
안녕하세요. LINE+ ABC Studio에서 messaging-hub를 만들고 있는 송재욱입니다. messaging-hub는 독립적이고 범용적인 메시징 플랫폼이라는 방향으로 자체 개발하고 있는 시스템으로, 현재 일본의 No.1 푸드 딜리버리 서비스인 Demaecan에서 사용하고 있습니다. messaging-hub를 소개했던 이전 글(1편, 2편)에 이어 이번에는 서비스 운영 과정에서 진행한 몇 가지 트러블 슈팅 사례를 공유하겠습니다. 글은 다음과 같은 순서로 진행합니다.
첫 번째 사례: 불안정한 네트워크에서 '보냈는데 못 받은' 메시지
첫 번째 사례는 분명히 서버 푸시를 보냈음에도 클라이언트가 받지 못하는 현상의 원인을 파악하고 해결해 나간 사례입니다.
messaging-hub는 클라이언트와 웹소켓으로 연결돼 있습니다. 만약 앱이 백그라운드로 전환되는 등의 상황이 발생하면 클라이언트는 웹소켓 연결을 명시적으로 끊기 때문에 이때의 메시지는 Firebase Cloud Messaging(이하 FCM)으로 전환해 전달하는 식으로 예외 케이스에 대응할 필요가 있습니다. 물론 이는 예상했던 시나리오였고 사전에 대응도 해놓았습니다만 간과했던 부분이 발견됐습니다.
클라이언트 앱의 네트워크 환경은 유동적일 수 있어서 네트워크 연결이 끊겼다가 다시 연결되는 상황이 발생할 수 있습니다. Merchant 앱은 가게 안에서 대체로 고정된 상태로 운영된다는 특성상 네트워크가 안정적인 편인 반면, Driver 앱은 배달 라이더의 잦은 이동에 따라 수시로 네트워크 환경이 변화하기 때문에 상대적으로 네트워크가 불안정한 상태에서 작동한다고 할 수 있습니다.
처음에 재현 시나리오를 도출하기 전에는 서버 푸시를 보냈음에도 클라이언트가 받지 못했다는 결과에만 초점을 맞춰서 버그를 찾는 데 많은 시간을 쏟았습니다. 그러다 보니 '보냈는데 못 받았다'는 사실에 공포도 느꼈습니다. 그럼에도 다행이었던 점은 Merchant 앱 사용자에게서는 이런 상황이 보고되지 않았고 Driver 앱에 한정해 이슈가 발생했다는 점입니다. 이에 둘의 차이를 검토해 상황을 좁혀볼 수 있었고, Driver 앱 클라이언트 개발자 분과 이슈를 재현하기 위해 긴밀히 협업할 수 있었습니다.
네트워크가 불안정한 상태에서는 클라이언트 앱의 웹소켓 연결 유지 과정에서 문제가 발생합니다. 아래는 문제가 발생하는 과정을 정리한 사용 패턴 시나리오입니다. 참고로 Driver 앱에서 먼저 문제가 발생했던 것일 뿐 실제로는 어떤 클라이언트에서도 발생할 수 있는 시나리오였습니다. 시나리오는 아래와 같습니다.
- 클라이언트는 messaging-hub와 웹소켓으로 연결한다.
- 기기에서 네트워크를 강제로 끊는다(예: 비행기 모드).
- messaging-hub는 클라이언트와 웹소켓 연결이 끊겼다는 것을 인지하지 못한다(이 부분이 문제의 핵심입니다).
- 클라이언트가 연결되어 있다고 판단한 messaging-hub는 서버 푸시를 보낸다.
- messaging-hub는 서버가 메시지를 푸시했다고 판단한다.
- 클라이언트는 네트워크가 끊긴 상태이기 때문에 메시지를 받지 못한다.
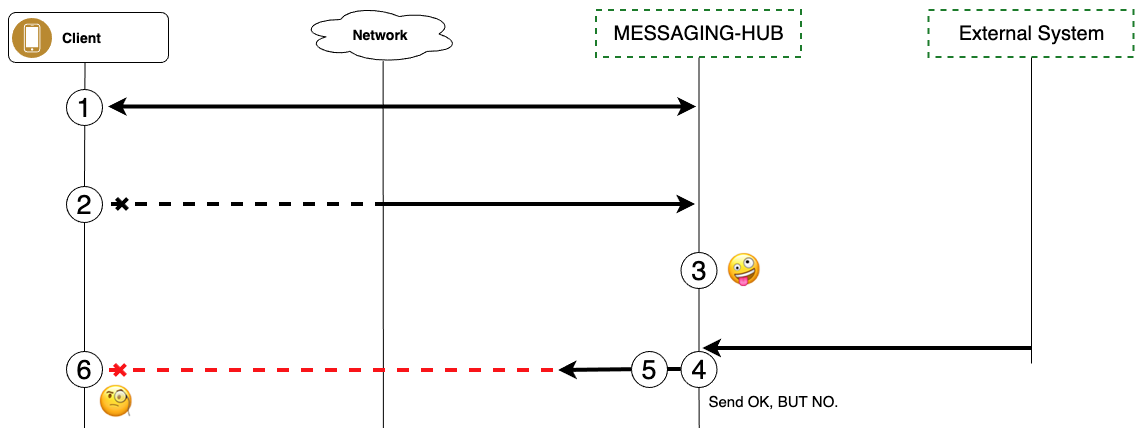
시나리오 3번, 기기의 네트워크가 끊긴 상황을 서버가 인지하지 못한다는 사실을 놓쳤던 것이 수렁으로 빠지게 된 원인이었습니다. 한때는 TCP 연결을 양쪽에서 고무줄을 맞잡고 있는 것이라고 비유적으로 생각하곤 했습니다. 팽팽해진 고무줄을 어디선가 끊는다면 상대 쪽도 연결이 끊겼다는 것을 알 수 있을 것이라고 말입니다. 하지만 이 생각은 TCP 연결과 그 수명 주기는 클라이언트의 네트워크 상태와는 별개라는 점을 간과했던 것으로 전제부터 오류를 머금고 있었습니다.
이런 현상을 'half-open'이라고 부릅니다. 이는 클라이언트의 네트워크가 강제 종료되는 것과 같은 상황처럼 웹소켓 닫기(close)가 명시적으로 처리되지 않고 유지되는 상황을 의미합니다. 시나리오 5번에서 서버가 메시지를 푸시했다고 판단하는 이유는 애초에 채널이 끊겼다는 사실을 콜백받지 못했기 때문입니다. 이때 서버의 푸시 성공 응답은 클라이언트에게 메시지가 안전하게 전달됐다는 의미가 아니라, IO 버퍼에 쓰기(write)하는 것을 성공했다는 뜻입니다. 그러니까 서버는 현재 연결된 클라이언트의 채널을 통해 IO 버퍼로 메시지를 보낼 수 있는지에 대한 조건만 확인할 수 있을 뿐 네트워크에 문제가 발생했는지는 독자적으로 판단할 수 없습니다. 결국 코드로 시그널을 받을 수 있어야 하는데 그럴 수 없기 때문에 현재 커버하지 못하는 회색 영역이 존재한다는 사실을 인정할 수밖에 없었습니다.
시나리오가 나왔고, TCP 연결이 끊기는 상황을 서버로 트리거할 수 없는 상황을 이해했으니 이제 대책을 강구해야 했습니다. 저는 이 상황을 타개할 최대한 명료하고 공신력 있는 가이드를 알고 싶었고, 웹 표준을 세우고 가이드라인을 제공하는 W3C에서 이와 관련된 힌트를 얻을 수 있었습니다.
- 푸시 메시지는 클라이언트가 일시적으로 오프라인일 때도 보낼 수 있어야 한다.
- 이를 위해서는 푸시를 보내는 서비스에서는 클라이언트가 메시지를 수신할 수 있는 상태가 될 때까지 메시지를 보관해야 한다.
이 글을 읽는 순간 FCM의 작동 방식을 닮았다는 생각이 들었습니다. 기기의 전원이 꺼졌거나 네트워크가 차단된 뒤 다시 온라인 상태가 됐을 때 FCM 알림 푸시 메시지가 우르르 쏟아지는 경험을 해보셨을 겁니다. 이는 푸시 메시지를 보관하고 있다가 클라이언트가 온라인 상태로 복귀했다는 것을 서버가 인지한 시점에 보관된 메시지를 클라이언트에게 보내는 절차와 같습니다. FCM 문서에서도 이와 같은 내용을 확인할 수 있었습니다.
messaging-hub에서는 이미 RECENT_MESSAGES라는 커맨드(messaging-hub에서 독자적으로 사용하는 통신 프로토콜)를 제공하고 있습니다. 이름에서 알 수 있듯이 해당 클라이언트에게 전달된 최근 메시지를 조회할 수 있는 커맨드입니다. 이 커맨드를 이용해 클라이언트에서 웹소켓에 연결한 후 자신이 받지 못한 메시지와 관련해서 messaging-hub에서 보관하고 있는 최근 메시지를 가져가서 비즈니스 로직에 활용할 수 있기 때문에, 이 커맨드를 클라이언트에서 잘 활용하는 것도 문제 해결 방법 중 하나라고 생각했습니다.
하지만 이렇게 넘어가기에는 여전히 웹소켓의 '연결 확인'과 '메시지 수신 확인'을 지원하지 못한다는, 신뢰의 관점에서 대응해야 할 이슈가 남아 있다고 생각했습니다. RECENT_MESSAGES를 이용한 해결책을 사용하면 클라이언트에서 메시지 수신 관련 처리를 꼭 해야 한다는(해달라고 요청해야 하는) 부담이 생기지만, 클라이언트의 연결 확인과 메시지 수신 확인이 가능하다면 서버에서 이 정보를 이용해 능동적으로 푸시 방식을 선택하고 재발송하는 등의 처리가 가능합니다. 이는 messaging-hub 시스템의 완결성 측면에서도 중요한 이슈입니다.
해결 방법 1: 연결 확인 과정 확립
첫 번째로 연결 확인에 대해 정리했습니다. Netty를 만든 이희승 님이 Stackoverflow에 남겨주신 댓글을 요약해서 인용하면 '네트워크가 비정상적으로 끊겼을 때 이를 감지하는 방법은 주기적으로 클라이언트에게 메시지를 보내고 예상되는 응답을 통해 판단하는 것이다'입니다. 더 짧게 요약하면 'ping-pong'을 구현하라는 내용입니다. 웹소켓 프로토콜과 관련해 RFC-6455를 읽어보면 마찬가지로 ping-pong에 대한 얘기가 나옵니다.
messaging-hub는 서버 인프라의 idle 타임아웃 때문에 연결이 끊기는 것을 방지하기 위해서 주기적으로 ping 요청을 보내고 있습니다. 다만 이를 웹소켓 연결 확인용으로 사용하고 있지 않았기 때문에 클라이언트에게 ping에 대한 pong을 응답해 달라고 요청하지 않았습니다. 이번 사례를 계기로 클라이언트 개발자분들께 pong 처리를 부탁드렸고, 더불어 pong에 대한 서버 응답으로 'PONG_ACK'를 하나 더 추가했습니다. 클라이언트 입장에서도 pong에 대한 ACK를 명시적으로 받음으로써 자체적으로 연결 처리를 할 수 있도록 하기 위함입니다. 그러니까 양방향 연결 확인이 가능해진 셈입니다.
또한 연결 상태의 idle 여부에 따라 서버가 웹소켓을 닫는 방식을 ping에 대한 pong이 구현된 클라이언트 버전부터 사용하기 위해서는 클라이언트의 버전에 따른 분기 처리가 필요했습니다. 이에 클라이언트 배포 일정에 의존하지 않고 서버 먼저 작업 결과물을 배포하기 위해서 Remote Config를 사용했습니다. 참고로 서버에서 ping 요청을 보내거나 클라이언트에게서 pong 응답을 받지 못했을 때의 처리 관련 타이밍 작업에서는 Netty의 IdleStatHandler를 사용했습니다. ReadTimeoutHandler도 검토했으나 ReadTimeoutHandler에는 이벤트 콜백 후 내부적으로 연결을 닫는 로직이 있었습니다. 클라이언트 앱의 하위 호환을 지원하기 위해서는 하위 버전의 클라이언트에서는 내부에서 연결이 닫히면 안 되고 직접 제어해야 했기에 사용할 수 없었습니다.
해결 방법 2: 메시지 수신 확인 절차 확립
두 번째로 메시지 수신 확인 방식을 정리했습니다.
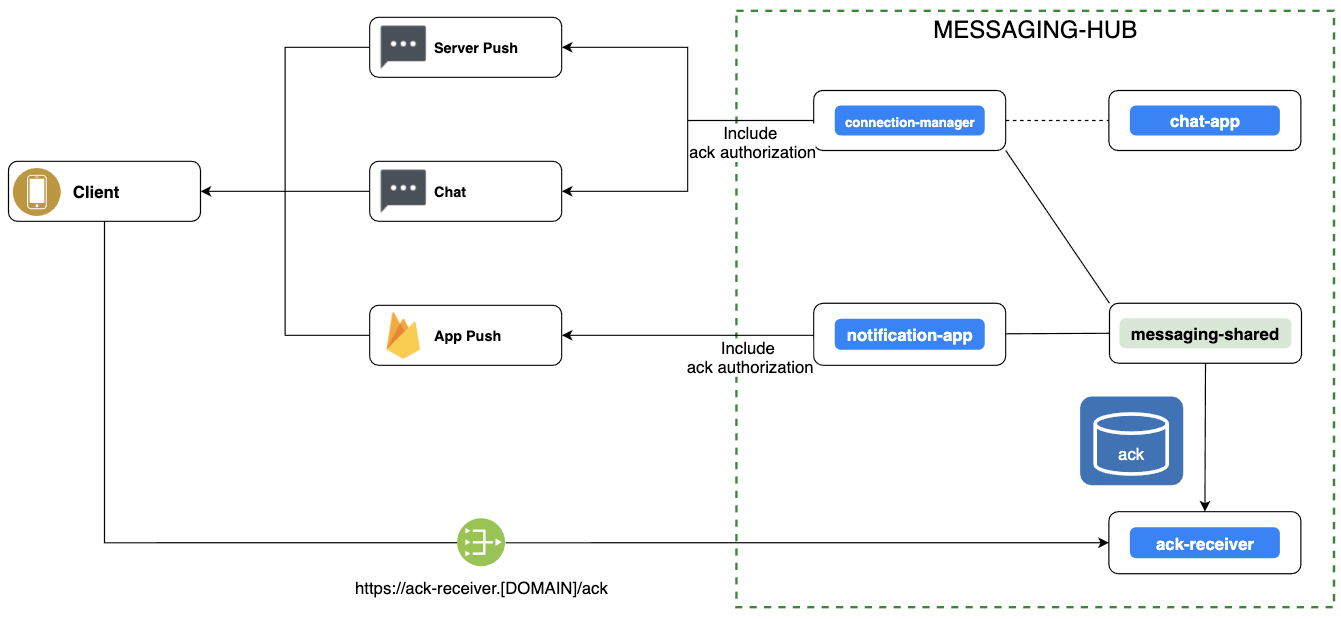
messaging-hub에서 클라이언트로 메시지를 전달하는 채널이 다변화되고 있기 때문에 메시지 수신 확인 처리 방식을 일원화할 필요가 있었습니다. 그래서 ACK 리시버 API 서버를 뒀고, 엔드 포인트의 요청 포맷을 통일했습니다.
그런데 한 가지 걱정이 생겼습니다. messaging-hub 관련 이전 블로그를 보신 분이라면 아실 텐데요. messaging-hub와 연결된 클라이언트는 messaging-hub를 위해 만들어진 클라이언트가 아닙니다. 본체 시스템(여기서는 Merchant/Delivery 시스템을 말하며 messaging-hub 관점에서는 이들을 외부 시스템(external system)이라고도 함)이 별도로 있고, messaging-hub는 메시지 통신을 위해 추가로 연동하는 시스템입니다. 이와 같이 도메인이 분리돼 있기 때문에 클라이언트의 본래 인증 정보를 messaging-hub에서 직접 접근하는 것은 강력하게 금지돼 있습니다.
이런 상황에서 클라이언트에게서 직접 수신 확인 API 호출을 받아야 하기 때문에 '호출한 클라이언트가 유효한 사용자인지 어떻게 판단할 수 있을까?'라는 문제를 해결해야 했습니다. 그렇다고 클라이언트에서 본체 시스템을 경유해서 messaging-hub로 ACK를 전달하게 하면 지나치게 엔지니어링이 복잡해지고 각 시스템의 강결합을 야기합니다.
이를 피하기 위해 메시지에 추가로 ACK에 대한 인증 토큰을 포함시키는 방법을 선택했습니다. 클라이언트는 사전에 합의한 도메인으로 인증 헤더와 수신 시간을 넣어서 호출하면 됩니다. 여러 번 호출하더라도 최초에 단 한 번만 반영되도록 해서 혹시나 모를 어뷰징을 방지했습니다. 처음에는 도메인 정보도 서버에서 관리하고 전달하려고 했으나 클라이언트에서 외부로 호출하는 도메인의 안전 확인 작업을 거치지 않으면 보안 위협의 요인이 될 수 있다는 피드백에 따라 도메인 정보는 클라이언트에서 관리하기로 했습니다. 단순히 생각했을 때는 도메인 정보도 서버가 전달하는 방식이라면 클라이언트는 받은 대로 수신 확인을 보내면 되니 훨씬 더 편할 것이라고 생각했는데 '보안 위협의 소지가 있다'는 클라이언트 개발자분의 얘기를 듣고 나니 '이래서 협업 과정이 배움의 연장이구나'라고 느낄 수 있어서 개인적으로 감사했습니다.
이렇게 메시지 수신 확인 절차가 완성되면 활용 가치가 있는 정보가 생깁니다. 메시지를 전달했지만 클라이언트에서 받지 못했다는 것을 추적하는 근거로 활용할 수 있고, 클라이언트의 종류나 환경, 메시지 종류와 관련해 메시지 도달률을 체크해 볼 수 있을 뿐 아니라, 메시지를 정상적으로 수신하지 않은 클라이언트는 서버에서 연결을 명시적으로 끊고 FCM으로 전환하는 등 비즈니스 관점에서도 활용할 수 있습니다. 물론 클라이언트의 응답에 의존하기 때문에 충분한 시간을 거쳐 보완해 나가며 신뢰성을 확보하는 과정이 꼭 필요합니다.
두 번째 사례: 평생 마주치고 싶지 않았던 Out Of Memory
일본 동쪽 지역에 배포할 때까지는 별다른 이상이 없었던 웹소켓 서버(connection-manager)가 서쪽 지역까지 확대 배포한 이후 Out Of Memory(이하 OOM)를 일으켜 쿠버네티스 파드(pod)가 재시작되는 일이 발생했습니다. 당시 별다른 GC(garbage collection) 튜닝 없이 가장 기본적인 옵션으로 힙 메모리 정도를 설정해서 사용하고 있었습니다.

수년 전에 다른 서비스를 운영했을 때의 일입니다. JDK 1.7 버전을 사용하고 있었는데 한정된 서버 자원 내에서 안정적인 메모리 운영에 문제가 있어 GC 튜닝을 진행했던 적이 있습니다. 여러 가지 튜닝 테스트의 결과는 허무하게도(물론, 소중한 배움의 기회였습니다만) 결국 JDK 1.8로 버전을 올리는 것과 함께 약간의 기본적인 옵션을 설정하는 것이었습니다.
개인적으로 JVM으로 구동되는 시스템에서 GC 튜닝은 가장 마지막에 고려해야 할 선택지라고 생각합니다. 이에 우선 가장 손쉬운 선택인 스케일 아웃으로 급한 불을 끄고, 메모리 덤프로 누수가 생기는 곳은 없는지 살펴봤습니다. 메모리를 상대적으로 많이 소비하고 있는 오브젝트가 있긴 했지만 필요에 따라 의도된 상황이었고, 그 외에 특별히 개선해야 할 포인트를 찾지는 못했습니다. JDK 11 버전을 사용하고 있었고, 최소한의 JVM 기본 옵션인 -Xmx와 -Xms를 설정한 상태였습니다. 그렇다고 마이크로 매니징 수준의 GC 튜닝을 섣불리 감행하기에는 해당 서버가 하는 일의 복잡도가 그리 높지 않다고 판단했습니다.
하지만 OOM이 발생해 쿠버네티스 파드가 재시작하는 상황은 운영 관점에서 반드시 해소해야 하는 이슈였습니다. 혹시라도 JDK 버전이 올라가면서 제가 놓친 구동 설정이 있는지 알아보는 한편, 쿠버네티스를 사용하고 있기 때문에 컨테이너 환경에 따른 권장 설정도 다시 파악했습니다.
해결 방법 1: 쿠버네티스 QoS 클래스 변경
쿠버네티스는 컨테이너 구동과 관련해 리소스의 요청 스펙(resource.request)과 상한 스펙(resource.limit)을 지정할 수 있습니다. 이 설정에 따라 컨테이너의 QoS 클래스는 Guaranteed, Burstable, BestEffort 중 하나가 됩니다.
- Guaranteed: 리소스(CPU와 메모리) 설정을 하면서 요청 설정값과 상한 설정값을 같게 설정하면 Guaranteed가 부여됩니다.
- Burstable: Guaranteed 기준에 맞지 않고, 리소스 요청 설정값과 상한 설정값이 다를 때 Burstable이 부여됩니다.
- BestEffort: 리소스 요청과 상한 설정을 하지 않았을 때 BestEffort가 부여됩니다.
OOM 때문에 파드가 다운된 후 재시작하는 것은 노드에서 가용할 수 있는 메모리를 상회하는 요청 때문에 해당 컨테이너가 종료되면서 발생합니다. 종료된 파드가 자동으로 재시작하는 것은 다행스러운 일이지만, 공교롭게도 그 순간 외부 연동을 통해 요청된 처리에 대해서는 실패 응답이 발생합니다. 그러므로 가장 신뢰할 수 있는 형태의 QoS 클래스를 설정하는 것이 좋다고 봅니다.
메모리 부족에 따른 파드 종료 관점에서 BestEffort는 가장 신뢰성이 떨어집니다. 그렇지만 무조건 안 좋다고 생각하기보다는 리소스에 여유가 있다면 여유분을 모두 사용할 수 있지만 한편으로는 리소스가 부족해지면 가장 먼저 종료된다는 트레이드오프가 있다는 것을 인지하고 상황에 맞게 사용하는 게 좋습니다. Burstable은 BestEffort보다는 보수적으로 종료되지만 리소스 압박이 발생하면 여전히 종료될 가능성이 있습니다. Guaranteed는 리소스 한도 초과가 발생하지 않는 한 종료되지 않는다는 것을 보장해 줍니다. 따라서 리소스 압박이 발생한 상황에서 종료될 수 있는 가능성을 우선순위로 매기자면, BestEffort > Burstable > Guaranteed 순입니다.
당시 CPU는 request : limit = 1000m : 1500m이었고, memory는 request : limit = 2Gi : 3Gi로 설정돼 있었습니다. 따라서 QoS 클래스는 Burstable이었습니다. 이를 Guaranteed로 바꾸기 위해서 동일한 크기인 1500m과 3Gi로 변경했습니다.
해결 방법 2: JVM 옵션 설정
다음으로 JVM 옵션에 대한 내용입니다. 전통적으로 힙 메모리를 할당하는 방법으로 -Xmx와 -Xms 설정을 사용합니다. 더불어 -Xms 크기에서 -Xmx로 확장될 때 소비되는 워밍업 시간을 줄이기 위해서 동일한 크기로 설정하곤 합니다. messaging-hub에서도 그와 같이 설정하고 있었는데 이번 이슈가 터지고 설정을 검토하던 중에 -XX:MaxRAMPercentage라는 옵션을 알게 됐습니다.
-XX:MaxRAMPercentage는 할당된 메모리에서 어느 정도의 비율을 힙 메모리로 사용할지 설정하는 옵션입니다. 이 설정은 컨테이너 환경에서 쓸모가 많다고 생각합니다. 가령 컨테이너의 리소스에 할당된 메모리 상한이 3Gi라고 했을 때 JVM의 힙 메모리에는 어느 정도를 할당하는 게 적당할까요? 이는 단순하게 답하기 어려운 질문입니다. 왜냐하면 컨테이너 내에서 사용 가능한 메모리에는 힙 메모리 외에도 다른 영역을 위해 얼마간의 크기를 남겨 놓아야 하기 때문입니다. 만약 리소스 상한과 같은 크기로 힙 메모리 할당을 설정하면 파드는 메모리 부족으로 구동되지 않습니다. 그래서 반드시 더 작은 값을 힙 메모리에 할당해야 합니다. 보통 여분이 어느 정도인지 가늠하기 어렵기 때문에 설정의 특성상 정수로 할당하곤 합니다. 그러다 보니 상한이 3Gi라면 2Gi 정도로 할당하는 식이 돼버립니다. -MaxRAMPercentage 옵션은 이런 고민을 많이 줄여줍니다. 가용할 수 있는 크기 중 얼마의 비율을 할당할지만 설정하면 되기 때문에 가용 크기를 변경하는 상황이 생기더라도 JVM 옵션을 다시 건드릴 일은 별로 없습니다. 설정하는 입장에서는 조금 더 간편해졌다고 생각합니다.
이때 주의할 점이 있습니다. -XX:MaxRAMPercentage 옵션을 살펴보다 보면 자연스럽게 -XX:MinRAMPercentage 옵션도 알게 됩니다. 여기서 우리는 이 둘의 관계를 관성적으로 -Xmx와 -Xms 옵션의 관계와 같을 것이라고 생각하게 됩니다. 그리고 워밍업을 없애기 위해 -Xmx와 -Xms를 같은 값으로 설정하듯 자연스럽게 -MaxRAMPercentage와 -MinRAMPercentage 옵션도 똑같은 값으로 설정하게 됩니다. -MinRAMPercentage 옵션을 힙 메모리의 최소 크기 비율이라고 이해한 결과입니다. 그러나 -MinRAMPercentage 옵션은 그렇게 작동하지 않습니다. -MinRAMPercentage는 가용할 수 있는 메모리의 크기가 250MB보다 작을 때 적용되는 옵션입니다. 예를 들어 가용 영역이 100MB일 때 -MinRAMPercentage를 50으로 설정하면 힙 메모리는 50MB가 할당됩니다. 그렇다면 -MaxRAMPercentage 옵션의 경우는 어떨까요? -MaxRAMPercentage는 가용 영역이 250MB보다 클 때 적용되는 옵션입니다. 예를 들어 가용 영역이 1GB일 때 -MaxRAMPercentage를 70으로 설정하면 힙 메모리로 700MB가 할당됩니다. 즉 -MaxRAMPercentage와 -MinRAMPercentage 옵션은 컨테이너 혹은 물리 서버의 가용 메모리 영역이 250MB보다 큰지 작은지를 기준으로 각 상황에서 힙 메모리를 비율로 할당할 때 적용하는 옵션입니다. 보통 프로덕션 수준과 같이 GB 단위로 메모리를 사용하는 환경이라면 굳이 -MinRAMPercentage 옵션은 설정하지 않아도 된다는 말입니다. 결론적으로 저는 -MaxRAMPercentage 옵션을 70으로 설정했습니다.
이게 끝이 아닙니다. 하나 더 주의할 점이 있습니다. -MaxRAMPercentag나 -MinRAMPercentage 옵션을 사용할 때 -Xmx 옵션과 함께 사용하지 않는 편이 좋습니다. *RAMPercentage 관련 옵션을 사용했다는 것은 힙 메모리를 비율로 정하겠다는 의도를 명확히 드러낸 것이라고 봅니다. 따라서 이 옵션을 추가하는 개발자는 -Xmx보다 더 강력한 의도를 가지고 옵션을 설정했을 가능성이 높습니다. 그런데 -Xmx 옵션을 함께 쓸 경우 *RAMPercentage 옵션은 반영되지 않습니다. -Xmx의 우선순위가 더 높기 때문입니다.
적용 결과
이와 같이 OOM 이슈를 해결하기 위해 두 가지 작업을 진행했습니다. Kubernetes 컨테이너의 QoS 클래스를 Guaranteed로 설정했고, JVM 옵션을 -MaxRAMPercentage로 바꿨습니다. 이후 모든 파드의 메모리 상황은 안정을 되찾았고, OOMKilled는 더 이상 발생하지 않고 있습니다.
아래 JVM 힙 메모리 그래프를 보면 가용 영역 대비 사용률이 매우 안정적인 상태라는 것을 확인할 수 있습니다. 향후 가용 메모리 크기를 점진적으로 낮춰보면서 이를 통해 확보한 추가 메모리를 스케일 아웃에 활용할 수 있습니다.

세 번째 사례: 웹소켓 연결이 동시에 끊겼는데 네트워크 장애가 아니라면?
웹소켓 연결 드롭
어느 날 무시무시한 그래프가 발견됐습니다. 최대 트래픽이 아니었음에도 웹소켓 연결이 일순간 드롭되며 그래프에 깊은 골짜기를 만들어 냈습니다. 이 현상은 일회성에 그치지 않았고, 비정기적으로 꾸준히 발생했습니다. 트리거가 될만한 전조증상을 찾아 문제의 원인을 찾는 게 무엇보다도 중요한 사례였습니다.
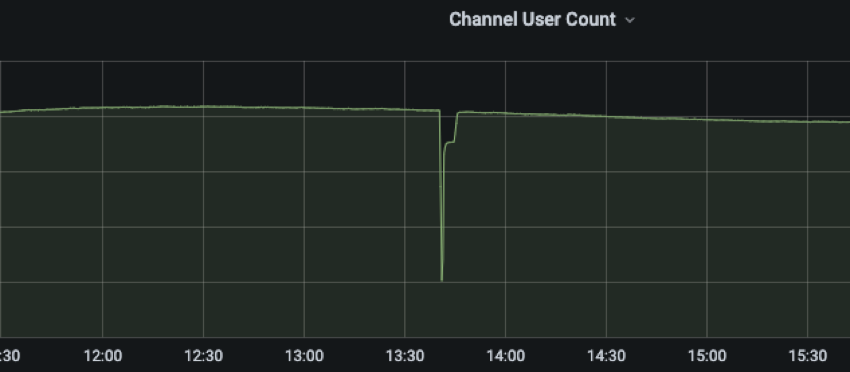
이 와중에도 다행이었던 점은 웹소켓이 모두 끊기더라도 messaging-hub는 각 메시지를 FCM 발송으로 전환하기 때문에 메시지를 받아야 할 클라이언트에게는 영향이 전파되지 않았다는 것입니다. 그래서 처음에는 여유를 두고 천천히 문제에 접근해야겠다고 생각했습니다. 그런데 모든 일이 생각대로만 흘러가면 참 좋겠는데 그렇지 않은 것이 운영의 묘미 아니겠습니까?
API DDoS 발생
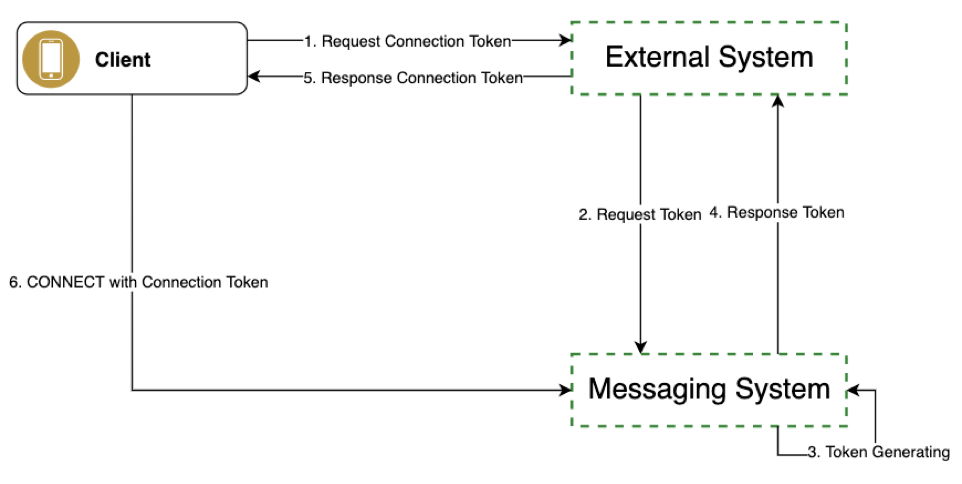
앞서 발행된 messaging-hub 블로그를 보신 분이라면 아시겠지만, 클라이언트가 messaging-hub와 웹소켓으로 연결하기 위해서는 커넥션 토큰(connection token)이 필요합니다. 이를 발급받기 위해서는 본체 시스템(Merchant/Delivery 시스템, 아래 그림의 External System)을 경유하는 흐름이 필요합니다.
웹소켓 드롭이 발생하면 클라이언트는 협의된 대로 재연결을 시도합니다. 그런데 서비스 적용 범위가 넓어지면서 연결 수가 많아지다 보니 토큰 발급을 위한 트래픽이 본체 시스템으로 몰리는 상황이 발생했습니다. 한 마디로 API DDoS가 발생한 것입니다.
앞서 messaging-hub는 Merchant와 Delivery 시스템과 연동 중이라고 말씀드렸습니다. 이 중 Merchant 시스템에서 Delivery 시스템에 비해 훨씬 많은 웹소켓 드롭 건수가 발생했는데 그 이유는 Merchant 앱의 네트워크 상태가 대체로 Driver 앱보다 안정적이면서 사용 패턴의 특성상 앱을 켜놓는 경우가 많아서 연결을 유지하는 수가 더 많기 때문으로 추정할 수 있습니다. Merchant 시스템은 messaging-hub의 토큰 발급을 위한 API뿐 아니라 다른 시스템과의 연동과 자체 비즈니스 로직도 포함하고 있습니다.
이런 상황에서 토큰 발급 API가 과도하게 몰리자 처리가 지연됐고, 이게 다시 다른 컴포넌트에 영향을 미치면서 이슈 전이가 발생했습니다. 결국 이 현상은 Merchant 사용자에게 직접 영향을 끼치는 이슈로 번졌고, 이에 messaging-hub에서도 문제의 원인인 웹소켓 드롭을 해결하는 게 무엇보다도 높은 우선순위가 되었습니다. 더불어 Merchant 시스템이 겪고 있는 지연 이슈에 대해서도 별도로 개선 포인트를 찾고 대응해야 했습니다.
급한 불을 끄는 것이 우선이었기 때문에 API DDoS 발생 시 지연 처리가 발생하는 위치를 찾기 위해 Merchant 시스템 개발자분들과 함께 스트레스 테스트를 진행해 지연 구간을 찾았습니다. 결론적으로 Merchant 시스템에서 사용하는 DB가 병목 구간이었습니다. 이에 messaging-hub 토큰 발급 때문에 다른 Merchant API에 지연이 발생하는 것을 최소화하기 위해서 Merchant 시스템에서 토큰 발급 API를 별도로 분리해 배포해 주시는 것으로 대응을 마무리했습니다.
API 분리는 웹소켓 드롭 이슈가 아니더라도 인프라 혹은 네트워크에 장애가 발생하면 동일한 상황이 발생할 수 있기 때문에 추후를 위해서라도 필요한 조치였다고 생각합니다. 그러나 아직 근본적으로 messaing-hub 이슈가 연동 시스템에 부하를 초래하는 현상은 풀어야 할 숙제로 남아 있습니다.
Nginx 패킷 드롭 발생
API DDoS의 영향으로 messaging-hub에서도 이슈가 하나 발견됩니다. 바로 Nginx에서 패킷이 드롭되는 현상입니다. 패킷 드롭 때문에 에러가 발생하면 호출하는 측에서 요청을 다시 시도하겠지만, 그렇다고 묵과할 일은 아니었습니다. 말 그대로 패킷이 버려지는 현상이다 보니 오히려 꽤 심각한 수준으로 받아들였습니다. 아직 이 현상의 근본 원인인 웹소켓 드롭 발생 이유가 불분명한 상태라서 언제든 재발 가능성이 있기 때문입니다.
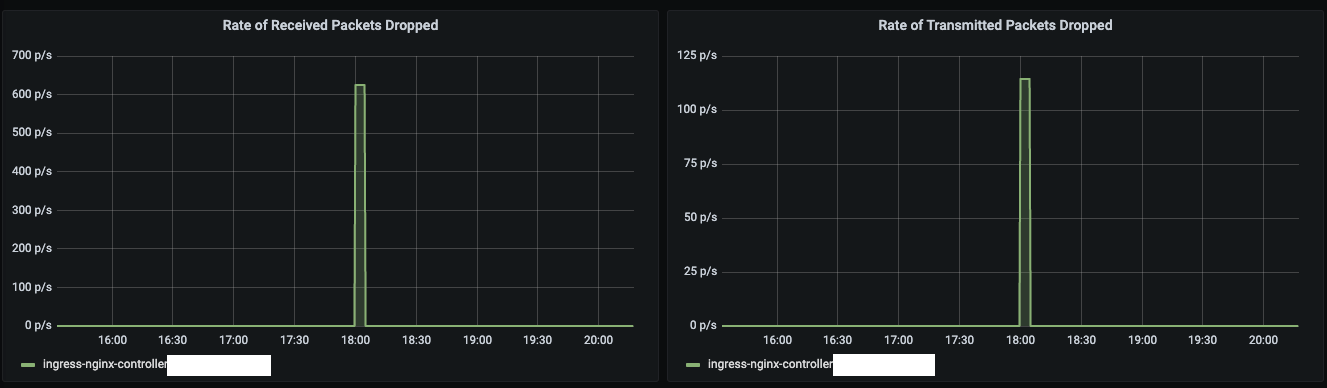
네트워크를 모니터링해서 원인을 파악할 수 있었습니다. 트래픽이 몰리는 시점에 NF_CONNTRACK 모듈에서 관리하는 테이블이 임계치에 도달하며 Nginx에서 패킷 드롭이 발생했습니다. NF_CONNTRACK는 iptables(리눅스의 방화벽 설정을 처리)의 상태를 추적하는 모듈로 네트워크의 연결 상태를 기록하는데 이때 상태를 기록하는 테이블이 꽉 차면 이후 들어온 패킷은 드롭됩니다. 이를 해결하는 방법으로는 NF_CONNTRACK의 테이블 최댓값을 수정하거나 모듈을 언로드(unload)하는 방법이 있지만, 섣불리 운영체제의 시스템 정보를 수정하기보다는 직접 제어할 수 있는 부분을 변경하는 보수적인 방법을 선택했습니다. 바로 스케일 아웃입니다.
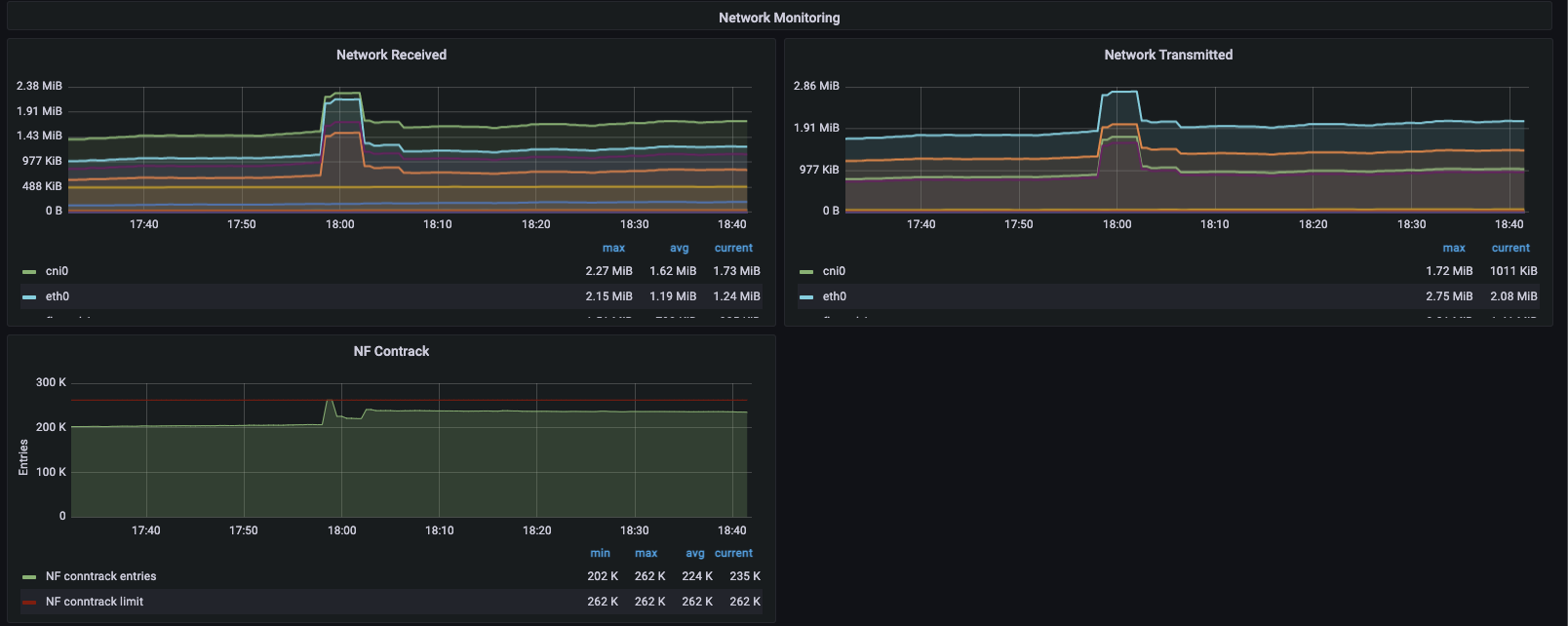
Nginx를 증설한 이후에 또다시 웹소켓 드롭이 발생하고 API DDoS로 이어졌지만 더 이상 Nginx 패킷 드롭은 발생하지 않았습니다.

그런데 Nginx를 증설할 때 한 가지 신경 써야 하는 점이 있습니다. 바로 증설된 Nginx는 각각 다른 노드로 배포돼야 한다는 것입니다. NF_CONNTRACK는 VM당 하나씩 갖는 모듈이므로 한 노드에 중복 배포되면 스케일 아웃 효과가 그만큼 떨어집니다. 쿠버네티스를 기준으로 노드가 3대 있는 상황에서 테스트를 진행했습니다. 아무 설정 없이 배포했을 때 아래와 같이 우연찮게 Nginx 파드가 같은 노드에 배치된 것을 확인할 수 있습니다.

어피니티(affinity)를 사용하면 운에 따라 결정되는 이런 상황을 피해 제대로 분배되게 만들 수 있습니다. 저는 파드 안티-어피니티(anti-affinity)와 레이블 셀렉터(label selector)를 사용해서 같은 파드가 한 노드에 여러 개 배치되지 않도록 설정했습니다.

여기서 또 한 번 주의할 점은, 노드 수 이상으로 스케일 아웃하려는 경우에는 펜딩(pending)이 발생한다는 것을 인지하고 있어야 한다는 것입니다.

다시, 추적 시작
웹소켓 드롭으로 파생된 API DDoS 이슈를 해소한 뒤, 다시 본격적으로 본래 이슈인 웹소켓 드롭을 추적했습니다. 당시의 소회를 밝히자면, 며칠간 자면서도 악몽에 시달릴 정도였습니다. 꿈에서도 웹소켓 드롭이 발생해서 원인을 찾으려고 끙끙대는 제 자신이 안쓰러울 지경이었고, 꿈에서 깨어나면 현실도 다르지 않았습니다.
인프라와 네트워크 팀에 여러 차례 문의했으나 그때마다 여전히 문제없다는 답변이 돌아왔기 때문에 제가 제어할 수 있는 시스템 내에서 발생할 수 있는 문제로 한정해서 실마리를 찾아야 했습니다. 때때로 문제가 너무 안 풀릴 땐 요행을 기대하는 경우가 있습니다. 그러나 이 문제는 명확하게 원인을 파악하지 못하면 해결하기 어려운 문제였고, 결국 모든 가능성을 전부 검토해 보는 정공법으로 돌파해야 했습니다.
1. 웹소켓 연결을 관리하는 connection-manager 확인
웹소켓 연결을 관리하는 connection-manager를 먼저 살펴봤습니다. 혹시나 하는 마음에 운영 대수를 50% 추가로 늘려봤지만 유의미한 변화를 관찰하기는 어려웠습니다. 이미 기존에도 컨테이너 리소스가 문제될 상황은 아니었고, connection-manager 1대당 수천 개 정도의 커넥션이 유지되는 수준에서 밸런싱도 문제가 없었습니다.
GC로 인한 영향도 파악해 봤지만 앞서 OOMKilled 이슈에 대응한 상황에서 더 이상 메모리 이슈는 발견되지 않고 있었습니다. connection-manager에 서버가 클라이언트의 연결을 끊는 로직이 있었지만 극히 제한적인 상황에서 가동되는 로직이었고 실제로도 원인이 아니었습니다. 계속해서 그 밖의 웹소켓 설정과 로직 등을 살펴봤지만 connection-manager가 주체가 되어 연결을 대량으로 끊을 만한 상황은 발견되지 않았습니다.
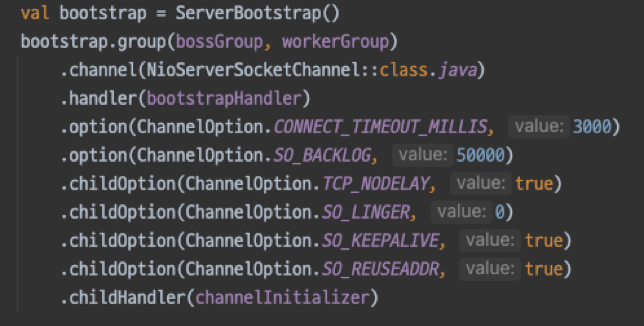
connection-manager에는 idle 핸들러가 등록돼 있고, 연결에서 idle 이벤트가 발생하면 이를 콜백 받아 클라이언트에게 PING을 보내고 있습니다. 웹소켓 연결이 idle 타임아웃 때문에 끊기는 것을 방지하기 위해서입니다. connection-manager에서 관리하는 idle 타임아웃은 3분이었고, 로드밸런서(loadbalancer, 이하 LB)나 Nginx의 idle 타임아웃은 그보다 긴 5분으로 설정한 상태였습니다. 만에 하나 PING이 전송되지 않았다면 연결이 끊길 수 있겠지만 각 연결의 타임아웃 주기는 접속 시점에 따라 다르므로 동시에 연결이 끊기는 상황의 원인으로 판단하기에는 무리가 있었습니다.
2. connection-manager 한 대당 소켓 수 설정 확인
다음으로 connection-manager 한 대가 가질 수 있는 소켓 수를 결정하는 설정을 확인했습니다. 각 클라이언트 커넥션은 각각 하나의 로컬 포트를 사용하며 포트 범위(port range)는 1~65535입니다. /proc/sys/net/ipv4/ip_local_port_range에서 확인해 보면 가용 포트는 약 28,000개로 확인됩니다. 로컬 포트만 할당된다면 Netty에서 연결을 거부할 이유는 없어 보입니다. 따라서 로컬 포트 가용 영역도 넉넉하다고 볼 수 있기 때문에 이 설정에는 특이사항이 없다고 판단했습니다.
아주 예전에 다른 서비스를 운영할 때 TCP 연결을 종료하는 과정인 4way-handshake에서 발생하는 TIME_WAIT이 문제가 됐던 적이 있습니다. TIME_WAIT은 연결을 끊는 쪽에서 발생하는데 당시에는 서버에서 연결을 대량으로 끊으면서 서버 쪽에 TIME_WAIT이 그 수만큼 발생했습니다. 당연하게도 이것이 해소되기 전까지 가용 포트가 부족해지는 상황이 발생했고, 연결을 시도하는 클라이언트에서 실패가 발생했습니다. TIME_WAIT은 패킷이 정상적으로 전달되도록 보장하기 위한 대기 시간임과 동시에 그 시간만큼 포트를 재사용하지 못하게 묶어두는 역할을 합니다. 따라서 서버에서 연결을 종료하는 경우 포트 고갈의 원인이 되기도 합니다. 그러나 이번에 netstat으로 확인해 보니 무시해도 될 만한 수준이었습니다.
소켓은 운영체제의 파일 디스크립터를 사용하기 때문에 open files 또한 소켓 수의 한계를 결정하는 요인 중 하나입니다. ulimit로 확인했을 때 이 값은 1048576로 충분했습니다. 그 밖에 Nginx가 허용할 수 있는 최대 접속 수(worker_processes와 worker_connections의 곱)도 충분했으며 운영 중인 현 상황을 하회하고 있었기에 특이사항은 없다고 판단했습니다.
이미 예상하셨듯이, 처음부터 소켓 연결의 허용량을 초과하는 것이 웹소켓 커넥션 드롭을 야기하는 직접적인 원인이 될 것이라고 보기는 어려웠습니다. 다만 전수조사를 하는 마음으로 처음부터 하나씩 설정을 살펴봄으로써 혹시나 하는 작은 의심을 확실히 걷어내기 위한 확인이었습니다.
3. 웹소켓 연결이 끊기는 클라이언트 종류 조사 및 확인
웹소켓 연결이 끊기는 클라이언트의 종류를 조사해 본 결과 Merchant 앱이 압도적으로 높았습니다. 점검 차원에서 클라이언트 개발자분들께 확인을 요청드렸습니다. 그 당시 인프라 및 네트워크 팀에서 클라이언트에서 연결을 끊는다는 취지로 아래와 같이 캡처한 지표를 공유해 주셨습니다.
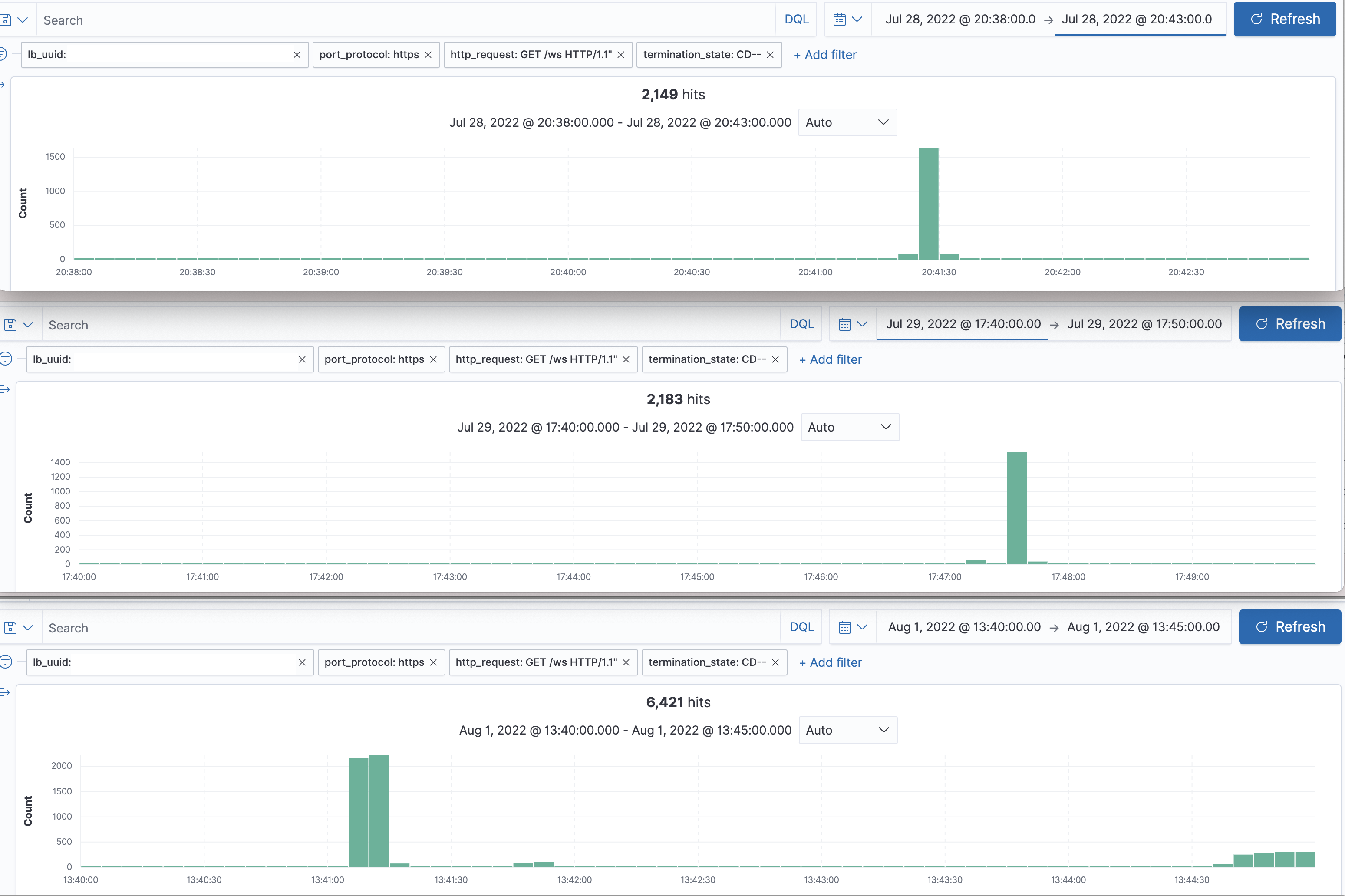
처음에는 이 지표를 '클라이언트가 연결을 끊는다'로 잘못 해석했습니다. 조금만 더 생각해 봐도 상식적으로 독립적인 기기 환경에서의 클라이언트가 일순간 약속이나 한 듯 동시에 연결을 끊는다는 것은 매우 이해하기 어려운 일입니다. 오히려 이 지표에 대한 해석은 지금 찾고 있는 연결을 끊어내는 주체 때문에 발생한 정상적인 리셋 로그라고 보는 게 합당해 보였습니다. 하지만 모니터링 그래프를 보며 이를 원인 그래프가 아닌 결과 그래프라고 재확인하는 과정 또한 지루하지만 꼭 거쳐야 할 확인 작업이었습니다.
4. 타깃 국가 통신사의 네트워크 이슈 확인
서비스가 운영되는 타깃 국가는 일본입니다. 혹시 일본 내 통신사에서 네트워크 이슈가 있었는지 웹 검색을 해봤습니다. 이때는 '참 별걸 다 찾아보고 있구나'하는 마음도 들었습니다. 동료가 찾아준 기사가 있기는 했지만 오래된 기사였습니다. 또한 선진국의 네트워크에서 이렇게 빈번하게 이슈가 발생한다는 것은 믿기 어려웠습니다. 만약 진짜로 그런 일이 일어났다면 여기저기서 기사화되고 서비스 담당자들의 아우성이 들려왔을 겁니다. 그러나 그런 일은 없었습니다.
5. Nginx 설정 확인
리버스 프록시로 Ingress Nginx를 사용하고 있습니다. Nginx는 충분히 웹소켓 연결을 끊을 수 있는 위치에 있었기 때문에 가장 의심했던 부분이었습니다. Nginx 설정 중 proxy-read-timeout과 proxy-send-timeout의 기본값은 60s이고, 당시 이를 300s로 설정해서 사용하고 있었습니다. 개발 환경에서 이 값을 극단적으로 줄인 후(3s) 테스트를 실행해 보니 웹소켓 드롭 현상이 재현됐습니다.

쿠버네티스의 Ingress Nginx 문서를 보니 웹소켓을 사용할 때 proxy-read-timeout과 proxy-send-timeout을 3600s(1시간) 이상으로 설정하라고 가이드하고 있어서 수정 후 배포를 진행했습니다. 또한 LB timeout은 Nginx timeout 이상으로 설정하는 것이 안전하기 때문에 이 값도 3600s으로 변경했습니다. 지금까지 도출한 가설 중 가장 가능성이 큰 유력한 가설이었지만 기대가 무색하게도 웹소켓 드롭은 또다시 발생했습니다.
우리는 답을 찾았다. 늘 그랬듯이.
원인을 알아야 대안을 찾을 텐데 발생 원인조차 파악하지 못하는 이 상황이 그야말로 깜깜한 백사장을 손으로 더듬거리며 작은 열쇠를 찾을 때의 막막함을 느끼게 했습니다. 그러나 언제나 한 줄기 빛은 나타나기 마련입니다. 이번에는 동료 개발자분을 통해 답을 찾을 수 있었습니다. 저와 다른 팀에서 다른 서비스를 만들고 있는, SRE 경험이 풍부하신 박민근 님이 주인공입니다. 내공이 강한 분이라는 것을 익히 알고 있었기 때문에 도움을 요청드렸고 바쁘신 와중에도 흔쾌히 함께 해 주셨습니다.
그렇게 찾은 웹소켓 드롭의 주범은 L7 LB였습니다. 인프라와 네트워크 팀에서 문제없다던 답변을 곧이곧대로 믿었던 저는, 제가 제어할 수 있다고 한정한 영역에서만 원인을 찾으려고 했는데 민근 님은 L7에서 사용되는 HAProxy를 로컬에 세팅한 뒤 테스트까지 진행하셨고 원인이 될 수 있는 유력한 지점이 LB라는 답을 내리셨습니다. 그제야 저도 갇혀있던 시야가 확 트이는 느낌이 들었습니다.
Nginx 설정을 잘못했거나 혹은 Nginx가 재시작될 때 웹소켓 드롭이 발생할 수 있듯이 LB가 재시작되는 경우에도 같은 현상이 발생할 수 있습니다. HAProxy를 로컬 Docker에 올려놓고 아래와 같이 테스트해 봤습니다.
$ docker-compose kill -s HUP haproxy그러자 '일정 시간'이 지난 후에 연결이 끊겼습니다. 여기서 '일정 시간'은 HAProxy의 hard-stop-after 설정을 따릅니다. 그러니까 HAProxy가 다시 로드(reload)되거나 재시작되면 hard-stop-after 시간이 지난 뒤에 이전 프로세스가 종료되면서 당시 연결돼 있던 웹소켓 연결도 끊기는 것입니다.
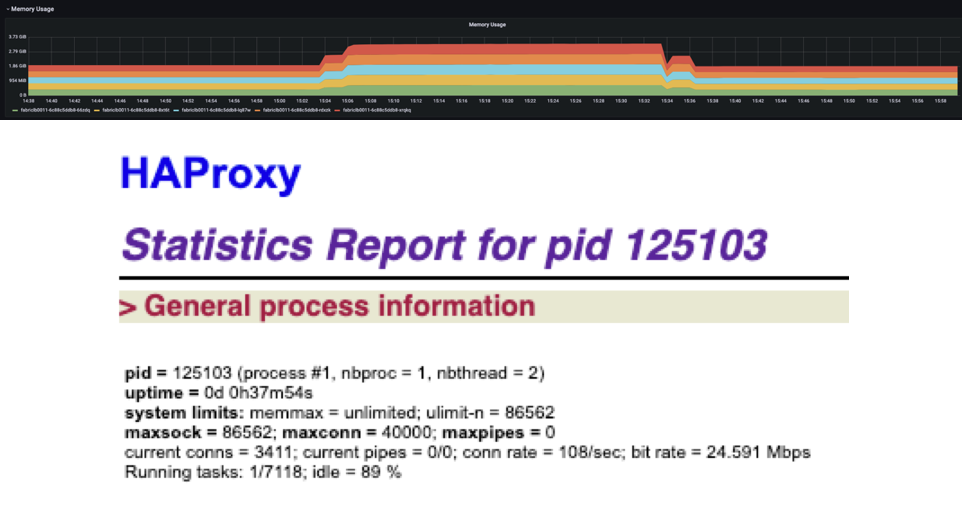
주범이 될 수 있는 또 하나의 유력한 가설이 나왔기 때문에 실제 운영 환경에서도 같은 일이 벌어지는지 확인이 필요했습니다. 아래는 가설이 맞다는 것을 증명하는 그래프와 정보입니다. 의심 구간을 알고 나서 찾아보니 그래프와 정보가 눈에 확 들어옵니다. 인프라 팀에 HAProxy의 hard-stop-after 설정을 문의하니 30분이라고 답변했습니다. 저희가 사용하는 사내 IaaS인 Verda 대시보드에서 저희 쪽 LB를 배포하자 아래 캡처에 보이는 HAProxy uptime도 정확히 30분 후에 갱신됐고, 동시에 웹소켓 드롭도 재현됐습니다. 아는 만큼 보인다는 말에서 더 나아가 아는 만큼 찾아볼 수 있다는 것을 직접 체험할 수 있었습니다.
여기까지 오니 한 가지 의문이 생겼습니다. '우리가 Verda 대시보드에서 설정하고 사용하는 LB는 거의 수정과 배포를 하지 않는데 HAProxy는 왜 재시작되는 걸까?'. 이유는 꽤 단순했습니다. LB를 다른 서비스와 공유해서 사용하고 있기 때문이었습니다. 우리 서비스가 아니라 함께 LB를 공유하고 있는 다른 서비스의 담당자가 자신의 LB 설정을 배포하는 것만으로 HAProxy가 재시작되고 다른 서비스에 영향을 줄 수 있는 것입니다. 이는 웹소켓 드롭이 비정기적으로 발생한 이유이고, 꽤나 아쉬운 부분이기도 합니다. 예전에 다른 서비스에서도 웹소켓 서버를 만들 때 앞단에 HAProxy를 사용한 적이 있습니다. 그때 이런 문제가 발생하지 않았던 이유는 독립된 환경이었기 때문이었습니다. 애초에 Verda 대시보드가 프로젝트별로 나뉜 상태에서 LB를 설정한 것이기에 이를 공유해서 사용하고 있을 것이란 생각 자체를 하지 못한 것이 원인 파악이 어려워진 이유 중 하나였습니다.
민근 님과 같이 이 문제를 파헤치면서 배운 점은 문제의 범위를 속단해서 스스로 제한을 걸면 안 된다는 것입니다. 또한 원인을 추적하는 과정에서 여러 시행착오를 겪더라도 의심의 실마리를 쉽게 놓지 않고 끝까지 파헤쳐 나갈 수 있는 의지와, 평소에 경험으로 다져 놓은 저력이 중요하다고 느꼈습니다. 잘 배웠습니다.
L7 LB에 내포된 운영 관점의 한계를 극복할 수는 없었기에 이 문제는 L4 LB로 전환하는 것으로 해결했습니다. 이후 웹소켓 드롭 이슈는 해소됐습니다.
네 번째 사례: Schema Registry에서 스키마 등록 실패
잘 작동하던 Schema Registry에서 갑자기 에러가 발생했습니다(다행히도 개발 환경이었습니다). KAFKASTORE 설정에 등록한 토픽으로 스키마를 등록하는 데 실패하는 이슈였습니다.
아래 'Finished rebalance with leader election result' 로그를 보면 'host'가 '172.A.B.C'입니다.
> INFO Finished rebalance with leader election result: Assignment{version=1, error=0, leader='sr-1-4478b149-xxx-xxx-xxx-xxxx', leaderIdentity=version=1,host=172.A.B.C,port=80xx,scheme=http,leaderEligibility=true} (io.confluent.kafka.schemaregistry.leaderelector.kafka.KafkaGroupLeaderElector)이어서 스키마가 등록(Registering new schema)될 때 아래와 같은 에러와 함께 타임아웃이 발생합니다. Schema Registry의 HTTP endpoints로 스키마 정보를 조작하려고 할 때는 'Leader not known'과 같은 에러도 마주했습니다.
> io.confluent.kafka.schemaregistry.exceptions.SchemaRegistryRequestForwardingException: Unexpected error while forwarding the registering schema request {...생략...} to [http://172.A.B.C:80xx]위 로그에 나온 호스트 정보인 '172.A.B.C'는 제가 모르는 IP 주소였습니다. Kafka 클러스터를 공유하고 있는 다른 누군가의 컨테이너 IP 주소였던 것입니다. 이 호스트 값에 자신의 Schema Registry가 올라간 컨테이너 IP 주소를 찾아야 했습니다.
Schema Registry의 group.id는 기본값이 'schema-registry'입니다. 카프카 클러스터에 여러 Schema Registry를 붙여 사용하는 경우 group.id를 고유한 값으로 적용해서 분리시켜야 합니다. 이는 Schema Registry의 컨테이너 환경 설정에 SCHEMA_REGISTRY_SCHEMA_REGISTRY_GROUP_ID를 추가하는 것으로 해결할 수 있습니다.
이 경우도 앞서 웹소켓 드롭 현상 때와 마찬가지로 기술 리소스를 다른 서비스와 공유해 사용하면서 발생한 이슈입니다. 따라서 어떻게 생각하면 흔히 만나기 어려운 특이 케이스(edge case)라고도 볼 수 있으며, 공용 기술 리소스를 제공하는 인프라를 운영하는 관점에서 효율을 올리고 싶을 때 발생하는 트레이드 오프라는 생각이 들기도 합니다.
장애 보고서는 반성문이 아닙니다
문제가 발생하면 문제를 일으킨 당사자는 죄송한 마음이 들며 민폐를 끼쳤다고 자책하게 됩니다. 주변에서 아무도 탓하지 않는다고 하더라도 당사자가 이런 마음이 드는 건 자연스러운 현상이라고 생각합니다. 또한 개인적으로 이런 자책은 성장의 근간을 이루는 감정 중 하나라고 생각합니다. 또다시 같은 이슈로 문제가 재발하지 않도록 자책의 크기만큼 되새김하면서 이를 내 것으로 만들어야겠다는 의지를 만들어 내는 감정이기 때문입니다.
이때 경계해야 할 것은 이 감정을 '나라는 존재의 부끄러움'까지 확대해서는 안 된다는 것입니다. 그렇게 되면 단기적으로 문제를 일으키지 않기 위해서 소극적인 태도를 취하거나 극단적으로는 방어 기제를 발동시켜 책임을 전가하려는 태도를 갖게 되는 경우도 있기 때문입니다. 이해는 되지만 최악의 전개라고 생각합니다. 하루이틀 개발하다가 떠날 게 아닌 이상 예상치 못한 이슈를 맞이했다는 것에 속은 조금 쓰리더라도 장기적으로는 '오히려 좋다'는 마음가짐이 필요합니다. 자신의 시야가 좁다는 것을 깨달을 기회이고, 부족한 역량을 채울 기회이기도 하며, 근본적으로는 책임지고 있는 프로젝트를 이전보다 견고히 만들 수 있는 기회입니다. 물론 과정은 당연히 녹록지 않겠지만 말입니다.
얼마 전에 일본으로 출장 갔을 때의 일입니다. 그동안 한국 시장을 타깃으로 하는 IT 회사들에만 있었기에 이런 장애 상황에 대해 일본 현지 분들은 어떤 생각과 철학을 갖고 계신지 궁금했습니다. 그래서 혹시 장애 보고서가 반성문처럼 느껴지지는 않으신지 물어보았습니다. 다행히 그렇지 않다고 답하셨습니다. 아무도 개인을 비난하지 않으며 중요한 것은 후속 조치라고 하셨습니다. 이런 과정을 통해 생산적이고 실용적인 측면에서 함께 서비스를 만들어 가는 것이라는 공감대에 아주 쉽게 이를 수 있었습니다. 언어나 문화의 차이를 넘어 엔지니어링의 기본 마인드는 똑같다는 것을 직접 체험할 수 있어서 기분 좋았고, 위로받았습니다.
개발자가 느끼기에 좋은 문화 중 하나는, 이슈가 발생했을 때 개인을 탓하는 것이 아니라 재발 방지를 위해 어떤 프로세스와 대책을 세울 것인지에 집중하고 협력하는 문화입니다. 더 나아가 '네 일, 내 일'을 떠나 엔지니어링 측면에서 호기심을 갖고 문제를 탐구하며 해결하기 위해 힘을 보태는 것입니다. 저는 일련의 트러블 슈팅 과정을 진행하면서 기본 소양을 탄탄히 갖추고 이런 문화를 가꾸어 나가고 있는 훌륭한 동료분들께 매우 큰 도움과 가르침을 받을 수 있었습니다. 익숙하다고 생각했던 것에서도 불현듯 새로운 것을 배울 수 있는 개발이라는 직업이 참 즐겁게 느껴집니다.
함께 만들어 보실래요?
ABC Studio는 일본 음식 배달 플랫폼 시장 No.1을 확고히 다지기 위해 많은 분들과 함께 항해해 나가고 있습니다. messaging-hub는 그 한 축을 이루어 앞으로 더욱 도전적이고 신나는 여정을 준비하고 있으며, 대한민국에서 함께 하실 분을 찾고 있습니다.
messaging-hub에 관심이 생겼다면 먼저 발행된 아래 블로그도 참고해 보시기 바랍니다.