
はじめに
こんにちは、東京大学大学院学際情報学府修士1年の野田栞穂と申します。2023年8/21~9/29の6週間、LINE株式会社の就業型インターンシップにサーバサイドエンジニアとして参加させていただきました。Data platform室のIU Devチームに配属され、LINE社内のData CatalogにOpenAI APIを利用したAI アシスタントシステムの導入を目指すというプロジェクトを行いました。
本記事では、そのプロジェクトの内容について報告します。
背景
IU Webとは
LINEでは、データ利活用を促進するため、社内のデータをまとめて管理・処理できるInformation Universe(IU)というデータプラットフォームが構成されています。そして、IUのData Catalogとして開発されているのがIU Webです。IU Webでは、「データの民主化」というスローガンを元に、誰もがデータのアクセス・活用がしやすいことを目指しています。
機能としては以下のようなものが挙げられます。
- データの説明や意味などのメタデータやデータ同士の関係をまとめる。
- データの検索・可視化機能を提供することで、社内で蓄積されている膨大なデータの中から必要なデータを参照しやすくなる。
IU Webで提供されているキーワード検索機能が一番利用されており、IU Webがユーザが欲しいデータを探す目的で頻繁に活用されていると考えられます。
IU Webにおける潜在的課題
現状のIU Webにおける検索機能はある程度データを探すというニーズに応えられています。しかし、キーワード検索のみでは限界があり、Database (DB)やTableを検索・利用する際に、そもそもそれらに精通していないとIU Webをうまく活用できないといった潜在的課題もあります。具体的には、以下のような場合が考えられます。
- DB名・Table名を正確に覚えていないと、検索機能で探すことができない。
- 各DB・Tableがどのような情報を持つかなどをしっかりと把握していないと求める情報にアクセスするのが難しい。
- IU Web上では各Tableに対してSQLクエリを走らせることで簡易的なTable操作ができるが、DBにあまり詳しくない人にとっては即座にクエリを作るのが難しいため、データ操作のハードルが高い。
目的
本プロジェクトでは、これらの潜在的課題を対し、あまりIUの前提知識がない人も所望のデータを探すことを可能にすることを目的としています。これにより、更なる「データの民主化」の実現に繋げることができると考えられます。
その目的のため、大規模言語モデル(LLM)を活用したAI アシスタントシステムの導入を目指しました。近年、Data CatalogはLLMとの相性が良いことが知られており、先進的なData Catalog SaaS (例: atlan, metaphor)でもLLMを活用したAI アシスタントシステムの導入が行われています。
具体的なAI アシスタントシステムの機能は以下の通りです。
- 自然言語で気軽にData Catalogに関して質問することができる。
- 曖昧な表現によるDB・Tableの検索ができる。
- データに関しての説明やTable操作についても助言してくれる。
完成したシステム
今回完成したシステムは以下のようなものです。
AI アシスタントはIU Web内の右下からいつでも起動でき、チャットアプリ形式で様々な質問を投げかけることができます。Data CatalogのDB/Tableについての様々な質問に対応できます。
- 特定のデータがどこにあるか尋ねる

- データの説明を聞く
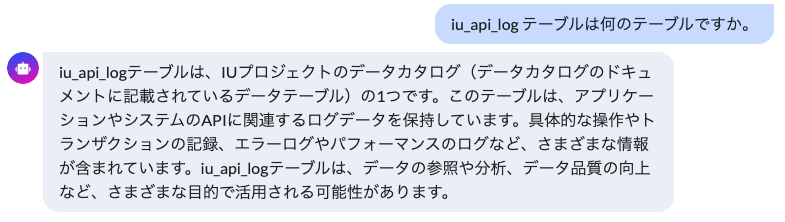
- 操作クエリを尋ねる
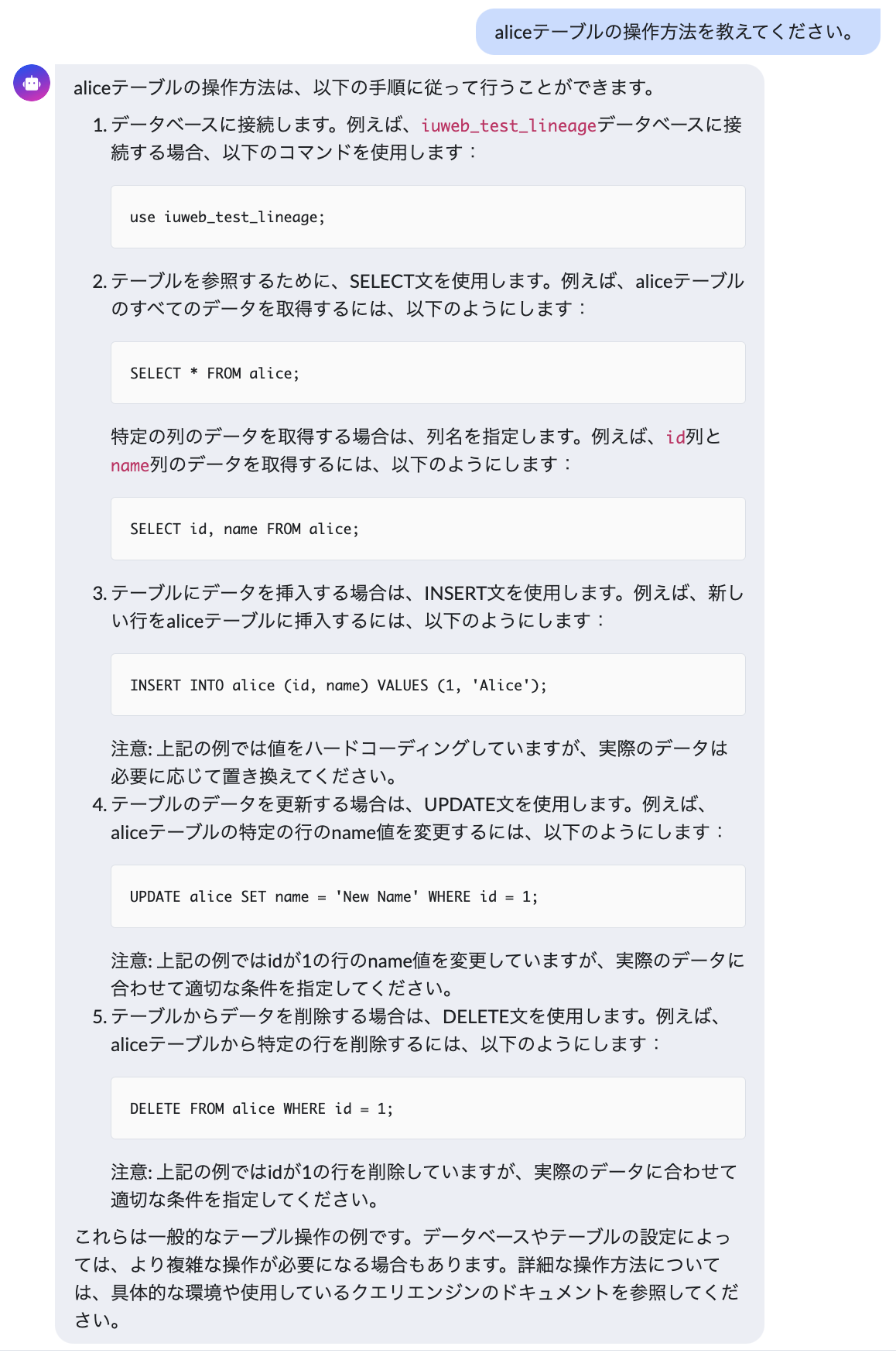
設計
ChatGPTを用いたデータ検索
Embeddings-based search method
AI アシスタント実現のため、OpenAI社が提供する対話型のインターフェース、ChatGPTを利用していきます。ChatGPTは大量のテキストデータを用いて学習されており、ユーザの問いに対して文脈を理解した上で自然なテキストで回答をしてくれるAIです。
皆さんの中でも普段からChatGPTを利用し、基礎知識からプログラミングのコードまで分からないことを質問したり、文章の要約などを行っている方も多いのではないのでしょうか。また、モデルを構築し直したり再学習させることなく、Promptと呼ばれるChatGPTに対する指示文を工夫することで、特定の分野に特化させたり、任意の方式で回答を得られるように促すことも知られています。
今回は、OpenAI APIを介してそのChatGPTの機能をうまくIU Webのシステムに組み込むことで、LINEのData Catalog情報に特化したAI アシスタントシステムを構築していきます。LINEの親会社であるZ HoldingsとOpenAIは業務締結しており、社内でも安全にOpenAIのサービスを利用することができます。(参考)
しかし、ChatGPT自身は広く多くの一般的な情報を持っている一方、IU Webのドメイン知識は持っていません。そこで、ChatGPTにIU Webに特化した質問を答えてもらうために、今回はEmbeddings-based searchと呼ばれる手法を用いていきます。
この手法では、Embeddingという文や単語などの自然言語の構成要素に対して、何らかの空間におけるベクトル表現に変換したものを用います。このembeddingは、基本的に近い意味を持つものを近いベクトル表現にするように定められています。OpenAI社によるAPIの中にも、自然言語をEmbeddingに変換するモデルが提供されています。
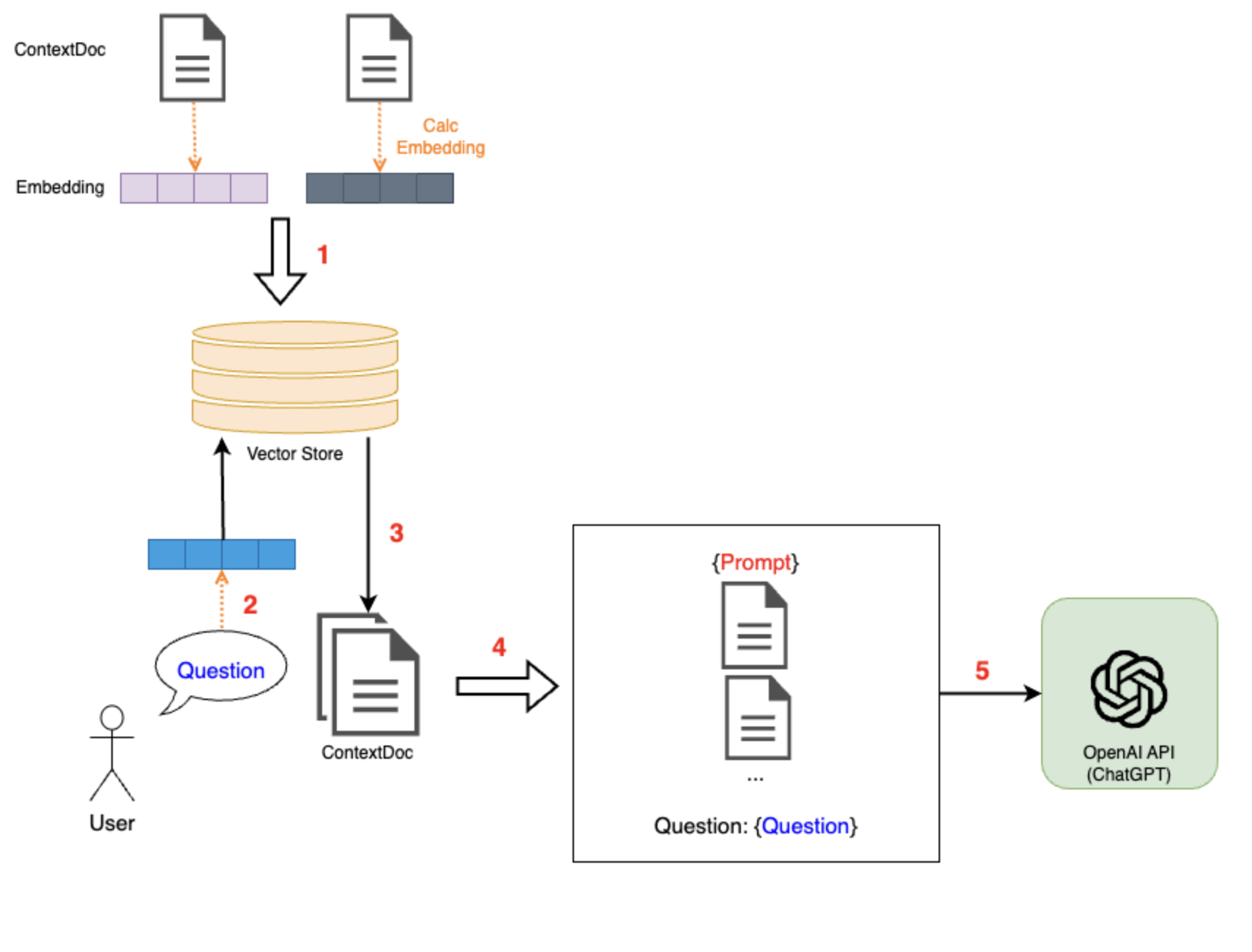
具体的なアルゴリズムは以下の通りです。
- 根拠となる情報源を分割し、それぞれ1つのドキュメント(ContextDoc)としてまとめ、それぞれのContextDocから求めたEmbeddingをVector Storeに保存してくおく。
- ユーザからの質問に対し、その質問文のEmbeddingを求める。
- ユーザの質問のembeddingを基準に、Vector Storeでベクトル検索を行う。そして、類似度の高いEmbeddingを持ついくつかのContextDocを選択する。
- 適切なPromptとともに、手順3で取得したContextDocの内容とユーザの質問をchatの内容としてまとめる。
- まとめた内容をChatGPTに送る。
他手法との比較
既に既存のChatGPTを、特定のシステムや領域に特化させるようにする手法としては、上記で挙げたEmbeddings-based search method以外に、Few-shotやFine-tuningといった方法があります。下の表にそれぞれの手法の説明と特徴をまとめます。
|
Embeddings-based search method
|
Few-shot
|
Fine-tuning
|
|
|---|---|---|---|
| 手法 |
|
|
|
| 利点 |
|
|
|
| 欠点 |
|
|
|
ここで、今回の目的ケースでは以下のような要件が求められます。
- LINE社内では大規模で様々なデータが使われており、Data Catalogの情報は頻繁に更新される。 → 即座に最新の更新情報に対応できる。
- データの検索や説明・Tableの操作方法の説明など多岐の用途に対応したい。 → 決まった形式での返答ではなくユーザのニーズに合わせて柔軟な回答ができる。
以上の比較を踏まえると、今回の目的ケースでは最新の情報や様々なニーズの質問にも対応できるのが好ましいと考えられます。したがって、本プロジェクトではこのEmbeddings-based search methodを採用しました。
ContextDocとembeddingの作成フロー
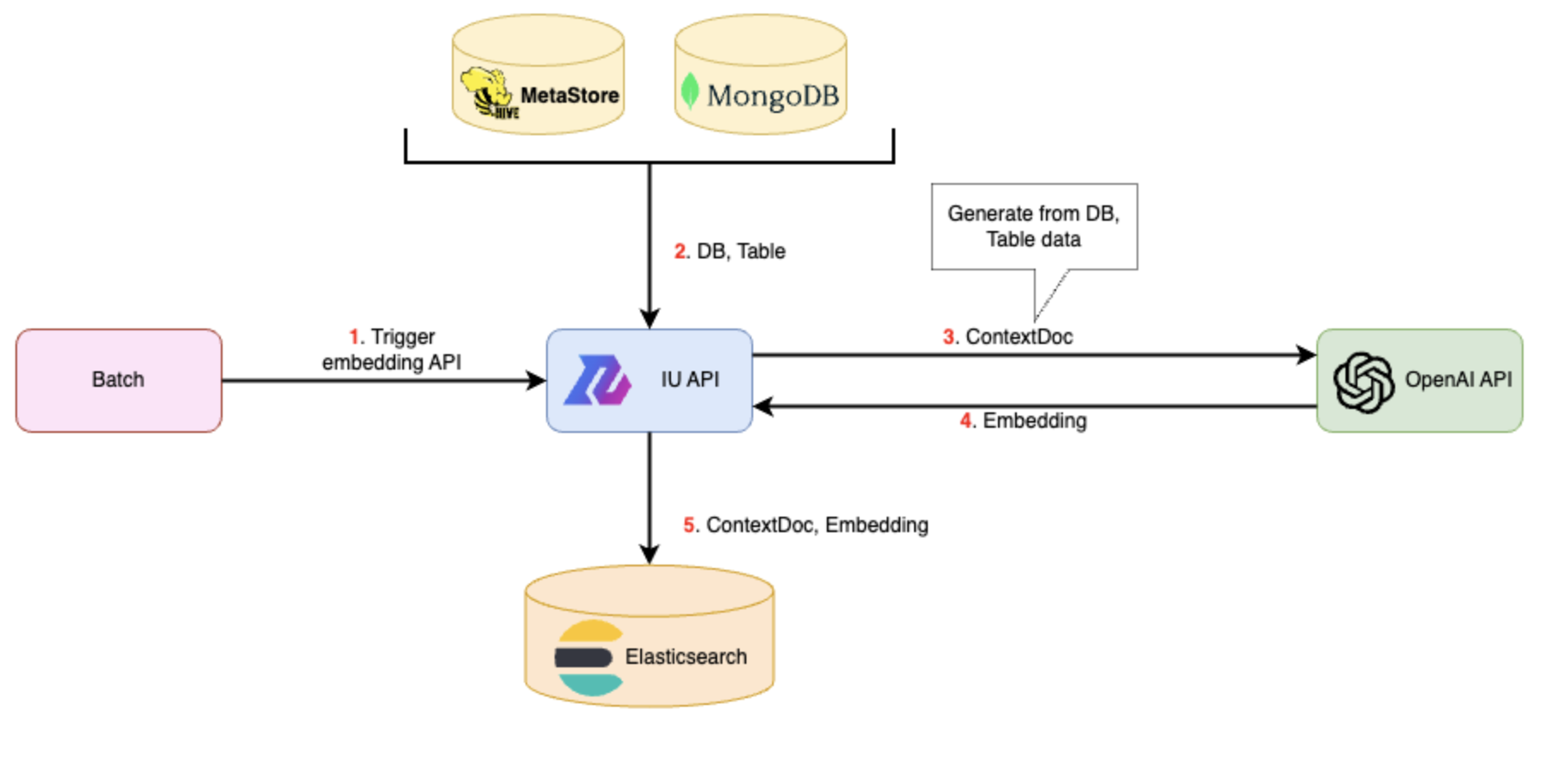
まず、あらかじめDBやTableの情報からContextDocを作成し、そのEmbeddingを専用のDB (Vector DB)に保存しておきます。そのために、IU WebのAPI(IU API)にContextDocとEmbeddingを作成するためのAPIを作成します。
このIU APIにリクエストが送られたときのIU APIサーバの処理の流れは以下の通りです。
- DB、Tableの情報が入ったmetadata DBにアクセスし、必要な情報を取得。これらの情報はHiveのMetaStoreサービスやMongoDBなどに保存されています。
- 取得した情報からContextDocを作成。
- OpenAIのCreate embeddings APIにリクエストを送る
- ContextDocのEmbeddingを取得
- ContextDocとEmbeddingをともにVector DBに保存する。
今回、Vector DBとして、Elasticsearchを利用しました。Vector DBとは、データをベクトル形式で保存し、検索するための特殊なDBシステムです。このVector DB機能がElasticsearchでも提供されており、高速でベクトルの最近傍探索(k-NN)が可能となっています。(参考)
ユーザからの質問への回答フロー
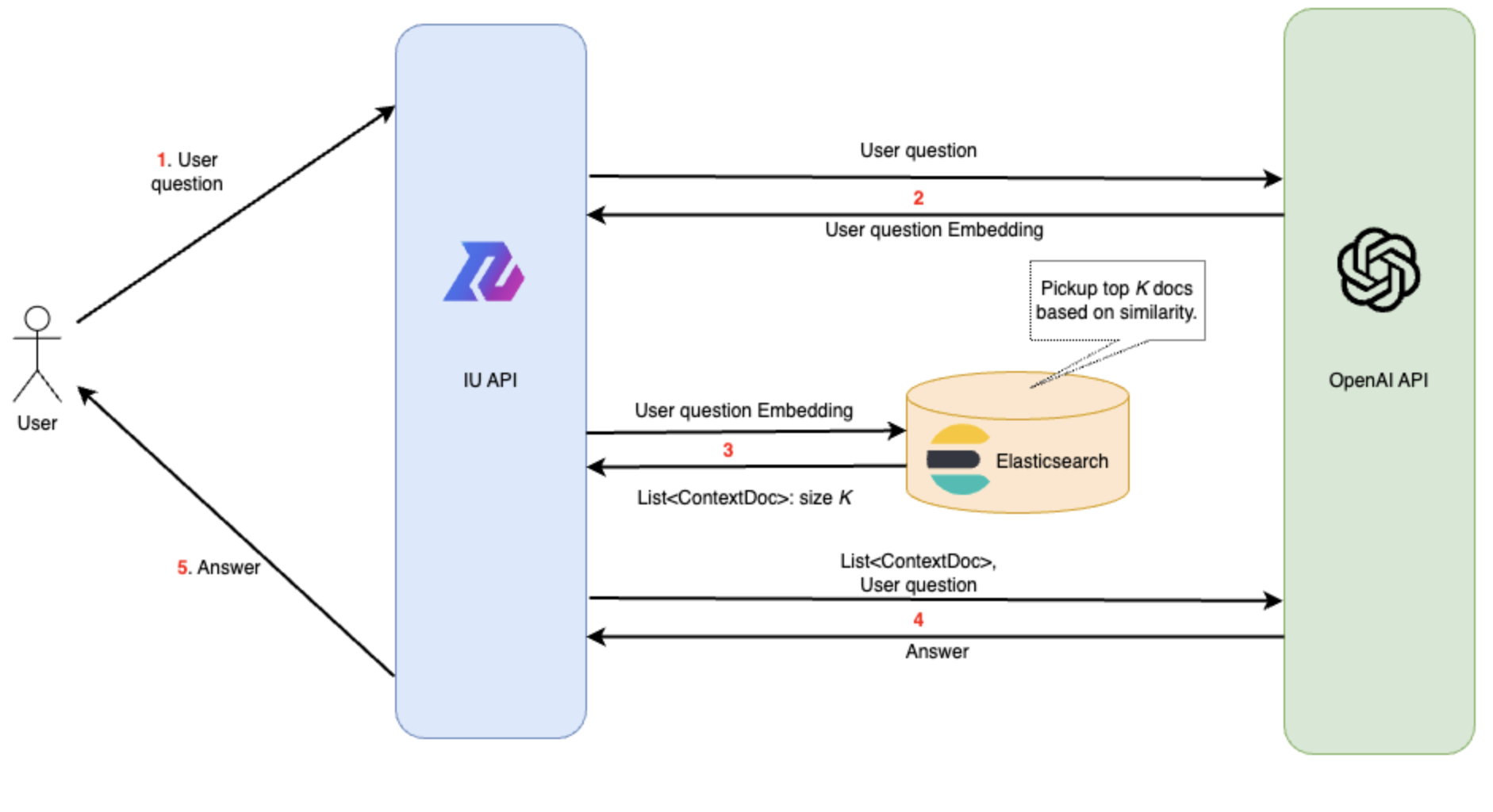
次に、ユーザの質問に対し、適切なContextDocを選び、ChatGPTに送信して回答を得るフローについては以下のようにしました。
- ユーザがIU APIにリクエストを送る。
- IU APIサーバからOpenAIのCreate embeddings APIにリクエストでユーザの質問を送り、Embeddingを取得。
- ユーザの質問のEmbeddingを元に、Elasticsearchでk-NNを行い、類似度が高いEmbeddingを持つtop K個のContextDocを取得する。
- ユーザの質問と手順4で得たContextDocを内容を共にOpenAIのCreate chat completion API (ChatGPT)に送り、ChatGPTによる回答を得る。
- 得られた回答をIU APIサーバからIU Web APIサーバを介してユーザに送る。
実装
API
APIの実装方法を記載します。APIは、フレームワークはSpring Boot、言語はJavaで実装されています。
ContextDoc, Embeddingの作成
各DB、TableについてのContextDocとEmbeddingを作成し、それらを保存するAPIを作成しました。
このAPIでは、リクエストで指定されたDBまたはTableに関しての情報を取得し、ContextDocの形にしていきます。ContextDocはMarkdown文書の形にまとめることにしました。下に一例を載せます。
データベースのドキュメント例
# DataBase: [database_name](database_url)
- description: {description}
- owner project: [project_name](project_name)
## tables
|name|field1|field2|...|
|---|---|---|...|
|{table1}|{field1}|{field2}|...|
|{table2}|{field1}|{field2}|...|
...Markdownの形式にした理由としては、ChatGPTへの入力をMarkdownの形式で行うことで、自動でMarkdown形式で返答してくれる可能性が高くなると考えたからです。実際に、完成した例を見てみると、ChatGPTからの返答はMarkdownとなっており、埋め込みURLや表、リストなどの表現を踏まえて分かりやすい返答を返してくれています。
ユーザの質問への返答
Promptの構成方法
次に、本プロジェクトのメインとなる、ユーザの質問に答えるAPIについてです。APIでは、ユーザの質問を受け取ると、以下のようにChatGPTに渡す入力を作成します。
(system) {High priority command (例: データカタログに関する質問に答えてください。)}
(user) {Description of information (例: 下記の私たちのデータカタログに関するドキュメントを使ってください。もし、データの中に答えがなければ、「分かりません。」と書いてください。)}
Document: {K ContextDocs}
Question: {ユーザの質問}ユーザの質問と共にPromptとContextDocsの情報を送信することで、情報をChatGPTが元にユーザの質問に答えてくれます。
ここで、本プロジェクトで一番大きく工夫した点である、Chatの実現方法について説明していきます。
Chatの実現
今回のシステムでは、従来のChatGPTと同様にChat、すなわち以前の会話内容を踏まえて次の会話を続けていくことが可能にしています。まず前提として、サーバをステートレスに保つため、Chatの履歴はフロント側で保存しておき、APIのリクエスト時に履歴ごと送信してもらう設計にしました。これはOpenAIのCreate chat completion API (ChatGPT)へのリクエストでも使われている方法を参考にしています。
次に、ChatGPTの方に対してChatの履歴の送信を行うのですが、このときの履歴の構成方法に考慮するべき点がいくつかあります。
- token数制限への対応
- OpenAI APIでは、会話履歴+レスポンスの合計token数に上限があるが、精度を上げるためにできるだけ多くのContextDocsをメッセージ内に含める必要があり、すべての履歴をChatGPTに送信するのが難しくなります。
- ContextDocsは会話の中のどの部分を基準として選択するのか。
- Embeddings-based search methodでは、回答の精度がPrompt内でChatGPTに含めるContextDocsの情報に大きく左右されるため、選択の基準となるユーザの質問内容が重要です。
- ユーザの最新の質問のみを基準として利用することを考えた場合、適切なContextDocsが選択されるとは限りません。これは、ユーザはAIが以前の会話も踏まえた上で返答をくれることを期待しているため、最新の質問は前の文脈を踏まえて「1つ目のデータベースについて教えて」といった簡潔で曖昧な表現の質問が来る可能性があるからです。ContextDocs選択の基準となるテキストをどのように構成するのかを考える必要があります。
- PromptとContextDocsは会話の履歴の中のどこに挿入するか。
- ChatGPTに入力するChat履歴の中には、ChatGPTに適切に回答を行ってもらうため、どこかにPromptとその情報源とするContextDocsを必ず含めなければいけません。ここで、自然なChatと行うために会話の流れも保つ必要があるため、履歴の中でPromptとContextDocsの挿入場所も考慮しなければいけません。
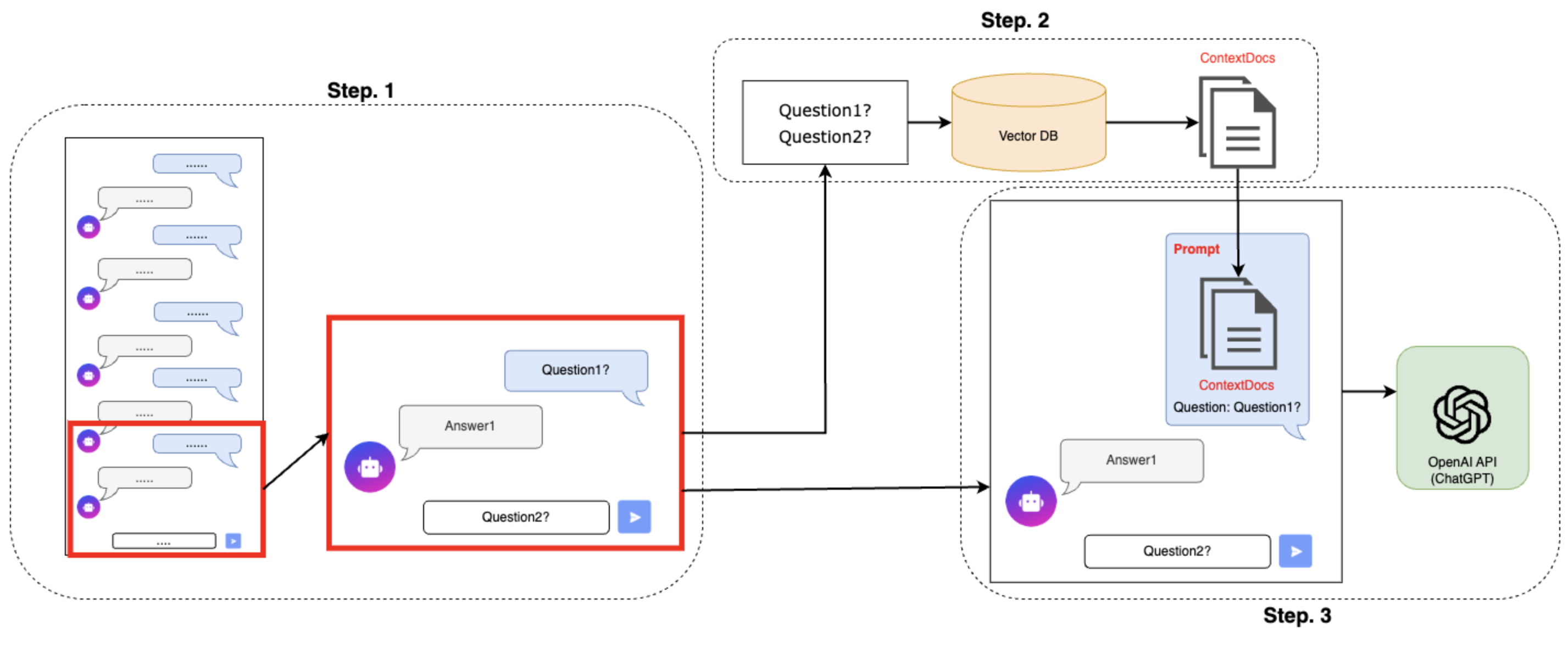
そこで、これらの課題を全て考慮しつつ、Chatが実現できる方法を考えました。具体的なChatGPTへの履歴の構成方法のイメージ図を下に示します。
Step.1 必要な履歴分だけを抽出
token数制限に対応するため、Chat履歴を必要な分だけ抽出します。具体的には、リクエストで受け取ったChat履歴の中から、最新の履歴からとあるtoken数 M以内に収まる範囲だけ遡って抽出します。ここでtoken数 MはChatGPTのtoken数制限より小さい数を表します。後に挿入するPromptやContextDocsのtoken数、ChatGPTからのレスポンスのtoken数などを考慮した上でパラメータ Mをあらかじめ定めておきます。
また、履歴の一番初めは必ずユーザからのメッセージとなるように抽出範囲を定めます。
Step. 2 ユーザの質問からContextDocsを選択
抽出された履歴の中からユーザからのメッセージを全て抽出し、一つのテキストとしてまとめます。複数のメッセージを統合することによって、それらの文脈を踏まえたContextDocsを適切に選択することができると考えられます。
次に、まとめたテキストのembeddingを計算し、そのembeddingを元にk-NNにより類似度が近いembeddingをもついくつかのContextDocsを取得します。
Step. 3 ChatGPTへの入力を作成
PromptやContextDocsを1で抽出した履歴の中の一番初めのメッセージに挿入します。初めのメッセージにPromptとContextDocsを挿入することで、その後の会話の流れを保つことができます。
ContextDocsは、合計のtoken数がChatGPTの制限を超えない範囲でできるだけ多く挿入していきます。その後、他の履歴を統合し、それらをChatGPTのAPIにリクエストします。
以上の方法により、token数制限や適切なContextDocs選択の課題を解決しつつ、できるだけ自然なChatを可能にできていると思います。
Vector DB
embeddingの保存・検索のために、Vector DBを用いていきます。今回用いたVector DBはElasticsearchです。ElasticsearchはOpen Distroのk-NNプラグインを導入することで、HNSWアルゴリズムを用いたApproximate k-NNにより、cosine類似度が近いembeddingを持つK個のデータを高速に取得できます。
Vector DBの比較・検討
ここで、embedding保存のためのVector DBに関して比較検討を行い、今回用いてたElasticsearchを採用しました。ベクトルの検索を高速で行うことができるVector DB機能提供するDBはいくつかあります。比較検討の指標としては、ベクトル検索の性能や速度など様々なものが挙げられますが、今回は導入コストとマネジメントコストに焦点を当てて考えました。試験的なシステムの導入となるため、出来るだけ簡単にシステムを実現でき、保守運用も簡単にできる必要があるからです。
導入コストを抑えるため、IU Web内で既に使われているDBを候補として比較検討を行いました。具体的な候補のDBとそれぞれの特徴をまとめます。
|
Elasticsearch
|
MongoDB
|
Redis
|
|
|---|---|---|---|
| IU Webでの現状の使われ方 |
|
|
|
| Vector DBとしての利用方法 |
|
|
|
それぞれのDBの現状の使われ方とVector DBとしての利用方法を比較してみると、MongoDBやRedisは現状IU Webで使われているサービスに対し、新たなサービスの導入や異なるバージョンの利用が必要となってくることが分かります。一方、Elasticsearchは現状使われているサービスをそのまま利用可能なため、導入コストが低いと言えます。また、Elasticsearchは社内クラウドのマネージドサービスをそのまま利用できる一方、MongoDBとRedisでは、マネージドサービス対象外のバージョンが必要となってしまうため、自分自身で新たにサーバを建てた上でマネジメントを行っていく必要があります。
以上の比較により、導入コスト・マネジメントコストが一番低い、Elasticsearchを選択することにしました。
k-NN クエリ
Elasticsearchのデータ構造の設定は以下の通りです。特に、今回の場合、類似度としてcosine類似度("cosinesimil")、EmbeddingのdimensionとしてOpenAIにおけるEmbeddingの次元数(1536)を設定しました。
ContextDocのEmbedding作成時には、このデータ構造に合わせて各ContextDocの内容とそのEmbeddingを格納していきます。
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "cosinesimil"
}
},
"mappings": {
"properties": {
"context": {
"type": "text"
},
"embedding": {
"type": "knn_vector",
"dimension": 1536
},
"category": {
"type": "text"
}
}
}
}次に、実際にユーザの質問に合わせたContextDocを選択するためのk-NN クエリを実装していきます。まず、k-NNクエリは下のようなクエリとなります。
例) top10を取得するとき
GET {index名}/_search
{
"size": 10,
"query": {
"knn": {
"embedding": {
"vector": [1,2,3,4......2,1],
"k": 10
}
}
}
}IU Webの実装では、Elasticsearch Rest High Level ClientによってSpring bootアプリケーション内からElasticsearchに接続しています。このクライアントは、Elasticsearchの基本的な接続・リクエストを行うクライアントであるRest Low Level Clientを拡張し、各クエリに対してそれぞれに特化した関数や機能を提供し、制御しやすくしたものです。しかし、こちらで提供されているSearchクエリの中には、今回使うk-NNクエリは含まれていません。
そこで、今回はRest Low Level Clientを直接利用し、Elasticsearchのsearch APIへのリクエストを直接定義することにより、自力で上記で挙げたk-NNクエリの構築を行うという方法を取りました。ドキュメントなどではRest High Level Clientを利用した接続方法が主流となっており参考文献が少なく、この方法に辿り着くのが実装の中で一番苦労した点だと思います。
private final RestClient client; // Elasticsearch Rest Low Level Client
public List<CatalogEmbeddingDocument> searchTopKByEmbedding(List<Float> embedding, Integer topK) {
Request request = new Request("POST", String.format("/%s/_search", indexName())); // searchAPIへのRequestの定義
request.addParameter("size", topK.toString());
request.setJsonEntity(buildKNNQueryJson(embedding, topK)); // クエリパラメータ"query"の構築
Response response = search("searchTopKByEmbedding", request);
return parseResponse(response.getEntity());
}
private static String buildKNNQueryJson(List<Float> embedding, int topK) {
try {
XContentBuilder builder = XContentFactory.jsonBuilder().startObject().startObject("query");
builder.startObject("knn");
builder.startObject("embedding");
builder.field("vector", embedding);
builder.field("k", MAX_TOPK_SIZE);
builder.endObject().endObject().endObject().endObject();
return Strings.toString(builder);
} catch (IOException e) {
throw new CatalogSearchException("Failed to build query", e);
}
}今後の展望
今回のインターン期間中に実装したAI アシスタントシステムでは、時間の関係でまだ実現できていない部分や技術的な問題による制限がいくつかあります。
- 現状、ContextDocとEmbeddingをVector DBに格納を行う操作を1つのDB/Tableごとに行っているため、Data Catalog内全ての情報を網羅するのにかなり時間がかかってしまう。
- LLMの入力に文字数制限があり、情報量の多いデータベースやTableの情報を全てContextDocに含めることができない。
- Embeddingの類似度の計算に精度が大きく左右されているため、精度に限界がある。
- セキュリティ観点でOpenAI APIに送信できるデータが限られていた。
今後の展望として、バッチごとにEmbeddingの作成が可能なAPIを追加することで、embeddingに必要な時間を節約したり、1つのContextDocにまとめていた情報を複数に分散させたり要約を行うことで文字数制限に対応したりなどが改善の施策として挙げられます。精度面に関しても、Embeddingの作成・検索方法を工夫したり、ChatGPTへのPromptを工夫することでよりよい回答が得られるようになるなど、工夫の余地が残っていると思います。セキュリティ面に関しても、マスキング処理などを加えることで安全に幅広い情報に対応可能にできると予想できます。
また、今回は主にData Catalogのデータ検索に焦点を置きましたが、今後はプロジェクトやデータベース間の関係性などIU Web内が提供する他のサービスもAI アシスタントがサポートできるようにするといったシステムの構築も展望として考えられます。
感想
私自身、サーバサイドエンジニアとしての経験があまり豊富であるというわけではなく、分からない部分が多い中、今回のインターンシップを通じてとても沢山のことを学ばさせていただきました。特に、Data Platformに関わり、Elasticsearch、MongoDBをはじめとした様々なDBやデータの管理方法など、個人では関わることが難しいデータに関するシステムや技術について学び、実際に実務を通じて利用することができたのがとても貴重な経験でした。また、Data Catalogという概念をこのインターンを通して初めて知り、その便利さと今後将来における重要さを体感することができました。さらに、プロジェクトを通して、実際にシステムのデザインから実現までのシステム開発の一連の流れを体験することができ、自分が考えたシステムが実現できた時の嬉しさやエンジニアとしての仕事の楽しさを体感することができました。
メンターの方には一日に何度もmtgを設けていただき相談に乗っていただいたり、slackで質問するとチームの方からすぐ回答をいただけたりと、IU Devチームの皆さんにはこの6週間本当に沢山のサポートをいただきました。また、他のチームの方との交流機会を設けていただいたり、出社した時には一緒にお昼にいって様々な貴重なお話を聞かせていただいたりと様々な面で支えていただき、とても充実したインターンシップでした。
本当にありがとうございました。