

This blog post is the second part that continues from Verda at CloudNative/OpenStack Days 2019 (1/2). In the previous post we took a look at the overall ecosystem of Verda. In this post I will explain our network side challenges and how we optimized and improved Verda to overcome those challenges.
LINE's Verda Network designs:
Lets go through the 3 transitions of LINE data center networks.
- L2-based network backed with upstream solution using Linux bridge
- L3-only flat network: Developed by LINE OpenStack engineers
- L3 Base Overlay network: Developed by LINE engineers
1. L2-based network backed with upstream solution using Linux bridge
Motivation:
- Maintaining a large L2 network across racks pose problems and difficulties such as the need to treat BUM traffic.
- To shorten L2 domains in our private cloud, we actually provisioned L2 networks for each rack.
- OpenStack Nova requires you to provide the actual network to be used for the VM at the time of boot request, so we ended up exposing all the underlying networks per rack to user. This came from the concept of one neutron network representing one L2 network. In case of VM failure on a particular rack because of network allocation, the user needed to retry with a different rack network, which increased a lot of complexity from the end user's point of view.
Solution Network Design:
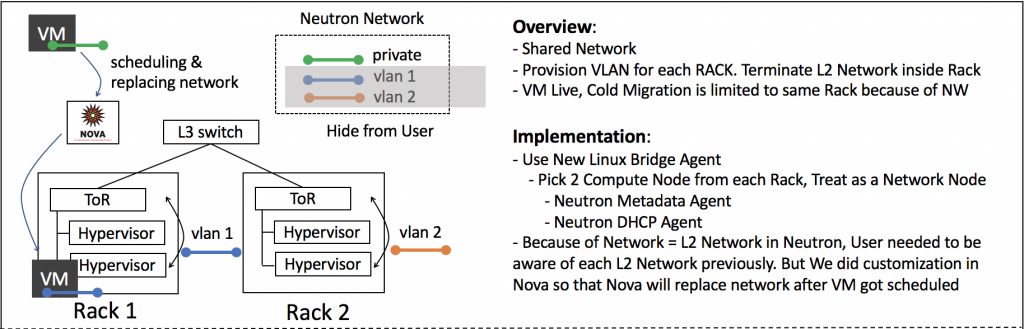
- We try to avoid large L2 networks and that's why we provisioned L2 for each rack.
- We can achieve multiple small L2 in a single private cloud, but at the same time, it leads to multiple networks being exposed to the end user which can lead to user confusion.
- To solve this problem, we introduced network abstraction by only providing user visible shared networks, which are actually not used by any VMs, to users.
- Since we have an L2 network per network rack, we have replaced the network asked by user in VM boot request with the underlying network used by the hypervisor on which the VM is scheduled to boot.
- We used OpenStack Neutron Linux Bridge agent on each hypervisor and placed Neutron Metadata agent and Neutron DHCP agent on two of the compute nodes from the same network rack.
Problems with this design:
- This design worked well for the first few months. After some time, we started running into trouble because of the uplink bandwidth from ToR to the aggregation switch. Whenever there was a massive amount of East-West traffic between VMs located in different network racks, ToR (Top of Rack Switch) caused problems and dramatically decreased the throughput.
- That's why our next challenge was to achieve a Non-Blocking Network, more precise traffic management, portable IPs etc.
- This design also limited some Nova features, only allowing users to resize, migrate or evacuate in the same rack.
- Since we have shared networks all tenants were using the same network, There was no multi-tenancy support.
To know more about this Network design please this blog post written by one of my colleague: OpenStack Summit Vancouver 2018 Recap (2/2)
2. L3-only flat network: Developed by LINE OpenStack engineers
Motivation:
In the previous network design, there were Nova feature limitations along with decreasing throughput. We decided to introduce a new network design that uses the CLOS network concept using BGP and recommended by the IETF (Use of BGP for Routing in Large-Scale Data Centers).
Solution Network Design:
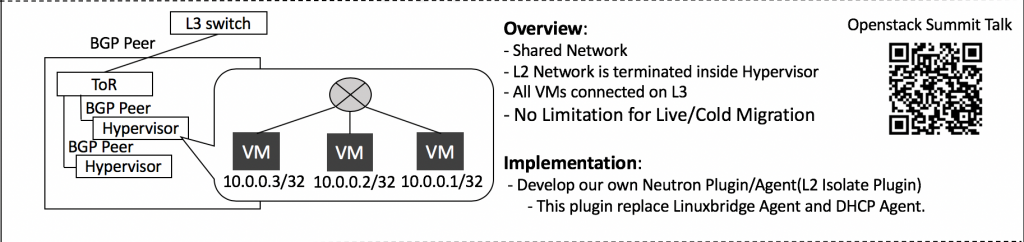
- As you can see in the image above, we have terminated the L2 network at hypervisor level.
- We use routing /32 for all VM inter-communication. No network node required.
- Neither upstream solutions Neutron Linux Bridge agent nor Neutron OVS agent support VM inter-communication with just /32 Routing.
- So LINE Verda engineers developed a new Neutron L2 Isolate agent which is composed of:
- L2 Isolate mechanism driver (ML2 Plugin)
- Routed type driver (ML2 Plugin)
- L2 Isolate Agent
- You do not need a network node with L2 Isolate Agent. In this environment, compute nodes terminate L2 networks. Services that require VM to reach L2 need to be provided by each compute node. That is why the metadata agent has moved from the network node to a compute node, and DHCP services are provided by dnsmasq configured by the L2 Isolate Agent running on each compute node.
Difference between having a common Linux bridge agent and L2 Isolate agent:

VM communication:

- When new a TAP device is created by nova-compute, our new Neutron L2 Isolate agent detects that and configures a VM/32 route and proxy-arp against the detected TAP.
- This allows VMs to directly communicate with other VMs on the same hypervisor without any bridges.
- To allow VMs to communicate with other VMs on different hypervisors, we use an FRR routing daemon to tell BGP to advertise VM/32 to ToR (Top of Rack switch).
- For providing DHCP to VMs, every hypervisor runs its own dnsmasq as shown in the image.
- For metadata access to VMs every hypervisor, runs its own proxy metadata service as shown in the image.
Problems with this design:
- We cannot support network per tenant with L3-only flat networks. Multi-tenancy support was missing in this design.
To know more about this Network design please visit the dedicated blog written by one of my colleagues: OpenStack Summit Vancouver 2018 Recap (2/2)
3. L3 Base Overlay network: Developed by LINE engineers:
Motivation:
- Previously our private cloud was only used by LINE developers. That's why our private could was designed more like a single tenant system. From a keystone perspective, we used multi-tenant support, but from network perspective it was flat.
- Some departments partially outsourced development to other companies. It was risky for us to run software developed by other companies in our flat network, since we could be allowing them to connect to anywhere inside our cloud.
- To avoid this situation. we needed to re-think about our network architecture.
Solution Network Design:

- We needed to provide strong tenant isolation to users so we developed a new neutron agent to support L3-based overlay networks.
- This neutron agent is based on SRv6 to create overlay networks.
- We use BGP to ensure underlay network IPv6 reachability so that hypervisors, VRF (Virtual Routing Function) and network appliances can communicate.
- Each tenant has its own dedicated network and dedicated VRF that configures encap rules for VMs which are in the same network regardless of the hypervisor it is deployed on. This allows VMs from the same tenant to communicate with each other.
- Encap rules help the hypervisor to determine where and how to send packets sent by the VM residing on the same hypervisor.
- The traffic of VMs attempting to communicate with other tenant VMs goes through the network node.
To learn more about this network design you can check the work done by one of my colleagues: JANOG (Japanese only)
About various optimization and improvements efforts inside Verda:
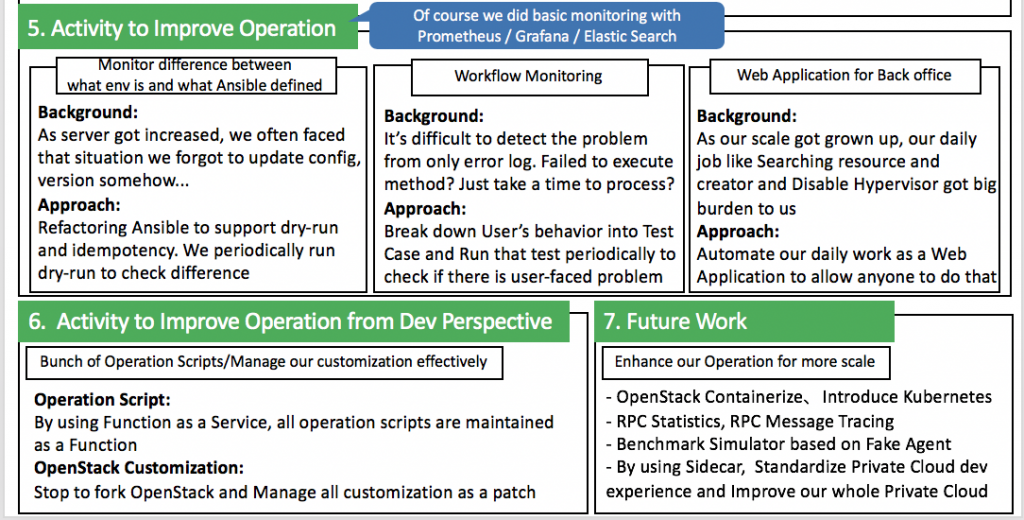
Operation perspective improvements:
- We have basic monitoring based on tools such as Prometheus, Grafana and Elasticsearch etc.
- Apart from the existing monitoring systems, we have adopted more advanced monitoring/operating systems.
- Some of which I list below:
Monitor difference between what actual environment is having and what Ansible has defined:
- As the scale of the cloud became bigger and bigger, it became difficult to manage all the servers. We sometimes forgot what changes we applied to the environments as a hotfix without updating Ansible. So the next time we executed Ansible it overrode the changes we've made.
- To solve this problem, we refactored Ansible and started to run Ansible every morning in dry-run mode to check the inconsistencies between changes.
Workflow monitoring
- As the scope of the cloud became bigger and bigger, with various services interacting with each other, it was difficult to track down and debug a particular failure inside the entire Verda ecosystem.
- To find the root cause of some failures we started to break down user behaviors into specific sub-operations as test cases. We then ran them periodically to check if user were facing any issues.
Web application for Back Office:
- Our everyday job includes searching the cloud resources, managing them, and disabling the hypervisor in case we needed to perform maintenance. With the increased scale of the cloud, these jobs became difficult without using a managing tool.
- So we have Verda Back Office (VBO), a web application that automates our daily work, making it easier for anyone to do them.
Developer perspective improvements:
Operation scripts:
- The increasing size of the cloud made it difficult to maintain and manage the various operation scripts that we had.
- We decided to make use of Verda Faas (Function as a Service) which is based on Knative. We migrated all scripts to the FaaS and they are now maintained as a function.
Managing OpenStack customizations:
- Whenever we needed to customize any OpenStack component, we used to fork that component and add a customization commit on top of it.
- This became cumbersome as our cloud became bigger and we required a lot of customization. It was difficult to keep track of all the customizations, and making more customization commits to fix bugs found in the previous version was a hassle.
- We decided to not fork the repositories and instead use git tags and patches.
- We cloned specific tags of the OpenStack component and applied our customization patches on top of it. Maintaining patches instead of commits was much easier.
More about future work in Verda:
Enhance our operation for bigger scale:
Containerize OpenStack:
- We are in the process of containerizing OpenStack services and introducing Kubernetes in the system to manage them.
RPC Statistics/RPC Message Tracing:
- We observed that its better to trace the RabbitMQ messages and have a clear picture of various RPC metrics to improve OpenStack performance.
Benchmark simulator based on Fake agents:
- By making use of fake Neutron agents and Nova drivers we would like to benchmark the scale of the cloud.
Use SideCar Containers:
- We would like to make use of the concept of sideCar containers to standardize our private cloud.
Ending notes
It was the first time LINE had its own Panel in the CNDT/OSDT event. We are continuously improving our private cloud and hope to participate in future panels in many more events and conferences.
Thank you for spending time to read this blog series. I hope you got the general idea of LINE's Verda ecosystem and network designs.