
この記事は UIT 新春 Tech blog 4 日目の記事です。
こんにちは。LINE フロントエンド開発センターの前川です。主にフロントエンド開発センターで働く方々のDX改善や、社内サービスの運用を行なっています。
私の所属しているチームは、フロントエンドと名前はついているものの、実際はフロントエンドとそれ以外の業務の割合が2:8程度という珍しいチームです。そのため、技術記事というカテゴリからはやや外れてしまいますが、その業務内容をご紹介したいと思います。
LINEを支えるプラットフォーム
本題に入る前に、まずはLINEのプロダクトがどのようなプラットフォームの上で動作しているか説明します。
LINEでは、Verdaというプライベートクラウド環境を運用しており、LINEのほとんどのプロダクトはこのVerdaの上で動いています。
LINE NEWSやLINEギフトといった、フロントエンド開発センターのプロダクトもその例に漏れず、Verda上で稼働しています。
内製のプライベートクラウドがあるということは、Verdaを運用しているバックエンド・インフラ開発者の方々とダイレクトにコミュニケーションを取れる環境があることになります。
そのため、Verdaの機能等で分からないことがあっても、問い合わせをし、すぐ返事が返ってくる環境があり、綿密に連携を取りながら問題解決を行うことができます。
一方で、フロントエンド開発者にとってはやや扱いが難しい点もあり、それらについては後述致します。
Verdaの詳しい情報に関しては、こちらの記事をご参照下さい。
https://engineering.linecorp.com/ja/blog/verda-at-cloudnative-openstack-days-2019-1-2/
https://engineering.linecorp.com/ja/blog/verda-at-cloudnative-openstack-days-2019-2-2/
LINEのフロントエンド開発におけるDevOpsの成り立ち
Verdaはフロントエンド開発者の為だけに作られたサービスではないため、様々な機能を、自由に組み合わせて開発を行えるように作られています。
裏を返すと、フロントエンドのプロダクトを開発するという用途に絞るには、自由度が高すぎるという問題があります。
例えば、静的なリソースをCDNで配信したいだけなのに、Verdaのダッシュボードにアクセスして、CDNのセットアップをし、キャッシュやCNAME、オリジンの設定をして・・・といった風に、様々な設定を行う必要があり、学習コスト、運用コストがかかってしまうという問題がありました。
このように、フロントエンド開発者からよく上がる、
- Herokuのように簡単にアプリをデプロイできるサービスが欲しい
- 複雑な環境設定を省き、必要な項目の設定のみで、静的なリソースの配信を行いたい
などといった要望を実現する為に、フロントエンド開発者のためのDevOpsやDX改善を考える組織が立ち上がりました。
フロントエンド開発者の仕事の広がり
ところで、昨今、フロントエンド開発というと、どんどん業務の領域が広がっています。
一昔前では、フロントエンド開発と言えばHTMLやCSS、JavaScriptを駆使し、ユーザに見える画面部分を作成する仕事でした。
しかし、現在では、フロントエンド開発者の業務範囲はどんどん拡大しています。
例えば、Vue.jsやReactでサーバサイドレンダリングをしようと思うと、バックエンドのNode.jsの最適化の知識などが必要になってきたりしますし、firebase等で手軽にサーバレス構成等ができるようになり、フロントエンド開発者だけで一気通貫してアプリを作り上げられるようになってきており、理解していないといけない知識・知見の範囲が急拡大しており、これからもさらにできることが増えていくことが予想できます。
LINEの作るフロントエンドのプロダクトもその例に漏れず、LINE LIVEBUYといった双方向コミュニケーションを行うような複雑なものが出てきています。
このように、フロントエンド開発者側でできることが増えると共に、色んな知識が必要になってきており、LINE社内ではもちろんの事、社外では例えばLINE DEVELOPER DAYやカンファレンス等、様々な場所で技術共有や勉強会を積極的に行っています。
LINEでサービスを作る場合、バックエンド開発者と組んで動作基盤を作ることがほとんどです。
バックエンドとフロントエンド部分で完全に分業してしまうと、先程サーバサイドレンダリングの話を挙げましたが、仕組みを説明するためのコミュニケーションコストも高くつきますし、お互いの認識に齟齬がある場合に、手戻りが発生してしまうリスクすらあります。
そのため、そうした開発を行う上で、どんな知識が必要になってくるか、どのように勉強していけばいいか、というノウハウを蓄え、他のフロントエンド開発者に共有し、全体の知識向上を目指す、SRE TF(SRE TaskForce)というグループが発足しました。
現在、このグループでは、フロントエンド開発におけるデプロイ作業の効率化や一貫性向上、開発環境の改善などを目標として、フロントエンド開発者用の開発基盤 (BFF - Backends for Front-ends - 基盤) の構築を目指し、kubernetesに関する情報共有・ノウハウの展開を行なっています。
ここで、なぜkubernetesなのか、という疑問が生まれるかもしれません。
理由としては、LINEが全社的に、kubernetesを活用して運用効率を最大化することを推奨している事や、VerdaにもVKSというKaaS (Kubernetes as a Service) 基盤が提供されている為、検証・運用が始めやすい環境が整っている、という事があります。
DevOpsの仕事
LINEのフロントエンド開発者を取り巻く環境や問題について踏まえた上で、本題に入ります。
私たちは、フロントエンド開発センターの皆さんの業務を改善すべく、以下のようなサービスを開発・運用しています。
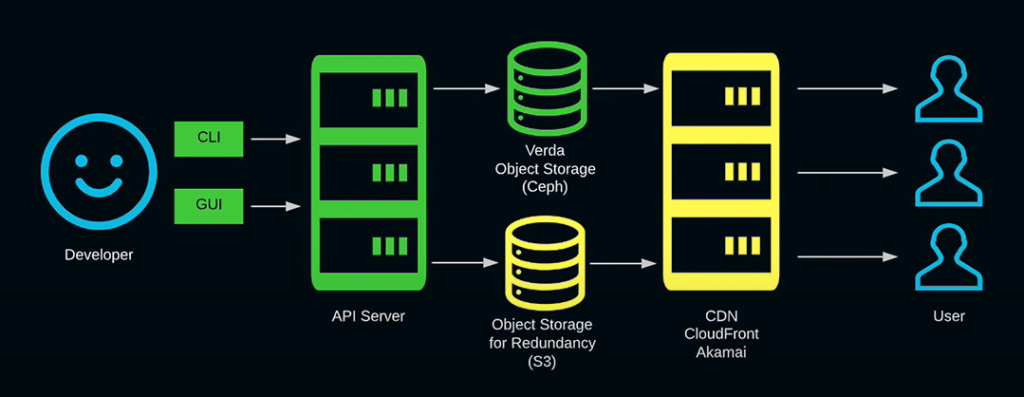
Abyss
簡単な操作で、プロジェクト内の静的なリソースをCDNから配信することができるサービスです。
フロントエンド開発者はCLIかGUIを通して、静的リソースをデプロイ・管理することができます。
例えば、以下のような機能があり、ユーザは背後のVerda環境を意識する事なく各種機能にアクセスでき、自分の担当業務に集中することができます。
- 誰が、いつデプロイを行なったのかの履歴確認
- 問題発生時のデプロイやCDNのログの確認
- 静的リソースの権限管理、キャッシュ設定などの管理
- 自分のプロジェクトのファイル一覧をGUIで確認し、各ファイルの操作を行う機能
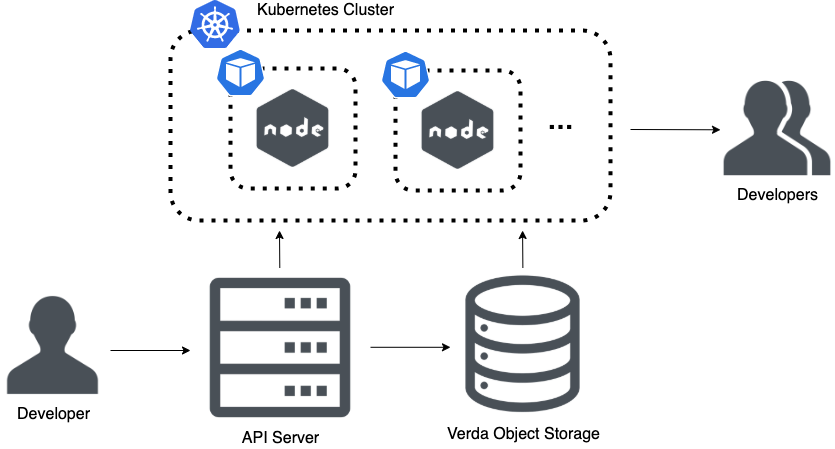
Belchero
Node.jsで作成されたウェブアプリケーションを、コマンド一つで配信することができるサービスです。
自分の作ったウェブアプリケーションをワンコマンドで社内に公開することができ、環境構築と設定の手間を大きく減らすことができます。
このサービスはkubernetesクラスタ上に展開されており、その冗長性や拡張性に優れた特性を活かして、機能拡張と安定運用を続けています。
Abyss, Belcheroに関する詳しい説明に関しては、やや情報が古いですが、以下の動画をご参照ください。
Private NPM
LINEでは社内向けのnpm packageの管理の為に、Private NPMを運用しています。
こちらに関しては、8日目の記事として、私と同じチーム所属の吉澤さんがPrivate NPMについての記事を書きますので、そちらをご覧いただければと思います。
日々の業務の紹介
こうしたサービスの開発運用を行う中で、紹介も兼ねて、最近私が行なった業務の一部をご紹介します。
ジョブスケジューラーの改善
今までは、定期的に実行するジョブはcrontabで管理・実行していました。
しかし、crontab単体では以下のような問題がありました。
- ログが参照しづらい
- 処理失敗時のリトライ処理がない
- 処理終了時に柔軟に通知を送る機構がない
- cronの処理を行うサーバの冗長化が難しい
そこで、以上の問題を解決するための基盤を作成することになりました。
調査してみると、この問題を解決するためのサービスがかなりの数あり、その中から選定することになりました。
参考: https://github.com/meirwah/awesome-workflow-engines
(複雑なジョブを実行する基盤のことをワークフローエンジンと呼ぶそうなので、以降はその呼称を利用することにします)
こうしたワークフローエンジンは機械学習の前処理等に使われる事があり、この中の多くはPythonで記述する事を前提としています。
フロントエンド開発者はJavaScriptをメインに触ってきており、Pythonを触る機会が少ないという方が多いため、今後のメンテナンスの容易性等を考慮し、そうしたものの採用は避けることにしました。
その中で、Kubernetes環境上で動作する、Argo Workflowというサービスがあります。Kuberenetesのサービスを運用し、ノウハウを蓄積し、周りに技術共有できれば、SRE TFの目的とも合致します。
また、Argo Workflowの姉妹プロダクトであるArgoCDを使う事で、GitHub上で管理しているソースを定義元として、各種リソースを管理できるという運用上のメリットもあります。
このメリットは非常に有用で、例えば、実行するジョブをひとつ追加する場合に、その方法ひとつとっても、様々な手段が存在します。
- Argo WorkflowのUIから
- KubernetesのCLI (kubectl) から
- その他Kubernetesクラスタにアクセスする手段から
これを、GitHubリポジトリをSSOT (単一の情報源) として情報を集約することで、
- GitHubの機能を活用できる (PRを投げてソースのチェックを行ったりその記録を残したりでき、ブランチを分けて各環境を管理できる)
- 現在稼働中のジョブのデプロイ方法やソースを確認したい場合、GitHubリポジトリを見に行くだけで済む
- そもそも更新履歴が残るので、過去から現在の状況を容易に把握できる
という環境を作り出す事ができます。
メリットだけ書いても不公平なので、デメリットも書くと、以下のようなものがあります。
- Kubernetes、ArgoCD、Argo Workflowの学習コスト
- Argo自体がCNCFのIncubation段階であるため、大きな機能変更やバグ存在の可能性
社内のエンジニアしか使わないという事と、入念な動作検証を行い、現状の使途に十分耐えられそうという事で、Argo Workflowを選定する事にしました。
構成は以下のようになります。
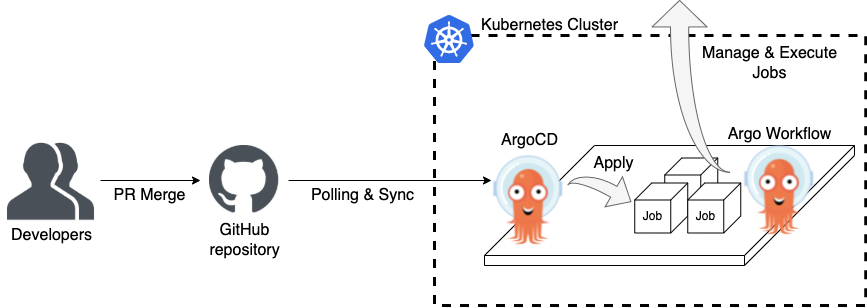
Argo Workflowの運用にあたり、いくつか工夫した点をご紹介します。
Workflow Templateの活用
Argo Workflowでは、処理の実行単位の事をWorkflowと呼称します。
このWorkflowはKubernetesの定義ファイルとして記述するので、慣れていない人が新しくWorkflowを追加するには、やや煩雑です。
Argo WorkflowにはWorkflow Templateという機能があり、繰り返し使う機能をパーツごとにテンプレートとしてまとめ、簡単に再利用する仕組みがあります。
そこで、以下のようなテンプレートを用意する事で、一番よく使う用途では、いくつかのパラメータを設定するだけで簡単にWorkflowを作成することができるようにしています。
# 特定のURLにリクエストを送るテンプレート。urlとretriesのパラメータを元に、curlのimageを呼び出して、リクエストを送る
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: kick-api-template
spec:
# kick-apiテンプレートをの処理を行い、終了時にexit-handlerテンプレートの処理を行う
entrypoint: kick-api
onExit: exit-handler
arguments:
parameters:
- name: url
# ここでvalueを指定しておくと、デフォルト値になり、実際のWorkflowの定義時にパラメータを省略できる
- name: retries
value: "3"
templates:
- name: kick-api
inputs:
parameters:
- name: url
- name: retries
retryStrategy:
limit: "{{inputs.parameters.retries}}"
retryPolicy: "Always"
container:
image: curlimages/curl
command: [curl]
args: [--fail-with-body, -L, -sS, "{{inputs.parameters.url}}"]
- name: exit-handler
# 終了時の処理。もし処理が失敗していたら (workflow.status != Succeeded) 、notifyテンプレートを呼び出す
steps:
- - name: failure-notification
when: "{{workflow.status}} != Succeeded"
template: notify
- name: notify
# 失敗時の処理。slackのwebhook等にリクエストを送ることで通知を行う
container:
image: curlimages/curl
command: [curl]
args: [--fail-with-body, -L, -sS, "http://example.com"]上記のテンプレートを使う場合、以下のように雛形をコピーしてきて、 `schedule` と `url` パラメータを設定し、呼び出すテンプレートを指定するのみで、リクエストを送信し、失敗時に通知を飛ばすジョブの作成ができるようになります。
apiVersion: argoproj.io/v1alpha1
kind: CronWorkflow
metadata:
name: sample-job
spec:
# crontabと同じ記載方法で、実行時刻を指定
schedule: '0 0 * * *'
timezone: 'Asia/Tokyo'
concurrencyPolicy: 'Allow'
workflowSpec:
arguments:
parameters:
# リクエストしたいurlを記載
- name: url
value: 'http://example.com'
# 使用するテンプレートの選択。テンプレートのmetadata.nameを参照する
workflowTemplateRef:
name: kick-api-template設定の差分の明確化
今回運用するArgo Workflowは、公式からデフォルトで用意されている定義ファイルに対して、いくつか改変を加えて運用しています。
- ジョブのログの保存先として、Verda Object Storageを利用
- 永続性確保のため、外部のMySQLにWorkflowの構成や、実行履歴等を保存
- セキュリティ担保のため、Argo Workflowのログイン認証として、GitHub認証を利用
これら変更点は、Kustomizeという、我々が改変を加えた部分を差分で用意できる仕組みを使う事で、改変部分を明確にし、かつデフォルトの定義ファイルに直接改変を加えずに、設定変更を実現しています。
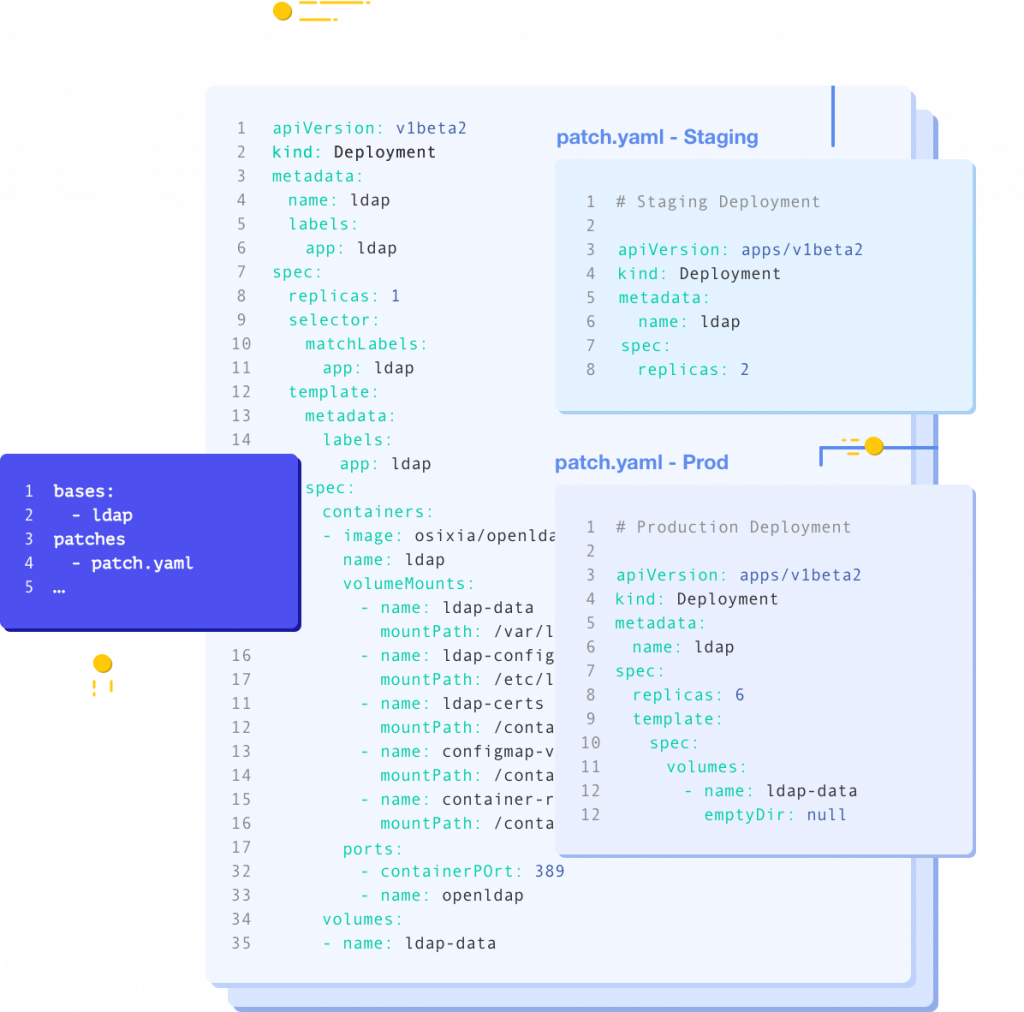
デフォルトの設定に対して、どこに改変が加えたのか把握できることは非常に重要です。
問題発生時、原因の切り分けが容易になりますし、公式が構成を変えても、差分ファイルが別にあるので、そのまま上書き更新するのみで更新が完了します。
他の方がメンテナンスを行う際に、どこを改変したのかを容易に把握できるという点も利点として挙げられます。
Kustomizeは、差分ファイルを用意するか、特定の定義ファイルを丸ごと置き換えるという挙動で改変を行います。その為、複雑な設定変更を行うと、記述がやや煩雑になりがちだったり、誤った更新により容易にサービスが動作しなくなるとう欠点があります。
その為、どこをどういう風に、どういう目的で改変したのかというドキュメントを用意したり、近い箇所の改変は近いところにまとめるなど、工夫する必要があります。
テスト環境の用意
Kubernetes自体がややとっつきにくい事もあり、上記のテンプレートの用意だけして、そのまま本番環境に反映する、というのは、慣れていない人にとってはややハードルが高いです。
そのため、素振りしながら動作確認できる、本番環境のコピー環境 (sandbox環境) を用意する事で、sandbox環境で動作確認が取れたもののみを本番環境に導入できる、という仕組みを作っています。
これ自体は特別難しいことはしていないのですが、既にKubernetesの定義ファイルを作成していたので、本番環境と同等の環境構築が非常に簡単に行う事ができました。
Kubernetesの環境構築を行う中で、その優位性を説明するのに役立つ体験だったので、ご紹介させていただきました。
loggingの改善
ここまでKubernetesの話ばかりしてきましたが、もちろんそれ以外の改善も行なっています。
そのうちの一つ挙げると、各サービスのログの集約があります。
今までAbyssやBelchero、Private NPMで問題が起きた際には、サーバに直接ログインして、システムログを参照する事で、原因究明にあたっていました。
しかし、サービスを複数台のサーバで冗長化構成を組んで運用していたりすると、全てのサーバを見に行かなければいけなかったり、ログの検索性もあまり良くなかったり、といった問題がありました。
また、昨今、セキュリティに関連して、ログデータの価値が一段と高まっています。ある時間帯での時系列データを追ったり、普段とは異なるトラフィックの傾向に気付くために、ログの傾向等も追える必要があります。
それらの解決策の一環として、ElasticSearchに各サービスのログを集約して、管理できるようにするといったことを行なっていました。
このような構成で構築しています。
(あまりにも一般的な構成なので、構成図を書くまでもなかったかもしれませんね・・・)
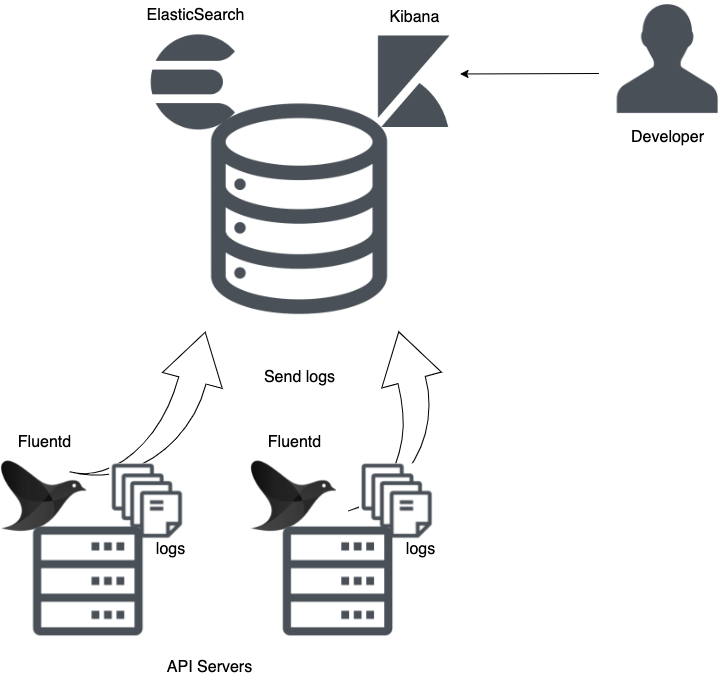
この構成に加えて、APIサーバの同じリクエストに対しては同一のタグを振り、そのリクエストのログを時系列として追えるようにしたり、システムログに付加する情報を取捨選択することで、ElasticSearchのログが肥大化しすぎないようにするといった対策を行いました。
一方、Belcheroのログ収集に関してはやや特殊で、Kubernetes上で動いているサービスのため、それにあったログ収集を行わなければならず、やや工夫が必要でした。
そもそものログの量が膨大なため、不要なシステムログに関してはElasticSearchに送信する対象から排除できるよう、パラメータを柔軟に設定できるようにしました。ログ収集の仕組み自体もKubernetesの上で稼働しているので、これらの設定はKustomizeで行うようにし、Kubernetesの設定方法と親和性を高めるようにしています。
・・・結局Kubernetesの話に戻ってきてしまいましたが、たまたまです。
普段各サービスの開発運用を行う上で、その規模に合った、最適な技術スタックを選択し、業務にあたっています。
このように、私たちは「フロントエンド開発をしている」というよりは、「フロントエンド開発者の為のツールを開発運用したり、意見を吸い上げてDX改善をしている」という事をやっています。
フロントエンド開発がどんなものかを知っていないと、開発者の求めるプロダクトはできないですが、このようなサービスの開発運用には、バックエンドの知識や、高負荷を捌く最適化のノウハウが必要になってきたりと、幅広い分野の知識が必要になってきます。
要望の吸い上げや、トラブル対応、機能追加の業務に携わっているだけで、非常に広範な知識が身に付く、エンジニアとして幸せな環境でもあります。
まとめ
この記事では、フロントエンド開発者の組織内にありながら、フロントエンドの領域に留まらない様々な技術を活用し、組織内の業務支援を行なっているチームについてご紹介しました。自分が手を挙げれば様々な技術に挑戦することができるため、幅広い技術に興味がある自分としては、知識欲を満たせるとても良い環境です。
皆様も興味がありましたら、ぜひお問い合わせ下さい。
採用について
フロントエンド開発センターでは、フロントエンド開発者はもちろんのこと、そのフロントエンド開発者を支えるプロダクト開発を行うエンジニアも募集しております。
興味のある方は、カジュアル面談など気軽に話を聞くこともできますし、定期的に採用イベントなども開催しておりますので、ぜひ参加いただければと思います。
- フロントエンドエンジニア / フロントエンド開発センター(UIT)
- ソフトウェアエンジニア / DevOps / フロントエンド開発センター(UIT)
- フロントエンド開発センター(UIT) 参考情報一覧