

Ever wondered what LINE uses internally for infrastructure management? If yes, then you came to the right blog post.
Recently at CloudNative/OpenStack Days Tokyo, LINE presented on its OpenStack cloud project called Verda.
This article is going to be a series of two blog posts which provide a summary of the entire Verda ecosystem:
- Verda at CloudNative/OpenStack Days 2019 (1/2)
→ Bird's eye view of Verda - Verda at CloudNative/OpenStack Days 2019 (2/2)
→ LINE's network design to meet private cloud user requirements
In this blog post, we'll be looking through a bird's eye view of LINE's OpenStack project Verda and introduce you to the entire OpenStack ecosystem that LINE has. Without further ado, let's begin!
Overview of LINE's OpenStack:
In this overview, I will discuss the contents of the panel below:
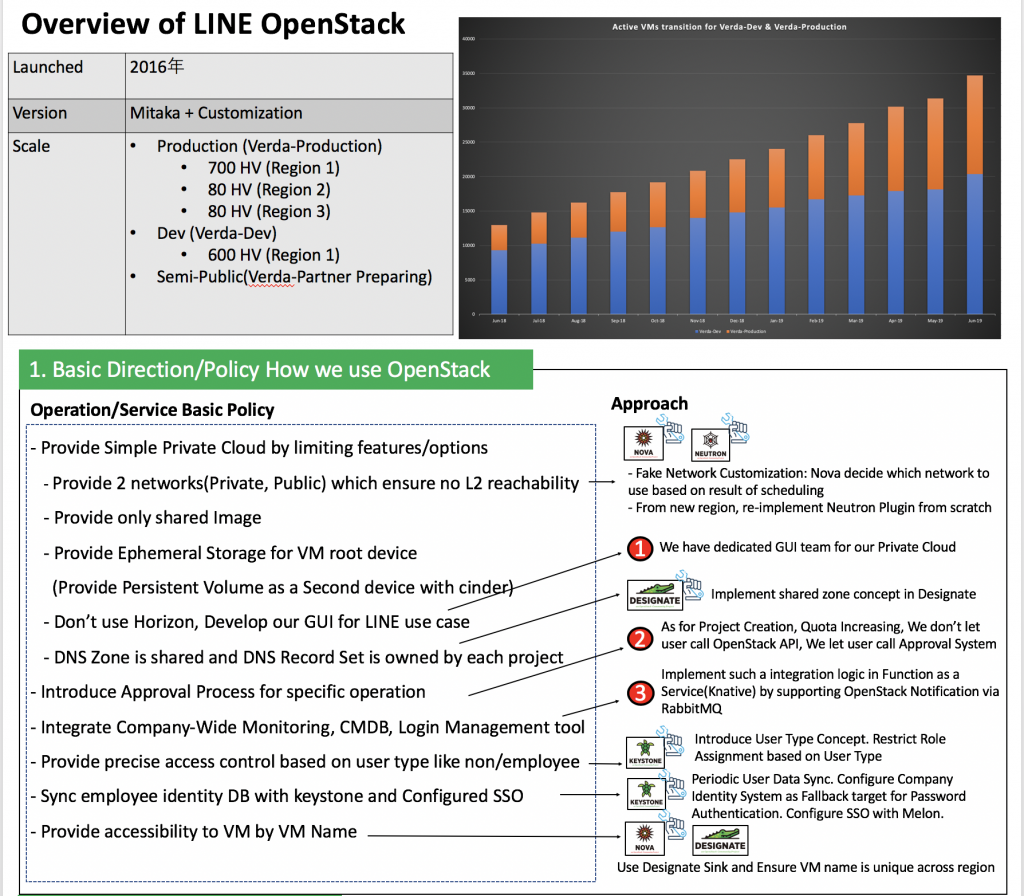
Every cloud starts with a very small scale. LINE started its OpenStack journey with Mitaka in 2016, having just one region and a handful of hypervisors. Now it has 3 regions with a total of 860 hypervisors in the Production cluster and 600 hypervisors in the Dev cluster.
We have also introduced a new cloud which is semi-public and the first private cloud to implement multi-tenancy.
In the next few sections, I'll be going over the fundamental policies that we've employed while using OpenStack for our private cloud.
Provide simple private cloud by limiting access to users
Right now our users are LINE application developers who might not have enough knowledge about how to operate and use OpenStack. So we don't want them to get confused and as much as possible we want them to focus on actual application development and let the infrastructure and operating part on us.
Lets go through some of the customization's that we did to achieve this abstraction.
- Provide only limited networks:
- If you want to create a VM in OpenStack you need to provide the network to be used for that VM.
- So the user has to be aware of the various networks, and if the VM creation fails due to a network assignment failure they have to try with some other network.
- We don't want our users to get into such low level network details. We want to handle the network assignment part by ourselves as much as possible.
- We only provide two user-visible networks: Public and Private. We let OpenStack Nova replace those networks with underlying actual networks that the hypervisor is actually using.
- This was for the old regions having Linux bridge-based hypervisors. For new regions we adopted CLOS-based BGP networks that do not require this network abstraction.
- Provide only shared images:
- We don't want our users to get into the complexity of managing various cloud images.
- So we only provide cloud images managed by us and let users use them. We have taken care of easy VM access and security stuff inside the image. We call them golden images.
- Provide Ephemeral Storage to VMs:
- Provide OpenStack Cinder Volume as a second device for persistent storage.
- Provide a more easy dashboard:
- We found that our users have difficulties using complex software like OpenStack Horizon.
- Also we don't want our users to accidentally make changes into the cloud disturbing their own services due to lack of knowledge like networks and security groups.
- So we provide our custom dashboard that streamlines features so that it's easier for more users. We have a dedicated GUI team for our private cloud.

- Provide shared DNS Zone:
- Sharing Neutron networks between projects is a very common use case. As such, zones should have a similar functionality.
- We provide shared DNS zones that are not yet supported in the upstream community. We customized OpenStack Designate to mark a particular zone as shared so that it can be used among different projects.
- Designated record-sets are owned by each project.
Approval process for specific operations
- We don't want users directly performing certain OpenStack operations, as the result of those operations might have an impact on the existing cloud. The impact could affect creating projects, applying for quota etc.
- We use an in-house developed approval system. Only approved operations are performed by particular OpenStack services.
- We have customized required OpenStack components so that requests that require approval are sent to the approval system first. Once it gets approved it is sent back to the actual service.
Integrate legacy systems into OpenStack
- Before migrating to an OpenStack infrastructure, our users and application developers had to use company-wide systems for checking server statuses, either for monitoring or to log in.
- We integrated these legacy systems with OpenStack using FaaS (Function as a service) backed by Knative.
- FaaS provides the ability that enables end users and private cloud operators to register any type of function that can be triggered by many different type of events (Such as cron or vm-creation).
- This service actually supports resource change events in OpenStack such as port-creation, vm-creation thanks to the oslo.messaging notification ecosystem. We achieved legacy system integration by heavily using this FaaS.
- This approach can keep upstream code clean. That's why this kind of customization has been done outside of OpenStack and has been done by FaaS.
- Our users used to login to the servers using Kerberos credentials without injecting SSH keys into them. We have maintained the same user experience by customizing OpenStack Keystone and our cloud images.
Limit access control based on the user types
- In LINE we have multiple types of users using the cloud so we control their access based on the user types whether they are a LINE employee or not.
- We have introduced a
user_typeconcept which helps us to controls role based assignment of the users. - For example,
employee_useris allowed to haveproject_admin, others not.
Sync Employee identity with Keystone from the company managed system
- We have a new service on top of the OpenStack Keystone which syncs users from the company-managed system and configures SSO (Single sign-on) so that users don't need to log in every time they jump from the company system to the Verda cloud.
Provide accessibility to VMs by VM name
- We provide users with ways to access VMs through the VM name as we make sure that VM names are unique in the entire cloud which helps create unique DNS records in Designate.
LINE's OpenStack Verda Ecosystem
The picture below depicts the Production cluster's ecosystem.

Right now we have 3 OpenStack regions in the production environment.
- In-house components
- OSS or existing software
- Customized OSS or existing software
There are 3 categories of components in terms of their role in the Verda ecosystem.
- Global components
- Region-based components
- Operation components
Global components
The components below are globally deployed:
- Keystone
- Designate
- Approval
- Function as a service (Knative)
By saying Global components we mean that these components are shared among all the OpenStack regions we deployed. Later we have to provide the high availability of these global components as well so we decided to replicate some of the important components to other regions which can act as a DR (disaster recovery) region. As you can see in the above ecosystem, region 1 has Keystone and Designate which are then replicated to region 2 for DR. We have a hardware loadbalancer in front of each region.
Region-based components
Each region has target uses to serve so to keep the cloud ready for on demand service we have kept the resource providing services per region.
Below services are per region:
- Nova
- Provide VMs on demand
- Neutron
- Provide network to the VMs of the same region
- Glance
- Provide cloud images to the VMs of the same region
- Cinder
- Provide persistent volumes for VMs
- MySQL
- This is the database service used by all local region-based services for keeping their data.
- RabbitMQ
- Currently we have 3 different clusters each having 3 data nodes. RabbitMQ cluster with 2 additional management nodes.
- The reason we have separated the data nodes and the management nodes is that we have observed that the RabbitMQ Management plugin uses a lot of memory for keeping statistics of all the other nodes from the cluster which crashes the node out of high memory usage.
- OpenStack clients will only connect to the RabbitMQ data nodes which will serve the RabbitMQ requests. Management nodes are just for monitoring and operation purposes.
- We observed that Nova and Neutron are the top most active services which puts a lot of traffic on RabbitMQ so we decided the have separate RabbitMQ clusters for each of them like below:
- Nova:
- 3 data nodes
- 2 management nodes hosting stats database (Shared with Neutron cluster and deployed with containers)
- Neutron:
- 3 data nodes
- 2 management nodes hosting stats database (Shared with Nova cluster and deployed with containers)
- Other services:
- 3 data nodes
- 2 management nodes hosting stats database
- Nova:
- To ensure the connections are distributed among all the RabbitMQ data nodes we are keeping the RabbitMQ data nodes behind the L4 hardware loadbalancer.
- To move RabbitMQ messages from one region to another we make use of RabbitMQ shovel plugin
Operation components
Below are the Operation components that we use:
- Monitoring tools:
- Prometheus
- Grafana
- Elastic Search
- Legacy Verda Back-office (VBO) tool for monitoring the actual stats of the servers including bare-metal servers.
- Ogenki-workflow monitoring: For monitoring the various OpenStack operations.
- kraken-Ansible tool: We use this tool for usual deployment as well as for monitoring the consistency between the actual cloud state and the configurations in Ansible.
Multi-Region Deployment

We use keystone catalogs for service discovery on each region, which means we can know which service is available on which region by checking keystone service catalog.
Ending notes
Thank you for taking time to read this blog. We provide three different types of networks which I will go into detail in the next entry in this series.
Stay tuned...