
DataCon.TW (Data Conference Taiwan 台灣資料工程年會) 是由 Taiwan Hadoop User Group、Taiwan Spark User Group、Taiwan Flink User Group、Taiwan Fluentd User Group 等社群成員共同發起的台灣資料工程協會(Taiwan Data Engineering Association)所主辦,是 Hadoop、Spark、Flink 及大數據相關領域研討會 。
DataCon.TW 的前身是Hadoop TW,今年是第十屆會議,今年的年會活動以「開發者」、「營運者」、「應用案例」三大主題分軌進行專題講座活動。
資料科學已經被廣泛運用在許多領域上,也取得了相當好的成果。希望藉由參與本次會議,隨時跟上資料科學的最新議題,在我們的相關服務上也可以有很好的發揮。
Keynote議程: Top 5 Big Data Project Myths I faced in last 10 years
講者: Jazz Yao-Tsung Wang / Chair @ Taiwan Data Engineering Association
今年的 DataConf 由台灣資料工程協會理事長 Jazz Wang 揭開序幕,理事長提到了在近十年來,大家對大數據資料的六個迷思。
Miss 1: 為了效能問題,把現有應用通通搬上大數據平台 (e.g. 改用NoSQL/MPP來取代RDBMS) (?)
並非搬上大數據平台就能改善效能,需視你的應用而定,再來決定使用NoSQL還是RDBMS。在傳統資料庫中,一個資料表的schema是在資料載入時就被強制套用了,可以針對欄位做索引,並對資料做壓縮,讓查詢的效率比較快,但代價是它必須花較久的時間來把資料載入資料庫,屬於schema on write。Hive不會在資料載入時進行驗證,相反地它只有在進行查詢時才做驗證,初始化載入可以很快執行,載入的操作也只是檔案的複製或搬運,屬於schema on read。簡而言之,如果你的應用以寫入居多,那使用NoSQL是合適的,如果以查詢居多,MySQL是合適的。
Miss 2: 用大數據平台取代傳統資料倉儲/資料庫 (?)
大數據平台與資料倉儲是不同的概念,Data Lake放的是raw data,Data Warehouse則是存放分析過的資料。
Miss 3: 用大數據平台,因為平行化一定跑得比較快 (?)
資料運算時間一定大於資料傳輸時間,所以資料運算複雜度才是速度的關鍵。
Miss 4: 衡量大數據專案的成功與否,可用「有多少內部應用改用大數據平台」這個指標來衡量 (?)
這個並非是對的指標,應該是要以能創造多少企業價值為指標。
Miss 5: 剛開始導入大數據平台當然就要先符合資安規範 (Ex. ISO27001) 跟隱私規範 (Ex. GDPR) (?)
理事長建議,先求有再求好,先確定平台是有價值的再考慮資安的問題,不需要一步到位。
Miss 6: 誠徵大數據人才,熟悉以下系統為佳:Hadoop, Hbase, Phoenix, Spark, Kafka, Flink…薪資面議 (?)
理事長認為,人才的流失來自於 1. 市場的低薪以及高端人員的出走 2. 學校供給不夠快,應該要從這兩方面來改善人才問題。
Keynote議程: Machine Learning Model Experiments and Deployment
講者: Josh Yeh / Software Engineer @ Cloudera
本議程講者Josh來自Cloudera,該公司是業界知名的hadoop方案提供商,看起來也將部分重心從大數據處理移到AI/ML的total solution方面,比對各家網路龍頭公司,如facebook、uber、google等也都公布他們的AI/ML平台,對比過去幾年談到AI、ML時總把重心放在deep learning的架構與框架及應用上的突破等。而最近1年來因AI/ML在業界落地到一定程度後,業界逐漸把目光放在解決從資料處理到model部署等更實務問題,如:如何執行ML得更快更有效率?如何更自動化?如何reuse減少資源浪費等等,總括來說也算是engineering的範疇。
講者一開始以facebook每天執行200 trillion次預測(1秒500萬次)的現況,這樣的挑戰已經不是找到最新deep learning演算法就可解決的,而是需要從資料處理到model部署面面俱到的整體架構。
以下整理講者介紹整個AI/ML執行過程一般包含哪些工作,以及會遇到哪些問題與解決方向。
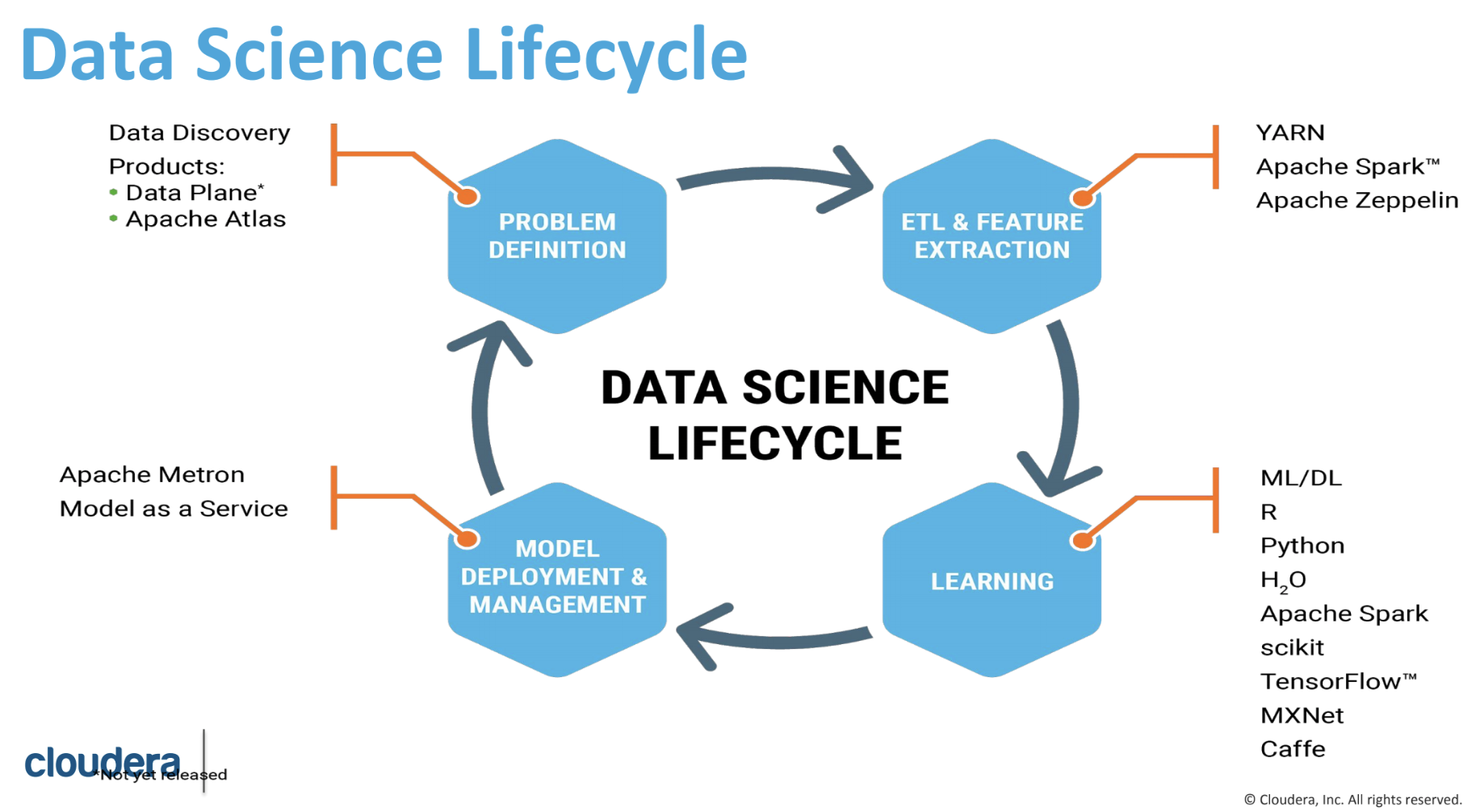
出處:cloudera
| 工作 | 遭遇問題 | 解決方向 |
|---|---|---|
| 資料探索 | 工具、硬體規格 種類版本太多,難以快速自行建置、管理 | Containerization, Containerization orchestration |
| Model實驗 | 如何管理不同model及其實驗過程?(可能達上萬個model版本)如何針對每個model有效測試不同hyperparameter每個model需要多少資源才能快速訓練?model用新資料重新訓練的頻率? | model倉儲管理系統 |
| Model部署 | 如何很快速將訓練好的model部署到線上並收集反饋? | serverless deployment |
講者提到處理個別工作的問題外,一套良好的流程整合系統也是關鍵,類似軟體開發常用的CI/CD觀念,以幫助使用者知道目前工作執行到哪個階段(如:資料處理),進而分析哪個工作需要優化(如:訓練時間太久),及監控線上的綜效(如:某model準確率比上個版本好12%)等,這都是平台欲解決的問題。
關於AI/ML平台的未來趨勢,講者的看法如下:
- 分散式學習的強化 (Distribute Learning)
- 轉移學習 (Transfer Learning)
- 無伺服器部署 (Serverless Deployment)
- 邊緣裝置 (Edge-device)
比較各家AI/ML平台似乎現在還在百家爭鳴階段,不像container orchestration或是CI/CD已經有幾家主流方案再主導。如Uber的michelangelo平台著重在model, feature重用與online/offline流程分離,google ML平台則側重於分散式學習的效率。由此可知,目前每家企業的需求還是很分歧的階段,另一方面在大方向的工作流程上也逐漸在收斂,似乎可以預期分歧的情況還是會持續一陣子,但最終應該是有機會發展出類似container orchestration或CI/CD讓業界重用的框架。
應用案例講題分享: Apache Kafka 的架構與應用
講者: 江孟峰, 亦思科技執行長
從今年會題的主題看來,Hadoop Spark Hive已經不是重點了,多了許多Kafka與Flink的分享,可見streaming technology是目前的趨勢,亦思科技的執行長江孟峰從應用的角度切入,認為Kafka是未來一年需要關注的技術。大數據平台的演進,事實上是個從需求而來的演進,都是先有需求再研發技術,一開始大家希望有個分散式檔案系統,因此Hadoop誕生,接著希望能用SQL語法查詢,因此有了HBase,為了改善分散式系統的運算效能產生了Spark,希望有個streaming process將資料源源不絕的流入,因此產生了Spark Streaming, STORM, Flink, Kafka Streams等技術,為了有high throughput message queue而有了Kafka,資料處理也從batch到了real time。
以往ETL的重點在於轉換,以及目地儲存在哪裡,企業在評估使用Kafka的重點在於,是否可以支援多種format以及存在多種storage,是否來源量的throughput很大 ,假設你的資料只是從一個來源複製到另一個,直接透過一般網路傳輸即可,假設你的來源與目的是多對多,而且會需要隨時擴充,那Kafka會是個好選擇,Decoupling的特性讓Kafka可以快速的擴充而不需要改動到程式碥。Kafka適用於一些即時的應用,包括即時的庫存管理,生產控制,線上討論,線上商店的即時處理、即時銷售情況(dashboard)、用戶追蹤位置等相關應用。
應用案例講題分享: AI at PIXNET
講者: 施晨揚, PIXNET
接下來參加了 AI at PIXNET 這一場演講。可以想像,PIXNET 平台上擁有龐大的 UGC (User-generated content) 內容,機器學習有絕佳的利用機會。這是一場比較軟性的演講,從團隊建立的角度出發,首先介紹一個資料團隊所需要的人員結構,彼此如何分工。在PIXNET的AI團隊內,組成人員的專長分成以下幾種:
- 演算法設計開發:ML, DL, Spark, scikit-learn, NLP, TensorFlow
- ML系統建制:Spark, Flask, GPU Server, Elasticsearch
- Insight分析師:BigQuery, DataStudio, Jupyter, Statistics, Dataprep, Metabase
- 跨領域:心理學
這些專長大致上與企業界公認的 Data Engineer, ML Engineer, Data Scientist, Data Analyst 所需的技能相同,其中一個比較特別之處,是採用了心理學相關領域的專長在其中。
接著介紹在企業內,他們如何以人工智慧技術幫助政策制定,改善產品品質,提升市場滲透率。
人工智慧畢竟還不是一個很容易理解的技術,大家對於人工智慧還有太多電影上的想像,不太理解如何把人工智慧技術落實在產品的改善上。講師根據經驗,介紹如何把人工智慧技術帶入產品開發生命週期的流程內。講師把整個週期分成以下階段:
- Problem definition (定義問題):將人工智慧落地,最困難的就是這一點,定義問題。將一個產業上實際的問題,轉化成一個人工智慧能解決的問題。最重要的一點,就是要先能想像,並確認期望得到什麼結果。
- Modeling (將問題模型化):定義好問題後,就需要選擇一個適當的模型來描述,解釋,並預測這個問題。不同的模型有不同的適用情境,不同的訓練成本。在眾多模型中選擇適當的模型並不容易,講師建議大部分情況下從簡單的開始。
- Data understanding(理解與分析資料):近年來,人工智慧的解法都脫離不了大數據的支持,蒐集與理解需要哪些資料以及其型態就成了必要的一環。在導入前,必須分析收集資料的輸入/輸出的格式,是離散或連續,文字或聲音或圖片或影像,是批次的蒐集還是即時的,才能有效處理蒐集到的資料。
- Deployment(部署到線上環境):最後,就需要將開發完的系統搭配訓練好的模型部署到線上。人工智慧的應用與一般應用,在上線前的測試與部署都不相同。基於演算法的人工智慧應用免不了都有不夠準確,或訓練不足的地方,如何在上線前確保準確度達到一定水準?如何在上線後持續收集反饋並優化模型?都需要特別注意。
機器學習理論與實際應用的系統有不小差距,在應用到實際問題時,幾乎都是將問題所處的情境簡化,在簡化的條件下才會有比較好的效果。
開發者&營運者講題分享: 104 AI chatbot using ElasticSearch and deep learning
講者: 林宗甫, Trend Micro
在big data的應用方面,AI相關的題目仍然是熱門的主題之一,業界也紛紛舉辦AI的比賽。趨勢科技的隊伍於今年7月參加了104人力銀行舉辦的黑客松:AI chatbot的比賽中,獲得了第一名的殊榮。
而在104 AI ChatBot這場演講中,趨勢科技的隊伍分享了他們的參賽過程,如何針對不同的題目來設計不同的方法。比賽的內容為設計一個可以回答104網站中各公司資訊與勞基法相關問題的聊天機器人(ChatBot),評分方式分為是非題、選擇題與填空題,問法則可能是一字不變、稍做變化與換句話說的難易。這種類型的題目在AI中屬於Qustion-Answering(QA)的領域,問題主要分為open domain(例如: siri,可以回答任何領域的問題)與close domain(只處理特定領域的問題);而方法主要分為IR-based、knowledge-based與machine learning(neral network / deep learning)的方式。在這個比賽中,很顯然是屬於close domain(104公司資訊與勞基法)的問題,講者的隊伍在一開始選擇了IR-based的方法,使用Elasticsearch的highlight source技術來找到與問題最相近的文本內容,透過定位句子(anchoring)並與問題相減來找到可能的答案。這個方法在問法一字不變或稍作改變的時候有很好的效果,但當問題被換句話說後,結果變得非常差,於是他們決定在當問題是換句話說的題型時,使用deep learning的方法。
在deep learning的方法中,他們選定用context2vec的技術,利用正反向的LSTM模型(bi-LSTM),將句子與句中相對應要填空的字放進模型訓練(如下圖)。當然,要訓練模型,標記的訓練材料就會變得很重要!講者的隊伍利用主辦單位不定期丟出的測驗題目來做標記,收集的300多題的材料做訓練。老實說,300多個標記資料在deep learning的模型訓練中,算是相當少的訓練材料(通常都是上萬筆),可能會需要做up-sampling等動作,但講者在此沒有特別提到。最後講者分享了能獲得第一名的一些小技巧,例如在最後一關比回答速度時,他們去找出舉辦單位server的所在地,並把ChatBot的機器也移到當地,非常聰明!
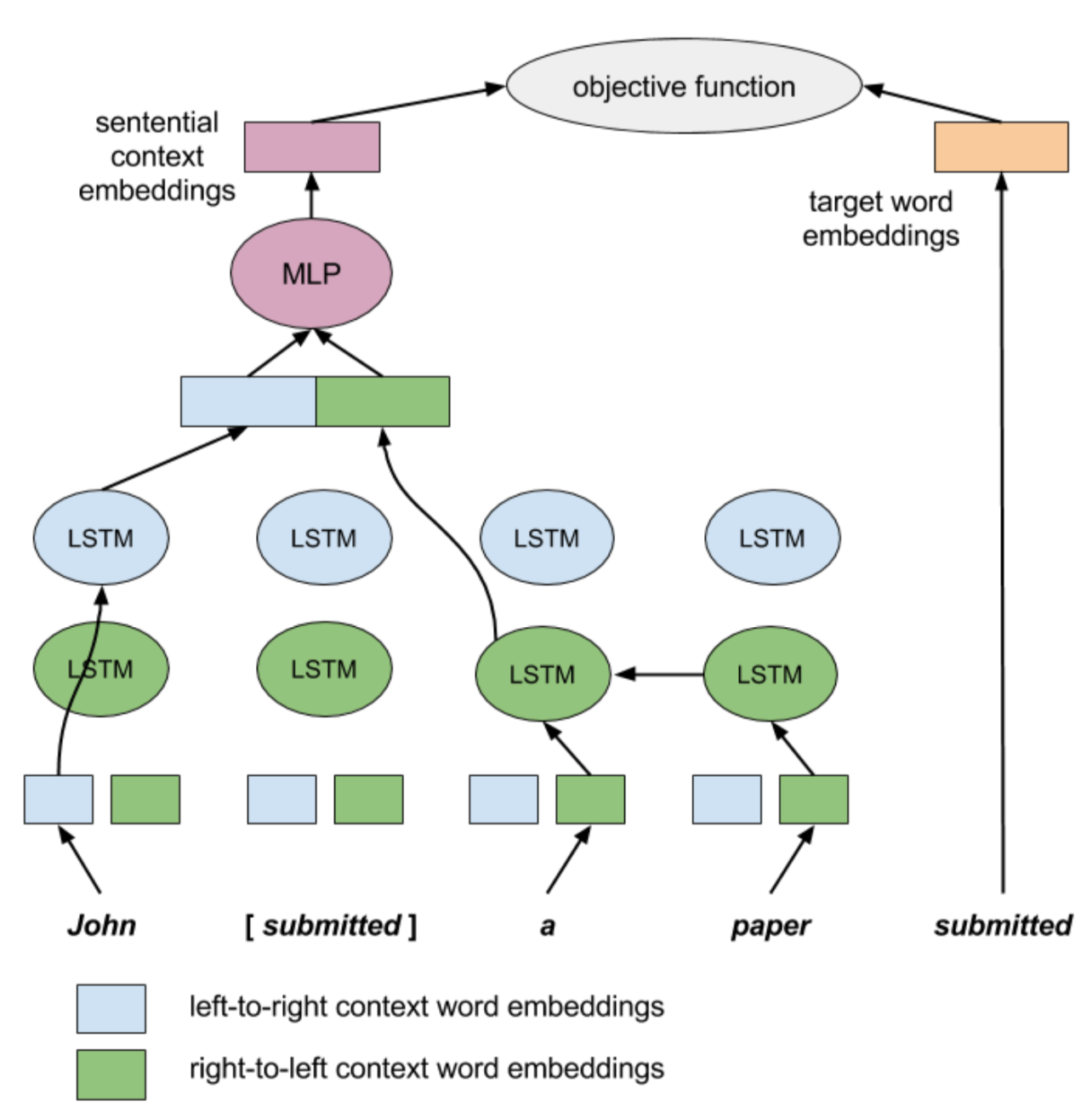
出處: context2vec: Learning Generic Context Embedding with Bidirectional LSTM. Melamud et al., 2016 [pdf].
在這個演講中,我覺得很值得學習的一點是,他們針對不同的問題,選擇使用不同的解決方法,雖然現在deep learning很火紅,也許建一個模型就可以回答所有答案,但是有必要嗎?但是如果問題很簡單,用簡單的IR技巧就能快速解決,就不需要浪費資源在建立模型上,而deep learning的使用上也是有它的限制。所以當我們面對要處理的問題,專注於問題,才會找到好的方法。
結語
聽完DataCon.TW的演講,發現LINE TW目前在資料工程與資料科學所使用的技術應用,都有在大趨勢上,例如資料串流上使用Kafka,在語言訓練的deep learning模型上也用到LSTM等;另外也得到需多新的觀點跟方法很值得參考,例如在AI/ML的平台的建立方面,LINE福岡 Data Labs的同事之前也曾經在開發者小聚上分享過LINE Fukuoka的ML Platform,如果把cloudera演講中提到的幾個未來趨勢考慮進去,將來也可以對我們的平台做優化。大數據領域的技術翻新得相當快,透過參加這樣的活動,可以看到同樣在業界的夥伴們,都使用什麼樣的技術來解決問題,並回頭檢視及調整自己的方法,是一個很好的學習與交流管道。
很高興可以參加此次研討會,所見所聞都對開發資料相關應用很有啟發,期待可以在接下來相關的研討會與各地開發者有更多交流機會。