
들어가기
안녕하세요. LINE Ads에서 DSP Manager를 담당하고 있는 김용훈입니다. LINE Ads는 일본과 태국, 대만 등 전 세계 LINE 사용자를 대상으로 하는 글로벌 광고 플랫폼을 개발하고 있습니다. LINE의 광고 플랫폼은 대량으로 생성되는 데이터를 실시간으로 처리하며 사용자들이 관심을 가질 광고를 예측해서 제공합니다. DSP(Demand Side Platform) Manager는 간단히 이야기하면 광고주가 사용하는 광고 관리 도구라고 할 수 있습니다. 광고 등록과 등록한 광고에 대한 심사, 심사 완료 후 집행된 광고의 효과와 비용에 대한 청구 정보 확인 등 여러 가지 기능을 제공하는 시스템입니다.
LINE Ads에서는 이런 요구 사항을 효율적으로 적용해 나가기 위해서 많은 인원이 효율적으로 협업할 수 있는 환경이 필요하다고 판단, MSA를 기반으로 각 서비스를 게이트웨이와 애드서비스, 리포트, 빌링, 리뷰 등의 여러 개로 구성했습니다. 이런 선택은 서비스가 성장하면서 인원이 늘어났을 때 효율적으로 협업할 수 있도록 좋은 영향을 주었지만 서비스가 안정화되기까지는 발생한 문제들을 확인하는 데 어려움이 있었습니다. 이런 경험을 바탕으로 MSA 환경에서 효율적으로 문제를 확인하기 위해 LINE Ads에서 진행하고 있는 것들을 공유하려고 합니다.
MSA 환경과 OpenTracing이란
모놀리식(monolithic)과 MSA(Micro Service Architecture)에 대해서 간단하게 설명하겠습니다. 모놀리식의 경우 하나의 서버가 서비스의 전반적인 기능을 모두 제공합니다. 그로 인해 복잡도가 증가하고 역할을 나누기 어려운 등 많은 문제가 발생하지만, 클라이언트의 요청을 받으면 하나의 스레드에서 모든 요청을 실행하므로 로그를 확인하기 쉽다는 장점이 있습니다. 그에 반해 MSA의 경우에는 각 서비스의 복잡도가 낮아지고 역할 분담이 용이하지만 클라이언트의 요청을 받았을 때 여러 개의 마이크로 서비스 간에 통신이 발생해 로그를 확인하기 어려운 문제가 있습니다.
이런 문제를 해결하기 위한 방법으로 OpenTracing이 알려져 있습니다. OpenTracing은 간단히 말해 애플리케이션 간 분산 추적을 위한 표준이라고 할 수 있습니다. 이 표준의 대표적인 구현체로 Jaeger와 Zipkin이 있는데요. LINE Ads에서는 Java와 Spring 프레임워크 환경에서 손쉽게 연동할 수 있는 Zipkin을 선택했습니다.
OpenTracing 환경 구성하기
Zipkin 설정하기
먼저 Zipkin에 대해 알아보겠습니다. Zipkin의 아키텍처는 아래와 같습니다.
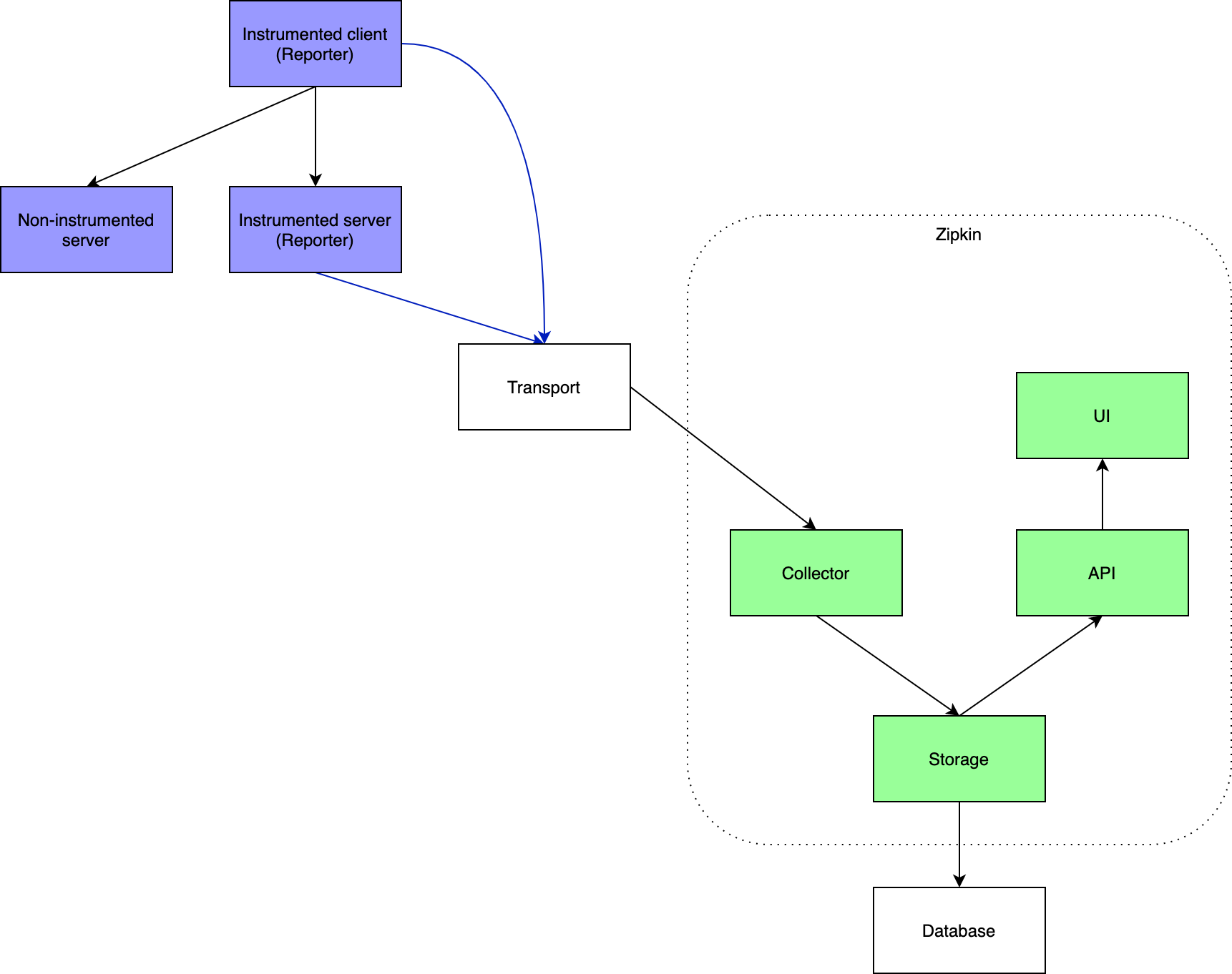
Zipkin의 아키텍처는 간략하게 아래와 같이 설명할 수 있습니다.
- Reporter가 Transport를 통해서 Collector에 트레이스 정보를 전달합니다.
- 전달된 트레이스 정보는 Database에 저장됩니다.
- Zipkin UI에서 API를 통해 해당 정보를 시각화해서 제공합니다.
각 컴포넌트를 조금 더 자세히 살펴보겠습니다.
- Reporter
- 각 서버는 계측(instrumented) 라이브러리를 사용해야 Reporter로서 동작할 수 있습니다. Zipkin에서는 다양한 언어에 대한 라이브러리를 제공하고 있습니다(참고). LINE Ads에서는 Java 환경에서 개발하고 있어서 Brave를 사용할 수 있었습니다. 또한 Spring 프레임워크도 사용하고 있었는데요. Spring Cloud Sleuth는 BraveTracer를 통해서 트레이스 데이터를 관리하기 위한 대부분의 기능을 제공하고 있었으므로 빠르고 쉽게 적용할 수 있었습니다.
- Database
- Zipkin에서 몇 가지 Storage를 지원하고 있었는데요(참고). 이미 ES(ElasticSearch)를 사용하고 있었기 때문에 고민 없이 ES를 선택했습니다.
- Zipkin
- 웹에서 제공하는 명령어를 실행하는 것만으로 간단하게 설치할 수 있으며, 여기에 약간의 설정을 추가해서 ES를 사용할 수 있었습니다.
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9200
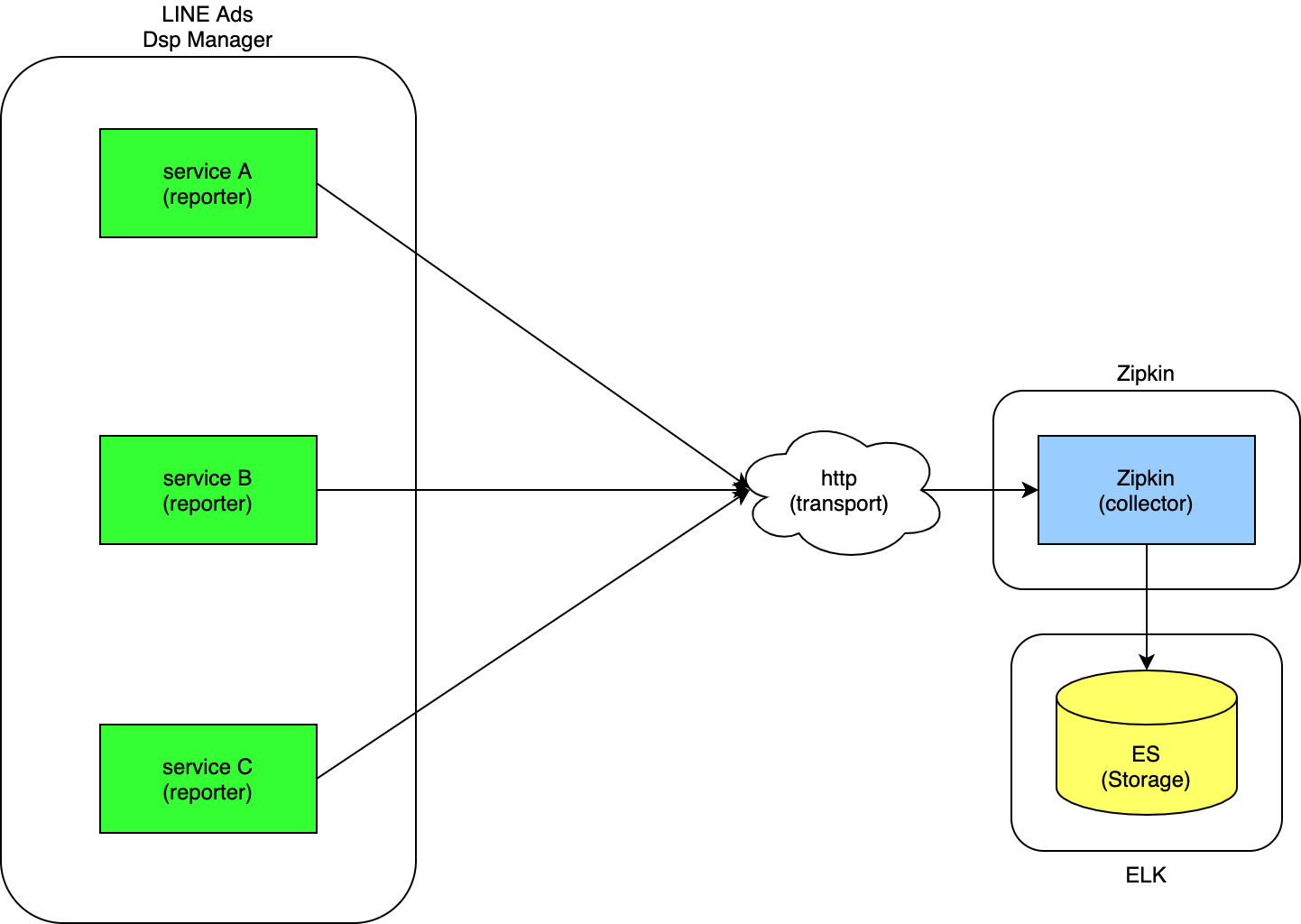
이처럼 간단한 설정으로 Zipkin 서버를 설치하고 각 서비스에 라이브러리를 적용해 아래와 같은 트레이스 환경을 구성할 수 있었습니다.
Spring Cloud Sleuth 설정하기
Spring Boot 환경에서 의존성를 추가하는 것만으로도 기대 이상의 효과를 얻었지만, Zipkin의 동작 원리에 대해 더 알아보았고 좀 더 세밀하게 설정할 수 있었습니다.
Zipkin 헤더
Zipkin은 B3-Propagation을 통해서 OpenTracing을 구현하고 있습니다. B3 propagation은 간단히 말해 'X-B3-'으로 시작하는 X-B3-TraceId와 X-B3-ParentSpanId, X-B3-SpanId, X-B3-Sampled, 이 4개 값을 전달하는 것을 통해서 트레이스 정보를 관리합니다. 서버에서는 이 값들을 TraceContext에서 관리하는데요. Spring 프레임워크와 SLF4J(Simple Logging Facade for Java)를 사용하고 있었기에 MDC(Mapped Diagnostic Context)에서 해당 값을 꺼내서 사용할 수 있었습니다. HTTP를 통해 다른 서버로 전달하는 경우에는 HTTP 헤더를 통해서 전달하고, Kafka 메시지를 통해 전달하는 경우에는 Kafka 헤더를 통해서 전달합니다.
Spring cloud sleuth
Zipkin의 Brave는 B3-propagation의 Java 구현체이고, Spring Cloud Sleuth는 BraveTracer를 Spring 프레임워크에서 쉽게 사용하기 위한 라이브러리입니다. TaskExecutor와 RestTemplate, KafkaTemplate, KafkaListener, RedisTemplate을 사용하는 것만으로 새로운 스팬(span)이 생성됩니다. 다만, BeanPostProcessor를 통해서 동작하기 때문에 아래와 같이 메서드 내부에서 생성된 오브젝트를 사용하는 경우에는 동작하지 않습니다.
TaskExecutor executor = new TaskExecutor();따라서 아래와 같이 항상 'bean' 형태로 사용하는 것을 권장합니다(LazyTraceExecutor로 래핑해서 사용하는 방법도 있습니다).
@Bean
public TaskExecutor taskExecutor() { return new TaskExecutor();}이렇게 관리하는 B3 헤더는 MDC에 저장되기 때문에 로그 설정을 수정하면 로그에서 스레드 대신 트레이스 ID와 스팬 ID를 확인할 수 있습니다. 참고로 Spring Cloud Sleuth 최신 버전에서는 B3 헤더 이름 대신 traceId와 spanId, spanExportable을 사용할 수 있습니다.
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS,Asia/Tokyo} %clr(%-5level) [%thread,%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}] %clr(%logger{36}){cyan} [%file:%line] - %msg%n</pattern>
마지막으로 여러 서버에 있는 로그를 한 번에 조회하기 위해서 Tomcat 로그가 ES에 저장되도록 합니다. 로그를 ES에 저장하는 방법으로는 Beats와 ELK 조합으로 로그 파일의 내용을 ES에 저장하는 방법과, Beats 없이 로그 어펜더(appender)에서 직접 Logstash로 전송하는 방법이 있는데요. 이번 글에서는 해당 부분에 대한 자세한 설명은 생략하겠습니다.
로그 확인하기
환경 설정을 완료했으니 이제 로그를 확인해 보겠습니다.
Zipkin을 통해서 ES에 저장된 스팬 정보는 위와 같이 ES 인덱스에 저장되며 각 도큐먼트는 아래와 같습니다.
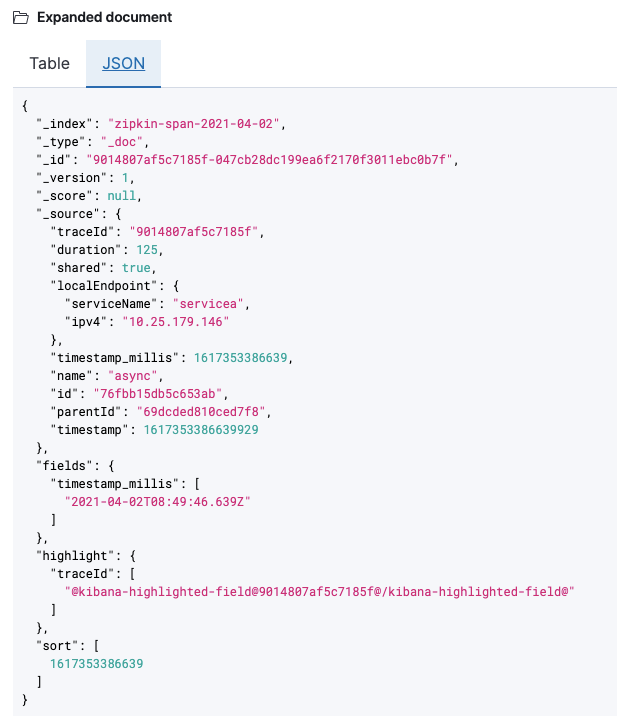
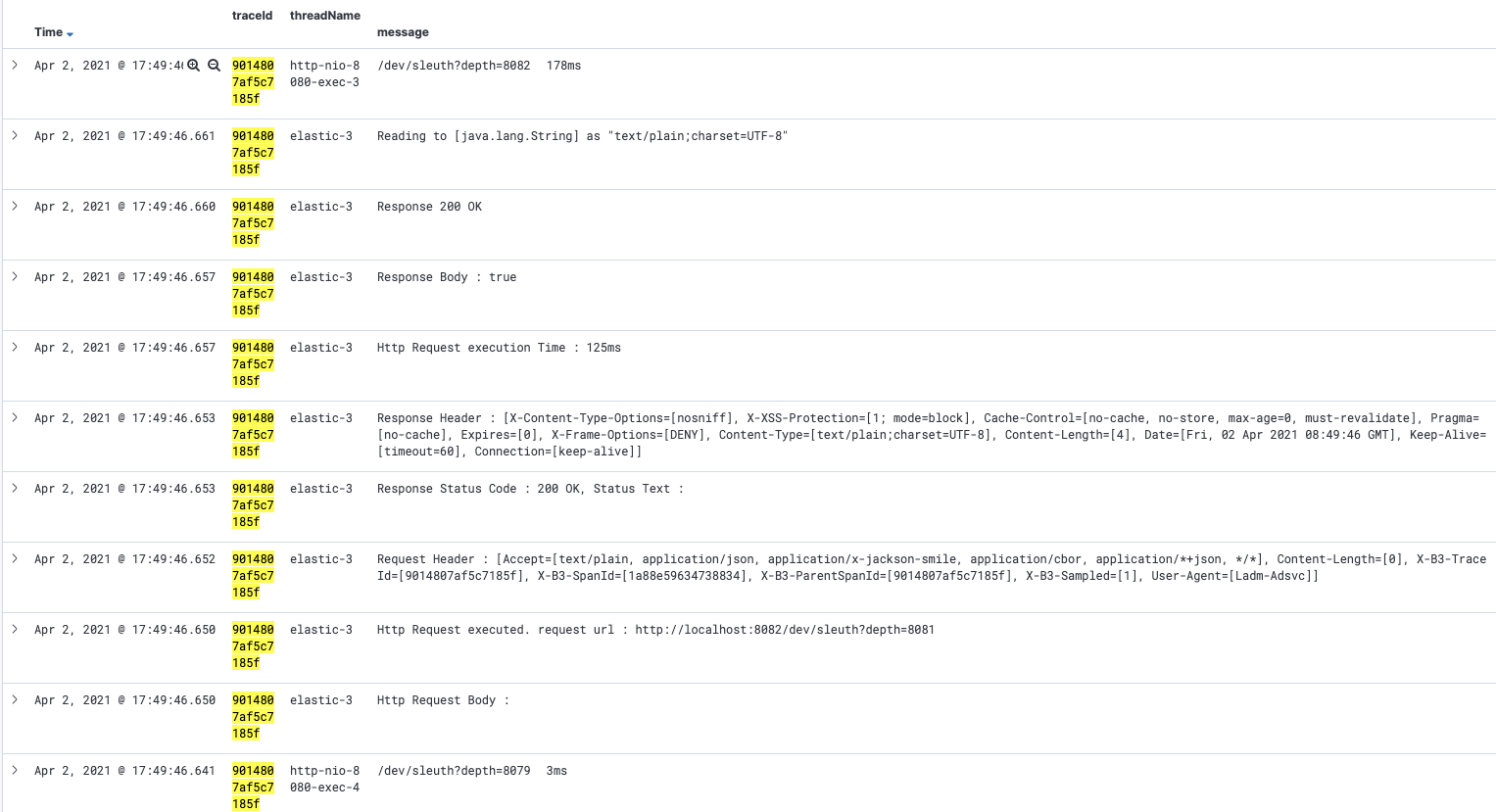
실제로 저장된 도큐먼트를 직접 조회하는 경우는 거의 없고 일반적으로 Zipkin 서버에서 traceId를 사용해서 조회할 수 있습니다.
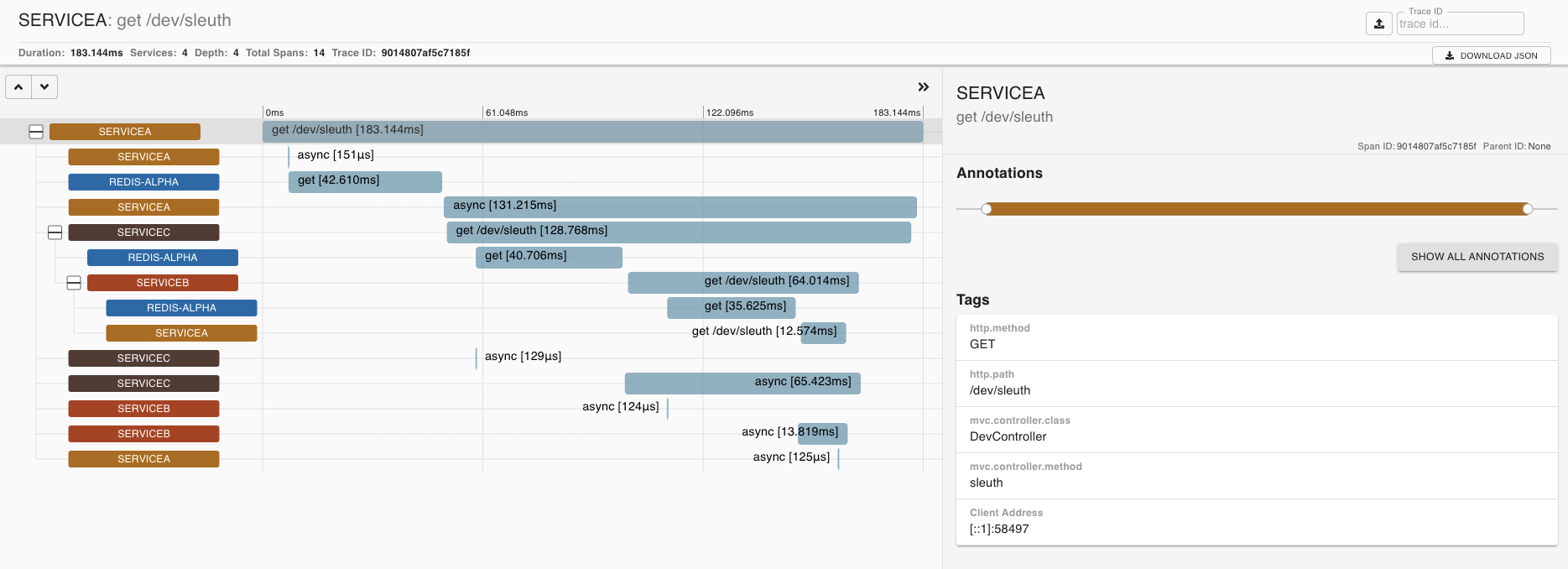
또한 앞에서 Logback 설정으로 traceId를 추가해 두었으므로 Kibana에서 traceId로 검색할 수 있습니다.
OpenTracing 적용 전과 후 비교하기
개발 환경 또는 실제 서비스 환경에서 에러가 발생한 경우 모니터링 시스템에서 아래와 같은 로그 알림을 보냅니다.
2021-04-05 19:10:28.557 ERROR [http-nio-8082-exec-2,24f160ed64c95ac1,45b819491d98780b,true] errorResponse [ErrorResponse.java:114] - Responded error status: 500 - HttpException: Code : 500
이 로그 알림을 보고 에러와 관련된 로그를 찾는 과정을 적용 전과 후로 나눠 살펴보겠습니다.
적용 전
우리는 로그에 있는 정보를 최대한 활용해서 원인을 찾을 수밖에 없습니다. 트레이싱 기술을 적용하지 않았다면 traceId(24f160ed64c95ac1)를 얻을 수 없기 때문에 위 로그에서 쓸만한 정보는 시각(2021-04-05 19:10:28.557)과 스레드 이름(http-nio-8082-exec-2) 정도입니다.
스레드 이름으로 해당 서버의 로그를 검색하면 동일 스레드의 로그를 확인할 수 있고 운이 좋다면 이를 통해서 요청 URL을 알아낼 수 있을지도 모릅니다. 만약 에러가 발생한 스레드가 Tomcat 스레드가 아닌 태스크 실행(task executor) 스레드라면 Tomcat 스레드와 태스크 실행 스레드 간의 연결성을 추측해야 할지도 모릅니다. 그렇게 요청 URL을 찾아냈다고 해도 요청을 발생시킨 클라이언트를 찾기 위해서 접속 로그의 사용자 에이전트(user-agent)로 클라이언트를 특정해야 하고, 클라이언트 서비스의 담당자는 해당 호출이 발생한 위치를 특정하기 위해서 소스 코드를 찾아봐야 할 것입니다.
몇 가지 가능한 경우의 수를 추려냈다면 이제 클라이언트의 접속 로그와 시간을 비교해서 요청을 찾습니다. 운 좋게 요청을 특정하면 앞에서 했던 일들을 반복합니다. 최종적으로 사용자 요청을 특정하면 비로소 에러를 유발한 요청의 흐름을 파악할 수 있게 됩니다.
위 과정은 중간중간 몇 번의 추측을 포함하고 있기 때문에 때때로 잘못된 로그를 살펴보면서 많은 시간을 허비하게 됩니다. 게다가 위에서 설명한 일련의 과정은 디버깅 경험이 많은 개발자라면 능숙하게 해낼 수도 있겠지만, 대부분의 개발자의 경우 많은 시행착오를 겪게 될 것입니다.
적용 후
트레이싱 기술을 적용했다면 traceId(24f160ed64c95ac1)를 얻을 수 있고 Zipkin UI도 사용할 수 있습니다. 전체 흐름을 찾는 과정은 너무나 간단합니다. 웹 UI에서 ID를 넣고 검색하면 서비스 A와 B, C의 호출 순서를 타임라인과 함께 볼 수 있으며 에러가 발생한 구간도 명확하게 표시되는 것을 확인할 수 있습니다.
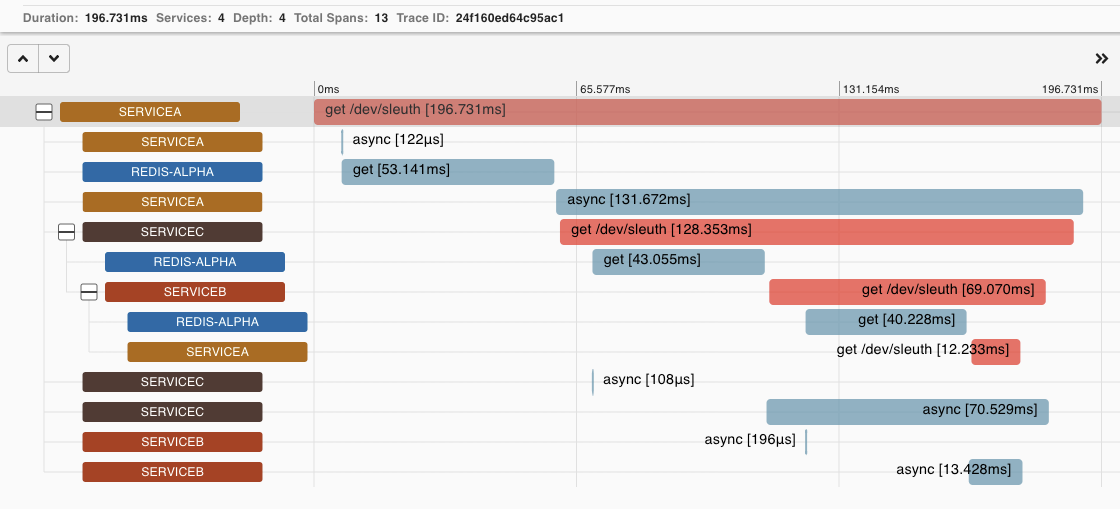
이런 방식은 특별한 경험이 필요하지 않습니다. 간단한 가이드 문서를 읽어 보는 것만으로도 쉽게 파악할 수 있어서 새로 팀에 합류한 사람도 금방 적응할 수 있고 문제 해결에 소요되는 시간을 상당히 단축할 수 있습니다.
마치며
지금까지 OpenTracing 라이브러리 중 하나인 Zipkin을 적용하고 MSA 환경에서 로그를 확인하는 방법을 알아보았습니다. 이번 글에서는 세 개의 서비스가 HTTP로 통신하는 환경을 기반으로 설명드렸는데요. 실제 서비스 환경에서는 한 번의 HTTP 요청이 여러 개의 Kafka 메시지를 발생시키는 것과 같이 요청이 복잡하게 전달되는 경우가 많이 있어서 이런 것들을 추적하기 위해 여러 가지 방법을 찾아보고 있었습니다. 그러던 중 이미 표준화된 기술이 있다는 것을 알게 되어 적용했고, 큰 공수를 들이지 않고 편리하게 사용할 수 있는 환경을 구성할 수 있었습니다.
처음에는 팀원들도 새로 추가된 환경이 익숙하지 않아서 제대로 활용하지 못하는 경우가 많았는데요. 지금은 이런 환경 없이 개발하는 것은 상상할 수 없을 정도로 모두 편리하게 사용하고 있습니다. MSA를 도입했을 때 아키텍처의 변화가 개발 환경의 변화를 야기하면서 로그를 확인할 때 불편함이 많았는데요. OpenTracing을 적용한 이후에는 더 이상 불편함을 느끼지 않고 있습니다.
개발자가 일하는 환경은 언제나 당연하다는 듯이 변화합니다. 이에 따라 개발자는 수시로 새로운 환경에 놓이게 되는데요. 항상 그 변화 속에 내재된 또 다른 변화들을 놓치지 않아야 한다는 것을 느끼게 해 준 경험이었습니다.