
안녕하세요! LINE에서 프런트엔드 개발을 담당하고 있는 Jun입니다. 최근 프런트엔드 분야는 흥미로운 기술이 가득해서 전부 다 파악하는 게 힘들 정도인데요. 개인적으로 가장 관심이 가는 건 머신러닝입니다. 오늘은 웹 프런트엔드에서 머신러닝 활용하기를 주제로, TensorFlow.js를 사용해서 간단하게 머신러닝을 구현해 본 경험을 공유하겠습니다.
들어가기 전에
저는 TensorFlow.js를 사용해서 브라우저에서 동작하는 간단한 classification 모델을 만들어 보았는데요. 제 경험을 말씀드리기 전에 TensorFlow와 classification에 대해 짧게 소개드리겠습니다.
TensorFlow란?
TensorFlow는 오픈소스 머신러닝 프레임워크입니다. 머신러닝에서 자주 사용되는 모델과 함수 등이 잘 추상화되어 있어서 애플리케이션 프로그래머도 손쉽게 머신러닝을 구현할 수 있는데요. 2018년 중순에 TensorFlow의 JavaScript port인 TensorFlow.js가 공개되었습니다. 최근 Apple의 Core ML이나 Google의 ML Kit처럼 클라이언트에서 머신러닝 모델을 실행하는 게 보편화되고 있는데요. TensorFlow.js는 브라우저에서 머신러닝 모델을 실행하는 방식입니다. 웹 환경에서 머신러닝을 바로 실행시키면 UX를 세밀하게 제어할 수 있고 개인 맞춤형 콘텐츠를 제공할 수 있다는 장점이 있습니다.
Classification이란?
Classification은 머신러닝의 supervised learning 방법 중 하나로 데이터를 여러 개의 클래스로 분류하는 문제입니다. 예를 들어, 스팸 메일을 분류하는 작업 등이 classification 문제에 속합니다. 아래 분포도는 오타와 특수문자의 개수를 각각 가로축과 세로축으로 설정하여 메일이 스팸 메일에 해당되는지 여부를 OX로 표현한 것입니다.
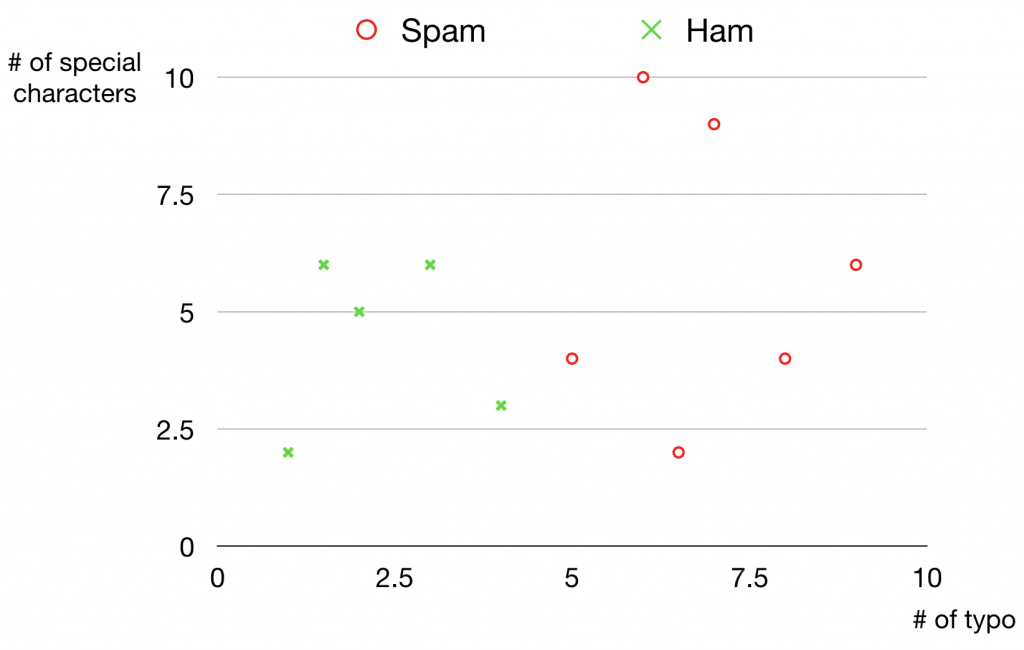
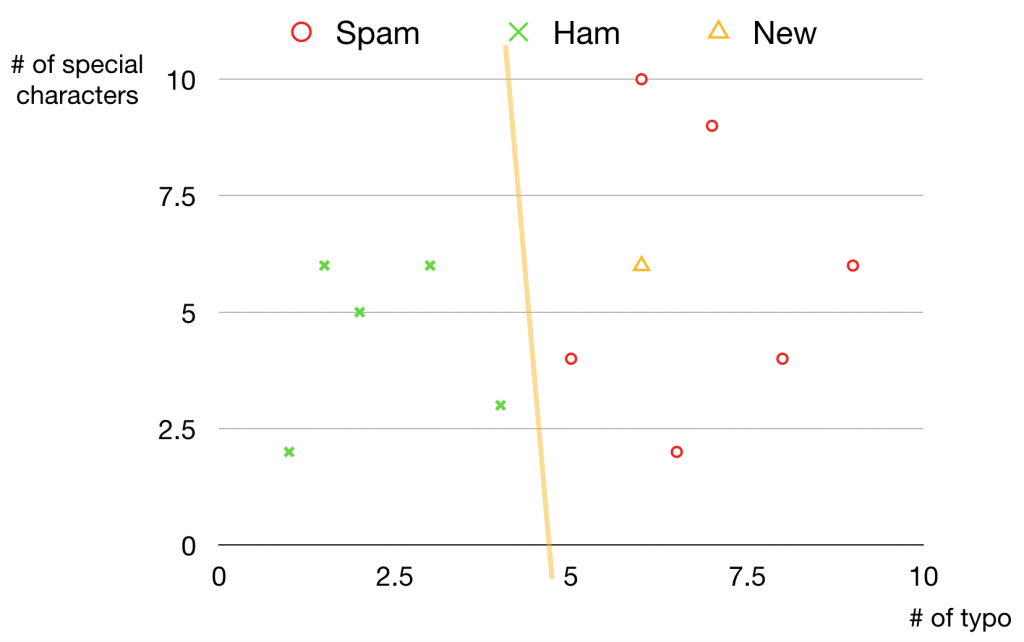
오타가 많고 느낌표 등의 특수문자가 많으면 스팸 메일일 가능성이 높다는 것을 알 수 있습니다. 머신러닝 모델은 이런 패턴을 학습해서 새로운 데이터가 주어졌을 때 어떤 클래스에 속하는지 판단할 수 있게 됩니다. 예를 들면 아래 그림에서 삼각형으로 표시된 데이터가 스팸 메일일 것 같다는 추측을 할 수 있게 되는 거죠.
Color recommendation system 만들기
그럼 이제 제가 구현해 본 color recommendation system에 대해 말씀드리겠습니다. Color recommendation system은 색상에 대한 사용자의 반응을 토대로 선호할 만한 색상을 추천해 주는 시스템입니다.
구현 방법
우선 색상 RGB 값을 각각 사용하는 feature이기 때문에 입력 데이터는 3차원 벡터입니다. Classification 모델로는 가장 기본적인 logistic regression을 사용했습니다. 이번 시스템은 브라우저에서 실행되기 때문에 많은 데이터를 확보하기 어렵습니다. 그래서 low variance를 가지며 데이터 양이 많지 않아도 잘 작동하는 모델을 선택했습니다. 또한 activation 함수는 Sigmoid activation을 사용하고 손실함수는 binary crossentropy를 사용했습니다. 사용자의 동작에 따라 매번 fitting시켜나가는 방식이라서 optimizer는 stochastic gradient descent(SGD)를 사용했습니다. 이 내용을 TensorFlow.js로 작성하면 아래와 같은 코드가 나옵니다.
const model = tf.sequential({
layers: [
tf.layers.dense({ inputShape: [3], units: 1, activation: 'sigmoid' })
]
})
model.compile({
optimizer: tf.train.sgd(1), // learning rate = 1
loss: 'binaryCrossentropy'
})입력값이 RGB이기 때문에 inputShape가 [3]으로 되어 있습니다. 그 외의 내용은 위에서 설명한 바와 같습니다. 아래와 같은 방법으로 이 모델을 훈련 데이터 세트로 학습시킬 수 있습니다.
await model.fit(x, y, {
batchSize: 1,
epochs: 3
})x와 y에는 각각 tensor가 들어갑니다. batchSize는 입력 크기에 따라 달라지는데, 이번에는 매번 불러오도록 1로 설정했습니다. SGD를 정상적으로 사용하기 위해 입력이 normalize됩니다. 새로운 데이터에 대한 예측을 수행하려면 아래 코드를 실행하면 됩니다.
model.predict(newExample)Demo
위 모델을 실제로 프런트엔드에서 실행시켜 보겠습니다.

위와 같은 웹 앱을 준비한 뒤 '좋아요' 버튼을 누르면 해당 색상을 positive로 학습시킵니다. 사용자는 좋아하지 않는 것에는 피드백도 잘 하지 않기 때문에 negative 버튼은 만들지 않았습니다. 대신 사용자가 '좋아요' 버튼을 누르지 않고 스크롤 등을 이용해 색상을 화면 밖으로 내보내면 negative로 인식되도록 구현했습니다. 구현할 땐 Intersection Observer API를 사용했습니다.
사용자가 버튼이나 스크롤을 사용해서 피드백을 주면 아래와 같은 데이터가 수집됩니다. 입력값이 3차원의 RGB라서 3차원 분포도로 표현됩니다.

분포도를 보면 사용자가 붉은 계통의 색상에 '좋아요' 버튼을 많이 눌렀다는 결과를 확인할 수 있습니다. Positive(파란색 O) 데이터와 negative(주황색 X) 데이터가 나뉘는 경향이 대강 보입니다. 모델이 정상적으로 학습되었다면 이런 패턴을 판단할 수 있습니다.
model.predict() 함수를 호출하면 0에서 1 사이의 값이 반환됩니다. 1에 가까울 수록 positive를 의미합니다. 새로 생성된 컬러에 0.5를 기준으로 예측을 적용시켜 보았더니 아래와 같이 전체적으로 붉은 계통의 컬러만 필터링된 것으로 보아 정상 작동한다는 것을 확인할 수 있었습니다.

어려웠던 점
일단 위의 예시는 잘 실행되었는데요. 전체 과정에서 쉽지 않은 부분이 있었습니다. 처음에는 hidden layer가 1개인 shallow NN 모델로 구현해 보았는데요. 어떻게 해도 generalization error가 증가하는 문제가 있었습니다. 아무래도 샘플 데이터 50개로는 충분하지 않았던 것 같습니다.
{
layers: [
tf.layers.dense({ inputShape: [3], units: 3, activation: 'sigmoid' }),
tf.layers.dense({ units: 1, activation: 'sigmoid' })
]
}훈련 데이터를 추가로 준비해서 batchSize를 키우니 잘 작동했는데요. 프런트엔드에서는 많은 훈련 데이터를 확보하기 힘들기 때문에 고민되는 대목입니다. 서버에서 학습된 weights를 다운로드하는 방식으로 하더라도 layer나 unit 수를 늘리면 weights 수가 방대해지기 때문에 다운로드 용량이 고민거리인 웹에선 쉽지 않을 것 같습니다. 좀 더 효율적인 해결 방안이 있을지 더 고민해 봐야겠습니다. 혹시 좋은 의견 있다면 여기로 알려 주세요!
마치며
준비한 내용은 여기까지입니다. 어떠셨나요? 저도 아직 머신러닝 초보자라서 미숙한 부분이 많은데요. 앞으로도 계속 공부할 예정이니 개선할 점 등을 알려 주시면 감사하겠습니다. 개인적으로 클라이언트 사이드의 머신러닝은 여러모로 제약이 많아서 어려운 부분도 많지만, UX 등을 직접 연동할 수 있다는 장점도 느낄 수 있었습니다. iOS, Android, Unity 등 여러 클라이언트 플랫폼에 이미 라이브러리가 준비되어 있고 앞으로 실사례도 늘어날 것 같아서 계속 연구해 볼 생각입니다. 이번에 사용한 코드는 GitHub 저장소에 전체 공개로 올려 두었으니 관심 있으신 분들은 참고해 주시기 바랍니다.