
들어가며
안녕하세요. Global EC(Global E-Commerce, 이하 GEC)에서 쇼핑 개발을 담당하고 있는 김성도입니다. LINE 쇼핑에서는 실시간으로 상품 정보를 업데이트할 수 있는 LINE 쇼핑 플랫폼을 사용해 모든 상품 정보를 취합하고 있으며, 취합한 상품 정보는 사용자의 쇼핑 경험을 개선하기 위해 검색 엔지니어와 데이터 엔지니어에게 제공하고 있습니다. 수억 개에 이르는 상품 정보를 서비스에 영향을 주지 않으면서 ETL(Extract, Transform, Load)하는 작업은 쉽지 않은 일입니다. 그런데 여기에 한술 더 떠서 실시간으로 업데이트까지 하려면 어떻게 해야 할까요? 이번 글에서는 이 어려운 과제를 해결하기 위해 어떤 과정을 거쳤는지 소개하려 합니다.
글은 다음과 같은 순서로 진행합니다.
요구 사항 분석
Hadoop 에코 시스템에서 작동하는 Hive를 사용한다는 전제가 있습니다. 이를 염두에 두고 요구 사항을 '데이터베이스 부하 감소'와 '업데이트 주기 개선', '정합성 유지', 세 항목으로 나눠 살펴보겠습니다.
데이터베이스 부하 감소
이번 개선 작업 전에는 상품 정보를 모두 받아오기 위해서 MongoDB를 풀 스캔하는 방식으로 ETL 작업을 해왔습니다. 평소에 가해지는 부하량만 놓고 보면 이와 같은 방식이 문제 되지 않지만, 평소보다 상품 정보 업데이트가 많이 발생하거나 많은 사용자가 몰릴 때에는 문제가 발생할 수 있습니다. 데이터베이스에 적정량 이상의 부하가 가해지면 자연스레 서비스에 영향을 미치기 때문입니다. 이로 인해 판매자가 상품 정보의 가격을 변경했지만 바로 반영되지 않는다거나 사용자가 상품을 조회했을 때 결과가 제대로 나오지 않는 현상이 발생할 수 있습니다. 이런 상황에서는 아무래도 서비스에 직접적인 영향을 미치지 않기 때문에 상대적으로 중요도가 떨어지는 ETL 작업을 포기할 수밖에 없습니다. 이와 같은 현상을 사전에 방지하려면 데이터베이스에 부하를 주지 않는 방법을 생각해야 합니다.
업데이트 주기 개선
이번 개선 작업 전에는 업데이트 주기가 하루였고 이보다 더 짧게 만들기는 어려웠습니다. 주기가 짧아질수록 데이터베이스에 더 큰 부하를 유발하기 때문입니다. 하지만 ETL 데이터를 사용하는 쪽에서는 주기가 짧아질수록 좋습니다. 주기가 짧아질수록 아래와 같이 할 수 있는 작업이 더 많아지기 때문입니다.
- 업무 시간 중에 업데이트된 상품 정보를 사용해 통계 산출
- 상품 정보 데이터로 만드는 검색 피처(feature) 갱신 주기 단축
- 상품 정보 수신 여부 확인
이와 같은 작업을 통해 LINE 쇼핑에 상품을 등록한 판매자에게 정확한 통계 정보를 제공해 상품 판매에 도움을 줄 수 있고, LINE 쇼핑 사용자에게 최신화한 관련 상품 정보를 더욱 풍부하게 보여줘 더 나은 쇼핑 경험을 제공할 수도 있습니다.
정합성 유지
기존에 사용하던 ETL 데이터와 개선하며 만든 데이터는 동일해야 합니다. UPDATE, CREATE, DELETE 이벤트가 정상적으로 반영되지 않으면 정합성을 유지할 수 없으며, 이는 의사 결정에 잘못된 데이터를 사용하거나 저품질의 검색 피처를 만드는 결과를 초래할 수 있습니다.
또한 MongoDB를 풀 스캔하는 방식으로 대량 데이터를 추출하면 읽기 일관성(read consistency)을 확보하기 어렵습니다. 읽기 일관성을 확보하지 못하면 쿼리 수행 시점의 데이터만 추출하지 못하고 추출하는 동안 영향을 받은 데이터까지 포함됩니다.
우리에게 필요한 데이터는 특정 시점의 데이터이지만 마지막(최신)에 변경한 데이터만 저장하는 구조에서 특정 시점의 대량 데이터를 순간적으로 뽑아내는 것은 쉬운 일이 아닙니다. Oracle에서는 이 문제를 undo log를 이용해 해결하고 있지만, 이 방식을 사용하면 데이터 전송이 모두 완료될 때까지 undo log를 유지해야 한다는 또 다른 과제가 발생합니다. 또한 잦은 DML 수행 때문에 undo log 영역을 모두 사용하면 데이터를 전송하고 있던 세션이 강제로 종료돼 버립니다. 물론 MongoDB에서는 Oracle과 같은 방식을 사용하는 것조차 쉽지 않습니다.
HBase를 사용한 1차 개선
LINE 쇼핑에서는 데이터 히스토리를 관리하기 위해 HBase를 사용하고 있습니다. HBase는 칼럼형 데이터베이스입니다. 변경된 데이터만 칼럼 단위로 저장해 저장 공간 사용을 최소화할 수 있으며, Hadoop 내 HDFS로 기록하기 때문에 저장 용량에 대한 부담도 덜어낼 수 있습니다. 이런 특징들 때문에 보조 데이터베이스로 사용하고 있으며, 최종 데이터는 주 데이터베이스(MongoDB)의 데이터와 동일하게 유지하고 있습니다. 서비스에 직접 사용하고 있는 데이터베이스가 아니라서 부하에 대한 부담도 덜해 ETL을 실행할 데이터베이스로 사용할 수 있습니다.
LINE 쇼핑에서는 대용량 데이터를 조회하기 위해 Hive를 사용하고 있습니다. Hive에서 쿼리를 실행하면 내부적으로 여러 과정을 거칩니다. 쿼리를 분석해서 최적의 실행 형태로 구성해 리소스를 Mapper와 Reducer로 구분해 할당하는데 데이터를 분산해서 처리하기 때문에 대용량 데이터도 빠르게 처리할 수 있습니다. 데이터베이스에 직접 질의하는 것에 비해 부하가 덜하고 빠르게 처리할 수 있다는 장점 때문에 Hive를 사용하고 있습니다.
Hive는 HBase에 연결할 수 있는 기능을 지원합니다. 이 기능을 사용하면 손쉽게 데이터를 조회할 수 있지만, 성능 제약이 존재합니다. 사용할 데이터가 HBase로 기록돼 있다면 사용 가능한 Mapper의 수는 HBase RegionServer 수만큼으로 제한되기 때문입니다. 적은 양의 데이터를 사용한다면 문제 없겠지만 LINE 쇼핑의 데이터는 수억 건이고 칼럼도 많습니다. 수백 개의 Mapper를 사용하더라도 최소 10분의 시간이 소요되는데 제한된 개수의 RegionServer만 사용해야 한다면 얼마나 오래 걸릴 지 감이 오시나요? RegionServer를 늘리면 속도를 개선할 수 있겠지만 서버를 증설하는 데 많은 비용이 들어갈 뿐 아니라 가격 대비 효율도 좋지 않습니다. 또한 인증에 따른 제약도 존재합니다. HBase가 사용하고 있는 Hadoop 클러스터와 전사 공용 Hadoop 클러스터는 분리돼 있습니다. 두 Hadoop 클러스터는 서로 인증 체계가 다르고 크로스 렐름(cross-realm)이 지원되지 않습니다. 따라서 성능 제약이 아니더라도 사용할 수 없었을 것입니다.
이와 같은 제약 사항만 본다면 HBase를 사용할 수 없겠지만, 대안으로 HBase에서 지원하는 스냅샷(snapshot) 기능을 생각해 볼 수 있었습니다. 스냅샷은 일종의 태그(tag)처럼 작동합니다. HBase는 각 칼럼의 과거 버전 데이터를 보유하고 있기 때문에 특정 시점에 마킹을 하는 것만으로 읽기 일관성을 유지하면서 스냅샷을 얻을 수 있습니다. 따라서 스냅샷을 사용하면 초기화된 HBase에서도 마킹한 시점까지의 데이터를 완벽히 복구할 수 있습니다. 게다가 스냅샷 생성 명령어는 매우 빠르게 수행되며 서버 내 추가 공간이 필요하지 않다는 장점도 있습니다. 스냅샷 데이터를 활용하면 MongoDB와 HBase에 부하를 주지 않고 ETL을 진행할 수 있습니다.
1차 개선 구현 방법
HBase를 사용하기 위해 여러 가지 방법을 시도해 보며 시행착오를 겪었습니다.
1. HBase 스냅샷 직접 읽기
Hive에는 HBase 스냅샷을 직접 읽어 사용하는 기능이 있습니다. 예를 들어 아래와 같이 DDL(Data Definition Language)을 표현할 수 있습니다.
CREATE EXTERNAL TABLE test3(id string, a string, b string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf:a,cf:b")
TBLPROPERTIES ("hbase.table.name"="test", "hive.hbase.snapshot.name"="testSnapshot-111113");
SET hbase.rootdir=/test;
SET hive.hbase.snapshot.name=testSnapshot-111113;하지만 설정을 변경하며 여러 번 시도해 보았으나 에러가 발생하거나 데이터가 정상적으로 출력되지 않았습니다. HBase와 연결할 수 없다는 메시지가 출력된 것으로 보아 같은 클러스터 내에 HBase가 없어서 발생한 것으로 추정됩니다. 추가 설정을 통해 원격 클러스터에 연결할 수 있겠지만 앞서 말씀드린 것처럼 인증 문제 때문에 이 방법은 사용할 수 없었습니다.
2. SERDE 설정
Hive에서 사용하고자 하는 데이터 포맷이 다양하기 때문에 Hive에서는 사용자가 SERDE(serializer, deserializer)를 지정할 수 있게 지원합니다. SERDE를 지정해서 사용하는 데이터 포맷에 맞는 직렬화와 역직렬화 방법을 지정할 수 있습니다. 또한 입력 형식과 출력 형식도 지정할 수 있기 때문에 HBase 스냅샷에 맞는 입력 형식과 출력 형식을 지정해 스냅샷 데이터를 읽을 수 있다면 별도 처리 없이 Hive에서 바로 사용할 수 있을 것이라고 판단했습니다.
CREATE EXTERNAL TABLE test(key string, value1 string, value2 string, value3 string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf:a,cf:b,cf:c", "hbase.table.default.storage.type"="binary")
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.hbase.HiveHBaseTableSnapshotInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION '/test'
TBLPROPERTIES ("hive.hbase.snapshot.name"="testSnapshot-111111", "hbase.table.name"="test", "hive.hbase.snapshot.restoredir"="/tmp");
SET hbase.rootdir=/test;
SET hive.hbase.snapshot.name=testSnapshot-111111;위 쿼리를 해석해 보면 아래와 같습니다.
- ROW FORMAT의 SERDE는 org.apache.hadoop.hive.hbase.HBaseSerDe를 사용
- SERDE의 특성으로 ("hbase.columns.mapping"=":key,cf:a,cf:b,cf:c", "hbase.table.default.storage.type"="binary")를 사용
- 매핑 정보를 의미
- INPUTFORMAT은 'org.apache.hadoop.hive.hbase.HiveHBaseTableSnapshotInputFormat'를 사용
- OUTPUTFORMAT은 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'를 사용
- 저장된 LOCATION은 '/test'
- 테이블 특성으로 ("hive.hbase.snapshot.name"="testSnapshot-111111", "hbase.table.name"="test", "hive.hbase.snapshot.restoredir"="/tmp")를 사용
- 스냅샷 테이블 정보를 의미
하지만 오랜 시간 설정을 바꿔가며 많은 시도를 해 보았지만 텅 빈 데이터가 조회되거나, 역직렬화가 되지 않은 데이터가 출력됐습니다. 비슷한 사례를 찾아봤지만 발견할 수 없었고, 성과 없이 시간이 지체돼 다른 방안으로 진행했습니다.
3. 스냅샷 변환
이 방법은 그동안 시도했던 방법과는 다르게 Hive에서 스냅샷 데이터를 직접 읽지 않고 MapReduce나 Spark 같은 프레임워크를 사용해 애플리케이션을 만들어 처리하는 방법입니다. 애플리케이션에서 비즈니스 로직에 맞게 변환한 뒤 Hive가 읽을 수 있는 데이터 형태로 남깁니다.
개선 방법 정리 요약
Hive와 HBase를 함께 쓸 수 있는 방법을 모두 정리해 봤습니다.

1번 방법은 인증 제약이 없었다면 사용 가능했겠지만, 성능이 좋지 않아 쿼리를 실행할 때마다 오랜 시간이 걸렸을 것입니다. 2번은 적용하려고 시도했지만 적용할 수 없었습니다. 3번은 별도 애플리케이션을 만들어 관리해야 하는 단점이 있으나, 필요한 만큼 Mapper를 할당해 성능을 높일 수 있다는 장점이 있었습니다. 이에 따라 3번으로 진행했습니다.
1차 개선 아키텍처
HBase에서 사용 중인 Hadoop 클러스터와 사내 공용 Hadoop 클러스터의 인증 체계가 다르다고 앞서 말씀드렸습니다. 이에 따라 클러스터 간에 데이터를 직접 전송할 수 없어 Object Storage인 S3를 중간 저장소로 사용했습니다. HBase Hadoop 클러스터에서 S3로 HBase 스냅샷 전송이 완료되면, Jenkins 잡 트리거를 호출해서 ETL을 진행합니다. S3에 저장된 스냅샷을 사내 공용 Hadoop 클러스터로 전송한 후 MapReduce를 구동해 Hive DDL에 맞는 스키마로 변환합니다. 변환이 완료되면 사용자는 최신 데이터를 조회할 수 있습니다.
위 설명을 그림으로 표현하면 아래와 같습니다.
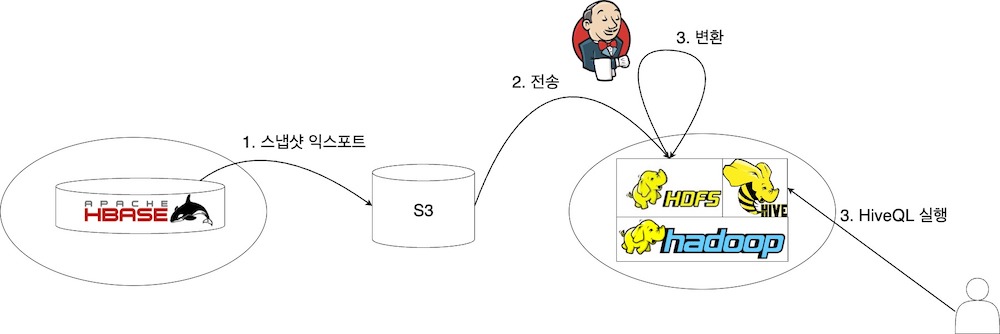
1차 개선 결과 및 문제점 분석
ETL 프로세스를 개선해 MongoDB의 부하를 줄일 수 있었지만 예상치 못한 곳에서 문제가 발생했습니다. LINE 쇼핑의 경우 상품 정보 데이터가 많다 보니 자연스레 데이터 용량(2.5TB ~ 3TB)이 클 수밖에 없었고, 이에 따라 전송 시간이 증가했습니다. 전송에 소요되는 시간을 줄이기 위해서 대역폭(bandwidth)를 높이는 방법이 있었으나 이는 S3를 사용하고 있는 타 서비스에 악영향을 미칠 수 있었습니다. 다행히도 이를 사전에 감지하고 대역폭에 제한을 둬 문제가 발생하지는 않았으나 이 때문에 시간을 단축했던 효과가 사라지면서 개선 효과가 반감됐습니다. 오히려 HBase를 장기간 운영하면서 발생한 데이터가 축적되면서 시간이 늘어날 수 있었습니다. 이를 표로 정리해 보면 아래와 같습니다.
| ETL | MongoDB 풀 스캔 | HBase 스냅샷 익스포트 |
|---|---|---|
| 장점 |
|
|
| 단점 |
|
|
Kafka를 사용한 2차 개선
ETL로 생성된 데이터의 갱신 주기를 단축할수록 사용자에게 제공하는 서비스의 품질을 높이기가 쉬워집니다. 따라서 갱신 주기를 줄이는 것은 LINE 쇼핑 사용자를 위해서 포기할 수 없는 과제입니다. 그런데 HBase 스냅샷을 사용한 ETL은 S3를 중간 저장소로 사용하기 때문에 시간을 더 단축하기 어려웠습니다. 이에 다른 데이터 소스를 사용하는 것을 고려할 수밖에 없었습니다.
일정 규모 이상의 데이터는 고성능 컴퓨팅 자원을 사용해 배치로 처리함으로써 시간 이득을 얻을 수 있습니다. 하지만 데이터의 규모 때문에 그 어떤 좋은 프레임워크를 사용하더라도 단일 배치 처리로는 일정 시간 이상 단축할 수 없습니다. 이때 처리해야 할 데이터를 나눌 수 있다면 이야기가 달라집니다. 데이터를 나눌 수 있다면 큰 배치 작업을 여러 개의 작은 배치 작업으로 나눠 분산 처리할 수 있으며, 더 작은 배치 작업으로 나눠 처리할 수 있다면 스트림까지 생각해 볼 수 있습니다.
ETL만을 위해 스트림 환경을 구축한다는 것은 어려울 수 있겠지만, 다행히 LINE 쇼핑은 이미 이벤트 드리븐(event-driven) 아키텍처 플랫폼으로 구성돼 있었습니다. 따라서 판매자가 변경한 상품 정보를 실시간으로 받아 업데이트할 수 있었습니다. 또한 상품 정보는 MongoDB에 저장한 후 Kafka Source Connector를 통해 변경된 내용에 따라 각각 다른 데이터 처리 과정을 거친 후 다시 저장하기 때문에 ETL을 위한 Kafka Consumer가 있다면 실시간으로 Hive에 변경된 상품 정보를 제공할 수 있습니다.
또한 기존 MongoDB 풀 스캔이나 HBase 스냅샷을 이용한 방식으로는 변경이 없는 데이터도 매번 복사해야 했습니다. 수 GB 정도의 데이터라면 그렇게 해도 큰 문제가 되지 않을 수 있겠지만 데이터가 수백 GB에 이른다면 이야기가 달라집니다. 이와 같은 관점에서도 변경이 발생한 데이터만 전송받아 기록하는 게 보다 효율적일 것입니다.
2차 개선 구현 방법
Hive 트랜잭션
ACID는 데이터베이스 트랜잭션의 네 가지 대표 특성을 뜻합니다. Hive는 0.13 버전 이후 완전한 ACID를 지원하면서 트랜잭션을 사용할 수 있게 되었습니다.
- Atomicity
- Consistency
- Isolation
- Durability
HDFS는 파일 변경(update, delete)을 지원하지 않습니다. 또한 사용자가 읽고 있는 파일에 추가(append)하더라도 읽기 일관성(read consistency)을 제공하지 않습니다. 이런 특성 때문에 Hive에서도 다른 데이터 웨어하우스 툴과 같은 일반적인 접근 방식으로 구현됐습니다. 테이블과 파티션은 베이스 파일(base file)로 분류하고 저장합니다. 이후에 생성되는 새로운 레코드와 UPDATE, DELETE는 .stage라는 디렉터리에서 델타 파일(delta file)로 분류하고 저장하며, 테이블과 파티션을 변경할 수 있는 각 트랜잭션도 델타 파일에 기록됩니다. 사용자가 읽기(read)를 시도할 때에는 베이스 파일과 델타 파일을 머지한 후 UPDATE와 DELETE를 적용한 뒤 보여줍니다. 생성된 델타 파일의 개수가 많아지거나 파일 크기가 커지면 백그라운드 작업을 통해 주기적으로 통합합니다.
트랜잭션을 사용할 수 있으면 아래 기능들을 사용할 수 있습니다.
- 스트리밍 API
- SQL 머지
- SQL UPDATE, SQL DELETE
하지만 사내 공용 Hadoop 클러스터의 사용량이 이미 많은 상태인데 트랜잭션 기능을 활성화하면 더 많은 부하가 발생하기 때문에 이 방법은 사용할 수 없었습니다.
테이블 데이터 다시 쓰기
UPDATE와 DELETE 쿼리는 모두 트랜잭션이 지원돼야 사용 가능한 기능입니다. 이 기능들을 사용할 수 없기에 이를 제외한 INSERT와 OVERWRITE, UNION 등의 기본 쿼리를 사용해 기존 테이블과 UPDATE, DELETE 데이터를 병합하는 방법을 시도했습니다. Hive 트랜잭션 기능 설명을 읽어보면 단순합니다.
- 기본 데이터는 베이스 파일로 관리
- 변경 사항이 기록된 데이터는 델타 파일로 관리
- 사용자가 읽기를 시도할 경우 베이스 파일과 델타 파일을 합친 결과를 보여줌
- 주기적으로 델타 파일 통합
위 네 가지 기능을 Hive 시스템에서 지원하기 때문에 이를 이용해 실시간 변경 사항을 반영할 수 있습니다. 이는 네 가지 기능을 구현한다면 Hive를 통해 실시간으로 데이터를 조회할 수 있다는 말이기도 합니다. 다른 대안이 없으므로 이 방법을 사용해 구현했습니다. 그럼 구현 내용을 상세하게 살펴보겠습니다.
2차 개선 상세 개념
쿼리를 사용해 구현할 때 고려해야 할 점이 몇 가지 있습니다. 첫 번째는 발생하는 이벤트의 종류입니다. 예를 들면 판매자가 새로운 상품을 등록 또는 삭제하거나, 판매자가 상품의 가격을 변경하거나, 데이터 가공으로 인한 변경이 발생하는 등의 이벤트가 있습니다. 두 번째는 ID 중복이 발생할 수 있다는 것입니다. 동일한 ID인 이벤트가 시차 없이 여러 개 발생할 수 있습니다. 세 번째는 시간입니다. 짧은 시간 동안 수많은 이벤트가 발생할 수 있는데 간혹 타임스탬프의 밀리초(ms) 단위까지도 같은 경우가 발생합니다.
이 중 첫 번째 사항은 큰 문제가 되지 않지만, 두 번째와 세 번째 사항은 골치 아픈 문제입니다. 간단하게 정리하면 '중복 제거'와 '최신순 정렬', 이 두 가지를 잘 할 수 있는지에 따라 실시간 업데이트를 구현할 수 있는지 없는지가 판가름 납니다. 이 두 가지 문제를 어떤 방법으로 해결해 나갔는지 순서대로 설명하겠습니다.
UNION 연산
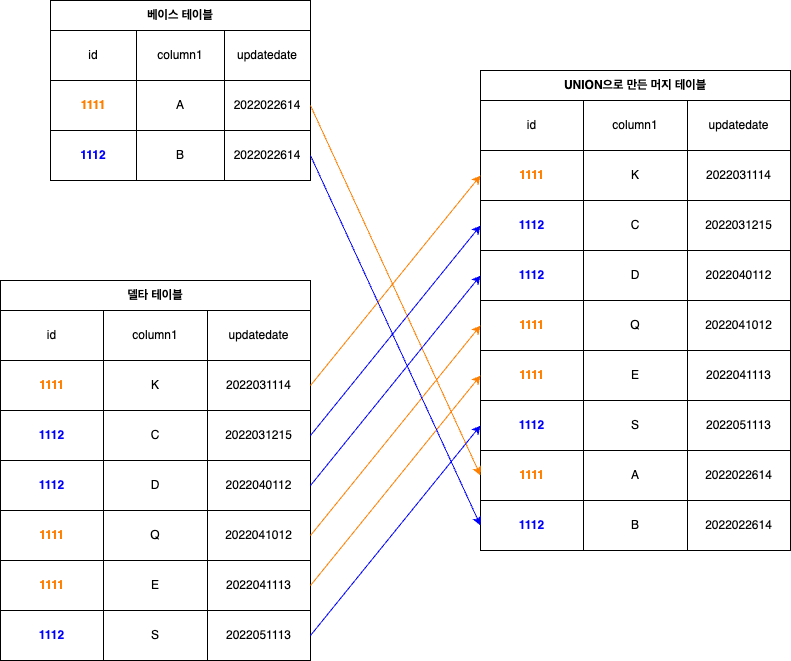
다이어그램의 각 테이블을 설명하겠습니다.
- 베이스 테이블: 가장 최근에 ETL된 데이터를 포함하고 있는 테이블이며, 특정 시점에 생성된 스냅샷 데이터가 담겨 있습니다.
- 델타 테이블: 업데이트 이벤트가 담겨 있는 테이블입니다. 베이스 테이블에 업데이트해야 할 'full document(모든 칼럼 포함)'를 모아둔 테이블을 의미합니다.
- UNION으로 만든 머지 테이블: 베이스 테이블과 델타 테이블을 UNION해 만든 결과물입니다(업데이트가 정상적으로 완료되면 새로운 베이스 테이블이 됩니다).
어떻게 델타 테이블을 사용해서 베이스 테이블을 업데이트할 수 있을까요? 다양한 방법이 있겠지만 ID로 그루핑(grouping)할 수 있다면 고려해야 할 범위를 줄일 수 있습니다. 그루핑하기 위해서는 다른 두 개의 테이블을 하나로 합칠 필요가 있습니다. 다른 데이터베이스와 마찬가지로 Hive에서도 UNION 연산을 제공합니다. 두 테이블의 스키마가 동일해야 한다는 조건이 있지만, 조건만 맞추면 손쉽게 하나의 테이블로 만들 수 있습니다.
최신순 정렬
그루핑할 수 있는 조건을 충족했습니다. 이제 그루핑 연산이 완료됐다고 가정하고 다음 단계를 생각해 보겠습니다. 동일한 ID끼리 묶여 있는 그룹의 데이터를 사용해서 업데이트하면 되는데 이를 단순하게 생각하면 아래 그림처럼 가장 최신 데이터를 사용하면 업데이트할 수 있습니다.
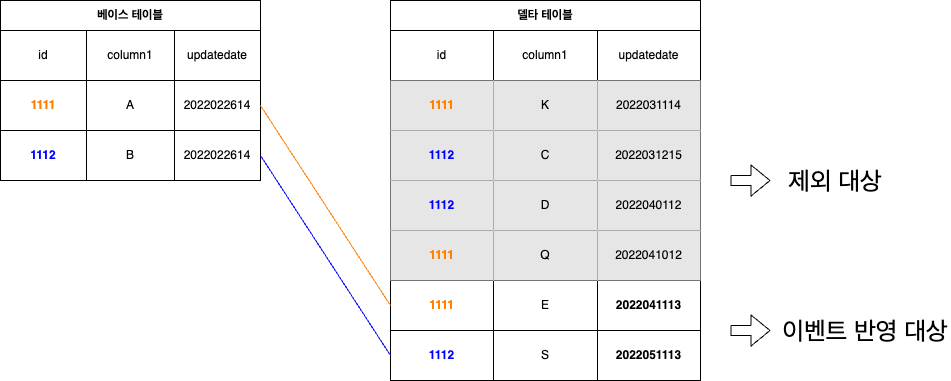
하지만 앞서 말씀드렸듯 LINE 쇼핑 데이터는 수많은 칼럼을 사용하고 있어서 위 그림처럼 쉽게 해결하긴 어렵습니다. 이런 상황에서는 델타 테이블의 칼럼을 어떻게 구성할 것인지 고민해야 하는데 단순하게 두 가지 경우로 나눠 생각해 볼 수 있습니다.
첫 번째는 업데이트된 칼럼만 데이터로 제공하는 경우입니다. MongoDB에서 생성되는 oplog는 실제로 변경된 데이터에 대한 정보를 포함하고 있기 때문에, 사용하기 좋은 형태라고 볼 수 있습니다. 위 그림에는 Column1만 있었지만 Column1부터 시작해 ColumnN까지 있다고 가정해 봅시다. 그때 데이터가 아래와 같이 존재한다면 어떤 행(row)을 사용해야 할까요?
| row_number | ID | Column1 | Column4 | ... | ColumnN-3 | ... | ColumnN |
|---|---|---|---|---|---|---|---|
| 1 | 1111 | "K" | "chicken" | ||||
| 2 | 1111 | "kukudas" | "document" |
당연히 모든 행을 사용해야 합니다. 각 행이 가진 칼럼이 중복되지 않기 때문에 칼럼을 모아 하나의 행으로 만들어야 합니다. 그러면 아래의 형태가 됩니다.
| ID | Column1 | Column4 | ... | ColumnN-3 | ... | ColumnN |
|---|---|---|---|---|---|---|
| 1111 | "K" | "kukudas" | "chicken" | "document" |
이와 같은 시나리오의 경우는 처리하는 게 그리 어렵지 않겠지만, 만약 다른 행에서 중복되는 칼럼의 데이터가 변경된다면 문제가 복잡해집니다.
| row _number |
ID | Column1 | Column4 | ... | ColumnN-3 | ... | ColumnN | ColumnN+1 | updatedate |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1111 | "K" | "chicken" | "cookie" | "20220522" | ||||
| 2 | 1111 | "kukudas" | "document" | "fruit" | "20220523" |
위 예시에서는 ColumnN+1 칼럼과 updatedate 칼럼이 모두 변경됐습니다. 이런 상황에서는 가장 최근에 업데이트된 값인 "fruit"를 사용해야 합니다. 단순한 예시이지만 중복된 칼럼 하나가 생기면서 조건이 하나 추가됐고, 실제 상황에서는 중복 칼럼이 여러 개일 수 있습니다. 그 상황에 모두 대응하려면 수없이 많은 조건이 생기게 됩니다. 이는 만들기도 쉽지 않을뿐더러 유지 보수도 어렵게 만듭니다. 이에 이 방법은 더 이상 고려하지 않았습니다.
두 번째는 업데이트된 칼럼뿐 아니라, 테이블 스키마에 포함된 모든 칼럼을 제공하는 경우입니다. 이를 위해서는 별도의 질의를 수행해 데이터를 가져와야 하지만, 모든 칼럼을 한 번에 제공하기 때문에 첫 번째 방법보다 상당히 쉽게 구현할 수 있습니다. ID가 동일한 행이 다수라고 하더라도 모든 칼럼 데이터가 있기 때문에 가장 최근에 업데이트된 행을 사용하면 정합성 문제가 발생하지 않습니다. 이와 같은 이유로 두 번째 방법으로 진행했습니다.
다음으로 최신순으로 정렬하는 방법을 고민해야 합니다. GROUP BY 연산을 사용한다면 최신순 정렬을 손쉽게 진행할 수 있습니다. 하지만 앞서 동일한 ID로 그루핑하는 것을 전제로 진행했는데 최신순 정렬까지 사용하면 GROUP BY에 사용하는 칼럼이 두 개가 됩니다. 이를 한 단계 더 나아가 생각해 보겠습니다. GROUP BY 연산을 사용하면 GROUP BY에 사용된 칼럼만 SELECT할 수 있습니다. ID별로 가장 최신의 updatedate를 가진 행을 추출하기 위해 GROUP BY를 사용했지만, 그 외 칼럼들도 필요한 상황입니다. 그런데 모든 칼럼에 대해서 GROUP BY를 적용하기에는 불필요할 정도로 과한 연산이 필요합니다. 다른 방법으로 ID와 updatedate를 사용해 베이스 테이블과 델타 테이블을 조인하는 것을 고려할 수 있지만 효율적이진 않다고 판단했습니다.
사면초가인 상황이었지만 다행히 Hive에서 제공하는 분석 함수(analytics functions) 중 하나인 row_number 함수와 over clause를 사용해 손쉽게 해결할 수 있었습니다. 이를 다이어그램으로 표현하면 아래와 같습니다.
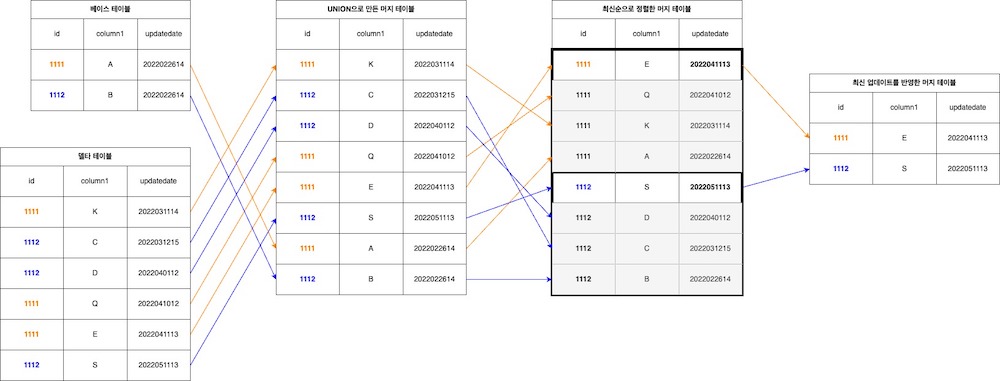
위 그림을 코드로 표현하면 아래와 같습니다.
SELECT *
FROM ( SELECT *,
row_number() over (partition by id order by updatedate desc, ord desc) as row_num
FROM UNION_TABLE
) a
WHERE a.row_num = 1위 코드의 row_number() 함수 부분을 살펴보겠습니다. 행을 ID 기준으로 파티셔닝한 뒤 ORDER BY 구문을 이용해 updatedate 내림차순으로 정렬합니다. 정렬된 순서대로 row_num 값이 부여되기 때문에 첫 번째 행의 updatedate가 최신입니다. ID별로 파티셔닝하기 때문에 자연스럽게 중복 제거 효과도 얻습니다.
간혹 타임스탬프의 ms까지 동일한 경우가 발생할 수도 있습니다. 이와 같은 상황에서는 의도한 대로 작동하지 않는데요. 다행히 ord(타임스탬프가 동일한 행들의 유입 순서 일련번호)라는 값을 사용할 수 있어서 가장 최근 값을 골라내기 위해 ord를 추가 정렬 기준으로 사용했습니다.
2차 개선 상세 구현
이와 같이 2차 개선 가능 여부를 결정할 주요 기능들을 살펴봤고 다행히 가능하다는 것을 확인했습니다. 이제 정규 작업으로 만들기 위해 프로세스를 어떻게 구성할지, 데이터는 어떻게 만들지 고민해야 합니다.
데이터 흐름
앞에서 델타 테이블의 행을 어떻게 구성할지 약식으로 설명하면서 모든 칼럼의 데이터를 만들기 위해서는 데이터베이스에서 조회해야 한다고 말씀드렸습니다. 테이블 스키마에 맞는 데이터 변환이 필요해서 별도 Consumer를 사용하고 있던 중이라 Consumer에서 데이터베이스 질의를 하려고 했습니다만, 최신 버전의 Connector가 MongoDB의 ChangeStream 기능을 사용할 수 있도록 업데이트되면서 Connector에서 full document를 만들 수 있다는 사실을 알게 됐습니다. 이 때문에 데이터베이스에 질의하는 역할을 어디서 맡아서 진행하는 게 좋을지 고민하게 됐고, 아래와 같은 세 가지 방안이 제시됐습니다.
참고. 사내 HDFS 버전과 호환되는 Confluent HDFS3 Sink Connector는 ORC 포맷을 지원하지 않고 라이선스 문제가 있어서 검토 대상에서 제외했습니다.
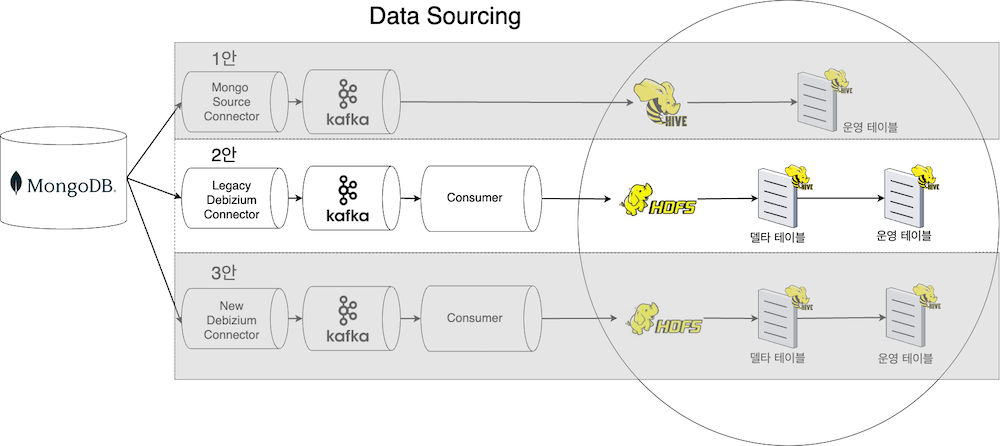
1번 안은 Mongo에서 공식 지원하는 Source Connector를 사용하며, Consumer와 HDFS를 읽는 용도로 사용할 테이블을 만들지 않는 게 핵심 아이디어입니다. MongoDB Source Connector에서 ChangeStream 기능을 사용해 DB를 조회한 뒤 full document 데이터를 Kafka에 전송하며, Hive에서는 full document가 담긴 Kafka topic을 외부 테이블(델타 테이블)로 정의한 뒤, 조회해 사용하는 방안입니다.
| 장점 | 단점 |
|---|---|
|
|
2번 안은 1번 안과 유사합니다. 하지만 운영하고 있던 레거시 Debizium Connector에는 ChangeStream을 지원하지 않아 full document를 만들 수 없습니다. 따라서 Consumer에서 MongoDB을 조회해 full document 데이터를 만듭니다. 단, 비지니스 로직을 포함할 수 있기에 기존 테이블 스키마와 동일하게 유지합니다. Consumer는 HDFS에 기록할 때는 기록할 시점을 기준으로 파티션을 지정해 기록합니다. 이렇게 생성되는 것이 바로 델타 테이블입니다.
| 장점 | 단점 |
|---|---|
| 비즈니스 로직을 포함할 수 있어서 기존에 사용하던 스키마를 유지할 수 있다. | HDFS로 쓸(write) 때까지 지연이 있을 수 있다. |
3번 안은 2번 안과는 다르게 Debizium Connector 최신 버전을 사용합니다. Connector에서 생성된 데이터 형식을 유지할 수 있다는 장점이 있고, ChangeStream 기능을 지원해 full document를 만들 수 있습니다. 또한 Consumer에서 DB 조회 기능을 제거할 수 있고, Connector에서 이를 대신할 수 있습니다. 타 스트림 애플리케이션에서 DB 조회 기능을 제거할 수 있게 만들어 DB 부하를 줄일 수 있습니다.
검토할 당시에는 1번 안과 2번 안만 존재했습니다. 1번 안이 매력적이긴 했지만 테스트 당시 원인을 파악할 수 없는 급작스러운 부하가 발생해 2번 안으로 데이터를 제공하도록 구현했습니다. 나중에 추가로 설명하겠지만 3번 안으로 개선하는 방안을 검토하고 있습니다.
아키텍처
요리로 비유하자면 재료가 준비됐으니 이제 준비한 재료를 어떻게 요리해 나갈지 정해야 하는 단계입니다. Hive에서 테이블을 UPDATE하기 위해 필요한 기능들을 베이스 테이블과 델타 테이블을 예로 설명했습니다. 데이터 소싱으로 델타 테이블 데이터는 준비했지만, 아직 베이스 테이블은 준비하지 않았습니다. 베이스 테이블을 만들어 내기 위한 테이블 생성 단계와, 델타 테이블과 베이스 테이블을 사용해 업데이트를 수행하는 단계가 필요합니다. 이 단계들을 어떻게 진행했는지 설명하겠습니다.
- CREATE 테이블: 데이터 정합성 문제로 테이블 재생성이 필요한 상황 또는 베이스 테이블이 필요한 상황에서 진행하는 단계입니다. HBase 스냅샷으로 생성한 테이블을 사용해 베이스 테이블과 상시 테이블을 만듭니다.
- UPDATE 테이블: 매시간마다 트리거되며 HDFS에 쓴 데이터를 사용해 테이블을 UPDATE하는 단계입니다. 상시 테이블과 한 시간 전의 델타 테이블 파티션을 사용해 업데이트하고 머지합니다. 정상적으로 완료된다면 베이스 테이블의 파티션으로 기록하고 최신으로 업데이트된 테이블을 뷰로 제공합니다.
좀 더 쉽게 이해할 수 있도록 위 두 단계를 그림으로 표현하면 아래와 같습니다.
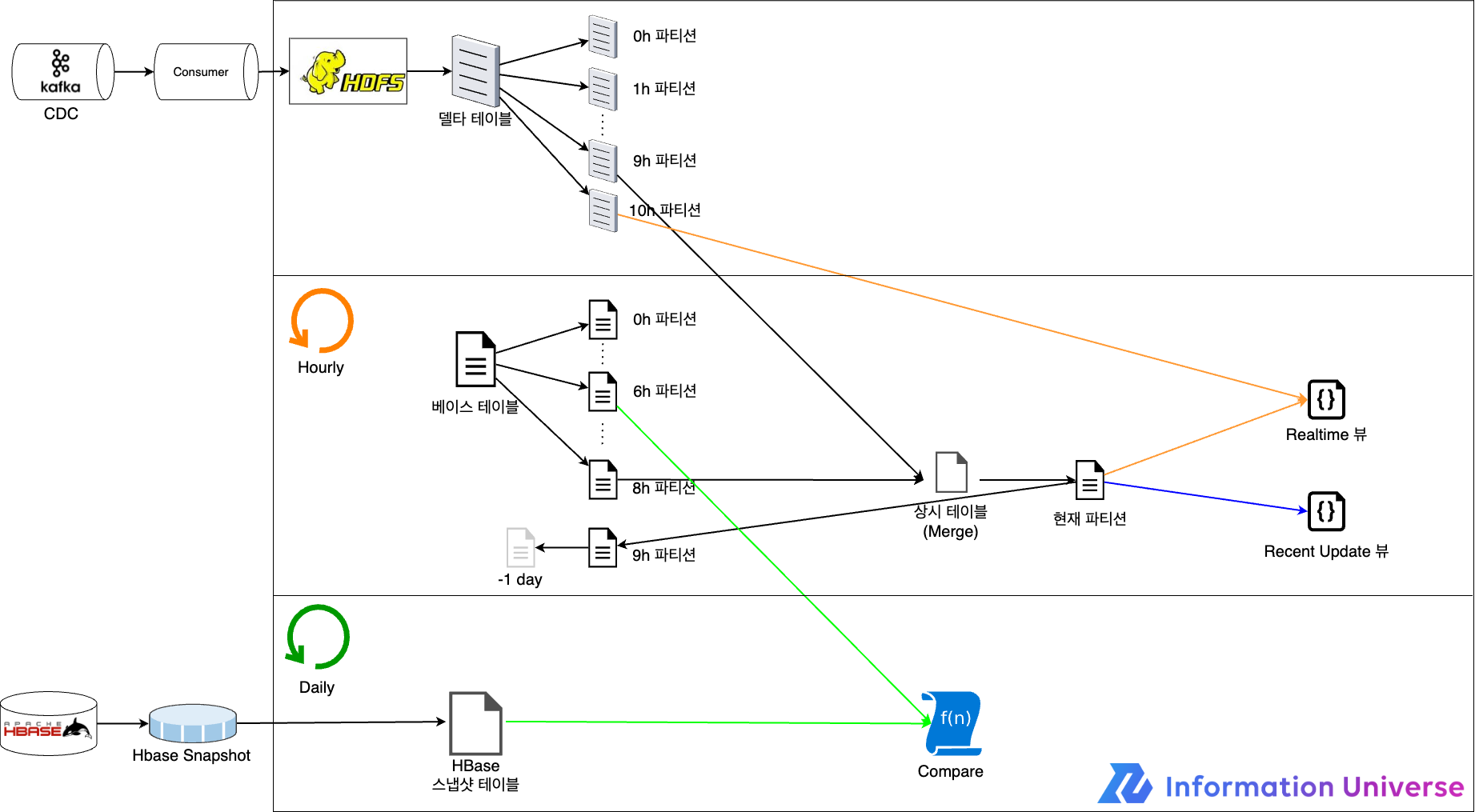
각 테이블에 대해 추가 설명하겠습니다.
| 테이블 명 | 설명 |
|---|---|
| 델타 테이블 | UPDATE, DELETE, CREATE가 발생한 MongoDB 레코드를 저장하고 있는 테이블입니다. Consumer가 MongoDB에 조회해 full document(모든 칼럼 포함) 형태로 레코드를 만든 뒤 HDFS로 기록합니다. 테이블은 시간 단위(yyyyMMddHH)로 파티션을 나눠 관리하며 모든 레코드는 HDFS로 쓰는 시점에 해당하는 파티션에 기록합니다. 예를 들어 2022052010 파티션에는 '2022.05.20 10:00:00.000 ~ 2022.05.20 10:59:59.999'에 쓴 레코드가 있습니다. |
| 상시 테이블 | 업데이트하기 위해 사용하는 테이블로, 항상 가장 최신의 데이터(실시간 아님)가 있습니다. 델타 테이블과 베이스 테이블을 머지한 뒤 상시 테이블에 덮어씁니다. 예를 들어 현재 시간이 '2022.05.20 10:21'이라고 한다면 '과거 ~ 2022.05.20 08:59:59.999' 시점까지의 업데이트가 반영된 운영 테이블과 '2022.05.20 09:00:00.000 ~ 2022.05.20 09:59:59.999'에 해당하는 업데이트 테이블과 머지를 시도합니다. 머지한 테이블은 상시 테이블에 덮어씁니다. |
| 베이스 테이블 | 매시간 업데이트된 운영 테이블 데이터를 시간 단위로 파티션(yyyyMMddHH)을 나누어 저장하고 있습니다. 예를 들어 현재 시간이 2022.05.20 10:21이라고 했을 때 운영 테이블이 정상적으로 업데이트됐다면 상시 테이블 데이터가 '2022052009' 파티션에 써집니다. |
| Realtime 뷰 | 실시간 업데이트가 반영된 데이터를 보기 위해 만든 뷰입니다. 베이스 테이블에서 가장 마지막에 쓴 파티션에 해당하는 데이터와 업데이트 테이블을 머지한 뒤 데이터를 제공하며, 조회를 수행할 때마다 머지가 진행됩니다. 예를 들어 현재 시간이 '2022.05.20 10:21'이라고 한다면 스냅샷 테이블에서 '과거 ~ 2022.05.20 09:59:59.999' 시점까지의 업데이트가 반영된 파티션(2022052009)과 업데이트 테이블에서 '2022.05.20 10:00:00.000'부터 쓰고 있는 파티션(2022052010)을 머지한 뒤 데이터를 제공합니다. |
| Recent Update 뷰 | 스냅샷 테이블에서 가장 최근에 쓴(write) 파티션을 사용해 데이터를 제공합니다. 예를 들어 현재 시간이 '2022.05.20 10:21'이라고 한다면 Recent Update 뷰는 스냅샷 테이블에서 '2022052009' 파티션을 사용합니다. |
별도 단계로 일일 검증도 진행합니다. 매일 HBase 스냅샷 데이터와 MongoDB 데이터를 비교해 데이터 정합성을 확인합니다.
개선 적용 결과 및 문제점 분석
데이터를 생성하는 프로세스부터 Hive 테이블을 업데이트하는 프로세스까지 모두 살펴봤습니다. 다행히 의도한 대로 Kafka에서 실시간으로 업데이트된 상품 정보를 받아 하나의 프로세스로 처리하는 데 문제가 없는 것을 확인했습니다. 이제 남은 일은 주기적으로 업데이트하는 잡을 수행하는 것입니다. 이때 업데이트 주기를 어떻게 설정할 것인지 선택해야 합니다.
Hive는 쿼리를 실행하면 Hadoop 클러스터의 리소스를 할당받은 뒤 작동하는데 사내 공용 Hadoop을 사용하다 보니 시간대 별로 사용량이 달랐습니다. 주간에는 느린 편이었고, 저녁이나 밤에는 빠른 편이었습니다. Hive도 이에 영향을 받아 테이블을 업데이트하는 데 소요되는 시간이 시간대에 따라 달라져서 빠를 때는 20분, 느릴 때는 40분까지 걸렸습니다. 이에 여유 있게 한 시간마다 업데이트를 진행했고, 설계한 대로 잘 작동했습니다. 새롭게 생성된 상품 정보, 변경된 상품 정보, 삭제된 상품 정보가 정상적으로 반영돼 정합성을 유지할 수 있었고, 테이블을 뷰 형태로 제공함으로써 아래 문제들을 해결할 수 있었습니다.
- 업데이트하고 있는 테이블 조회
- 복잡한 쿼리를 사용하지 않고 업데이트가 반영된 데이터 질의
하지만 새로운 칼럼이 추가되는 경우에 발생하는 생각하지 못했던 문제점도 발견했습니다. 새로운 칼럼이 추가돼 DDL을 변경하면, 해당 칼럼은 값을 가지고 있지 않기 때문에 NULL인 상태입니다. 이때 상품 정보가 변경돼 이벤트가 발생하면 새로운 칼럼 값이 추가되기 때문에 문제가 없지만, 만약 변경이 발생하지 않는다면 어떻게 될까요? 계속 NULL 값을 가진 상태를 유지하게 될 겁니다. 이는 데이터를 사용하는 입장에서는 큰 문제일 수밖에 없습니다. 이 문제를 다음과 같은 개선 작업으로 해결하고자 했습니다.
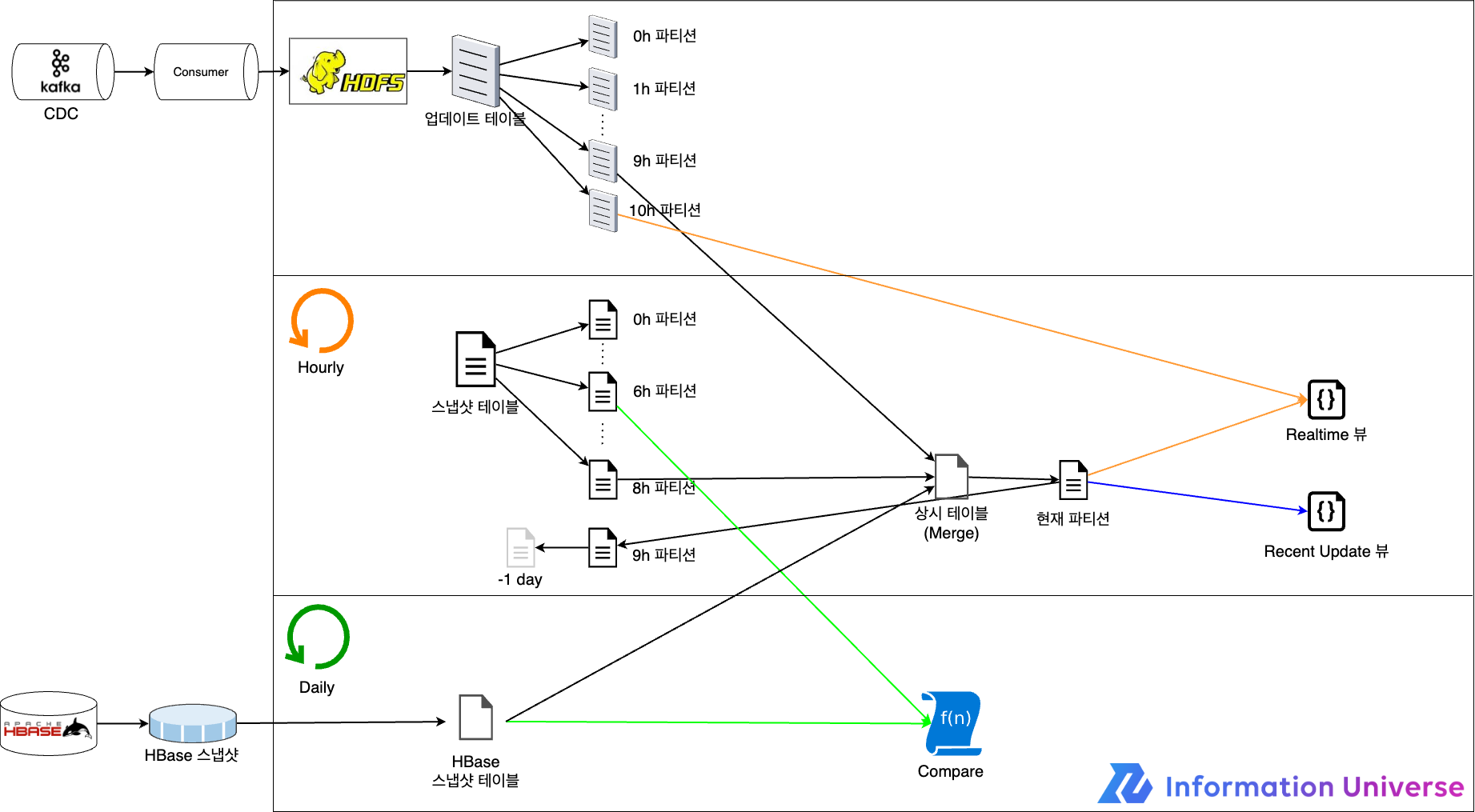
데이터 정제를 위한 3차 개선
업데이트가 발생하지 않은 행의 칼럼은 어떻게 보정해야 할까요? 단순하게 생각해 볼 수 있는 방법은 데이터베이스 조회입니다. 새로운 칼럼 값이 NULL인 행을 대상으로 주기적으로 조회를 수행해 업데이트하는 방법입니다. 하지만 이 방법을 사용하면 다시 데이터베이스에 많은 부하가 가해지면서 초기 목표였던 데이터베이스 부하 감소를 해결할 수 없었습니다. 또한 새로운 칼럼이 추가될 때마다 매번 변경해야 했습니다.
다른 방법으로는 전체 데이터를 덤프(dump)해 사용하는 방법이 있습니다. 덤프한 데이터에는 새로운 칼럼 값이 모두 포함돼 있어서 이를 사용하면 업데이트 이벤트가 발생하지 않은 행이더라도 새로운 칼럼 값을 채울 수 있습니다. 1차 개선 때 만들어 뒀던 테이블은 모든 칼럼을 덤프해서 만들었으니, 데이터 정제 용도로 활용해 볼 수 있었습니다. 그런데 스냅샷은 생성하고 전송, 변환하는 데 오랜 시간이 걸리기 때문에 상황에 따라 스냅샷 데이터를 보정 용도로 사용하기에 적합할 수도 있고, 적합하지 않을 수도 있습니다. 이에 여러 기준이 있겠지만 LINE 쇼핑에서는 아래 기준에 따라 HBase 스냅샷 테이블 데이터를 사용할지 말지 결정했습니다.
- updatedate가 더 최신인 쪽
- updatedate가 동일할 때는 시퀀스 값이 높은 쪽
- HBase 테이블의 시퀀스 값은 999, 스냅샷 테이블의 시퀀스 값은 1로 updatedate가 동일할 때는 무조건 HBase 선택
정제 과정이 포함된 흐름을 그림으로 표현하면 아래와 같습니다.
트러블 슈팅 - 놓친 업데이트 이벤트
데이터 흐름과 업데이트 원리, 업데이트 프로세스를 살펴보며 실시간으로 변경 정보를 받아와 매시간 업데이트를 반영하는 방법을 살펴봤습니다. 당연히 업데이트에 관한 내용이 압도적으로 많은 부분을 차지하고 있는데요. 정기적으로 검증하는 프로세스에서 데이터의 정합성이 유지되지 않는 문제가 발생했습니다.
발생한 문제
HDFS에 사용할 파일의 Replication 값을 기본 값인 3으로 설정하고 사용하고 있었습니다. 그런데 비정기적으로 DataNode 교체 또는 쓰기(write) 불가 에러 로그가 발생하면서 이 시점에 유입됐어야 할 데이터들이 사라졌고, 이 때문에 데이터의 정합성이 유지되지 않았습니다.
대처 방안 1 - Hadoop 설정 변경
Hadoop 클러스터는 NameNode와 DataNode로 구성됩니다. NameNode는 저장될 데이터에 대한 메타 데이터와 데이터가 저장된 DataNode에 대한 정보를 갖고 있습니다. DataNode는 HDFS에 저장되는 데이터를 갖고 있으며 Hadoop 클러스터에서 분배된 잡을 실행합니다. 이때 DataNode가 Hadoop 클러스터의 실제적인 두뇌 역할을 하다 보니, 갑자기 서버가 다운되는 것과 같은 문제가 발생했을 때 대처할 수 있는 방안이 필요합니다. 이에 Hadoop 클러스터에는 이런 상황에 대처하기 위한 교체 정책(REPLACEMENT POLICY)을 제공합니다.
이 정책을 DEFAULT로 사용하면서 Replication 값을 3으로 설정한 게 문제였습니다. 기본 설정에 따르면 DataNode 중 한 대만 문제가 발생해도 바로 교체 프로세스가 진행되면서 쓰기 락(write lock)이 걸립니다. 이에 Replication 값을 3에서 6으로 늘려서 빈번한 DataNode 교체와 쓰기 락을 방지했습니다. 이 방법이 데이터 누락에 대한 근본적인 해결 방안은 아니었지만, 복제본이 늘어나면서 데이터의 안정성을 확보할 수 있었습니다.
대처 방안 2 - 로직 개선
Kafka에서 데이터를 받아와 처리하는 과정에서 익셉션(exception)이 발생하면 오프셋(offset)을 되돌려 재처리할 수 있게끔 구현해 놓았습니다. 그럼에도 데이터 누락이 발생했다는 건 전송했다고 생각한 데이터가 실제로는 전송되지 않았다고 추론할 수 있습니다.
이에 첫 번째로 조치한 내용은 flush()를 hsync()로 변경한 것입니다. OutputStream을 직접 쓰는 불편함을 덜고 전송 효율도 높이기 위해 별도 Writer로 래핑(wrapping)해서 사용합니다. 이때 write()는 버퍼가 가득 차야 전송하는 반면 flush()를 사용하면 버퍼의 데이터를 바로 전송할 수 있기 때문에 flush()를 사용했습니다. 하지만 Hadoop에서는 flush()를 사용해도 DataNode의 저장소에 데이터가 저장됐다는 것이 보장되지 않습니다. Hadoop 클러스터에서 데이터를 읽어들일 수 있는 상태로 변경되는 것까지만 보장됩니다. 이 때문에 비용은 더 비싸지만 모든 레플리카의 저장소에 저장이 보장되는 hsync()를 사용했습니다.
두 번째로 조치한 내용은 버퍼가 없는 Writer로 변경한 것입니다. 편리하기 때문에 Writer 사용을 배제하기는 어렵지만, 효율성을 위해 Writer에 만든 버퍼 때문에 데이터가 누락된다는 의심이 가는 상황이었습니다. 게다가 DFSClient에서 사용하는 DFSOutputStream에는 통신을 위한 별도 버퍼가 존재하기 때문에 이중으로 버퍼를 유지하는 것은 비효율적이라고 판단해 버퍼가 없는 OutputStreamWriter로 변경했습니다.
위 두 조치를 시행한 후 더 이상 데이터 누락 현상이 발생하지 않았고 정합성을 유지할 수 있었습니다.
마치며
개선 작업으로 얻은 이점은 크게 두 가지입니다. 첫 번째는 대용량 데이터의 사용성이 증대된 것입니다.
그동안에는 여러 사용처에서 ETL이 완료될 시점을 공유 받아 후속 배치 작업을 실행하곤 했습니다. 이 때문에 간혹 Hadoop 지연이 발생하면 하루 전에 생성된 데이터를 사용해 버리는 문제가 발생했습니다.
하지만 일 주기, 시간 주기 또는 준실시간 주기로 업데이트된 테이블을 뷰로 제공할 수 있게 되면서 문제가 사라졌습니다. Hadoop 지연이 발생하더라도 비교적 최근 데이터를 제공할 수 있게 됐고, 시간 제약이 사라지면서 사용처가 원하는 시간에 대용량 데이터를 다루는 마이크로 배치를 많이 사용할 수 있게 됐습니다. 예를 들어 이전에는 통계 데이터를 하루 단위로 밖에 만들 수 없었지만 이제는 시간 단위로 만들 수 있게 된 것입니다.
두 번째는 이벤트 드리븐 아키텍처의 운영 및 유지 보수 비용이 감소한 것입니다.
판매자가 상품 데이터를 잘못 올리거나 유입된 상품 데이터를 잘못 정제해 문제가 발생할 수 있습니다. 이런 경우 디버깅하며 원인을 찾아야 하는데 LINE 쇼핑의 경우 상품 정보 데이터가 많다 보니 쉽지 않았습니다. Kafka에 존재하는 많은 메시지를 확인하는 것 자체도 어려운데 보유 기한도 짧아 문제가 발생한 지 며칠이 지나면 원인을 찾을 수 없었기 때문입니다. 이 문제를 해결하기 위해 KSQL과 Elasticsearch를 도입해 활용하고 있었지만 비용 문제로 활용도를 더 높이기는 어려웠습니다.
하지만 이제 Hive에 실시간 데이터를 입력하고 업데이트할 수 있게 되면서 고민거리가 해결됐습니다. SQL 문법을 사용할 수 있는 HiveQL로 손쉽게 상품 데이터를 찾을 수 있고, 상대적으로 비용이 저렴한 HDFS를 사용하면서 보유 기한도 늘릴 수 있습니다.
향후 계획
마지막으로 현재 계획하고 있는 두 가지 개선 방안을 소개하겠습니다.
먼저 첫 번째 개선 방안입니다. 개선 작업을 진행하면서 데이터베이스 부하가 줄어들긴 했지만 아직도 부하가 많은 상태입니다. LINE 쇼핑 플랫폼을 구축할 당시에 MongoDB 변경 내역(oplog)을 스트리밍할 수 있는 Debizium Source Connector를 사용했습니다. 이를 통해 oplog를 테일링(tailing)하며 업데이트 내용을 추적해 다른 애플리케이션에도 손쉽게 적용할 수 있었습니다.
하지만 행의 모든 칼럼을 사용해야 하는 애플리케이션의 경우 oplog만 사용할 수 없어서 데이터베이스를 조회하는 프로세스가 추가됐습니다. 이후 데이터베이스를 조회하는 애플리케이션이 많아지면서 부하가 점차 늘어났고, 현 상황에 이르렀습니다.
다행히 MongoDB에서 ChangeStream이라는 기능을 지원하기 시작하면서 상황이 변했습니다. Connector에서 ChangeStream 방식을 이용할 수 있게 됐고, 데이터베이스를 조회하는 프로세스도 추가할 수 있게 됐습니다. 이 기능을 사용하면 애플리케이션에서 데이터베이스를 조회하는 기능을 Connector에서 대신 수행함으로써 자연스레 부하를 줄일 수 있습니다. 이에 따라 현재 Connector로 전환하기 위한 검토를 진행하고 있으며, 성공적으로 전환하면 LINE 쇼핑을 더욱 안정적으로 운영할 수 있게 될 것으로 기대합니다.
두 번째 개선 방안입니다. 개선 작업으로 서비스에 사용할 데이터는 준비됐지만 개발 담당자들이 준비된 데이터를 사용하는 것이 쉽지 않습니다. Hive 클라이언트 환경을 구성하고, HDFS를 이해하고, 연동하는 방법을 파악하는 등 사용하기 위해서 알아야 할 것들이 많습니다.
이에 손쉽게 연동할 수 있도록 SQL을 입력 값으로 사용하는 마이크로 배치를 만드는 단계를 검토하고 있습니다. 이 단계까지 성공적으로 마무리한다면, LINE 쇼핑은 사용자들이 더 편리한 쇼핑 경험을 할 수 있게 될 것으로 기대합니다.