
안녕하세요. 저는 LINE에서 LINE 개발자를 위한 서비스, Pipeline을 개발하고 있습니다. Pipeline은 테스트부터 서비스 배포까지 가능한, Kubernetes 기반 워크플로(workflow) 서비스입니다. 사용자가 코드를 검증하기 위한 테스트나 코드를 배포하기 위한 빌드 또는 주기적으로 작업을 실행하기 위한 크론(cron) 작업과 같이 실행하고 싶은 작업을 워크플로 형태로 Pipeline에 정의하면, Pipeline이 사용자가 정의한 대로 작업을 실행합니다. 작업의 결과는 다양한 형태로 나타나는데요. 파일이 산출되기도 하고 서비스가 실행되기도 합니다.
이번 글에서는 외부에서 발생한 트래픽을 Kubernetes 클러스터에서 실행되는 서비스로 전달하기 위해 필요한 Pipeline 컴포넌트를 직접 개발한 경험을 나누고자 합니다.
컴포넌트 개발 배경
Kubernetes 클러스터 내부로 트래픽을 전달하는 대표적인 방법으로는, 파드(pod)의 경우 hostNetwork 설정, 서비스의 경우 NodePort 혹은 LoadBalancer 유형을 사용하는 방법이 있습니다. 하지만 서비스의 특성상 사용자의 워크 로드(work load)를 파악할 수 없어서 사용할 수 있는 방법이 제한되었습니다. 먼저 hostNetwork와 NodePort는 80(HTTP), 443(HTTP) 등과 같이 널리 알려진 포트를 중복으로 사용할 수 없고, 서비스가 생성되거나 삭제될 때마다 직접 로드 밸런서(load balancer)를 생성하거나 삭제해 줘야 했는데요. 노드가 스케일 인 혹은 아웃될 때마다 실제 로드 밸런서에 해당 정보를 업데이트하는 것은 노역(toil)에 가깝기 때문에 적당하지 않았습니다.
이러한 문제를 LoadBalancer 유형의 서비스로 해결할 수 있어 사용하려고 했습니다만, 아직 내부 개발자를 위해 제공되는 관리형(managed) Kubernetes 클러스터에서는 지원되지 않았습니다(참고). 또한 Kubernetes 클러스터를 직접 별도로 구축해서 사용하고 있는 다른 팀에서도 그러한 컴포넌트를 필요로 하고 있다는 걸 확인할 수 있었고, 이에 Cloud Provider를 개발하기로 결정했습니다.
프로젝트 스캐폴딩(scaffolding)
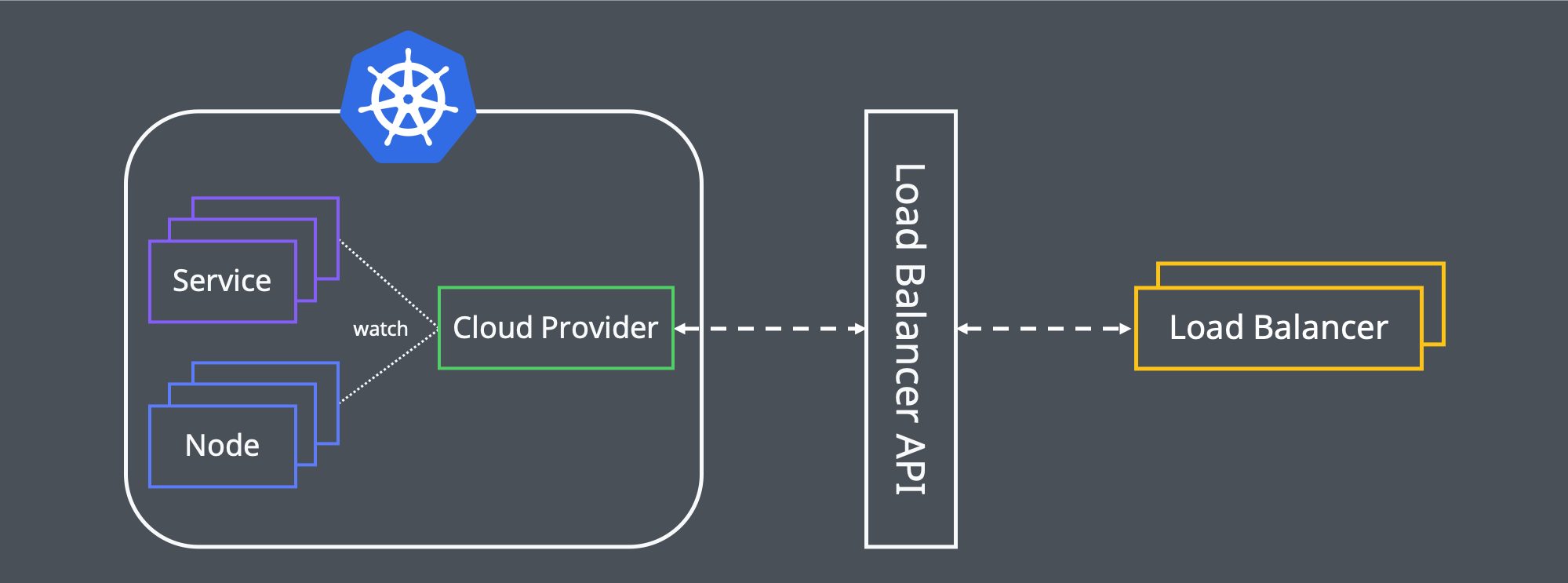
우선 위 구조와 같이 클러스터의 Cloud Provider가 서비스와 노드를 감시하다 생성이나 삭제, 변경과 같은 이벤트가 발생하면, 서비스와 노드를 로드 밸런서 API의 스펙으로 변환한 후 호출하여 실제 로드 밸런서를 생성하거나 삭제 혹은 변경하는 형태로 PoC(Proof of Concept)를 진행하기로 했습니다. 예를 들어 아래와 같은 서비스가 새로 생긴다면, 80 포트로 유입되는 트래픽을 현재 클러스터에서 활성화되어 있는 노드들의 31313 포트로 포워딩하는 로드 밸런서가 생성되는 겁니다.
apiVersion: v1
kind: Service
metadata:
name: store-api
spec:
selector:
app: store-api
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 31313
clusterIP: 10.0.10.100
type: LoadBalancer그런데 위와 같이 Cloud Provider에서 모든 로직을 처리하는 팻(fat) 클라이언트 구조로 개발하려다 보니 문제가 있었습니다. 둘 이상의 클러스터에서 사용할 때 클라이언트(Cloud Provider)를 업데이트하거나 로드 밸런서 API에 장애나 변경이 발생했을 때 대응하는 게 까다로울 것 같았습니다. 그래서 아래와 같이 Cloud Provider API 단계를 중간에 추가하여, 여기서 로드 밸런서 API 관련 로직을 처리하는 씬(thin) 클라이언트 구조를 고민하게 되었습니다.
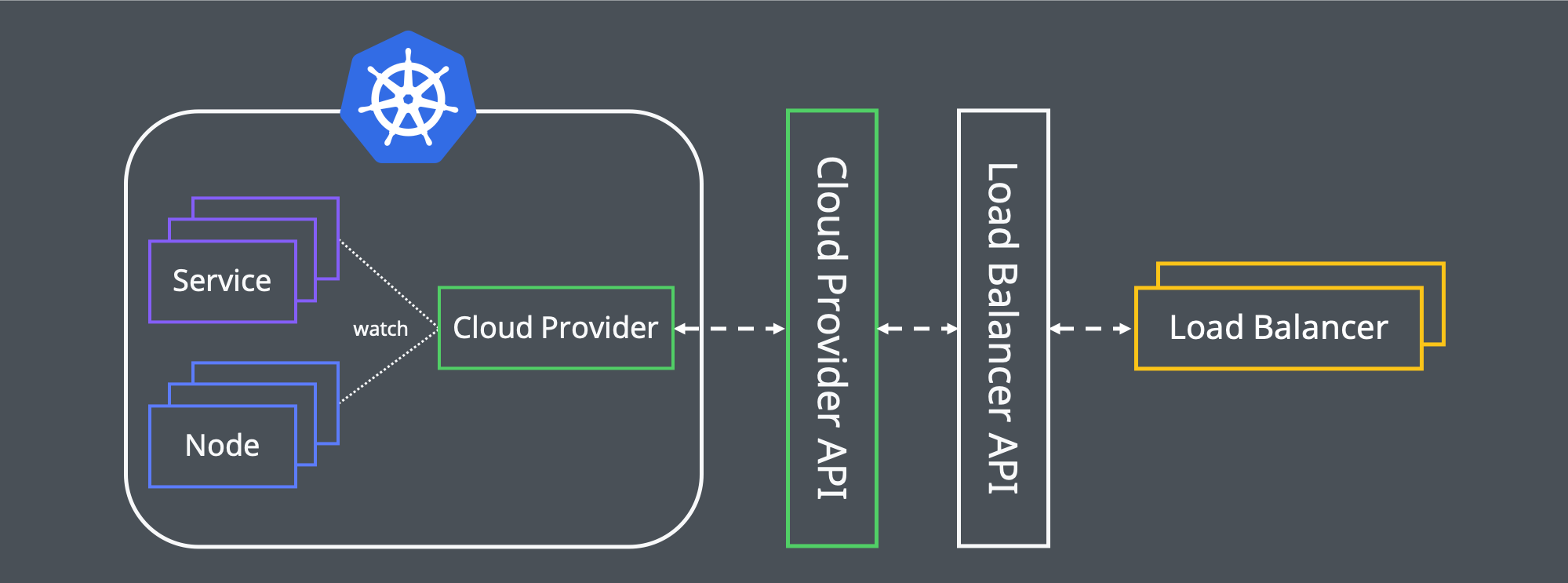
씬 클라이언트 구조로 개발하면 팻 클라이언트와 비교할 때 구조가 복잡해지고 개발해야 할 컴포넌트가 늘어난다는 단점이 있습니다. 하지만 팻 클라이언트의 가장 큰 문제점인 클라이언트 업데이트를 중간 단계 수정으로 어느 정도 해결할 수 있고, 서드파티 API가 추가로 필요하거나 요청 스로틀링(throttling) 같은 복잡한 비즈니스 로직을 처리해야 할 때 유연하게 대응할 수 있다는 장점이 있어 씬 클라이언트 구조로 개발하기로 결정했습니다.
기본 골격을 결정한 다음엔 Cloud Provider API를 어떻게 개발할지 고민했는데요. 처음에는 기존처럼 MySQL이나 MongoDB와 같은 DBMS를 데이터 소스로 사용하는 형태로 개발할까 고민하다가, 이미 사용하고 있던 Kubernetes를 Full featured 프레임워크로 사용해보기로 했습니다. Kubernetes는 CRD를 이용해 원하는 리소스를 정의할 수 있고, 이벤트를 통해 리소스 변경을 감지할 수 있으며, 리소스 버저닝(versioning)으로 연속된(transactional) 작업에서 경쟁 상태가 발생하는 걸 회피할 수 있다는 장점이 있었습니다. 그리고 무엇보다도 이와 같은 로직을 Kubernetes에 온전히 위임함으로써 개발자는 오직 비즈니스 로직 작성에만 집중할 수 있어 더더욱 사용하지 않을 이유가 없었습니다.

CRD와 컨트롤러는 Kubebuilder를 활용해 개발했습니다. Kubebuilder에서 생성해 주는 보일러 플레이트(boiler plate) 코드 덕분에 client-go를 사용했을 때보다 더 빠르게 개발할 수 있었습니다. 그뿐만 아니라 로드 밸런서 API에서 액션이 비동기로 처리되고 설정값들이 리비전(revision) 형태로 관리되기 때문에 동기화(reconcile) 로직을 좀 더 편하게 구현할 수 있었습니다.
다만 동기화 로직을 작성할 때 실수한 부분이 있었습니다. 아래 Kubebuilder 가이드에 나와 있듯, 상태(status)는 동일 스펙으로 동기화 로직을 실행하면 언제든지 재현될 수 있어야 합니다.
Remember, status should be able to be reconstituted from the state of the world, so it’s generally not a good idea to read from the status of the root object. Instead, you should reconstruct it every run. That’s what we’ll do here. - The Kubebuilder Book
그런데 어느 순간부터 상태 값으로 동기화 로직 분기를 처리하는 코드를 작성하게 되었고, 이 때문에 스펙과 상태가 업데이트되면서 간헐적으로 무한 루프에 빠지는 경우가 발생했습니다. 이 문제는 디버그하는 데에도 어려움을 겪었는데요. CQRS 패턴과 같이 스펙은 쓰기(write), 상태는 읽기(read)라는 개념을 대입, 서로의 의존성을 제거하는 방향으로 리팩토링해서 해결할 수 있었습니다. 왼쪽은 리팩토링이 완료된 후의 순서도입니다.
개발 중 발생한 두 가지 고민과 해결 방법
리전(region) 변경 처리
현재 LINE의 인프라는 여러 리전에서 운영되고 있습니다. 이에 맞춰 사용자가 어노테이션을 이용해 지정한 리전에 로드 밸런서를 생성할 수 있는 기능도 구현했습니다. 그런데 만약 리전 어노테이션을 A 리전에서 B 리전으로 변경하는 경우 어떻게 처리하는 게 맞을까요? 동기화라는 동작 관점에서 본다면, 아래 순서대로 처리해야 합니다.
- A 리전 로드 밸런서 중지
- A 리전 로드 밸런서 삭제
- B 리전 로드 밸런서 생성
- B 리전 로드 밸런서 배포
이때 A 리전의 로드 밸런서를 중지한 후부터 B 리전에 로드 밸런서가 배포되기 전까지 그 사이에 다운 타임이 발생할 가능성이 있습니다. 또한 순서를 바꿔 B 리전에 로드 밸런서를 배포한 뒤 A 리전의 로드 밸런서를 삭제한다고 해도, 로드 밸런서를 관리하는 관점에서는 DNS와 같은 외부 자원의 존재를 알 수 없기 때문에 사용자가 의도하지 않은 다운 타임이 발생할 가능성이 있습니다. 그래서 저희는 리전을 변경하더라도 기존 로드 밸런서는 삭제하지 않기로 결정했습니다. 이렇게 삭제하지 않는 경우엔 고아(orphaned) 로드 밸런서가 발생하는데요. 그보다 서비스 안정성이 더 중요했기 때문에 고아 로드 밸런서를 주기적으로 확인해 사용자에게 확인 요청을 보내는 방식으로 해결했습니다.
Cordon 상태 판별
Kubernetes에서 Cordon 명령어를 사용하면 특정 노드를 'unscheduled' 상태로 표시합니다. 보통 해당 노드를 관리할 필요가 있을 때 사용하는데요. 기존 파드들은 살아있고, 스케줄링만 비활성화된 노드에 트래픽을 전달하는 게 맞을까요?
노드 관리 관점에서 본다면 트래픽을 전달하지 않는 게 맞지만, 서비스 관점에서 본다면 파드가 살아있으니 트래픽을 전달하는 게 맞습니다. Ingress 컨트롤러로 유명한 ingress-nginx에선 Cordon 처리된 노드에는 트래픽을 전달하지 않아서 사람들이 이슈를 제보하고 있는 것도 확인할 수 있습니다(참고).
처음에는 서비스 제공자 관점에서 트래픽을 전달하지 않는 게 맞다고 생각했습니다. 하지만 문득 이전 회사에서 겪었던 일이 떠올랐는데요. Kubernetes 클러스터의 버전을 업그레이드하기 위해 모든 노드를 Cordon 처리한 뒤 점진적으로 파드를 새로운 노드로 이동시키려 했을 때, 위 이슈 때문에 트래픽이 클러스터로 들어가지 않으면서 서비스 장애를 겪은 적이 있었습니다. 또한 동료들도 서비스 중심으로 생각하라고 피드백을 주어서, 결과적으로 Cordon 처리한 노드에도 트래픽을 보내는 방향으로 결정했습니다.
서비스를 만들 땐 항상 사용자 중심으로 생각해야 한다고 다짐했지만, 어느 순간부터 서비스를 제공하는 입장에서 생각하고 있었다는 사실을 깨달았고, 반성하게 되었습니다.
맺으며
현재 구조로는 해결할 수 없는 문제들도 있습니다. 예를 들어 여러 개의 클러스터를 하나의 컨트롤러가 관리하는 형태이다 보니 한 클러스터에서 많은 이벤트가 발생할 때 다른 클러스터의 업데이트가 느려질 수 있다는 문제가 있습니다. 또한 트래픽이 로드 밸런서에서 클러스터 내부로 전달된다고 해도 해당 노드에 대상 파드가 없을 땐 홉(hop) 수가 증가하게 되는데요. 다음 버전에서는 아래와 같이 로드 밸런싱 전용 노드를 클러스터에 넣고, 해당 노드가 트래픽을 받게 하는 방안을 생각하고 있습니다.

끝으로 저희와 함께 하실 Developer Productivity Engineer를 찾고 있습니다. 개발자들이 창출한 가치를 전 세계의 사용자들에게 좀 더 빠르고 안정적으로 전달할 수 있게 도와주는 서비스에 관심이 있다면, 언제든지 아래 링크로 지원해 주세요. 부족한 글 읽어주셔서 감사합니다 :D
이 자리를 빌려 이 글과 코드를 리뷰하고 리팩토링해주신 이승 님께 감사의 말을 전합니다.