
この記事はLINE Advent Calendar2018の16日目の記事です。
こんにちは!LINEでフロントエンド開発を担当しているJunと申します。最近のフロントエンド世界は面白いことがいっぱいで全部把握できないくらいですが、個人的に一番興味があるのは機械学習です。今日はWEBフロントエンドでの機械学習というテーマで、TensorFlow.jsを使って簡単な機械学習を実装してみた経験について書きます。
TensorFlow
TensorFlowはオープンソース機械学習フレームワークです。機械学習でよく使われるモデルや関数などを抽象化しているので、アプリケーションプログラマでも簡単に機械学習を実装することができます。
そして今年の中旬頃、TensorFlowのJavaScript portのTensorFlow.jsが公開されました。最近AppleのCore MLやGoogleのML Kitなど、クライアントで機械学習モデルを動かすことが一般的になってきていると思いますが、TensorFlow.jsはブラウザ上で機械学習モデルを動かすものとなっています。WEB環境で直接機械学習を動かすことで、細かくUXを制御できたりパーソナライズされたコンテンツを提供できると思います。
今回はTensorFlow.jsを使ってブラウザ上で動く簡単なclassificationモデルを作ってみました。
Classification
Classificationは機械学習のなかでもsupervised learningの一例で、データをいくつかのクラスに分類する問題です。例えば迷惑メールを分類するようなタスクがclassification問題になります。
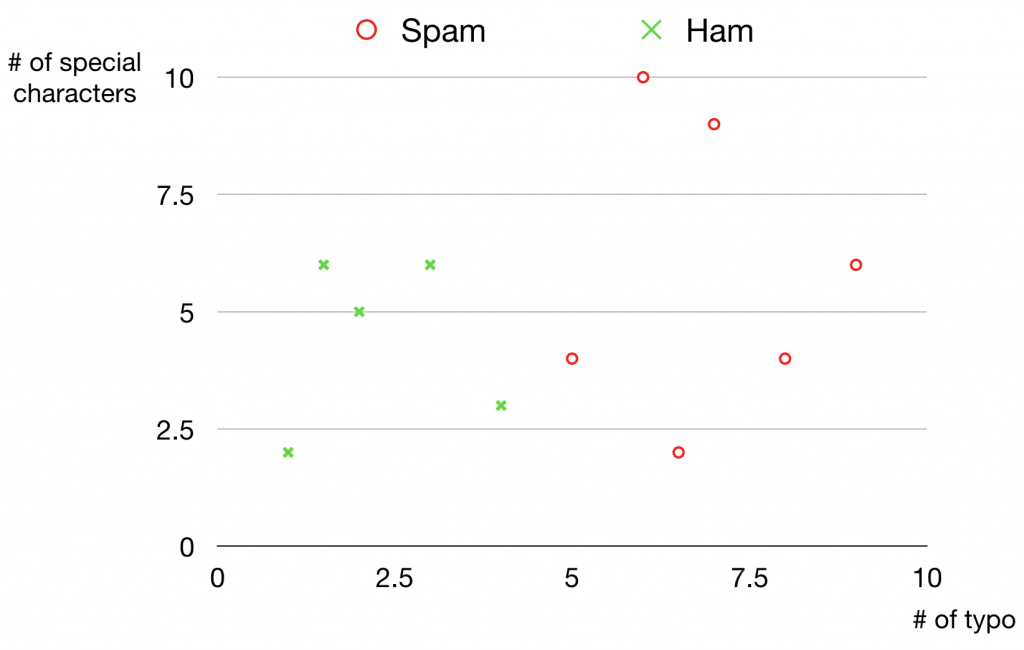
上の散布図はタイポと特殊文字の数を軸としてメールデータが迷惑メールかどうかをマルとバツで表現した図になっています。
タイポが多くてビックリマークなどの特殊文字が多い方が迷惑メールになりやすい傾向を確認できます。機械学習モデルはこのような傾向を学習して新しいデータが来たときどのクラスに所属するのかを判断できるようになります。
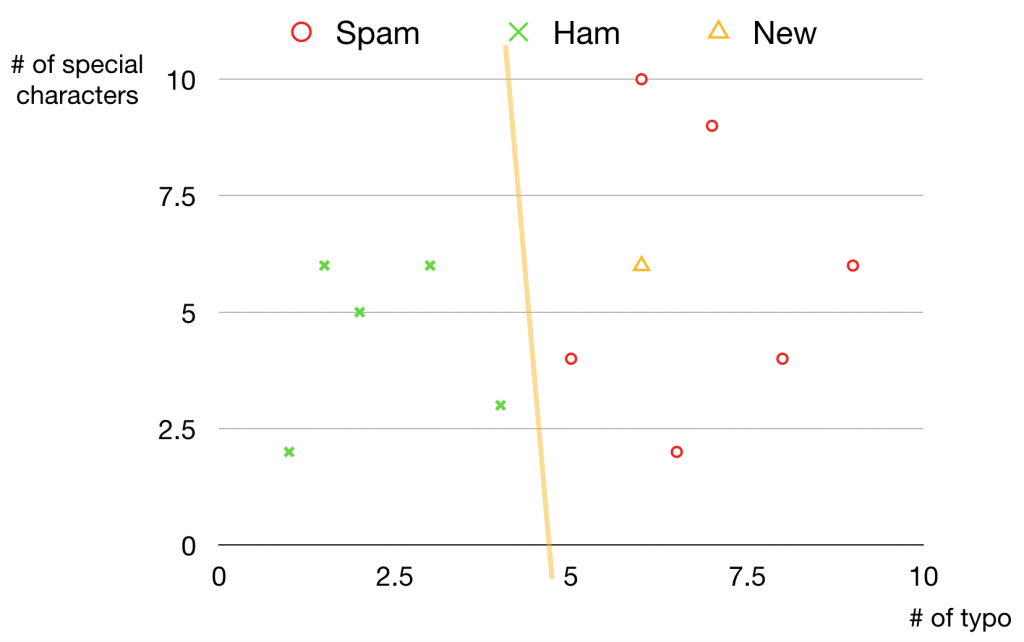
例えば上の図に三角で表示されているデータは多分迷惑メールだろうなという推測ができるようになります。
Color recommendation
今回実装してみたのはcolor recommendation systemです。色に対してのユーザの反応をみて、ユーザが好きそうな色をおすすめできるシステムを作りました。Featureとしては色のRGBの値をそれぞれ使いましたので3次元のベクトルが入力データになります。
Classificationのモデルとしては一番基本的なlogistic regressionを使いました。今回のシステムはブラウザ上で動くため、たくさんのデータを確保することが難しいです。そのためlow varianceでデータが少なくてもよく動くモデルを選びました。
Sigmoid activationを使っていて損失関数はbinary crossentropyです。ユーザの動作に対して毎回fittingして行くため、stochastic gradient descentを使いました。
この内容をTensorFlow.jsで書くと以下のようなコードになります。
const model = tf.sequential({
layers: [
tf.layers.dense({ inputShape: [3], units: 1, activation: 'sigmoid' })
]
})
model.compile({
optimizer: tf.train.sgd(1), // learning rate = 1
loss: 'binaryCrossentropy'
})RGBが入力なのでinputShapeが[3]になっています。その他の内容は上で説明した通りですね。
このモデルをトレーニングデータセットを使って学習させようとすると以下のようになります。
await model.fit(x, y, {
batchSize: 1,
epochs: 3
})xとyにはそれぞれTensorが入ります。batchSizeは入力のサイズによって変わりますが、今回は本当に毎回呼ぶように1で設定しています。SGDを正しく使うため入力はnormalizeされます。
model.predict(newExample)新しいデータに対しての予測は上のようなコードでできます。
Demo
上のモデルを実際にフロントエンドで動かしてみます。

上のようなWEBアプリを用意し、「良さげ」ボタンを押すとその色はpositiveとして学習させます。Negative入力についてもボタンにする方法もありますが、ユーザは良くないと考えることに対してはフィードバックも弱くなるのでUX的に不自然です。そのため、スクロールなどで色が画面の外に離脱した場合をnegativeとして認識するようにしました。実装のためにはIntersection Observer APIを使っています。
ユーザがどんどんボタンかスクロールでフィードバックしていくと、以下のようなデータが集まります。

上の図はユーザが赤っぽい色に対して「良さげ」した結果を見せています。入力がRGBの3次元なので3次元の散布図になっています。傾向としてpositive(青いマル)のデータとnegative(オレンジのバツ)のデータがざっくりと別れていることが分かります。もしモデルが正しく学習されていれば、その傾向を判断できるはずです。

model.predict()関数を呼ぶと、0から1の間の値が帰ってきます。1に近いほどpositiveの意味ですね。0.5を基準として新しく生成された色に予想を適用してみました。確かに全体的に赤っぽい色だけフィルタリングされましたので、とりあえずは正しく動くことが確認できました。
Discussion
いったん上の例は動くように見えましたが、全体的には簡単ではない部分もありました。
最初はモデルとしてhidden layerを一つ持つshallow NNで実装してみましたが、どうしてもgeneralization errorが高くなる問題がありました。
{
layers: [
tf.layers.dense({ inputShape: [3], units: 3, activation: 'sigmoid' }),
tf.layers.dense({ units: 1, activation: 'sigmoid' })
]
}50個のサンプルだとデータ少なすぎたせいだと思っています。追加のトレーニングデータを用意しbatchSizeを増やすとよく動くようになりましたが、実際の使用例を考えるとフロントエンドだけでたくさんのトレーニングデータを確保するのは難しいです。悩ましいところですね。
例えサーバで学習されたweightsをダウンロードするとしても、layerやunit数を増やすとweightsの数が膨大になることもあります。WEBだとダウンロードサイズは気になる要件の1つなので、効率よく解決できる方法について今後考えてみたいです。もし良い意見などがあれば教えてください!
Conclusion
準備した内容は以上になります。いかがでしたか?
自分自身も機械学習初心者なので、未熟な部分が多かったと思います。今後も勉強していきたいと思いますので、もし改善できる部分など教えて頂けると嬉しいです。
個人的な感想ですが、client-sideの機械学習は色々制限が多く難しい部分も多いですが、UXなどと直接連携できるというメリットも持っていると思いました。iOS、Android、Unityなど数多くのclient platformですでにライブラリが用意されていて、今後実例も増えていくと思いますので勉強し続けていきたいです。
今回使ったコードなどはGitHubリポジトリにすべて公開されていますので、もし興味ある方は見てみてください。
明日はMasahiro IdeさんによるAnnotation processingについての記事です。お楽しみに!