
以通訊軟體為核心,LINE持續發展圍繞用戶生活的各種服務,同時也抱持著開放的態度,積極與不同的平台或開發工具串聯。因此,我們鼓勵、更贊助LINE的工程師參與各式各樣的外部研討會,激發更多創意或合作的可能性,並於會後撰寫見聞,分享給LINE Engineering Blog的讀者們。
《LINE 強力徵才中!》與我們一起 Close the Distance 串聯智慧新世界 >> 詳細職缺訊息 (Data Engineer, NLP Engineer)
參與機器學習開發後,能把模型放到真實機器上跑是一件很令人興奮的事,尤其是近年來很火紅的自駕車。因此一聽聞Amazon AWS舉辦機器學習戰鬥營,並透過AWS DeepRacer來實驗自動駕駛賽車模擬,幾乎是毫不猶豫就報名了。LINE的許多服務中,都使用到機器學習,更在今年優化"LINE客服小幫手"這個OA,使用自然語言處理與深度學習技術,開發可辨識語意的AI聊天機器人。因此公司一直鼓勵開發工程師可以參加外部的活動,即使活動辦在上班時間,還是可以請公假參加。
這個活動有三個很大的亮點,第一是使用AWS自家出的自動駕駛駕賽車;第二是使用不需要任何標記的強化學習模型(Reinforcement Learning, RL)來訓練;第三是完成模型訓練後,如果有不錯的成績,可以參加今年6/12, 6/13的2019 AWS Summit,把自己的模型放到usb帶到現場,用真實的AWS自動駕駛駕賽車來比賽,台灣區第一名還可以被贊助飛到拉斯維加斯參加決賽。
這次的活動比較像賽前暖身,教會你怎麼使用自動駕駛賽車模擬器,怎麼調整參數與寫強化學習中最重要的報酬函數(reward function),並使用AWS機器學習的平台來訓練與從log中發掘問題。沒有機會參加到實驗營但也很想玩玩看的人也可以參考這篇中"自駕車模擬實驗營實作"的手把手教學。
什麼是AWS DeepRacer?
大部分人可能都是第一次聽到AWS DeepRacer這個名詞,它其實是AWS出的一款1/18比例賽車,讓一般人可以透過很有趣的方式來學習"強化學習模型"(Reinforcement Learning, RL)。開發人員只要使用AWS的雲端平台,與3D模擬器中的虛擬汽車及賽道,就可以很快速的開發自駕車機器學習模型,並部署到DeepRacer上,就有機會與全球的高手一同較高下。
這部1/18比例的賽車(如下圖),目前只能在Amazon上預購,這次在會場難得有機會摸到實機(如下圖),講者特地把殼拆開,裡面由四輪驅動加裝引擎的底盤,加上搭載Intel處理器與一顆攝影鏡頭組成,其他感應器有整合式加速度器和陀螺儀。


什麼是Reinforcement Learning?
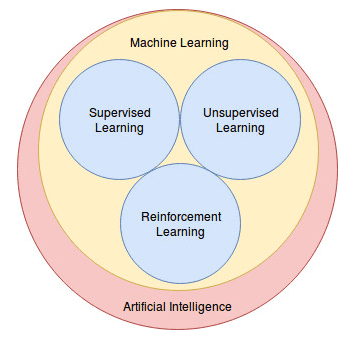
目前的機器學習種類主要分為三種(如下圖): 監督式學習(Supervised Learning),非監督式學習(Unsupervised Learning)與強化學習(Reinforcement Learning),其中強化學習不同於監督式學習,不需要標記資料,又與非監督式不同,是一種互動式的學習。例如要教狗學坐下這個動作,可以透過給狗狗獎勵,讓狗狗自己去探索坐下可以得到獎勵,透過學習把獎勵(reward function)最大化的過程,就是強化學習的核心精神。
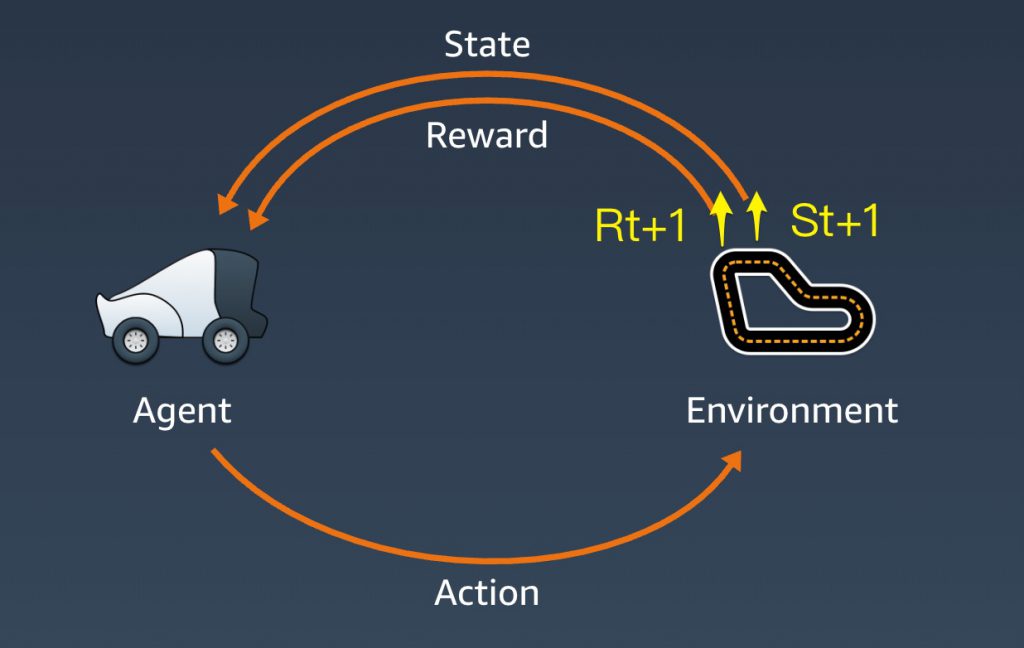
即使之前沒有聽過強化學習,應該還是有聽過AlphaGo 或AutoML吧!這兩個厲害的產品背後都是用到強化學習的技術。所以它到底是怎麼運作的呢?這邊直接以DeepRacer當例子大家可以比較快進入狀況,首先來認識幾個詞:在這邊賽車代表agent,賽道代表environment,state是賽車在賽道中某一時刻的狀態,action則是賽車(agent)在目前state做出的反應,包含特定的速度與方向盤旋轉的角度的組合。最後reward會根據action算出一個回饋的分數。
簡單來說,整個任務是要訓練賽車(agent)去適應賽道(environment),這個agent會將每個時間點觀察到的集合當作環境的state,從環境的state跟reward再去選擇最好的一個action,稱作策略(policy)。強化學習的目的就是要找出一個最好的policy,可以讓reward最多。而強化學習的核心,就是需要去設計這個reward function。
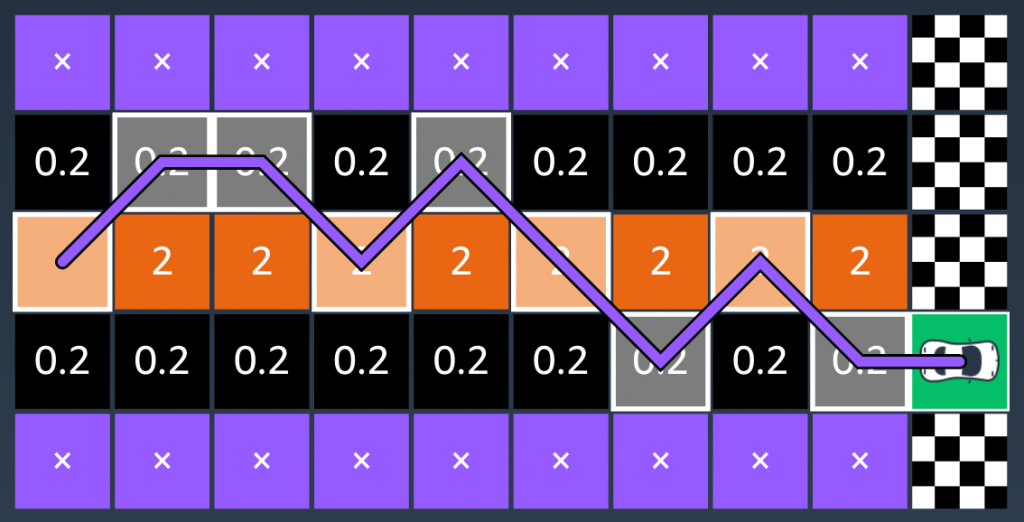
要了解學習的過程,可以把賽道簡化為下列圖表,每個格子給一個分數,愈接近中線分數愈高,當賽車跑完第一趟時(如圖一),可以計算出這趟的分數,學習結果希望分數愈高愈好,因此車子就會不斷的嘗試(如圖二),直到得到最高的分數(如圖三與圖四)。值得注意的是這邊有一個小陷阱,如果reward function設計只單純設愈高分愈好的話,車子最終也許會盡可能走遍所有的格子來達到目的,但實際上這樣卻會花更長的時間才能抵達終點,因此可能需要加入步數的判斷,設定愈少步分數愈高,則可解決這個問題。


DeepRacer其實已經把強化學習的模型部份實作好了,但開放給大家設計reward function的彈性來體會強化學習的精神,在這個任務中,有以下參數是可以加入reward function的: 賽車在賽道的位置、車身與水平的角度、賽道上的位置、賽道的寬度、車身與中心的距離、是否所有的輪子都在賽道上、目前速度、目前角度等。
另外,除了設計reward function外,也可以透過設定action的組合與超參數的調整,來讓模型訓練得更好。接下來就是實作的部分,活動當天因為時間有限,所以實際訓練的時間很少(只有5分鐘),訓練出來的車子連一圈都跑不完,回家後再重新做一次完整的訓練,車子可於37秒內跑完一圈。希望大家透過下面的教學,也能對強化學習有更深的體驗。
自駕車模擬實驗營實作
實作部分可以分為兩部分:訓練(training) 以及評測(evaluation)。賽車模型的訓練目標是在最短的時間內跑完一圈賽道,所以評測的方式會是以一圈計時來作為比較的標準。
DeepRacer的訓練是透過模擬器(simulator)訓練的,也就是其實並不需要靠真實的一台賽車(agent)在跑道(environment)上不斷衝刺碰撞繞圈(action)來學習最快的跑法。所以使用者需要透過AWS提供的simulator來訓練模型。
Pre-requisite Setting
在訓練模型之前需要完成AWS DeepRacer的設定,沒有完成設定是無法建立模型的。當然,你需要事先建立好屬於自己的AWS 帳號(免費12個月)。
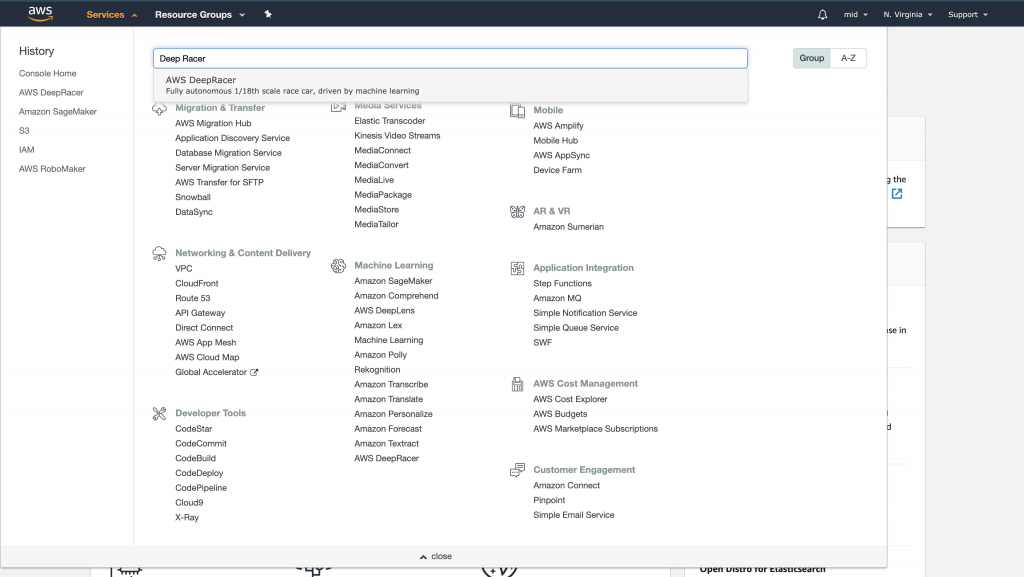
- 首先前往AWS management console (AWS console):如圖所示,前往services>Machine Learning>AWS DeepRacer,或是直接點選services並搜尋 DeepRacer。
2. 使用者將會被導引到AWS DeepRacer的頁面,所有的訓練以及評測將都會在這裡進行。中文介面可以選擇畫面最左下角的語言切換(You may change the language setting at the left bottom corner)。
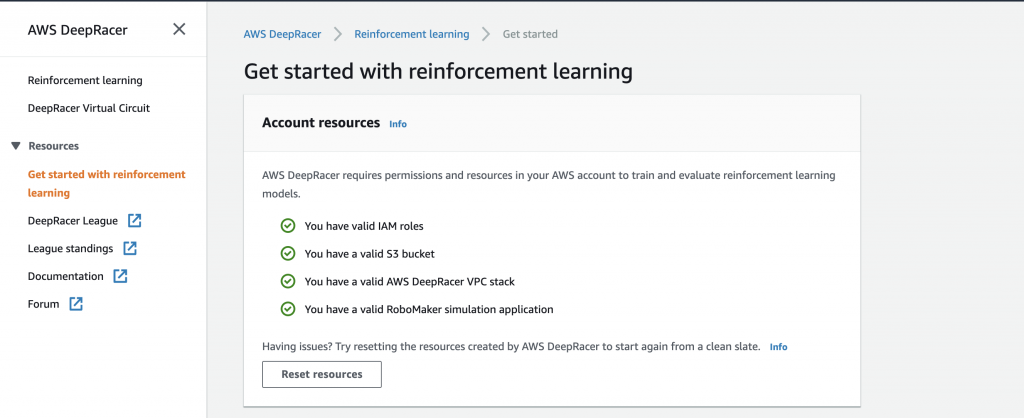
而訓練的模型會陳列在中間的Model List;對於初次使用的人,需要設定好DeepRacer使用權限跟資源。 點選畫面左邊AWS DeepRacer選單下的 “Get started with reinforcement learning”並且點選接著出現的create resources進行設定。

這將會是完成設定的頁面,如此一來就可以開始訓練模型了!
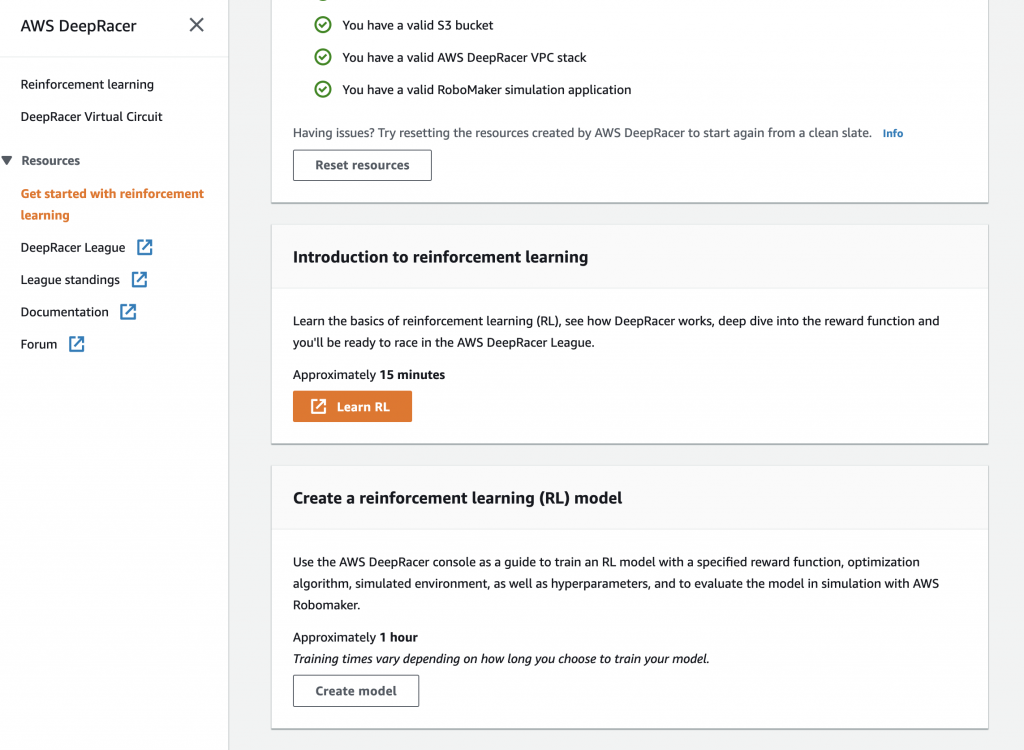
Training A DeepRacer Model
- 訓練一個DeepRacer model:完成設定之後可以下滑畫面點選create model,或是回到AWS DeepRacer 選單下的"Reinforcement Learning",一樣點選create model.
2. AWS提供的訓練方式並不要求使用者調整模型結構的細節,像是演算法的選擇、網路層數、選擇使用何種ML library,還有訓練資料的提供以及處理。
DeepRacer的模型結構與一般強化學習模型一樣,由agent, environment的交互作用來完成訓練,其中每個時間點的step會有agent基於前一個step的reward和state做出的新action,以及environment因應agent的新action產生新的state與reward。AWS DeepRacer提供使用者設計或選擇不同的environment種類、action種類、reward function還有超參數來訓練模型。其訓練步驟如下:
a. 命名模型:在model details下填入模型的名稱(required)。
b. 選擇environment:在deep racer 中的environment就是賽車的賽道;在2019 AWS summit 上比賽使用的訓練environment會是預設的賽道re:Invent 2018。
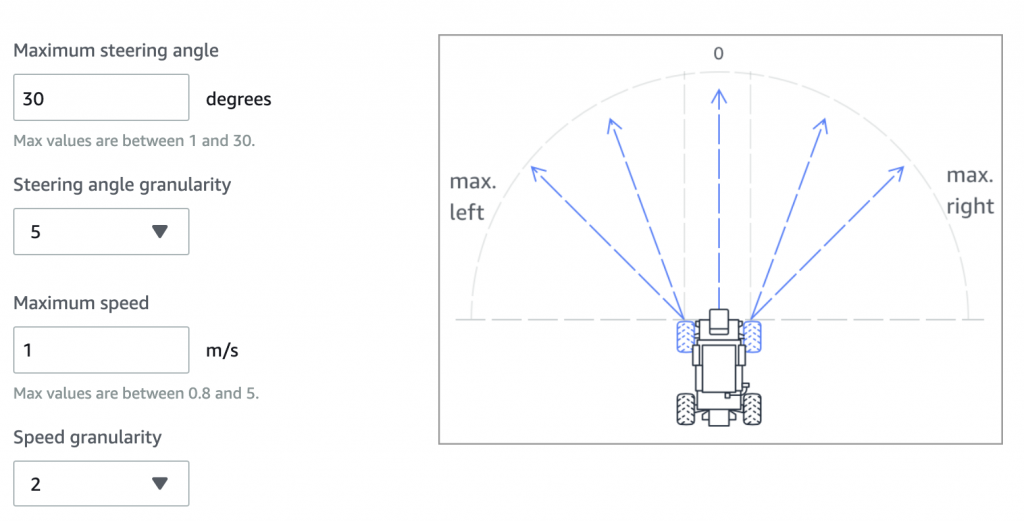
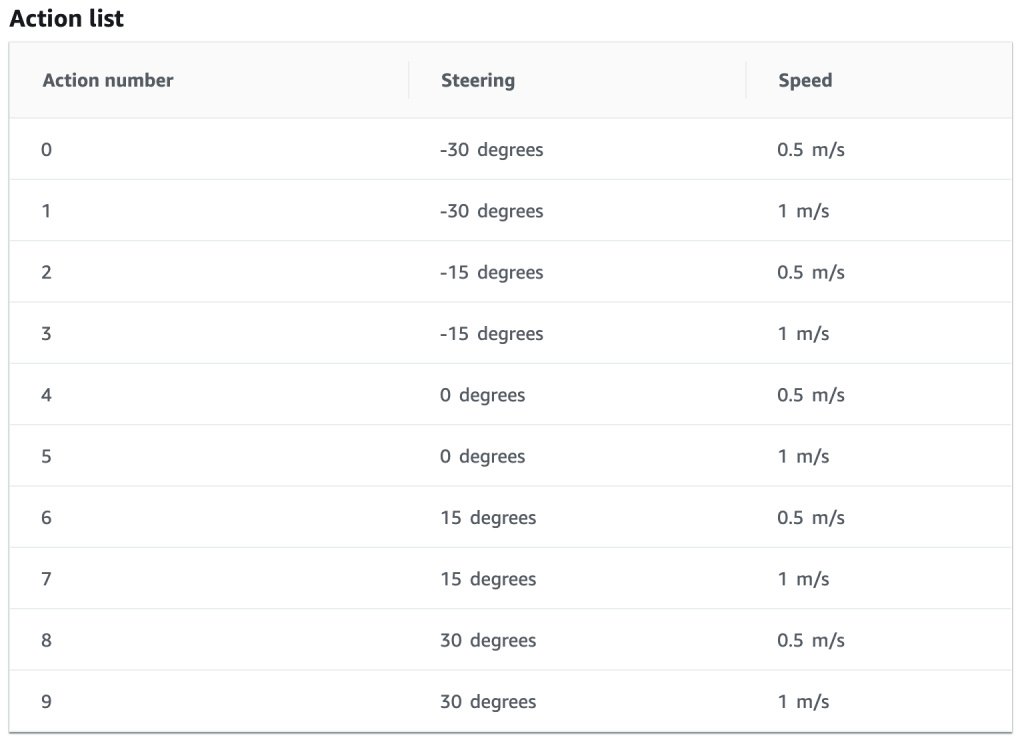
c. 選擇 action list: 賽車的action由兩個關於賽車的數值來決定。如圖所示,一個是轉彎(輪軸角度)的程度,一個是賽車的速度。使用者藉由決定最大的角度、最大速度以及切割區間來將這角度與速度的搭配分割成不同數值的組合,例如一種action會是傾斜角度為0速度為0.5m/s,這樣的action就會是「以每秒0.5m的速度直進」。如此數個action可以構成一個action list (action space)。
d. reward function: reward function是訓練模型最為重要的地方;DeepRacer的reward function是由使用者自己設計的。在官方提供的reward function example中,reward 是由賽車在環境中的「位置」所決定。
AWS提供了一個關於賽車與環境的測量數據參數列表(DeepRacer repo, 請找到Section 3.4 Reward function),例如:「賽車與跑道中心距離」、「賽車是否在賽道上」、「賽車位座標位置」或是「賽道寬度」等等。使用者可以利用這些特徵設計對模型的reward或是penalty,也可以修改官方提供的reward function example。舉一個簡單的reward function為例:
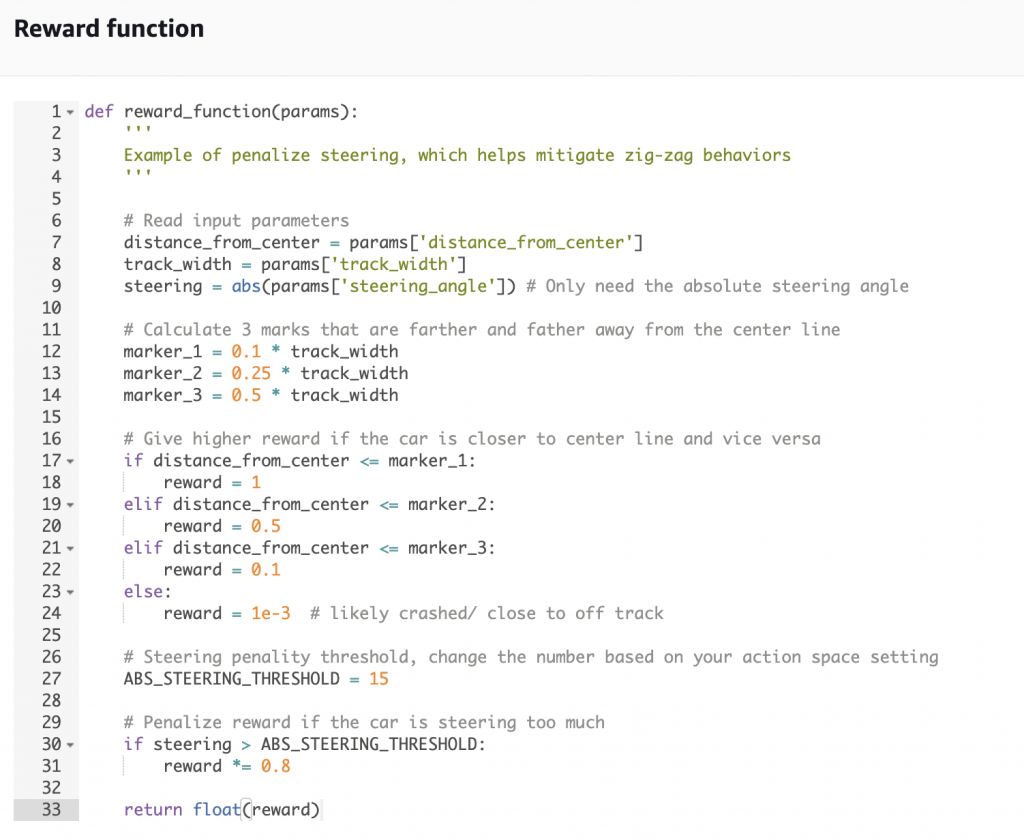
這個function使用了一些從環境測量到的數值,像是distance_from_center, track_width, steering。目標是防止賽車Z字前進,為此官方設計了一些規則作為懲罰,如圖中的marker_1~3與distance_from_center的比較對應了實際車子離中線的遠近程度給予不同的reward。還會檢查車子轉彎的程度進行懲罰,圖中的例子是車子轉彎幅度過大會使reward減少20%,如此模型在最大化reward 的過程中會避免這些減少reward的情境,也就學會決定該使用哪些action來完成賽事。
e. 超參數: 超參數的部分無異於一般機器學習的範疇,使用者可以選擇批次量、learning rate、迭代次數或是損失函數(不能自己設計)等等。
f. 最後是模型訓練時間,對於初次嘗試的使用者可以選擇短一點的時間來完成整個流程。而對於一個正常的DeepRacer 模型來說,官方說明是至少2~4個小時的訓練時間為佳。選擇完訓練時間之後就可以開始訓練模型。
Evaluating Model
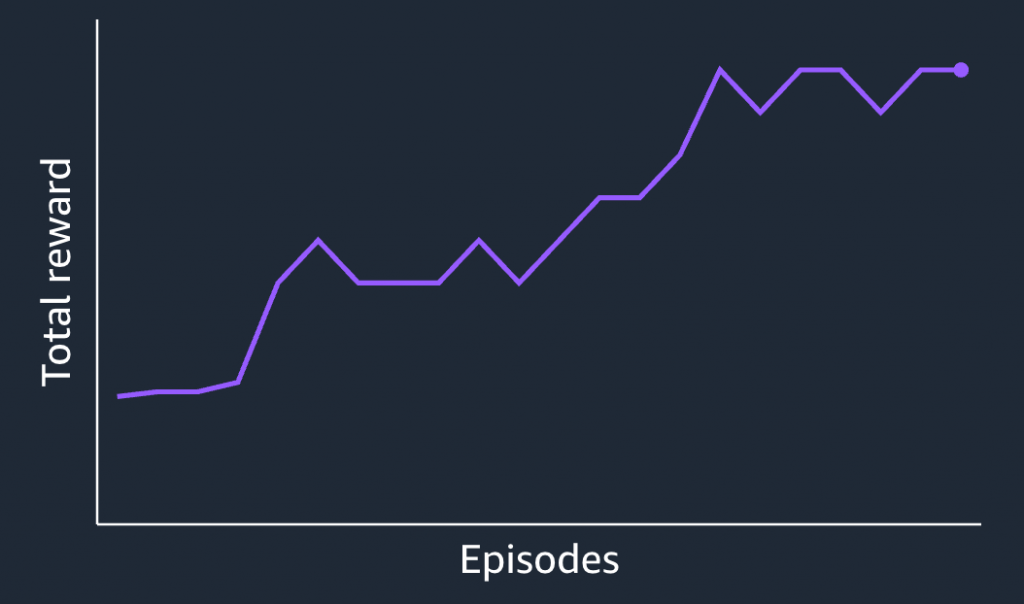
訓練模型過程中,使用者其實可以看到模擬的影片結果,以及total reward的變化量,由此來觀察訓練的成效。但實際評測的過程中,仍需要透過一圈計時的方式來評測模型好壞。
使用者可以回到Reinforcement learning的模型列表中,隨時檢查模型是否已經完成訓練了。
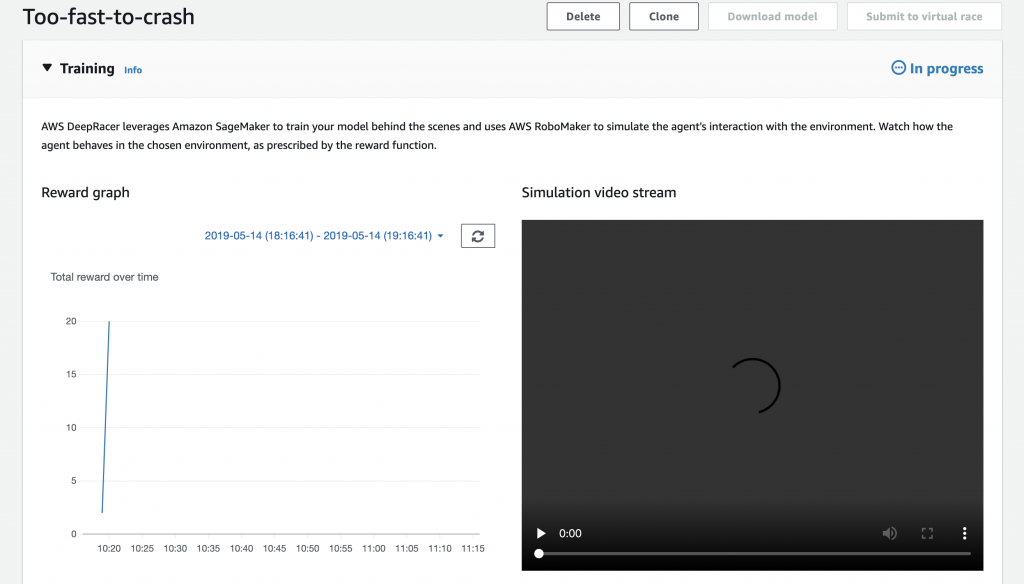
- 訓練完成後,來到Reinforcement介面。模型的status會呈現"Ready"字樣,表示模型可以評測了。
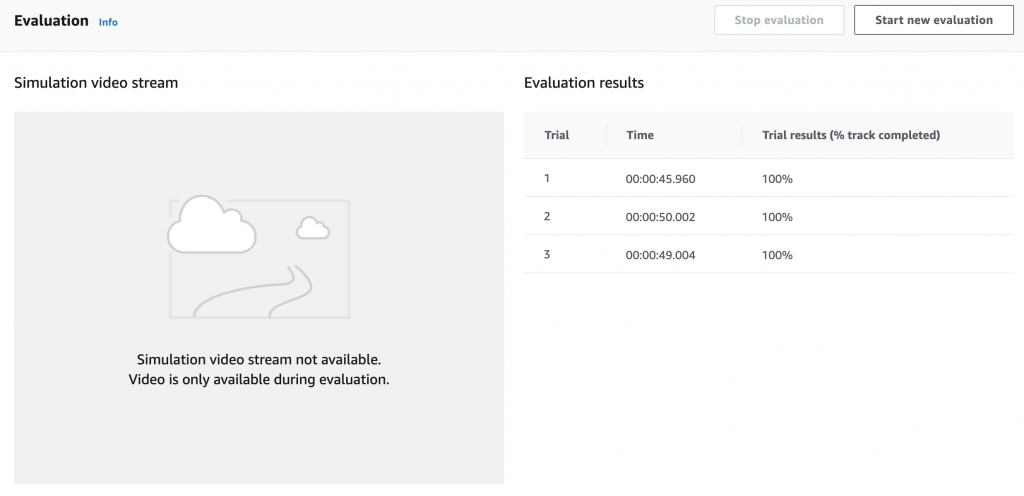
- 點選訓練好的模型之後,下滑畫面到Evaluation欄位並選擇"Start new evaluation"。使用者可以選擇要評測的賽道環境,接著點選Start evaluation就可以開始測試了。
- 測試完的結果會以一圈計時的方式呈現。如下圖,該模型最好的成績就是45.96秒/一圈。模型的測試就到這邊完成了。
Appendix
AWS上的SageMaker有另外建立Jupyter Notebook的服務,DeepRacer學習營這次有提供額外的log analysis notebook供使用者使用。有興趣的話可以前往Services>Amazon SageMaker 並將官方github(ipynb)導入notebook中來使用。
- 選擇create notebook instance。
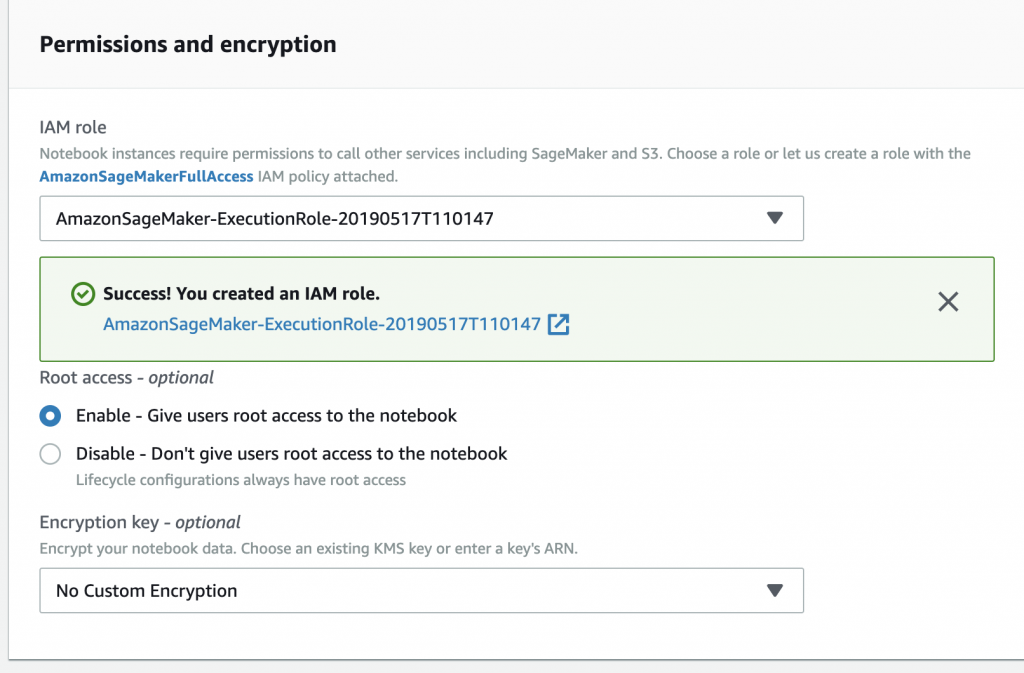
2. 設定好notebook 名稱後下滑畫面到 Permission and encryption中,在下拉式選單中選擇create new role,在S3 bucket的選擇部分,因為有位使用者預設DeepRacer的bucket,所以可以選擇Any S3 bucket並create role。
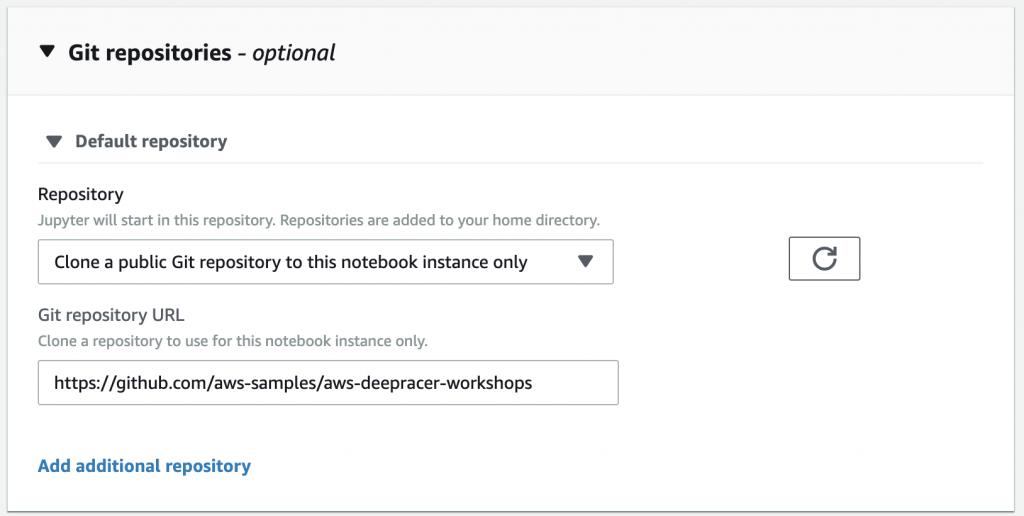
建好role如下,接著再往下滑到Git repositories 的部分,選擇Clone a public Git repository to this notebook instance only並把官方git repo網址填在下方(https://github.com/aws-samples/aws-deepracer-workshops),最後建立notebook。
3. 稍待片刻等待notebook建立完成就可以打開Jupyter notebook了!
另外官方有在AWS上提供免費的RL90分鐘課程,有興趣的同學也可以前往收看!
總結
透過AWS提供的一整套DeepRacer教學,我認為在LINE的不少應用是可以透過強化學習近一步得到更好的效果的。最直覺的是對話聊天的機器人,如果應用在LINE在今年推出的客服小幫手,就可以透過收集使用者對線上機器人/真人的回應 feedback,加入現在我們已有的機器人模型作為reward function,可以更容易選擇/生成出迎合使用者的回答(更深入的可以參考:Deep Reinforcement Learning for Dialogue Generation)。
當然不僅侷限於此,在例如LINE EC 或Today 的推薦上,也可以將用戶點擊轉換成reward來改善推薦系統(有興趣的同學可以參考這篇論文:DRN: A Deep Reinforcement Learning Framework for News Recommendation)。最後很開心有機會參與到這次的實驗營,作為LINE Data Dev team的一員可以接觸到前沿的實作成果。