
Hi, this is Shinji Shimamura from the IU Dev team in the Data Platform Division.
The Data Platform Division operates a data analysis platform with a size of approximately 400 petabytes. This data platform, called Information Universe (IU), collects, processes, analyzes, and visualizes data generated from LINE’s various applications so that LINE employees can utilize them. My team, namely the IU Dev team, has been developing "IU Web", which is used by every service in the LINE Group, providing data catalog functions to enable safe and efficient use of IU data.
During development for IU, one of the challenges we faced was that the more complicated data pipelines became, the more difficult it became to understand the relationship among data when a data-related problem occurred. To address this challenge, we introduced data lineage functions into IU Web. In this article, I'd like to share the data lineage functions we introduced, what problems occurred during development, and finally their solutions.
Reasons why LINE introduced data lineage
As a precondition for a company to make decisions based on reliable data, it's important to enhance the capability to recognize the status of its data system (data observability). Data lineage is positioned as one of the 5 pillars of data observability. Data lineage makes it possible to trace the path certain target data took from its generation to the present and the changes made on the path. Data lineage enables you to easily trace data errors and grasp data dependencies. In particular, it's getting difficult to grasp data lineages as data pipelines become more complicated with an increased amount of data and an increased number of related organizations in a data platform.
Also in IU, as shared at LINE DEVELOPER DAY (article written in Japanese) last year, we handled a large scale of data (for example, approximately 150,000 jobs are executed every day), and we faced the following challenges:
- Difficult to debug when a data generation job has failed
- When data generation jobs fail, we used to check the source code of the job and identify the table used for data generation to check whether a partition exists in the table.
- Difficult to determine the scope to be affected by a change to a table schema
- When changing table schema, we used to not only identify which tables would be affected but also examine their owners.
In order to tackle these challenges, we started developing data lineage.
Goals to be achieved with data lineage
To address the challenges faced by IU users as described above, we defined the following goals for introducing data lineage functions:
- To enable an efficient survey of data-related problems
- To facilitate a preliminary survey of effects brought about by data changes
Data lineage functions
Let me share the data lineage functions we actually developed for IU Web.
Table lineage
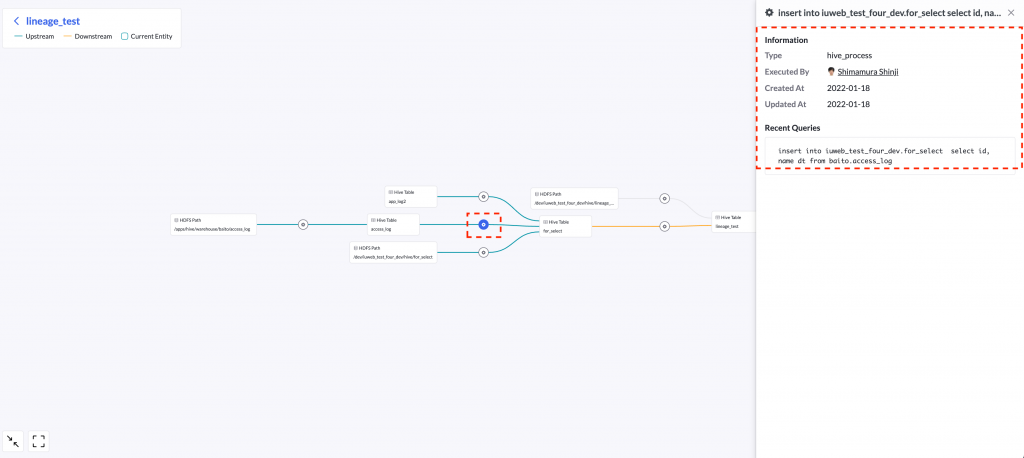
Table lineage lets you see the relationship of tables in a graphical form. If you select a table, metadata such as the owner and partition are displayed. The green arrow in the graph shows the path to the selected table after data generation (upstream). On the other hand, the orange arrow in the graph shows the dataset to be affected by changes to the selected table (downstream).
If you select a gear symbol, information related to the query that has executed data generation is displayed.

Column lineage
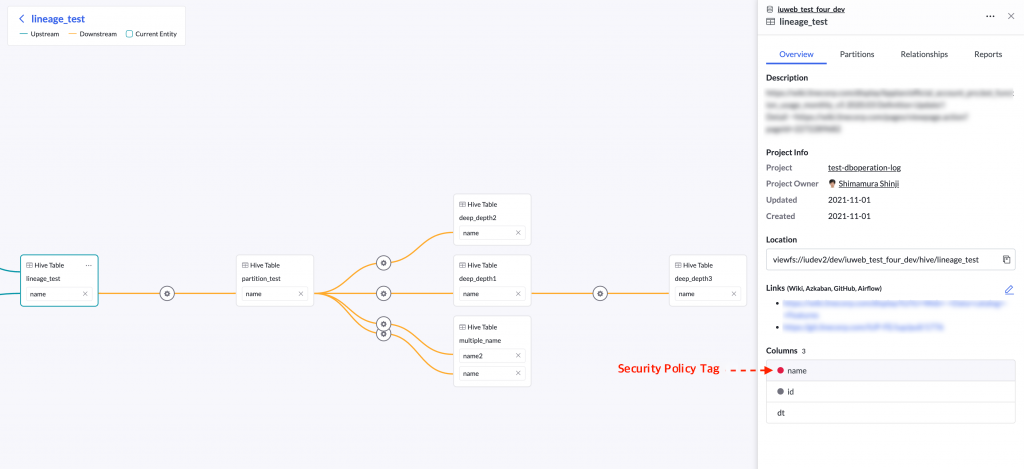
Column lineage shows the relationship of columns in a graphical form. This enables you to identify the scope to be affected by a change to a column and understand where columns with a high security level are used. For example, the diagram below shows the data lineage of a column named "name", which is marked with a red circle. This red circle means that a tag showing a high security level has been set for it.
Dashboard lineage
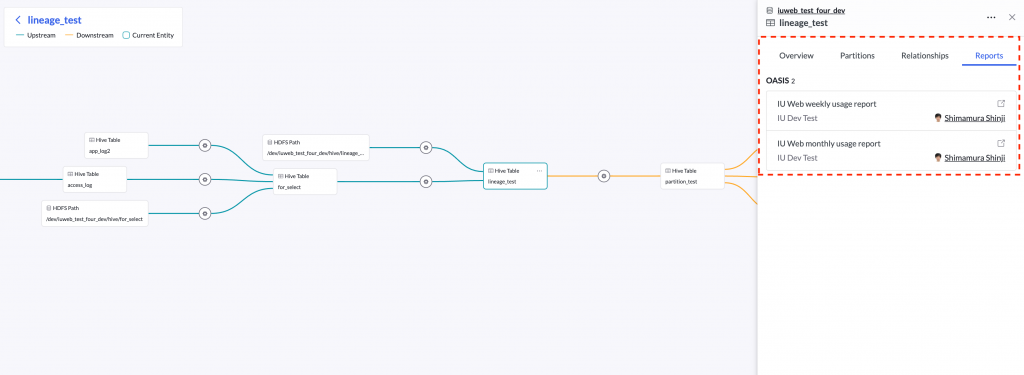
Dashboard lineage shows links to dashboards in OASIS, an internally developed reporting tool provided in IU, as table-related information. This function enables you to accurately grasp the data source and how data is used. it's also possible to know when a dashboard is affected when data is changed or a failure occurs, and refer to use cases of data.
Notification functions
Two notification functions are provided so that users can promptly detect abnormality of and changes to data.
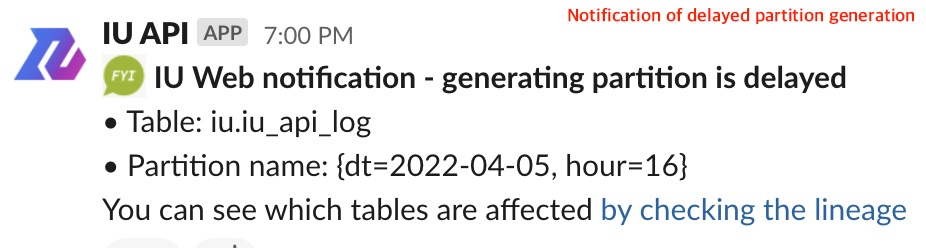
- Notification of delayed partition generation: Notifies a slack channel when a delay occurs in partition generation. Slack notification is linked to the data lineage of the table where partition generation has been delayed so that users can investigate efficiently where the delay has been caused in the data source.
- Notification of DB and table changes: Notifies when attribute information is updated, such as DB and table schemas, tags, and descriptions. Using data lineage, changes on the data generation path of a table for which notification has been set are also notified. This function enables you to recognize in a timely manner how changes will affect each operation and system.
System configurations
Next, let me share the system configurations for realizing the data lineage functions explained above.
Apache Atlas
Apache Atlas is used to acquire the relationship between tables, so let me explain first what Atlas is. Atlas is an open source data catalog, which stores metadata generated with data changes by Apache Hive, Apache Spark, etc. In addition to data lineage functions, it can also be used for metadata search, tagging, and authority management, among others.
Lineage system configurations
Currently, IU Web supports Hive lineage and dashboard lineage.
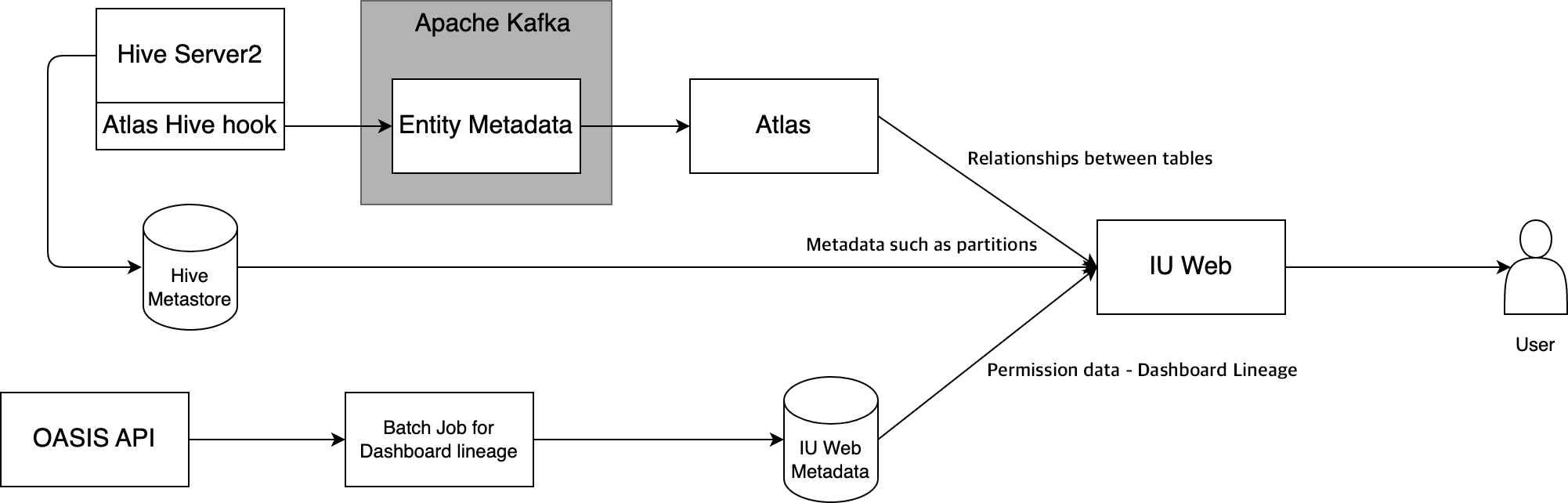
First, let me show the system configuration of Hive lineage. As shown in the figure above, Hive lineage places the Atlas Hive hook provided by Atlas on HiveSever2 and registers change operations on Hive with Atlas via Apache Kafka. IU Web obtains the relationship between tables with Atlas REST API. In the end, a data lineage is displayed by combining the data obtained from Atlas with authentication information and dashboard lineage information managed within the Hive Metastore and IU Web. Although lineage UI functions are also provided by Atlas, useful functions can be provided for users by adding information retained in IU Web and the Hive Metastore to information provided by Atlas.
As shown in the above functional description, dashboard lineages are linked to OASIS dashboards. This link to dashboards is realized by analyzing SQL queries included in them. OASIS supports two engines, Trino and Spark SQL. What's important here is how to associate SQL queries with the data catalog. IU Web uses official Trino and Spark SQL parser libraries to analyze SQL, extract tables contained in SQL queries, and save and use the correspondence between SQL queries and IU Web. As of May 2022, approximately 85,000 SQL queries are associated with tables.
Major challenges and how we addressed them
Problems with Apache Atlas performance
Performance problems occurred when the data lineages of specific tables were obtained with Atlas REST API. At first, API calls increased Atlas memory consumption, causing Atlas to hang up and become disabled unless restarted. These problems were corrected in cooperation with members from Cloudera, a partner of the Data Platform Division (ATLAS-3590, ATLAS-3558). However, even after the correction, API calls took approximately 30 minutes in specific tables, so we tried to improve the performance.
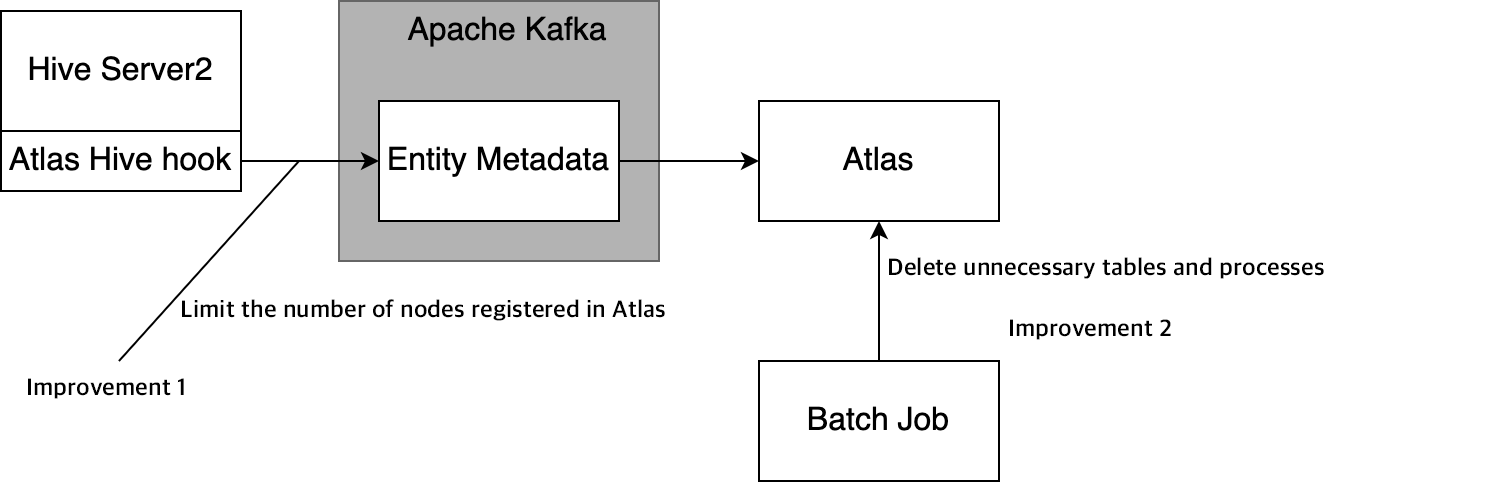
Our investigation of the reasons why the Atlas API took so long revealed that too many nodes in a data lineage graph caused its display to be delayed. In particular, we found that, with tables related to temporary tables generated by every hourly and daily job, nodes connected to them increased at every job execution, resulting in too many nodes in the graph. Therefore, we reduced the number of nodes in lineage graphs by applying the following two improvements:
- Suppressing the number of nodes to be registered from Hive with Atlas: Atlas Hive hook has a setting that disables registration with Atlas through filtering with regular expression (ATLAS-3006).By using this setting, we prevented tables containing strings used for temporary tables such as tmp from being registered with Atlas. This reduced the number of tables to be registered with Atlas by approximately 90%.
-
Removing unnecessary tables and processes from Atlas with a batch job: Although the above approach prevented registration of temporary tables, it added Hive Process nodes related to temporary tables at every job execution in specific tables, resulting in an increased number of nodes in lineage graphs. To address this problem, we introduced a batch job that removes Hive Process nodes connected to these temporary tables from Atlas. This batch job removes approximately 300,000 nodes every day.
As a result of introducing these improvements, the Atlas API execution time has been reduced to approximately 6 seconds or less in almost all cases and to 15 seconds or even less in worse cases.
Complicated data lineages
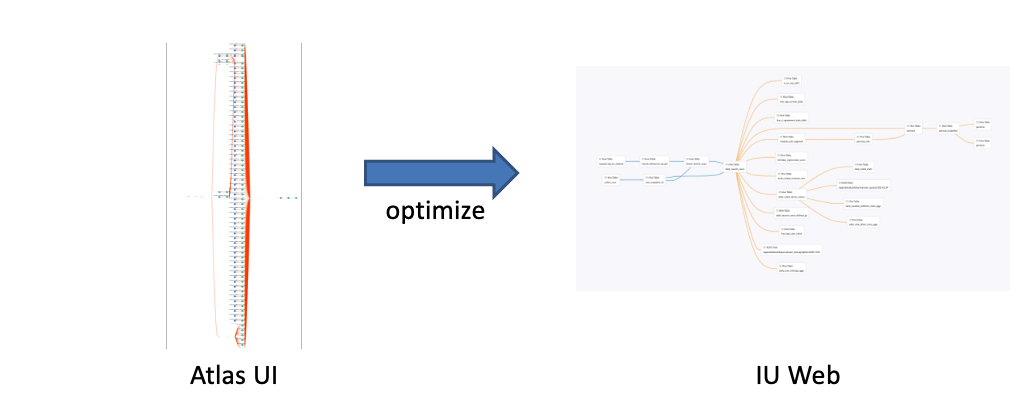
In some tables, too many data lineage nodes caused problems that made it difficult for users to confirm data generation paths they want to confirm. To address these problems, we implemented the following two optimizations for data lineages returned by the Atlas API in IU Web so that only data lineages necessary for users is displayed:
- Hiding columns when table lineages are displayed: In some data lineages, tables are connected directly to columns. The existence of a large number of nodes in a table leads to a large number of nodes. On the other hand, we also found that, if columns in table A and table B are related, there is a also a relationship between table A and table B. Accordingly, hiding columns will not remove the relationship between tables, so we determined to hide columns when table lineages are displayed.
- Hiding HDFS path nodes with a low importance: We determined to hide HDFS path nodes whose importance is assumed to be low, such as those including tmp in the path.
As a result, a data lineage that is complicated and difficult to understand on the Atlas UI is now simple and easy to understand on IU Web, as shown below.
Effects of introducing data lineage and how It's Used
Since the initial introduction of data lineage functions in November 2021, the number of users has increased gradually, and the functions are used in 79 services and departments as of May 2022. Data lineage is used by users who handle data every day, such as members in Data ETL, Data Management, and Data Science.
Specifically from the Data ETL team, we received feedback that it's now easier to confirm the scope affected during table maintenance (DROP TABLE or ALTER TABLE execution). In addition, from daily communication with IU users on Slack, we have confirmed that data lineage is used, for example, in investigating the causes of data errors.
Future plans
Since we have confirmed the effects of introducing data lineage, we are planning to add further functions related to data lineage. Let me share two functions out of several being planned:
- Expanding the scope to be traced with data lineage: In a short term, we aim to cover the most parts of data relationships in IU by newly supporting Apache Spark and Hive Metastore data lineages. In a longer term, we will make it possible to trace changes made outside IU as well. This will enable users to understand data relationships in a wider scope.
- Enhancing the security governance: Atlas can propagate data catalog policy tags through data lineages. With tag propagation, for example, by setting a tag assigned to personally identifiable information to a certain table (or column), the tag is automatically assigned also to tables that use the table. We aim to enhance the security by introducing functions such as notifications of tag propagation and tag setting, and setup of access rights using tags.
Conclusion
The IU Dev team offers opportunities to solve issues faced in building data catalogs for large-scale data platforms. We are recruiting people interested in support of data utilization by LINE employees or in data-related technical fields. While there are many issues we want to solve to promote further data utilization in our company, we don't have sufficient resources for it yet. If you are interested, we would like you to apply to our team through the following link. Let me also mention that experience related to big data is not a prerequisite (I had no experience when joining the company, either).