
はじめに
こんにちは。東京大学大学院修士1年の江口大志です。10月から12月にかけてのパートタイムジョブという形で、LINEでソフトウェアエンジニアとして働きました。
今回はData Platform室のIU Devチームに所属し、LINE社内のData Catalogの検索精度の改善に取り組みました。本ブログではその内容について紹介します。
背景
LINEでは、社内のデータ利活用を促進するためにInformation Universe(以下、IU)と呼ばれる内製のデータプラットフォームを利用していて、LINEのほぼ全てのサービスから生成されるデータが集積されています。
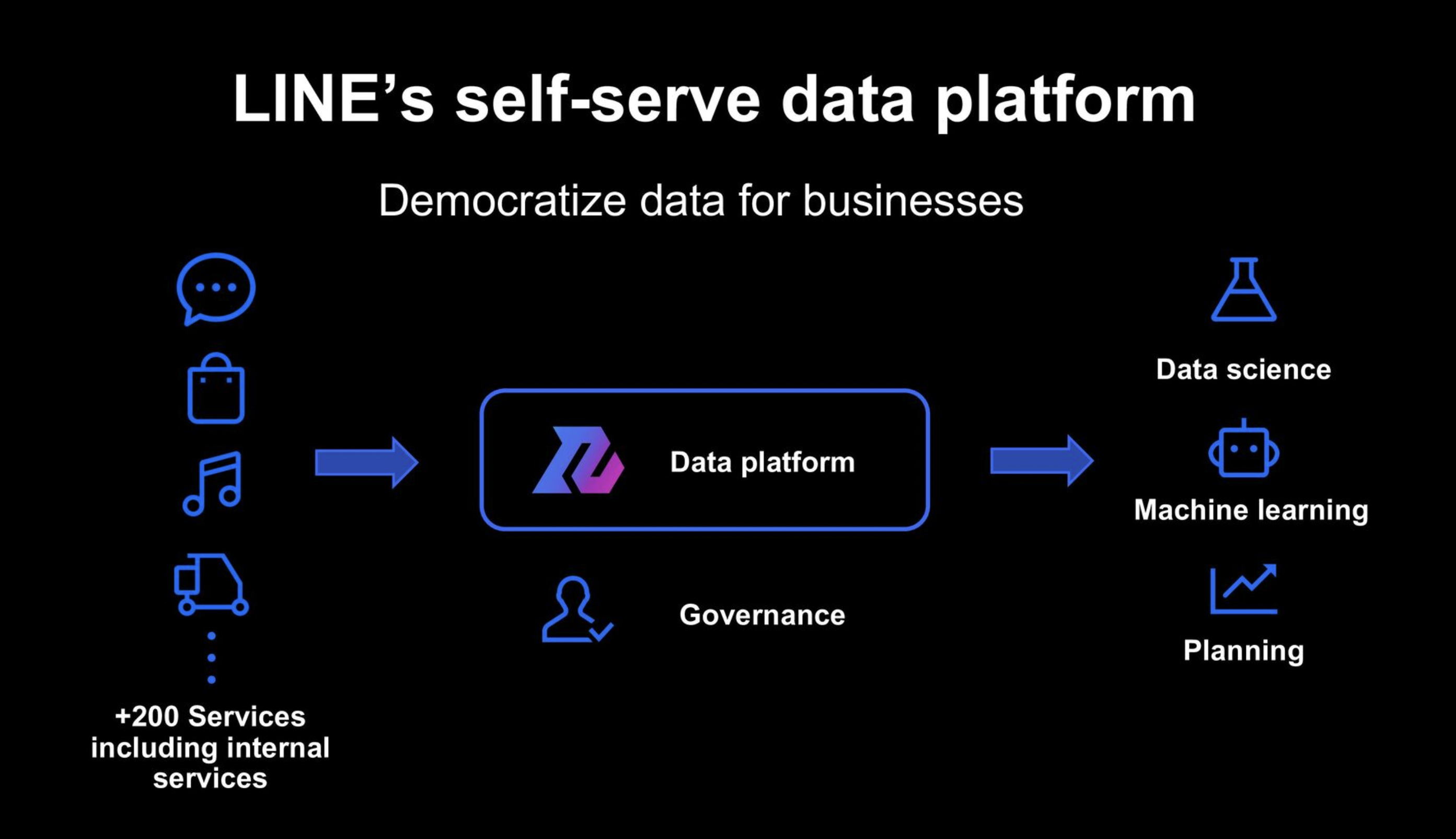
現在IUでは、4万テーブルに約400 PBのデータが入っており、それらのデータは毎日150,000ものジョブで生成・変更され増え続けています
「IU Web」は、IUのデータを安全かつ効率的に活用できるように、Data Catalogとして以下のような機能を提供しています。
- データの検索機能
- データの権限管理
- データのメタデータの管理機能(Data Lineageなど)
- Ad-hoc Query Editor
課題
LINE社内のユーザは、IUの膨大なデータから目的のデータを探すために、IU Webの検索機能を利用しています。
LINEでは「Always Data-Driven」を掲げており、またIUでは「全社横断のデータ利活用」を目指しています。データ活用において必ずデータを探すことから始まるので、検索を改善することは重要です。
IU Webの検索では、多量のデータ(例えばTableのデータはおよそ4万件以上ある)から、多種類のカテゴリを横断して、目的のデータを探し出す必要があります。
カテゴリには以下のようなものがあります。
- Table: Hive Table
- Database: Hive Database
- Project: IUを利用するサービス
- Service Account: サービスの利用するアカウント
しかしながら、現状のIU Webの検索では検索ランキングのチューニングが十分にされておらず、以下のような課題がありました。
- データ名に入力文字列が一致しているデータが検索結果の上位に来ないパターンが多くある
- Projectなどカテゴリによってはあまり上位に表示されない
- なぜ検索にヒットしたかがわからない (現状はフロントエンド側で一部のハイライトをしているのみ)
実際にユーザーからも検索クエリとその結果について問い合わせも来ている状況でした。


今回のゴール
これらの課題を解決するため、今回のゴールを以下のように設定しました。
- 検索結果の上位3~5件に関連するデータが返されるようにする
- なぜ検索にヒットしたのかを分かりやすくするためにハイライト機能を強化する
これらに加え、改善前とパフォーマンスが変わらないにようにする制約条件もあります。
上位3~5件としたのは、検索結果のページでスクロールせずに目に入る点、GoogleでのWeb検索の調査によると60~80%のユーザが最初の3つの結果をクリックするという話などから来ています。
開発・実装の詳細
IU Webの検索では、検索エンジンとして、Elasticsearch 7.10を利用しています。
検索エンジンでは大きくIndexと検索の機能があります。
Indexとは検索対象のデータを検索エンジンに格納するプロセスのことです。検索クエリが実行される際には、あらかじめIndexされたデータを走査することになります。
IU Webでは、Apache AirFlowのバッチを用いて、1日1回全ての検索に関連するデータをIndexingし直しており、1時間おきに変更があったデータのみをIndexしています。
検索に関連するデータはDatabaseやTable、それらの権限情報、クエリの実行回数などで、Hive MetaStoreやTrinoなどのQuery Engine、MongoDBから収集しています。
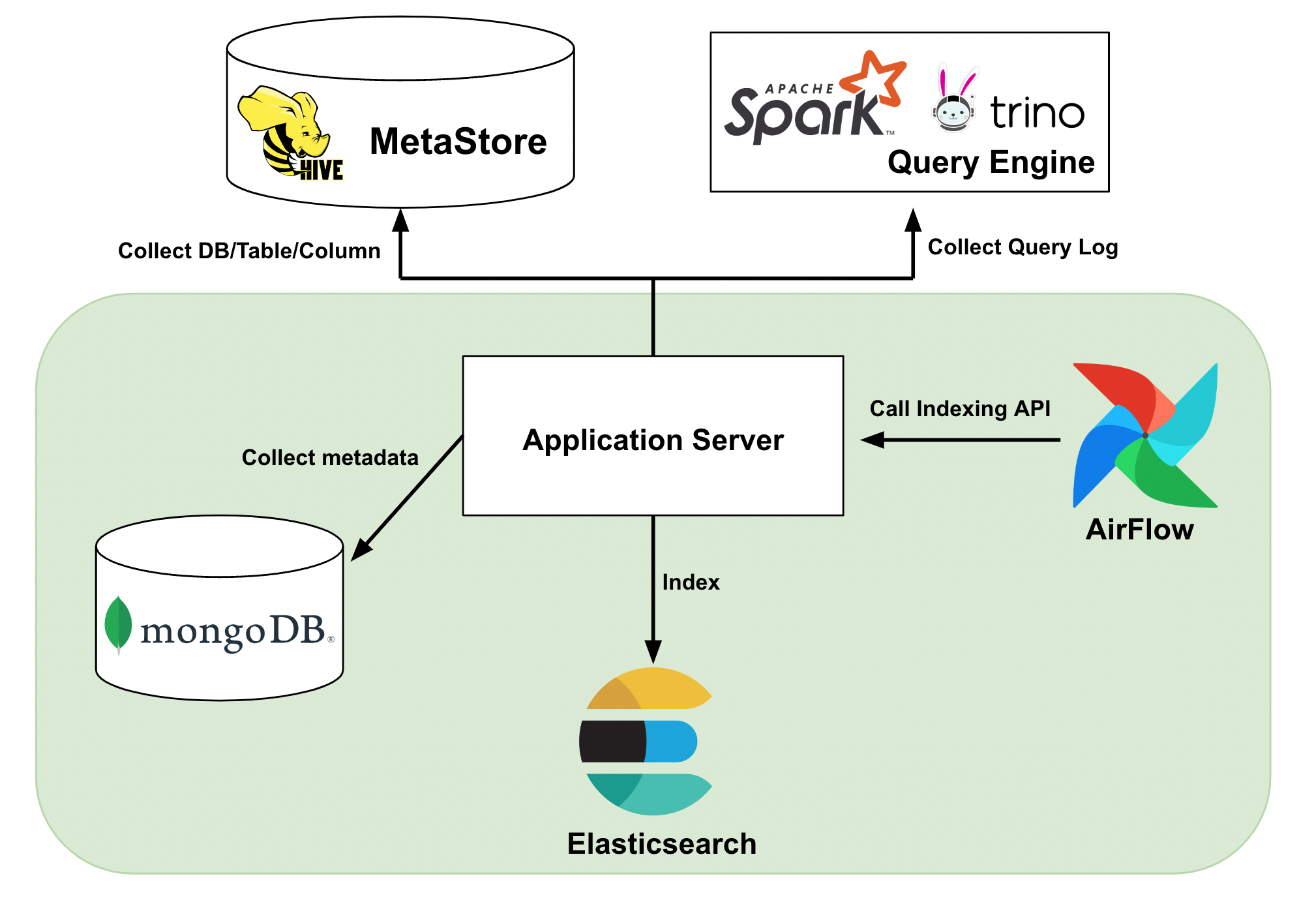
これらの前提を踏まえて、今回はElasticsearchの機能を用いてゴールの達成を目指しました。
現状の検索の使われ方を調べる
まず検索結果の精度を改善するにあたり、ユーザーが検索をどのように使っているかを調べました。
直近3ヶ月のユーザーのアクセスログなどを収集し分析した結果、次のようなことがわかりました。
基本的には文字列が一致しているものを探索している
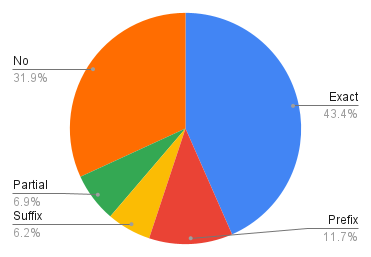
例えば、上記の図は、クエリと開いたページがTableだった場合に関して、項目名とどの程度一致しているかを示しています。全体の43.4%はTable名と完全一致(Exact)したページを開いており、ユーザーはメインの項目名に一致するクエリを入力していることがわかります。
これにはIU Webに備わる検索の補完機能などの要因もあると思われます。Tableの場合、不一致(No)のものの中には、`Database.Table`の形式のものも含まれていたので、文字列ベースで一致しているデータを上位に出すことの重要度は高そうです。
ほとんどのQueryは重複しない
同じユーザーの同じクエリは1回とカウントすると、5回以下しか実行されていないクエリが全体の90%以上を占めていました。
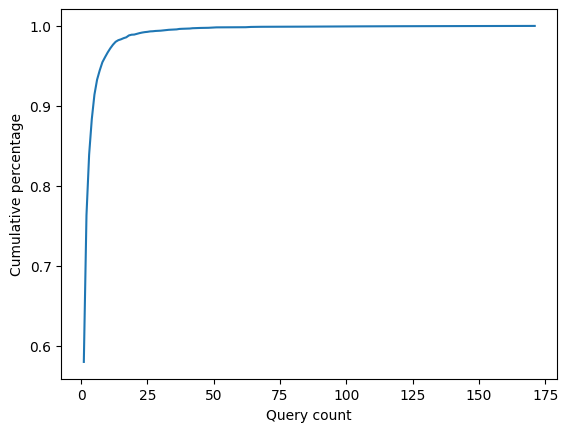
その他のさまざまなQuery
クエリを分析することで、他にも事前に想定しきれていなかったユーザーの動向が見られました。
- 大文字と小文字はあまり区別されない。
- 例. 「NEWS」と入力されたり、「news」と入力されたりする。
Database.Tableの形式のQueryが全体の9.96%あった。これはSQLからコピペしてクエリ欄に入力されていたり、同じTable名のものから特定のものを見つけ出す目的だと思われます。- 例. iuというDatabaseの、iu_apiというTableに対して「iu.iu_api」と入力されるなど。
- 「LINE」という文字列を省略してクエリに入力されるケースがある
- 例. 「LINE NEWS」を「News」として調べていたり、「LINE Pay」を「Pay」として調べるなどのケースです。
- 検索結果に出ないカテゴリを探すケースがある(これへの対応は「展望」として後述しています。)
- 例. 社員名で検索するなど。
検索結果のチューニングサイクルを作る
ユーザーの動向がわかったので、検索結果の改善に移ります。
その前に何を持って検索結果が良くなったとするかの評価を行えるようにする必要があります。
今回の場合、Queryの重複は少ないので、特定のクエリに特化して検索結果をよくするよりも全体として検索結果がどう良くなったかを評価したいです。
Elasticsearchには、Ranking Evaluation APIという機能があり、これを使うことで全体の検索結果の改善を評価できます。
Ranking Evaluation APIを使うにあたり、考えなくてはいけない点は主に2点です。
- 評価指標の選定
- 評価データの作成
評価指標の選定
結論から言うと評価指標にはnDCG@5を採用しました。
DCGはDiscounted cumulative gainの略で、以下のような数式で表されます。kは、上位何件を評価するか、の値です。
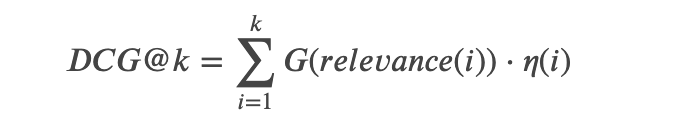
nDCG@kは、実際の結果結果のDCG@kを理想の検索結果のIDCG@kで割った値です。つまりNormalizedされているので0.0から1.0の間の値です。
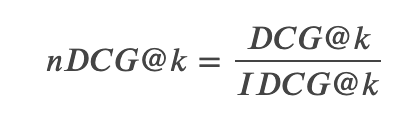
他の検索ランキングの評価指標としてRecall@kやPrecision@k, Mean Reciprocal Rankなどもありますが、nDCG@kは他のものに比べて、
- 関連度を多段階で評価できる(関連しているか否かの二値ではない)
- 関連度の高いものが上位にあることを評価できる
などのメリットから今回採用しました。
例えば、5つのアイテムについて、検索結果が上から、関連度
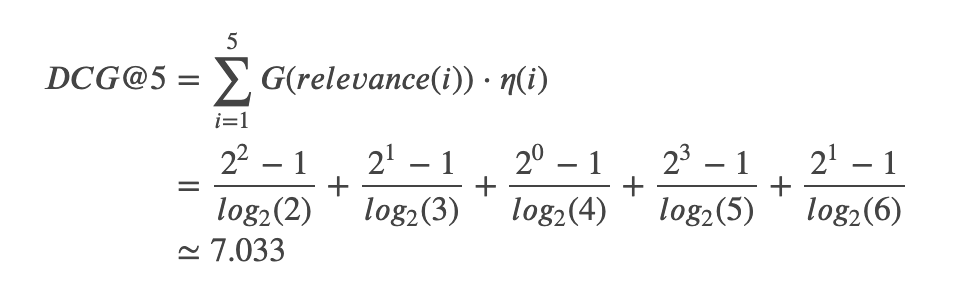
理想の順番としては、関連度
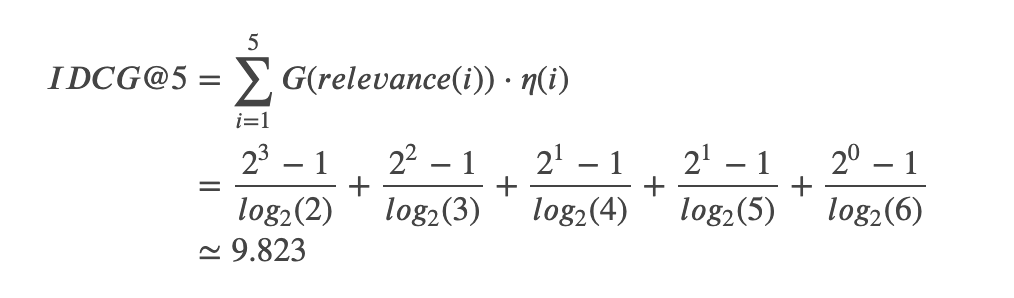
これらより、この例ではnDCG@5が0.716と求まります。
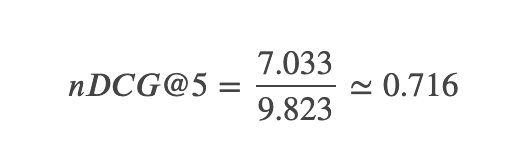
評価データの作成
評価データとはつまりクエリとそのクエリに対する理想的な検索結果のペアです。
評価データは、利用動向調査時に収集したユーザーのアクセスログをベースにしました。具体的には実際に過去入力されたクエリに対して、どのデータに辿り着いたか、何人が何回そのデータに辿り着いたかなどのログを参考に、クエリと理想の検索結果のペアを100件ほど作成しました。
以下評価データの1例です。
| 検索クエリ | カテゴリ | 項目名 | 関連度 |
|---|---|---|---|
| iu | Database | iu | 5 |
| Project | iu | 4 | |
| Table | iu_api |
3 |
|
| Table | iu_dev |
3 |
|
| Table | iu_beta |
1 |
Query DSL、Mapping、Analyzerの設定
ここのまでの議論を踏まえて、上記のチューニングサイクルを元に、検索結果がよくなるようにElasticsearchのチューニングを行いました。
今回Elasticsearchで設定を調整したのは以下になります。
- Mapping
- Analyzer
- Query DSL
MappingとAnalyzerは検索とIndexに関する設定で、Query DSLは検索に関する設定です。
Mapping
MappingはElasticsearchがドキュメントをIndexに登録する際に作成する型情報のようなものです。
以前の設定に加えて今回は
- main: TableであればTable名、DatabaseであればDatabase名などメインの名前を格納するfield (上記のスコアリングの問題を解決する)
- DatabaseTable: Tableについて、`Database.Table`というフォーマットのデータを格納するfield
- isAlphaOrBeta: `beta`や`alpha`などの文字列が含まれるものであれば表示優先度を下げるためのfield
というfieldと型情報を追加しました。
なぜこういった設定を追加したかに関しての詳細な話は、後述の苦労したことのセクションでお話しします。
Analyzer
AnalyzerはIndex時や検索時のtext field解析方法を指定するものです。
前述の通りユーザーの利用動向から、例えば「LINE NEWS」というProjectを探すのに「News」というクエリが入力される、と言った行動が散見されました。このことから「LINE」や「line」という文字列が含まれていなかったとしてもこれらのデータにたどり着けるようにするための設定をAnalyzerに追加しました。
以下の設定では正規表現でLINEやlineというprefixを除去した文字列もtext fieldにtokenとして格納できるようにしています。
Query DSL
Elasticsearchは検索クエリを柔軟に構成できるように、Query DSL (Domain Specific Language)を提供しています。詳細は公式ドキュメントなどを参照してみてください。
Query DSLを用いることで開発者は柔軟に検索クエリを設定することができます。
改善前は、multi_matchクエリで、ドキュメントのさまざまなfieldを同じ重みづけ(boost)で走査しています。
また検査結果に含めたくない個人的なデータ(rootPathがuserのもの)や検索対象でないColumnカテゴリのデータなどをmust_notやnegative_boostで処理しています。
改善後は、termやprefix, multi_matchなどのクエリにそれぞれboost値を優先したい順で組み合わせて、完全一致や前方一致、曖昧一致などの順番の制御をしています。
deprecated済みのデータ、alphaやbeta環境のデータ、利用頻度などの順番の反映をsortで行っています。
これらの設定の詳細については、同様に後述の苦労したポイントで記述します。
{
...
"query": {
"bool": {
"filter": [
{
"terms": {
"category.keyword": [
... // カテゴリ
]
}
},
{
"bool": {
"must_not": {
"term": {
"rootPath": {
"value": "user"
}
}
}
}
}
],
"should": [ // termやprefix, multi_matchを組み合わせて、それぞれに優先したい順でboost値を設定しています。
{
"term": {
"databaseTable.keyword": { // databaseTable fieldを追加しています。詳しくは苦労したことのセクションで記述します。
"value": "{{query_string}}",
"boost": 50.0,
"case_insensitive": true // ユーザー動向で大文字と小文字の区別がそれほどなかったため区別をなくしています。
}
}
},
{
"term": {
"main.keyword": { // main fieldを追加しています。詳しくは苦労したことのセクションで記述します。
"boost": 10.0,
...
}
}
},
{
"prefix": {
"main.keyword": {
"boost": 5.0,
....
}
}
},
{
"multi_match": {
"query": "{{query_string}}",
"fields": [
"main^10.0",
"databaseTable^5.0",
... // その他のfield
],
"type": "best_fields",
"boost": 0.5,
...
}
},
{
"terms": { // userが所属するプロジェクトを少し優先して表示する(他の項目に影響を与えないように小さなboost値にしている)
"projectIds.keyword": [
... // ユーザーが所属しているProjectのリスト
],
"boost": 0.1
}
}
],
"minimum_should_match": 1
}
},
"sort": [
{
"_score": {
"order": "desc"
}
},
{
"deprecated": { // 同じscoreのドキュメントの中でdeprecatedされているデータを下位にします。
"order": "asc"
}
},
{
"isAlphaOrBeta": { // alphaやbetaが含まれているテスト用のデータを下位に表示します。
"order": "asc"
}
},
... // その他利用頻度に関する項目
]
}検索結果のハイライト
また今回新たにハイライトの機能をより強化するために、バックエンド側でのハイライト機能を実装しました。
以前では、ハイライトをフロントエンド側で実装しており、限られた項目にしか対応できていませんでした。
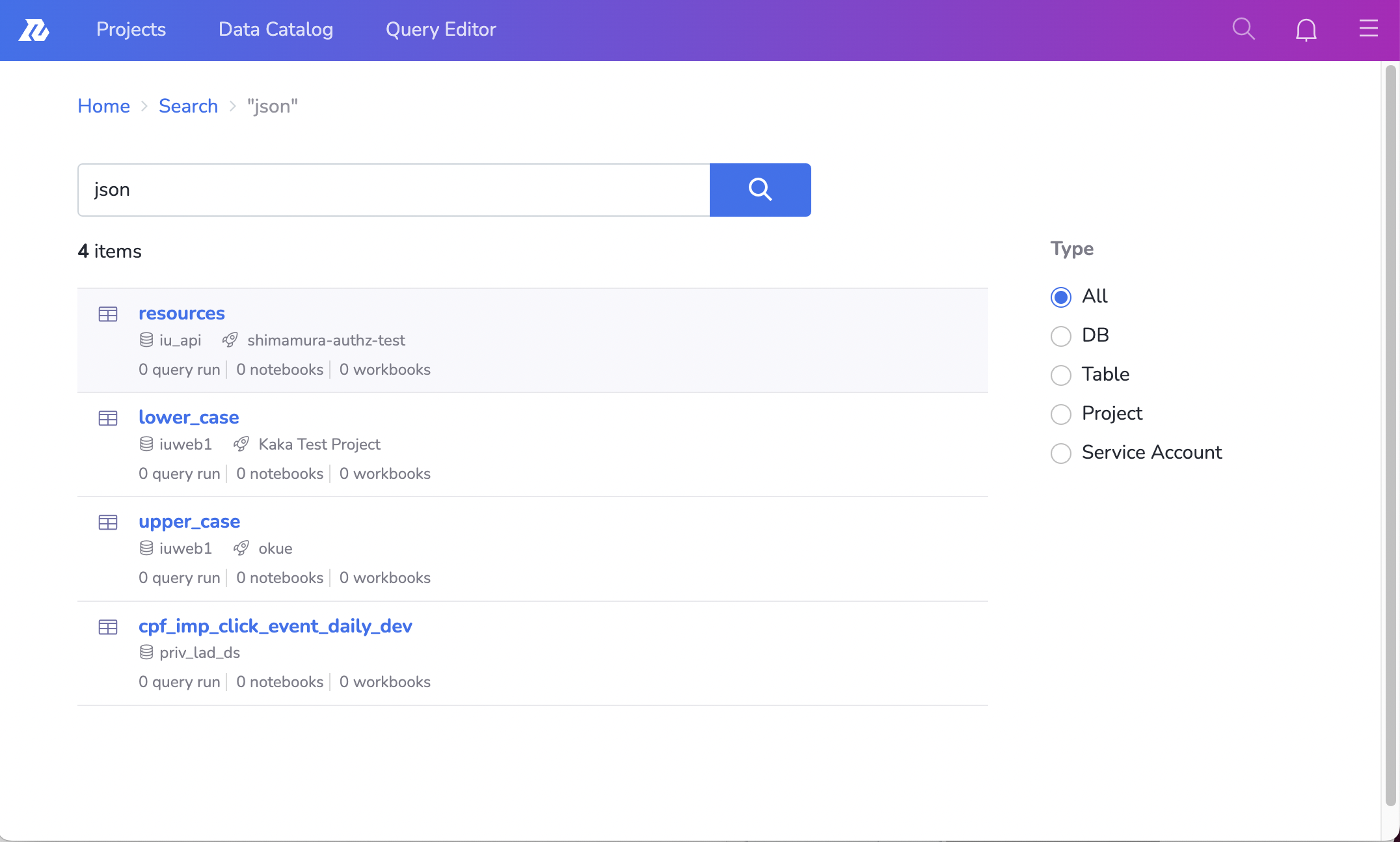
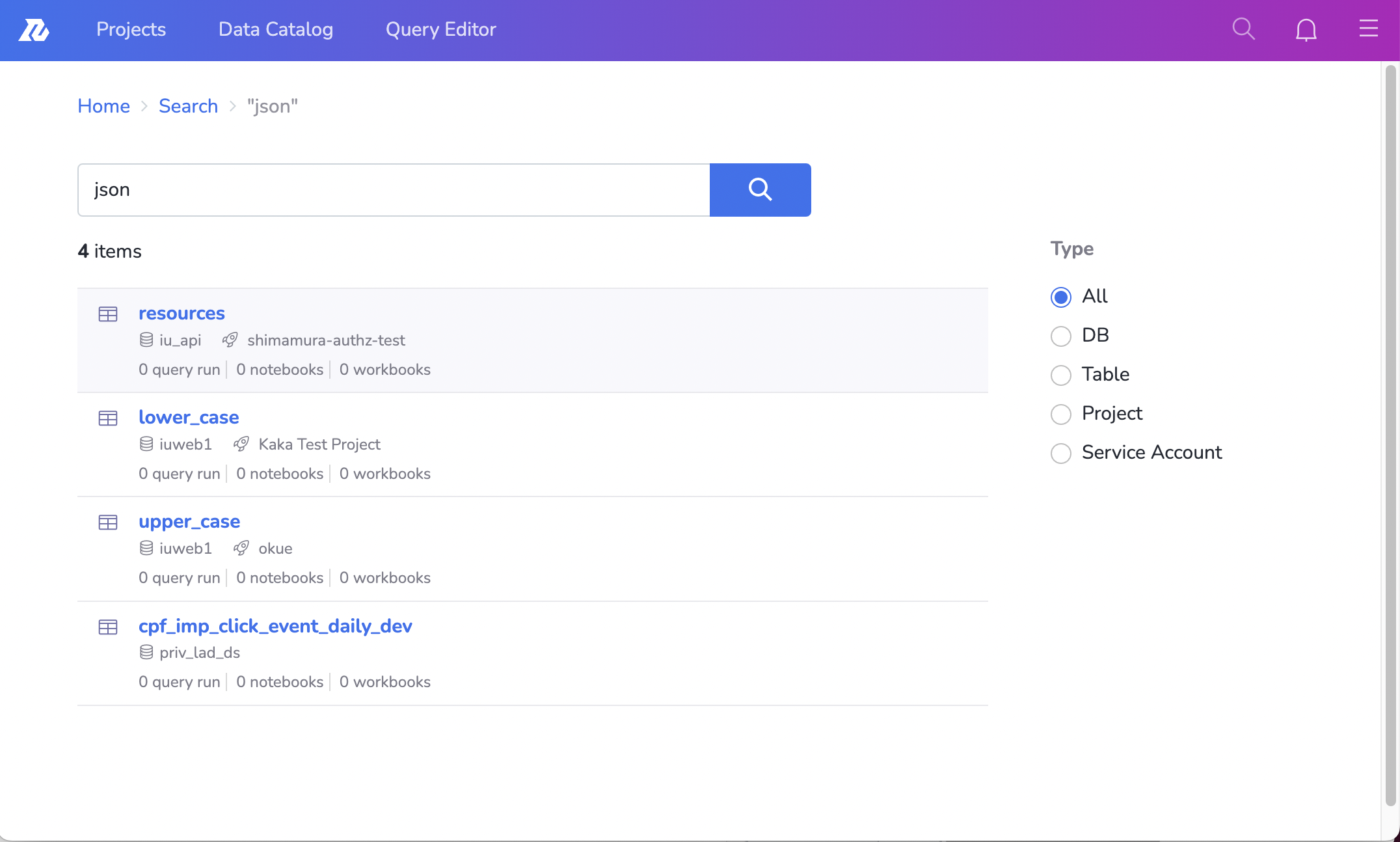
その結果、この図のように、例えば"json"という文字列に対して、なぜ「resources」「lower_case」というTableがヒットしているかわからない、などの事態が発生していました。
そこで新たにさまざまな項目のハイライトに対応できるようにバックエンド側のハイライト機能を追加しました。
今回は時間がなかったのもあり、ハイライトの設定は極力シンプルに保つようにしています。
IU WebのバックエンドはJavaとSpring Bootで動いているので、Query DSLのJSONの設定内容はElasticsearchのJavaのSDKで実装しました。
苦労したこと・それをどう解決したか
異なるカテゴリのデータをどうやって同じ検索結果に並べるか?
検索精度を改善していくにあたり、Data Catalogでは複数のカテゴリのデータがあるのでそれらをどう同等に同じ検索結果に並べるかという問題がありました。
今回のチューニングにおいて最も苦労したのはこの点でした。
最初はboostの機能を用いて例えば以下のように対応しようとしました。
しかしながらこれはmatchクエリのscoring的にfieldごとに異なる結果が出てしまいます。Elasticsearchで採用されているスコアリングはBM25をベースとしており、ざっくりと
- Term frequency (TF): fieldに検索文字列の出現回数が多いほど関連度が高くなる。
- Inverse document frequency (IDF): fieldに検索文字列が含まれているドキュメントが多いほどその用語の重要度が低くなる。
- Field length: 単語数が少ないfieldほど検索文字列が含まれていた場合の関連度が高くなる
といった要素があります。これらのスコアはfieldごとに算出されるため、例えば、Tableのドキュメントのtable fieldにおける「iu」という文字列のスコアとDatabaseのドキュメントのdatabase fieldの「iu」という文字列のスコアはかなり異なります。
これはTableカテゴリのtable fieldの「iu」という文字列のレア度と、Databaseカテゴリにおけるdatabase fieldの文字列のレア度が異なり、またそれぞれのドキュメントの数も異なるからです。このスコアの差分をboostで調整したとしても今度は「uts」など別の文字列に対するスコアがまた異なったものになります。
従って異なるカテゴリのデータでそれぞれ異なるfieldに値が格納されているような場合、boostでの調整では、特定のクエリに対して理想の検索結果を出すように調整できても、さまざまなクエリに対して理想の検索結果を出すと言った調整は難しかったです。
以上により今回は、
という設定を追加して、上記のように、TableであればTable名、DatabaseであればDatabase名などメインの名前を格納するfieldであるmainを追加し、mainをtermやprefix, multi_matchで検索するようにしています。
文字列一致と利用頻度などのバランスを取る
また苦労した点として、利用頻度を検索結果に反映しつつ、文字列への一致自体の検索の大筋を汚さないことでした。
言い換えると、どうやって完全一致, 前方一致, 曖昧一致, ユーザーに関係するデータ, 利用頻度をこの順番の優先度で検索結果に影響させるかという問題です。
例えば利用頻度を考慮しすぎると文字列に完全一致しているものよりも利用頻度の高いデータが上位にきてしまう可能性があります。
これらのバランスを保つため、今回はtermクエリやprefixクエリ、matchクエリをboostで調整し、ソートで文字列への一致を保ったまま利用頻度を反映しています。
また利用動向の分析から、`Database.Table`という形の文字列も多く入力されており、このタイプのクエリは探している対象のデータが特定のTableと明確であるため、termクエリで上記のdatabaseTableのfieldに対して大きなboost値をつけて上位(極力1位)に表示されるようにしています。
`Database.Table`のfieldをmatchクエリで検索してしまうと曖昧一致した場合のTableのスコアが大きくなりすぎて他のカテゴリより上位になりやすくなってしまうため、termクエリで完全一致した場合のみ上位に表示されるようにしています。
これらはもっとスマートにやる方法があるかもしれません。今回はパフォーマンステスト(後述)の結果問題なかったためこのような一見重複とも感じられる方法を取っています。
スコアリング対象のドキュメントをいかに絞るか?
検索結果のスコアリングを計算するにあたり、スコア対象のドキュメントをできるだけ絞り、かつそれらをキャッシュできるとパフォーマンスの向上が期待できます。
Elasticsearchにはfilterされたドキュメントをキャッシュするようです。以下が以前の設定となります。
以前の設定ではmust_notやnegative_boostなどスコア対象のドキュメントの絞り込みのための要素が散らばっており、キャッシュが効果的に使えていない可能性があります。
改善後の設定は以下です。
改善後はこのようにfilterを一箇所にまとめてスコア対象のドキュメントを毎回同様に絞り込まれるようにしています。これはQuery DSLの設定をシンプルにして可読性が上がるという効果も期待できそうです。
今回はここら辺のキャッシュヒットを厳密に調査する時間がなかったので展望としたいと思います。
結果
検索精度の改善
全体の指標の結果
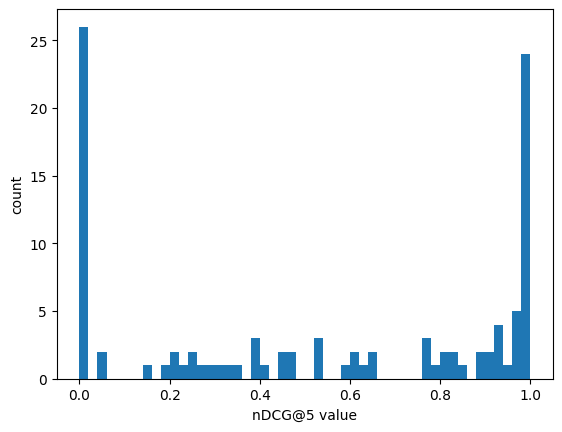
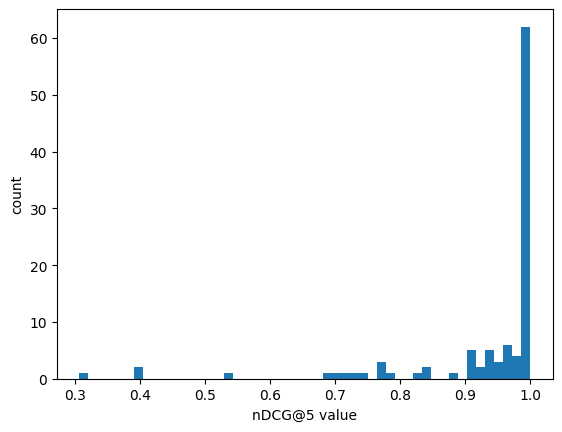
上記の工夫の結果、次のような全体の指標の改善結果となりました。nDCG@5の値が改善前の平均0.541から改善後の平均0.936へ大幅に上昇しました。各クエリのnDCG@5の分布を見ても、改善前では0.0のクエリが多くあるのに対し、改善後では1.0側にクエリの分布が寄っているのがわかります。ゴールの「検索結果の上位3~5件に関連するデータが返されるようにする」に対してある程度達成できていると言えると思います。
検索結果の例
具体的な検索クエリに対する、改善前後の差分を見比べてみます。
改善後のクエリの方がより文字列への一致度が良く、さまざまなカテゴリを混合して検索結果に出せている様子が見られると思います。
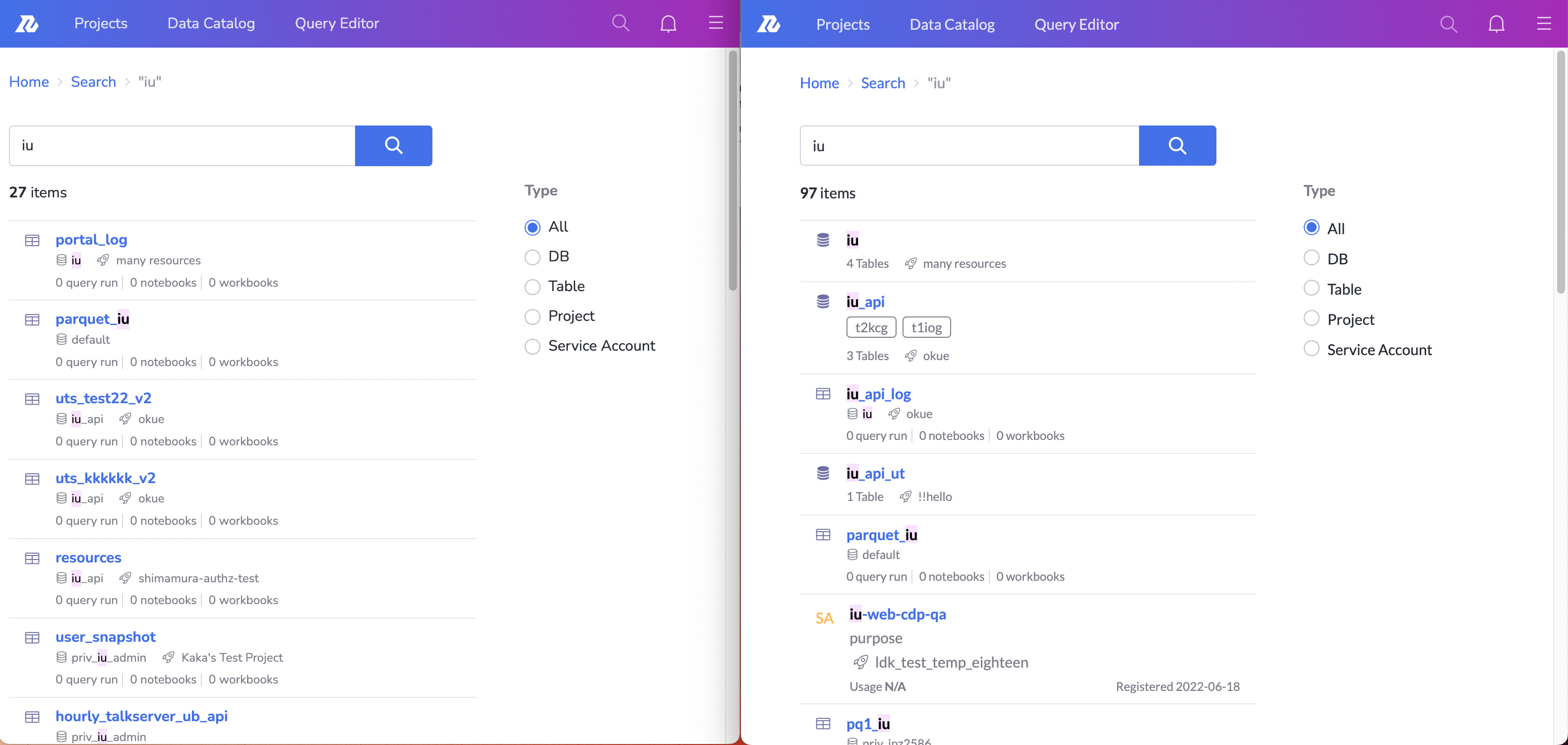
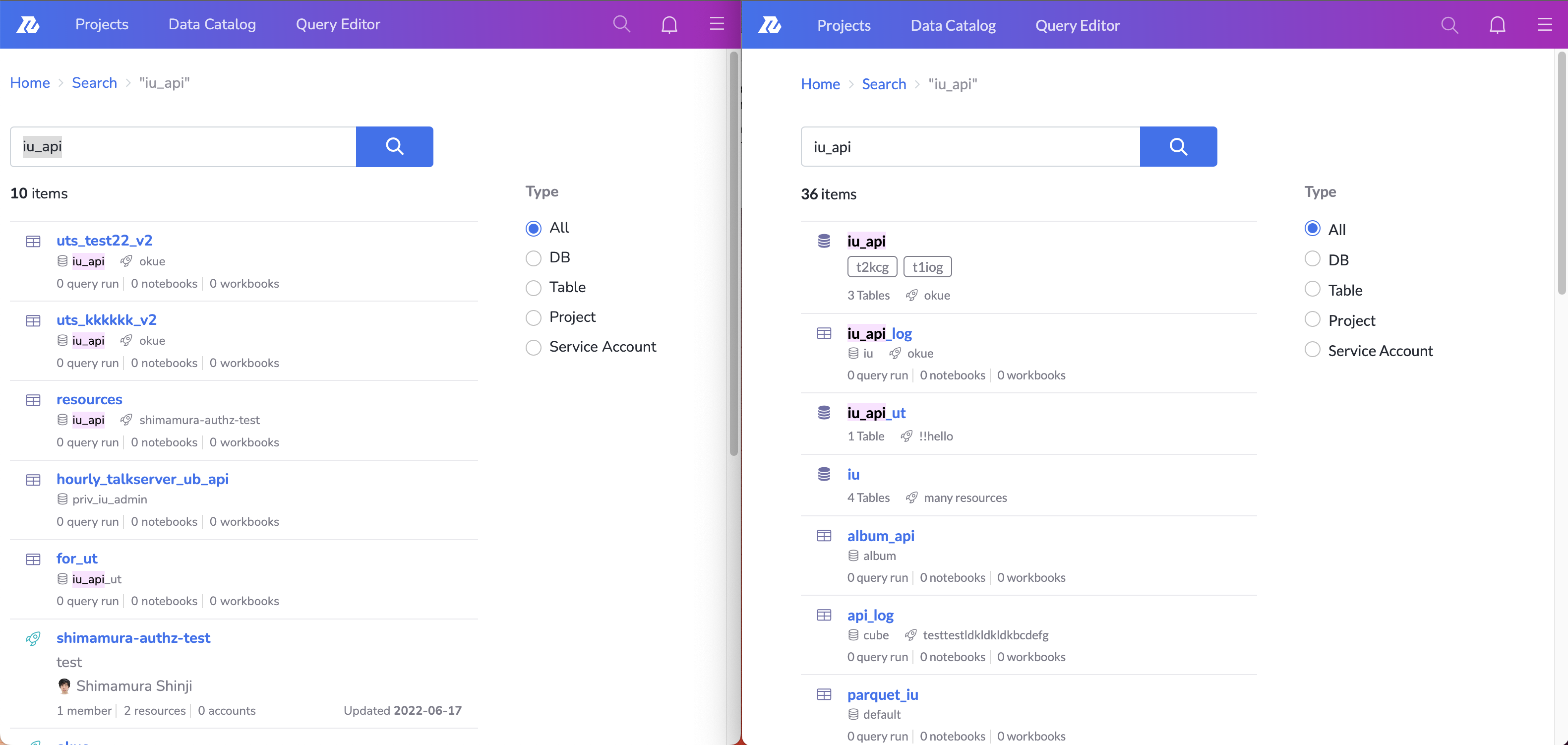
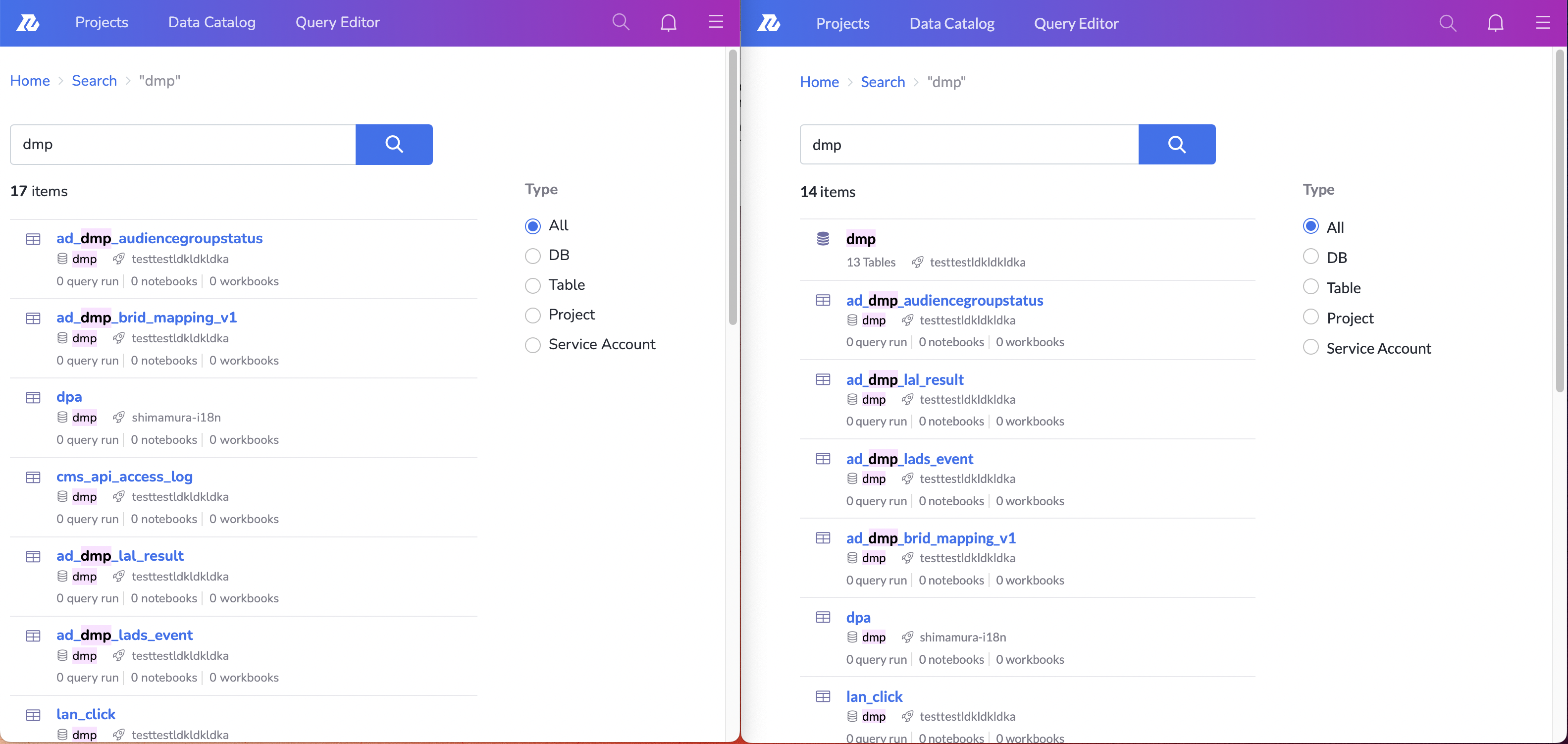
検索結果のハイライトの様子
パートタイムの期間中にはフロントエンドのリリースは間に合いませんでしたが、私の担当領域であるバックエンドの実装は完了しました。
前で例に挙げた、改善前の"json"という文字列に対してなぜ「resources」や「lower_case」がヒットしているかわからないという問題がありました。
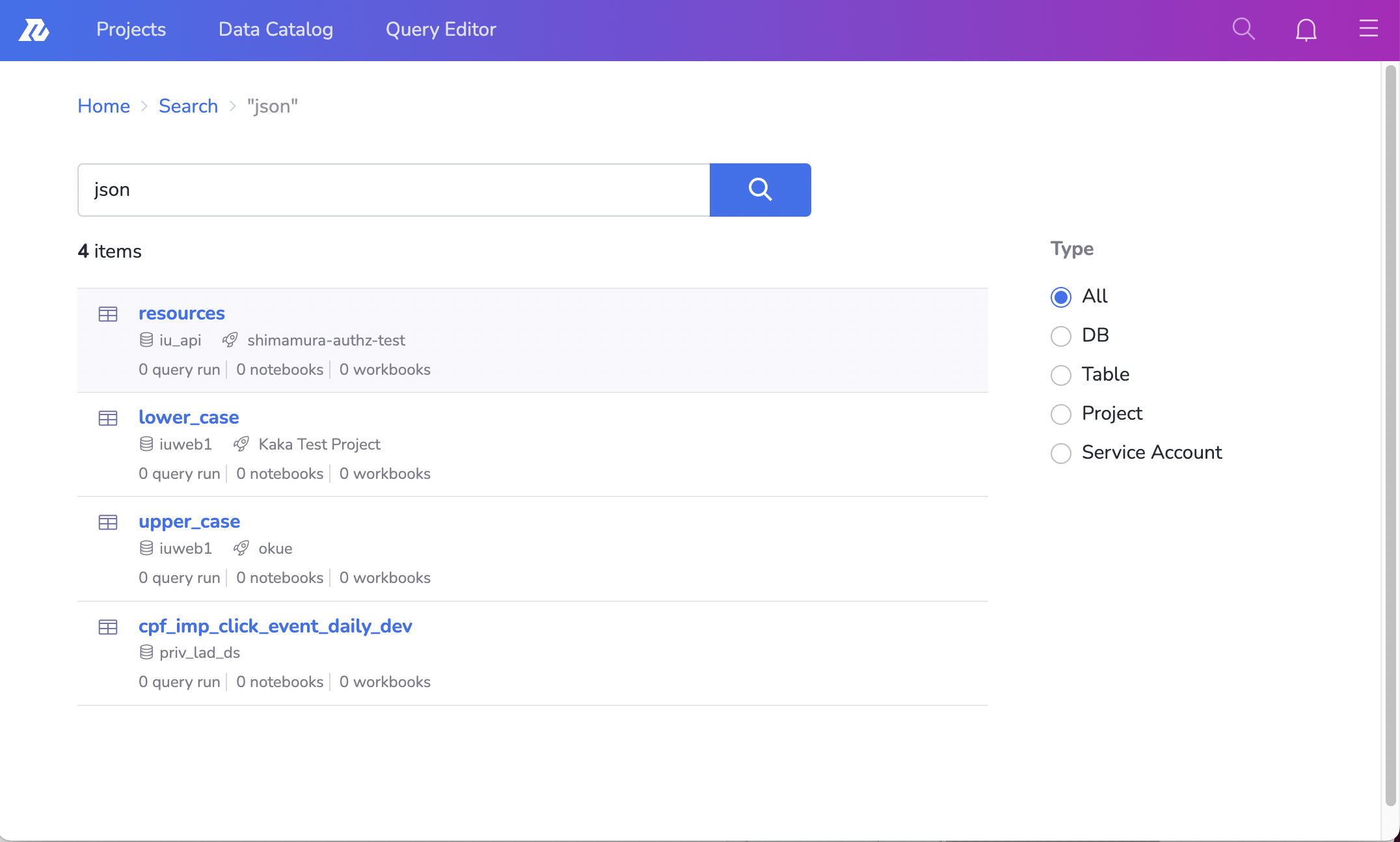
Query DSLにハイライトの設定をしたことで、レスポンスに、どのfieldに対してどの部分がハイライトすべきか、の結果が含まれるようになりました。
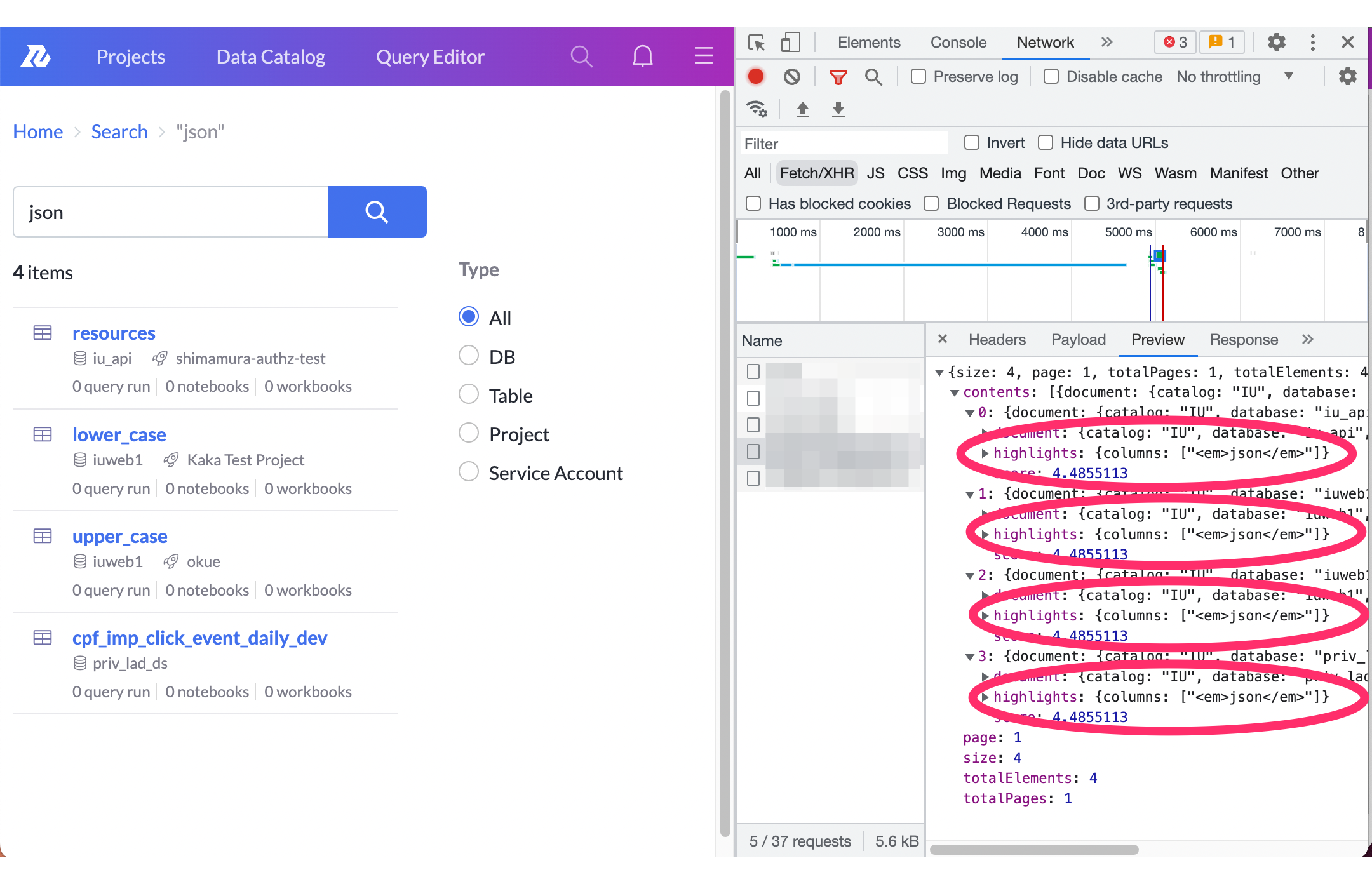
この例でいえば、「resources」や「lower_case」、「uppser_case」などのTableは、「json」という名前のColumnを持っており、検索結果に返ってきていたことがわかります。
検索パフォーマンスのチェック
リサーチを元に検索結果の実際に入力されている文字列を元にテストしました。
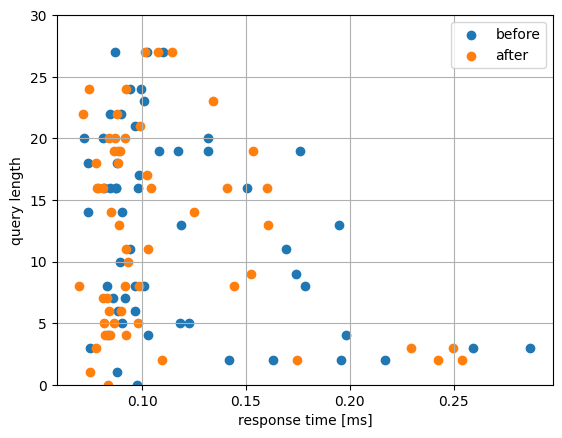
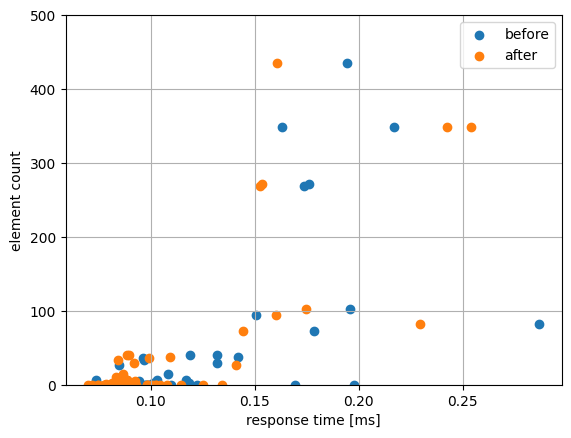
空文字や空白スペースなどのエッジケースも含め50種類以上のクエリで、各クエリのレスポンスタイムとその他の要素について相関関係をチェックしました。
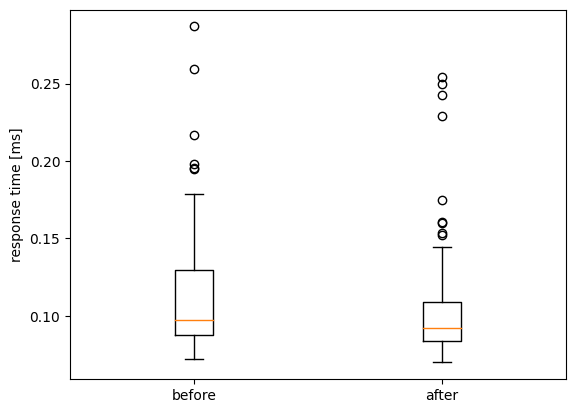
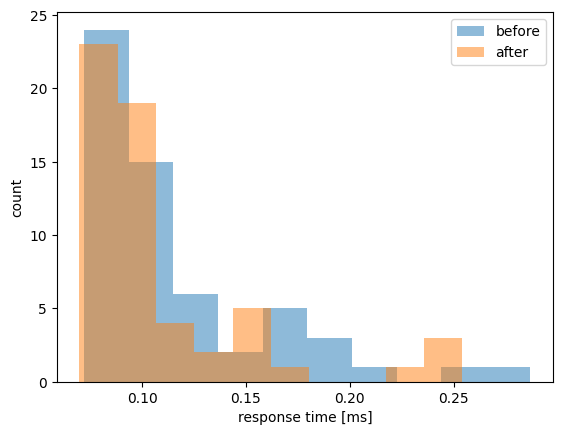
レスポンスタイム
改善前と改善後の分布です。概ね同程度か少し短いレスポンスタイムで検索結果を返せていることがわかります。
CPU/Memory/GC Count
また実際に入力された検索クエリを元に負荷テストを実施しました。
CPUやメモリ使用量、GCの回数といった要素について、IU WebのサーバとElasticsearchのClusterの負荷をチGrafanaでチェックして改善前と後で大きく異ならないことを目視で確認しました。
展望
今回はパートタイムの期間がある程度決まっていたので取り組める内容にも限りがありました。今後の検索精度の改善の施策として次のようなものが考えられます。
検索対象のデータを増やす
現在は検索対象のカテゴリとして、Database、Tableなどがあります。
これらに加えて、ユーザーやColumn、各ダッシュボードなど検索対象のデータを増やすことが考えられます。
実際利用動向の分析からこれらのデータを探そうとするクエリも見受けられました。
検索対象のドキュメントが大幅に増えることで検索時やIndex時のパフォーマンスや、日本語や韓国語などの多言語対応、一致するドキュメントが増えることによる更なるランキングの改善の必要性など、よりチャレンジングになりますが、社内のほとんどのデータに1つの検索窓からアクセスできるようになる恩恵も大きそうです。
検索補完機能の改善
現状の検索補完機能では補完された項目を選ぶと勝手にカテゴリも絞り込まれる仕様になっています。しかしながら今回の検索精度の改善によって文字列の一致ベースで、カテゴリを横断的に同等に検索結果に現れるようになったため、補完はカテゴリを含まずに単に文字列を提案した方がユーザー体験が良い可能性があります。
また`Database.Table`という形の文字列を表示するなどの工夫も考えられます。
利用頻度のfieldをカテゴリ間で同等に評価する
今回は利用頻度の反映として文字列一致を優先させるために全文検索クエリでスコアリングした後にソートするという方針を取りましたが、ソートの欠点として、特定のカテゴリが優先して上位に表示されてしまうという問題があります。
これに対応するために、例えば、利用頻度に関わるようなfieldを正規化して0.0~1.0の範囲に収めて、それらのfieldを文字列一致に影響しない程度に加算するなどの施策が考えられます。この方法のメリットとして、利用頻度が高いデータと最近作成されたデータなども同等に評価しやすいという点です。
ただしさらっと正規化と言っていますが、正規化するためにはいわゆるオフラインアルゴリズムで全データを参照する必要があるため、Index時に常にデータの分布を保持・更新するなどの工夫をするか、検索時に計算コストを払って各fieldの正規化を行う必要があります。
ハイライトの更なる設定
現在はハイライトとしてシンプルな設定を採用していますが、よりハイライトできる範囲を増やしたり、ハイライトの細かい設定をする上で、Elasticsearchの他のハイライトのオプションを使う選択肢が考えられます。ハイライトはフロントエンドに密接に結びついている機能なのでフロントエンド側で実現したい機能と併せてAPIの設計考えていくことが重要だと思われます。
今後のユーザー動向の変化を反映させる
今回はあくまで改善前の検索機能を使っているユーザーの直近3ヶ月の行動の分析を元にした検索結果の改善施策となりましたが、改善後の検索機能によってユーザーの動向が変化する可能性があります。
ユーザーが目的のデータに最短で辿り着けるようにするために定期的にユーザーの行動を分析して検索精度を改善していくことが必要だと思われます。
より高度な検索結果の改善
今回はElasticsearchのQuery DSLのパラメータを手作業でチューニングしてルールベースの検索を行なっていますが、ランキング学習など機械学習を用いて検索精度のチューニングを行う方法が考えられます。
感想
今回のパートタイムでは、LINEの夏インターンシップなどと異なり、大学院の授業などの都合で週3日という形での参加でしたが、メンターの島村さんから熱心にサポートいただき、内容に取り組むことができました。またJava、Spring Boot、Elasticseach、検索という分野、どれも初めて触れた技術だったため、キャッチアップが大変でしたが、改善した内容を本番環境にリリースするところまで行けたのも本当に良かったです。
期間中はメンターの島村さんだけでなく開発チームのメンバーからもたくさんのサポートを受けることができ大変感謝しています。サポートを通して、スクラムでの開発サイクルやGitHubのコードレビューからマージ、ドキュメンテーションなどチーム開発プロセスや実装・設計についてさまざまな知見を得ることができましたし、チームでのランチ会などを通してソフトウェアエンジニアとしてのキャリアについて真摯に相談に乗っていただけました。課題には直接関係のないことでも、興味がある技術について教えていただける機会を設けていただいたり(Data Platform室にはBig dataに関する面白い技術がたくさんあります!)、技術書の内容をチーム内での勉強会の場で発表したり、パートタイムで取り組んだ内容をData Engineeringセンター全体で発表する機会もいただけました。とても有意義な時間を過ごすことができました、本当にありがとうございました!