
前言
訪談節目會邀請各工程團隊成員來分享在 LINE 學系到的經驗分享,讓對於我們團隊日常工作、作業方式、各種解決方案、讀書會...有興趣的開發者朋友可以透過線上的方式來聆聽成員分享,當然過程中還會分享許多講者們的個人實戰經驗,廢話不多說,跟著我們一起往下看吧!
訪談影片
開場介紹

LINE 除了通訊外還有很多周邊的服務,像是新聞、購物、旅遊、音樂、貼文串等等。
而且這些服務其實產生了大量的內容。Data Dev 團隊透過許多機器學習、統計方法等等技能,可以更了解內容之間的關係、內容與使用者的關係,進而優化這些服務的使用者體驗。
另一方面,兩位講者也分享經驗,其實 LINE 也是一個大家很重視的行銷工具,我們有官方帳號,以及許多廣告版位。透過使用者與各服務的互動,我們可以更全面了解使用者的輪廓與偏好,精準的區分出目標客群,來做商業上的應用。所以實際上涵蓋很多技術的應用!
除了知識圖譜、POI、許多推薦系統以及增益模型 (Uplift Modeling) 來找出搖擺使用者,也因為各服務有許多文字內容,我們也做了基於自然語言處理 (NLP) 的服務,像是文章分類,命名實體辨識 (NER),自動關鍵詞擷取,甚至是文章生成,有些服務其實可以很有效的結合我們提供的服務,像是訊息查證服務就屬於此類,接下來會介紹有涵蓋到的一些應用。
訊息查證
Johnson:
訊息查證的運作方式是以兩個功能來完成:
- 假訊息搜索
- 被檢舉的文章分類
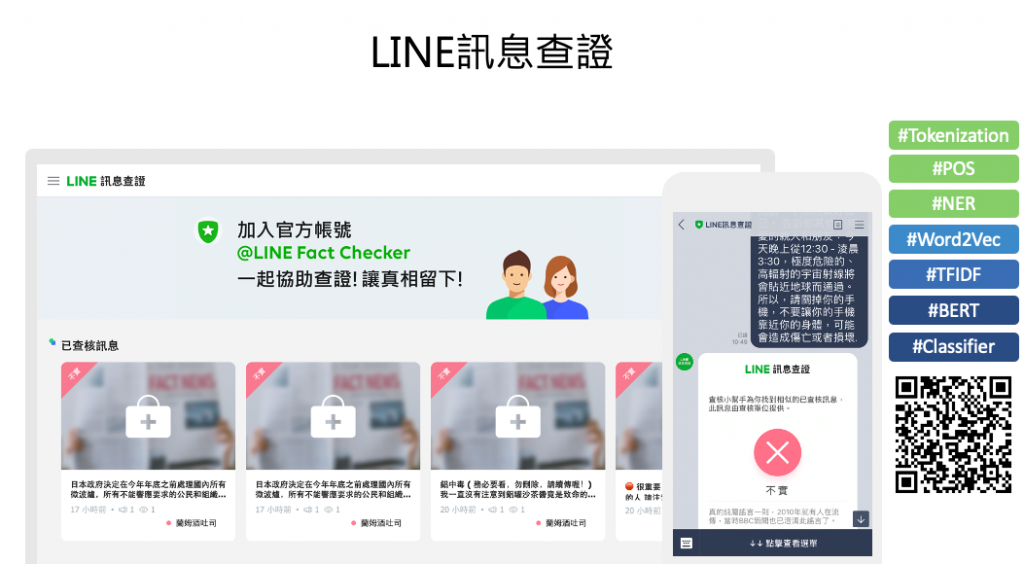
用戶可以在官方帳號上提供/檢舉訊息內容或來源,後台會使用到由我們開發的近似文章搜尋模型,來與我們現有的假新聞資料庫做一個比對,如果有很類似的文章被找到,代表他是假新聞的可能性非常高,可以作為用戶查證的結果。
而當新的假新聞出現時,我們則需要第三方合作夥伴來人工驗證訊息的真偽;而為了加快整個人工查證的過程,我們透過分類文章的功能,加速了尋找專家跟判斷訊息專業領域資訊的過程。
模型的細節上,我們使用目前比較常見的自監督式學習 Bert 系列的模型在文章分類的功能上,接著進一步搭配最鄰近搜索的演算法,透過自監督式學習模型將文章編碼並做好類似 index 的做法,來實現近似文章搜索的功能。
我們使用了預訓練好的 Sentence Bert 模型來做文章編碼,finetube ELECTRA 模型在少量的假新聞資料集上來做文章分類。
加入訊息小幫手,一起協助查證

關於訊息查證,講者 Johnson 也在過去的活動中提過 - LINE 開發社群計畫: 20200707 Test Corner #26 聚會心得
Penny:
有了厲害的模型後,我們需要把模型上線,比較好的整合方式就是把它包裝成一個 API,接下來就遇到了以下的問題
- 假訊息病毒碼一直在更新,內容千變萬化,模型也必須一起更新才行,因此需要建立自動化的 pipeline
- 訊息查證只是眾多 LINE 服務裡面的一個服務,如果將來有另一個也需要可以找相似文章或做分類的話,像是旅遊文章的分類等等,我們豈不是要重頭做一遍?
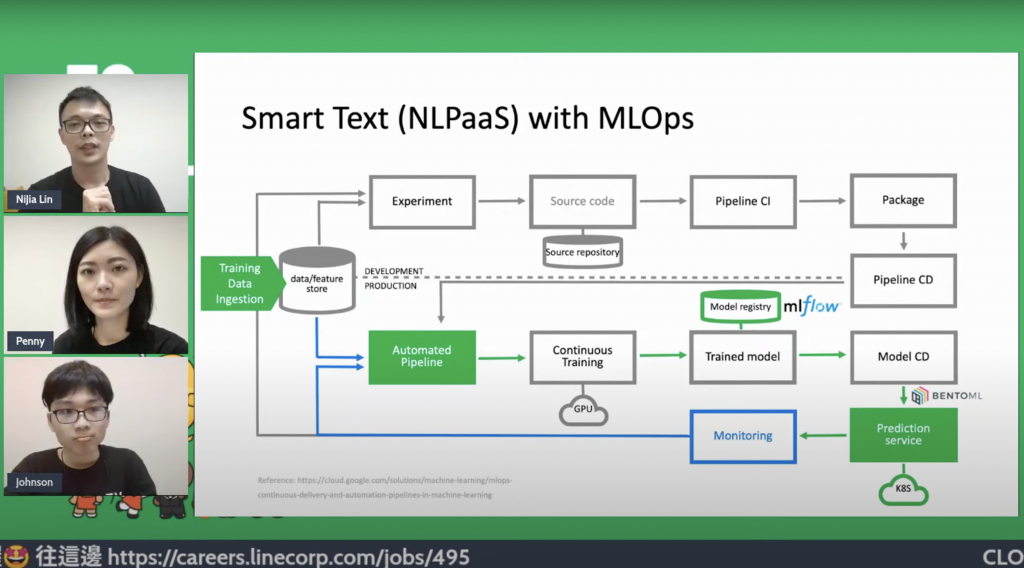
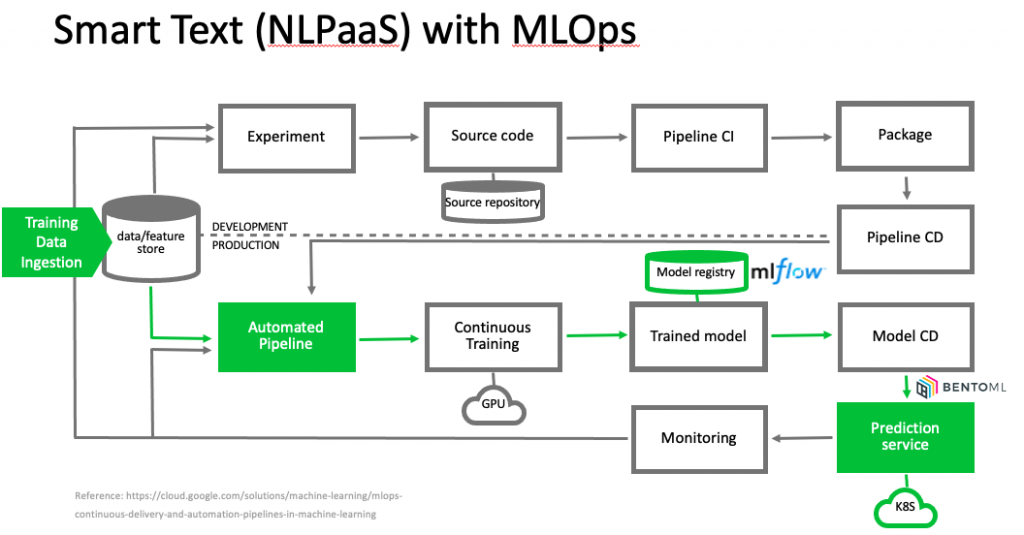
於是我們開始思考,是不是有一個系統可以解決這些問題,我們的 Smart Text 專案就因此誕生。
簡單來說,Smart Text 可以讓使用者自己提供要訓練的資料,透過我們的平台,選擇任務 (e.g. 分類、近似文章搜尋)、訓練,產生一個可以整合到他們服務的 API,使用者不需要做任何開發,就可以享有 sota 的模型結果。
實際上,LINE 內部有非常多的內容服務,像是 LINE TODAY 的新聞文章、LINE SHOPPING 的商品描述、LINE 旅遊的景點描述等等。
為了讓這些服務都可以建立客製化的模型,我們建立了可以區分不同領域訓練材料的資料庫,針對不同任務建立各自的自動化 pipelines,整個系統運用了 MLOps 的概念,pipeline 除了基本資料準備,模型訓練外,我們加入了 MLFlow 做模型版本控管,並且用 bentoml 做模型打包成 API 來部署到 Kubernetes cluster 上。
- 對模型開發者來說:
- 當有任何模型結構或邏輯的改變,只需要更動 code,就可以一鍵部署整條 pipeline。
- 對使用者來說:
- 如果發現模型效果有衰變的現象,可以加入新的資料重新啟動訓練,產生新的模型部署,服務端不需要做任何更動。
Smart Text 其他應用上有沒有使用的挑戰呢?
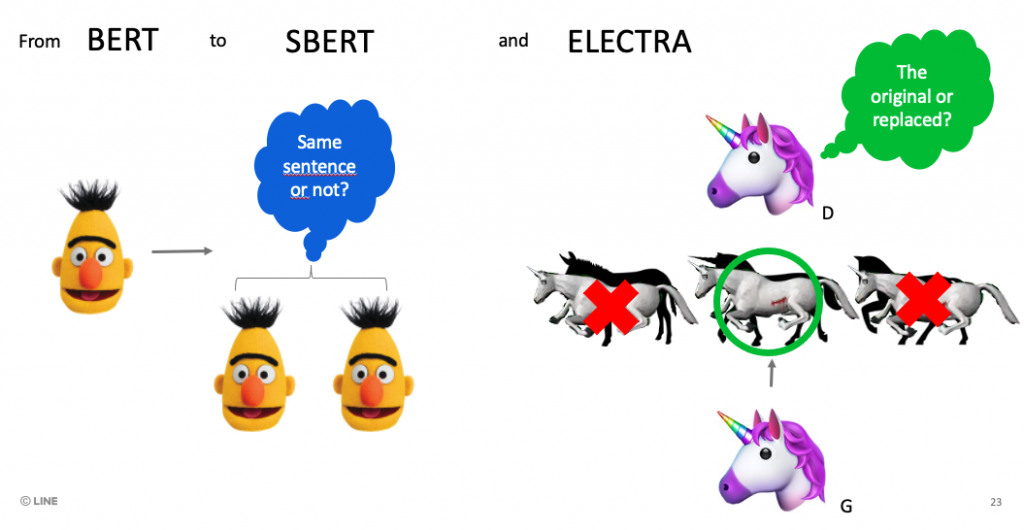
像剛剛提到使用 Bert 系列作為起點,其實是這一兩年來的模型升級。在資料方面的改善是最困難的,要如何盡可能地收集到假新聞其實很花時間,在我們這邊因為沒有擁有資料,所以其實只能透過 data augmentation 來增加資料的多樣性。
而在模型方面,經過研究文獻,最早期的 bert 其實長文章的 embedding 表現上,並沒有辦法有效區別出相似與不相似內容的文章,所以後續更新有使用以孿生網路訓練 bert 模型的 sentence bert (SBERT) 來加強文章編碼的效能。
在文章分類方面,為了加強模型分類準確度以及部署效率,我們也應用 Google 提出 ELECTRA 這種類似 GAN 訓練架構的 transformer model 來加速模型預測效率以及準確度。
模型使用者不懂
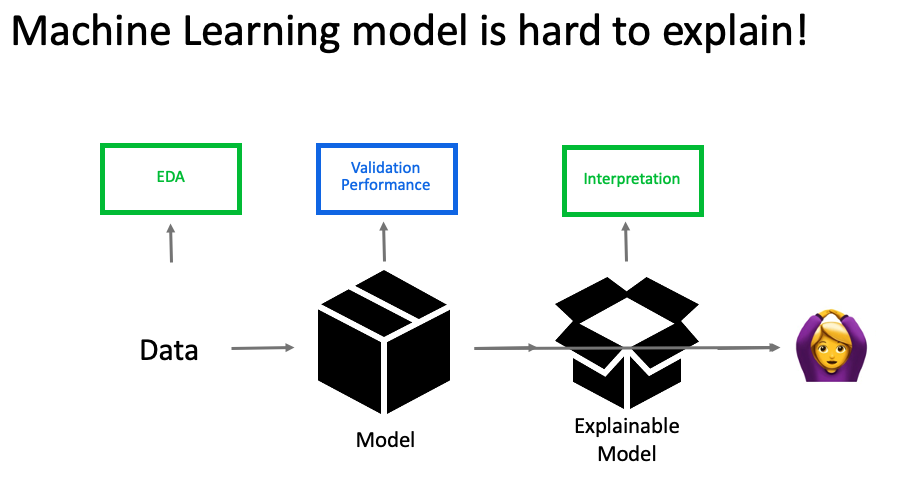
對於不懂模型的使用者來說,最痛苦的可能會是模型對他們來說是一個黑盒子,不知道要怎麼解釋為什麼上次猜對,這次卻猜錯了?
Penny:雖然我們在模型上著墨很多,但 Smart Text 在大部分的使用情況,會是一個 data centric 的 AI 平台,也就是說,使用者要在模型結構不更動的情況下,靠更動手邊的資料,讓模型可以猜得更準。
於是要怎麼樣可以引導使用者放入比較好的資料來訓練,可能是做 EDA,以及模型訓練完後,要怎麼樣讓使用者很清楚的知道,這個模型,為什麼會這樣猜,可能需要提供模型解釋,就會是我們接下來的挑戰。
吸引你的部分或是成就?難在哪?
Penny: 我覺得把一些 ML pipeline 上一直重複發生的問題用工程的方法來簡化,有帶給我蠻大的成就感。過程中遇到的困難是,整個 pipeline 上會有不同角色的參與,要對整個流程做改善的話,可能需要跳脫舒適圈,了解更多其他角色的工作技能,像是要多一些 DevOps 的技能,模型開發的技能等等。
Johnson: 當然是能看到有許多 end-user 在使用我們的服務這點,可以感受的自己開發的功能能被很好的使用到,是非常有成就感的。
困難點的話,其實不外乎是要持續的改善模型這點,有時候為了改善準確度,必須不斷地做實驗、改參數、改資料這樣的循環,其實是每個做機器學習的應該都有的體悟,雖然做到最好很困難,但是這是必須要做的才能讓成果更好。
讀書會

我們的讀書會有點像重回校園的感覺,成員會招集公司內部不同團隊中對 data 有興趣的同事一起參加,大家會一起決定要讀的書目,一年大概會讀兩本書,內容涵蓋很多元,包含 data 相關,機器學習,生成模型,強化學習及 MLOps 都有,用分組的方式進行導讀。比較特別的是,我們會進行期末專題實作,每個組別會選擇跟工作相關的專案,導入書中所學到的技巧。好處是這些期末專案在未來,很有可能會發展成一個內部的正式專案。
像是:LINE 熱點的 POI 推薦,就有用到強化學習的概念,還在實驗階段的自動摘要生成,用到生成模型等等。
團隊的職責組成
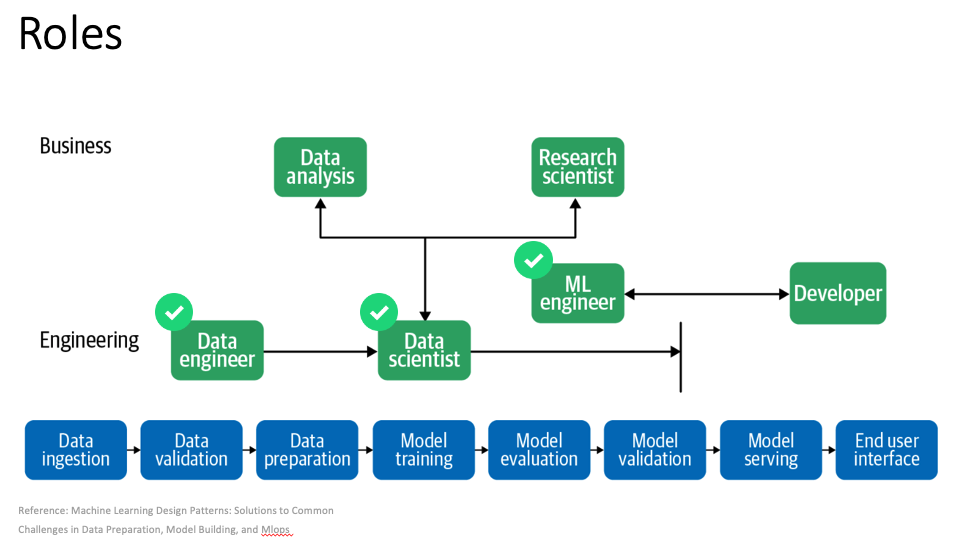
這邊借用 machine learning design pattern 裡面的這張圖,解釋目前我們 team 的角色。以 machine learning pipeline 來看,我們有資料工程師,負責處理資料的 pipeline,資料科學家,負責模型的開發以及挖掘資料 insight。
另外還有機器學習工程師,負責把實驗好的模型整理上線,並確保上線的品質符合服務端的需求。而資料科學家會比較頻繁的跟 business 端的分析師合作,機器學習工程師會跟服務端的工程師合作。
面試 tips & Q&A
Johnson:我覺得最重要的特質是對問題解法能有一個完整規劃的能力,我們蠻喜歡跟面試者一起討論怎麼解決的一個困難的問題,能夠知道你有什麼特別的理解,為什麼這麼做,這麼做的好處是非常有幫助的。
Penny:不論是資料工程師,資料科學家或是機器學習工程師,都離不開 data, 都會需要撈取資料,所以 SQL 是我們必備的能力,基本上是必考!
Q: Whats your tech stack for data lake, data analytics, and stream processing?
A: 我們有總部開發的 Data Platform,
- Data Lake 會基於底層的 Hadoop Cluster。
- Data Analytics 會在上面建立一些內部的 BI 工具,也有使用 Tableau。
- Stream processing 的部分有使用 kafka。
Q: 可不可以多著墨如何針對黑盒子如何 interpret?以及如何 convince 主管?
針對很難解釋的模型 (e.g. deep learning model)目前的方法會是像 johnson 提到的,提供 performance metrics 的方法,但是對於不懂模型的使用者來說,metrics 本身要解釋可能也是一門藝術,如果要專注於“打開黑盒子“的方法,目前有一些可解釋模型可以使用。像是 LIME 或是 SHAP
LIME 是用使用在 sample 附近建立簡單的可解釋模型 (e.g. linear model),就可以解釋某個 sample 的結果;
SHAP 是用 Shapley Value 找貢獻值的概念,找出影響模型推測的原因。例如訓練一個情緒分類器,解釋模型可以做到:
我没有感到被羞辱 -> 判斷為"悲傷"類別可能是因為 "羞辱" 這個詞
用這樣的解釋方式,可以讓使用者用不同 sample 去看實際模型的運作是否如同所想的那樣。
看使用什麼模型,當然我們自己看可以觀察最底層的 train/valid loss 來觀察收斂狀況,也可以透過一些 evaluation metric e.g. f1-score, ndcg, precision, recall 這些定義好的指標。interpret 的部分,有些模型(decision tree 系列)可以有效觀察 feature importance,也有許多開源的 repo 有提供模型可解釋性的功能可以輔助觀察。
有時候我們也會觀察 embedding 分佈、搭配 label 分佈的合理性。attention based 的模型,我們也會觀察多種 Input 的 attention 變化來判斷模型學習的好壞。
結論
藉由 Penny 以及 Johnson 精彩的分享,相信大家對於資料工程團隊應該有初步的了解吧?在這短短的時間裡面可能大家還有很多想了解的部分,歡迎參考過去成員們分享的相關文章,裡頭也是乾貨滿滿喔!
- 帶你了解 LINE Developers Meetup 第 14 場的精彩內容!
- TechPulse 2019 – Timeline Post Recommender System 議程回顧
- 「How ML Powers LINE Services」機器學習如何的讓 LINE 的服務能更貼近使用者
活動小結
立即加入「LINE 開發者官方社群」官方帳號,就能收到第一手 Meetup 活動,或與開發者計畫有關的最新消息的推播通知。▼
「LINE 開發者官方社群」官方帳號 ID:@line_tw_dev
關於「LINE 開發社群計畫」
LINE 於 2019 年開始在台灣啟動「LINE 開發社群計畫」,將長期投入人力與資源在台灣舉辦對內對外、線上線下的開發者社群聚會、徵才日、開發者大會等,已經舉辦 30 場以上的活動。歡迎讀者們能夠持續回來察看最新的狀況。詳情請看: