
前言
大家好,我們是 LINE 台灣資料工程團隊的資料工程師 Penny 與資料科學家 Charlie。今年因為新冠肺癌的關係,大多數的研討會都採取線上的形式舉辦,而 DataCon.TW 也不例外。DataCon.TW 2020 是由台灣資料工程協會 (Taiwan Data Engineering Association,簡稱 TDEA) 主辦,以及社群成員發起的大數據相關領域研討會,今年來到第十二屆,不知不覺中我們也已經參加了三年 (有興趣可以參考之前的 DataCon.TW 2018 會議分享)。
年會跟以往一樣,除了 keynotes 主議程會邀請一些重量級講者以外,活動以「開發者」、「科學家」、「應用例」三個主題分軌進行專題講座活動。近年來,隨著大數據等資料基礎建設的完善成熟,以及機器學習、深度學習的蓬勃發展,專題講座的內容逐漸向應用面靠攏,而在基礎建設方面,如何不斷向上整合,提供在開發機器學習模型或應用上更方便的工具,會是今年主要探討的議題。在這篇心得裡,我們會分享在 keynote 中,由外國講者 Lee Rhodes 所主講的 Data Sketches 開源工具,以及專題講座中,覺得蠻有趣的電商 hashtag 應用與銀行的出國預測。
Keynotes 主議程: A Production Quality Sketching Library for the Analysis of Big Data
講者:Lee Rhodes / Distinguished Architect @ Verizon Media
講者 Lee Rhodes 雖然因為疫情沒辦法親自來到台灣,但透過線上研討會的方式,我們可以利用平台,更近距離的跟講者互動來得到及時的回饋。Lee Rhodes 是 Verizon Media(前身是大家比較熟知的 Yahoo!)的資深技術架構師,也是這個分享中 Data Sketches 專案的發起人與主要貢獻者之一。Data Sketches 是一個 2012 發起的專案,在 2015 年開源,並於 Yahoo 中被廣泛使用。在深入探討這個工具前,我們先來看看在大數據中分析查詢時會遇到的問題:
我們儲存資料往往是為了後面的分析應用,例如 logs 為了做分析,會以 key-value 對的方式儲存,但這樣的儲存方式會需要大量的儲存空間。當我們進一步要做分析時,會需要對這些資料做一些查詢,像是計算不重複項目的個數 (count distinct)、找出高頻項目 (most frequent items)、查詢直方圖 (histogram)、連接多張表 (joins)、以及做主成分分析的矩陣運算 (matrix computations) 等計算,但很不幸的是,這些計算方法都是無法擴展或被有效平行化的,會需要大量的運算資源來得到精確的結果。也就是說,一但資料愈來愈龐大,這些聚合算法 (aggregation) 就會變得愈來愈慢,無法達到實時性 (real-time) 的要求。想要同時追求實時的速度與無偏差的準確度幾乎是不可能的,那如果退而求其次,可以容忍一定程度的近似結果來換取速度呢?
事實上,只要仔細控制誤差,近似的結果是可以被接受的,而講者所提出的 Data Sketches 就是使用 Sketches 演算法,產生小的摘要資料結構來近似大的數據流,得到一個足夠好的近似答案。細部拆解 Sketch 的過程來說明 (如圖一),第一步 (Transform) 會把數據流透過簡單的 hash 轉換並將值標準化 (normalize) 到 0 與 1 之間,使數據具有均勻分布。第二步是 sketch 資料結構 (Data Structure),保留從轉換階段所接收到的有限 hash 值,以此可以限縮資料的大小。最後一步是一系列估計算法 (Estimator),根據需求在 sketch 資料結構中查詢並返回近似的結果,其相對誤差小於 1.6%,在容許範圍內。
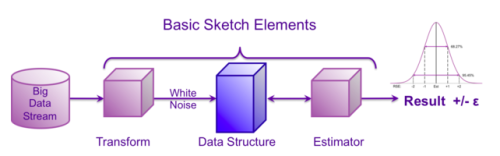
了解了 Sketch 的方法後,講者點出了使用這個方法的 6 個致勝點:
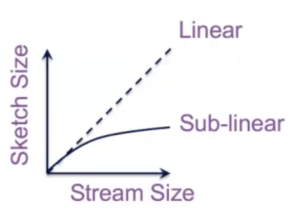
- Win #1:小的查詢空間 (Small Query Space)。透過上面描述的方法,sketch 的大小並不會隨著資料流的大小而線性成長 (如圖二),而保持 sub-linear 成長也意味著所需要的空間較小。
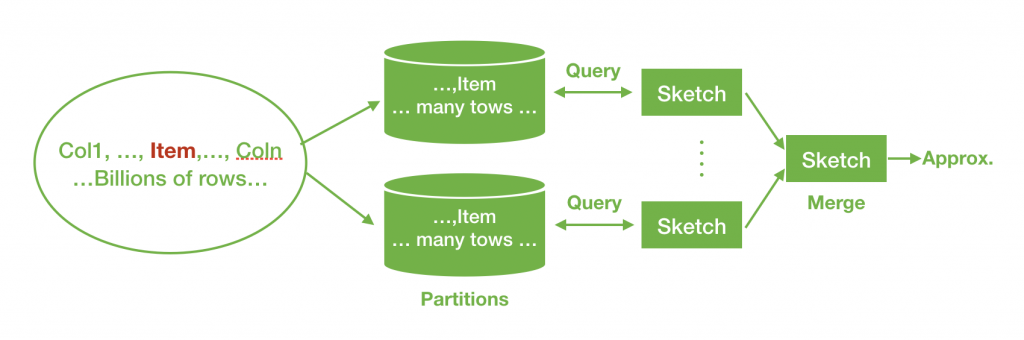
- Win #2:可合併性 (Mergeability)。透過 Sketch 的方法,在大型數據處理中,可任意將輸入資料做切分後轉成 sketches,而這些中間的 sketches 可以進行快速求和,也就達到了有效平行的效果 (如圖三)。適合在大規模的計算環境中使用 (例如 Hadoop 或 Druid)
- Win #3:近實時的查詢速度 (Near-Real Time Query Speed)。
- Win #4:簡單的架構 (Simpler Architecture)。由於每一筆資料可以產生自己的 sketch 做儲存,不需要考慮歷史資料,這樣的方式也使得架構較單純,同時因為這樣的儲存方式,sketches 可以以任意維度被合併計算,達到 #3 快速查詢的優點。
- Win #5:舊資料處理 (Late Data Processing)。每一筆資料都會透過一個 N 天的 window 做一次 sketch 處理,所以可以方便的處理舊資料。
- Win #6:系統成本較低 (Lower System Cost)。
綜合以上優點,Data Sketches 的方法可以有效用低成本達到近實時的查詢速度 進行資料分析,並運用在 Yahoo 內的一些產品 (例如:flurry) 上獲得實際的性能提升。這個工具目前是開源的,在 Maven Central 中提供了相關的 libraries。在 LINE 中,我們也常常會需要對上億筆資料做查詢分析,希望未來有機會可以導入這個工具,來改善內部產品的效能。
Application「應用例」議程:#正確打開電商 Hashtag 的姿勢
講者:Brandon Lin, Hsin-Ping Chen @ Verizon Media
在電商中,由於背後有上百萬個商品,平台會希望使用者除了正在查看的商品以外,可以觸及到更多的商品,說白了,就是希望他們可以逛久一點。比較簡單可行的方式,是在商品頁面標上有關的標籤 (#hashtag),使用者可以透過這些標籤,找到相關的商品。例如圖四中,商品「MAGY 氣質紋布面尖頭低跟鞋 灰色」跟尖頭低跟鞋、MAGY、布面、灰色是有關的。如果用傳統人工上標籤會非常耗費人力,而直接使用廠商規格資料又需要制定統一標準,因此,Yahoo 團隊就希望可以透過自動化的方式來完成上標籤。接下來,我們會以方法的演進來一步步說明。

傳統方法
要自動產生標籤,最直覺的方法是用 TF-IDF,先對商品描述做斷詞,找出出現頻率較高,同時又不是很普遍的詞當作關鍵的標籤,但是商品的標題或敘述,通常內容都很短、字詞較少,較難找出高頻詞。比較理想的方式是使用命名實體識別 (Named Entity Recognition, NER),找出特定的關鍵字。最簡單的 NER 就是給定一個已知的關鍵字詞典,把斷詞完的結果與詞典比對,但這種方法很容易被斷詞結果影響成效,也很依賴人工去維護新詞。
機器學習
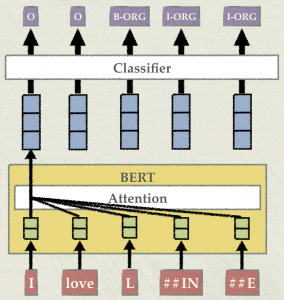
要使用機器學習的方法找出關鍵字的話,我們可以先對每個詞做 BIO tagging,例如「尖頭低跟鞋」可標記為,尖頭:B - 商品、低跟鞋:I - 商品,非關鍵字標記為 O,其中 B 代表開頭字,I 代表中間字。有了標記資料後,就可以變成一個分類問題,對每個斷詞做分類標記,就可以找到關鍵字。講者在這邊提到,在做斷詞時,使用字元 (charactor-based) 會比用詞 (word-based) 做 token 效果來得更好,而剛剛「尖頭低跟鞋」的標記則會變為,尖:B - 商品、頭: I - 商品、低: I - 商品、跟: I - 商品、鞋: I - 商品。在建立分類模型時,所擷取的特徵會是一個關鍵,如果單純使用詞嵌入 (word embedding),會遇到相同的詞在不同句子中有不同意思的問題,例如:屏東盛產「洋蔥」、這篇文章有「洋蔥」兩個句子中的洋蔥是不同的。這時候,使用上下文嵌入 (contextual embedding) 的方式就可以解決,例如 BERT 模型。透過 BERT 模型得到的上下文嵌入特徵,就可以輕易的使用分類器 (Classifier,例如 Bi-LSTM + CRF) 來完成 NER (如圖五)。
個人化推薦
有了 NER,其實就已經可以做自動上標籤了,但是怎麼把這些標籤做排序,變成了另一個問題。由於每個人有不同偏好,在意的商品特性也不同,透過使用者的點擊狀況,建立強化學習 (RL-based) 的個人化模型,可以用比較動態的方式來調整排序。最後,講者也展示了一些實際案例,以及如何量化「讓顧客在平台上逛久一點」這件事來訂定上線後的關鍵指標。
Application「應用例」議程:Keep Learning Keep Journey – 誰要去他鄉?出國預測實作
講者:吳璧羽 (Peggy) @ 玉山銀行
除了電商的應用情境之外,我們也聆聽了金融業者如何透過機器學習來改善使用者體驗、創造有溫度的服務。據交通部觀光局統計,2019 年國人出國總人次已達將近一千七百萬,而出國旅遊消費總支出則達近兆元 (出處)。如此龐大的商機,身為金融業者的玉山銀行當然不會放過!如何提高本行信用卡的海外簽帳金額成為至關重要的議題。接下來,我們就從「目標定義」、「模型訓練」與「成效評估」三個階段,來看資料科學家 Peggy 如何解決業務端最實際的需求吧!
目標定義
常常業務目標並不等同於模型目標,資料科學家必須透過精巧地設計來讓模型目標與業務目標產生連結。在業務人員希望提高海外簽帳金額的需求下,Peggy 認為模型目標不應該是直接預測每個人的海外簽帳金額,而是找出未來一段時間內會出國的人,這樣才能在對的時間向對的人進行行銷,吸引他們使用本行信用卡做海外消費。
有了建模目標後,就要決定目標變數的定義,例如一段時間是指多長呢?一個月、三個月、半年還是一年?以及怎麼知道用戶真的有出國的行為呢?
- 觀測時間方面,必須配合業務單位的行銷模式與模型評估的表現來決定,過程中嘗試過近一個月至六個月,最後是以「近三個月」作為觀測長度,不只模型成效最佳,也符合實務上檔期的安排。
- 出國行為方面,不單用真實海外實體消費資料,也搭配海外 IP 模糊比對、國外 ATM 提領等資料來進行貼標,如此一來便能擴大母體的範圍,讓模型更能泛化到每一位用戶。
在定義好目標變數為「近三個月是否有出國」後,即可確認要解決一個二元分類的問題 (當客戶在近三個月內出國,則目標變數為 1;否則為 0),接著就能進行特徵功能與模型訓練!
模型訓練
訓練模型之前,必須先針對每一位用戶產生相對應的特徵來描述他們的輪廓,好讓模型得以透過這些特徵來學習判斷該客戶是否會在三個內月出國。由於銀行業者可提供客戶全方面的金融服務,故在特徵工程能有較多面向的著墨。Peggy 利用客戶過去 180 天 (六個月) 在本行所累積的的各項資料來進行特徵工程,總共可歸納為七大層面:
| 層面 | 特徵範例 |
|---|---|
| 顧客基本資料 | 年齡、性別、往來年限等 |
| 帳戶資料 | 帳戶餘額、持有賬戶類型等 |
| 本行貢獻度 | AUM、獲利資料 |
| 信用卡持有狀況 | 持有特定卡別註記等 |
| 顧客外幣交易 | 近期外幣買賣、提領紀錄等 |
| 客服進線狀況 | 是否進線、進線問題類別等 |
| 信用卡交易資料 | 海內外交易與特定消費的頻次和金額等 |
決定好特徵工程的方向後,接著就是準備訓練資料、驗證資料以及測試資料,藉此資料科學家才能建立出穩健、可信的模型。
由於預測的目標是有時間性因素的,所以在資料切割上必須採取移動窗格的方式 (Walk-forward Split),例如使用 2017/09 ~ 2018/06 這段期間的資料來產生訓練資料;使用 2018/12 ~ 2018/09 這段期間的資料來產生測試資料。如此一來,模型在學習、驗證的過程才能與實務上的使用情境相一致。最後,Peggy 使用微軟所開源的 LightGBM 模型來進行二元分類任務的學習。
成效評估
根據測試資料集的結果,相較於傳統業務單位所制定的 Rule Base 方法,LightGBM 模型在各項評估指標 (e.g. Precision, Recall, AUC) 上皆有明顯的提升。甚至只要抓出模型預測 Top10% 的客戶,就可以掌握 52% 會出國的人呢!如此一來便能大幅地降低廣告的投遞成本與干擾用戶所造成的損失。Peggy 也在最後提到模型並不是萬靈丹,在找出可能出國的客戶後,後續的行銷活動也仍需經過嚴謹的隨機對照實驗來驗證其成效,例如提高回饋率是否能顯著提升簽帳金額等,藉此來最大化海外簽帳消費總金額。
結語
雖然這次的線上研討會,在一開始有因為技術問題,導致一些行程延後,但就內容而言,還是非常的充實的。在 LINE 中,秉持著 Closing the Distance 使命,對於龐大客戶資料的基礎建設、如何有效導入資料工程與機器學習技術、以及如何活用這些技術到應用面,都是我們很認真看待的事。在這個研討會中,我們聽到了一些與我們正在做的很類似的應用,像是在這個心得中提到的電商商品 hashtag 應用,就與我們的 LINE 購物非常相關。為了讓顧客可以逛久一點,我們也有透過使用者的搜尋內容,建立模型來推薦他們可以再查找的關鍵詞。而對於預測客戶未來行為的議題,在考量廣告內容對用戶有差異化的影響之下,希望盡可能地提升用戶的購買意願與最大化廣告投資報酬率,我們也有開發增益模型 (Uplift Modeling)。另外,也接觸到了一些以前沒有用過的工具與方法,像是 Data Sketches 還有 TensorFlow on Spark,希望在未來,可以導入這些方法,讓我們的服務更棒!最後,很感謝公司鼓勵大家參加外部的研討會,相信今後對於加強資料基礎建設以及將機器學習應用在產品面會有很大的幫助。