
こんにちは、開発5センターの Zhu です。
現在は LINE NEWS の SRE チームに所属しています。
この記事は、2023年3月末にサービス提供を終了したライブ配信サービス「LINE LIVE」において、今まで行ってきた施策の紹介や大規模サービスならではのクロージングに関わる話を連載するシリーズの2本目の記事です。
今回の記事では、データベース上で Replication Delay によって起きていた問題と解決までの経緯やDB構成について、図を交えて紹介します。
背景
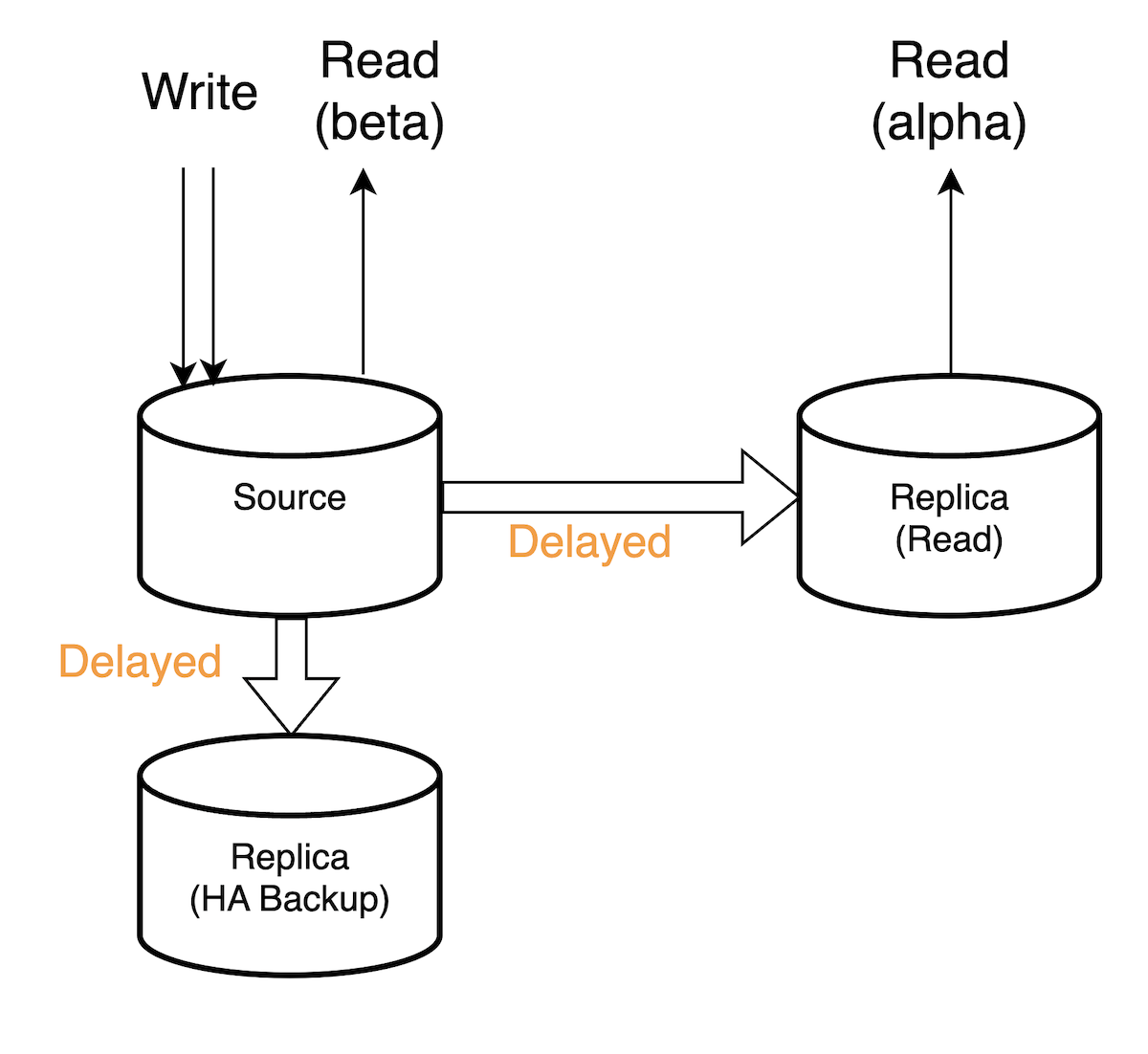
LINE LIVE では、大規模のアクセスに耐えるために DB(MySQL) へのアクセスは Read/Write で分離しています。つまり書き込みは MySQL のクラスター Source へ、読み込みは Replica から行う実装でした。よく使われている手法ですが、イメージの概要は下図の通りです。
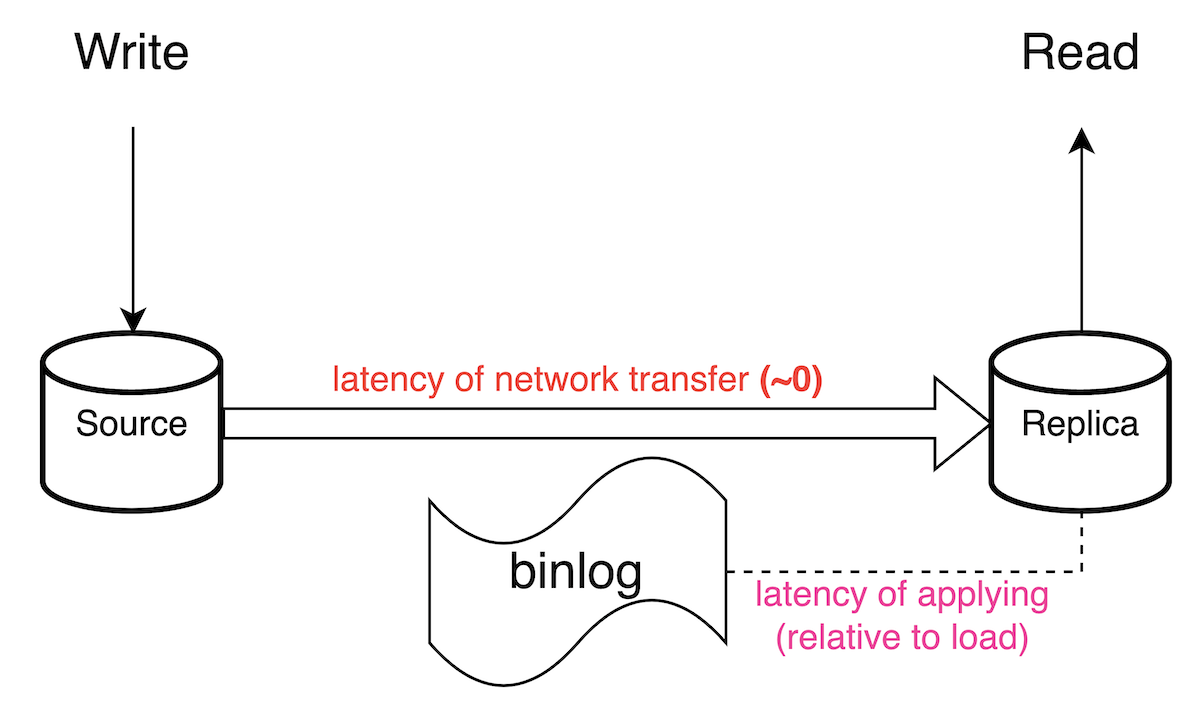
DB に書き込み処理をしてコミットした際の大まかなフローは下記です。
- バイナリログ (binlog) に書き出されます。次に、バイナリログダンプスレッドがバイナリログの内容を読み取ってレプリカに送信する
- レプリカのレプリケーションI/Oスレッドは受け取ったバイナリログの内容をリレーログに書き出す
- レプリケーションSQLスレッドはリレーログから内容を読み取り、更新をレプリカに適用する
その際、アクセスがスパイクするなどの状況により DB 更新が頻発する場合、binlog(正確にはrelay log)のレプリケーション SQL スレッドの適用が重くなり、Replication Delay が顕著になります。
ちなみに、LINE LIVE では Semi Sync で運用していましたが、それはあくまで binlog が Replica まで確実に届くまでの待機を保証するまでで、Replica の実際の適用までは待機しないのでレプリケーション遅延の発生に変わりはありません。
そして、LINE LIVE などの高トラフィックなサービスの特徴として、発行する SELECT クエリが多いため Replica 数(10)も多い状態でした。特に大型配信時は各 Replica で 20000QPS は出ていました。そのため Replica の利用は重要でありながらも遅延の影響で不具合が発生するのは課題でした。
レプリケーション遅延による現実問題
実際に問題があったのは大きく分けて下記2点です。
- 読み込みむデータが直前に書き込まれた場合、遅延によって当たり外れが発生すること
- 開発/検証環境は最小構成のため Replication Delay が発生しない状態だったので、このような動作をする箇所が実際UXを悪化させることにリリースまで気付き難いこと
まず1点目については、この遅延による影響がないか、ユーザーが気付かない場合がほとんどですが、タイミングがシビアになるほどUXに影響するので、可能な限り解消したいと考えていました。
LINE LIVEの特性として、この問題が発生する箇所はコンポーネントAがDBへの書き込み→別のコンポーネントBが同じデータを読み込むという並行だけど「更新」からの「読み込み」の順序を守っているところなどがありました。修正方法は、特にアクセスがスパイクしないところなら読み込みを Source に変更するだけで済みます。
ちなみに、アクセスがスパイクするところはキャッシュを使っており、DB を更新したらすぐにキャッシュも更新する構造のため同じような問題は結果的に発生しませんでした。
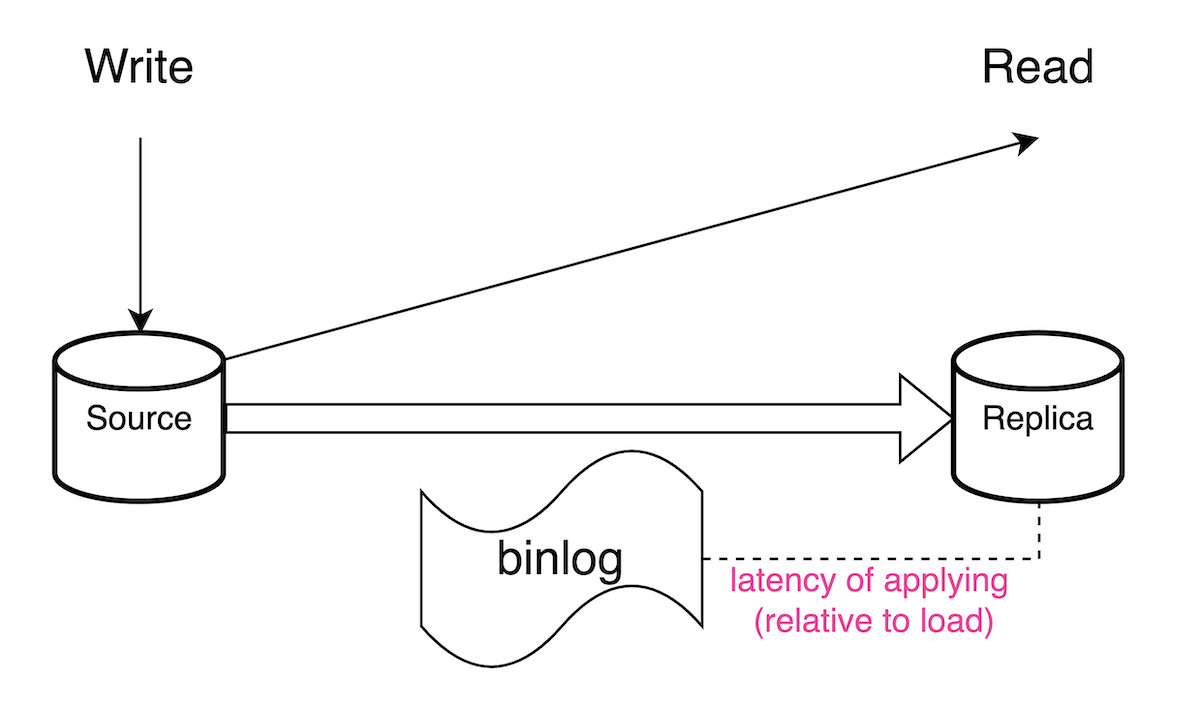
1点目の対処が容易な一方で、2点目は悩ましい問題でした。上記の通り開発環境で Replication Delay が発生しないので、リリースされてから初めて発覚することが結構ありました。「やはりリリースを待たずにこういう箇所を検知したい」と思いながら、意図的に Replication Delay を発生させることを DBA と相談しました。
MASTER_DELAY
その相談の結果、MySQL には MASTER_DELAY という設定があることが分かりました。
MASTER_DELAY に秒数を設定したら、Source からわざと Replica への Replication を指定された秒数で遅らせることができます。これはまさに欲しい機能でしたので、すぐに LINE LIVE の開発/検証環境に入れる計画と実施をしました。
実際の運用について
LINE LIVE の開発環境の DB は元々 read/write 分離していないHA対応最小構成でした。
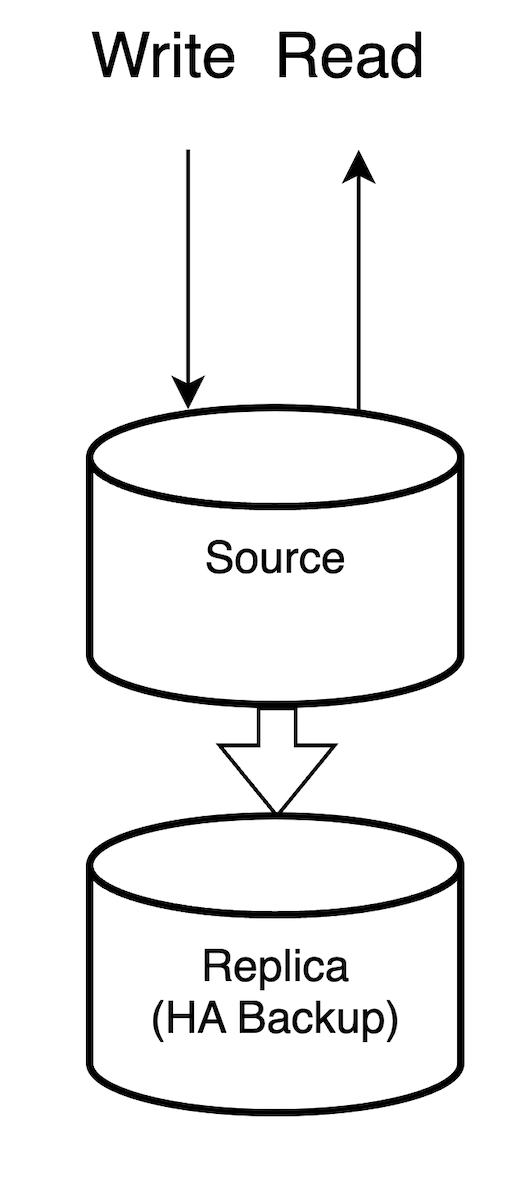
そのため、まず read 用 replica を用意し、MASTER_DELAY を設定し、それからアプリケーションサーバの開発環境の read 用設定も source から replica に設定しました。
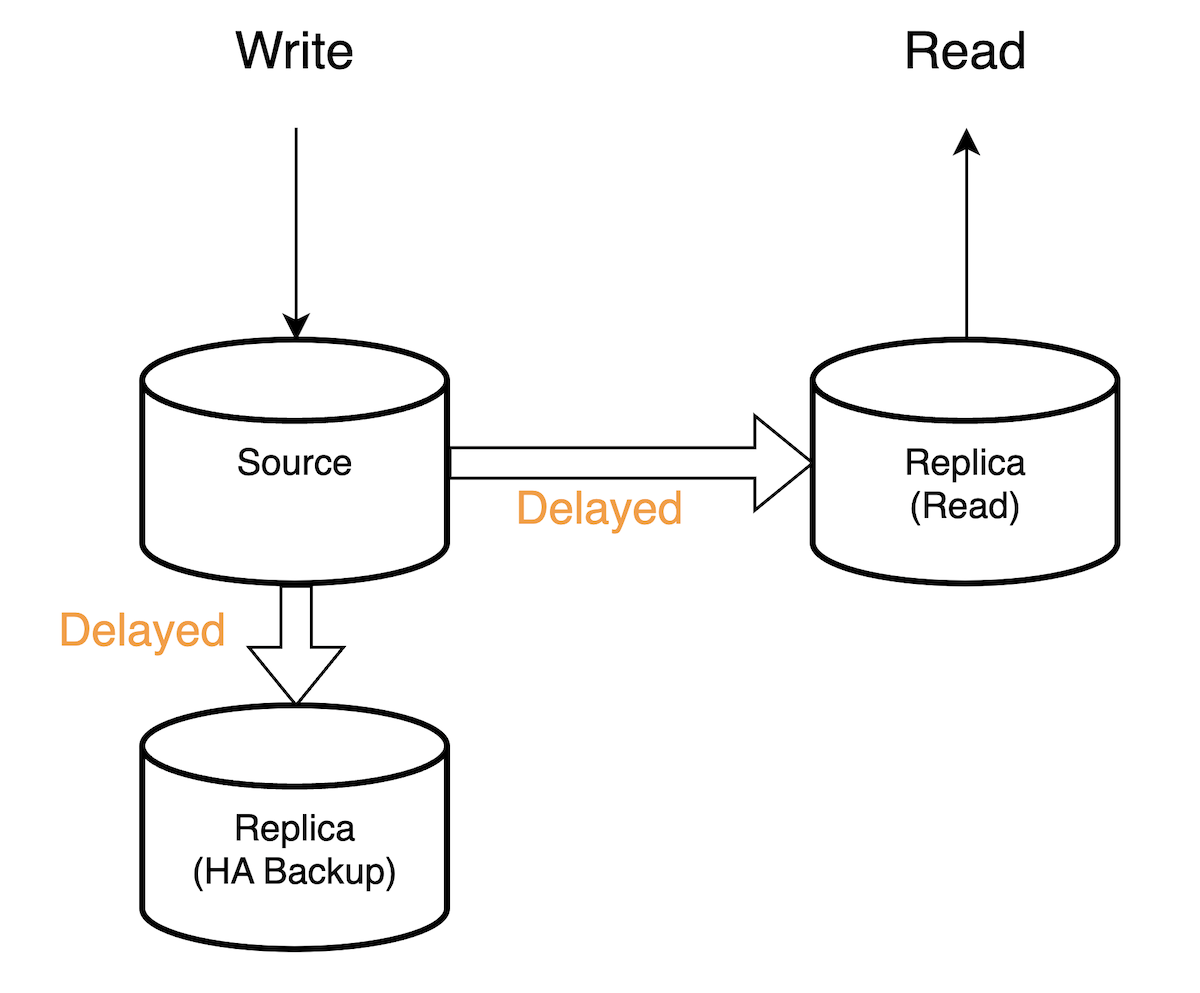
そうしたら、ある程度は予想してましたが既存部分の処理が起因と思われる不具合が出てきました。これにより、開発/検証環境で発生してる不具合が新規開発によるものか、既存実装によるものかは見分けづらくなってしまいました。そのため、しばらくは開発環境のみ適用しつつ必要に応じて一時的に read を source に戻す運用に落ち着きました。
具体的な成果として、有料配信の購入直後に自動で視聴に行くところで一時的にエラーポップアップが出るなどの小さい不具合をいくつか発見しました。修正方法は前述の通り該当箇所の読み込みを Source に向けました。Source へのロードが増えることになりますが、許容できる範囲で安定の動作を実現できました。
他に、新規開発機能にも replication delay による影響が確認しやすくなり、同じような対処をしました。
おまけ:落とし穴について
MASTER_DELAY は便利な設定ですが、LINE のプライベートクラウド Verda の HA の仕様上、DBクラスターで failover が発生して Source が切り替わってもこの設定は引き継がれません。なので、 もし failover が発生したら設定のやり直しが必要です。
それを監視するために、LINE LIVE にもこうした開発環境専用の Tool API を実装して運用しました。
- まず DB へ書き込む
- 書き込んだデータをすぐに読み込む
- もし書き込んだデータが読み込めたら Replication Delay が発生していないと判断してエンジニアに通知を飛ばす
- 書き込んだデータを削除する
おわりに
いかなるプロジェクトにとって、問題になり得る箇所を、できる限り早い段階で表面化することが大事だと思っています。
そのため注意点と改善点は山ほどありますが、今回の記事はあくまでその中の一環にすぎないです。そして、似たような構成ではそこそこ悩ませる問題でもあり、こうした施策で少なくとも LINE LIVE にはいくつかの問題点を未然に洗い出し、新規開発などに与える影響を未然に防ぐ可能性を高めました。
私は違うサービスの担当に変わりましたが、今後も可能な限り引き続き新しい知見の共有をしたいと思っていますので、どうぞよろしくお願いします。