
LINE Data Labs의 데이터 엔지니어 Keiji Yoshida입니다. 저희 부서는 2017년부터 LINE 직원이라면 누구든지 담당하는 서비스의 데이터를 필요할 때 분석할 수 있는 환경을 구축하여 제공하는 작업을 수행해왔습니다. 이번 글을 통해 이 작업을 여러분께 소개하고자 합니다.
LINE Data Labs란
LINE Data Labs는 LINE의 각 서비스의 데이터를 수집, 처리, 집계, 분석하는 작업을 전문화하여 분석된 데이터를 활용하여 각각의 서비스가 성장할 수 있도록 지원하는 부서입니다. 약 50명의 머신 러닝 엔지니어, 데이터 사이언티스트, 데이터 기획자, 데이터 엔지니어가 서로 협력하여 데이터를 수집하고 데이터 집계 및 가시화에 필요한 BI(Business Intelligence)/리포팅 서비스를 제공하는 것뿐만 아니라 서비스 관계자들이 의사 결정할 때 활용할 수 있도록 수집된 데이터를 분석하고 그 결과를 제공하고 있습니다. 또한 각 서비스에 머신 러닝을 적용하는 등 다양한 데이터 관련 업무를 수행하고 있습니다.
BI/리포팅 서비스를 제공하면서 발견한 새로운 과제
LINE Data Labs에서는 하둡(Hadoop) 클러스터에 축적되어 있는 각 서비스 데이터를 집계하여 IBM Cognos와 Tableau를 활용하여 가시화 리포트를 만들어 서비스 부서에 제공합니다. 이를 통해 서비스 부서의 프로덕트 매니저, 영업, 기획, 엔지니어는 담당하는 서비스의 사용자 수와 매출 등의 KPI를 지속적으로 모니터링 할 수 있습니다.
BI/리포팅 서비스는 다음의 절차를 거쳐 제공됩니다.
- LINE Data Labs의 데이터 기획자와 서비스의 담당자가 모니터링 할 KPI 및 리포트의 사양 확정
- LINE Data Labs의 데이터 엔지니어가 서비스 데이터를 하둡 클러스터에 수집하고, 수집한 데이터를 가공 및 집계하는 ETL(Extract, Transform and Load) 모듈 개발
- LINE Data Labs의 데이터 플래너가 IBM Cognos와 Tableau를 활용하여 리포트를 만든 후 서비스 부서에 제공

그동안 서비스 부서에선 LINE Data Labs의 하둡 클러스터에 접근 권한이 없었기 때문에 자유롭게 데이터를 분석하여 자체적으로 리포트를 작성할 수 없었습니다. 즉, LINE Data Labs가 제공하는 리포트를 열람만 할 수 있다는 단점이 있었습니다.
하둡 클러스터 데이터 전사 공개
각 서비스의 데이터 분석과 리포팅 업무의 효율성을 높이기 위해 앞서 언급한 단점을 해결하고자 LINE Data Labs가 직접 관리하고 있는 하둡 클러스터의 데이터를 LINE 전사에 공개하는 작업을 작년 2017년 후반부터 시작했습니다.
요구사항
데이터를 전사에 공개하는 작업에 대해 정리된 주요 요구사항은 아래와 같습니다.
- 보안각 사용자, 즉 각 LINE 직원은 자신이 담당하고 있는 서비스 등 허가를 받은 데이터에만 접근할 수 있어야 함 (하둡 클러스터로 임포트하는 사용자 데이터 혹은 추출하는 사용자 데이터는 개인 정보 보호를 위해 전사 공개 전에도 통제하였으며, 전사 공개 후에도 계속 통제함)
- 안정성
- 특정 사용자가 처리 부하가 큰 쿼리 애플리케이션을 하둡 클러스터에서 실행하더라도 해당 작업이 다른 쿼리, 애플리케이션의 실행과 성능에 영향을 미치지 않아야 함
- 사용자 수가 증가하더라도 서비스를 안정적으로 제공할 수 있어야 함(최대 사용자 수 = LINE 직원 수)
- 기능
- 사용자가 쿼리 애플리케이션을 생성하여 하둡 클러스터에서 데이터를 추출할 수 있어야 함
- 데이터 추출 결과를 표 또는 그래프로 가시화할 수 있어야 함
- 여러 건의 데이터 추출 결과를 취합하여 리포트를 생성할 수 있어야 함
- 작성한 리포트를 같은 서비스를 담당하는 구성원 간에 공유할 수 있어야 함
- 임의의 일정에 따라 리포트를 자동으로 업데이트하여 항상 최신 데이터가 리포트에 반영될 수 있어야 함
- 생성이 완료된 리포트는 집계 기간 등의 파라미터를 변경하여 다시 재구성할 수 있어야 함
요구사항 대응
보안 항목에 대해서는 하둡 클러스터에 Kerberos 인증을 도입하여 Apache Ranger로 각 유저가 어느 HDFS 경로에 접근할 수 있는지를 제어해서 대응하기로 했습니다. 안정성 항목을 충족하기 위해 하둡 YARN 클러스터에서 YARN 애플리케이션으로 실행되는 Apache Spark를 쿼리 애플리케이션 실행 엔진으로 채택하였습니다. 사용자용 웹 인터페이스로는 아래와 같은 이유로 아파치 제플린(Apache Zeppelin)을 채택하고 LINE Data Labs 내부에서 시범으로 운영해보기로 했습니다.
- User impersonation 기능을 사용해서 사용자 계정으로 Spark 애플리케이션을 실행할 수 있음(Apache Ranger ACL을 HDFS 파일 접근 시점에 적용할 수 있음)
- 아파치 제플린의 문서를 확인한 결과, 기능 관련 요구사항에 열거된 대부분의 요건을 충족시킬 수 있을 것으로 판단됨
시범 운영 용 시스템은 아래와 같은 구조로 구성하였습니다.

이상과 현실의 간극
시범 운영을 하면서 알게 된 사실은 우리가 바라던 조건과 아파치 제플린의 기능 및 철학 가운데 몇 가지 차이점이 있다는 것입니다. 충족되지 않은 요구사항은 구체적으로 다음과 같습니다.
시범 운영에 사용한 아파치 제플린의 버전은 당시 최신 버전이었던 0.7.3이며 이 블로그 글을 쓰는 시점 기준으로 최신 버전인 0.8.0에서 해결되었거나 개선된 부분이 있을 수도 있으니 감안해 주시기 바랍니다.
- 보안
- 제플린 노트북에 자동 실행을 설정할 때 실행 계정으로 본인이 아닌 임의의 사용자를 설정할 수 있음. 이를 이용해서 임의의 사용자로 Spark 애플리케이션을 실행하면 Apache Ranger ACL(Access Control List)에 정의된 권한 대로 본인 계정으로는 접근할 수 없는 데이터에 접근할 수 있게 됨
- 제플린 노트북 자동 실행 시 실행 계정이 본인 계정이 아닌 다른 사람의 계정으로 설정되어 있는 제플린 노트북을 사용하면 노트북에 있는 Spark 애플리케이션 코드를 편집할 수 있음. 이를 이용하여 임의의 사용자로 Spark 애플리케이션을 실행하여 Apache Ranger ACL에 정의된 권한 대로 본인 계정으로는 접근할 수 없는 데이터에 접근할 수 있게 됨
- 안정성
- 아파치 제플린을 하나의 서버에서만 동작시킬 수 있으며 Spark 애플리케이션은 yarn-client 모드에서만 실행할 수 있기 때문에, 특정 Spark 애플리케이션의 드라이버 프로그램 처리 부하가 커지면 서버 전체에 과부하가 걸려 아파치 제플린의 동작이 불안정해 짐
- Apache Livy 및 Livy Interpreter를 사용하면 yarn-cluster 모드에서 Spark 애플리케이션을 실행할 수 있지만, 그 대신에 다음과 같은 단점으로 애플리케이션을 효율적으로 실행할 수 없음
- 동일한 제플린 노트북 안에서도 Spark SQL, PySpark, SparkR이 각각 별개의 Spark 애플리케이션으로 실행됨
- 동일한 Livy 세션 내에서 여러 건의 작업을 병행해서 실행할 수 없음
- Spark가 지원하는 동일한 Spark 애플리케이션 내에서 작업을 병행 실행하는 구조(fair scheduler, fair pool)를 활용할 수 없음
- 제플린 노트북과 인터프리터가 동시에 동작을 멈추면 아파치 제플린 JVM에서 데드락이 발생하여 아파치 제플린을 재실행할 때까지 서비스 전체가 반응하지 않게 됨
- 기능
- 제플린 노트북 단위로만 노트북의 접근 제어(읽기, 쓰기)가 가능하기 때문에 노트북을 생성할 때마다 접근 제어를 설정해야 하므로 사용자의 부담이 커짐
- 제플린 노트북 페이지를 읽기 모드로 열 수 없고 항상 편집 모드로만 열 수 있기 때문에 만약 분석 작업을 위해 작성 완료된 노트의 집계 대상 기간 등의 파라미터를 일시적으로 변경해서 실행하거나 그래프 레이아웃을 변경하면 그 변경 내용이 즉시 저장되어 버림
아파치 제플린으로 시범 운영하는 중에 위와 같은 문제가 발견될 때마다 아래와 같이 JIRA 이슈, GitHub 풀리퀘스트를 생성하여 아파치 제플린에 컨트리뷰트하면서 아파치 제플린을 우리의 용도에 맞게, 문제 없이 사용할 수 있도록 노력했습니다.
- ZEPPELIN-2950: JIRA, GitHub
- ZEPPELIN-2995: JIRA, GitHub
- ZEPPELIN-2997: JIRA
- ZEPPELIN-3022: JIRA, GitHub
- ZEPPELIN-3045: JIRA, GitHub
- ZEPPELIN-3048: JIRA, GitHub
- ZEPPELIN-3049: JIRA, GitHub
- ZEPPELIN-3054: JIRA, GitHub
- ZEPPELIN-3066: JIRA, GitHub
- ZEPPELIN-3077: JIRA, GitHub
하지만, 권한 제어를 수정하는 것은 기존의 아파치 제플린의 설계 철학과 부합하지 않는다는 이유로 받아들여지지 않은 것도 있고, 아파치 제플린 버전 업데이트와 릴리스 횟수가 1년에 2번 정도인지라 사내에서 사용하려면 공식 저장소를 사내 저장소에 fork한 후 릴리스 전에 수정된 사항을 백포트해야 했기 때문에 운영 비용과 관리 비용이 커지기도 했습니다. 이러한 이유로 우리는 이번에 아파치 제플린을 계속 사용하기 어렵다고 판단하였습니다.
그래서 우리는 하둡 클러스터의 데이터를 전사적으로 공개하기 위한 사용자용 웹 인터페이스를 직접 개발하기로 했습니다.
OASIS
그래서 개발된 것이 OASIS라는 웹 인터페이스입니다. 아파치 제플린이 제공하는 기능과 이용하는 방법을 참고하는 한편, LINE 전 직원이 사용하는 도구인만큼 권한을 엄격하게 제어하고 이용자 수가 증가하더라도 안정적으로 작동해야 한다는 점을 가장 중시해서 개발했습니다.
주요 페이지 소개
OASIS의 주요 페이지를 소개합니다.
메인 페이지
메인 페이지는 노트북이나 디렉터리를 한꺼번에 관리하는 '스페이스'라는 루트 디렉터리의 구성 목록이 표시되는 페이지입니다. LINE의 서비스나 부서별로 스페이스가 생성되며, 이 스페이스 단위로 권한이 제어됩니다. 예를 들어, A님은 Data Labs 스페이스 내의 노트북만 접근 가능하다 등의 권한이 설정됩니다.

노트북 참조 페이지
작성 완료된 노트북을 열람하기 위한 페이지입니다. 집계 기간 등의 파라미터를 변경하여 노트북을 재실행하거나 재구성하고, 그래프 포맷을 변경할 수 있습니다.

노트북 편집 페이지
노트북을 생성하거나 편집하기 위한 페이지입니다.
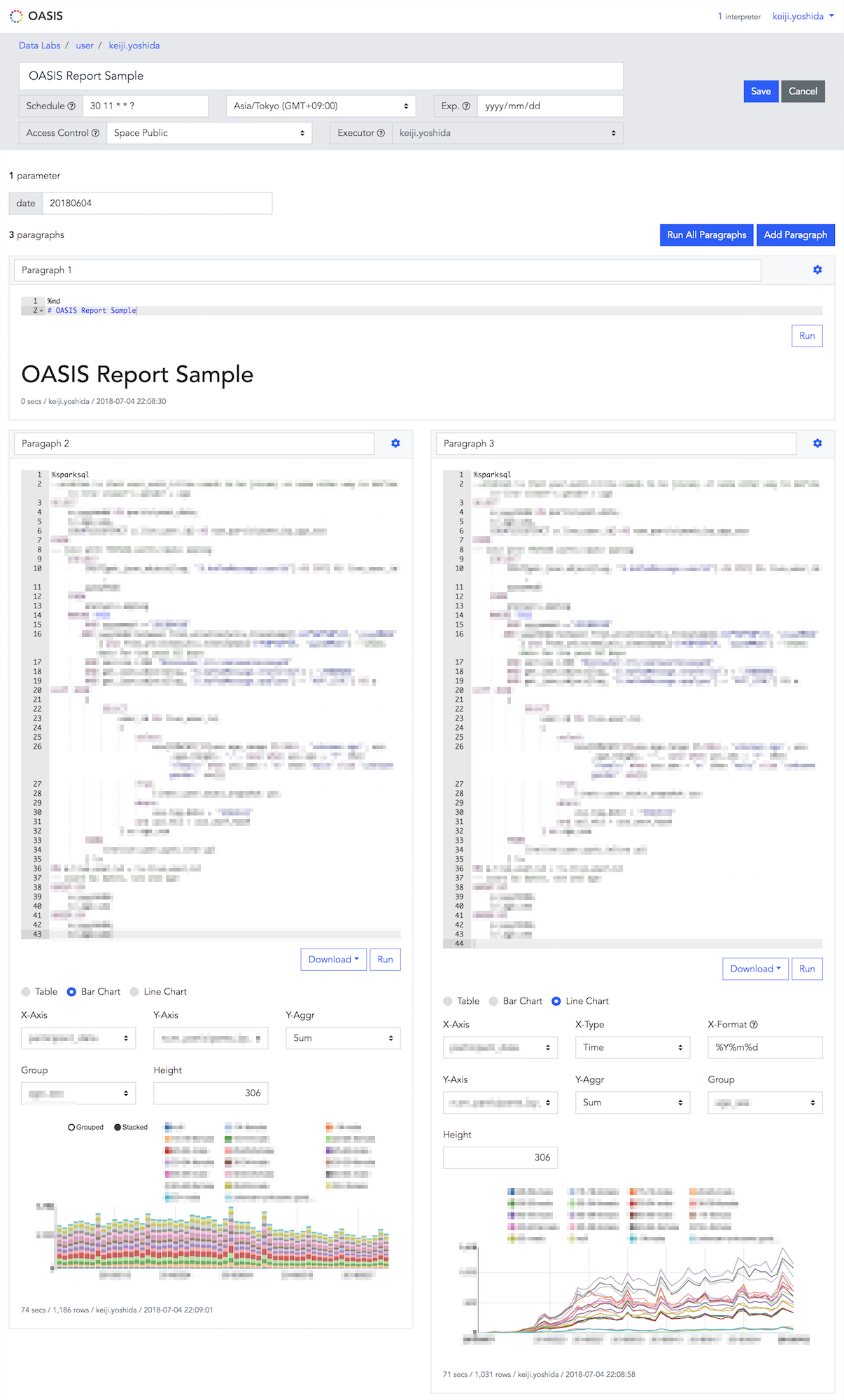
OASIS 기능 소개
OASIS의 주요 기능과 장점은 아래와 같습니다.
- Apache Spark 애플리케이션(Spark, Spark SQL, PySpark, SparkR) 및 Presto 쿼리를 실행할 수 있음
- 동일한 노트북에 속한 Spark, Spark SQL, PySpark, SparkR에서 동일한 Spark 애플리케이션을 공유하기 때문에, 예를 들면 PySpark의 연산 결과를 SparkR로 처리하고, 최종 결과를 Spark SQL로 추출하여 그래프화하는 것과 같이 세 가지 프로그래밍 언어를 활용해서 동일한 데이터셋을 처리할 수 있음
- Apache Spark의 메모리 캐시 기능을 활용하여 동일한 노트북 안에서 Spark SQL의 쿼리 실행 결과를 다른 쿼리에서도 참조하고자 한다면, 쿼리 실행 결과를 메모리 캐시에 저장하고 다른 쿼리에서 메모리 캐시에 접근해서 데이터를 고속으로 추출할 수 있음(동일한 데이터 소스를 다양한 디멘션으로 집계하거나 그래프화하는 등 노트북을 효율적으로 생성할 수 있음)
- 노트북을 저장할 때 Apache Spark 애플리케이션(Spark SQL, PySpark, SparkR)과 Presto 쿼리의 실행 결과가 함께 저장하므로, 노트북을 열람할 때 하둡 클러스터에 접근하지 않아도 바로 노트북의 내용이 표시됨
- 노트북을 특정 일시나 특정 주기로 자동 실행할 수 있음. 이로써 노트북이 표시하는 내용을 항상 최신 상태로 유지하거나 사용자가 ETL을 간이로 구현할 수 있게 됨
- Spark SQL의 실행 결과를 표 형식과 막대 그래프, 꺾은 선 그래프로 표시할 수 있음
- Spark SQL의 실행 결과를 CSV/TSV 파일로 다운로드할 수 있음
- HDFS의 조작(파일 업로드/다운로드 등)이 가능함(Ambari Files View가 담당하는 기능을 이용할 수 있음)
- Hive 데이터베이스 및 테이블 리스트, 각 테이블의 정의를 확인할 수 있음
- CSV/TSV 파일을 업로드하여 Hive 테이블을 작성할 수 있음
- 노트북 접근을 다음의 세 단계로 제어할 수 있음
- Private: 작성자만 접근할 수 있음
- Space Public: 해당 노트북이 속한 스페이스에 접근 권한을 가진 모든 사용자가 접근할 수 있음
- Space Public (Read Only): 해당 노트북이 속한 스페이스에 접근 권한을 가진 모든 사용자가 접근할 수 있으나, 마지막으로 업데이트한 사용자만 해당 노트북을 편집할 수 있음
- 노트북을 복제하거나 덮어쓸 수 있음. 리포트로 공개된 노트북을 시간을 들여 편집하고 특정 시점에 업데이트할 때, 먼저 해당 노트북을 복제하여 편집 작업을 한 후, 노트북을 업데이트하려는 시점에 복제해서 편집한 노트북의 내용을 원래 노트북에 덮어써서 릴리스하는 방식의 작업이 가능함
OASIS 시스템 구성
OASIS의 시스템 구성 개요는 아래와 같습니다. 주요 컴포넌트로는 Frontend/API와 Job Scheduler, Spark/Presto Interpreter가 있으며, 만약 이용자 수가 증가하면 세 컴포넌트 모두 스케일 아웃할 수 있습니다. 또한, 노트북에서 저장하지 않은 상태로 편집 중인 Apache Spark 애플리케이션과 Presto 쿼리의 실행 결과는 Redis에, 실행 결과를 포함한 노트북의 저장 내용은 MySQL에 각각 저장됩니다. 간략하게 보여 드리기 위해 아래 그림에선 생략했지만, 이 외에도 LINE 사내의 인증 및 통합 인증(Single sign-on) 시스템을 사용하고 있으며 HDFS를 조작하기 위한 API 서버가 별도로 구축되어 있습니다.

이 글을 작성하는 시점 기준으로 LINE Data Labs에서 관리하고 있는 하둡 클러스터의 사양은 아래와 같습니다.
- DataNode/NodeManager 수: 500대
- HDFS 사용 용량: 약 20PB
- Hive 데이터베이스 수: 약 70개(서비스 단위로 데이터베이스 생성)
- Hive 테이블 수: 약 1,300개
OASIS 이용 현황 및 도입 효과
2018년 4월, 데이터를 전사적으로 공개한 후, 제공 대상 서비스 및 부서를 점차 확대하고 있으며, 이 글을 작성하는 현재 약 20개의 서비스와 부서에서 이용하고 있습니다. 월간 이용자 수는 약 200명입니다. 서비스의 각종 KPI 가시화, AB 테스트 실시 현황 대시보드 구축, 노트북 자동 실행 기능을 이용한 간이 ETL 실시, 특정 데이터에 대한 모니터링 및 이상 감지(임계치를 넘었을 경우 사내 메신저에 알림 전송) 등 다양한 용도로 OASIS가 활용되고 있습니다. 릴리스 이후 약 두 달만에 이미 활발하게 이용 중인 부서도 있으며, 직접 리포트를 만들어 운영에 활용하고 있습니다.
필요한 내용을 필요한 시점에 각 부서에서 직접 작성할 수 있기 때문에, 서비스의 진행 속도에 맞춰 데이터를 빠르게 활용하거나 LINE Data Labs에 요청하기는 애매하지만 궁금했던 데이터를 스팟 분석하는 등의 업무를 더 부담 없이 할 수 있게 되었습니다. 각 부서가 자체적으로, 또한 주도적으로 필요한 데이터를 신속하게 활용하는 문화가 시작된 것이지요.
마치며
이상으로 LINE Data Labs에서 2017년 말부터 진행한 'LINE 직원 누구나 데이터 분석할 수 있는 환경 구축하기' 활동에 대해 소개했습니다. 이번 활동 내용은 아래 해외 컨퍼런스에서도 발표할 예정입니다.
- DataEngConf Europe, 2018/09/25~26, 바르셀로나
- Spark + AI Summit Europe, 2018/10/02~04, 런던
참고로, LINE Data Labs에서는 데이터 분석 및 활용이라는 측면에서 LINE의 각 서비스를 지원하는 일에 관심 있는 분들을 모집하고 있습니다. LINE에서는 신규 서비스와 프로젝트가 계속해서 시작되고 있습니다. 이에 따라 데이터 분석 및 활용과 관련된 활동과 과제가 증가하고 있는 반면, 일손은 매우 부족한 상황입니다. 관심 있는 분들은 아래 채용 공고를 통해 지원해 주시기 바랍니다. 지원하기 전에 먼저 부담 없이 이야기를 들으며 현장 분위기나 업무 내용을 알고 싶으신 분도 대환영입니다.
- [LINE PLUS] 빅데이터 플랫폼 운영/개발 - 한국
- [LINE PLUS] 게임 데이터 분석 - 한국
- [LINE PLUS] LINE 데이터 분석 & Anomaly Detection - 한국
- 머신 러닝 엔지니어 - 도쿄
- 프로젝트 매니저(머신 러닝) - 도쿄
- 데이터 사이언티스트/데이터 애널리스트 - 도쿄
- 프로젝트 매니저(데이터 분석) - 도쿄
- 데이터 플래너 - 도쿄
- 프런트엔드 엔지니어 - 도쿄
- 서버 엔지니어/데이터 엔지니어 - 도쿄