
LINE就業型インターンでネットワークオペレーションチームに6週間お世話になりました鈴木大地と申します。普段は東京大学大学院情報理工学系研究科コンピュータ科学専攻というところで主に化学や物理のための科学計算を量子計算で高速化できないか研究しています。
大学院では量子力学や行列と戯れていますが今回のインターンではジャンルを大きく変えて以前より興味を持っていたネットワークオペレーションチームに配属され6週間インターンとして仕事をしました。ネットワークと言えども仕事は数多ありますが、今回のインターンではタイトルの通りLINEの大規模で複数データセンタにまたがるネットワークについて稼働状況を監視するシステムの構築をしました。具体的には以下の機能を備えています。
- 各データセンタから相互にpingを送信しあうことで、LINEのデータセンタネットワークの稼働状況を監視する
- 監視データを元に現在のネットワークの状況をわかりやすく可視化する
- 稼働状況に異常がみられた場合社内slackの然るべきチャンネルに通知する(執筆現在開発中)
この記事では上の監視システムが必要となった背景や実現にあたって使用した技術とアーキテクチャを解説した後、実際の監視ダッシュボードのデモをお見せします。また普段は学生で業務開発経験のない人間が6週間のインターンで学んだこと、印象に残ったことについても言及しておきます。
目次
- 背景
- 解決法
- アーキテクチャ
- 動作図
- 各技術の詳細
- 学んだこと
- 最後に
背景
LINEのサービスはご存知のチャット機能を初め、LINE Payといった決済・送金サービスやLINE MUSICといった音楽サービスなど数多存在します。そのサービス内容の大きさとインフラ的性質を鑑みてLINEでは各所にデータセンターを自前で管理し、大量のトラフィックを捌きつつサービスの冗長性を確保しています。この大規模なデータセンターを基盤として社内でVerdaと呼ばれる社内クラウドサービスを運用しており、RegionやAZを各地に確保しているため、例えば急にどこかのデータセンターで障害が発生したとしても他のデータセンターで運用を続けられる、といった様子になっているわけです。
このデータセンタだけでもおおよそ日常では関わらないような巨大なネットワークであることは想像に難くないと思いますが、これに加えてLINEでは日本・海外各所に存在するオフィスもあり、その上今後はYahoo! Japanとの合併に伴いさらに巨大なネットワークになることが見込まれます。このような大規模なネットワークになると各経路が正常に動作しているか監視する経路監視が重要となってきます。もちろん既に社内で経路監視のシステムが動いていたのですがこのシステムには以下のような問題点が以前より挙げられていました。
課題
- 一つのVMのみから監視しているためそのVMから通らない経路上で障害が起きても検知できない
- トップページの段階で監視対象の全ネットワーク機器の疎通状況が表示されるため概要を掴みづらい
- 監視の特性上非常に重要な役割を持つため、より高い可用性と保守性が求められる
- ネットワーク環境の変化に対して手動で運用することが必要になってしまっている
課題1というのは図にすると以下のような様子です。
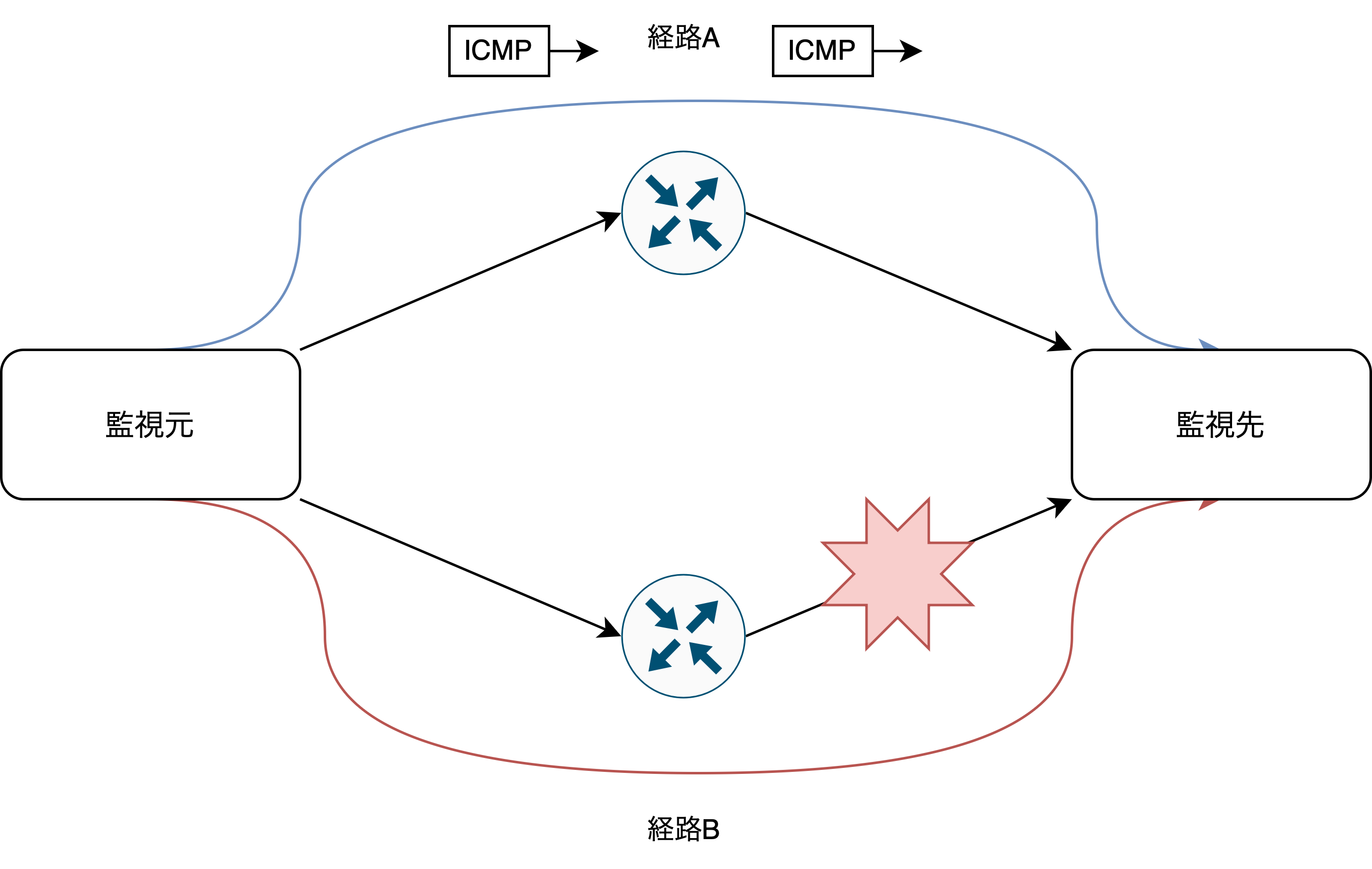
監視元から監視先への経路として経路A,Bと複数あり、経路Aが選択される場合に経路Bを監視できないため障害が起きた際に検知ができない可能性が出てくるという話です。
このように現状の監視システムにはいくらか問題が見られました。私がお世話になったチームではTorchと呼ばれるモニタリングツールがPrometheusによるデータ収集やGrafanaによるデータ可視化を用いてKubernetesのクラスタ上で動いています。このTorch上でネットワークを専門とする人にもしない人にも分かりやすい新たな監視システムを構築することが今回の私のインターンでの仕事となります。
解決法
それでは上に挙げた現在の課題を今回のシステムでどのように解決したのか概要をご紹介します。
1.複数の監視元の設置
現行のシステムでは監視元が1つのVMになってしまうため監視する際に通らない経路で障害が発生したとしても気付けない可能性がありました。よって今回の監視システムではLINEがVerdaで運用しているAZの全てにVMを設置しping監視をすることとします。すなわち監視元を複数設置することで多くの経路を監視できるようにしよう、という目論見です。もちろん社内ネットワークであり得る全経路を確認するということは到底不可能なのですがこれまでのシステムが1つのVMから監視していたのに対し今回のシステムでは10個以上のVMから監視するためより多くの経路を監視できるようになっています。
関連する技術: Prometheus, Blackbox exporter
2.構造化されたダッシュボード
現行のシステムではトップページの段階で全機器の疎通状況を表示するため特に一般ユーザからすると全体の概要が掴みにくくなっていました。そのため今回作成するシステムにおいてはネットワークを専門としない人にも現在の状況がパッと分かるようなものを目標とします。例えばダッシュボードのトップページで敢えて細かい情報を省き現在のネットワークの概要がシンプルに掴めるようにするようにします。
その一方でネットワークエンジニアがトラブルシュートする際にも使えるような監視システムとしてのユースケースもあります。そのためにはトップページからより詳細な部屋毎、機器毎にページに飛べるようにして現在のネットワーク機器の疎通状況一覧なども見られるようにする、RTTの時系列データを表示することで障害の発生時点を特定しやすくします。
関連する技術: Grafana
3.インフラ構成管理
これまでに説明した通り、経路監視のシステムはLINEの大規模ネットワーク環境の正常性を図るために非常に重要な位置付けを期待されています。この監視が停止するとネットワーク全体の稼働状況が把握できなくなるため、現実的な範囲で可用性と保守性をより高めることを目標としました。そのため現在動いているKubernetesクラスタのTorchに組み込み、後述するHelm chartによりPrometheusやHelmfileでの宣言的なデプロイを可能にします。これにより監視先を変更する際は設定ファイルを変更しhelmfile applyというコマンドを叩くだけでデプロイでき、非常にメンテナンス性が高くなります。またKubernetes上で冗長化しているため可用性も以前に比べ格段に高まりました。
また各AZに設置したVMにBlackbox exporterやそのdaemonを設置する作業は単純作業の繰り返しの割に工数を要するためAnsibleによる構成管理の自動化をすることでもメンテナンス性を確保しています。
関連する技術: Kubernetes, Helm, Helmfile, Ansible
4.監視対象の自動取得(部分的解決)
現行のシステムではネットワーク環境の変化、例えば機器の増減があった場合に監視先の設定ファイルを手動で変更することが必要となっていますが、このような増減はLINEの規模のネットワークにおいては頻繁に発生するため保守の手間を軽減をできると嬉しいです。これについてはネットワークデバイスを管理しているDBがすでに存在するため、それを叩き監視先を自動取得するシステムを構築することが理想となります。現在チームではこれに近いシステムが動いているためこれに似たようものを構築できればよかったのですが工数の観点から断念し、設定ファイルを生成するスクリプトを作ることで暫定的対処をすることになりました。
関連する技術: Pythonスクリプト
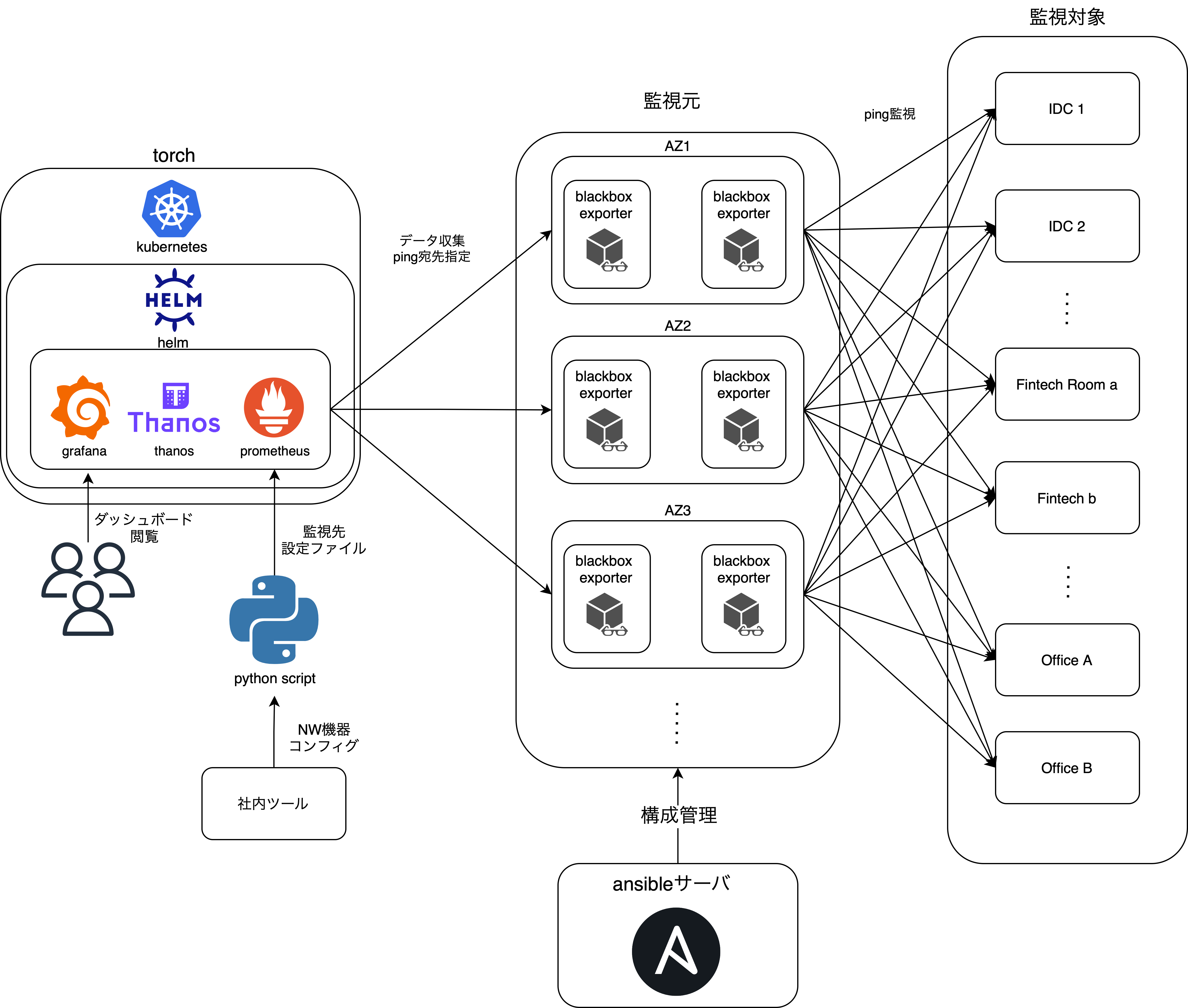
アーキテクチャ
以上4点の解決法をベースに今回構築したシステムのおおよそのアーキテクチャについては以下のような図になっています。各技術の詳細については動作のデモの後に説明します。
動作図
それではまず実際の動作図についてご覧ください。例えばあなたがネットワークの責任者で急にVerdaの一部のサービスのネットワークが変、という報告が上がってきた時やもしくはVerdaのユーザーでネットワークに何か異常が無いか疑っている場合を想定していただくと使い道が浮かぶのではないでしょうか。あまり考えたくはないですけどね?
トップページ
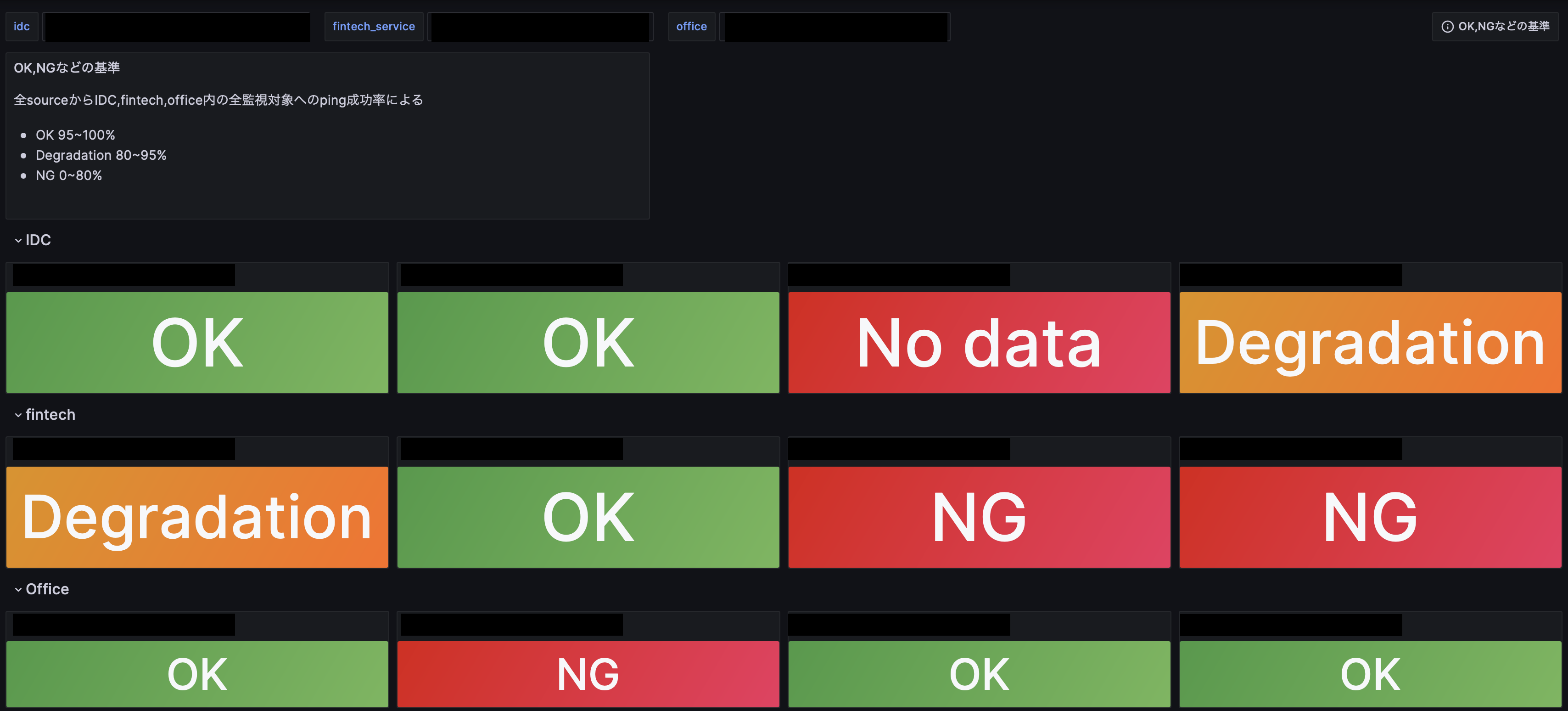
まずダッシュボードのトップページでは以下の図のようにIDCやfintech系のサービス、Officeなどといった広い単位で現在のネットワークの状況が一目に分かるようになっています。もし下記の画面でDegradationやNGが出ていた場合緊急の可能性が高いです。下記画面はデモなので大丈夫ですが...
なお以降でデモにおいてIDC名やその数については非公開のため黒塗りしてある上、数も実際のIDCと同じとは限らないものになっています。
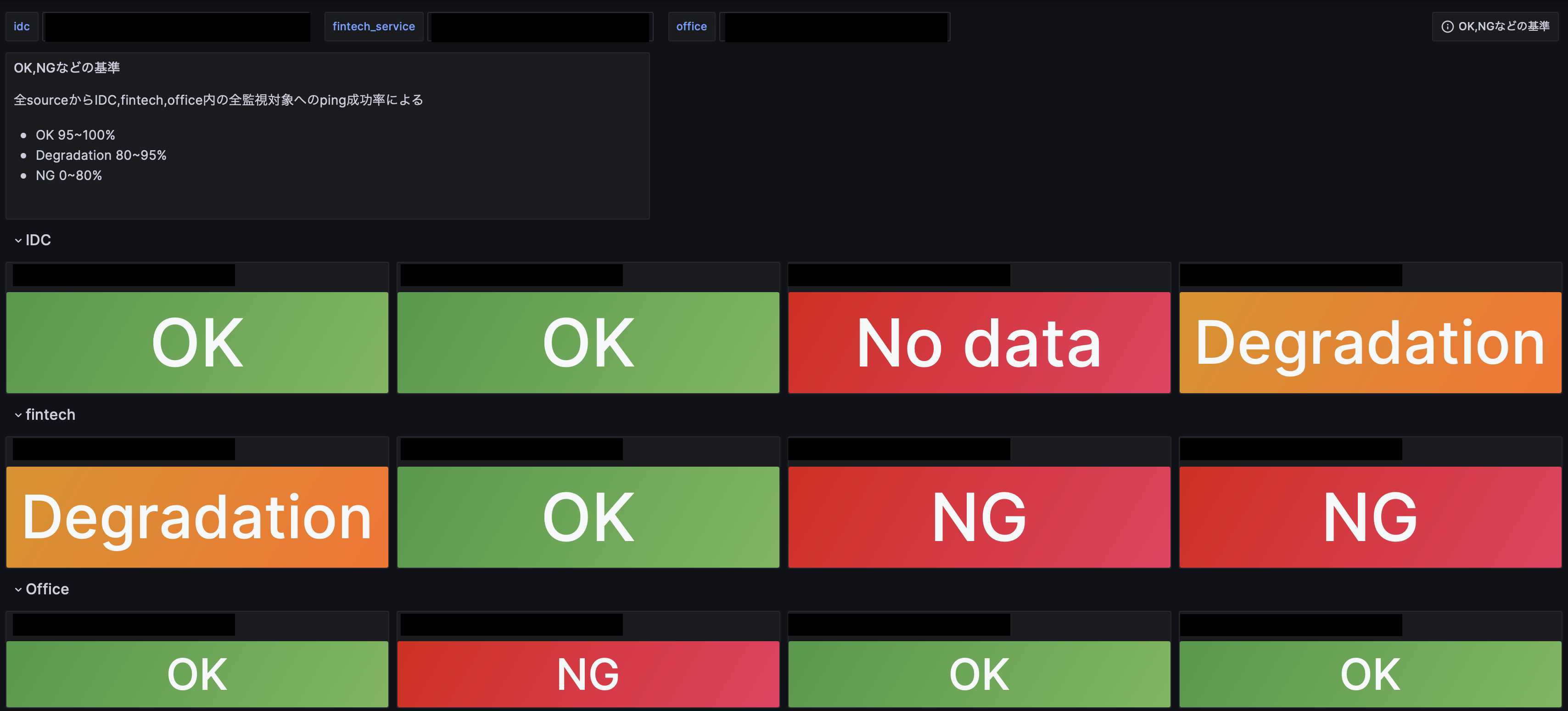
デフォルトでは全IDC、Fintech、オフィスサービスを一覧で見られるようになっている他、もし一部分だけ見たいのならば左上のidc,fintech_serviceという部分から欲しいサービスだけを指定してざっと見られるようなものになっています。
ネットワークに障害が発生した際まずこのページからどのIDCに障害が起きているのかを突き詰めるのに使うことができるでしょう。たとえば上の図だと一番右のIDCがDegradationとなっているように異常が発生している、少なくとも様子がおかしいということが分かる訳です。詳しく状況を確認するためには該当するパネルをクリックすることでIDC内の各部屋を監視しているページに飛ぶことができるので見て見ましょう。
ルーム毎のページ
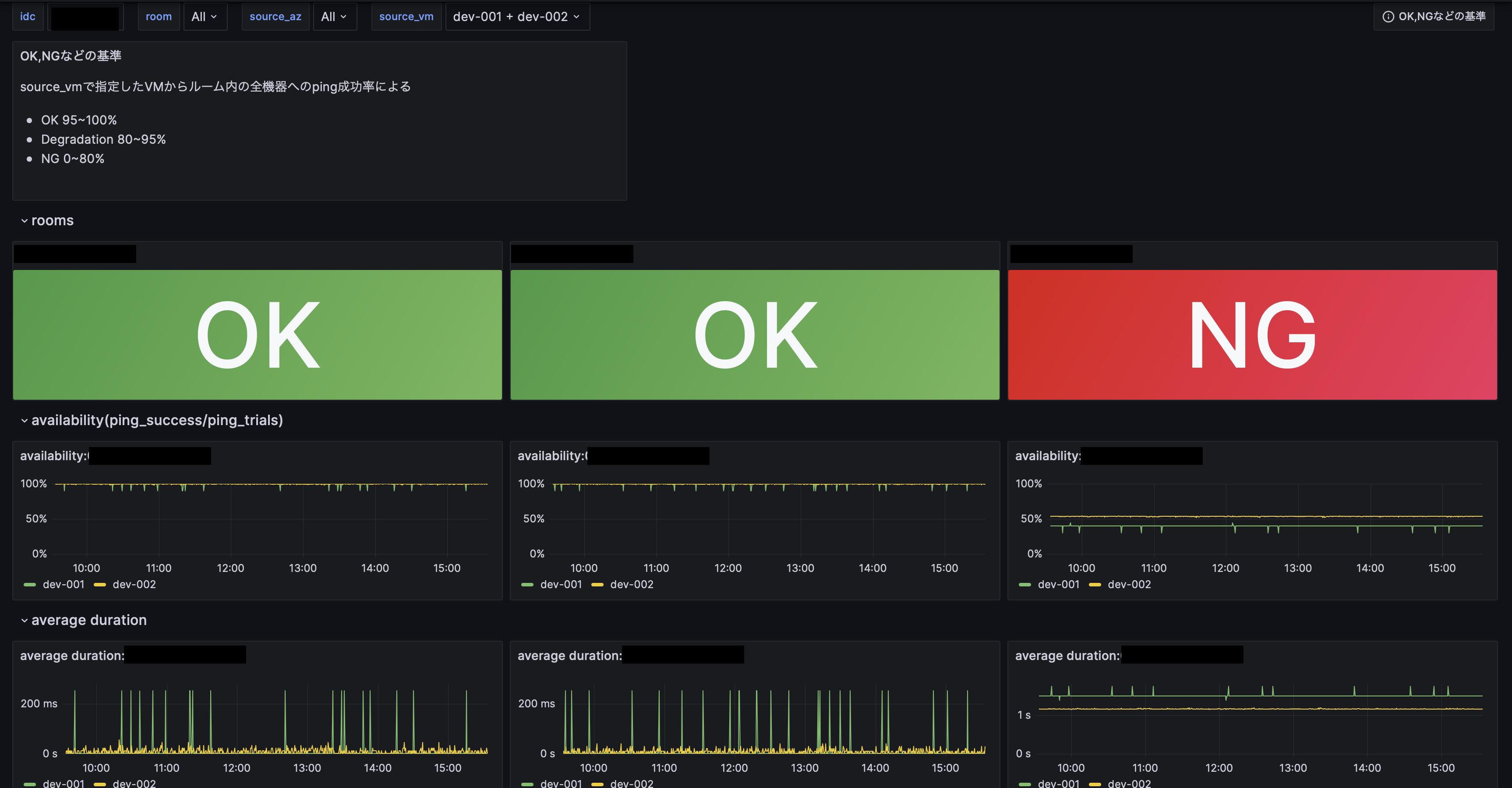
このダッシュボードでは選択したIDCの中にある各ルーム内の概要の表示やpingの成功率に関する推移に加え、平均のRTTなどを表示しています。また特定のAZないしVMからの通信だけがおかしくなるパターンを想定しpingを飛ばす元のAZやVMも指定できるようになっています。上記の写真は開発環境のため監視元は2個程度ですが本番環境においてはVerdaのAZ全てをカバーしており、10個以上のVMから経路監視したデータを見ることができます。
先ほどDegradationになっているIDCから飛んできてトラブルシューティングをしようとしている人はこれにより一番右のルームがおかしい、ということがこれまた一目でわかるかと思います。availabilityの図を見ると数時間単位でpingの成功率が50%前後で一定しておりおかしい様子が分かります。こうなると今度はこのルーム内の機器の状況を見よう、となるのが自然な流れでしょう。ここでもルームのNGのパネルの部分をクリックすると以下のようなルーム毎の機器の状態を見ることができるダッシュボードに遷移します。
ルーム内のページ
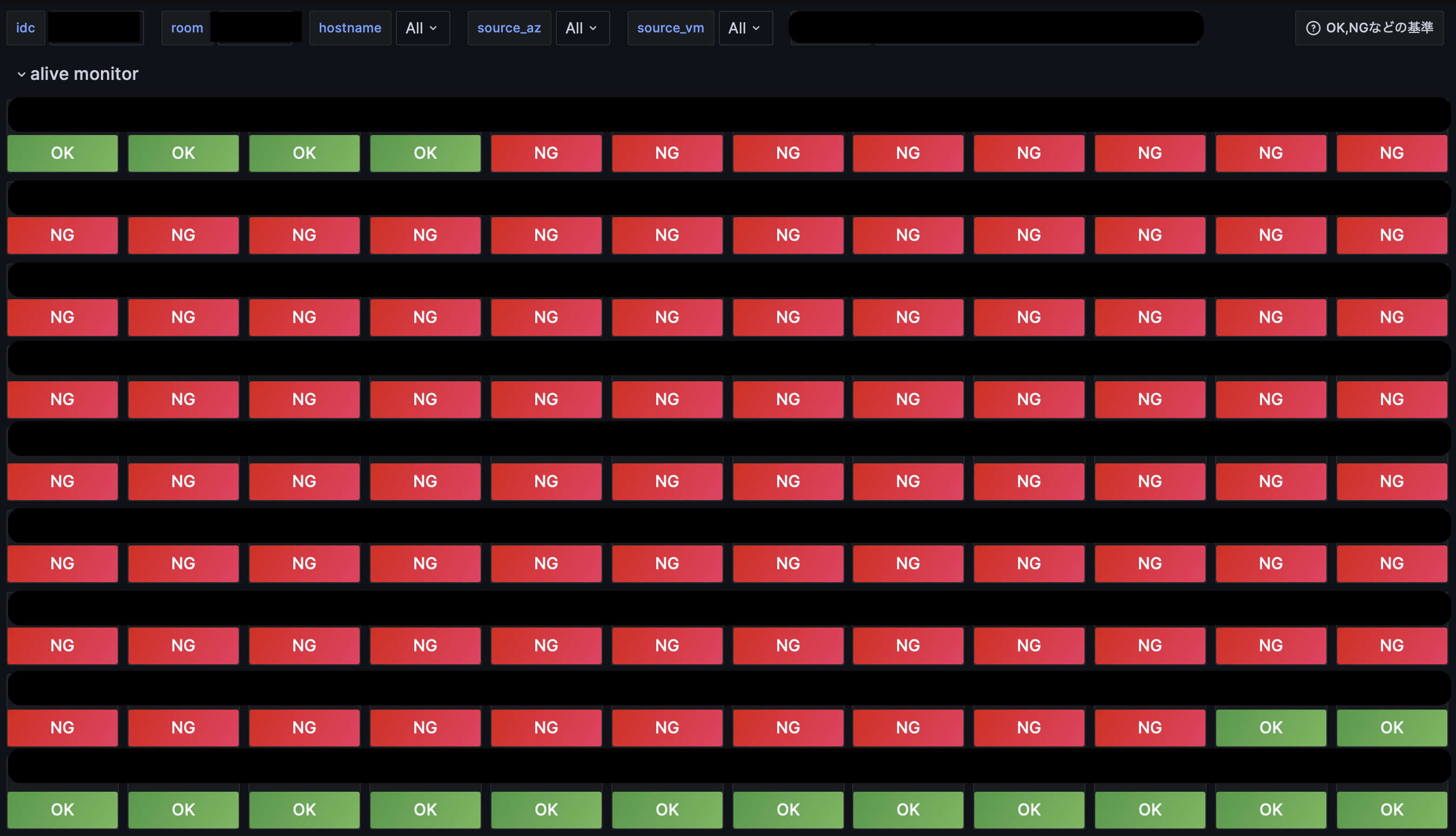
ルーム内のページまで来るといよいよ監視対象としているネットワーク機器全ての稼働状況が見られるようになりました。ネットワーク機器は1部屋に100台単位で置いてあることもありますが上のように表示することでルームの中でこの機器が落ちている、ということがこれまた一目でおわかりいただけると思います。ここまで来ればあとはこれらの落ちている機器についてログや設定ファイル、現在の疎通状況などを見ることで詳細なトラブルシュートができるのでは無いでしょうか、めでたしめでたし。
各技術の詳細
先に述べた解決法毎に使った技術の詳細を説明します。
1.複数の監視元の設置
Prometheus・Thanos
監視にあたってはPrometheusというOSSを用いています。これはOSSの監視ツールで監視対象のデータを一定時間毎に監視してデータベースに記録し、後からPromQLというクエリ言語を使うことでデータを効率的に取り出すことができるものになっています。またアラート機能も兼ね備えており、今回は後述するGrafanaのそれを使いましたが、例えばネットワークの致命的なダウンやトラフィックの圧迫をPromQLで検知してメールやSlackに通知を送る、ということができます。これらの集めたデータをDBに入れたりクエリを効率的に実行するためにThanosというOSSも併用していますが今回のインターンではThanosについて意識する機会はほとんどなかったため詳細は割愛させていただきます。
PrometheusについてはTorchで既に動いておりSNMP監視やKubernetesのリソース監視などをしていたためこの上に設定を追加する形となりました。具体的な設定の例としては以下のようになります。
Prometheus:
PrometheusSpec:
additionalScrapeConfigs:
- job_name: "pingmesh_AZ1_vm1"
metrics_path: /probe
params:
module:[icmp]
relabel_configs:
- source_labels:[__address__]
target_label: __param_target
- source_labels:[__param_target]
target_label: instance
- target_label: __address__
replacement: ip_of_AZ1_vm1:9115
scrape_interval: 5s
scrape_timeout: 3s
static_configs:
- labels:
hostname: "NWDevice1"
idc: "IDC1"
model: "MODELNAME"
ping_source: "AZ1-VM1"
role: "IDC"
room: "ROOMNAME"
targets:
- "IP of NWDevice1"
- labels:
....
この設定ファイルのtargetsを見てPrometheusはNWDevice1を監視するのだな、と判断し後述するBlackbox exporterに監視させます。pingが成功したか否かやRTTなどの監視結果を受けとった後Prometheusはlabels以降のラベルを付与してThanosを使いDBにデータを格納してクエリに備えます。
PromQLによるクエリ
PromQLでpingが成功したか否かといったデータを取り出すにはprobe_successといったメトリクスを指定します。他にもRTTを取得するためのprobe_duration_secondsといったメトリクスがあります。probe_successにラベルを指定することで特定のIDCやルームだけを指定することができるようになっており、例えば
probe_success{job="pingmesh_AZ1_VM1", role="idc", idc="IDC1", room="ROOM1"}
と指定するとIDC1内のROOM1にある機器についてAZ1_VM1というVMからpingを飛ばした時の結果が取得できるようになっています。クエリに対して集計関数のようなものも用意されているため例えばavgという平均を返す関数を使うことで
avg(probe_success{job="pingmesh_AZ1_VM1", role="idc", idc="IDC1", room="ROOM1"})
とIDC1内のROOM1という部屋へのAZ1_VM1からのpingの成功率が計算できます。このようにしてPromQLを使うことでDBから有益な情報を抽出しダッシュボードに欲しい情報を纏めていくわけです。
(間に合わなかった)監視先の自動化
監視先について理想を言えばPrometheusのservice discoveryという自動的にAPIから取得する機能を使い、LINE社内のネットワーク機器を管理しているデータベースから動的に現在のネットワーク機器を取得することで自動でネットワーク機器の変化に追従できると良かったのですがこれについては断念しました。理由としては
- 自動追従のために変更が必要となる社内ツールが1つでは済まないことからコーディング・コードレビュー・テストなどを合わせるととても間に合わない
- 自動追従より先にアラートや経路の監視などやるべきことがある
- 手動とはいえスクリプトにより監視対象を手動で楽に取得できるためネットワーク機器の変更があっても設定の変更に手間取りはしないこと
といった事情によります。後2、3週間あれば是非やりたかったですが...
Blackbox exporter
先ほどPrometheusで監視すると大雑把に述べましたが具体的にデータを収集するのにはexporterと呼ばれる別ソフトウェアが担当することになります。このexporterは監視対象、手法により様々な種類のものを様々な場所に置いておくことができ、Prometheusの役割はこれらのexporterのデータを集計することにあります。
今回はpingによる疎通監視が主な手段となるためBlackbox exporterというPrometheus公式に管理されているexporterを採用しました。名前の通り監視対象の内部には触れず(=Blackbox)外部からアクセスした際の挙動を監視するもので、ICMPによる疎通確認やRTTの測定を用いました。また監視においては使用していませんが他にもTCPによるコネクション確立のテストやHTTPでアクセスした際のステータスコードの確認などの機能を兼ね備えています。
今回のシステムではこのBlackbox exporterをVerda全AZ上の2台のVMに設置しネットワーク機器への監視を行いました。上のアーキテクチャ図において監視元という枠の中のそれぞれのAZに入っているものになります。これらのexporterたちがPrometheusの指定した宛先にpingを飛ばし、その結果をPrometheusが集計する、という流れになります。
2.構造化されたダッシュボード
Grafana
GrafanaはOSSのデータ図示ツールであり、リアルタイム/時系列データの図示をするための様々なパネルによる図示化はもちろん、データ毎に設定したアラート条件からSlackやメールに通知を送ることも可能です。特にPrometheusのデータを表示する際のデファクトスタンダードのようなポジションを占めておりPromQLでの結果からデータを可視化しやすいような作りになっています。例えばルーム単位でのping成功率が図示したい場合PromQLのクエリを書くだけでシンプルに以下のような図を出力することができます。
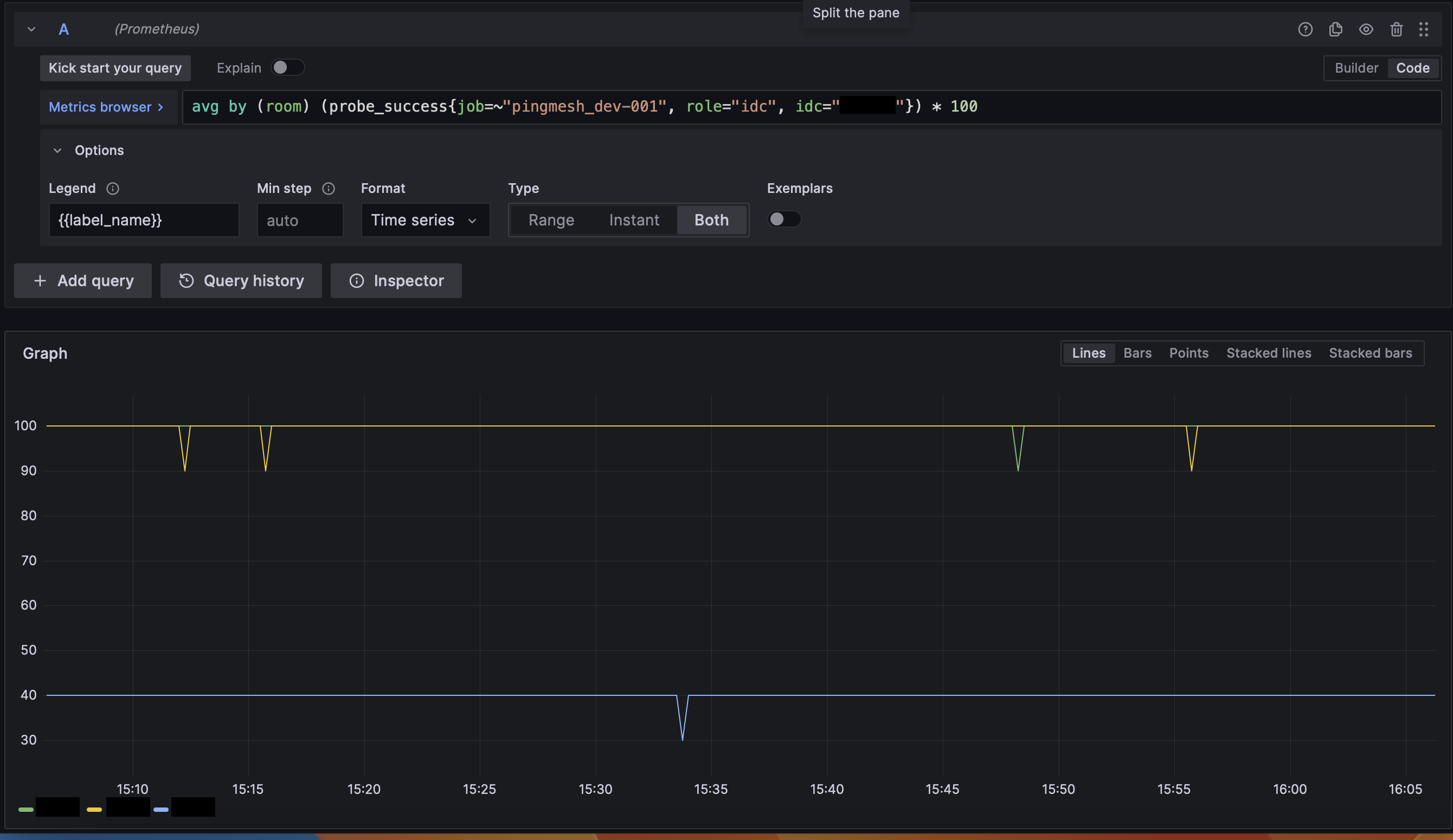
上はシンプルな時系列データでしたがこれ以外にも様々なパネルが用意されており表現に困ることはあまり無いでしょう。
さて今回のシステムにおいてはわかりやすく見せる、ということが大目標としてありました。上のような分かりやすいパネルの表示以外にも機能的な面でこの目標を達成するのにGrafanaは十分な機能を兼ね備えています。例えばGrafanaにはダッシュボードから別のダッシュボードへ遷移する機能があるため、まず最初に概要的なページで現在の状況をざっと把握し、危ういデータセンターがあった場合にそのデータセンターの詳細に関するページに遷移する、といった遷移を実装することができます。これについては動作例のところをご覧ください。
変数によるクエリの指定
また、ダッシュボード上に表示する情報を変数というものを用いて指定することもできます。この変数はPromQLで使えるため例えばダッシュボード上に載せる監視対象のIDCを指定したり、もしくは監視元のBlackbox exporterを指定することで今現在危うい経路だけを取り出す、といった使い方ができるようになり大変便利です。変数としてはラベルの値やクエリの結果から正規表現で抽出したものなどを使うことができ、例えば変数source_vmとして
label_value(ping_source)
というものを指定するとラベルping_sourceに使われている値が変数として指定できるようになります。
PromQLでは$source_vmと指定することでこの変数の値を使うことができるため
avg(probe_success{job="pingmesh_AZ1_vm1", role="idc", idc="IDC1",room="ROOM1" ping_source=~"$source_vm"})
と書くことで変数の値で指定したVMからIDC1内ROOM1へのping成功率を取得することができるのです。
パネルの繰り返し
Grafanaには変数に渡ったパネルの複製機能があり、何かと面倒かつワンパターンになりがちなパネルの作成を単純化することができます。例えば監視元のVM毎それぞれからのある部屋へのRTTの平均、というようなダッシュボードが作りたくなった時にVM1つ1つパネルを作るのではやってられません。そこで
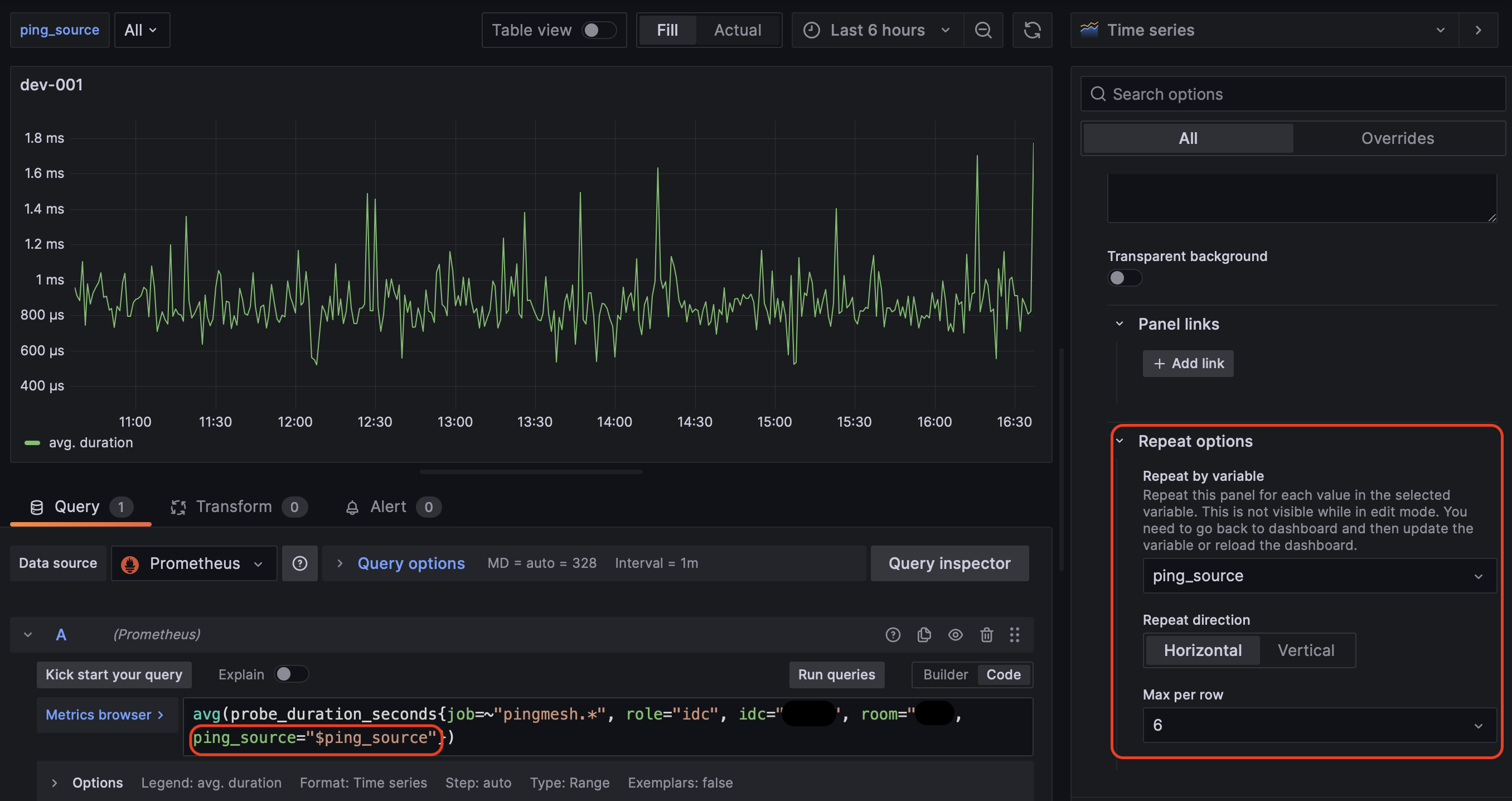
上の図の右側の赤枠内Repeat optionsに変数ping_sourceを指定し、PromQLでも左側赤枠のように変数ping_sourceを使用します。こうすると後は変数としてAllなど指定するだけで
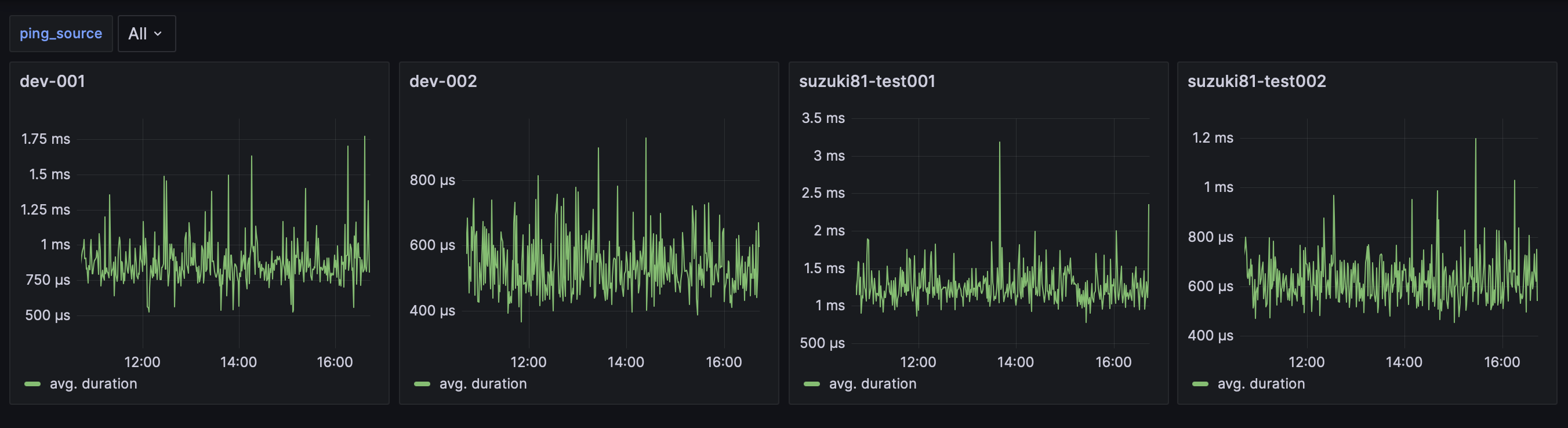
このようにパネルを自動的に作ってくれるのです。開発環境だと監視元を現在4つ用意しているのですが、それらを逐一指定しなくても無事全て表示されました。
この機能により構造的なダッシュボードの作成が作れる上にメンテナンス性も向上しました。
アラート機能
ダッシュボードには関係ありませんがGrafanaの機能の一環としてここで紹介します。Prometheusにアラート機能があるのと同じようにGrafanaもアラート機能を兼ね備えており、例えばどこかのオフィスへの通信が断絶した場合slackに通知を投げたい、という要件に答えることができます。
まずアラート条件をこれまで同様PromQLで書きます。

avg by (place) (...) == bool 0というクエリによりオフィス毎に現在通信が断絶しているかしていないかの判定を行うことができます。試しに現在使われていないオフィスをあえて監視対象に入れると以下のようにアラートが発火します。

place=""の部分には現在通信が断絶しているオフィス名が入ります。これらの情報を使ってslackのbotを使い通知を送ることができます

またこれらの通知を送るチャンネルや文面についてはアラートについているラベルによって変えられるため例えばseverityが深刻なものについては@channelでメンションをしたり、オフィスのダウンの場合はオフィスのネットワーク責任者がいるチャンネルに通知を送る、といったことができます。
3.インフラ構成管理
Ansible
Blackbox exporterはシンプルに動くバイナリではありますがそれでも
- 公式サイトからダウンロード、解凍
- 設定ファイルを置いて実行
という作業を全AZの2台のVM毎に毎回行うと2桁単位で同じ作業を繰り返すことになってしまい面倒極まれり、といったところでしょう。今後合併に伴ってAZが増えるとまた同じような作業を繰り返したり、VMに問題があって再起動などしたりすることを考えるとここは自動化しておきたい部分です。
また、せっかくネットワークを監視しようとしているのにBlackbox exporter自体が落ちてしまっては元も子もありません。そのためにはBlackbox exporterのdaemon化も必要となることでしょう。つまり何らかの事情でexporterが落ちたとしてもsystemd上などでdaemon化させておくことで再起動するようにする、という仕組みが必要です。この作業も新規のVMで行うならば今回はsupervisordを使ったため
- supervisordのインストール
- supervisordのための設定ファイルの設置
- supervisordでexporterの起動
という作業が入ることになります。この上記の作業を手作業で行いたいでしょうか。無論答えはNoです。
と上のように面倒な作業の繰り返しが多くなってしまうためexporterの起動、daemon化については自動化するのがメンテナンス性の観点から望ましいでしょう。元からチーム内で一部のサーバの構成管理のために使っていたansibleサーバがあったため、それを使って構成管理をすることになりました。Blackbox exporterとsupervisordをインストール、実行するansibleのplaybookを作り、ansibleサーバでコマンドを叩くだけ、という状態まで持って行ったことになります。コードのサンプルをお見せすると
- name: download Blackbox_exporter
unarchive:
src: https://url/to/Blackbox_exporter
dest: /dst
remote_src: true
mode: 0644
owner: root
group: root
- name: copy binary
copy:
src: /src/to/Blackbox_exporter
dest: /dst/to/Blackbox_exporter
mode: 0744
remote_src: true
owner: root
group: root
といった様子です。上のコードはBlackbox_exporterを公式からダウンロードして解凍し特定のフォルダに置く、というシンプルなものですがこれを重ねていくと信じられないほどの労力削減となります。
これにより目的通りVM上でBlackbox exporterがdaemonとして動作するようになり、VMの新規追加の際にもansibleサーバのssh公開鍵をVMに追加してansibleのコマンドを叩くだけという2ステップでインストールできるようになりました。これにより運用の工数について大幅に削減できているはずです。
Kubernetes,Helm,Helmfile
これまで述べてきたツールが載っているインフラ環境について言及しておきます。
今回使用しているPrometheusやGrafanaは基本的にシングルバイナリやシンプルなDockerイメージ1発で動く分かりやすいものとなっています。実際現行のシステムもDocker composeでPrometheus,Grafana,Blackbox exporterを繋げる構成をとっていました。しかしこれが独立した1つのVMでDocker Composeによりこれらのツールをつなげるというシンプルな構成で動いているためこのVMが落ちた瞬間に監視が止まるという可用性の問題や、保守運用の観点からの問題が出てきてしまいます。
Torchではこれらのツールの管理をKubernetes上のクラスタにHelmとHelmfileを用いて管理しています。HelmはKubernetesのパッケージマネージャーのような物でchartと呼ばれる単位でマニフェストを管理し、管理を楽にしてくれるツールです。今回だとPrometheusを動かすのに必要な各種設定をまとめたkube-Prometheus-stackというchartが既に動いておりそれに監視先の設定だけを追加していく形で実装しました。
HelmfileはHelmをラップすることで、より宣言的にHelm chartをデプロイできるツールです。Torchでは監視のために使っている各種Helm chartをHelmfileによって管理しており、設定ファイルを宣言的に記述したらあとはHelmfileのコマンドを叩くだけで簡単にデプロイできる仕様となっています。
KubernetesでPrometheus・Thanos・Grafanaを冗長化することによる可用性は向上し、Helm・Helmfileでパッケージ化されたマニフェストを宣言的にデプロイできるようになることでメンテナンス性も大幅に向上しました。
4.監視対象の自動取得(部分的解決)
Blackbox exporterの設定ファイルをいちいち手書きするのはネットワーク機器が数千台にわたることを考えるととても現実的ではありません。またPrometheusのPromQLを有効に使うためにはラベルを設定する必要があり、これらのために設定ファイルをうまいこと生成するシステムが必要となります。実際はスクリプトを作るに留まってしまっため監視対象を更新する際はKubernetesマニフェストにコピーする手作業は必要となりましたが以前よりは大幅に軽減されました
監視する機器のIPを取得する部分は社内ツールとしてネットワーク機器のコンフィグを取得できるものがありこれを使いました。監視対象のコンフィグのうち、loopbackアドレスを設定している部分を正規表現で抜き出すことで監視対象機器のIPアドレスを取得します。このIPアドレスと共にPrometheusで使いたいIDC名やルーム名などタグをつけたYAMLの設定ファイルを生成し、Prometheusが読める設定ファイルに直します。Prometheusで監視先を設定する部分は
-labels:
hostname: "HOSTNAME"
idc: "IDC"
model: "MODELNAME"
ping_source: "PING_SOURCE"
role: "idc"
room: "ROOM"
targets:
- "IPADDR"
というようなlabelに各種ラベル、targetsに監視先のIPアドレスを設定したYAMLの辞書型で設定します。
よってPythonコードとして上のhostnameやidcなどを抽出した後、
target['labels'] = {'hostname': f'{hostname}' , 'idc': f'{idc}', 'model': f'{model}' , 'ping_source':f'{ping_source}', role:'idc', 'room':f'{room}', }
target['targets'] = [f'{ipv4addr}']
といったpythonの辞書型からYAMLにダンプします。
学んだこと
6週間という短い期間、かつ書いたコード量自体は少ないのですがリモートワーク環境下での実務開発の流れ、情報共有について大きな学びがありました。以下個人的に印象深く残ったといいますか、学べて良かったことをまとめておきます。
ネットワークの理解
ネットワーク監視に関わったことでLINEのような大規模ネットワークの構造、特にデータセンタのサーバファームで頻出するCLOSやデータセンタ間の接続に関する構成パターンについて把握できたのは良い学びになりました。正直なところインターンを始めたての頃はネットワークのトポロジー図を見てもそれぞれの機器の役割が分からずじまいだったのですが、監視システムを構築する過程でよく出てくる機械に慣れたり、社員さんにLINEのネットワーク講座を開いていただいたりした結果インターン終盤には機器名を見て大体何をしているか分かるにはなってきた、と思います。何もわかっていなかった序盤は監視先について社員さんに教えていただく形になりましたが終盤にはある程度自分でここを監視すれば良いんじゃなかろうか、と提案できるようになったのが感慨深かったですね。
Confluence
LINEでは主な情報共有ツールとしてConfluenceを使用しています。原則としてはこのConfluenceに日常業務で必要となるような情報がまとまっており例えば新しいツールの開発に加わることになった場合や、既存のツールでわからないことがある時など最初に概略的な情報源として使うわけです。当たり前ですがツールに関する情報が属人化すればするほどコミュニケーションコストは高まり新たに人が関わる際余計な時間を使いますし、ツールを作った方が退職などされると余計混乱を生み出します。もちろん初めて使うツールでもコードを読めば分かる、というのが理想ではありますが現実問題としてコードリーディングにも時間がかかること、コードの動作はわかっても意図がわからない時などあるためこのようなConfluenceは重宝します。
私が今回作成したツールについてはある程度メンターの方と相談しながら決めたため最悪私がいなくなった後もメンターの方が情報についてはある程度把握していますが、それでも後から見たら意思決定の理由がわからなくなるであろう部分、監視対象を作成するスクリプトなどわかりにくい部分が存在します。今後社員の方々に引き継ぐにあたりできるだけ情報共有をしておくのは重要なのだなぁと思い、この6週間の中ではシステム構築と同時にConfluenceやJIRAへの情報共有を大事にすることを心がける癖がついたのは良い学びだなと思います。
JIRA
チケットの管轄
開発においてはタスクの管理ツールとしてJIRAを使用しています。実務開発が初めての私としてはもちろん初めて使ったツールになるのですがこれに慣れるのに少し時間がかかりました。
1チケットが1つのタスクを表すためゴールやチケットの管轄範囲が明確でなければなりません。チケットをclose(完了)させるためにはコーディングのタスクの場合GitHub上でpull requestが無事マージされた時、調査に関するタスクだったらWikiなりJIRAなりに情報をまとめ終わった時、となるわけですがこれらのゴールを明確でないと1チケットの役割が曖昧になってしまったりコーディングで触る範囲が曖昧になって後から見返したときにわかりにくくなってしまいます。
当初チケットの範囲をどのように定めるか、ゴールをどう設定するか、という観点が抜けており適当にチケットを作った結果pull requestを投げた後のレビューでゴールに至っていないのではないか、ないしゴールの基準がわかりにくいなどのご指摘を頂きました。それ以降JIRAの使い方を徐々に理解しチケットの管轄を明確にするためにゴールを明記するようになって指摘をいただく回数はかなり減った、と思います。
情報共有の側面
また先ほどWikiが主な情報共有ツールとしましたがJIRAも同様に情報共有ツールとしての側面があり、Wikiとは違った役割を担っています。
Wikiは先ほど述べた通り概要からコードベースまでは踏み込まない詳細程度の情報を主に載せています。これはWikiが何かを調べるときにまず最初に見るツールであることを踏まえると、あまり詳細について書きすぎると逆に情報過多により見づらいため適度に概論を載せておくのが望ましいという判断によります。
それに対してJIRAはWikiよりも詳細な情報を載せておくツールとしての側面が大きくなります。Wikiで概要は掴んだもののコードの詳細や理由についてイマイチわからないことがある、コードベースを読んでいても今の実装になった理由がわからない、といったときに後から見返すツールとしてJIRAが使われるのです。というのもチケットが管理するのは日常の比較的細かく具体的なタスクであるため、後から見返すときにコードが今の形になっている理由や、そもそもなぜそのようなことを実装しようと思ったのかについてのslackの会話といった情報をまとめるのにちょうど良いためです。これらの情報をWikiに逐一まとめていては情報過多となりますが、後からリファレンス的に参照できるということがどれだけありがたいかというのは実際自分でチケットに情報を書き連ねるようになってから実感しました。
コードレビュー
業務で開発をするのならばおおよそ通常ある文化ではあるかとは思うのですが、これまで大学で生きてきた人間としてはあまりコードの品質、自分の書いたコードに対するコメントをいただく機会などほとんどなかった為印象深く残りました。業務でコードを書いている方には当たり前といえば当たり前かもしれないのですが単純に人が書いたコードを動作確認するだけではなく、コードの書き方、将来的な拡張性、シンプルさ分かりやすさなどを確認し、時にはレビュアーが具体的な例をあげて改善を促すなど自分が直接レビューに回ることはないものの学びが多かったです。
また時には社員の方がコードレビューをきっかけとしてそもそもチーム内のコーディングスタイルに関する議論を促してより良いチームのコーディングスタイルに関する議論が朝会で行われているのも印象深く残りました。ある程度チーム内でのコーディングスタイル・アーキテクチャに関する一般論は決まっていたと思うのですがそもそもそのスタイルが本当に良いのか、という問題提起から朝会の中で議論していたらしく是非とも参加、せめて聞きたかったです。残念ながら体調を崩しお休みした日となってしまいましたが...
最後に
まずは6週間お世話になったネットワークオペレーションチーム開発パートの皆様、特にメンターの方に心から感謝申し上げます。特にインターンを始めたての頃は内部ツールや今回作成するシステムが動いているKubernetesの構成が全くわからず頓珍漢な質問をしている私にzoomをすぐ開いてくださったりその後も質問に対して大変素早くお答えいただいたり、またチームの方とのランチ会を開いてくださったりと大変お世話になりました。
またメンターの方に限らずチーム内の方々も私が困った際slackに投げたらすぐにトラブルシュートに動いてくださったり質問に答えてくださるなど大変温かく、フルリモート環境ながらどうにか仕事を回すことができました。上長の方は始めたての頃に1on1で緩くお話ししてくださったり各種サーバの権限の申請など素早く許可してくださり実務的に大変助かりました。また社員さんに開いていただいたLINE社内のネットワーク講座は業務中出てきた機器の役割を把握するのに大変役立ちましたし、プルリクに対して他の社員さんから頂いたコメントやWiki、JIRAの書き方など大変学びになりました。この記事の草稿にも怒涛のコメントを頂き大変助かっております。師匠と呼ばせていただきます。また開発にあたってダッシュボードに関する意見をくださったサービスネットワークチームの方や運用上のアラート周りについてご相談させてくださった運用パートの方、しばしば勤務時間について我儘を通させていただいたHRの方々にも改めてお礼申し上げます。定期開催しているゲーム会に混ぜていただいたのも良い思い出となりました。
改めて6週間を振り返ると(これを書いているのはまだ5週目ですが)技術面で言えばKubernetesのチュートリアルから始まりHelmfile,Ansible,Prometheus,Grafanaなどなど様々な技術に触れることができて大変満足です。そして技術以外にもチーム開発のための情報共有技術や後のメンテナンス性を考えた設計手法、インフラ構成管理といったものを経験をできたのは大きな財産となりました。改めてインターンで関わってくださった皆様ありがとうございました。