
こんにちは。
LINEのNLP Foundation Devチームの清野舜と高瀬翔とoverlastです。
LINEでは2020年11月から日本語に特化した大規模言語モデル「HyperCLOVA」の構築と応用に関わる研究開発に取り組んできましたが、この「HyperCLOVA」と並行するかたちで複数の大規模言語モデルの研究開発プロジェクトが進行しています。
今回はそれらの研究開発プロジェクトのうち、我々を含むMassive LM開発ユニットから、日本語言語モデル「japanese-large-lm(ジャパニーズ ラージ エルエム)」をOSSとして公開できる状況になりましたので、本ブログを通じてお伝えすることにしました。
この記事では、我々が訓練・公開した36億(3.6 Billion)および17億(1.7 Billion)パラメータの日本語言語モデル(以下、 それぞれ3.6Bモデル、1.7Bモデルと呼びます) を紹介しつつ、途中で得られた言語モデル構築のノウハウを共有します。
使い方
1.7Bモデル、3.6Bモデル共にHuggingFace Hubの以下のURLにおいて公開しており、transformersライブラリから利用可能です。
ライセンスは商用利用も可能なApache License 2.0としましたので、研究者の方だけではなく、企業の方にも様々な用途でご利用頂けます。
- https://huggingface.co/line-corporation/japanese-large-lm-1.7b
- https://huggingface.co/line-corporation/japanese-large-lm-3.6b
以下のようなコードで生成を試すことができます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, set_seed
model = AutoModelForCausalLM.from_pretrained("line-corporation/japanese-large-lm-3.6b", torch_dtype=torch.float16)
# float16は指定しなくても問題ありません
tokenizer = AutoTokenizer.from_pretrained("line-corporation/japanese-large-lm-3.6b", use_fast=False)
# use_fast=False は必ず付与してください。なくても動きますが、我々の学習状況とは異なるので性能が下がります。
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
set_seed(101)
text = generator(
"おはようございます、今日の天気は",
max_length=30,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=5,
)
for t in text:
print(t)
# 下記は生成される出力の例
# [{'generated_text': 'おはようございます、今日の天気は雨模様ですね。梅雨のこの時期の 朝は洗濯物が乾きにくいなど、主婦にとっては悩みどころですね。 では、'},
# {'generated_text': 'おはようございます、今日の天気は晴れ。 気温は8°C位です。 朝晩は結構冷え込むようになりました。 寒くなってくると、...'},
# {'generated_text': 'おはようございます、今日の天気は曇りです。 朝起きたら雪が軽く積もっていた。 寒さもそれほどでもありません。 日中は晴れるみたいですね。'},
# {'generated_text': 'おはようございます、今日の天気は☁のち☀です。 朝の気温5°C、日中も21°Cと 暖かい予報です'},
# {'generated_text': 'おはようございます、今日の天気は晴天ですが涼しい1日です、気温は午後になり低くなり25°Cくらい、風も強いようですので、'}]この日本語言語モデルの特徴
超大規模&高品質な訓練データの活用
大規模かつ高品質なデータは性能の良い言語モデルの学習には必要不可欠です。
今回、モデルの訓練にはLINE独自の大規模日本語Webコーパスを利用しています。
Web由来のテキストにはソースコードや非日本語文のようなノイズが大量に含まれているため、フィルタリング処理を適用し、大規模かつ高品質なデータの構築をおこなっています(フィルタリングにより品質を向上させる効果については後述します)。
なお、フィルタリング処理にはNLPチームのメンバーが開発したOSSライブラリの HojiChar を利用しています。
最終的な学習には約650GBのコーパスを利用していますが、英語の大規模コーパスとして一般的に用いられているもの(Pileコーパス)が約800GBであることを踏まえると、我々のデータも遜色ない大きさであると言えます。
効率的な実装の活用
大量のデータを言語モデルの学習に取り入れるためには、相応の計算資源だけではなく、計算機を効率的に利用するためのテクニックとその実装が必要不可欠です。
我々は、3D ParallelismやActivation Checkpointingといったテクニックを駆使することによって、ミニバッチサイズを巨大化し、モデルの学習を高速化しています。これらは例えばMegatron-DeepSpeedに実装されています。
本モデルの構築に要した時間について、例えば1.7BモデルについてはA100 80GBで換算し、約4000GPU時間を費やしています。学習時間は特に日本語の大規模言語モデルの学習では公開されていないことが多く、適切な比較はできませんが、例えば rinna 0.3Bモデルの学習はV100 32GBで約8600GPU時間を費やしているようで、費やした時間に比して効率の良い学習が行えていると考えられます。
HyperCLOVAとは異なるモデル構築プロセス
今回の日本語言語モデルはHyperCLOVAとは別の開発ラインで並行して構築してきたもので、LINEのMassive LM開発ユニットが一貫して構築を担当しています。
LINEの大規模言語モデルの構築・運用・応用に関する全ての経験や知見を反映して、良質な日本語向けの事前学習済みモデルを継続的に構築します。
学習したモデルの性能
学習したモデルの性能評価として、開発データでのPerplexityスコア(PPL)および、質問応答・読解タスクの正解率を計測しました。PPLはコーパス中に出現する単語をモデルがどの程度正確に予測できたかを示す値で、小さいほど性能が良い、すなわち、正確に予測できていることを表します。なお、モデルのPPLとモデルをfinetuningしたときの性能には相関があることが経験的に示されており(例:Switch Transformers論文のAppendix E)PPLが良いモデルはfinetuning時の性能も良いことが期待されます。
PPLの計測にはC4データセットから開発データとして作成したものを使用し、質問応答・読解タスクについてはAI王 〜クイズAI日本一決定戦〜で配布されている開発データおよびJSQuADの開発データを用いました。質問応答・読解においては、AI王ではZero-shotで、JSQuADについてはStability AIによるevaluation-harnessの実装を利用し3-shotの設定で評価しました。
PPLと正解率を以下の表に記します。参考として2023年7月現在、日本語言語モデルとして広く使われているであろう、Rinna-3.6B(rinna/japanese-gpt-neox-3.6b)とOpenCALM-7B(cyberagent/open-calm-7b)の性能も記しています。また、日本語と英語のバイリンガル言語モデル(rinna/bilingual-gpt-neox-4b)の性能も記しました。
|
モデル名 |
パラメータ数 |
C4 (PPL) |
AI王(正解率) |
JSQuAD(正解率) |
|---|---|---|---|---|
|
1.7B |
8.57 |
32.2 |
57.50 |
|
|
3.6B |
7.50 |
48.5 |
63.85 |
|
|
3.6B |
8.18 |
48.6 |
50.09 |
|
|
3.8B |
8.83 |
43.0 |
52.72 |
|
|
6.9B |
11.87 |
35.4 |
48.13 |
上記から、我々の1.7BモデルはOpenCALM-7Bと同等かタスクによっては良い性能を達成し、3.6BモデルはRinna-3.6Bと同等かタスクによっては良い性能を達成可能なことが分かります。
訓練データの品質を向上させる効果について、Webコーパスに多く存在する非文や重複している文、日本語以外の言語の文書の除去などを行うことで、上記のような定量指標での性能と生成する文の品質が向上します。
訓練データにこのようなフィルタリングを行わずに学習した場合、例えば「千葉県船橋市の一戸建てを売る 千葉県千葉市中央区の一戸建てを売る 千葉市花見川区の一戸建てを売る 千葉市稲毛区の一戸建てを売る…」というような繰り返しを多く含む文や非文を生成しやすくなってしまいます。
大規模言語モデル学習Tips: 安定した学習で良いモデルを得るために
パラメータの初期値について
モデルサイズを大きくした場合、学習を安定させるためにはモデルパラメータの初期値を小さくしておく必要があります。
今回はBigScienceのレポートを参考に、(2.0 / (隠れ層の次元数 * 5)) ** 0.5 という値を採用しています。
また、一部のパラメータについてはモデルの層の数に応じて初期化した方が良いという議論がGPT-2の論文やMegatron-LMの論文でなされており、今回はMegatron-LMで行われている層の数に応じた初期値のリスケーリングを採用しました。理論的な正当性は不明ですが、Megatron-LMの採用しているリスケーリングは経験的に他の初期化よりも性能が高い傾向を確認しています。
Adam の beta2 について
今回のモデル構築では広く利用されているAdamを使っています。
Adamには学習率の他にbeta1, beta2というハイパーパラメータがあり、beta2は大きな値に設定すると性能は上がるが学習は不安定になりやすく、小さい値に設定すると学習は安定するが性能は上がりづらい(=学習の進みが遅くなる)という性質があります。Adamの論文で採用されているbeta2の値は0.999ですが、これを使っていると下記のように損失が跳ね上がることがままあります。
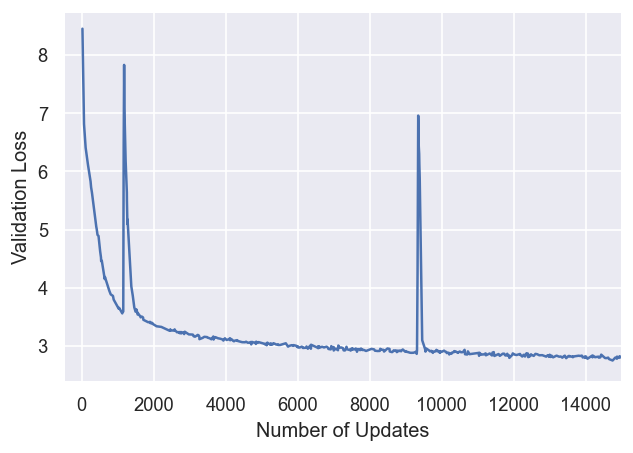
上記の例では更新回数を増やした際に、運良く損失が低い値に戻ってきていますが、このまま発散して学習に失敗する場合もあります。
これを防ぐためにデフォルト値よりも小さな値を使っています。Transformerの論文では0.98が使われており、大規模言語モデルの学習ではBigScienceの試行錯誤での議論にもあるように0.95が使われることが多いようです。
学習率について
学習率は高いほど学習が早くなる(=性能が高くなる)のですが、損失が発散する可能性も高まります。
いくつか既存の設定を見てみた所感としては、Megatron-LMの1.5e-4という設定がこの規模のモデルの学習にはちょうど良さそうです。
Metaの公開している大規模言語モデル、LLaMAの論文においては13Bパラメータのモデルまでは3.0e-4の学習率を用いていますが、我々の手元ではそこまで高い学習率を用いた場合には発散してしまいました。モデルの仕様や訓練データをどの程度クリーニングしているかによっても傾向が変わると考えられますが、主に英語コーパスを用いた際の学習率よりも低い値に設定した方が経験的には安定します。
学習率のスケジューラについて
Transformerの論文では更新回数の逆平方根で学習率を変化させる手法が採用されていましたが、大規模言語モデルの学習ではCosineスケジューラが広く使われています(例:Chinchillaモデルの論文)
経験的には以下のような傾向があり、同一の学習率、かつ学習に失敗しなければCosineスケジューラの方が優秀です。
- 更新回数の逆平方根:学習率が急激に下がり、学習の安定性が高いが最終的な性能はCosineよりも低い
- Cosineスケジューラ:逆平方根の場合と比較して相対的に学習率が高い時間が長いため、損失が発散する可能性の高い時間が長い。その一方で、学習に成功した場合には性能が高い
おわりに
今回公開しました1.7B、3.6Bの日本語言語モデルを皆様に広く使って頂ければ幸いです。
また、これらのモデルについて、指示文に対して適切な出力を行えるようにチューニング(Instruction tuning)したモデルを近日中に公開予定です。続報は@LINE_DEVをフォローしてお待ち下さい。
LINEは今後も構築したモデルの一部を継続的に公開しますので、どうか楽しみにお待ちください。