
Hello again, this is Nishiwaki from Verda 2 team at LINE. In my previous post, I've shared a number of sessions about containers that seemed interesting as a session attendee. On this post, I'd like to share our presentation in the summit, Excitingly simple multi-path OpenStack networking: LAG-less, L2-less, yet fully redundant The main topic of our presentation was the architecture of a data network center we were setting up for a new region and Neutron integration. The new architecture was built with enhanced capacity for east-west network traffic. Here are a recording of our presentation and slides for those who couldn't make it to the conference.
Horizontal expansion of data center network
The bandwidth of the legacy network architecture of LINE's private cloud was narrower than that of the downlink of ToR (Top of Rack), which caused bottlenecks in ToR communication, decreasing the throughput drastically. This won't be an issue if VMs do not communicate much with each other. But, you can easily realize that there is an increase of such use case on private clouds, due to having more systems based on microservice architecture and machine learning, which tend to have a high frequency of communication between VMs. We decided that our private cloud needed to support such use cases too.
Our first approach to avoid bottleneck on ToR was to schedule VMs that needed VM communication on the same ToR's hypervisor. This left us no option but to place the whole system on the same outage domain, and we were not able to enforce scheduling on the workload only with OpenStack Nova. Which gave us some homework, including having to deal with the structure where after creating VMs such as watcher—an OpenStack project—VMs were to be loaded on different hypervisors depending on the VM's workload.

So, to solve the fundamental issue in the new region, we setup a non-blocking network with Clos Network using BGP, a recommendation from RFC7938.

The bottleneck issue on ToR was resolved by Clos Network, but because ToR terminates L2, we needed to manage subnets of each ToR. Also, there were other problems such as packet losses in ToR switch maintenance and no support for live migration between racks. So, we are trying to solve these issues by using EBGP between hypervisors and ToRs to expand L3 routing domains to hypervisors.

Including hypervisors to L3 routing domain raised another issue. It became harder to create VLAN and subnets per rack like we used to do. To continue the way we worked in this environment required us to create networks and subnets as much as the hypervisors, and live migration became unavailable, and the number of subnets to manage was as much as the number of hypervisors. Thus we need to revise VMs accessing each other and also VMs and data center network. The options available are using the overlay technique such as VXLAN or GRE and guaranteeing accessibility by direct routing through dynamically allocating VM's IP to the /32 route of data center's network. If you take the former option, you'll get capsuling overheads or end up with a very complex network design. We wanted to avoid this so we went with the later; we guaranteed end-to-end accessibility only by routing and no overlaying.

L2 Isolate Plugin
So far, we've mainly dealt with data center network design without no mention of OpenStack. Connecting cloud resources (VM) created on a hypervisor to data center network is what OpenStack Neutron does. We need Neutron to support inter-VM communication by /32 routing, but neither Linux bridge agent nor OVS agent supports such use case.
So what we did was build our own Neutron Plugin/Agent(L2 Isolate Plugin). This plugin is built as a driver for ML2 and is composed of the following three parts:
- l2isolate mechanism driver (ML2 Plugin)
- Routed type driver (ML2 Plugin)
- L2 Isolate Agent

To use L2 Isolate Plugin, you need to use L2 Isolate Agent instead of Linux Bridge agent, and also change the way you deploy OpenStack cloud. The following diagram compares deploying with Linux Bridge agent–the top part of the diagram–and one with L2 Isolate Agent. The big difference is that you do not need a network node with L2 Isolate Agent. In this environment, compute nodes terminates L2 network, which means services that require VM to reach L2 need to be provided by each compute node. That is why the Metadata agent has moved from the network node to a compute node, and DHCP services are provided by dnsmasq configured by the L2 Isolate agent running on each compute node.

Configurations by L2 Isolate Agent
Now, let us introduce what configurations L2 Isolate Agent sets on compute nodes:
- Connectivity to other VM inside hypervisor
- Connectivity to other VM outside hypervisor
- DHCP
- Metadata proxy
- Security group support
Connectivity to other VM inside hypervisor
The following diagram shows configurations to guarantee VMs on hypervisors to reach L3. To prevent VMs having L2 connectivity, we use TAP as VIF_TYPE and then the nova-compute just creates a tap device.

Every VM gets the same prefix that is not /32 (in our slide it is 10.252.0.0/16) for their IP. Which means, when sending packets to a VM, ARP (Address Resolution Protocol) is not resolved due to VM's reachability to L2. To reach a VM closest to L3, we need to make the VM to send an IP packet to a hypervisor first. If we set Proxy ARP, we get the MAC address of the hypervisor as a response to the VM's ARP request, through which we can allow VMs to reach L3.
We set a gateway IP with noprefixroute option on a TAP device. This is based on the restriction that dnsmasq does not support a DHCP service on an interface without IP address allocation. We need the noprefixroute option also because we lose reachability between VMs on different hypervisors if the path 10.252.0.0/16 is added on the routing table.
Connectivity to VM from outside hypervisor
Now, how is reachability between VMs and devices in data center network guaranteed? In our case, each computer runs routing software apart from the L2 Isolate Agent. This routing software monitors the routing table on hypervisors, and uses the changes on the table as triggers to advertise VM's IP address(/32 path) to the ToR switch. This is how L3 reachability from outside hypervisor to VM is guaranteed.
We've designed the logic for advertising VM IP addresses to outside hypervisors as pluggable, and to be independent of any particular routing software, which allows combination with various routing software available, such as BIRD and FRR. The reason for such design is because we need to be able to use some technologies such as RFC 5549 that are yet to be implemented on some routing software, requiring us to be flexible in changing our choice of routing software.

DHCP
As mentioned earlier, since each compute node terminates L2 network, each one of them needs to provide a DHCP service. The default DHCP agent of Neutron, neutron-dhcp-agent, creates a dnsmasq per network and provides a DHCP service to VMs on the same network. Contrarily, with L2 Isolate Agent, a single dnsmasq provides a DHCP service to all VMs on the same hypervisor, regardless of the number of networks. Also, there is no need to consider L2 failure domain allowing creating a lot of VMs under a big subnet. So, if neutron-dhcp-agent keeps the configuration of all VMs of the same subnet on a single configuration file, the configuration file will become huge. To avoid this, the L2 Isolate Agent matches one configuration file per one entry on Neutron; this allows the dnsmasq to read in only the entity configuration needed in relation to the related compute node. We've used the option on dnsmasq to monitor changes simply by assigning a directory.

Metadata proxy
Now, I want to discuss about implementing a metadata service, in which we've used a rather strange trick. Before I get into the implementation, I'd like to cover how Neutron relays Metadata API with OpenStack. The Metadata API is a Nove API and is provided through the nova-api process. When you call the Metadata API, you need to send an HTTP request with the information that is only available on VM such as X-Instance-ID in the header. But, many of you would have had no experience in doing so when you call the API on a VM with curl http://169.254.169.254. This is because, additional information such as X-Instance-IDis injected through a separate process while the request reached Nova.
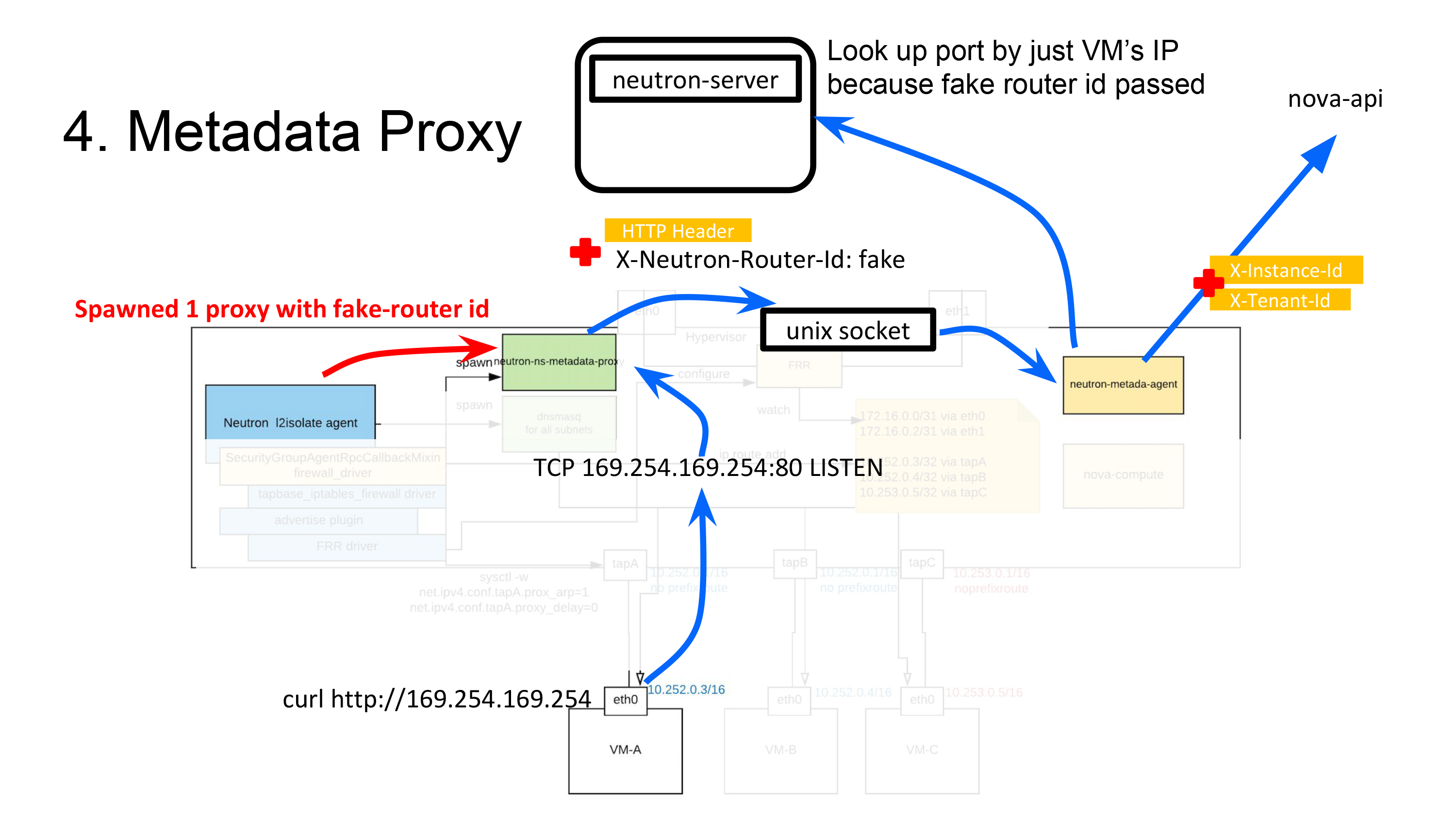
So, who injects this information? There are two of them; neutron-ns-metadata-proxy and neutron-metadata-agent:
neutron-ns-metadata-proxy: This is a process ran byneutron-dhcp-agentfor each network or byneutron-l3-agentfor each router. No operator runs this directly. When running this process, network ID router ID needs to be passed as a parameter.neutron-metadata-agent: This is a process to be run by an operator on the node where neutron-dhcp-agent or neutron-l3-agent runs.
The process of the Metadata API being relayed to Nova API is as follows. We will assume that we are using neutron-l3-agent:
- The
neutron-ns-metadata-proxyreceives the request directly from http://169.254.169.254, adds the router ID and VM's IP address at the time of the request to the request, and sends the request toneutron-metadata-agentvia a Unix socket. (View code)if self.network_id: cfg_info['res_type'] = 'Network' cfg_info['res_id'] = self.network_id else: cfg_info['res_type'] = 'Router' cfg_info['res_id'] = self.router_id - The
neutron-metadata-agentgets a list of all the networks belonging to the given router ID. (View code)networks = self._get_router_networks(router_id) - Search VM's port based on the result of step 2 and VM's IP address. (Include networks in the search condition, so port instance used can be known even if the IP is duplicated). (View code)
return self._get_ports_for_remote_address(remote_address, networks) - Get the Instance ID of the VM from the port's device owner that has been returned by step 3. (View code)
return ports[0]['device_id'], ports[0]['tenant_id'] - Set information including the Instance ID in the user request's header sent from
neutron-ns-metadata-proxyto connect to the Nova Metadata API. (View code)return self._proxy_request(instance_id, tenant_id, req)
We've briefly seen how the Metadata API is relayed. Let's see how it is implemented with our L2 Isolate Agent where we do not use neither neutron-dhcp-agent nor neutron-l3-agent.
The L2 Isolate Agent runs the neutron-ns-metadata-proxy process; one neutron-ns-metadata-proxy provides the proxy service to all VMS on the same hypervisor. The same works for VMs on the same hypervisor but with different network or subnet. So, how does neutron-ns-metadata-proxy that gets created per network support all VMs with a single process? The L2 Isolate Agent passes a fake router ID as the parameter and runs the neutron-ns-metadata-proxy. If a fake router ID is passed, the neutron-metadata-agent cannot obtain network information when searching a port. Searching for a port can only be done by VM's IP address and we get an instance ID (See the code). So, this solution does not allow duplicate IPs, but we can provide the metadata service to VMs with one neutron-ns-metadata-proxy. We opted for this to reduce the amount of code, as well as to reuse what we had.

Security group support
Lastly, we implement security groups. The firewall driver of each agent defines the actual configuration. But, the default firewall driver of Neutron, IpTablesFirewallDriver, requires the tap device to be connected to a bridge, thus cannot be used with the L2 Isolate Agent.
What we did was create a TAP-based firewall driver that can determine if given traffic is related to a particular VM just by looking at the in/out interface, as implemented here.

Our achievement
So, I've showed you how our L2 Isolate Plugin, including the L2 Isolate Agent, works with Neutron, and how L3 reachability between VMs, and also between VMs and data center network is guaranteed. It took us two months to develop this custom plugin, including testing, and the plugin is being used in production. Some of you may be surprised at the time it took us; there is a framework for common processes for agents that are actually used in Linux bridge agent, so we've based our agent on it too. Refer to the following links to see the framework.
Also, there are many internal libraries of RPC or Neutron, so it might seem costly to understand Neutron at first, but the actual cost isn't that high. Learning how Neutron works at the code level can be a big help in considering expansion or in troubleshooting, so the whole project was quite an achievement for us.
However, the new network architecture we've shared and the custom plugin are no silver bullets. There are indeed pros but also cons that we've known from the start of this project. We went ahead anyway, after a series of reviewings of operating systems and structures that would minimize the cons. Let me share the pros and cons we've come up with.
In the network manager's point of view
Pros
- Increases the average throughput in communication between VM and ToR
- Improves ToR's uplink bandwidth
- Does not use overlay network (L2 Isolate Plugin)
- Simple data center network design that do not depend on vendors
- Our data center network does not bond L2 network
- All redundancy is implemented with BGP(Border Gateway Protocol)
- Zero downtime maintenance on ToR switches
- Flexible traffic engineering with BGP
Cons
- We need to run a large-scale BGP network
In the cloud manager's point of view
Pros
- Support for live migration between racks
- No need to schedule VM due to requirements for inter-VM communication
Cons
- We need to continually maintain our custom plugin
Ending notes
In the second part of our articles, we've share the session we've presented, 'Excitingly simple multi-path OpenStack networking: LAG-less, L2-less, yet fully redundant' at OpenStack Summit Vancouver. It was the first time for LINE to present in an OpenStack Summit. We are continuing with considering various options to improve LINE's private cloud system. Our plugin still needs more work on it; we need to make it available for open source, introduce overlay network for network separation, transparently applying the same network architecture in BareMetal environment and many other improvements we can make. We hope to share our journey in other conferences and through communities. This posting turned out longer than I expected, but thank you for reading!