
들어가며
안녕하세요. LINE Financial의 데이터 엔지니어 김기훈, 윤평화, 김윤식입니다. LINE Financial에서는 여러 조직에서 사용할 수 있는 Airflow 환경을 제공해 달라는 요구가 있었습니다. 이번 글에서는 이 요구 사항을 효율적인 방식으로 풀어내 제공하는 과정에서 고민했던 내용과, 기능(feature) 개발 환경을 자동으로 제공하는 예시를 공유하려고 합니다.
배경 설명
저희는 'LINE Financial의 데이터 관련 업무를 리딩한다'라는 비전 아래 관련 조직의 데이터 파이프라인의 현재 상태를 파악하고 개선하는 프로젝트를 진행하게 되었습니다. 이에 흩어져 있는 데이터 파이프라인 환경을 점검하며 아래와 같은 문제점을 파악했습니다.
문제점
- 파편화되어 있는 데이터 파이프라인 환경 때문에 관리 포인트가 늘어나는 문제
- 온 프레미스(on premise) 환경에 구축돼 있기 때문에 추가로 구축이 필요한 경우 비용(서버, 운영, 구축 시간 등)이 증가하는 문제
- 여러 개발자가 하나의 데이터 파이프라인에서 비즈니스를 개발하기 때문에 온 프레미스 환경에 각 개발자에게 맞는 여러 개발 환경이 필요한 문제
점검한 결과를 토대로 데이터 파이프라인을 제공하는 입장에서 어떻게 하면 좀 더 편하고 효율적인 플랫폼을 제공할 수 있을지를 고민하며 아래와 같은 목표를 세우고 프로젝트를 진행했습니다.
목표
- 파편화된 데이터 파이프라인을 하나로 통합해 비용과 관리 포인트를 줄인다.
- 온 프레미스 환경으로 구축되어 있는 환경들을 '프라이빗 클라우드 관리형 Kubernetes'에 구성해서 컨테이너 환경의 장점을 최대한 활용한다.
- 하나의 데이터 파이프라인 환경에서 다수의 클러스터에 효율적으로 접근할 수 있게 한다.
- 기능 개발하기 불편한 사용자의 테스트 환경을 개선한다.
멀티테넌시 Airflow 환경을 제공하기 위한 고민
멀티테넌트 Git 프로젝트
기존 데이터 파이프라인 환경은 단일 데이터 파이프라인 Git 리포지터리와 연계해 DAG(directed acyclic graph)를 관리했습니다. 이는 단일 프로젝트의 파이프라인 환경으로는 적합했지만, 한 분석/개발자가 여러 프로젝트에 참여하는 경우에는 별도의 파이프라인 환경을 만들어줘야 하는 불편함이 있었습니다. 이런 불편함을 해소하기 위해 Apache Airflow에서는 단일 Airflow를 여러 구성원이 같이 사용할 수 있도록 멀티테넌시를 지원하는데요. 여기에도 몇 가지 단점이 있습니다.
게다가 A라는 개발자가 아래 그림과 같이 테넌트 프로젝트 1과 테넌트 프로젝트 2라는 프로젝트에 동시에 참여하는 경우, 프로젝트마다 파이프라인 환경 구조가 다르기 때문에 통일된 파이프라인 환경에서 일하기가 어렵습니다.
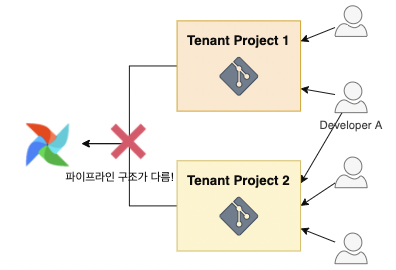
해결 방안
이와 같은 문제를 해결하기 위해 Git 리포지터리를 통일해서 여러 개 두는 것이 아니라, Kubernetes 환경의 장점을 극대화해 DAG Git 리포지터리별로 파이프라인 환경을 구축하는 것을 선택했습니다. 물론 공통으로 사용하는 구조 정도는 유지하는 것이 효율적이라고 생각했는데요. 이를 반영해 최소한으로 통일시킨 파이프라인 구조를 채택한 형태에서, DAG 코드나 구조는 각 프로젝트별로 자유롭게 사용하는 형태가 좋겠다고 생각했습니다. 이에 아래와 같이 공통으로 사용하는 코어 Python 패키지를 배포하면 이를 각 파이프라인별로 가져가는 형태를 고안했습니다.
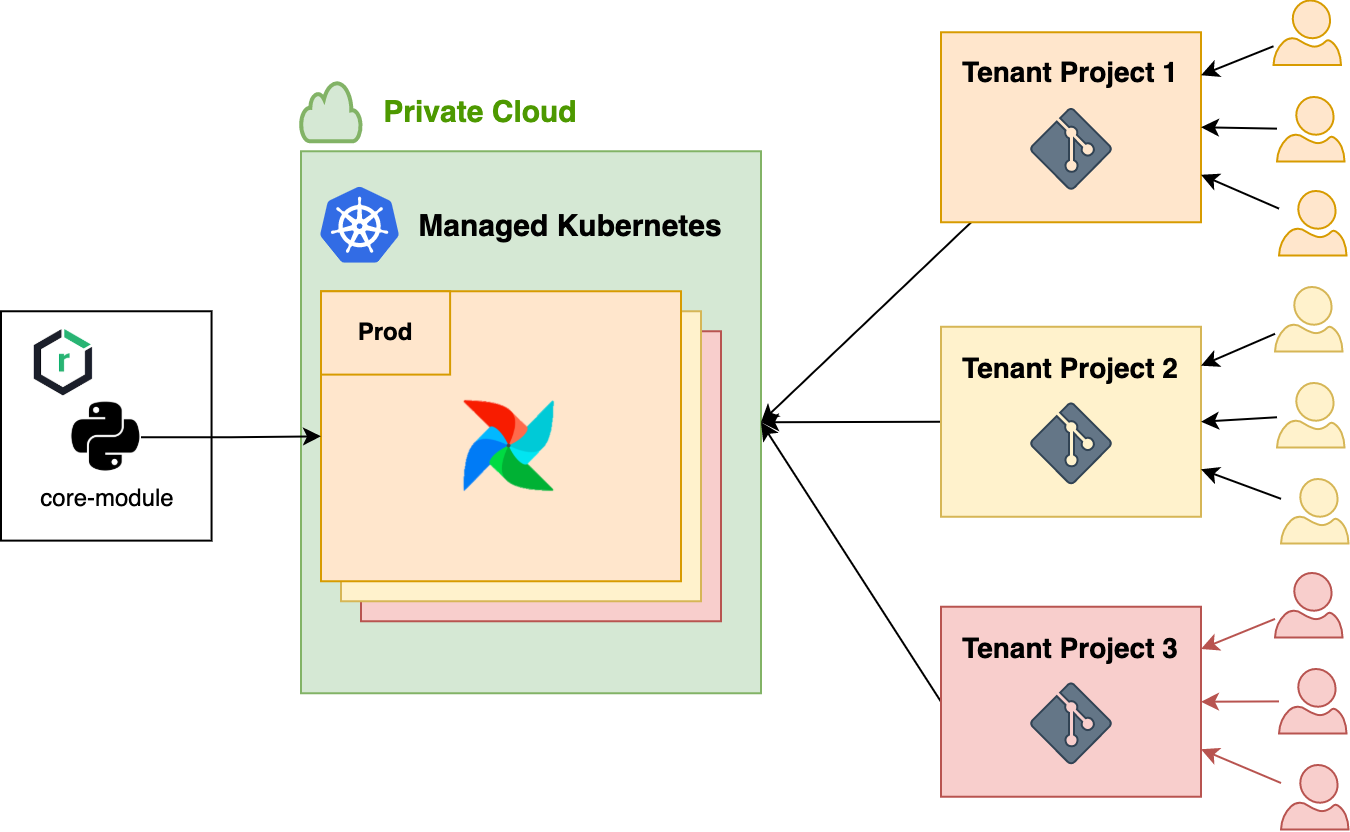
동일한 서비스에서도 여러 데이터 파이프라인 환경 제공
서버 엔지니어링 환경은 운영(production), RC(release candidates), Beta 등으로 세분화돼 있는데요. 데이터 파이프라인 환경을 이 정도로 세분화할 필요는 없다고 해도, 적어도 프로덕션(production)과 개발(development)로 나눌 필요는 있습니다. 따라서 적어도 2개 이상의 데이터 파이프라인 영역이 필요하다 보니 Airflow로 구축된 기존 파이프라인 환경은 아래와 같은 단점이 존재했습니다.
- 기능 개발 및 테스트에 사용하는 Airflow 환경이 상시 자원을 점유하는 것은 자원 낭비라고 볼 수 있습니다.
- 상시로 운영 중인 자원들을 모니터링하면서 가용 범위 내에서 파이프라인이 실행되는지 관리하기 위한 비용이 발생합니다.
해결 방안
Kubernetes 네임스페이스별로 파이프라인 환경을 구성한다면 환경별 자원 경합 없이 격리된 환경에서 파이프라인을 실행시킬 수 있다는 이점이 있습니다. 프로덕션 환경보다 유휴 시간이 긴 개발 환경을 고려해 사전에 노드풀을 구성한다면 자원을 적절하게 분배해 유연하게 확보하고 할당할 수 있기 때문에, 아래와 같이 프로덕션(Prod), 개발(Dev), 사용자 테스트(User Test) 환경별로 노드풀을 구성했습니다.
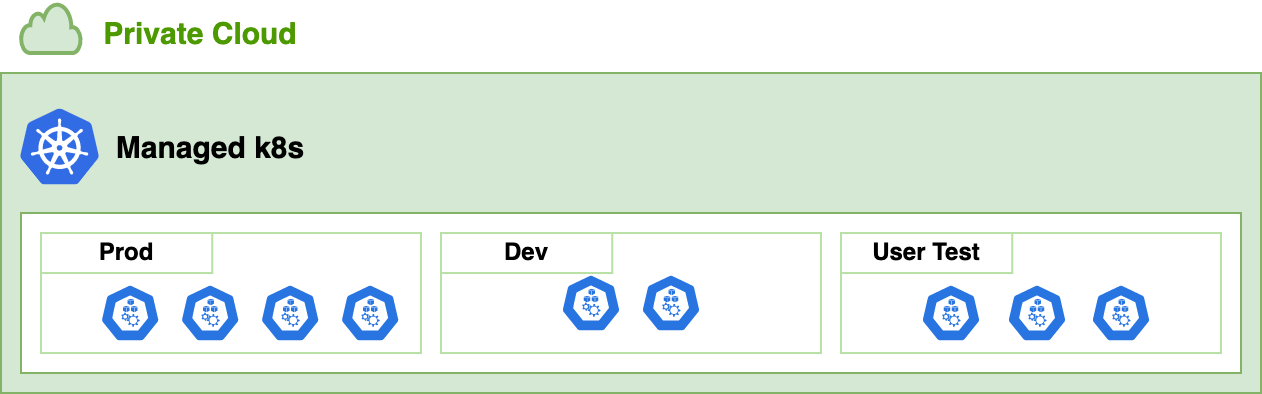
각 영역별로 가용할 수 있는 노드 수를 사전에 정의해 자원 사용량이 비교적 낮은 개발 환경은 할당 노드 수를 줄이고, 자원 사용량이 높은 프로덕션과 사용자 테스트 환경은 노드 수를 늘리는 방향으로 진행했습니다. 이런 방식은 노드풀이 곧 파이프라인인 환경이기 때문에 Grafana로 노드풀별 자원 사용량을 보고 스케일 인 혹은 스케일 아웃할 수 있다는 장점도 있습니다.
운영 환경과 격리된, 쉽게 접근할 수 있는 테스트 환경
파이프라인을 개발하고 테스트하려면 사용자 테스트 환경에 배포하고 개발해야 합니다. 이때 기존 개발 환경에 feature 브랜치를 머지하고 배포하는 것에는 큰 부담이나 불편이 없었지만, 동시에 여러 개발자가 파이프라인을 개발하기에는 불편한 점이 많았습니다. 기능의 우선순위에 따라 개발 환경을 사용하는 것이 아니라 개발 환경에 먼저 머지된 기능을 테스트하는 선입선출 방식으로 테스트를 진행했기 때문입니다.
해결 방안
이와 같은 문제를 개선하기 위해 아래와 같이 설계했습니다. 사용자는 배포할 때 Git 리포지터리에만 푸시하면 됩니다. 그러면 git-sync를 통해 자동으로 배포되게 구성했습니다. 설사 기능을 개발하는 사용자가 Kubernetes에 익숙하지 않더라도, 자동으로 Airflow 웹 서버 URL을 생성해 줌으로써 쉽게 Airflow 웹 서버에 접근해 파이프라인을 테스트할 수 있도록 환경을 구성했습니다. 이를 통해 누구나 쉽게 테스트를 진행할 수 있는 환경을 만들었습니다.
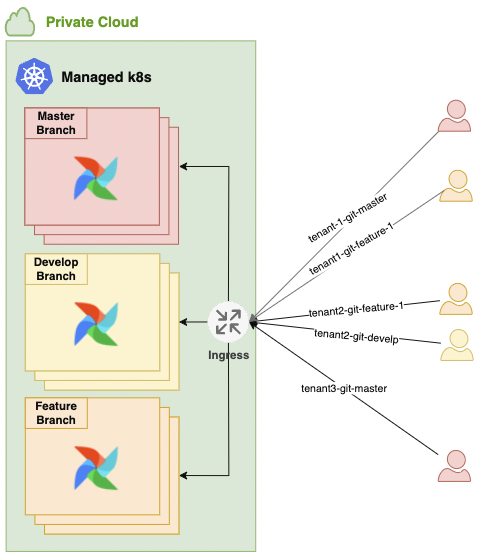
관리 비용 최소화
저희 팀에서 관리하는 핀테크 데이터 플랫폼은 자체적으로 관리하는 Kubernetes 클러스터 내 Airflow on Kubernetes로 데이터 파이프라인 환경을 구축해 놓았습니다. 하지만 글로벌 서비스의 특성 때문에 발생하는 여러 이슈로 이 구축 환경을 활용할 수는 없었습니다. 이에 팀 내부에서 공통으로 사용할 Airflow Helm 차트를 개발해 관리 비용을 최소화해야 했습니다.
해결 방안
아래와 같이 Airflow 사용자 커뮤니티에서 만든 Helm 차트를 여러 파이프라인 환경에서 사용할 수 있도록 커스터마이징했고, 배포 관리 도구로 Argo CD를 도입해 Helm chart를 저장해 놓은 Git 리포지터리가 GitOps 형태로 배포되게 구성했습니다.
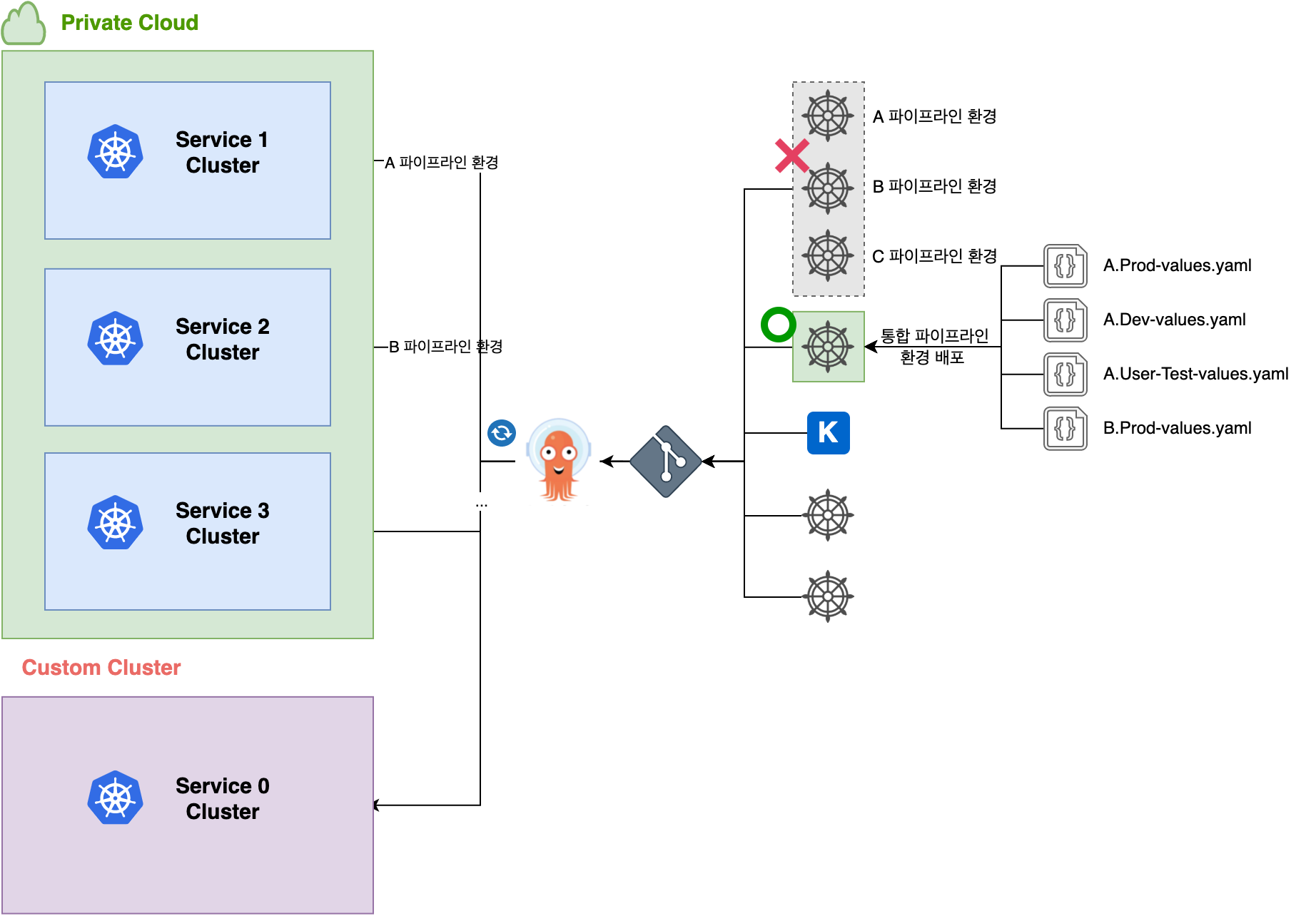
데이터 파이프라인 환경을 만드는 Helm 차트를 각 프로젝트별로 만들면 관리 비용이 많이 들기 때문에 하나의 Helm 차트로 여러 파이프라인 환경을 만들 수 있도록 구성했습니다. Helm 차트는 하나지만 Values.yaml 파일을 여러 개 만들어서 각 파이프라인 프로젝트와 환경별로 배포할 수 있습니다. 이렇게 구현하면 Helm 차트를 유지 보수할 때 공통으로 사용하는 템플릿과 배포 파일만 관리하면 되는데요. Helm 차트를 배포할 때 템플릿 엔진에 전달되는 빌트인 객체를 이용해 분기 처리해서 각 파이프라인 환경이 생성되도록 개발했습니다.
여러 Hadoop 클러스터에 접근할 수 있는 환경
개선된 데이터 파이프라인 환경은 여러 Hadoop 클러스터에 접근할 수 있어야 했습니다. 예를 들어 Hadoop 클러스터 A의 데이터를 처리하면서 Hadoop 클러스터 B의 또 다른 데이터를 처리하는 로직이 하나의 파이프라인(DAG)에 있을 수 있었습니다. 따라서 Hadoop 클러스터 A와 B 모두에 접근해 데이터를 핸들링할 수 있어야 했는데요. 이를 해결하기 위해서 Airflow 태스크가 Kubernetes 워커에서 실행되는 구조를 태스크별로 별도의 파드(pod)가 실행되는 KubernetesPodOperator를 사용하는 것으로 바꿔야 했습니다. 이 부분은 저희 팀 이웅규 님이 작성하신 블로그, Kubernetes를 이용한 효율적인 데이터 엔지니어링 - 2를 참고해 유사한 방식으로 진행했습니다.
해결 방안
다양한 Hadoop 클러스터에 접근할 수 있는 이미지를 생성하면 Kubernetes Executor는 수행할 시점에 태스크를 동적으로 파드를 실행합니다. 이때 어떤 테넌트 프로젝트에 정의된 파이프라인(DAG)의 태스크를 실행시켰는지, 그리고 어떤 환경(프로덕션 혹은 개발)에서 실행했는지 파악하기 위해 추가로 인수나 환경 변수를 파드에 전달합니다. 아래는 예시 코드입니다.
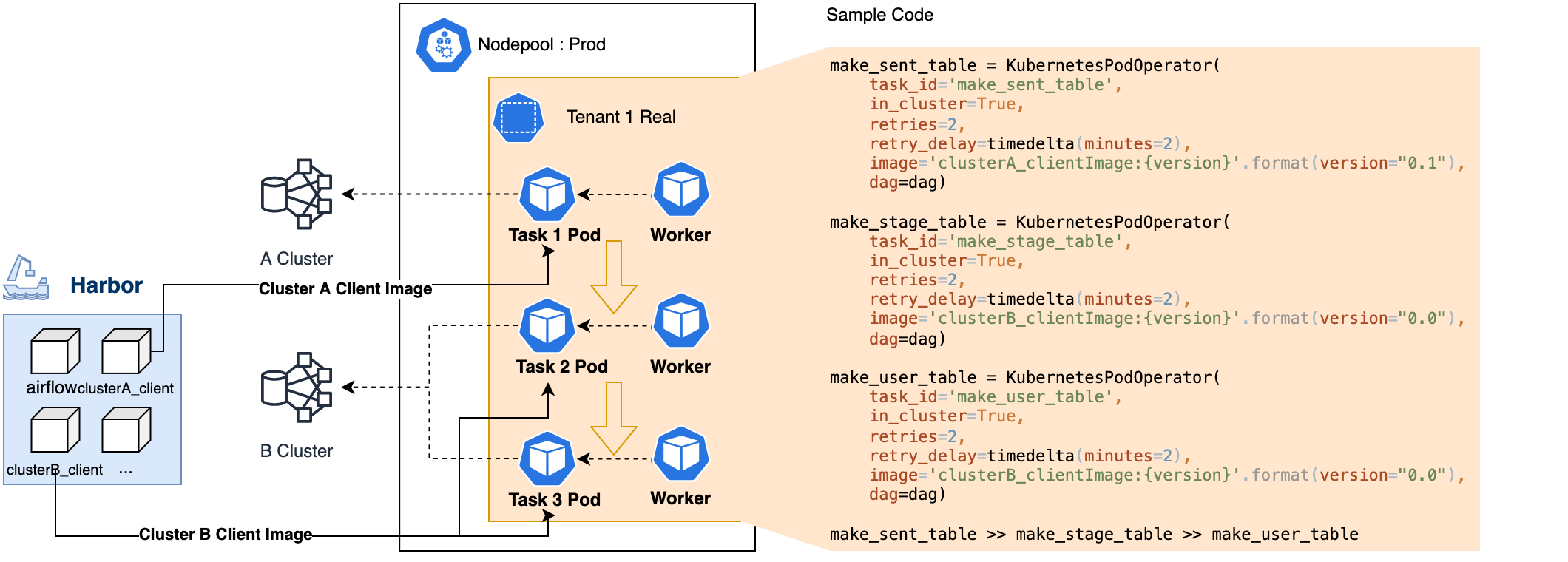
make_sent_table = KubernetesPodOperator(
task_id='make_sent_table',
in_cluster=True,
retries=2,
retry_delay=timedelta(minutes=2),
image='clusterA_clientImage:{version}'.format(version="0.1"),
dag=dag)
make_stage_table = KubernetesPodOperator(
task_id='make_stage_table',
in_cluster=True,
retries=2,
retry_delay=timedelta(minutes=2),
image='clusterB_clientImage:{version}'.format(version="0.0"),
dag=dag)
make_user_table = KubernetesPodOperator(
task_id='make_user_table',
in_cluster=True,
retries=2,
retry_delay=timedelta(minutes=2),
image='clusterB_clientImage:{version}'.format(version="0.0"),
dag=dag)
make_sent_table >> make_stage_table >> make_user_tableCore Module로 개발 편의성 증진
Core Module은 저희가 자체적으로 빌드해서 배포한 Airflow 용도의 Python 패키지입니다. 여러 팀에서 Airflow를 사용하기 때문에 각 팀마다 별도 DAG를 관리할 Git 리포지터리가 존재했고, 다양한 사용자들 중에서는 Airflow에 대한 이해도가 낮은 분들도 계셨는데요. 이에 Airflow DAG 작성 비용을 낮춰 아직 Airflow에 대한 이해가 부족한 사용자도 쉽게 Airflow를 사용할 수 있도록 제공했습니다(Core Module은 사내 PyPI 리포지터리에만 배포하고 있기 때문에 외부에서는 사용이 불가능합니다).
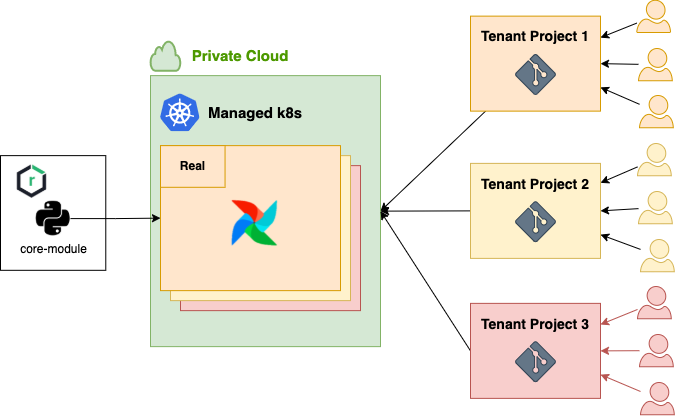
Core Module 구조 및 배포 방식
Core Module은 아래와 같이 크게 세 부분(config, operators, tools)으로 구성돼 있습니다.
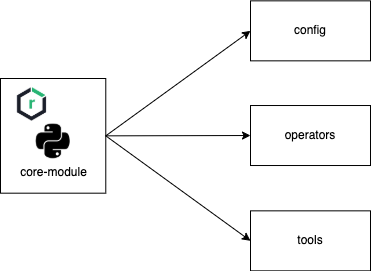
- Config: 프로덕션과 개발, 사용자 테스트 각 환경별로 운영에서 다르게 설정해야 하는 정보들을 YAML 포맷으로 저장합니다.
- 예를 들어, 개발과 사용자 테스트 환경에서는 이미지 풀 정책(image pull policy)을 'Always'로 사용하고 있고, 프로덕션 환경에서는 'IfNotPresent'로 사용하고 있습니다.
- 위 예시와 같이 각 환경별로 운영 정책을 다르게 설정하고 싶은 것들을 정의하는 공간이라고 할 수 있습니다.
- Operators: KubernetesPodOperator를 상속받아서 만든 커스텀 클래스를 제공합니다.
- 커스텀 클래스는 사용자가 최대한 단순하게 사용할 수 있도록 추상화했습니다.
- Kubernetes 운영 정책(예: 이미지명, 이미지 버전, 리소스 할당 노드 규칙 등)은 사용자가 신경 쓰지 않아도 되도록 숨겨 놓았습니다.
- 자세한 사항은 다음 'Core Module 사용 예시' 섹션을 참고하시기 바랍니다.
- Tools: 내부적으로 에러 코드를 관리하거나, 중복으로 사용하는 기능들을 모아 놓은 유틸리티 클래스 등이 있습니다.
Core Module은 python setup을 통해 빌드되어 사내 PyPI 리포지터리로 배포됩니다. 배포된 Core Module은 Airflow 워커 파드가 생성될 때 pip install로 설치됩니다.
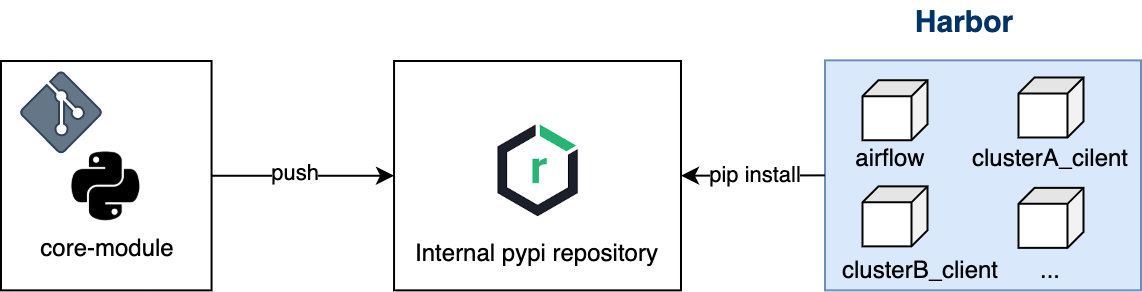
- Kubernetes Executor를 사용하고 있기 때문에 Airflow 워커 파드가 동적으로 생성됩니다.
- Worker 파드 템플릿에 사이드카 패턴으로
pip install을 진행하는 별도의 컨테이너가 생성돼 실행됩니다.
Core Module 사용 예시
아래 코드는 Core Module을 사용한 샘플 DAG 코드입니다.
from airflow import DAG
from sample_core.operators.clusterA_pyspark_kubernetes_pod_operator import ClusterAPySparkKubernetesPodOperator
from sample_core.operators.clusterB_sparksql_kubernetes_pod_operator import ClusterBSparksqlKubernetesPodOperator
dag = DAG(...)
sample_pyspark_task = ClusterAPySparkKubernetesPodOperator(
task_id='sample_pyspark_task',
name='sample_pyspark_task',
pyspark_file_path='ProjectA/pyspark_code.py',
keytab='MyPersonalKeytab',
dag=dag)
sample_sparksql_task = ClusterBSparksqlKubernetesPodOperator(
task_id='sample_sparksql_task',
name='sample_sparksql_task',
sparksql_file_path='ProjectB/sparksql_query.sql',
keytab='MyPersonalKeytab',
dag=dag)
sample_pyspark_task >> sample_sparksql_task위 코드에서 ClusterAPySparkKubernetesPodOperator 클래스는 클러스터 A에서 PySpark 코드를 실행하고자 할 때 사용하는 클래스입니다. 클러스터 A 환경에서 PySpark 코드를 실행할 수 있게 미리 준비된 Docker 이미지로 파드가 생성돼 실행됩니다. 사용자는 PySpark 코드가 작성된 파일의 경로와 클러스터 A 사용 인증을 위한 Kerberos Keytab 파일 이름만 제공하면 됩니다. 그 아래 ClusterBSparksqlKubernetesPodOperator 클래스는 클러스터 B에서 Spark SQL 쿼리를 실행하고자 할 때 사용하는 클래스입니다. ClusterAPySparkKubernetesPodOperator와 같이 SQL 쿼리문이 작성된 파일의 경로와 Kerberos Keytab 파일 이름만 제공하면 됩니다.
아래는 Cluster A를 대상으로 PySpark 코드를 실행할 때 사용하는 ClusterAPySparkKubernetesPodOperator 클래스 샘플 코드의 일부입니다. 파라미터를 받아서 검증하는 로직을 거친 뒤 상위 클래스(KubernetesPodOperator)의 __init__ 함수로 값을 넘기고 있습니다.
from sample_core.tools.config_tool import ConfigTool
class ClusterAPySparkKubernetesPodOperator(KubernetesPodOperator):
def __init__(self, pyspark_file_path, keytab, *args, **kwargs):
config = ConfigTool.load_config()
...
...
super().__init__(
namespace=self.namespace,
image='clusterA_client:{version}'.format(version=config.docker.clusterA_client_version),
image_pull_secrets=[k8s.V1LocalObjectReference('xxx')],
image_pull_policy=config.airflow.image_pull_policy,
in_cluster=True,
is_delete_operator_pod=True,
affinity={
...
},
*args,
**kwargs)__init__ 함수로 넘기는 값을 살펴보면 실행되는 환경에 따라 유동적으로 변경되거나 고정된 값을 미리 지정해서 사용하고 있습니다. 이런 파라미터들은 저희가 내부적으로 Kubernetes 운영 정책에 맞게 미리 정의한 값이기 때문에 불필요하게 사용자들에게 노출할 필요가 없었습니다. 예를 들어 파드 스케줄링을 결정하는 affinity 파라미터 같은 경우에는 사용자에게 노출하지 않고 수정도 불가능합니다. 따라서, 사용자 테스트 환경에서는 사용자 테스트용 노드풀 중 임의의 노드로 파드가 스케줄링되고, 개발 환경에서는 개발 노드풀 중 임의의 노드로 파드가 스케줄링됩니다.
Airflow에 이미 익숙한 사용자들은 API 문서를 참고해 추가 파라미터를 설정할 수 있습니다. 예를 들어 on_retry_callback 함수를 추가로 지정한 경우에는 ClusterAPySparkKubernetesPodOperator 클래스의 kwargs로 값이 전달돼 KubernetesPodOperator.__init__의 키워드 인자로 on_retry_callback 파라미터 값이 전달됩니다.
정리해 보면, 숨겨야 될 부분은 숨기고 사용자에게 꼭 필요한 부분만 동일하고 심플한 패턴으로 노출시켜서 DAG 작성 난이도를 대폭 낮췄습니다. 또한 DAG 태스크별로 해당 태스크에 필요한 파라미터를 따로 추가할 수 있게 해서 범용성을 높였습니다.
마치며
이번 글에서는 사용자에게 멀티테넌시 Airflow 환경을 제공하기 위해 어떻게 준비하고 개발했는지 살펴봤습니다. 다음 글에서는 사용자들이 데이터 파이프라인 개발을 할 수 있도록 격리된 Airflow 환경을 제공하는 방법을 말씀드리고, Airflow를 자동으로 제공할 수 있는 설정까지 자세히 살펴보겠습니다. 많은 기대 부탁드립니다.