisioner.provisionerName" . }}
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: {{ .Values.storageClass.reclaimPolicy }}
allowVolumeExpansion: true
{{- end }}이 스토리지 클래스를 사용하는 Kafaka 설정은 아래와 같습니다.
KafkaStatefullSet.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ template "cp-kafka.fullname" . }}
...............
- name: KAFKA_LOG_DIRS
value: {{ include "cp-kafka.log.dirs" . | quote }}
................
{{- if .Values.persistence.enabled }}
{{- $disksPerBroker := .Values.persistence.disksPerBroker | int }}
{{- range $k, $e := until $disksPerBroker }}
- name: datadir-{{$k}}
mountPath: /opt/kafka/data-{{$k}}
{{- end }}
{{- end }}
...........
{{- if .Values.persistence.enabled }}
volumeClaimTemplates:
{{- $disksPerBroker := .Values.persistence.disksPerBroker | int }}
{{- $root := . }}
{{- range $k, $e := until $disksPerBroker }}
- metadata:
name: datadir-{{$k}}
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: "{{ $root.Values.persistence.size }}"
storageClassName: "{{ $root.Values.persistence.storageClass }}"
{{- end }}브로커 수만큼 순서대로 반복해서 스토리지가 동적 프로비저닝돼 생성되고 각 파드가 마운트해 사용합니다.
애플리케이션 공통 설정
모든 컴포넌트가 쿠버네티스 환경에서 작동하기 때문에 쿠버네티스가 올바르게 애플리케이션 생명 주기를 관리할 수 있도록 아래와 같은 설정들을 해야 합니다.
그레이스풀 셧다운(graceful shutdown) 설정
쿠버네티스는 서비스 객체와 파드 종료 처리를 병렬로 수행합니다. 생성할 때는 파드 준비 완료 후 서비스 객체를 업데이트하지만 종료 시에는 그렇지 않습니다. 따라서 아래 그림과 같이 요청이 누락되는 구간이 발생할 수 있습니다.
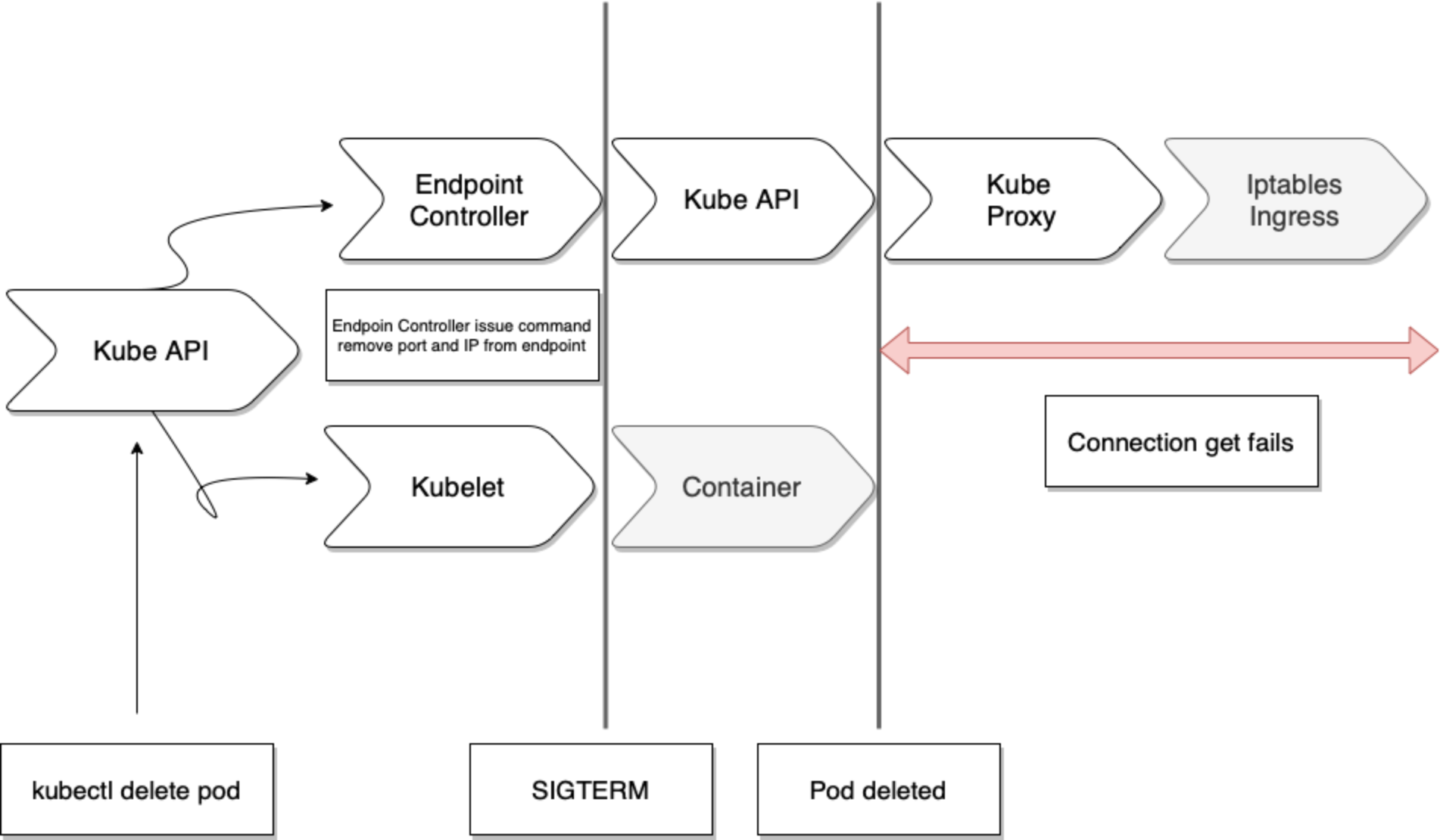
이를 방지하기 위해서는 아래와 같은 설정이 필요합니다.
- 애플리케이션에 그레이스풀 셧다운 옵션 설정
- 예를 들어 Spring Boot로 구축한 애플리케이션의 경우 아래와 같이 설정합니다.
- Boot.yaml
spring: lifecycle: timeout-per-shutdown-phase: 60s server: shutdown: graceful
preStopHook설정- SIGTERM 신호로 컨테이너가 종료되기 직전에 호출되는
preStopHook를 아래와 같이 디플로이먼트나 스테이트풀셋 Helm 차트에 설정합니다. - Deployment.yaml
lifecycle: preStop: exec: command: ["sleep", "10"]
- SIGTERM 신호로 컨테이너가 종료되기 직전에 호출되는
terminationGracePeriodSeconds설정- 이 설정값은 1번과 2번에서 설정한 값의 합보다 크게 설정해야 합니다. 예를 들어 앞서 1번과 2번 같이 설정했다면 컨테이너가 종료되기까지 최대 70초가 소요되기 때문에
terminationGracePeriodSeconds를 70초 이상으로 설정해야 합니다. - Deployment.yaml
template: spec: terminationGracePeriodSeconds: 75
- 이 설정값은 1번과 2번에서 설정한 값의 합보다 크게 설정해야 합니다. 예를 들어 앞서 1번과 2번 같이 설정했다면 컨테이너가 종료되기까지 최대 70초가 소요되기 때문에
프로브(probe) 설정
쿠버네티스가 애플리케이션의 상태를 정확하게 판단할 수 있도록 활성 프로브(livenessProbe)와 준비성 프로브(readinessProbe), 스타트업 프로브(startupProbe)를 설정해야 합니다. 아래는 Zookeeper의 활성 프로브 설정 예시입니다.
ZookeeperStatefulSet.yaml
livenessProbe:
exec:
command: [ '/bin/bash', '-c', 'echo "ruok" | nc -w 2 localhost 2181 | grep imok' ]
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 5
successThreshold: 1Kafka 설정
Kafka를 안정성과 성능을 고려한 최적의 상태로 사용하기 위해서는 파라미터를 조정해야 합니다. 아래와 같이 Helm의 Values.yaml로 설정한 파라미터들을 Kafka가 스테이트풀셋으로 배포될 때 읽어서 적용하도록 했습니다.
KafkaValues.yaml
configurationOverrides:
.............
"acks": "all"
"default.replication.factor": "3"
"min.insync.replicas": "2"
"offsets.topic.replication.factor": "3"
"kafka.transaction.state.log.replication.factor": "3"
"kafka.transaction.state.log.min.isr": "1"
"listener.security.protocol.map": |-
PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXTacks:"all", default.replication.factor:3, min.insync.replicas:2로 설정해서 동일 ISR(In-Sync-Replicas)에 속한 노드 한 대에 장애가 발생해도 서비스가 중단되지 않도록 하고 장애 노드를 복구할 수 없는 경우에도 데이터가 유실되지 않도록 설정했습니다.
파이프라인 구축
커스텀 Connector및 컨버터 개발
앞서 말씀드렸듯 커스텀 Connector 및 컨버터 개발과 관련된 자세한 내용은 추후 별도 포스트로 공유하겠습니다.
Kafka Streams 어플리케이션 개발
Kafka Streams은 Confluent Platform을 사용하지 않는 경우에도 Spring Boot 애플리케이션과 같은 형태로 이미 널리 구현 및 사용되고 있어 관련 자료가 많으므로 여기서는 설명을 생략하겠습니다.
각 Connector 설정
각 Connector 설정과 관련해서도 이번 글에서는 어떤 식으로 설정하는지 예시와 함께 간략히 소개만 하고 자세한 내용은 별도 포스트로 공유하겠습니다. 아래는 Mongo Sink Connector 설정 예시입니다. 아래와 같이 설정하면 Kafka Connector는 sample.topic에서 데이터를 읽어와서 connection.uri로 mongoDB에 접속한 후 common db의 sample 컬렉션에 데이터를 씁니다.
MongoSinkConnectorConfig.yaml
{
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"tasks.max": "1",
"topics": "sample.topic",
"collection": "sample",
"errors.deadletterqueue.context.headers.enable": "true",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy",
"database": "common",
"errors.deadletterqueue.topic.name": "sameple.sample-v1",
"name": "HidePostMongoDBSinkConnector",
"connection.uri": "mongodb://.............",
"value.converter.schemas.enable": "false",
"errors.tolerance": "all",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
}운영 환경 구축
인증 체계 통합
자체 개발한 사이드카 프록시를 사용해서 인증 체계를 통합했습니다. 이와 관련된 자세한 내용은 먼저 발행한 블로그 사이드카 프록시로 구현한 서비스 인증을 참고해 주시기 바랍니다.
어드민
KafKa-UI 오픈소스를 사용했으며 인증 부분은 위 인증 체계 통합과 같습니다.
로깅
로깅 파이프라인은 EFK(Elasticsearch, Fluentd, Kibana)로 구축된 로깅 플랫폼을 사용했습니다. 이때 로깅 플랫폼과 통합하기 위해서 두 가지 사전 작업이 필요했습니다.
우선 로깅 파이프라인이 지원하는 JSON 형식으로 로그를 출력하기 위해서 컴포넌트에서 사용하는 로거 종류별로 커스텀 레이아웃을 제작해 적용했습니다. 아래는 Logback용 레이아웃입니다.
LogbackJsonLayout.java
public class LogbackJsonLayout extends LayoutBase<ILoggingEvent> {
@Override
public String doLayout(ILoggingEvent loggingEvent) {
JSONObject jsonObject = new JSONObject();
jsonObject.put(Constant.FIELD_LEVEL, loggingEvent.getLevel().levelStr);
jsonObject.put(Constant.FIELD_LOGGER, loggingEvent.getLoggerName());
jsonObject.put(Constant.FIELD_TIME, loggingEvent.getTimeStamp());
jsonObject.put(Constant.FIELD_MESSAGE, loggingEvent.getFormattedMessage());
return jsonObject + Constant.NEW_LINE;
}
}이후 로깅 템플릿을 설정하고 위에서 제작한 레이아웃이 적용되도록 커스텀 Docker 이미지를 제작했습니다. 아래는 Schema Registry 예시입니다.
SchemaRegistryDockerImage
FROM confluentinc/cp-schema-registry:7.2.2
USER root
COPY files/log/ /usr/share/java/cp-base-new/
COPY files/log/ /usr/share/java/schema-registry/
COPY files/log4jtemplate/jdk.logging.properties /etc/schema-registry/jdk.logging.properties
COPY files/log4jtemplate/schema-registry.log4j.properties.template /etc/confluent/docker/log4j.properties.template위와 같은 방식으로 향후 유지 보수를 편하게 할 수 있도록 직접 소스 코드를 수정하지 않고 Docker 레이어를 추가해 모든 로깅을 처리했습니다.
알람
알람도 로깅과 비슷한 방식으로 처리했습니다. 로깅 템플릿에 전용 어펜더(appender)를 추가하는 방식으로 처리했고, 일정 레벨 이상의 로그는 알람 시스템으로 전송되도록 설정했습니다. 알람 규칙은 애플리케이션 로그와 쿠버네티스 시스템 로그 모두 한 곳에서 통합해 수집하며, 각 알람 규칙에 따라 지정한 경고 매체로 전송됩니다.
모니터링
Confluent Platform에서는 JMX Exporter를 사이드카로 사용해 Prometheus가 접근할 수 있도록 했고, Spring Boot로 제작한 Kafka Streams 애플리케이션에서는 Acutuator/Prometheus 방식을 선택했습니다.
- JMX Exporter 설정
- JmxExporter.yaml
prometheus: jmx: enabled: true image: bitnami/jmx-exporter imageTag: 0.17.0-debian-11-r30 ......
- JmxExporter.yaml
- Spring Boot Acutuator 설정
- BootActuator.yaml
endpoints: web: exposure: include: health,prometheus
- BootActuator.yaml
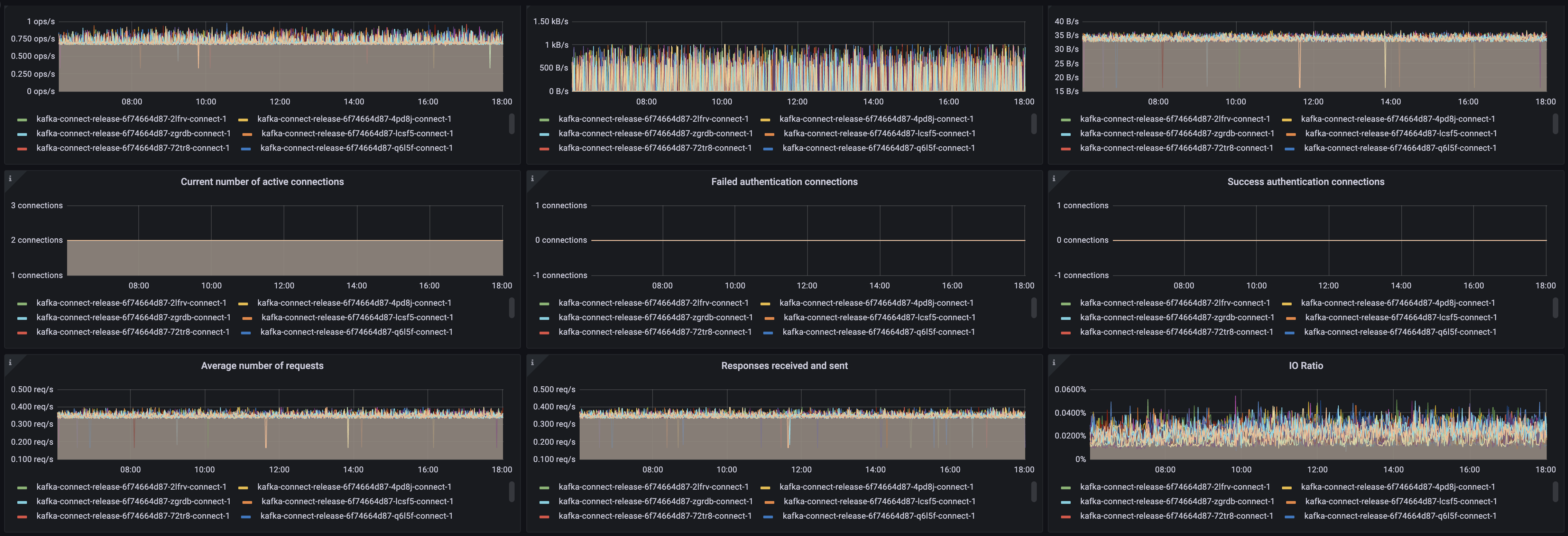
두 로그 모두 사내 인프라로 제공되는 공통 모니터링용 Prometheus로 수집해서 이를 Grafana 보드로 볼 수 있도록 구성했습니다. 모니터링하면서 수집한 지표 중 중요 지표에 대해서는 시스템 이상 징후를 조기에 알 수 있도록 알람 규칙을 설정했습니다.
새로운 데이터 파이프라인을 적용한 후 달라진 점
유연하고 재사용 가능한 파이프라인 구성 가능
설정 기반으로 파이프라인을 구성할 수 있다는 Confluent Platform의 특성은 여러 가지로 큰 메리트였습니다. 데이터 스키마가 변경될 경우 Schema Registry를 변경하는 것만으로 대응할 수 있고, Source와 Sink 스토리지 변동도 각 Connector 설정 변경으로 대응할 수 있습니다. 또한 새로운 파이프라인이 필요할 때도 이미 개발해 놓았거나 오픈소스 Connector로 대응할 수 있는 경우에는 개발을 전혀 하지 않고도 대응할 수 있습니다. 보유한 Connector 개수가 늘어날수록 설정만으로 구성할 수 있는 파이프라인 종류의 수가 곱절로 늘어나고, 개발자는 반복 작업에서 해방될 수 있습니다.
아래는 MongoSinkConnector와 MirrorSourceConnector를 설정만 바꿔서 다양한 파이프라인에서 반복해서 사용하는 예시를 보여주는 어드민 화면입니다.
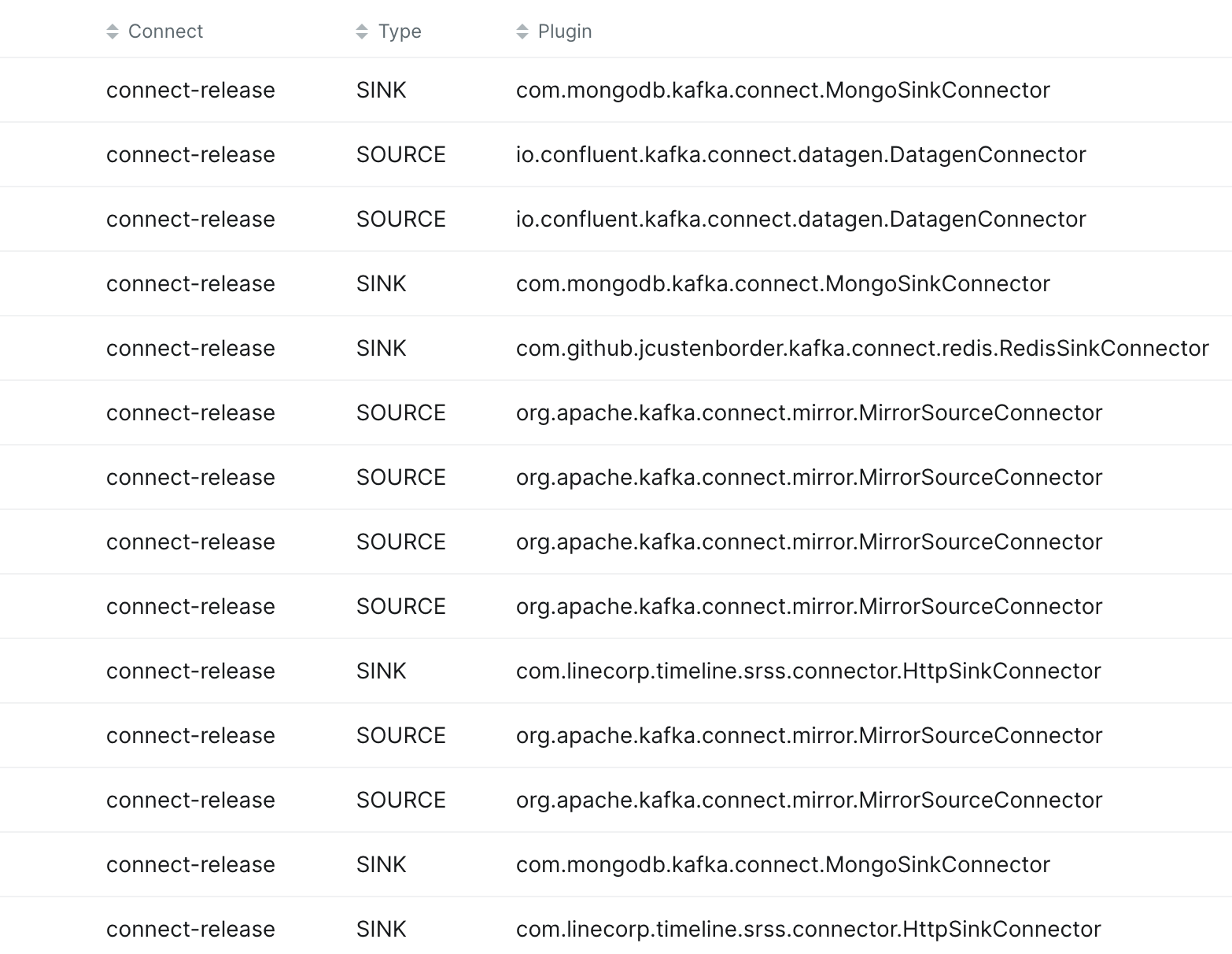
데이터 처리 순서 보장
API 서버에서는 일반적으로 다수의 서버를 로드 밸런서에 묶고 로드 밸런서가 라운드 로빈과 같은 알고리즘을 사용해 수신한 요청을 각 서버에 분배합니다. 이런 구조에서는 데이터의 정확한 순서를 보장할 수 없습니다. 서버별로 처리에 필요한 시간이 미묘하게 다르기 때문입니다.
예를 들어 A와 B 두 개의 메시지가 순서대로 발생해서 로드 밸런서를 거쳐 A 메시지는 A1 서버에, B 메시지는 B1 서버에 할당됐다고 가정하겠습니다. A1 서버는 이전 요청을 처리하고 있어서 처리하는 데 300ms가 걸렸고 B1 서버는 수신 즉시 데이터를 처리해서 10ms가 걸렸다면 데이터 처리 순서가 B, A로 역전됩니다. 그렇다고 로드 밸런서 없이 API 방식을 사용하면 확장성과 안정성이 극히 제약돼 현실성이 없기 때문에 API 방식에서는 구조적으로 완벽한 처리 순서를 보장할 수 없습니다.
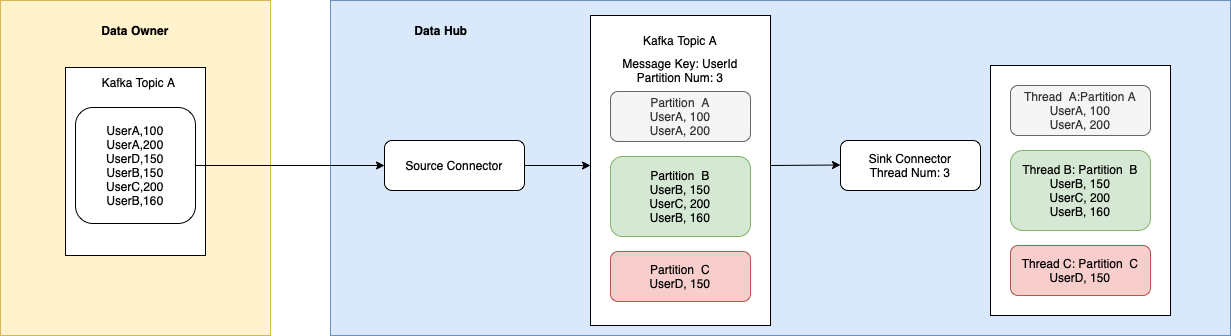
이에 비해 이번에 구축한 데이터 허브에서는 데이터를 처리하는 순서를 확실하게 보장할 수 있습니다. Confluent Platform의 Source Connector는 데이터 소스에서 데이터를 순서대로 읽고 이를 Kafka에 저장합니다. Kafka는 수신한 데이터를 메시지 키를 기준으로 파티션에 할당합니다. 키가 같으면 동일한 파티션에 배분되고, 이를 소비하는 Kafka Connect와 Kafka Streams, ksqlDB는 파티션 수만큼 스레드를 할당합니다. 각 스레드는 파티션을 하나씩 전담해서 처리하기 때문에 동일한 파티션에 속한 데이터는 순서대로 처리됩니다. 따라서 키를 잘 부여한다면 데이터 처리 순서를 보장하는 파이프라인을 구축할 수 있습니다.
모든 데이터 파이프라인에서 순서 보장이 중요한 것은 아니지만, 이번 프로젝트에서는 일부 파이프라인의 경우 순서 보장이 필수 조건이었는데요. 이때 메시지 키를 적절히 선택하는 것만으로 데이터 처리 순서를 보장하는 파이프라인을 쉽게 구축할 수 있었습니다.
확장 용이
모든 것이 쿠버네티스 환경에 있기 때문에 스케일 아웃은 단순히 Helm 차트의 Values 값을 변경하는 것만으로 수행할 수 있습니다. 아래와 같은 브로커 설정에서 brokers의 수를 원하는 값으로 변경하는 것으로 확장 작업은 끝납니다. 확장 시 브로커의 고유 ID는 템플릿 설정에 따라 자동으로 정의되므로 충돌 가능성은 없습니다.
BrokerValues.yaml
brokers: 14
resources:
limits:
cpu: 10000m
memory: 56000Mi
requests:
cpu: 10000m
memory: 56000Mi내결함성 향상
시스템 탄력성
데이터 허브에 유입되는 데이터와 이벤트의 양은 때때로 매우 큰 폭으로 변동합니다. 일반적인 시스템은 시스템이 처리할 수 있는 최대 TPS를 초과한 데이터가 유입될 경우 인스턴스 단위당 처리량이 감소합니다. 따라서 특정 임계치를 넘어서면 시스템은 급격히 처리 능력이 감소하며 장애가 발생합니다.
하지만 Confluent Platform을 기반으로 데이터를 풀(pull) 방식으로 처리하도록 구축한 결과 최대 처리량을 초과하는 데이터가 유입되는 환경에서도 일정한 처리량을 보장하며 시스템 장애를 예방할 수 있었습니다(다만 아래에서 말씀드릴 파이프라인 최적화는 과제로 남았습니다).
셀프 힐링
모든 컴포넌트를 쿠버네티스 환경에 넣은 결과 시스템 이상 징후 발견과 조건에 따른 셀프 힐링이 가능해졌습니다. 예를 들어 Kafka Connect 파드에서 이상이 발견되면 쿠버네티스에서 일정 시간 경과 후 제거하고 새로운 파드를 자동으로 배포합니다. 한밤중에 하드웨어 장애가 발생한다면 개발자는 모든 상황이 자동으로 종료된 후 상황을 확인만 해도 됩니다. 다만 스테이트풀셋으로 배포한 Kafka와 Zookeeper, ksqlDB는 셀프 힐링을 일부 제한적으로 적용했습니다. 스테이트풀셋에도 셀프 힐링을 적용하는 것이 기술적으로는 가능은 하지만, 여러 노드에 동시에 장애가 발생할 경우 자칫 데이터가 유실될 염려가 있기 때문입니다.
쉽고 편리한 모니터링
권한이 있는 사람은 누구나 어드민에서 파이프라인 설정을 확인해 데이터 흐름을 파악할 수 있고, 대시보드를 통해서 현재 파이프라인 상태를 진단할 수 있습니다.
향후 과제
Mirror Maker2를 커스텀 Source Connector로 대체
Kafka to Kafka 데이터 파이프라인에는 앞서 설명드린 것처럼 Mirror Maker2(이하 MM2)를 적용했습니다. 적용 후 정상 작동했지만 커스텀 Connector로 대체해야겠다고 느꼈는데요. 근본적인 이유는 MM2가 데이터 파이프라인 구축용 Connector가 아니기 때문입니다. MM2는 본래 클러스터 토픽의 미러링이나 복제가 목적이고 그 용도에 맞게 개발됐습니다. 아래는 MM2로 클러스터의 토픽을 복제하는 것을 나타낸 그림입니다.
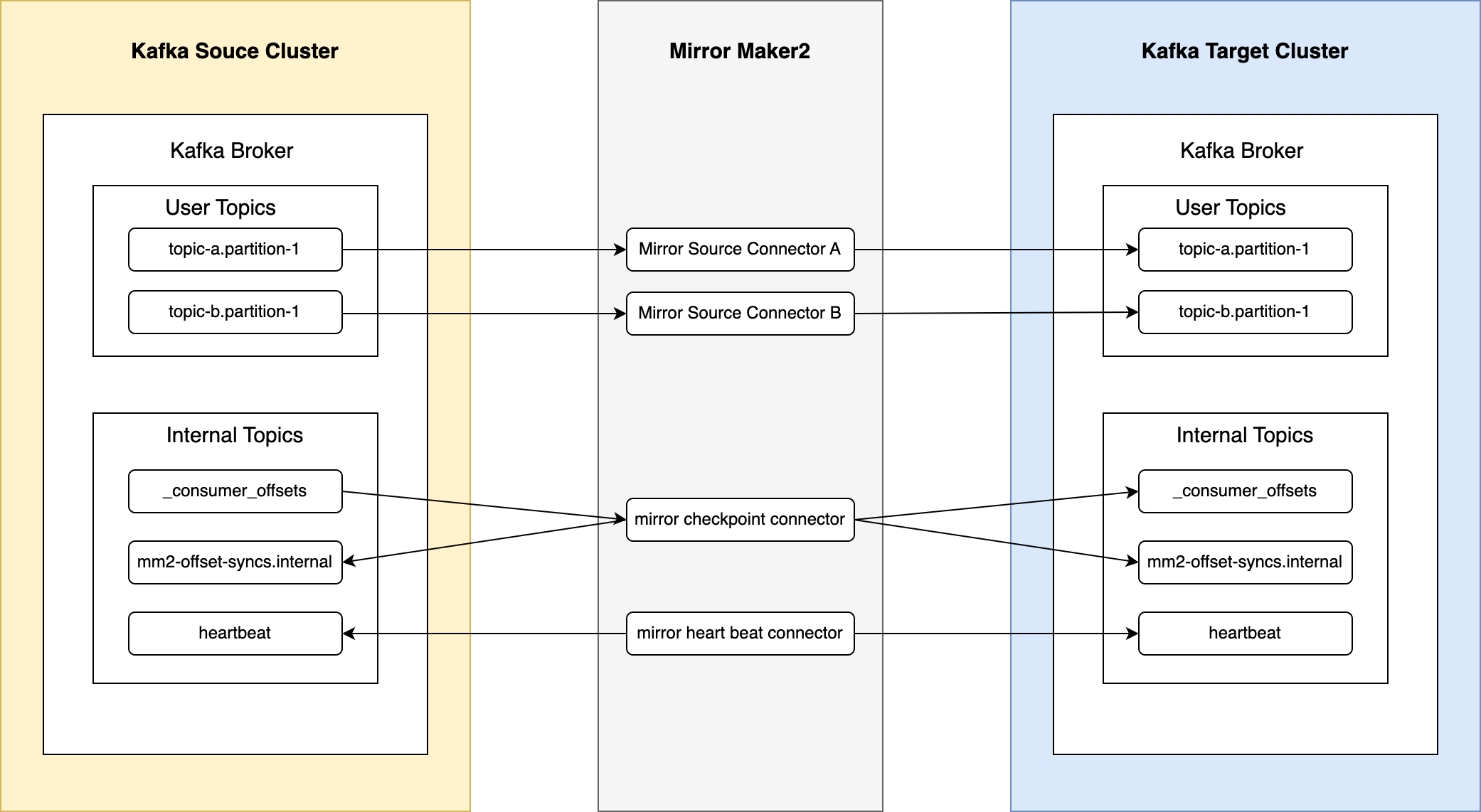
구체적으로 아래와 같은 점 때문에 데이터 파이프라인용으로는 부적합했습니다.
- 클러스터 토픽의 미러링이나 복제가 목적이기 때문에 원본 클러스터 토픽 상태 그대로 타깃 클러스터 토픽을 복제합니다.
- 예를 들어 원본 토픽의 파티션 수가 타깃 클러스터에도 동일하게 적용됩니다. 만약 파이프라인 과정 중 필터와 같은 변환 과정이 포함되면 원본과 타깃의 데이터량이 같지 않은데요. MM2는 이때에도 타깃 파티션 수가 원본과 동일하게 적용됩니다.
- 단순 파이프라인 구축용으로 필요한 기능보다 필요하지 않은 기능이 많습니다.
- MM2의 본래 목적이 클러스터 토픽 자체를 복제하는 것이기 때문에 위 그림과 같이 복잡하게 작동합니다. 예를 들어 일반적인 Source Connector는 보통 컨슈머와 같이 마지막으로 가져온 데이터의 오프셋을 하이 워터 마크(high water mark)로 기록할 뿐이지만, MM2는 양방향으로 별도의 내부 토픽에 기록합니다.
- 더욱이 MM2의 경우 소스와 싱크 클러스터 간 양방향 토픽 복제 기능을 지원하기 위한 설계도 포함하고 있어 더욱 복잡한 면이 있습니다.
위와 같은 이유로 MM2를 대체할 Kafka Source Connector를 개발할 필요가 있다고 느꼈습니다.
파이프라인 최적화
실제 데이터를 받아서 운영해 보니 특정 이벤트의 경우 데이터 유입량이 폭증할 때 처리 지연이 발생하기도 했습니다. 시스템 특성 덕분에 장애로 이어지지는 않았지만 파이프라인 ETL을 구성하는 각 컴포넌트에 성능 차이가 존재한다는 것을 확인했고, 이를 개선해서 각 컴포넌트를 최적의 비율로 배치하는 작업을 앞으로 운영해 나가면서 계속 수행하려고 합니다.
- 메시지 유입량
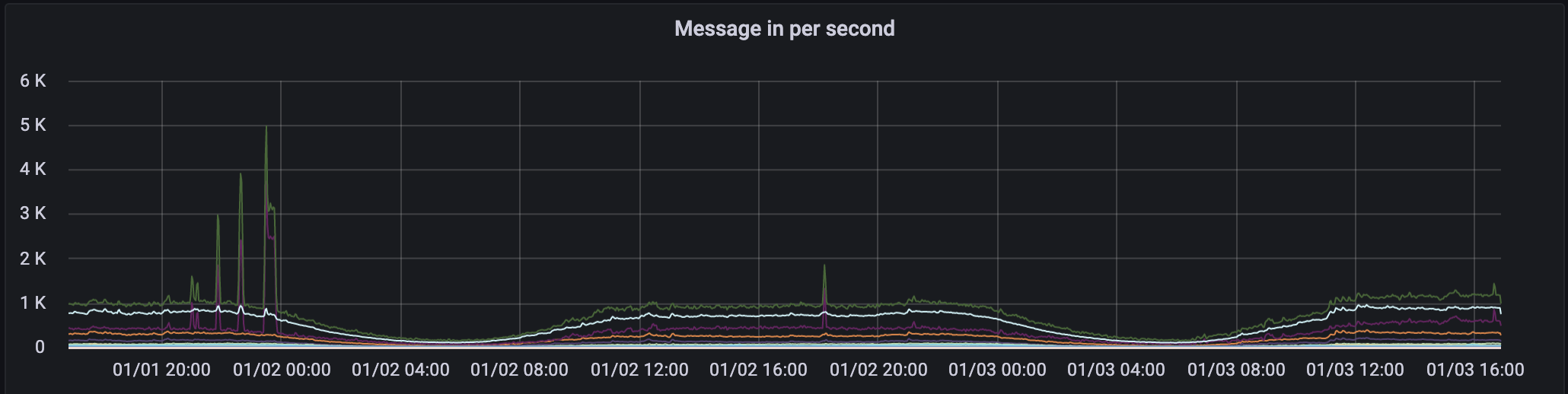
- 메시지 랙(lag)
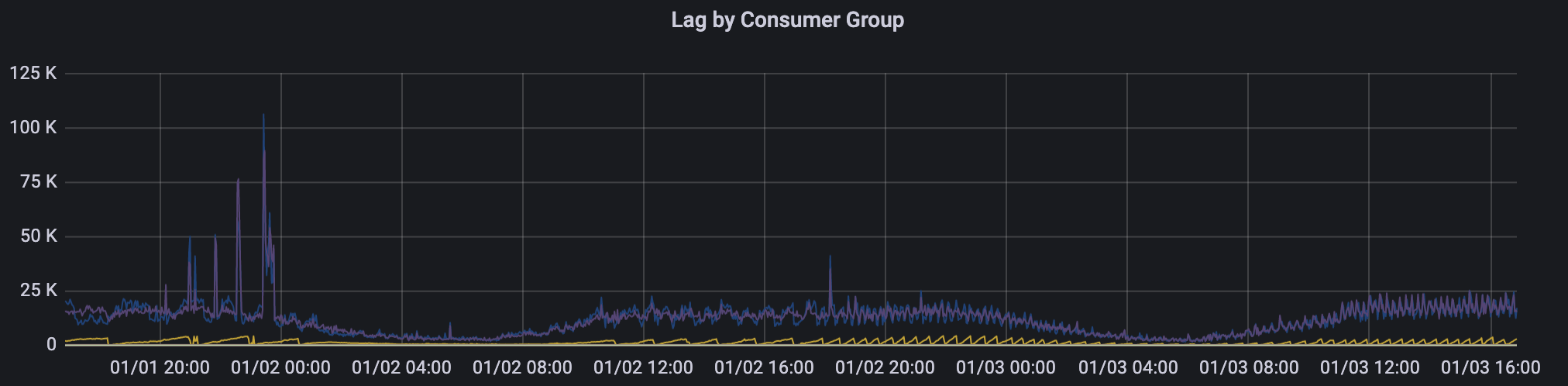
마치며
한정된 지면에 모든 내용을 다 담을 수는 없었습니다. Confluent Platform 구성 요소 전부를 쿠버네티스 환경에 올려 서비스 수준으로 고도화하는 작업은 정말 많은 노력이 필요했습니다. 고도화를 위한 추가 과제가 아직 남아 있지만, 최초에 새로운 데이터 허브의 목표로 삼았던 핵심 가치들을 어느 정도 충족했다고 자평하면서 그동안 같이 고생해 주신 분들께 감사 인사를 드립니다.
무엇보다 '실패를 두려워하지 말고 도전하라'는 LINE의 문화와 이 문화 속에서 함께 일하는 동료들, 그리고 그 문화를 이끌어 주시는 경영진이 있기에 이처럼 새로운 기술과 아키텍처로 프로젝트를 수행할 수 있었다고 생각합니다. 제 경험이 여러분께도 도움이 되길 바라며 이만 마치겠습니다. 긴 글 읽어주신 독자 여러분 감사합니다.