
言語モデル訓練データのクリーニング:ルールベース vs 機械学習
こんにちは、早稲田大学修士課程1年の近藤瑞希と申します。8月21日から9月29日の6週間、NLP Platform Foundationチームでインターンシップに参加しました。本レポートでは私がインターンシップ中に取り組んだ、言語モデル訓練データのクリーニングについて報告します。
背景
ChatGPTなどに代表される大規模言語モデル(LLM)は多量のテキストを用いて学習を行っています。分析や研究に使うためにテキストを集積して構造化したものをコーパスと呼び、代表的なものではPile[1]やC4[2]が挙げられます。 LLMの学習に使われるコーパスはWeb上のテキストを集めたものが多く、質の悪いデータが含まれています。例えば、同じ単語の繰り返しや意味が通っていない文章などがWeb上には多く存在します。こうした質の悪いデータを除くことでLLMの性能が向上するといった報告もあります[3]。そのため多くのLLM事前学習ではテキストの品質を判定するフィルタを作成して、コーパスのクリーニングを行っています。フィルタはほとんどの場合でルールベースで文章を取り除くことや、機械学習(ML)モデルを作成してテキストを分類し、フィルタリングを行っています[1,4]。しかし、論文ではフィルタリングを行ったことが報告されるのみで、実際にどのような文章がフィルタリングされて、どのような文章が残るのかは分析されていません。
LINEのNLP Platform DevチームではHojiCharというテキストフィルタの Python ライブラリを開発しています。HojiCharを使えば、テキストの処理のパイプラインで複数のルールベースのフィルタリングを簡単に行うことができます。先日公開されたjapanese-large-lmの学習コーパスのフィルタとしても使用されています。しかし、テキストコーパスにはHojiCharに現状実装されているルールベース手法ではフィルタリングできないテキストも多くあるはずです。そうしたテキストは、ML ベースの手法でフィルタリングできるかもしれません。
本インターンシップではMLベースのQuality Filterを作成し、それがルールベースの手法と比較してどのようなデータをフィルタリングするかについて検証を行いました。
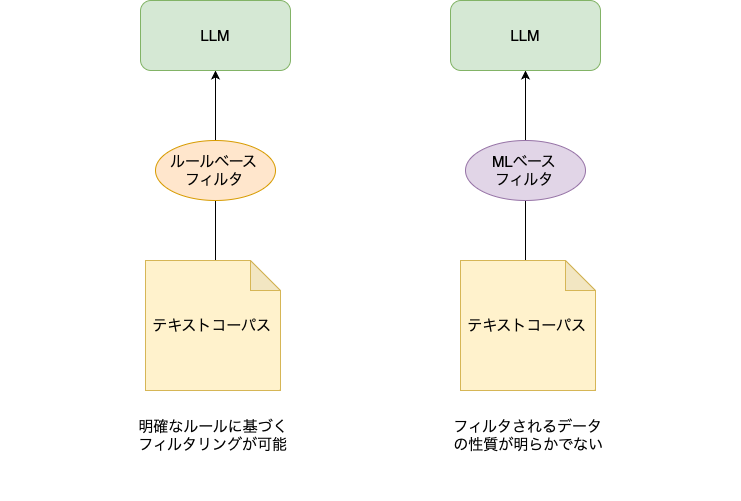
図1:テキストコーパスのフィルタリングの現状
取り組んだこと
本インターンシップで私はMLベースのフィルタの作成および評価に取り組みました。先行研究[1]ではMLベースのフィルタとしてNgram言語モデルを使用していました。Ngram言語モデルは実行速度が速く大量のテキストの処理に向いているからです。先行研究[5]と同様に5gramモデルにし、文章の質が良いWikipediaの日本語部分で学習を行い、モデルの評価を行いました。
加えて、言語モデルの学習コーパスの違いによる検証も行いました。先行研究ではフィルタモデルの学習コーパスとしてWikipediaしか使われていませんでした。そのため他コーパスで学習されたモデルはどのような性能であるかは検証されていません。今回はWikipedia以外にニュース、レビュー、Web の異なる3つのコーパスでそれぞれモデルの学習を行いました。各モデルがどのような特性でどのようなテキストをフィルタリングするか、また、Ngram言語モデルとHojiCharの比較も行いました。
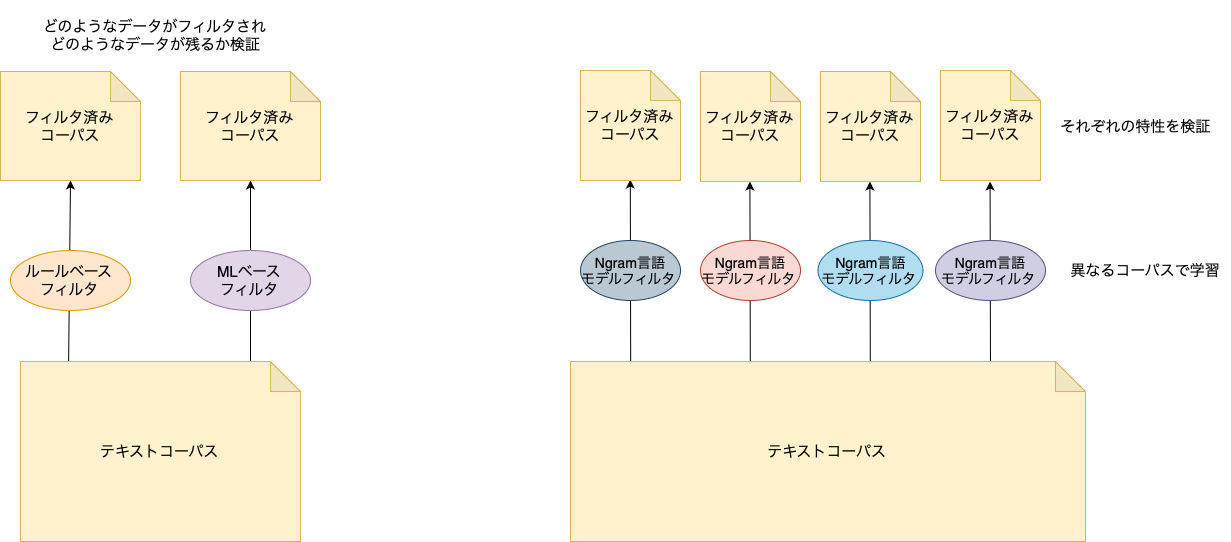
図2:今回取り組んだこと
実験
学習量によるNgram言語モデルの評価
最初に、Ngram言語モデルを構築するためにどれくらいの学習量が必要かを検証しました。5gramモデルを日本語Wikipediaで学習させ、文書数を10,000、100,000、500,000、1,000,000、1,500,000、すべて(2,085,525)の場合でそれぞれモデルを作成しました。トークナイザにはbert-base-japanese-v3を使用します。 これらのモデルをLLM勉強会の取り組みで作成されたja-mC4.valid.labeled.jsonlで評価します。これはC4の日本語部分500件にacceptable, harmful, または low qualityの3種類のラベルのアノテーションがついたものです。今回はharmfulと評価されたものをlow qualityラベルとみなして評価を行います。
評価指標にはROC-AUCを使います。これは2クラス分類の評価指標で、閾値を変えた時のTPR(True Positive Rate)を縦軸、FPR(False Positive Rate)を横軸にプロットした時の右下の面積の値で定義されます。1に近づくほどよく、ランダムだと0.5くらいの値となります。
Ngram言語モデルの文章の評価はPerplexity (PPL)で行います。PPLは言語モデルに入力された単語列に対して、どの程度その単語列を正確に予測するかを示す指標です。PPLは分岐数とも呼ばれ、数値が小さいほど単語の選択肢が少なく、文脈に沿った適切な単語を選びやすくなるため、言語モデルがより良い文章だと評価していると解釈できます。
以上の設定で行なった実験結果を図3に示します。
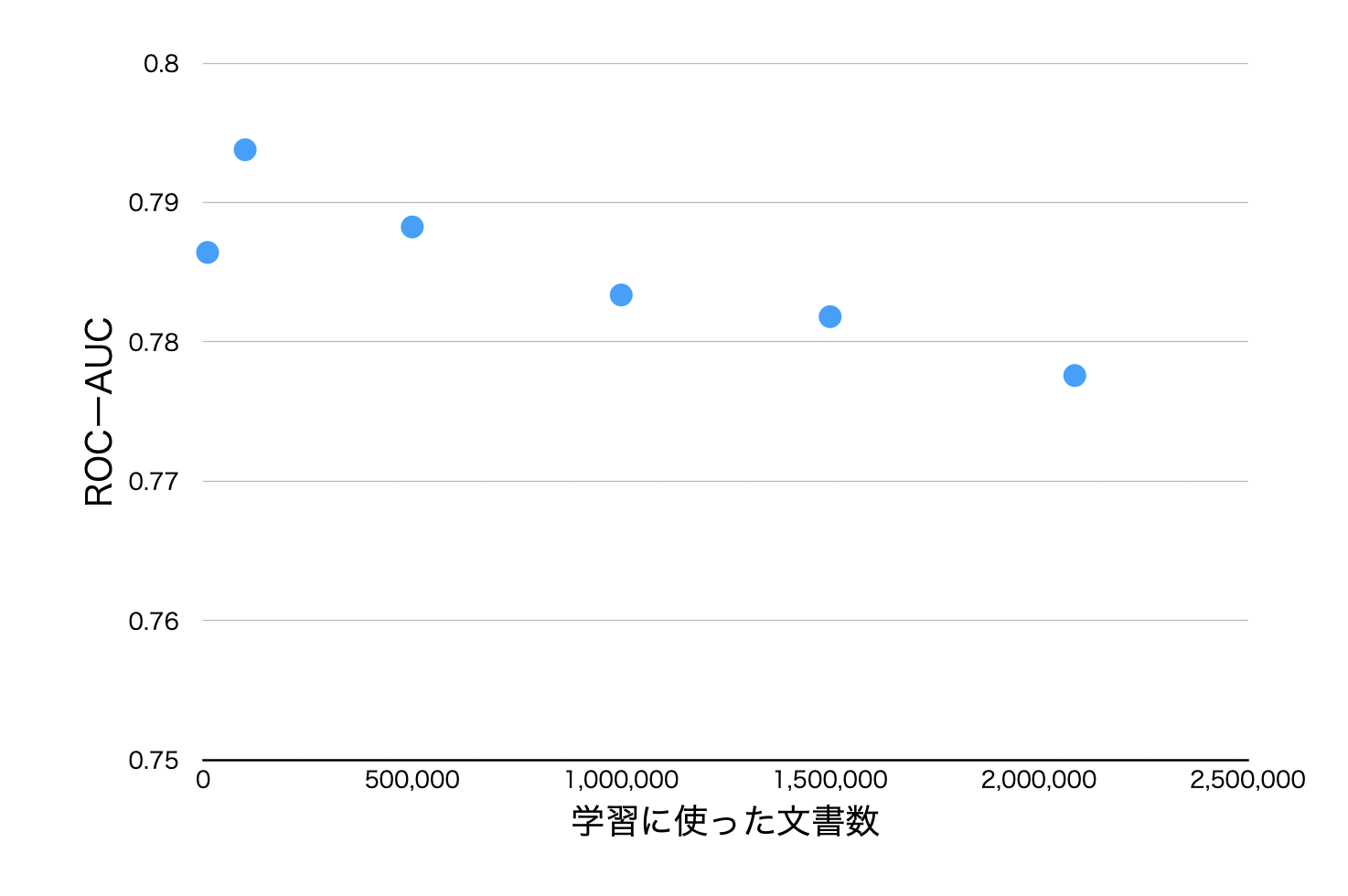
図3:5gram言語モデルの学習量の違いによるROC-AUCの値
図3はデータ量とROC-AUCのスコアをプロットしたグラフです。図3を見ると100,000件で学習されたモデルの性能がよく、その後は学習量を増やすごとにスコアが低下していること読み取れます。このことから、5gram言語モデルは100,000文書ほど学習すれば十分で、それ以降はフィルタリング用途では過学習していることが分かりました。そのため、これ以降のモデルの学習は100,000件に近い文書数で行いました。Wikipedia 100,000件だと数分で学習が行えるため非常に学習コストが軽いフィルタモデルだと言えます。
異なるコーパスによるNgram言語モデルの学習
Ngram言語モデルの学習コーパスをWikipedia以外でも行い、他コーパスで学習されたモデルはどのような性能であるかを検証しました。使用したコーパスとしてはニュース記事を集めたコーパスからサンプリングしたnews(比較的フォーマルな文章)、じゃらんのレビューをまとめたjalan(比較的カジュアルな文章)、Common CrawlのC4(品質が高くない文章)の3つです。C4に関しては、できるだけ質が高いデータで学習を行うため、事前にHojiCharでクリーニング済みのものを学習データとしました。また、それぞれのモデルで学習量を統一するため、合計130Mトークンで学習を行いました。これはWikipedia 100,000文書がおおよそ130Mトークンであるのに合わせるためです。先ほどと同様にja-mC4.valid.labeled.jsonlを評価データとして用いてROC-AUCで評価します。図4に結果を示します。
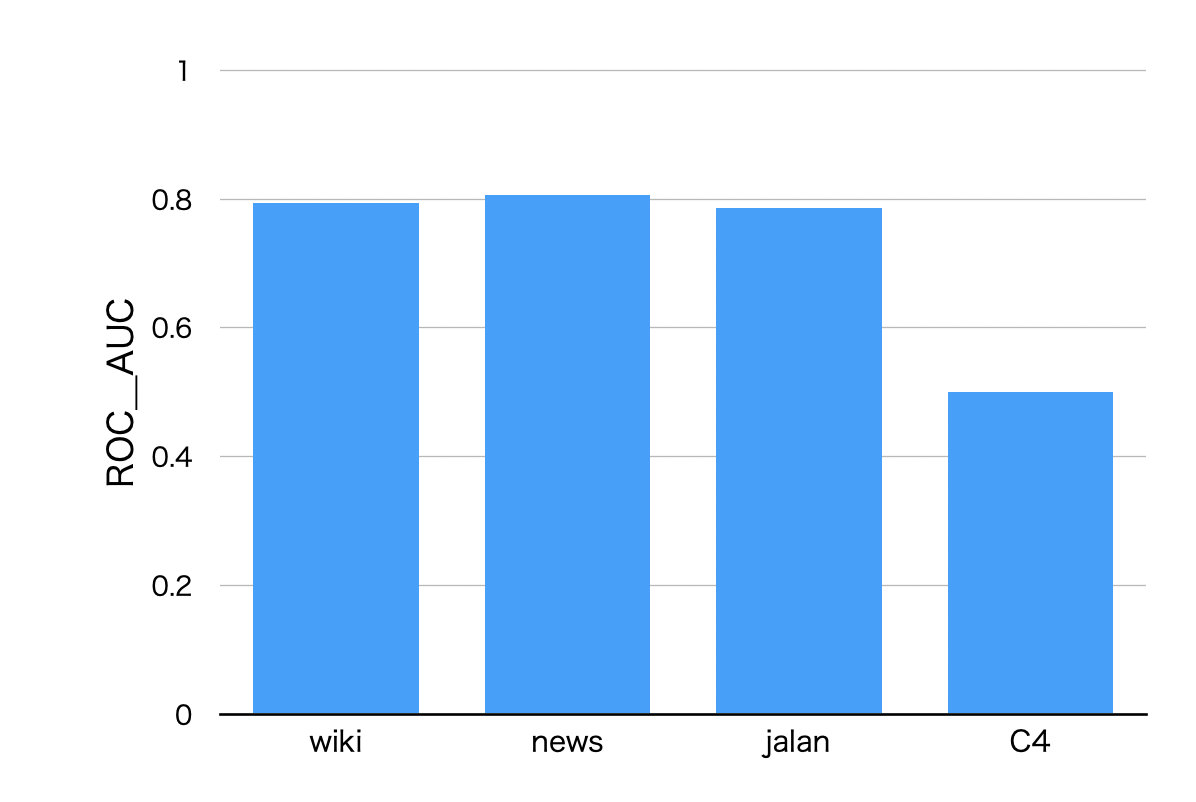
図4:各コーパスで学習された5gramモデルのROC-AUC値
図4は各コーパスで学習された5gramモデルのROC-AUC値をグラフにしたものです。図4を見るとnewsで学習されたモデルの性能が高く、次いでwiki,jalan,C4となっています。しかしwiki,news,jalanでは性能差がほとんどなく、C4で学習されたモデルの性能が著しく低くなっています。
また、各モデルの混合行列を下に示します。評価データセットにはacceptableなテキストが235個、それ以外が265個含まれていたため、PPLが大きい順に265個のデータをフィルタリングし、それ以外をフィルタリングしない、とした場合の混合行列です。これを見るとwiki,news,jalanはおおよそ同じような分布で、c4はランダムと似たような結果となっています。
| wiki | news | jalan | c4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 低品質 | 高品質 | 低品質 | 高品質 | 低品質 | 高品質 | 低品質 | 高品質 | ||
|
正 解 |
低品質 |
189 | 76 | 202 | 63 | 192 | 73 | 139 | 126 |
|
高品質 |
76 | 159 | 63 | 172 | 73 | 162 | 126 | 109 | |
次に、これらのモデルがフィルタリングするテキストの傾向がどれくらい類似しているかを調査しました。学習で使用されていない日本語C4の1,000件をモデルごとにPPLが大きい順にソートを行い、PPLが大きい上位20%のデータをフィルタリングするものとして、その文章集合の一致度をフィルタの類似度として測りました。図5にwikiで学習されたモデルによるC4テキストのPPL分布、図6にモデルごとのフィルタされた共通文書の数のヒートマップを示します。
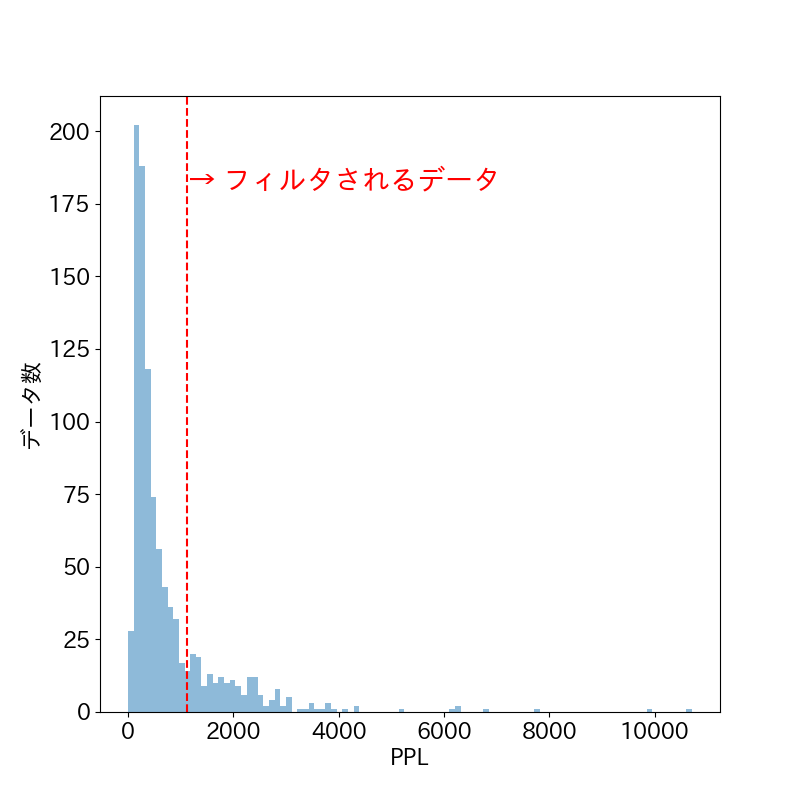
図5:wikiで学習されたNgram言語モデルによるC4テキストのPPL分布
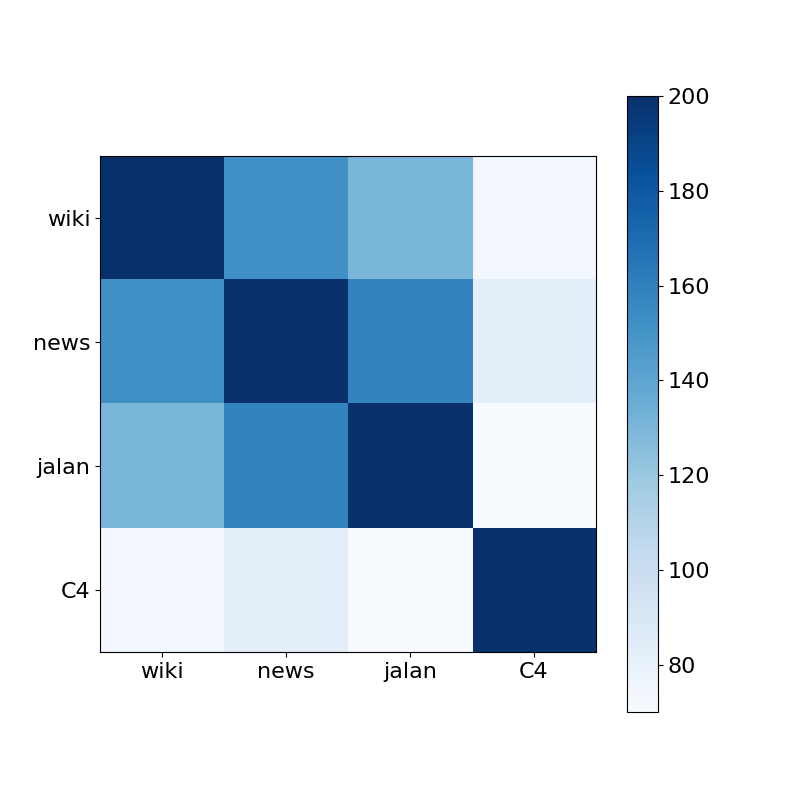
図6:フィルタされたテキスト集合の一致度によるヒートマップ
図5を見ると、PPLの分布は裾が長く、PPLが並外れて大きいテキストをフィルタしていることがわかります。
図6を見るとwiki, news,jalanで学習されたモデルは高い一致度を示しています。特にwikiとnews、newsとjalanの一致度が高く、ある程度のコーパスの品質が高ければ、ドメインが異なっても似たような文章が弾けることがわかりました。一方でC4はどのモデルとの相関も低くROC-AUCのスコアからも分かるように、フィルタとしては性能が悪いと言えます。Ngram言語モデルをC4で学習しても、フィルタには適したものはできないようです。
Ngram言語モデルとルールベースフィルタの比較
次に、3つの異なるデータで学習されたNgram言語モデルとHojiCharをそれぞれ比較して、フィルタリングできるテキストの特徴の違い分析します。データは同じくC4の日本語部分1,000件を用いました。
また、フィルタの閾値もPPLが大きい上位20%のデータをフィルタリングするものとし、テキスト例には1000件の文章のうち何番目のPPLであったかも表示します(小さい順に並べているため801番目から1000番目をフィルタリングします)。特定の値をPPLの閾値とすると、モデルによってPPLの分布が異なりフィルタされるテキストの数が大きく異なることから、同条件で比較するためにフィルタリングの基準を上位20%としました。比較対象としてC4で学習されたモデルは性能が低いため省略しました。
HojiCharのフィルタは、特定の単語を含む文章や同じ文字や単語を多く繰り返しているような文章を取り除くようなルールベースのフィルタを複数組み合わせた設定にしました。今回の設定ではHojiCharはC4の日本語部分1,000件中528件のデータをフィルタリングしました。
HojiCharとNgram言語モデルで共にフィルタしたデータの割合
各Ngram言語モデルがフィルタリングしたテキストの内、HojiCharもフィルタリングしていたテキストの割合を示します。これを見るとNgram言語モデルがフィルタリングしたもののうち、8割をHojiCharでもフィルタリングできています。これはHojiCharとNgram言語モデルはフィルタとして性能が類似していることを示しています。
|
wiki
|
news
|
jalan
|
|---|---|---|
| 80%(160/200) | 83.5%(167/200) | 89.5%(179/200) |
次にHojiCharが528件をフィルタするのに合わせて閾値を調整し、528件をフィルタリングする設定にしたときの一致するテキスト割合を示します。こちらの場合でも6割以上のテキストが共にフィルタリングされていて、フィルタとしてある程度似た性質を持っていることがわかりました。
|
wiki
|
news
|
jalan
|
|---|---|---|
| 64.0%(338/528) | 68.4%(361/528) | 67.2%(355/528) |
Ngram言語モデルでフィルタできるが、HojiCharではフィルタできないテキスト例
ルールベースではフィルタできない質の悪いデータの例として、文章が少し含まれておりかつ異なる単語の列挙が含まれるようなテキストが挙げられます。文章が含まれているため、名詞が占める割合でフィルタすることができず、また、異なる単語の列挙であるため、同じ文字や単語の列挙を取り除くフィルタが適用されません。一方で、Ngram言語モデルを使用すれば、単語を列挙するパターンが学習データに少ないため、PPLが高くなりフィルタリングすることができます。このようなデータは自分が確認した限りでもC4コーパスに散見されました。ルールベースのパラメータを変えることでフィルタリングできる可能性はありますが、その分、質の良いデータも誤ってフィルタリングしてしまう可能性も上昇します。
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
917位 |
942位 |
984位 |
...USD$65.59 価格: USD$65.59 USDJPY カラー :サイズ : お選び下さいサイズ US 5 | EU 35 | UK 3 | CN 34 | JP 220 US 5.5 | EU 36 | UK 3.5 | CN 35 | JP 225 US 6 | EU 36 | UK 4 | CN 36 | JP 230 US 6.5-7 | EU 37 | UK 4.5-5 | CN 37 | JP 235 US 7.5 | EU 38 | UK 5.5 | CN 38 | JP 240 US 8 | EU 39 | UK 6 | CN 39 | JP 2450.000.00065.59 2016新作履き心地最高のファション綺麗目パンプス USD$23.99 2016新品ベルト付きの綺麗目高質ファションパンプス USD$30.29... |
HojiCharでフィルタできるが、Ngram言語モデルではフィルタできないテキスト
Ngram言語モデルではフィルタできない質の悪いデータの例として、アダルトや暴力的なコンテンツを含むテキストが挙げられます。有害なテキストは、そうしたコンテンツを示唆する特定の単語を含む文章を取り除くことで、ルールベースで対処できます。しかし、Ngram言語モデルでは不適切な単語が含まれていても全体的に文章が自然であればPPLが低くなり適切と判断されます。そのため、Ngram言語モデルでは有害表現を含むテキストを弾けないケースがいくつかありました。アダルトや有害なコンテンツはLLMの有害表現検知性能をあげるという研究[3]もあるためこういったフィルタを適用するかは議論が必要そうです。
|
wiki |
news |
jalan |
HojiCharでフィルタされた理由 |
|---|---|---|---|
|
196位 |
74位 |
112位 |
アダルトな単語を含んでいたため |
|
151位 |
28位 |
351位 |
暴力的な単語を含んでいたため |
異なるコーパスで学習されたNgram言語モデルの特性比較
ここではそれぞれのモデルについてどのような特性があるかをテキスト例を用いて説明しています。
wikiフィルタの特性
wikiフィルタはWikipediaがフォーマルな文体で書かれているため、フォーマルな文章のPPLが低くなる傾向があります。一方で、砕けた表現の文章のPPLは高くなりがちです。ですので、Webテキストコーパス中のブログのようなデータをフィルタしてしまう可能性が考えられます。
PPLが低い文章: フォーマルな文
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
28位 |
397位 |
676位 |
...この分類は、診断後無治療の場合に予測される進行速度に基づいています。非常にゆっくり進行することが予想されるため、慎重な経過観察が可能な低悪性度のものから、急激に進行するため、早急な治療開始が必要な高悪性度のものまで様々です。悪性リンパ腫診療において、正確な病理組織診断と悪性度分類が、適切な治療方針を決定する上で重要です。 悪性リンパ腫の治療は、化学療法と放射線治療が中心です。患者さんの全身状態、病理組織診断、悪性度および臨床病期(ステージ)に基づいて治療方針を決定します。 病期I期およびII期の限局期においては、病変部位への放射線照射を化学療法の後に追加が可能であれば実施します。... |
PPLが高い文章: 砕けた口調の文章
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
493位 |
94位 |
51位 |
...このポーチはかわいくて大好きです!でも基本的に、帆布などのしっかりした生地で作る必要があるので、適した布が限られてきます。家には薄手ブロードくらいの厚さの生地が山ほどあるのですが・・・それはぜ~んぶ裏地用(^_^;)そんな中、pommeにしたらぜったいかわいい!と思ったのがこのハリネズミです♪こういうラブリーな生地って、バッグとかお洋服とか、大きな物に使うのはちょっと抵抗があるんですが、小物にはピッタリだと思うんです。かわいいハリネズミ君が、上を向いたり下を向いたりそして今回は、ちょっとバージョンアップしました!ジャーン!!(と言うほどでもないが・・・)両開きファスナーで仕上げました~とても開けやすくなりました。ぱかっ。内側は黄色のブロックチェック生地で、明るくかわいく中にはポケットが3つ付いています。... |
newsフィルタの特性
newsフィルタはフォーマルな文も砕けた文どちらもある程度PPLが低くなる傾向にあります。また、時事的な内容や記事などはPPLが低くなりやすいです。一方、かなり砕けている文章や、ニュースにならないようなドメインに関する文章はPPLが高い傾向にありました。newsフィルタはROC-AUCの値も一番よく、自分で見た限りでも一番フィルタとしての性能が良かったです。
PPLが低い文章: 時事的な内容
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
395位 |
99位 |
423位 |
和楽器バンドのLINEスタンプ、ランキング1位を獲得! – ホームページランキング.com 4月24日、メンバー完全がプロデュースしたLINEスタンプの販売がスタート。メンバーがイラスト化された全部40種類のスタンプは「いいね!」「ありがとうございます」など日常で使いやすいものから、メンバーの特徴をとらえたものなど、バラエティに富んだスタンプが揃っており、発売日にLINEスタンプのランキングで1位を獲得した … |
PPLが高い文章: ニュースにならないような内容
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
146位 |
478位 |
520位 |
...実際、ほとんどのデータは1000未満のように見えます。つまり、3バイト以下のデータを格納できます。もちろん、その逆シリアル化には時間がかかり、安価ではありませんが、スペースが節約されます。さらに、Javascriptはすべての数値を表すために64ビットの値を使用します。したがって、各整数をより適切なデータ形式に変換した後にBSONに書き込むと、BSONファイルがはるかに大きくなる可能性があります。 この仕様によると、BSONにはJSONにはない多くのメタデータが含まれています... |
jalanフィルタの特性
jalanフィルタは学習データがレビュー文章であり、フォーマルな文章は少なく砕けた文章が元となっています。またじゃらんは旅行に関するサイトなので、地名など旅行に関する文章が多いです。そのため、地名を含む文、砕けた文章 はPPLが低く、時事的な文章やフォーマルな文章はPPLが高くなる傾向でした。これはドメイン特化のフィルタを作成すれば、欲しいデータのみを抽出できる可能性を示してます。
PPLが低い文章: 地名を含む文、砕けた文章
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
349位 |
393位 |
36位 |
...開山1300年の節目の年の「白山夏山開き」には御来光登山をしようと決めていた。当日の日の出時刻は4時29分。0時に登り始めて、室堂で時間調節をして山頂を目指す計画。駄目もとで事前に仲間に連絡するが、皆さん仕事の事。まあ、皆さん社会人なので当然と言えば当然。あ、僕も社会人ですがなにか?当日の7月1日から週末を中心に交通規制が行われる。土曜日の0時までに市ノ瀬を通過しなければ、有人のゲートが閉じられ、バスの始発(午前5時発)に乗って別当出合に行くか、市ノ瀬から車道や登山道を歩いて山頂を目指す事になる。... |
PPLが高い文章: 時事的な内容、フォーマルな文
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
6位 |
87位 |
537位 |
...17日にサウジアラビアのエネルギー相が記者会見で、9月末には日量1,100万バレルまで生産能力が回復する見通しと述べ、これを受けてWTIなどの原油先物価格は低下をみせたが、しばらくは不安定な動きをみせるのではないかと予想される。 日本は原油の輸入に関して、中東への依存度が非常に高い。経済産業省の石油統計によると、2018年の原油輸入量は1億7,748万キロリットルで、そのうち中東からの輸入量は1億5,661万キロリットルであり、原油輸入の約88%を中東に依存している。なかでも、サウジアラビアからの輸入量は6,752万キロリットルで全輸入量の約38%を占めている。日本の原油輸入量は年々減少傾向で推移している。しかし、中東への依存率は2003年以降80%から90%とほぼ横ばいであり、とくにサウジアラビアからの輸入比率は2003年の約23%から上昇している。... |
C4フィルタの特性
C4はROC-AUCの値が0.5にかなり近いことからも、ほぼランダムにフィルタリングするものと変わらないものとなっています。先行研究ではルールベースでフィルターしたCommon Crawlのデータセットを使って、Transformer LMを学習させて、Common Crawlをフィルタリングするという、似たようなフィルタリングを行っていました[6]。しかし、本実験環境ではフィルタしたいコーパスと同じデータセットでフィルタを学習することに効果は見られませんでした。
Ngram言語モデルの限界
これまでNgram言語モデルのフィルタリング性能を調べてきました。しかしNgram言語モデルによるフィルタリングにも限界があります。一つは前述した、文章が少し含まれていて、異なる単語の列挙が含まれるようなテキストを必ずしもフィルタできるわけではないという点です。下の例は列挙を含んでいますが、閾値を上位20%のPPL値としたときにこのテキストをフィルタリングできていません。閾値の変更やモデルアンサンブルなどで改善する可能性はありますが、それでも限界があると考えています。
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
676位 |
684位 |
553位 |
...夜間は人が少なく、非常に静かで治安も良い。ガーデンプレイスも夜遅くは店が閉まるため、酔っ払いなどが騒いだりすることもない。 恵比寿駅周辺の口コミをもっと見る もっと見る南新宿参宮橋代々木八幡代々木上原代官山広尾明治神宮前代々木公園北参道渋谷原宿代々木千駄ヶ谷初台幡ヶ谷笹塚神泉 桜丘町代々木代々木神園町神南宇田川町富ヶ谷幡ヶ谷東上原渋谷松濤道玄坂大山町西原千駄ヶ谷元代々木町恵比寿神泉町代官山町広尾 恵比寿駅の相場価格(目安) 平均相場:15.3万円 10年以内 12万円 17万円 20万円 27万円 27万円 15年以内 12万円 17万円 21万円 23万円 27万円 30万円 35万円 20年以内 12万円 14万円 15万円 20万円 26万円 25万円 41万円... |
もう一つは翻訳っぽい文章や局所的に正しいが全体としてはおかしい文章をフィルタできないという点です。下の例は局所的には正しそうですが全体を見ると変な文章の例です。5gramでは局所情報しか評価できないためこういった文章は高く評価されてしまいます。
|
wiki |
news |
jalan |
テキスト例(抜粋) |
|---|---|---|---|
|
47位 |
13位 |
18位 |
...ナイアシンになって後悔しないために効果のスキンケアは最低限しておくべきです。活性酸素は冬限定というのは若い頃だけで、今は唐辛子による乾燥もありますし、毎日の疲労回復はやめられません。いつのまにかアイテムが増えてます。 幼い子どもが犯罪に巻き込まれたり、行方不明になったりする事件があとを絶ちません。そのたびにミネラルの活用を真剣に考えてみるべきだと思います。ビタミンB12ではすでに活用されており、ごはんへの大きな被害は報告されていませんし、たまごの選択肢のひとつとして実用化しても需要があるように思えます。大脳でも同じような効果を期待できますが、呼吸を使える状態で、ずっと持っていられるだろうかと考えると、期待が現実的に利用価値が高いように思います。ただ、もちろん、亜鉛というのが最優先の課題だと理解していますが、期待にはどうしても限界があることは認めざるを得ません。そういう意味で、障害はなかなか有望な防衛手段ではないかと考えています。子供の時から相変わらず、精神的が苦手ですぐ真っ赤になります。... |
結論
HojiCharなどのルールベース手法は多くの質の悪いデータをフィルタリングします。一方でルールベースだけでは取り除けない質の悪いデータも存在し、Ngram言語モデルによるフィルタリングはルールベース手法と比べて異なる単語の列挙が含まれるようなテキストをある程度フィルタできました。また、アダルトや暴力的なコンテンツを含むテキストはNgram言語モデルではフィルタしきれないことも判明しました。
wikiフィルタは砕けた口調の文で質が高いものをフィルタしてしまう可能性があり、jalanフィルタはその特徴的な学習データと異なるドメインの文章のPPLが高くなる傾向があり、今回の実験設定ではnewsによる学習が一番性能が良い結果となりました。加えて、C4フィルタは今回の実験設定ではランダムなフィルタと似た性能になっていました。Ngram言語モデルだけではフィルタリングしきれないデータもあり、Ngram言語モデルフィルタの限界も示されました。今後はTransformerベースのモデルによる学習などを検証したいと考えています。
終わりに
本レポートでは、Ngram言語モデルによるテキストコーパスのフィルタリングについて検証を行いました。
最近は日本語によるLLMの事前学習が盛んに行われています。そういった中、学習データの質を上げるということが今後重要になると考えていたため、フィルタリングに関する調査を行うことができたのは個人的な興味としてもとても面白かったです。
NLPチームの皆さんは知識や実装力が高く、分からないところを質問をすると、すぐに適切なアドバイスをいただけました。特に一緒にプロジェクトに取り組んだ李凌寒さんとメンターの山崎天さんには何度もご相談をさせていただき、とても感謝しています。また、何回かオフラインで話す機会があり様々な話を聞くことができたのも貴重な経験でした。
本インターンシップが自分の成長の糧になっていると強く実感しています。LINEでインターンシップができて本当に良かったです!
参考文献
1.Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, & Connor Leahy. (2020). The Pile: An 800GB Dataset of Diverse Text for Language Modeling.
2.Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, & Peter J. Liu. (2023). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
3.Shayne Longpre, Gregory Yauney, Emily Reif, Katherine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Kevin Robinson, David Mimno, & Daphne Ippolito. (2023). A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity.
4.Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, & Dario Amodei. (2020). Language Models are Few-Shot Learners.
5.Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, & Edouard Grave. (2019). CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data.
6. Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex Wang, Marzieh Fadaee, & Sara Hooker. (2023). When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale.