
Tech-Verse 2022에서 홍선형 님이 발표한 LINE의 End-To-End MLOps 플랫폼 세션 내용을 옮긴 글입니다.
안녕하세요. MLU 프로덕트 매니저를 맡고 있는 홍선형입니다. 이번 글에서는 LINE의 MLOps 플랫폼, MLU를 사용해 기계 학습(machine learning, 이하 ML)의 엔드 투 엔드 파이프라인을 구축하는 방법을 함께 살펴보려고 합니다.
본격적으로 살펴보기 전에 작년 콜로라도 주립 박물관 미술 대회에서 1위를 차지한 작품을 감상해 보겠습니다. 'Theatre D'opera Spatial'란 작품으로 미래의 우주에서 오페라를 하고 있는 장면을 생생하게 연출했다는 평을 받았습니다.
"Théâtre D’opéra Spatial," a painting created using Midjourney by Jason Allen. [WIKIMEDIA COMMONS]
사실 이 작품은 Midjourney라는 AI 프로그램으로 만든 작품으로 텍스트로 설명을 입력해 단 몇 초 만에 만들었다고 합니다. 예술가가 단 한 번의 붓 칠도 하지 않은 작품이 우승을 차지해 논란이 됐는데요. 이와 같이 ML 모델은 다양한 분야에서 뛰어난 성능을 보이고 있습니다.
이런 대단한 모델을 만들기 위해서는 당연히 굉장히 많은 리소스와 시간, 노력이 들어갔을 것이라고 예상할 것입니다. 그렇다면 아래 화면처럼 비가 오는 날에 제가 쇼핑을 갈지 아니면 커피숍을 갈지 예측하는 모델은 앞서 본 모델에 비해 아주 간단하게 만들고 운영할 수 있을까요?
'그냥 모델 하나만 만들면 되는 것 아니야?'라고 생각하시겠지만 아닙니다. 이렇게 간단한 모델을 하나 만들어서 운영할 때에도 아래와 같이 모든 인프라를 구축하고 각 프로세스를 모두 진행해야 합니다.
그래서 모델을 개발하기 위해 필요한 스킬은 다음과 같다고도 하는데요. 모델 개발자 여러분 안녕하신가요?
ML 모델을 운영하기 위해서는 수많은 난관을 뚫어야 한다는 것을 예측할 수 있는데요. LINE에서 어떻게 그 많은 난관을 극복하고 오롯이 모델 개발에 집중해 성능을 향상시킬 수 있게 만들었는지 알아보겠습니다.
ML 파이프라인이란
먼저 ML 파이프라인이 무엇인지부터 살펴보겠습니다. ML 파이프라인이란 데이터 수집과 전처리, 모델 학습, 모델 배포, 모델 예측 등 ML 전체 과정을 순차적으로 처리하는 일련의 프로세스를 말합니다.
ML을 처음 도입하는 많은 팀들은 아래 그림과 같이 수동으로 워크플로를 만들곤 합니다. 로컬 데이터를 수집하고, 수집한 데이터를 전처리하고, 모델을 학습하고, 검증하는 모든 과정을 하나의 Jupyter Notebook 파일에 기록한 뒤, 그 Jupyter Notebook 파일을 로컬에서 실행해 모델을 생성하고 서비스 엔지니어에게 전달합니다.
모델을 주고받으면서 모델 개발자(ML)와 서비스 개발자(Ops)는 다음과 같은 대화도 주고받습니다.
혹시 이 대화가 익숙하신가요? 앞서 살펴본 것과 같은 워크플로는 불필요한 커뮤니케이션을 야기합니다. 프로세스를 반복하기 어렵고 그 과정과 결과를 문서화하고 이력화해 관리할 수 없어서 수동적이고 임시적입니다. 만약 반복 주기가 빨라진다면 여러 장애를 발생시킬 수도 있습니다. 모델 개발과 모델 성능 향상에 집중할 시간이 줄어듭니다.
그렇기 때문에 우리는 자동화한 ML 파이프라인을 구축해야 합니다. 아래 그림과 같이 데이터와 모델을 중앙에서 관리해야 하며, 이력을 저장할 수 있는 여러 저장소가 필요합니다. 로컬이 아닌 중앙 클라우드 환경에서 모델을 만들고, 배포하는 모든 과정을 자동화하고 스케줄링해야 합니다. 모델이 아닌 파이프라인으로 커뮤니케이션해야 합니다.
제 설명과 워크플로만 보고는 잘 와닿지 않으실 텐데요. 지금부터 LINE의 대표 MLOps 플랫폼인 MLU를 적용해 실제 개선한 사례를 살펴보면서 파이프라인을 어떻게 자동화했는지, 어떻게 LINE의 모델 개발 프로세스를 개선했는지 알아보겠습니다.
MLU를 활용한 파이프라인 자동화 사례 - LINE VOOM 'For you'
LINE VOOM의 'For you'는 사용자가 관심 가질 만한 콘텐츠를 추천해 주는 공간입니다. 각 사용자가 관심 있게 본 콘텐츠를 기반으로 개인화를 진행해서 사용자가 콘텐츠를 선택하면 그 사용자가 좋아할 만한 콘텐츠를 계속해서 탐색할 수 있게 만듭니다.
'For you'에 사용한 ML 추천 모델의 특징과 요구 사항
LINE에서는 'For you'에 ML 추천 모델을 사용합니다. 사용자에게 추천할 만한 후보군을 생성한 뒤, 사용자 피드백과 품질을 기반으로 데이터 검증 및 필터링 과정을 거치고, 그 데이터를 이용해 다양한 임베딩 과정을 거쳐 모델을 학습시키고 배포합니다. 이렇게 배포한 모델을 통해 추천한 포스트에서 다시 사용자의 피드백을 받아서 그 결과를 반영해 지속적으로 더욱 적합한 추천 포스트를 제공합니다.
이와 같은 추천 모델에서 중요한 것은 모델에 새로운 추천 후보군과 사용자 피드백을 자주 반영해 사용자가 지속 가능한 경험을 느끼게 만드는 것입니다. 그렇기 때문에 'For you' 모델은 매일 일정한 시각에 업데이트하는 것이 가장 중요합니다. 또한 하나의 모델에서만 결과를 만드는 게 아니라 여러 모델의 결과를 종합해 사용자에게 앙상블한 결과를 추천하기 때문에 수십 개의 모델 파이프라인을 일정한 시각에 스케줄링해서 수행해야 합니다. 다수의 모델이 하나의 결과에 영향을 주기도 하고 반대로 하나의 모델이 여러 결과에 영향을 주기도 하기 때문에 어떤 추천 결과가 도출되는지 종속 관계를 한눈에 파악할 수 있어야 하며, 데이터와 모델 버전을 관리해 이력을 확인하는 것도 중요한 작업입니다.
여기에 더해 기존에는 하나의 모델에 문제가 발생하면 모든 모델에 장애가 전파되는 사례가 빈번했기 때문에 ML 모델 하나하나를 마이크로 서비스 형태로 쪼개서 독립적인 서비스로 구성할 수 있는 환경이 필요했습니다. 이때 엔지니어 지식이 많지 않은 ML 모델 작업자에게는 이런 환경을 구축하고 개발하는 것의 러닝 커브가 높기 때문에 단 몇 줄의 명령어로 손쉽게 모델을 API화하고 컨테이너화할 수 있는 도구가 필요했습니다. 또한 모델 학습과 서빙에는 GPU 자원이 굉장히 많이 필요하기 때문에 효율적으로 GPU 자원을 사용할 수 있는 유연하고 최적화된 알고리즘도 필요했습니다. 마지막으로 각 단계에서 팀 내 개발자가 서로 다른 환경 때문에 커뮤니케이션해야 하는 비용과 발생하는 오류도 해결해야 했습니다.
MLU로 파이프라인을 자동화해 문제 해결하기
우리는 MLU를 통해 이 문제들을 하나씩 해결해 보기로 했습니다.
우선 MLU가 제공하는 클라우드 서버 환경에서 데이터 전처리부터 모델 학습 및 검증을 진행하는 것으로 시작했습니다. MLU는 JupyterLab과 코드 서버뿐 아니라 로컬 아이디를 사용할 수 있도록 SSH 기능도 제공하고 있어서 로컬과 동일한 환경으로 개발을 진행하면서 MLU 자원과 공유 리포지터리는 온라인 환경과 동일하게 사용할 수 있습니다. MLU에서 제공하는 Docker 베이스 이미지에서 개발하고 커스텀 이미지를 만들어 프로젝트로 공유하면 모든 팀원이 동일한 환경에서 개발을 진행할 수 있습니다.
또한 모델 학습 과정에서 모든 로깅과 트래킹을 MLflow에 저장해, 연결된 데이터 셋과 모델을 학습시키는 데 사용한 파라미터와 학습 척도 및 성능을 효율적으로 관리할 수 있습니다.
패키징은 BentoML을 사용해 자동으로 도커라이징 및 API화했고, 서버 자원 스케일 인아웃도 관리할 수 있습니다. 모델 개발자가 엔지니어링 관련 지식이 전혀 없어도 효율적으로 GPU 자원을 최적화해 사용할 수 있습니다.
이 모든 워크플로는 Apache Airflow를 이용해 자동화 및 스케줄링했고, Python 코드로 작동하는 Apache Airflow를 사용하기 어려워하는 모델 개발자에게는 MLU에서 제공하는 커스텀 오퍼레이터와 GUI 툴을 이용해 로우 코드(low code)로도 파이프라인을 구축할 수 있게 제공합니다.
모델을 배포할 때는 모델 개발자 개입 없이 모델 스스로 수십 번의 테스트를 거쳐 최적화된 서버 환경을 찾습니다. 이 서버 환경은 자동으로 스케일링 및 로드 밸런싱되기 때문에 안정적으로 모델을 서빙할 수 있습니다.
이와 같은 파이프라인을 구축할 때 아래 그림과 같이 MLU 포털에서 제공하는 UI 환경에서 단 몇 번의 클릭으로 쉽고 빠르게 프로젝트를 만들고 각 인스턴스를 구축할 수 있습니다.
파이프라인 구축뿐 아니라 프로젝트에 속해 있는 모든 팀원과 개발 과정을 공유하고 커뮤니케이션할 수 있는 공간도 마련해 놓았으며, 프로덕션으로 서빙한 후에는 시각화한 모니터링을 제공합니다.
파이프라인 자동화 후 얻은 성과
MLU를 도입해 앞서 언급했던 LINE VOOM 'For you' 추천 모델의 많은 문제를 해결했습니다. 또한 추천 서비스 모델을 운영하기 위해 10대로 구성했던 서버를 MLU에서 제공하는 클라우드 서버 1대로 대체했고, 모든 프로세스를 자동화하면서 운영 인력 비용은 물론 운영 중 발생하는 장애 또한 획기적으로 줄였습니다. 이를 통해 궁극적으로 모델 성능 향상에 집중할 수 있었습니다.
MLU를 사용한 뒤로 더 이상 모델 개발자가 ML 모델을 개발할 때 인프라 구축 때문에 어려움을 겪지 않게 됐습니다. 쿠버네티스가 무엇인지, 어떻게 GPU를 사용할 것인지 전혀 신경 쓸 필요가 없습니다. MLU가 구축해 놓은 최적의 인프라 환경에서 그저 데이터 분석과 모델 개발에만 집중하면 됩니다. Airflow나 BentoML 같이 ML 생태계에서 각광받고 있는 여러 오픈 플랫폼을 개개인이 직접 설치해서 사용할 필요 없이 MLU가 제공하는 중앙 환경에서 손쉽게 인스턴스를 생성한 뒤 모든 팀원이 동일한 환경을 공유할 수 있습니다. 이 모든 과정을 어떤 설치와 코드 작업 없이 MLU 포탈에서 제공하는 직관적인 UI를 이용해 간단히 만들 수 있기 때문입니다.
LINE 그룹 내 MLU 사용 현황
MLU는 'For you' 추천 모델뿐 아니라 LINE 그룹 내 대부분의 ML 모델 팀 파이프라인 구축을 지원하고 있습니다. A사의 클라우드 비용 산정 기준 약 500억 정도의 클러스터 자원으로 모델을 만들기 위한 인프라를 지원하고 있으며, 일본과 태국, 대만 등 LINE 글로벌 오피스에서 쇼핑과 광고, 게임 등 300개가 넘는 다양한 ML 모델 개발 팀이 LINE MLOps 환경을 이용하고 있습니다. 결과적으로 현재 MLU에서 300개의 자동화 파이프라인이 수행되고 있으며, MLU를 통해 총 107개의 ML 모델이 실제 프로덕션으로 안정적으로 서빙되고 있습니다.
모델과 데이터 셋을 공유하는 리포지터리, MLU MARKET PLACE
현재 MLU에서는 ML 엔드 투 엔드 파이프라인 구축에서 한 발짝 더 나아가 유연하고 확장할 수 있는 ML 생태계 구성을 목표로 하고 있습니다. 이를 위해 LINE에서 제공하는 모델과 데이터 셋을 누구나 쉽게 공유하고 사용할 수 있도록 퍼블릭 모델 리포지터리 공간을 만들고 있으며, 그 공간 안에 있는 데이터를 효율적으로 관리하고 양질의 데이터를 계속해서 만들어 나갈 수 있는 파이프라인을 제공하는 것도 계획하고 있습니다. 또한 누구나 모델과 데이터에 대해 토론하고 지식을 함께 공유해 사용자가 스스로 자신들만의 ML 생태계를 발전시켜 나갈 수 있는 커뮤니티 활성화에도 힘쓰고 있습니다.
아래는 LINE에서 모델과 데이터 셋을 공유하는 리포지터리인 MLU MARKET PLACE 데모 영상으로, 어떻게 모델을 공유하고 관리하는지 살펴볼 수 있습니다. 먼저 Create 버튼을 클릭해서 모델 이름을 기입하고 공개 범위를 선택하면 MARKET PLACE에 모델 저장소가 생성됩니다.

생성된 주소를 복사해 MLU Jupyter Notebook 서버에서 리포지터리를 클론한 후, 해당 폴더에서 모델을 훈련합니다.
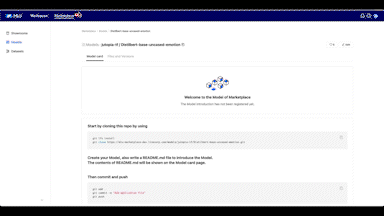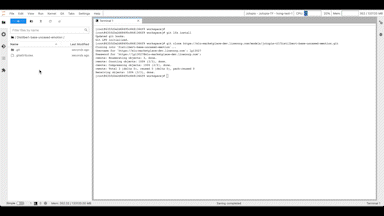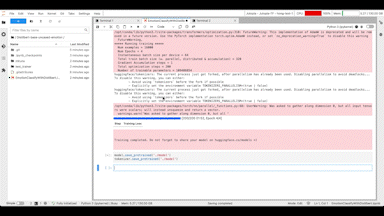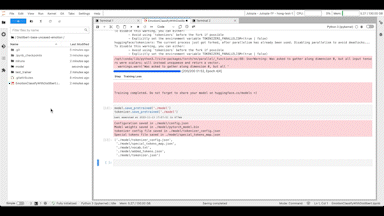
모델 훈련이 완료되면 모델을 소개할 README 파일을 작성하고 생성한 모델과 각종 파일을 저장소에 올립니다.
저장소에 올린 후 MARKET PLACE 화면으로 돌아가면 README 파일에 작성해 놓은 모델 소개 내용이 조화롭게 나타나는 것을 볼 수 있습니다.
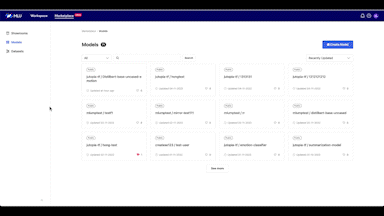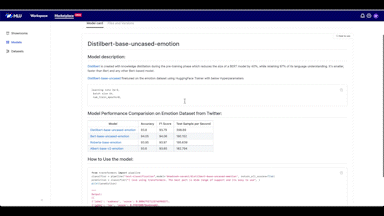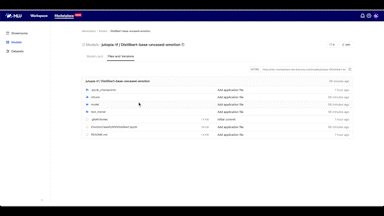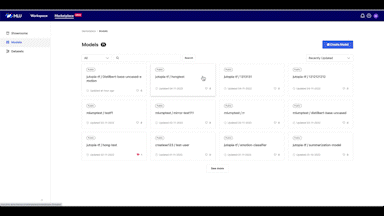
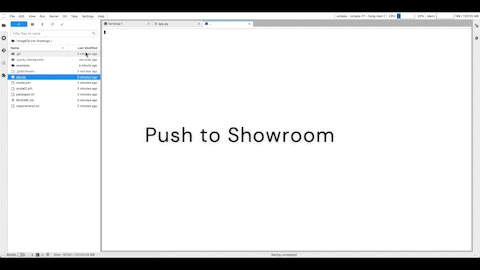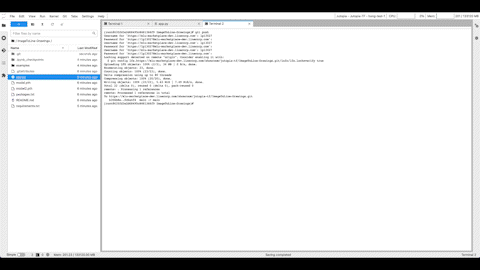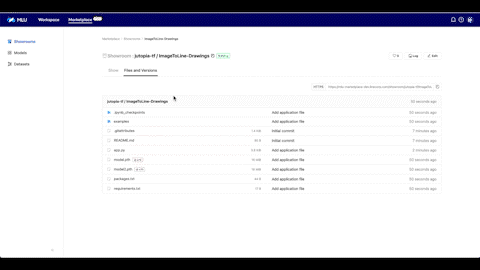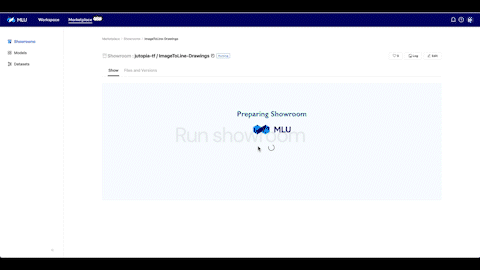
이와 같이 MARKET PLACE에서는 리포지터리를 쉽게 생성하고 모델을 효율적으로 관리할 수 있을 뿐 아니라 내가 만든 모델을 모두와 공유하고 함께 사용할 수 있습니다.
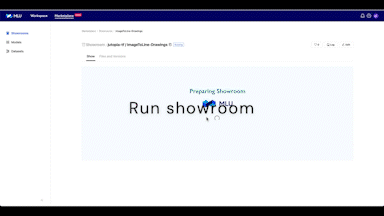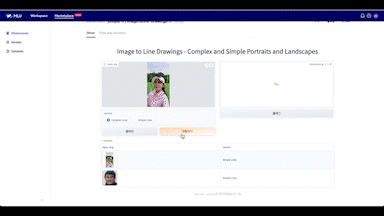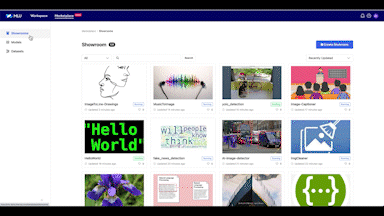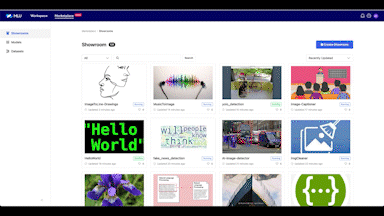
MARKET PLACE는 모델을 데모로 실행해 볼 수 있는 공간인 'Showroom'도 제공하고 있습니다. 아래는 사진을 스케치하는 데모 페이지를 만들어 본 영상입니다. Showroom 제목을 입력하고 대표 이미지를 업로드한 후 모델을 빌드할 SDK를 선택하고 Showroom을 생성합니다. 모델과 마찬가지로 리포지터리 공간이 생성됩니다.

다시 MLU Jupyter Notebook 서버에서 해당 리포지터리를 클론한 후 모델을 데모로 실행할 코드를 작성합니다. 어떤 모델을 사용할지 정의하고 데모 페이지 예시를 만듭니다. 여기서는 Showroom을 생성할 때 선택한 'Gradio'라는 라이브러리를 이용해 데모 페이지를 만들었습니다.

해당 코드를 리포지터리에 푸시하면 푸시하는 순간 자동으로 모델을 빌드할 서버가 생성되고 애플리케이션이 실행됩니다.
모델을 빌드하는 약간의 시간을 기다리면 데모 페이지를 웹에서 조회할 수 있습니다. 여기서는 제 사진을 사용했는데요. 제 사진이 한순간에 예쁜 스케치로 바뀌는 것을 볼 수 있습니다. 제가 만든 모델뿐 아니라 다른 팀에서 만든 모델도 웹에서 간단하게 데모를 실행해 볼 수 있습니다.
마치며
MARKET PLACE를 보신 소감이 어떠셨나요? 어렵게만 느껴졌던 ML이라는 기술이 조금은 쉽게 와닿지 않으셨나요? 이렇듯 MLU는 모델 엔지니어를 위한 MLOps 플랫폼으로 시작했지만 현재 모델 개발자뿐 아니라 서비스 엔지니어와 디자이너, 기획자 등 LINE 내 모든 직군이 자신의 서비스에 ML을 도입해 보고 싶을 때 누구나 쉽고 빠르게 ML을 사용해 볼 수 있는 환경을 구축하고 지속적으로 기능을 추가해 나가고 있습니다. 단순한 MLOps 플랫폼을 넘어 LINE의 ML 생태계를 조성하고 확산하는 것을 목표로 삼고 있으며, 그것이 바로 MLU가 꿈꾸는 ML 엔드 투 엔드 파이프라인의 완성 모습이 아닐까 합니다. 긴 글 읽어주셔서 감사합니다.