
はじめに
こんにちは、Data Platform室IU Devチームの島村です。
Data Platform室では、約400ペタバイトのデータ分析基盤を運用しております。このData Platformは、「Information Universe」(以下、IU) と呼ばれており、LINEの様々なアプリケーションから生成されるデータをLINE社員が活用できるように、データの収集、処理、分析、可視化を提供しています。私が所属するIU Devチームでは、「IU Web」を開発しています IU Webは、IUのデータを安全にかつ効率的に活用できるようにするData Catalog機能を提供しており、LINEグループのあらゆるサービスから利用されています。
IUにおいて、Data Pipelineが複雑になるにつれて、データに関する問題が発生した際のデータの関係性の把握が難しくなっていました。この問題を解決するために、IU Webでは、Data Lineage機能を導入しました。この記事では、導入したData Lineage機能と、機能開発時に発生した問題及びその解決方法についてご紹介します。
なぜLINEでData Lineageを導入したのか
前提として、企業が信頼性のあるデータに基づいて意思決定を行うためには、データシステムの状態を把握する能力(データ観測性)を高めることが重要です。Data Lineageはデータ観測性の5つの柱の1つとして位置付けられています。Data Lineageは、ある対象のデータについて、データが生成されてから現在に至るまでの経路と、経路上で行われた変更を追跡可能にします。Data Lineageによって、データエラーの追跡やデータの依存関係の把握を簡単に行うことができるようになります。特にData Platformで扱うデータ量や関わる組織が増えて、Data Pipelineが複雑になるにつれて、Data Lineageの把握は難しくなります。
IUにおいても、昨年のLINE DEVELOPER DAYでも紹介があったように、大規模なデータを扱っており(例えば、1日に約15万ジョブ実行される)、以下のような問題を抱えていました。
- データ生成ジョブ失敗時のデバッグが大変
- データ生成ジョブが失敗した際に、ジョブのソースコードを確認して、データ生成に利用しているTableを特定し、そのTableのPartitionの存在確認をしている
- Tableのスキーマ変更時の影響範囲を調べるのが大変
- Tableのスキーマを変更時にどのようなTableに影響を与えるのかを特定し、さらにそのTableのオーナーを調べている
このような問題に対応するため、私たちはData Lineageの開発に取り組みました。
Data Lineageで達成するゴール
上記で述べた、IU利用者の問題を解決するため、Data Lineage機能を導入によるゴールを以下のように定めました。
- データに関する問題の調査を効率的に実施できるようにする
- データ変更における影響の事前調査を行いやすくする
Data Lineage機能
実際に開発したIU WebのData Lineage機能についてご紹介します。
Table Lineage
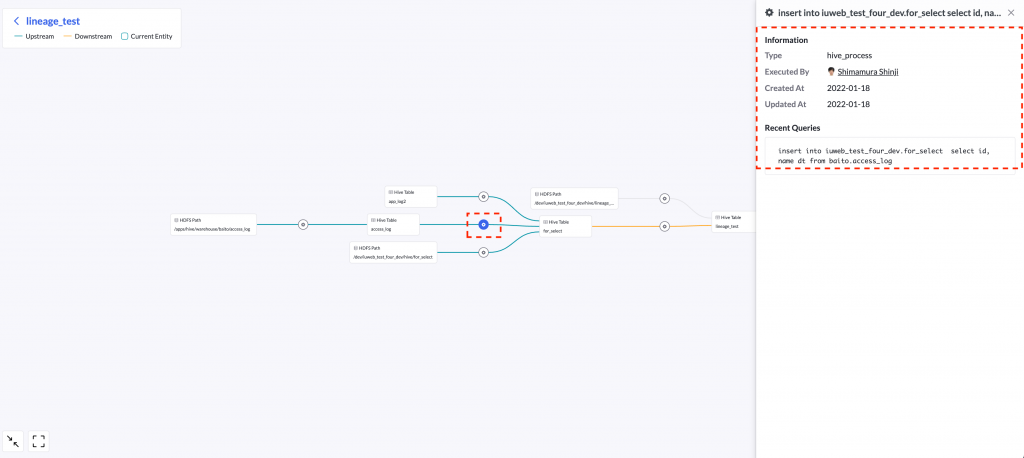
Tableの関係性をグラフで表示します。Tableを選択すると、TableのOwnerやPartiotion等のメタデータを表示します。グラフの緑の矢印は、データが生成されてからの選択されているTableまでの経路(Upstream)を示しています。また、グラフのオレンジの矢印は選択されているTableの変更が影響を与えるデータセット(Downstream)を示しています。
さらに、歯車のマークを選択するとデータ生成を実行したクエリーに関する情報を表示します。

Column Lineage
Columnの関係性をグラフで表示します。Columnを変更する際の影響範囲の特定やセキュリティレベルの高いColumnがどこで使われているかの把握が可能です。例えば下図では、nameというColumnのData Lineageを表示しているのですが、このColumnには赤丸が表示されています。この赤丸は、セキュリティレベルが高いことを示すTagが設定されていることを示しています。

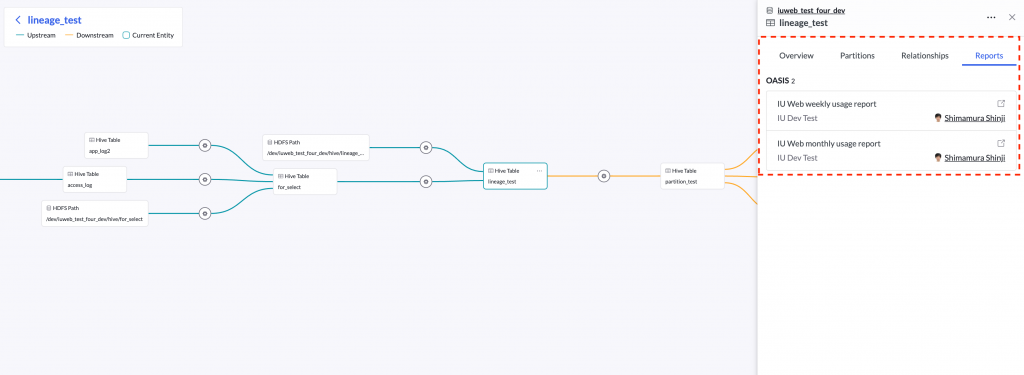
Dashboard Lineage
Tableに関連する情報として、IUで提供する内製のレポーティングツールであるOASISのDashboardへのリンクを表示しています。この機能によって、データの発生元や利用状況を正確に把握できます。また、データの変更/障害の発生時に影響のあるDashboardを把握したり、データの利用事例を参照することが可能となります。
通知機能
ユーザーがデータの異常や変更をいち早く検知するために、2つの通知機能を提供しています。
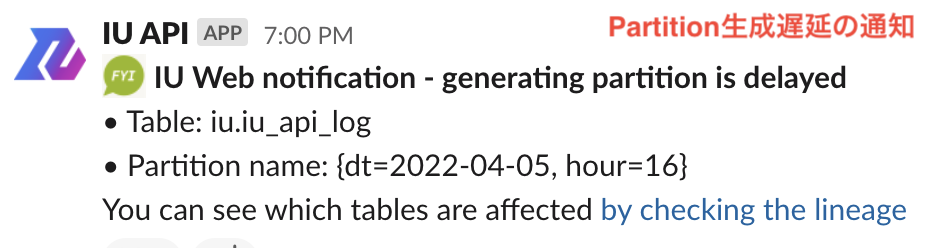
- Partition生成遅延の通知: Partitionの生成に遅延が発生した際に、Slackチャネルに通知します。Slack通知では、Partition生成が遅延したTableのData Lineageにリンクしているため、遅延の原因がデータ発生元のどこにあるのか、効率的に調査できるようになっています。
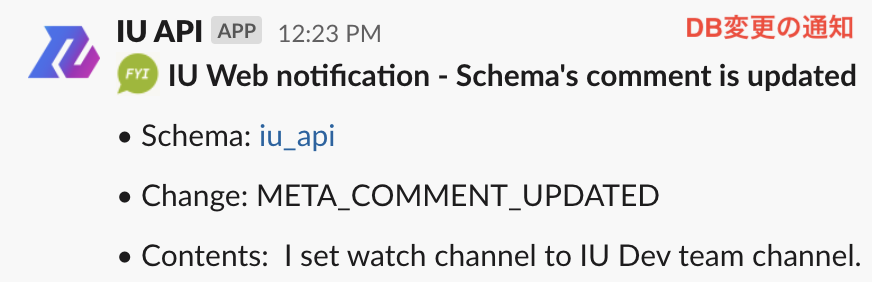
- DBやTableの変更を通知: DBやTableのSchemaやTag、Description等の属性情報が更新された際に通知します。Data Lineageを活用して、通知設定したTableのデータ生成経路上での変更も通知します。変更に伴う各業務・システムへの影響をいち早くキャッチアップできるようになっています。
システム構成
上記で説明したData Lineage機能を実現するためのシステム構成をご説明します。
Apache Atlas
Table間の関係性の取得には、Apache Atlas(以下、Atlas)を利用しています。そこで、まずはAtlasについてご紹介します。
Atlasは、オープンソースのData Catalogで、Apache Hive(以下、Hive)、Apache Spark等によるデータ変更により生成されたメタデータを蓄積します。Data Lineage機能に加えて、メタデータの検索、Tag付けや権限管理等に利用することができます。
Lineageのシステム構成
IU Webでは現在、Hive Lineage及びDashboard Lineageに対応しています。
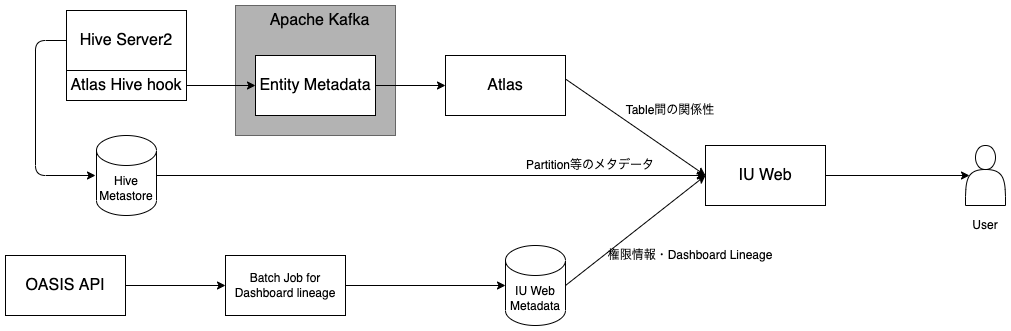
はじめにHive Lineageのシステム構成ついてご紹介します。Hive Lineageは上の図で示したように、Atlasで提供されているAtlas Hive hookをHiveSever2に設置し、Hive上の変更操作をApache Kafkaを通してAtlasに登録しています。IU Webでは、AtlasのREST APIからTable間の関係性を取得しています。最終的には、Atlasから取得したデータに、Hive MetastoreやIU Web内部で管理する権限情報やDashboard Lineage情報を組み合わせてData Lineageを表示しています。LineageのUI機能はAtlasでも提供されているのですが、Atlasに加えて、IU WebやHive Metastoreで保持する情報を組み合わせることによって、ユーザーにとって有用な機能の提供が可能となっています。
Dashboard Lineageとしては、上の機能紹介でご説明したように、OASISのDashboardとリンクしています。このDasoboardとのリンクは、Dashboardに含まれるSQLクエリーを解析することで実現しています。OASISでは、Trino、Spark SQLの2つに対応しています。ここで、重要になるのは、SQLクエリーとData Catalogをどのように紐づけるかという点です。IU Webでは、Trino, Spark SQLの公式のParserライブラリーを利用してSQLを解析し、SQLクエリー内に含まれるTableを抽出し、SQLクエリーとIU Webの対応関係を保存して利用しています。2022年5月時点で約85,000のSQLクエリーがTableに紐づけられています。
苦労したこと・それをどう解決したか
Apache Atlasのパフォーマンス問題
特定のTableのData LineageをAtlasのREST APIから取得する際にパフォーマンス問題が発生しました。
初めは、APIを呼び出すとAtlasのメモリー使用量が増えてハングし、Atlasを再起動するまでは利用できない状態となりました。こちらの問題については、Data Platform室のパートナーであるClouderaのメンバーに協力いただき、修正されました(ATLAS-3590, ATLAS-3558)。しかし、修正後も特定のTableにおいてAPIの呼び出しに約30分かかりました。そこで、パフォーマンスの改善を試みました。
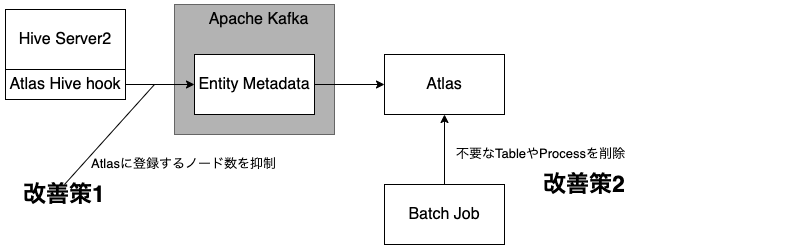
Atlas APIの時間がかかる原因を調べると、Data Lineageグラフのノード数が多いため、表示に時間がかかることがわかりました。特にhurly/dailyのJob毎に生成される一時的なTableに関連するTableでは、Jobが実行される度にTableに繋がるノード数が増えて、グラフのノード数が膨大になっていることがわかりました。そこで、以下2つの改善策を適用することで、Lineageグラフのノード数を減らしました。
- HiveからAtlasに登録されるノード数を抑制する: Atlas Hive hookには、正規表現でフィルターしてAtlasへの登録をしないようにする設定があります(ATLAS-3006)。この設定を利用して、tmp等の一時的なTableに使われる文字列を含むTableをAtlasに登録しないようにしました。これにより、Atlasに登録されるTable数は約90%削減されました。
- Batch Jobで不要なTableやProcessをAtlasから削除する: 1.のアプローチで一時的なTableの登録はされなくなりましたが、特定のTableでJobが実行される度に一時Tableと関連するHive Processノードが追加され、Lineageグラフのノード数が増えていました。そこで、このような一時的なTableに繋がるHive ProcessノードをAtlasから削除するBatch Jobを導入しました。このBatch Jobで毎日約300,000ノード削除されています。
これらの改善策を導入した結果として、Atlas APIの実行時間はほぼ全てのケースで約6秒以内、最悪のケースで15秒以内となりました。
複雑なData Lineage
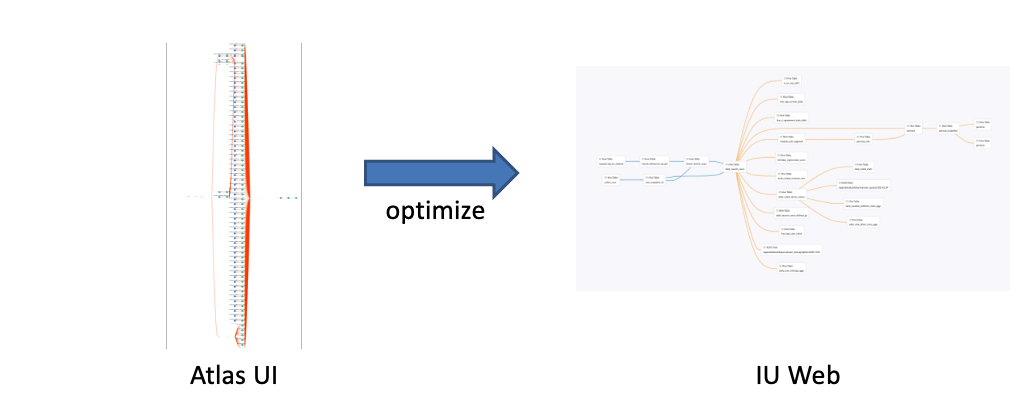
一部のTableにおいて、Data Lineageのノード数が多過ぎて、ユーザーが確認したいデータの生成経路の確認がしづらいという問題が起きました。これに対してAtlas APIが返すData LineageをIU Webで、以下2つの方法で最適化し、ユーザーにとって必要なData Lineageのみ表示するようにしました。
- Table Lineageの表示時にColumnは非表示にする: Data Lineageにおいて、TableとColumnが直接つながることがあります。1つのTableあたり大量のColumnが存在するような場合は、ノード数が大量になります。一方で、あるTable AとTable BのColumnが関連している場合は、Table AとTable Bの間にも関連があることがわかりました。そのため、Columnは非表示にしてもTalbe間の関連は失われないので、Table Lineageを表示時はColumnは非表示とすることにしました。
- 重要度の低いHDFS Pathノードを非表示にする: Pathにtmpを含む等、重要度が低いと考えられるHDFS Pathのノードを非表示にしました。
結果として、以下の例のようにAtlas UIでは、複雑で見づらいData Lineageが、IU Web上では、シンプルで見やすくなりました。
Data Lineageの利用状況導入効果
Data Lineage機能は2021年11月に初期導入してから、徐々に利用者が増えており、2022年5月時点で79のサービス・部署で利用されています。Data ETL/Data Management/Data Science等、日々データに携わっているユーザーから使われています。
個別にData ETLチームより、Tableメンテナンス(DROP TABLE, ALTER TABLE実行)時の影響範囲の確認が容易になったというフィードバックをもらっています。
また、日々のIUユーザーのSlack上のコミュニケーションにおいても、Data Lineageがデータエラーの原因調査等に利用されているのが確認できています。
今後の活動
Data Lineageの導入効果が確認できたので、今後もData Lineageに関する機能追加を計画しております。いくつか計画している中で、ここでは2つご紹介します。
- Data Lineageで追跡する範囲を広げる: 短期的には、Apache Spark及びHive MetastoreのData Lineageにも対応することで、IUにおけるデータの関係性の大部分を網羅します。長期的には、IU以外で行われた変更も追跡可能にします。これにより、ユーザーがより広い範囲でデータの関係性を把握できるようにします。
- セキュリティ・ガバナンス強化: AtlasはData CatalogのポリシーTagをData Lineageを通して伝播させることができます。Tagの伝搬を利用すると、例えば個人を特定できる情報に付与するTagをあるTable(又はCooumn)に設定した際に、このTableが利用されているTableにも自動でTagが付与されます。Tagの伝搬とTagが設定された際の通知や、Tagを利用したアクセス権限の設定等を導入することで、セキュリティの強化を目指します。
さいごに
IU Devチームでは大規模なData PlatformのData Catalog構築において直面する課題の解決に関わることができます。LINE社員のデータ活用の支援やデータに関わる技術領域に興味・関心がある方を募集しています。よりLINEのデータ活用を進めるために、多くの解決したい課題がある一方で、人手が足りていない状況です。少しでも興味がある方がいましたら以下よりご応募いただけましたら幸いです。尚、Big dataに関する経験は必須ではありません(私も入社時は、経験がありませんでした)。