
저를 소개합니다
안녕하세요. LINE+에서 엔지니어로 일하고 있는 이지현입니다. 저는 현재 글로벌에서 일하고 있는 수많은 LINE 엔지니어들이 좀 더 효율적으로 업무를 수행할 수 있도록 여러 가지 공통 엔지니어링 인프라(Common Engineering Infrastructure)를 제공하고, 그와 관련된 이슈를 해결해 나가는 업무를 수행하고 있습니다.
세상에는 정말로 다양한 기술이 존재하고, 지금 이 시간에도 끊임없이 새로운 기술이 등장하고 있습니다. LINE 엔지니어에게 필요한 기술의 수준은 상당히 높기 때문에, 주어진 제약 사항을 만족하는 새로운 기술을 끊임없이 도입해야 하는 것이 저에게 주어진 커다란 미션 중 하나입니다. 저는 이번 글에서, 요즘 개발자들에게 필수적인 공통 엔지니어링 인프라 중 하나인 'Private Docker Registry'를 사용자에게 제공하기 위해 어떤 고민을 했고 어떤 과정을 거쳤는지 이야기하려고 합니다.
기존 상황은 이러했습니다
Docker를 기업 환경에서 사용하려면 반드시 필요한 것이 Private Docker Registry입니다. 개발자가 만든 Docker 컨테이너 이미지를 저장하고 공유하면서 신뢰할 수 있는 저장소가 필수이기 때문입니다. LINE에서도 기존에 운영하던 Private Docker Registry가 있었고, 실제로 많은 개발자가 사용하고 있었습니다. 하지만 Docker에서 제공하는 가장 기초적인 형태의 리포지터리(repository)를 사용하고 있었기 때문에 관리 측면과 보안 측면에서 여러 가지 문제점이 있어서 개선이 필요한 상황이었습니다. 특히 이미지를 효율적으로 관리하기 위한 UI, 이미지 보안을 향상시키기 위한 접근 제어 기능이 필요하다고 사용자들이 계속 요구하고 있는 상황이었습니다.
이런 상황을 개선하기 위해 Portus, JFrog, Nexus Repository Manager 같은 프로젝트에 대해 조사해 보고, 기존 레지스트리를 이용해 향상된 기능을 제공하는 방법도 나름대로 테스트해 보고 있었습니다. 하지만, 팀에서 가용할 수 있는 인적 자원과 관련 경험이 부족하다는 현실적인 한계에 부딪혀 사용자가 체감할 수 있을 만한 변화를 적시에 제공하기가 어려웠습니다.
하지만 Docker를 사용하는 LINE 엔지니어가 점점 늘어났고, 조만간 사내에 Kubernetes-as-a-service도 오픈할 예정이라서 새로운 Private Docker Registry를 도입하는 걸 마냥 미룰 수는 없었습니다. 그래서 현실적으로 가능한 부분에서 실질적으로 사용자에게 가치를 줄 수 있는 방법을 찾아보기 위해 노력했습니다
문제를 해결하기 위해 이런 원칙을 세웠습니다
저는 '현실적으로 가능한 수준에서 향상된 기능의 Private Docker Registry를 최대한 빠르게 LINE 엔지니어에게 제공한다'라는 목표를 달성하기 위해 스스로 아래와 같은 기본 원칙을 세우고 해결책을 찾아보았습니다.
핵심적인 기능부터 제공
우선 사용자가 정말 원하는 것부터 제공하는 것을 목표로 정했습니다. 그래서 어떤 기능을 가장 먼저 제공해야 하는지 고민했습니다. UI를 통해 이미지를 편리하게 관리할 수 있게 하는 것, 인증(authentication)과 권한 부여(authorization) 기능을 통해 가장 기본적인 보안을 확보하는 것. 이 두 가지가 가장 필요한 기능이라고 생각하고 다른 기능은 일단 제공하지 않아도 괜찮다는 생각으로 접근했습니다.
충분히 검증된 도구를 선택
가능하면 널리 통용되는 도구를 사용하려고 했습니다. 그동안의 경험에 비추어 보면 세계 각지에 퍼져있는 LINE 엔지니어들은 저희가 생각지도 못했던 정말 다양한 방법을 이용해 자신이 원하는 방식으로 저희가 제공하는 공통 엔지니어링 인프라를 사용했습니다. 그래서 아무리 매력적인 소프트웨어라도 기존에 충분한 사용자로부터 검증받지 못했다면 이런 다양한 사용 방식을 만족시키지 못할 가능성이 높다고 생각했습니다. 또한 실질적으로 모든 상황에 대한 문서를 만들어 제공할 수 없는 상황이었기 때문에, 이미 문서화가 잘 되어 있어서 저희가 제공하지 못하더라도 사용자가 필요할 때 찾아볼 수 있는 문서가 있는가라는 점도 매우 중요했습니다.
상용 소프트웨어 도입 지양
가능하면 상용 소프트웨어는 도입하지 않으려고 했습니다. 기술 이슈를 LINE 내부에서 직접 처리하는 방식에 익숙한 LINE의 문화에서는, 상용 소프트웨어를 도입하여 기술 지원을 받는 이익이 비용 대비 크지 않다는 생각이 들었고, 특정 벤더에 종속될 수 있는 위험도 경계하고 싶었습니다. 라이선스를 관리하고 관련된 재무 업무를 처리하는 것도 인적 자원이 필요한 부분이라는 점도 고려했습니다.
운영이 쉬운 소프트웨어
운영하기 쉬운 소프트웨어를 찾으려고 했습니다. 한 번 설치하면 앞으로 꽤 오랜 기간 동안 시스템이 운영되어야 하기 때문에, 기능이 조금 만족스럽지 않더라도 운영하기 쉬운 소프트웨어를 찾으려고 했습니다. 아키텍처가 복잡하지 않고, 일반적인 사내 인프라 환경에서도 잘 구동되며, 운영할 때 꼭 필요한 기능을 제공하고 있는 소프트웨어를 원했습니다.
사내 인프라와 호환성 고려
사내 다른 팀에서 제공하는 시스템을 최대한 연계해서 사용할 수 있는 소프트웨어를 찾으려고 했습니다. LINE에서는 AWS(Amazon Web Services)의 S3와 유사한 형태의 Object Storage와 EBS(Elastic Block Storage)와 비슷한 형태의 Block Storage를 쉽게 사용할 수 있고, 사내 LDAP 서버를 이용하여 직원 정보도 연계할 수 있습니다. 이런 부분을 최대한 활용하고 싶었습니다.
디스크 용량 산정은 보수적으로
기존의 다른 사내 리포지터리 운영 경험에 비추어 보면, 디스크 사용량은 항상 예상보다 훨씬 더 빠르게 증가했는데요. 미리 예측하지 못한 이유로 폭발적으로 사용량이 증가할 가능성이 있기 때문에 추후 디스크 사용량을 최대한 보수적으로 산정했습니다. 동적으로 디스크 용량을 증가시킬 수 있는 방안을 마련하는 게 가장 좋았으나, 그게 힘들다면 사전에 충분한 용량을 확보하여 설치하고자 했습니다. 대신 응답 시간은 크게 고려하지 않았습니다.
Harbor 도입을 고려하게 되었습니다
Harbor는 기본적으로 '오픈 소스 컨테이너 이미지 레지스트리'를 제공하는 프로젝트입니다. 공식 사이트에서는 아래와 같이 설명하고 있습니다.
What is Harbor?
Harbor is an open source container image registry that secures images with role-based access control, scans images for vulnerabilities, and signs images as trusted. A CNCF Incubating project, Harbor delivers compliance, performance, and interoperability to help you consistently and securely manage images across cloud native compute platforms like Kubernetes and Docker.(Harbor는 역할 기반 접근 제어, 이미지 취약점 스캐닝, 이미지 서명 등의 기능을 갖춘 오픈소스 컨테이너 이미지 레지스트리입니다. CNCF Incubating 프로젝트인 Harbor는, Kubernetes와 Docker와 같은 클라우드 네이티브 플랫폼에서 이미지를 안전하고 일관적으로 관리할 수 있는 컴플라이언스와 성능, 상호 운영성을 제공합니다)
Harbor를 처음 고려하게 된 계기는, LINE 정도의 규모를 가진 회사는 아니더라도 기업 환경에서 Harbor를 사용해 본 경험이 있는 사람이 팀원으로 합류했는데, 그분에게 사용자 입장에서 편리하고 설치도 어렵지 않은 오픈소스 프로젝트라는 의견을 듣게 되었기 때문입니다. 좀 더 자세한 정보를 얻기 위해 우선 CNCF(Cloud Native Computing Foundation) 재단에서 제공하는 웹 페이지에서 Harbor가 어느 정도 수준에 위치하는지 확인해 보았습니다.
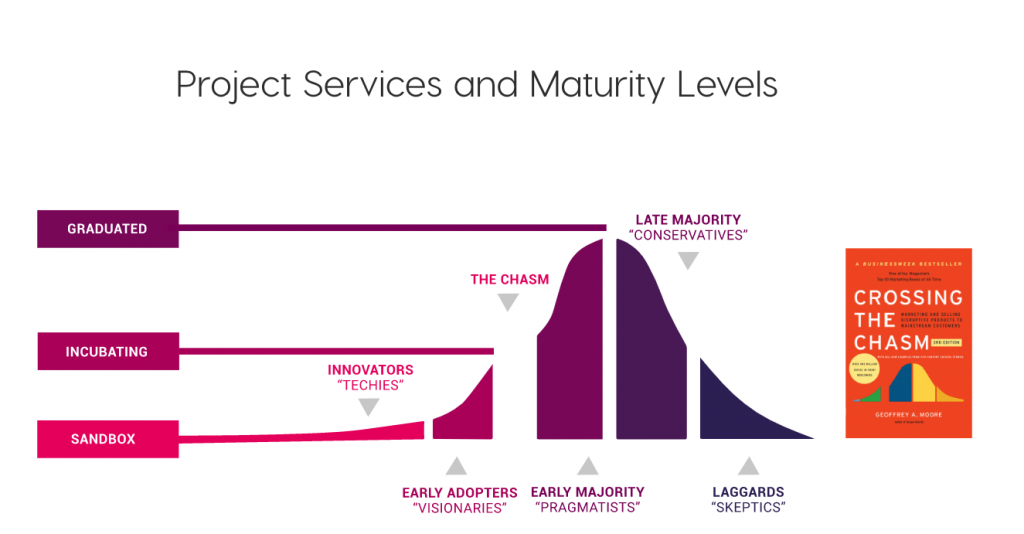

Harbor는 컨테이너 레지스트리 프로젝트 중 유일하게 'Incubating' 수준에 해당하는 오픈소스 프로젝트로, 이 정도면 충분히 사용해 볼 만한 성숙도를 가지고 있는 프로젝트라고 생각하게 되었습니다.
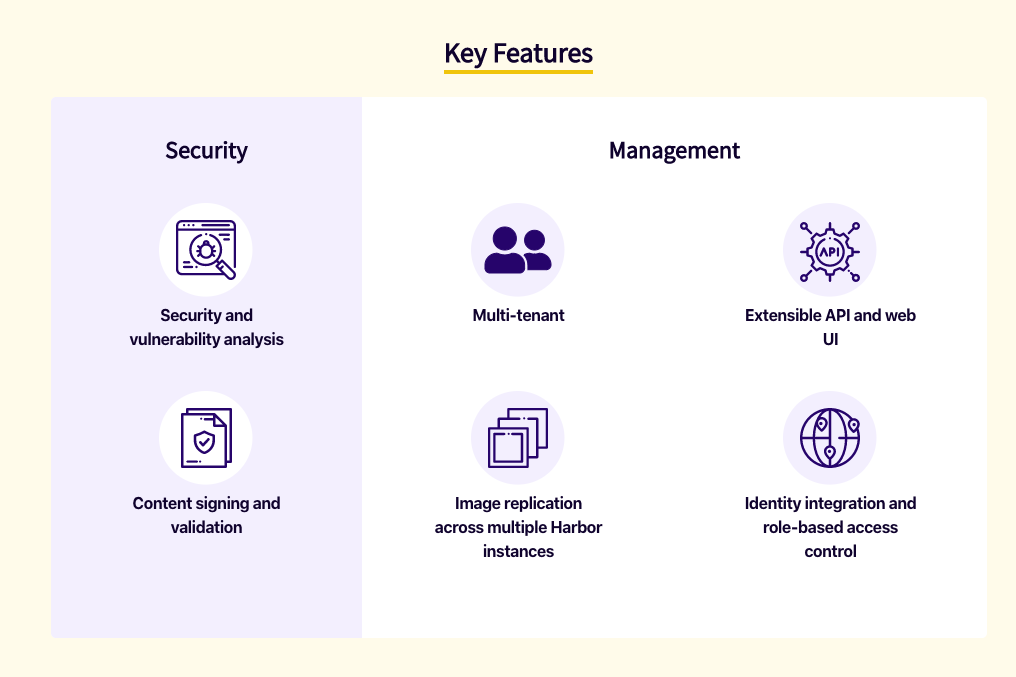
Harbor는 웹 UI와 역할 기반 접근 제어(Role Based Access Control)을 주요 기능으로 제공한다고 설명하고 있습니다. 그래서 제가 필수 기능으로 선정한 두 가지 기능, UI 제공과 사용자 권한 관리에 충분히 대응할 수 있겠다고 판단했습니다.
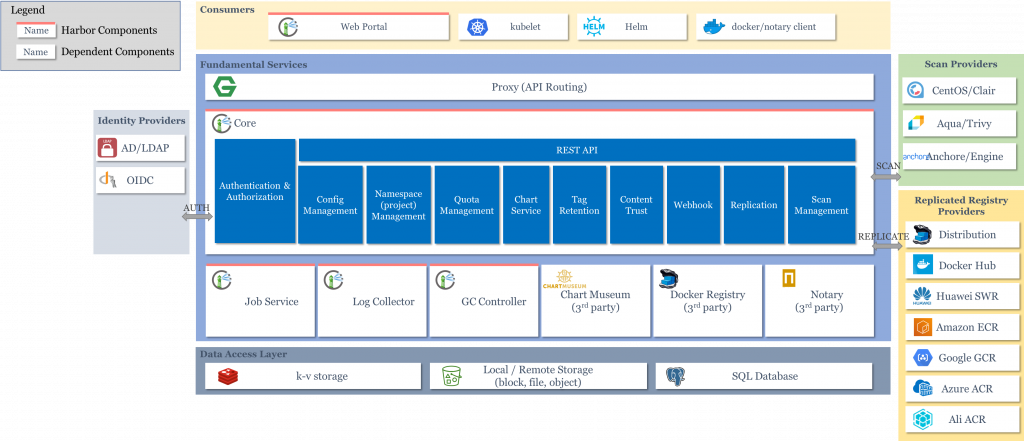
Harbor의 아키텍처를 보았을 때, 향후 운영하면서 어려움을 겪을 정도로 심각하게 복잡하진 않다고 생각했습니다. 또한 사내 인프라와도 잘 호환될 것 같았습니다. 이 정도면 Harbor가 제가 나름대로 세웠던 기본적인 기준을 충족시킨다고 판단했고, 실제 사용할 수 있을지 검증하는 절차에 들어갔습니다.
이런 부분을 검증했습니다
문서로는 아주 훌륭해 보였지만, 실제 검증해 보면 그 기대치를 충족시키지 못하는 소프트웨어가 아주 많습니다. 특히 비교적 새로운 분야에서 사용되는 오픈소스 소프트웨어의 경우에 더욱 그렇습니다. 사실 실제로 운영 환경에 도입해 보기 전에는 어떠한 소프트웨어도 100% 신뢰하기 어렵습니다. 다만, 최소한의 기능성과 신뢰성을 확인하기 위해 아래와 같은 과정으로 나름의 기술 검증 과정을 거쳤습니다.
설치 과정 검증
공식 설치 가이드에 따라 테스트 시점에서 최신 버전이었던 Harbor v1.8.1를 설치했습니다. 설정만 약간 수정하니 문제없이 진행되었습니다.
Docker 로그인, push, pull 테스트
Docker 클라이언트를 이용하여 로그인, push, pull 기능을 수행하는 데 문제가 없는지 확인했습니다. 특별한 이슈는 발견되지 않았습니다.
UI 기본 기능 점검
프로젝트 생성 및 삭제, 이미지 검색, 로그 확인과 같은 기본적인 UI 제공 기능을 확인했습니다. 사용자 가이드에서 설명하는 메뉴들을 직접 확인해 보았습니다. 큰 이슈는 없었습니다.
역할 기반 접근 제어 기능 점검
테스트용 계정을 이용하여 사용자 권한 관리 기능이 잘 동작하는지 확인했습니다.

사용자별로 허용된 접근만 가능한 것을 직접 확인할 수 있었습니다.
사내 LDAP(Lightweight Directory Access Protocol) 서버 연계 테스트
사내 LDAP 서버를 Harbor에 연계하고, 사번을 이용하여 Harbor에 로그인하는데 문제가 없는지 확인했습니다.
사내 S3 호환(compatible) Object Storage 연계 테스트
Harbor는 기본적으로 Docker 컨테이너 이미지를 로컬 파일 시스템에 저장합니다. 하지만 앞으로 증가할 용량을 예상해보면 반드시 외부 스토리지에 저장해야 될 거라고 판단해서 사내 S3 호환 Object Storage와 연계가 가능한지 확인했습니다.
Harbor는 스토리지 백엔드로 로컬 파일 시스템 대신 S3, OpenStack Swift, Ceph과 같은 다양한 것들을 고려할 수 있다고 이야기하고 있습니다.
"you may consider use other storage backend instead of the local filesystem, like S3, OpenStack Swift, Ceph, etc. These parameters are configurations for registry."
출처: https://github.com/goharbor/harbor/blob/master/docs/installation_guide.md#configuring-storage-backend-optional
하지만 실제 연계 테스트 중에 생각하지 못했던 이슈가 발생하여, 다른 방법을 찾아보아야 했습니다.
Issue Case
실제 검증할 때 Docker push 명령이 수행되지 않고 아래와 같은 문제가 발생했습니다.
level=error msg="response completed with error" auth.user.name=admin err.code=unknown err.detail="s3aws: SerializationError: failed to decode S3 XML error responses3 호환 object storage를 사용하면서 비슷한 문제를 겪은 사용자가 많이 있었습니다(참고).
MinIO를 활용한 전용 S3 호환 Object Storage 구축 및 연계 테스트
MinIO는 AWS의 S3 SDK와 호환되는 오픈소스 Object Storage 소프트웨어입니다. 사내 S3 호환 Object Storage 대신 MinIO를 활용하여 Harbor만을 위한 전용 S3 호환 Object Storage을 구성하기로 하고 테스트했습니다. MinIO를 새로 도입하면 운영해야 하는 부분이 더 늘어날 수 있지만, 감당할 수 있는 수준이라고 생각했습니다. 다른 팀원이 예전에 테스트했던 경험이 있어서 많은 도움을 받을 수 있었습니다.
Distributed MinIO 서버를 구성하여 테스트했고, 사내 S3 호환 Object Storage를 사용했을 때 발생했던 문제는 재발하지 않았습니다. 다른 특별한 이슈도 없었습니다.
버전 업 절차 검증
향후 Harbor의 새로운 버전이 발표되면 지속적으로 버전 업을 해야 하기 때문에 Harbor에서 제공하는 공식 가이드 절차를 검증했습니다. Harbor v1.7.0를 새로 구성한 다음, 제공되는 마이그레이터(migrator)를 이용하여 v1.8.0으로 업그레이드하는 방식으로 진행했습니다. 문서의 절차대로 진행했을 때 큰 문제없이 동작했습니다.
$ cd harbor
$ docker-compose down
$ cd ..
$ mv harbor /my_backup_dir/harbor
$ cp -r /data/database /my_backup_dir/
$ docker pull goharbor/harbor-migrator:v1.8.0
$ sudo cp -rp /my_backup_dir/harbor/harbor.cfg .
$ wget https://storage.googleapis.com/harbor-releases/release-1.8.0/harbor-offline-installer-v1.8.0.tgz
$ tar xvfz harbor-offline-installer-v1.8.0.tgz
$ docker run -it --rm -v $(pwd)/harbor.cfg:/harbor-migration/harbor-cfg/harbor.cfg -v $(pwd)/harbor/harbor.yml:/harbor-migration/harbor-cfg-out/harbor.yml goharbor/harbor-migrator:v1.8.0 --cfg up
Please backup before upgrade,
Enter y to continue updating or n to abort: y
Command for config file migration: python ./cfg/run.py --input /harbor-migration/harbor-cfg/harbor.cfg --output /harbor-migration/harbor-cfg-out/harbor.yml
input version: 1.7.0, migrator chain: ['1.8.0']
migrating to version 1.8.0
Written new values to /harbor-migration/harbor-cfg-out/harbor.yml
$ sudo ./install.sh백업과 복구 테스트
백업과 복구는 데이터를 아래와 같이 크게 3가지로 분리하여 각각 방안을 마련한 뒤 스크립트를 작성하여 테스트했습니다.
- Harbor 엔진과 캐시 데이터가 저장되는 로컬 파일 시스템
- Docker 컨테이너 이미지가 저장되는 Distributed MinIO
- 메타데이터가 저장되는 내부 PostgreSQL DB
특별히 복잡한 작업 없이, 백업 데이터를 신규 서버에 복원(restore)하는 정도로 복구가 가능했습니다.
고가용성(high availability) 점검
고가용성 점검은 Habor 서버 부분과 MinIO 저장소 부분으로 나누어서 진행하였습니다.
Harbor는 고가용성을 위해 복제 기능을 제공하지만(참고), 시간 관계상 이번에는 테스트해 보지 못했습니다. 콜드 스탠바이(cold standby) 서버를 구성하여 대응하는 수준이면 사용자의 기대치를 만족시키는데 크게 무리가 없다고 판단했고, 페일오버(fail over) 시나리오를 작성해서 실제로 테스트해보았습니다.
MinIO는 Distributed MinIO를 총 6대 구성하여, 동시에 2대까지 사용 불능 상태가 되어도 데이터에 접근할 수 있다는 것을 확인했습니다.
MinIO에서는 N개의 디스크를 사용할 때 아직 (N/2+1)개의 디스크를 사용할 수 있는 상황이라면 계속해서 읽기와 쓰기가 가능하다고 안내하고 있습니다.
High availability
A stand-alone MinIO server would go down if the server hosting the disks goes offline. In contrast, a distributed MinIO setup with n disks will have your data safe as long as n/2 or more disks are online. You'll need a minimum of (n/2 + 1) Quorum disks to create new objects though.
출처: https://docs.min.io/docs/distributed-minio-quickstart-guide.html
특이 사항으로, 만약 장애가 발생해 일부 Distributed MinIO 서버를 교체했다면, 작업 후 mc admin heal 명령어를 실행해야 한다는 것을 알게 되었습니다(참고).
docker run -it --rm --entrypoint=/bin/sh minio/mc -c "
mc config host add minio $MINIO_DOMAIN:9000 $MINIO_ACCESS_KEY $MINIO_SECRET_KEY;
mc admin heal -r minio
" 이렇게 구축했습니다
검증 과정을 진행해 본 결과 심각한 문제점은 발견되지 않아서, 실제 Harbor 구축을 진행했습니다. 조금 미진한 부분이 있더라도 일단 바로 진행할 수 있는 부분은 빨리 진행하고, 추후 더 발전시켜 나가는 것을 기본 콘셉트로 정했습니다.
아키텍처 확정
우선 간략한 시스템 구축 계획서를 작성하여 동료들과 검토했습니다. 최종적으로 아래와 같은 아키텍처를 구성하여 진행하기로 결정했습니다.


신규 Harbor 시스템의 RTO와 RPO는 최악의 경우에도 24시간을 넘지 않는 것을 목표로 정했습니다.
Distributed MinIO 구성
Harbor을 설치하기에 앞서, 데이터 컨테이너 이미지 저장 공간으로 사용할 Distributed MinIO를 구성했습니다. 우선 적당한 서버 6대를 할당받았고, 각각의 서버에는 /data라는 마운트 포인트에 저희가 산정한 용량에 맞는 사내 외장 블록 스토리지를 연결하여 로컬 파일 시스템처럼 사용할 수 있게 했습니다. 그다음에 사내 DNS에 MINIO_DOMAIN을 등록했고, 사내 로드 밸런서를 이용하여 MINIO_DOMAIN으로 접근하면 MINIO_HOST 1~6으로 요청이 전달되도록 설정했습니다. 그리고 MinIO 퀵 스타트 가이드와 Distributed MinIO 퀵 스타트 가이드를 참고하여 아래 과정을 모든 MinIO 서버에서 동일하게 수행했습니다.
$ wget https://dl.min.io/server/minio/release/linux-amd64/minio
$ chmod +x minio
$ mkdir $LOG_DIR
$ sudo sh -c
'export MINIO_DOMAIN=$MINIO_DOMAIN;
export MINIO_ACCESS_KEY=*********************;
export MINIO_SECRET_KEY=*********************;
nohup ./minio server
http://$MINIO_HOST1/data
http://$MINIO_HOST2/data
http://$MINIO_HOST3/data
http://$MINIO_HOST4/data
http://$MINIO_HOST5/data
http://$MINIO_HOST6/data
2>&1 > $LOG_DIR/minio.log &'마지막으로 MINIO_DOMAIN 주소로 MinIO 브라우저에 접속해서 Harbor에서 사용할 버킷(bucket)을 하나 만들어 주는 것으로 MinIO 설치를 마무리했습니다.

Harbor 설치와 설정
앞으로 운영하기에 적당한 성능의 서버를 할당받았습니다. Harbor는 기본적으로 Docker Compose 기반에서 운영됩니다. 그래서 사전에 Docker 엔진과 Docker Compose를 설치한 후, 아래와 같은 설치 단계를 진행했습니다. 검증 절차에서 진행한 것처럼 Harbor에서 제공하는 공식 설치 가이드를 따랐습니다.
$ wget https://storage.googleapis.com/harbor-releases/release-1.8.0/harbor-offline-installer-v1.8.1.tgz
$ tar xvf harbor-offline-installer-v1.8.1.tgz
# Configure harbor.yml
$ sudo ./install.sh
$ sudo docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------
harbor-core /harbor/start.sh Up
harbor-db /entrypoint.sh postgres Up 5432/tcp
harbor-jobservice /harbor/start.sh Up
harbor-log /bin/sh -c /usr/local/bin/ ... Up 127.0.0.1:1514->10514/tcp
harbor-portal nginx -g daemon off; Up 80/tcp
nginx nginx -g daemon off; Up 0.0.0.0:443->443/tcp, 0.0.0.0:80->80/tcp
redis docker-entrypoint.sh redis ... Up 6379/tcp
registry /entrypoint.sh /etc/regist ... Up 5000/tcp
registryctl /harbor/start.sh Up
------------------------------------------------------------harbor.yml은 아래와 같이 hostname과 https related config, storage_service 부분을 저희 환경에 맞게 수정한 뒤 사용했습니다. HARBOR_DOMAIN은 사전에 사내 DNS에 등록해 놓은 주소이며, HARBOR_BUCKET은 앞서 MinIO 브라우저를 이용하여 만들어 준 버킷의 이름입니다.
harbor.yml
~~~~~~
# The IP address or hostname to access admin UI and registry service.
# DO NOT use localhost or 127.0.0.1, because Harbor needs to be accessed by external clients.
hostname: $HARBOR_DOMAIN
~~~~~~
# https related config
https:
# https port for harbor, default is 443
port: 443
# The path of cert and key files for nginx
certificate: $CERT_PATH
private_key: $KEY_PATH
~~~~~
# Uncomment storage_service setting If you want to using external storage
storage_service:
s3:
accesskey: $MINIO_ACCESS_KEY
secretkey: $MINIO_SECRET_KEY
regionendpoint: $MINIO_DOMAIN:9000
region: us-east-1
bucket: $HARBOR_BUCKET
~~~~~검증 과정에서처럼 특별한 문제 없이 Harbor UI 화면을 볼 수 있었습니다.
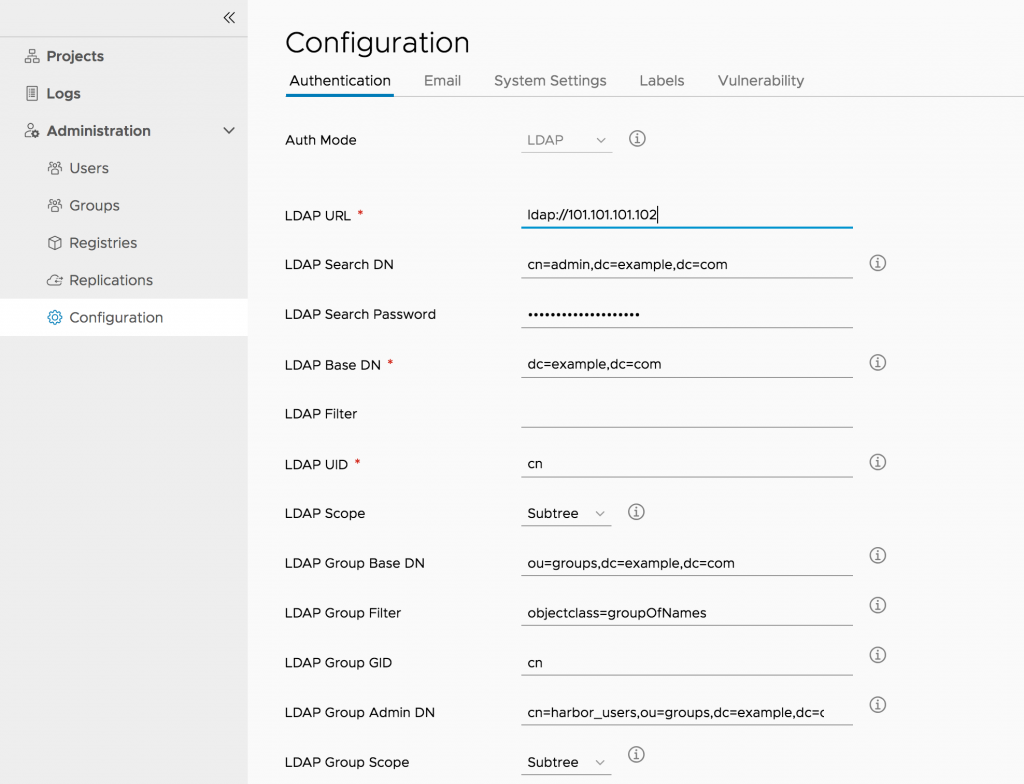
사내 LDAP 서버 연계
기본 시스템 계정으로 로그인한 다음 Harbor에서 제공하는 가이드를 참고하여, LINE 사내 LDAP 서버 정보를 Harbor에 설정했습니다.
백업 구성
백업은 저희가 별도로 보유한 Jenkins에서 잡(job) 스케줄링 기능을 이용하여 검증 절차에서 만들었던 항목별 백업 스크립트를 주기적으로 원격에서 실행시키는 구조로 정했습니다. 백업 데이터는 s3cmd와 MinIO 클라이언트(참고)를 이용하여 사내 S3 호환 Object Storage에 저장하도록 구성했습니다.
제가 작성한 백업 스크립트는 아래와 같습니다.
- Harbor 엔진과 캐시 데이터가 저장되는 로컬 파일 시스템
$ s3cmd --access_key=$BACKUP_S3_ACCESS_KEY --secret_key=$BACKUP_S3_SECRET_KEY --host=$BACKUP_S3_DOMAIN --host-bucket=$BACKUP_S3_DOMAIN --delete-removed sync $HARBOR_DATA_PATH/ s3://$BACKUP_S3_BUCKET/harbor/filesystem/data/;- 메타데이터가 저장되는 내부 PostgreSQL DB
$ docker exec harbor-db /bin/sh -c "pg_dumpall -U postgres --clean" > $DB_BACKUP_DIR/postgres_all_dump.sql;
$ s3cmd --access_key=$BACKUP_S3_ACCESS_KEY --secret_key=$BACKUP_S3_SECRET_KEY --host=$BACKUP_S3_DOMAIN --host-bucket=$BACKUP_S3_DOMAIN put $DB_BACKUP_DIR/postgres_all_dump.sql s3://$BACKUP_S3_BUCKET/harbor/postgres_all_dump/;
$ rm -rf /data/tmp/postgres_all_dump.sql;- Docker 컨테이너 이미지가 저장되는 Distributed MinIO
# Use MinIO Client https://docs.min.io/docs/minio-client-complete-guide.html
$ docker run -it --rm --entrypoint=/bin/sh minio/mc -c "
mc config host add minio $MINIO_DOMAIN:9000 $MINIO_ACCESS_KEY $MINIO_SECRET_KEY;
mc config host add backup_s3 $BACKUP_S3_DOMAIN $BACKUP_S3_ACCESS_KEY $BACKUP_S3_SECRET_EY;
mc mirror --overwrite --remove minio/harbor backup_s3/$BACKUP_S3_BUCKET/harbor/docker-registry/
"관련 문서 작성
Harbor를 운영할 관리자를 위한 문서와 일반 사용자를 위한 가이드 문서를 작성했습니다. 이 문서는 계속 업데이트하고 있습니다.


맺으며
설치 후 간단한 모니터링 설정을 마친 다음 Harbor를 도입했다고 공지했고, 많은 사람들이 Harbor를 사용하기 시작했습니다. 정확한 숫자를 밝히기는 어렵지만 많은 LINE 엔지니어가 활발하게 Harbor를 사용하고 있는데요. 특히 다양한 CI/CD 시스템과 활발하게 연계해서 Docker를 이용한 개발 프로세스를 더욱더 효율적으로 만드는 데 힘을 써주고 계십니다. 현재도 다양한 채널로 여러 나라의 사용자가 활발하게 Harbor에 대해 문의하고 있고요.
물론 아직 많은 과업이 남아 있습니다. RTO와 RPO를 더 줄일 수 있게 아키텍처의 많은 부분을 향상시켜야 하며, 기존에 사용하던 Private Docker Registry를 어떻게 중단시킬 수 있을지도 고민해야 합니다. 새로 발표된 Harbor 버전으로 업그레이드하는 작업도 계속 진행해야 하며, 모니터링도 더욱 발전시켜야 합니다. 더 많은 정보를 제공하는 문서를 만들어야 하고, 다른 공통 엔지니어링 인프라와도 추가로 연계해야 합니다.
아직 이런 이슈들이 남아 있긴 하지만, 일단 사용자에게 도움이 되는 어떤 가치를 실제로 제공했다는 것에 보람을 느끼고 있습니다. 도입하는 과정 내내 정말 사용자에게 필요한 게 무엇인지를 끊임없이 고민했습니다. 그런 과정에서 완벽함도 좋지만 조금 부족하더라도 빠르게 실행해 보는 것 또한 중요하다고 생각했습니다.
또한 Harbor를 도입하면서 여러 동료에게 많은 도움을 받을 수 있었습니다. 제가 생각하지 못했던 부분에 대해서 조언을 받았고, 제가 잘 모르는 부분과 관련된 경험도 들을 수 있었습니다. 응원도 많이 받았습니다. LINE은 새로운 무엇을 시도해 보기 좋은 회사라고 생각합니다. 스스로 의지만 있다면, 제약 없이 자신의 능력을 최대한 발휘하여 실제적인 가치를 만들어 낼 수 있습니다. 앞으로도 많은 시도를 해 보면서 실패의 경험을 쌓고 성공의 보람을 느끼는 LINER가 되고 싶습니다.