
들어가며
안녕하세요. 제가 LINE에서 테크니컬 라이터로 일한 지 어느덧 8개월이 지났습니다. 지난 8개월 동안 글을 다듬으면서 무언가 의문이 생기는 표현을 만났을 때 이용하는 사이트가 몇 군데 있었는데요. 그중 가장 신뢰하고 많이 이용했던 사이트는 국립국어원입니다. 문장을 보면서 무언가 어색하거나 이상하다고 느껴지면 브라우저에서 국립국어원 사이트를 열고 단어나 문구를 검색해 보았습니다. 검색 결과에 같은 표현이 나오면 안심하고 지나갔고요. 같은 표현이 나오지 않으면 다른 표현으로 수정했습니다(다만 기억력이 좋지 않아서 동일한 표현을 여러 번 검색하게 되더군요). 또한 하루가 다르게 발전하는 IT분야답게 처음 보는 단어나 용어를 종종 접하게 되는데요. 그럴 때 요새 다른 사람들은 이런 단어나 용어를 어떻게 사용하고 있나 궁금해서 네이버 뉴스에 들어가 검색해 보았습니다.
그런데 최근에 브라우저를 열고 문구를 검색하는 이 과정이 유독 번거롭게 느껴졌습니다. 특히 뉴스를 검색할 때는 상세검색을 이용해서 네이버에서 일간지로 분류해놓은 출처의 기사만 확인했는데요. 세션이 끊어지면 설정해놓은 상세검색 옵션이 초기화되어서 다시 설정해주어야 했습니다. 검색 결과도 너무 복잡했습니다. 화면에 잔뜩 나타난 사진이나 이미지는 저에게 불필요한 정보였습니다. 보통 국립국어원 검색 결과에선 '용례'라는 영역의 정보만 필요했고 네이버 뉴스 검색 결과에선 검색 문구가 포함된 문장과 그 앞뒤 문장 정도만 보고 싶었습니다.
그래서 이번 글에서는 LINE에서 제공하는 샘플봇과 여러 메시지 유형들, 그리고 각 사이트에서 제공하는 오픈 API를 이용하여 간단한 검색 친구를 만들어보려고 합니다.
준비 사항
작업하기 전 수정할 샘플봇을 준비하고 각 사이트에서 오픈 API 이용신청을 해야 합니다.
샘플봇
LINE에선 샘플봇을 여러 가지 언어로 준비해 놓았습니다. 제 이전 글에선 샘플봇 Java 버전을 이용했는데요. 이번 글에선 Python 버전을 이용했습니다. 샘플봇 빌드 가이드, 샘플봇이 업로드되어 있는 GitHub을 참고하면 어렵지 않게 샘플봇을 준비할 수 있습니다.
저는 샘플봇에서 아래 보이는 flask-kitchen-sample 폴더만 따로 떼내어 사용했습니다.
heroku에 업로드하기 전 Procfile을 추가했고, 검색 기능을 넣을 search_for_words.py 파일을 추가했습니다.
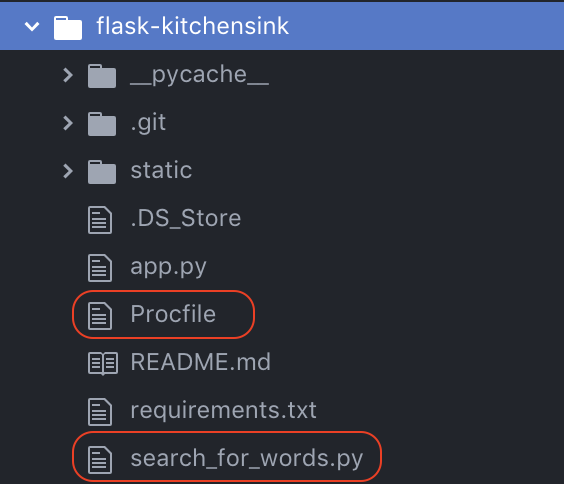
추가한 Procfile의 내용은 다음과 같습니다.
web: gunicorn app:app오픈 API 사용 신청
네이버와 국립국어원에서 제공하는 오픈 API를 이용하려면 먼저 이용신청을 해야 합니다. 이용신청은 아래 사이트에서 각각 가능하며 둘 다 회원가입 후 로그인이 필요합니다.
네이버 오픈 API 신청 후 받는 Client ID와 Client Secret, 국립국어원 오픈 API 신청 후 받는 인증 키는 API를 호출할 때 헤더에 추가해야 합니다. 서비스 요청은 둘 다 하루에 25,000건으로 제한되어 있습니다.
샘플봇 수정
제가 원하는 건 채팅창에서 샘플봇에게 간단한 키워드와 함께 검색어를 전달하면 샘플봇이 오픈 API를 통해 검색, 결과를 전달받아 적절히 처리한 뒤 채팅창으로 보내주는 것입니다. 이 과정을 간단하게 그림으로 그려보면 아래와 같습니다.
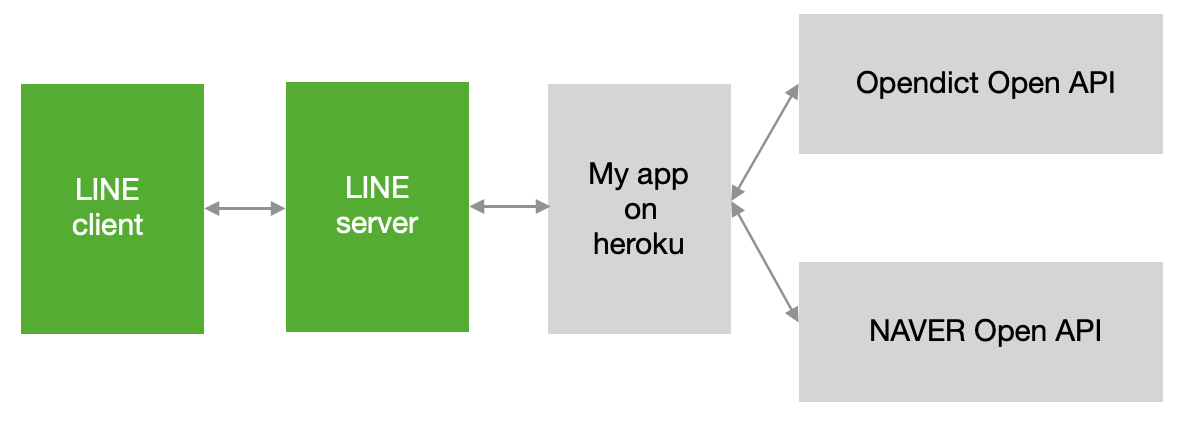
채팅창에 '뉴스' 혹은 'news'를 입력하고 한 칸 띄우고 검색어를 입력한 뒤 메시지를 전송하면 네이버 뉴스를 검색한 결과를 보내주고, 같은 방식으로 '우리말샘' 혹은 'opendict'를 키워드로 입력하면 국립국어원 우리말샘의 '용례' 검색 결과를 보내주도록 만들어 보겠습니다.
네이버 오픈 API 호출 적용
네이버에선 이곳에서 오픈 API 적용 가이드를 제공하고 있습니다. 여러 언어별로 상세하게 잘 나와 있기 때문에 참고하여 API를 호출하는 데 큰 문제는 없습니다. URL 구성을 news(JSON 형식)로 하느냐 news.xml(XML 형식)로 하느냐에 따라 전달받는 결과 형식이 달라집니다. 저는 좀 더 익숙한 JSON 형식으로 선택했습니다.
url = "https://openapi.naver.com/v1/search/news?query=" + encText # JSON 결과
url = "https://openapi.naver.com/v1/search/news.xml?query=" + encText # XML 결과네이버에서 제공하는 가이드를 쭉 살펴봤지만, 브라우저에서 가능했던 상세검색 옵션을 API 호출 시에 적용하는 방법을 찾지 못했습니다. 이리저리 생각을 해봤지만 다른 좋은 방법이 떠오르지 않아서 결국 약간의 하드코딩으로 네이버에서 일간지로 분류한 언론사들의 기사만 결과로 나오도록 처리했습니다.
아래는 코드 중 네이버 오픈 API 호출과 관련된 부분입니다.
naver_openapi_client_id = "부여받은 client_id"
naver_openapi_client_secret = "부여받은 client_secret"
#언론사 필터링을 위해 각 언론사 사이트 주소의 일부를 따온 문자열
my_newcompanyURL = [
'khan.co.kr', #경향신문
'kmib.co.kr', #국민일보
'naeil.com', #내일신문
'donga.com', #동아일보
'm-i.kr', #매일일보
'munhwa.com', #문화일보
'www.seoul.co.kr', #서울신문
'segye.com', #세계일보
'asiatoday.co.kr', #아시아투데이
'chosun.com', #조선일보
'joins.com', #중앙일보
'hani.co.kr', #한겨레
'hankookilbo.com' #한국일보
]
def search_for_words_in_the_news(search_str):
search_str = search_str.split(' ', 1)
if len(search_str) < 2 or len(search_str[1].strip()) < 1:
return TextSendMessage(text='Please enter words to search for')
#query는 검색을 원하는 문자열입니다. quote_plus 함수를 이용해 검색어를 UTF-8로 인코딩합니다. quote_plus 함수는 quote 함수와 달리 공백을 '+' 기호로 처리해줍니다.
defaultURL = 'https://openapi.naver.com/v1/search/news.json?&query=' + urllib.parse.quote_plus(search_str[1])
#검색 결과 출력 건수 지정. 10(기본값), 100(최대)
display = '&display=100'
#정렬 옵션: sim (유사도순), date (날짜순)
sort = '&sort=sim'
fullURL = defaultURL + display + sort
#header에 네이버 개발자 센터에서 받은 id와 secret을 넣어줍니다.
headers = {
'X-Naver-Client-Id' : naver_openapi_client_id,
'X-Naver-Client-Secret' : naver_openapi_client_secret
}
req = urllib.request.Request(fullURL, headers=headers)
response = urllib.request.urlopen(req)
rescode = response.getcode()
if rescode == 200:
result_json = json.loads(response.read().decode('utf-8'))
return extract_from_news_result(result_json, search_str[1])
else:
return TextSendMessage(text='response code:' + rescode)
def filter_news_search_result_by_newscompanyURL(originallink):
for url in my_newcompanyURL:
if originallink.find(url) != -1:
return True
return False
def extract_from_news_result(result_json, search_str):
title_str_arr = ['link', 'title', 'description', 'pubDate']
result_text = '-------------------------------
'
result_count = 0
for item in result_json["items"]:
if filter_news_search_result_by_newscompanyURL(item["originallink"]):
for title_str in title_str_arr:
result_text = result_text + title_str + '
'
replaced_str = str(item[title_str]).replace('<b>','').replace('</b>','')
result_text = result_text + replaced_str + '
'
result_count += 1
if result_count >= 5:
break
if result_count == 0:
return TextSendMessage(text='no results found for ' + search_str + 'in the news')
else:
return TextSendMessage(text=result_text)
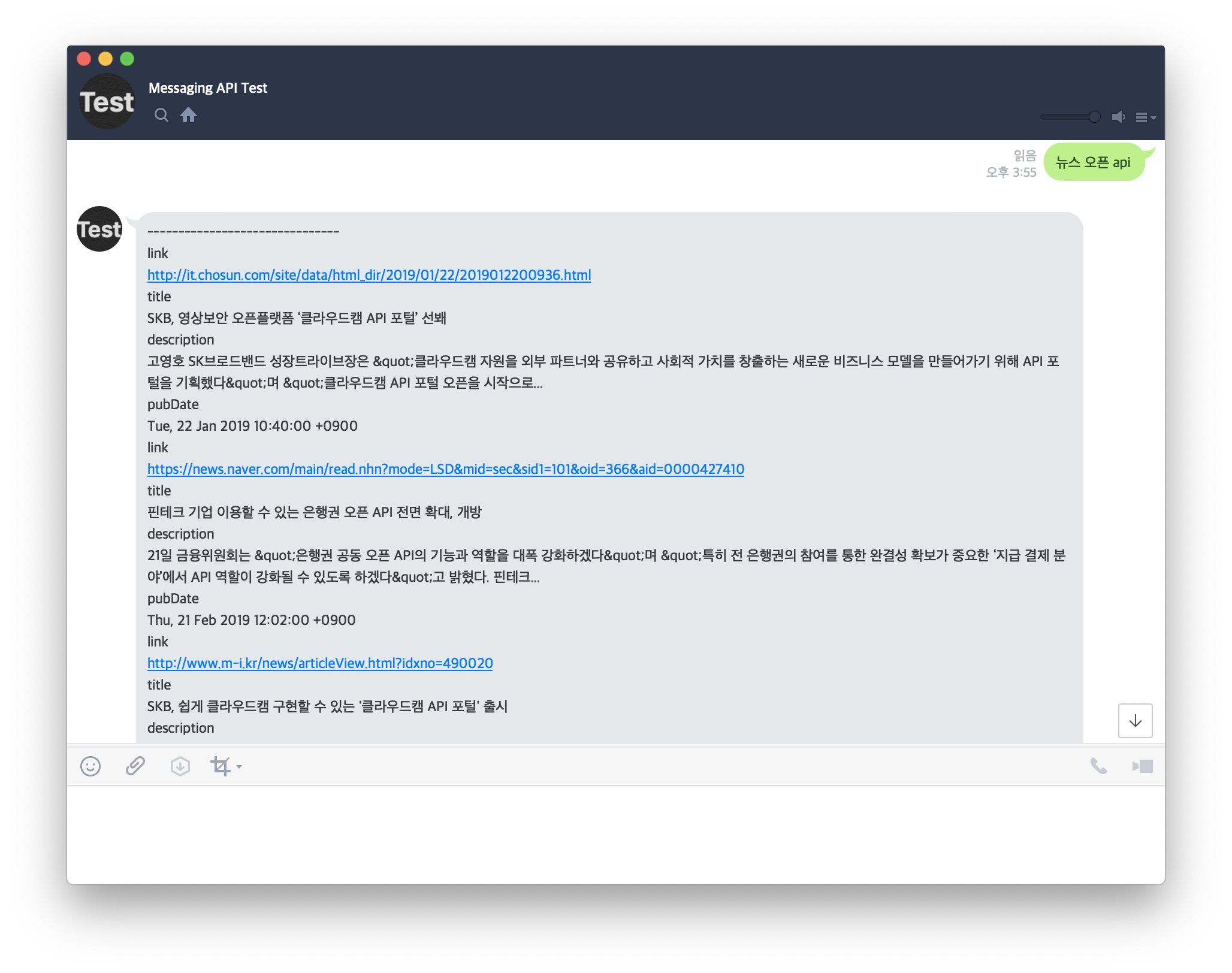
return아래는 채팅창에 '뉴스 오픈 api'를 입력해서 네이버 뉴스에서 '오픈 api'를 검색한 결과 화면입니다.
국립국어원 오픈 API 호출 적용
국립국어원에선 이곳에서 오픈 API 적용 가이드를 제공하고 있습니다. 역시 적용할 때 필요한 정보는 모두 나와 있으니 참고하여 API를 호출하는 데 큰 문제 없습니다. 결과는 네이버와 달리 XML 형식으로만 제공됩니다. 저는 XML 형식을 다루는 게 조금 부담스러워서 JSON 형식으로 변환하여 다뤘습니다.
아래는 제 코드 중 국립국어원 오픈 API 호출 관련된 부분입니다.
opendict_cert_key = '부여받은 인증키'
def search_for_words_in_opendict(search_str):
search_str = search_str.split(' ', 1)
if len(search_str) < 2 or len(search_str[1].strip()) < 1:
return TextSendMessage(text='Please enter words to search for')
#마지막이 search면 사전 검색 오픈 API, view면 사전 내용 오픈 API입니다.
defaultURL = 'https://opendict.korean.go.kr/api/search?'
#key에 우리말샘 오픈 API 이용신청 후 받은 인증키를 넣어줍니다.
key = 'key=' + opendict_cert_key
#part가 word면 어휘, exam이면 용례입니다.
part = '&part=exam'
#q에 검색할 문자열을 넣어줍니다.
q = '&q=' + urllib.parse.quote_plus(search_str[1])
#정렬 방식(기본값 dict)을 선택합니다. dict: 우리말샘순, popular: 많이 찾은 순, date: 새로 올린 순
sort = '&sort=dict'
fullURL = defaultURL + key + part + q + sort
req = urllib.request.Request(fullURL)
response = urllib.request.urlopen(req)
rescode = response.getcode()
if rescode == 200:
# xml -> dict -> json -> dict 한 번에 원하는 모습으로 바꾸는 방법이 잘 안 나와서 이렇게 했습니다. 더 깔끔하게 할 수 있는 방법이 있다면 알려주세요.
dict_type = json.loads(json.dumps(xmltodict.parse(response.read().decode('utf-8'))))
return extract_from_opendict_result(dict_type, search_str[1])
else:
return TextSendMessage(text='response code:' + rescode)
def extract_from_opendict_result(dict_type, search_str):
title_str_arr = ['link', 'word', 'example']
result_text = '-------------------------------
'
result_count = 0
for item in dict_type["channel"]["item"]:
for title_str in title_str_arr:
result_text = result_text + str(title_str) + '
'
result_text = result_text + item[title_str] + '
'
result_count += 1
if result_count >= 5:
break
if result_count == 0:
return TextSendMessage(text='no results found for ' + search_str + 'in opendict')
else:
return TextSendMessage(text=result_text)아래는 채팅창에 'opendict 이 중에'를 입력해서 국립국어원 우리말샘에서 '이 중에'를 검색한 결과 화면입니다.

검색 결과에 LINE 메시지 형식 적용
결과가 채팅창으로 제대로 전달된 걸 확인했으니 이제 화면에 나타나는 메시지를 좀 더 보기 쉽게 만들어 보겠습니다. LINE에서 제공하는 여러 메시지 형식을 이용할 건데요. 관련 가이드는 이곳에서 확인할 수 있습니다. 특히 Flex Message는 시뮬레이터를 이용하면 쉽게 구성해 볼 수 있으니 Flex Message를 사용하실 거라면 꼭 시뮬레이터를 이용해보시기 바랍니다.
아래는 네이버 뉴스 검색 결과를 좀 더 보기 쉽도록 꾸미는 코드입니다.
def decorate_news_result(result_json, search_str):
title_str_arr = ['link', 'title', 'description', 'pubDate']
carousel_contents = []
result_count = 0
for item in result_json["items"]:
if filter_news_search_result_by_newscompanyURL(item["originallink"]):
box_contents = []
for title_str in title_str:
text_left = TextComponent(text=str(title_str), color='#aaaaaa', size='xs', flex=1)
replaced_str = str(item[title_str]).replace('<b>','').replace('</b>','')
text_right = TextComponent(text=replaced_str, wrap=True, color='#666666', size='xs', flex=5)
box = BoxComponent(layout='baseline', margin='xs', spacing='xs', contents=[text_left, text_right])
box_contents.append(box)
carousel_contents.append(BubbleContainer(body=BoxComponent(layout='vertical', margin='xs', spacing='xs', contents=box_contents)))
result_count += 1
if result_count >= 5:
break
if result_count == 0:
return TextSendMessage(text='no results found for ' + search_str + 'in the news')
else:
return FlexSendMessage(alt_text='search for ' + search_str + ' in the news results', contents=CarouselContainer(contents=carousel_contents))우선, TextComponent를 이용하여 제목과 내용에 들어가는 텍스트를 각각 다른 색상으로 지정, 구분했고 생성한 TextComponent를 BoxComponent로 감싸 한 줄(row)을 완성했습니다. 이렇게 만든 줄들을 모아 다시 BoxComponent와 BubbleContainer를 이용해 둥글둥글한 하나의 상자로 만들었는데요. 검색 결과 하나 당 BubbleContainer 하나라고 보시면 되겠습니다. 이렇게 만든 여러 개의 BubbleContainer를 CarouselContainer에 담아 가로로 배치하여 FlexSendMessage로 전송했습니다.
아래는 채팅창에 'news 중에서는'을 입력해서 네이버 뉴스에서 '중에서는'을 검색한 결과입니다. 검색 결과를 둥글둥글한 상자에 한 건씩 담아 가로로 배치하니 여러 건의 검색 결과가 한꺼번에 주욱 나왔던 이전에 비해 한결 보기 좋아졌습니다.

아래는 국립국어원 우리말샘 검색 결과를 꾸미는 코드입니다. 방식은 위와 같습니다.
def decorate_opendict_result(dict_type, search_str):
title_str_arr = ['link', 'word', 'example']
carousel_contents = []
result_count = 0
for item in dict_type["channel"]["item"]:
box_contents = []
for title_str in title_str_arr:
text_left = TextComponent(text=str(title_str), color='#aaaaaa', size='xs', flex=1)
text_right = TextComponent(text=item[title_str], wrap=True, color='#666666', size='xs', flex=5)
box = BoxComponent(layout='baseline', margin='xs', spacing='xs', contents=[text_left, text_right])
box_contents.append(box)
carousel_contents.append(BubbleContainer(body=BoxComponent(layout='vertical', margin='xs', spacing='xs', contents=box_contents)))
result_count += 1
if result_count >= 5:
break
if result_count == 0:
return TextSendMessage(text='no results found for ' + search_str + 'in opendict')
else:
return FlexSendMessage(alt_text='search for ' + search_str + ' in opendict results', contents=CarouselContainer(contents=carousel_contents))아래는 채팅창에 '우리말샘 중에서는'을 입력해 국립국어원 우리말샘에서 '중에서는'을 검색해 본 결과입니다.

LINE에선 많은 메시지 형식과 함께 이를 활용할 수 있는 가이드도 제공하고 있어서 메시지를 취향에 맞추어 이리저리 쉽고 편하게 꾸며볼 수 있습니다. 별것 아니지만 혹시 코드가 궁금하신 분들은 git clone https://git.heroku.com/enigmatic-falls-19262.git 명령어로 코드를 내려받아 확인하실 수 있습니다. 또한 아래 QR코드로 제 테스트 봇을 친구 추가해서 사용해보셔도 됩니다.

맺으며
요즘 쇼핑, 금융, 유통 등 분야를 막론하고 여기저기서 AI가 적용됐다는 '챗봇'이 우르르 출시되고 있습니다. 그중에선 훌륭한 완성도를 보이는 챗봇도 있지만 도저히 챗봇이라고 부를 수 없는 실망스러운 챗봇도 있습니다. 수준이 떨어지는 챗봇을 만날 때면 '내가 혼자 만들어도 이것보단 잘 만들겠는데?'라는 생각이 들 때가 종종 있을 겁니다. 그런데 시험 삼아 혼자 시작해보면 이것저것 귀찮은 일들이 속속 눈에 들어와서 금방 그만두게 됩니다. 그럴 때 LINE Messaging API와 샘플봇을 이용하면 귀찮은 부분을 생략하고 내가 지금 머릿속에 상상한 바로 그 로직만 구현하여 바로 테스트해 볼 수 있습니다. 저는 아직 AI를 잘 모르기 때문에 이번엔 적용하지 못했지만, 샘플봇에 AI를 적용해서 나만의 AI 챗봇을 만들어 보는 것도 재미있을 것 같습니다. 물론 내가 만든 챗봇에 내가 실망하게 될 수도 있겠지만요.