
この記事は、 LINE Engineering Blog 「夏休みの自由研究 -Summer Homework-」 の 2 日目の記事です。
LINE Data Labs のデータエンジニアの吉田啓二です。昨年から行っている「 LINE の全社員が必要に応じて担当サービスのデータを分析できる環境を構築・提供する」という取り組みをご紹介します。
LINE Data Labs とは
LINE Data Labsは、 LINE の各サービスのデータの収集・処理・集計・分析を専門的に行うことで、データの分析・活用という側面から各サービスの成長を支えることを目的とした部署です。Hadoop クラスタへの各サービスデータの収集、データを集計・可視化する BI/レポーティングツールの提供、データ分析による各サービスの状態把握・意思決定支援、各サービスの価値向上を目的とした機械学習の適用など、データに関する多岐に渡る業務を、合計約 50 名の機械学習エンジニア・データサイエンティスト・データプランナー・データエンジニアが、お互いに協力して遂行しています。
BI/レポーティングツール提供業務の課題
LINE Data Labs の業務の一つとして、サービス側への BI/レポーティングツールの提供があります。これは、 LINE Data Labs の Hadoop クラスタに蓄積されている各サービスデータを集計して可視化するレポートを IBM Cognos / Tableau 上で作成してサービス側へ提供することで、サービス側のプロダクトマネージャーや営業、企画、エンジニアなどのメンバーが、担当サービスのユーザ数や売り上げなどの KPI を定常的にモニタリングできるようにすることを目的としたものです。最初に LINE Data Labs のデータプランナーとサービス側の担当者がモニタリング対象の KPI およびレポートの仕様を決め、次に LINE Data Labs のデータエンジニアがサービス側のデータを Hadoop クラスタへ収集して加工・集計する ETL を開発し、最後に LINE Data Labs のデータプランナーが IBM Cognos / Tableau 上でレポートを作成してサービス側へ提供する、という流れで業務が進行します。

サービス側のメンバーは、 LINE Data Labs の Hadoop クラスタへのアクセス権限が与えられておらず、 LINE Data Labs から提供されるレポートしか閲覧することができないため、サービス側で自由にサービスに関するデータを分析してレポートを作成することができないという課題がありました。
Hadoop クラスタのデータの全社公開
この課題を解消して各サービス側の分析・レポーティング業務を効率化させるために、 LINE Data Labs で管理している Hadoop クラスタのデータを LINE 全社へ公開するという取り組みが昨年後半から始まりました。主な要件としては以下のものがありました。
- セキュリティ
- 各ユーザ( LINE 社員)は、認可されている(自分が担当しているサービス等の)データへのみアクセス可能であること(なお、 Hadoop クラスタへインポート/または抽出されるユーザーデータに関しては個人情報保護の関連から従来から統制が行われており、公開にあたっても統制を継続維持しています。)
- 安定性
- 特定のユーザが処理負荷の高いクエリ・アプリケーションを Hadoop クラスタ上で実行したとしても、それが他のクエリ・アプリケーションの実行・性能に影響を与えないこと
- 利用者数が増加しても安定してサービスを提供できること(最大ユーザ数 = LINE 社員数 = 2018 年 4 月 30 日時点で 1,692 名)
- 機能
- ユーザがクエリ・アプリケーションを書いて Hadoop クラスタからデータ抽出を行えること
- データ抽出結果を表形式またはグラフで可視化できること
- 複数のデータ抽出結果を束ねてレポートを作成できること
- 作成したレポートを同じサービス・部署内のメンバ間で共有できること
- 任意のスケジュールでレポートを自動的に更新して、常に最新のデータがレポートに反映されるようにできること
- 作成済みのレポートについて、集計対象期間などのパラメータを変更して再描画できること
前述の「1. セキュリティ」については、 Hadoop クラスタに Kerberos 認証を導入し、 Apache Ranger で各ユーザがどの HDFS パスへアクセスできるかを制御することで対応することにしました。また、「2. 安定性」の要件を満たすために、 Hadoop YARN クラスタ上で YARN アプリケーションとして実行できる Apache Spark をクエリ・アプリケーションの実行エンジンとして採用することにしました。エンドユーザ向けの Web インターフェースについては、
- User impersonation 機能を使用して、エンドユーザアカウントで Spark アプリケーションを実行できる( HDFS ファイルアクセス時に Apace Ranger ACL を適用できるようにするため)
- ドキュメントを読む限り、前述の「3. 機能」であげた要件のほぼ全てを満たせそうである
という理由で Apache Zeppelin を採用することにし、 LINE Data Labs 内部でのテスト運用を進めることにしました。テスト運用時のシステム構成は以下の通りです。

Hadoop クラスタデータ全社公開インタフェースとして我々が求めていたものと Apache Zeppelin のギャップ
テスト運用を進める中で、 Hadoop クラスタのデータを全社公開するためのエンドユーザ向けインターフェースとして今回我々が求めていたものと、 Apache Zeppelin の機能・思想の間で、いくつか乖離があることがわかりました。具体的には、 Apache Zeppelin の以下の部分が、今回の我々の用途にうまくフィットしないということがわかりました。なお、このテスト運用時に使用していた Apache Zeppelin のバージョンは、当時の最新版であった 0.7.3 です。本記事執筆時点の最新版の 0.8.0 で解消・改善されている部分があるかもしれませんので、その点ご留意いただければと思います。
- セキュリティ
- Notebook のスケジュール自動実行時の実行アカウントに自分以外の任意のユーザを設定できてしまうため、これを利用して任意のユーザで Spark アプリケーションを実行することで、 Apache Ranger ACL で自分のアカウントがアクセス不可となっているデータに対してアクセスすることができてしまう。
- 同様に、スケジュール自動実行時の実行アカウントに他人が設定されている Notebook について、その中の Spark アプリケーションコードを編集できてしまうため、これを利用して任意のユーザで Spark アプリケーションを実行することで、 Apache Ranger ACL で自分のアカウントがアクセス不可となっているデータに対してアクセスすることができてしまう。
- 安定性
- Apache Zeppelin を単一のサーバでしか動かせず、かつ、 yarn-client モードでの Spark アプリケーション実行しかサポートされていないため、特定の Spark アプリケーションの driver program の処理負荷が高くなると、サーバ全体が高負荷になり、 Apache Zeppelin の動作が不安定になってしまう。
- Apache Livy および Livy Interpreter を使用することで yarn-cluster モードでの Spark アプリケーション実行が可能にはなるが、そのかわりに「同一 Notebook 内であっても Spark SQL, PySpark, SparkR が別々の Spark アプリケーションとして実行されてしまう」、「同一 Livy セッション内で複数のジョブを並行して実行させることができず、 Spark でサポートされている同一 Spark アプリケーション内でのジョブ並行実行の仕組み(fair scheduler, fair pool)を活用することができず、アプリケーションを効率的に実行することができない」といった機能面での別の課題が発生してしまう。
- Notebook の実行と Interpreter の停止が同時に実行されると、 Apache Zeppelin JVM で deadlock が発生し、 Apache Zeppelin を再起動するまでサービス全体が無反応となってしまう。
- 機能面
- Notebook 単位でしか Notebook のアクセス制御 (read, write) を実施できないため、 Notebook 作成のたびにアクセス制御を設定しなければならず、エンドユーザの操作負荷が高くなってしまう。
- Notebook ページの参照モードと編集モードが分かれておらず、分析のために作成済みの Notebook に対して一時的に集計対象期間などのパラメータを変更して実行したり、グラフのレイアウトを変えたりすると、その変更内容が即座に保存されてしまう。
Apache Zeppelin を使用したテスト運用を行っている中でこのような課題を見つけるたびに、以下のような JIRA Issue, GitHub Pull Request を作成して Apache Zeppelin へコントリビュートし、我々の用途でも Apache Zeppelin を問題なく使えるようにしようとしていました。
- ZEPPELIN-2950 : JIRA, GitHub
- ZEPPELIN-2995 : JIRA, GitHub
- ZEPPELIN-2997 : JIRA
- ZEPPELIN-3022 : JIRA, GitHub
- ZEPPELIN-3045 : JIRA, GitHub
- ZEPPELIN-3048 : JIRA, GitHub
- ZEPPELIN-3049 : JIRA, GitHub
- ZEPPELIN-3054 : JIRA, GitHub
- ZEPPELIN-3066 : JIRA, GitHub
- ZEPPELIN-3077 : JIRA, GitHub
しかしながら、権限制御の修正が Apache Zeppelin の今までの設計思想に反しているということで受け入れられなかったり、また、 Apache Zeppelin のバージョンアップ・リリースの頻度が年 2 回ほどと少なく、公式リポジトリを社内リポジトリへ folk し、リリース前の修正をそこへバックポートして社内で使用する必要があるために運用・管理コストが高くなったりし、今回の我々の取り組みで Apache Zeppelin を使用し続けることが難しいと考えるようになりました。
そのため、 Hadoop クラスタのデータを全社公開するためのエンドユーザ向けの Web インターフェースを、我々でゼロから新規に開発することにしました。
OASIS
そこで開発したものが "OASIS" という Web インターフェースです。 Apache Zeppelin の機能・操作性を参考にしながら、 LINE 全社員が使用するツールということで、権限制御を厳密に行うことと、利用者数が増加しても安定して稼働させられることを最も重視して開発を行いました。
ページイメージ
以下 3 つのページのイメージをご紹介します。
1. トップページ
「スペース」という Notebook やディレクトリをまとめて管理するルートディレクトリの一覧が表示されるページです。LINE のサービスや部署ごとにスペースが設けられ、このスペース単位で権限制御が実施されます。( A さんは "Data Labs" のスペース内の Notebook へアクセスできる、など)

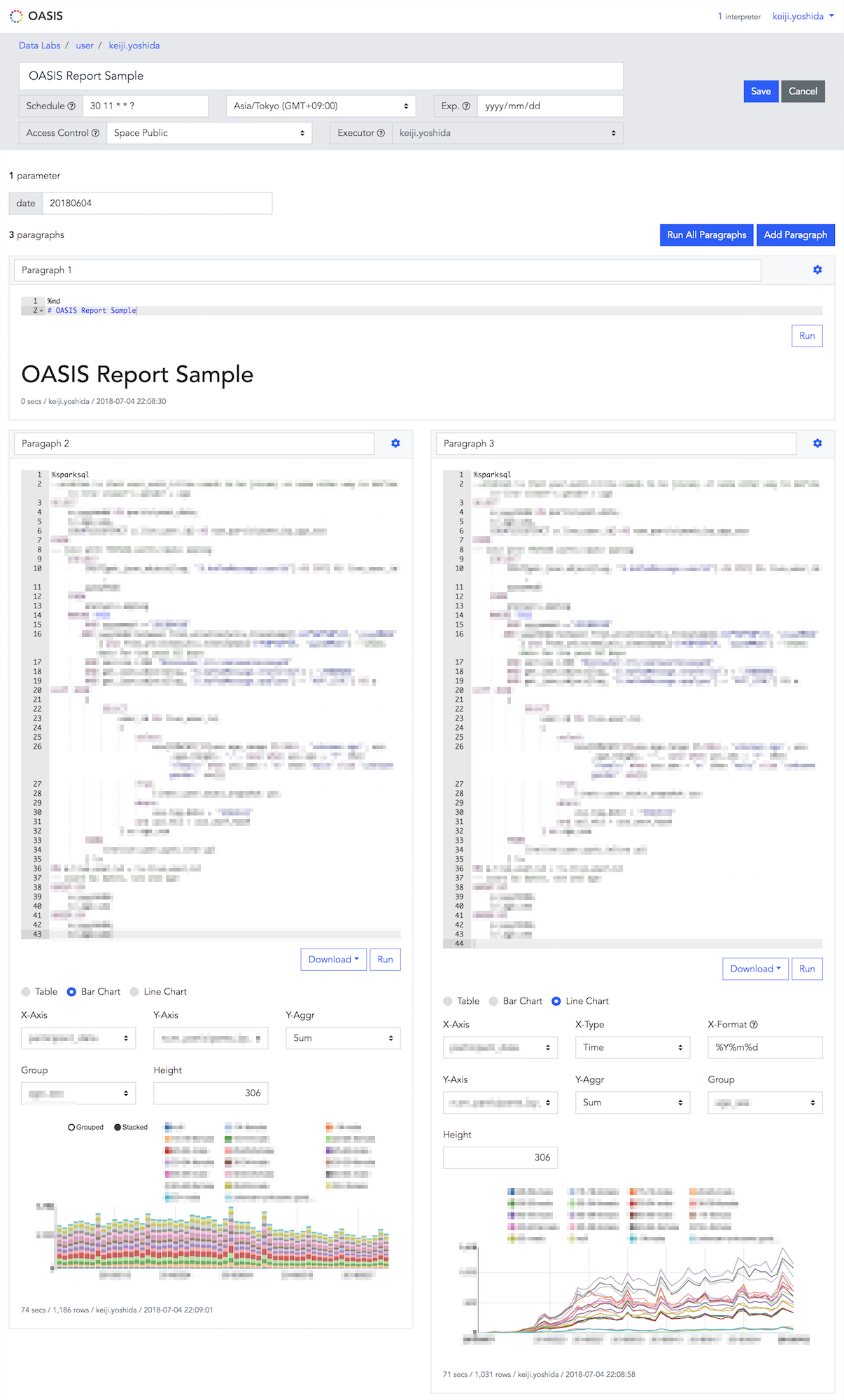
2. Notebook 参照ページ
作成済みの Notebook を閲覧するためのページです。集計対象期間などのパラメータを変更して Notebook を再実行・再描画したり、グラフのフォーマットを変更したりすることができます。

3. Notebook 編集ページ
Notebook の新規作成・編集を行うためのページです。
機能概要
OASIS の主な機能は以下の通りです。
- Apache Spark アプリケーション (Spark, Spark SQL, PySpark, SparkR) および Presto クエリの実行が可能。
- 同一 Notebook 内の Spark, Spark SQL, PySpark, SparkR で同一の Spark アプリケーションが共有されるため、例えば、 PySpark の演算結果を SparkR で処理し、最終結果を Spark SQL で抽出してグラフ化するというような、 3 つのプログラミング言語をまたいで同一のデータセットを処理することが可能。
- Apache Spark のメモリキャッシュ機能を活用し、同一 Notebook 内で、 Spark SQL のクエリの実行結果を別のクエリでも参照したい場合に、クエリの実行結果をメモリキャッシュにのせることで、別のクエリからはメモリキャッシュへアクセスして高速にデータを抽出することが可能。(同一のデータソースに対して様々なディメンションで集計したり、グラフ化したりするような Notebook を効率的に作成することが可能。)
- Notebook 保存時に Apache Spark アプリケーション (Spark SQL, PySpark, SparkR) および Presto クエリの実行結果も含めて保存されるため、 Notebook 閲覧時には Hadoop クラスタへのアクセスがなく即座に Notebook の内容が表示される。
- Notebook を特定の日時や周期で自動的に実行することが可能。これにより、 Notebook の表示内容を常に最新に保ったり、エンドユーザ側で簡易的に ETL を実装したりすることが可能となる。
- Spark SQL の実行結果を表形式・棒グラフ・折れ線グラフで表示することが可能。
- Spark SQL の実行結果を CSV/TSV ファイルとしてダウンロードすることが可能。
- HDFS の操作(ファイルのアップロード・ダウンロードなど)が可能。( Ambari Files View 相当の機能が利用可能。)
- Hive データベース・テーブルの一覧、および各テーブルの定義を確認することが可能。
- CSV/TSV ファイルをアップロードすることで Hive テーブルを作成することが可能。
- 以下の 3 段階で Notebook のアクセス制御が実施可能。
- Private : 作成者のみアクセス可能
- Space Public : その Notebook が属する Space へのアクセス権のあるユーザ全てがアクセス可能
- Space Public (Read Only) : その Notebook が属する Space へのアクセス権のあるユーザ全てがアクセス可能であるが、最終更新者のみがその Notebook を編集可能
- Notebook の複製および上書きが可能。これにより、レポートとして公開されている Notebook を時間をかけて編集し、あるタイミングで更新したい場合に、一度その Notebook を複製して別の Notebook で編集作業を行い、更新したいタイミングで上書き機能を使って、編集作業を行っていた Notebook の内容をもとの Notebook へ上書いてリリースする、というようなことが可能となる。
システム構成
OASIS のシステム構成の概要は以下の通りです。主なコンポーネントとして Frontend/API, Job Scheduler, Spark/Presto Interpreter の 3 つがあり、いずれも利用者数の増加にスケールアウトで対応できるようになっています。また、 Notebook 編集中の未保存の Apache Spark アプリケーションおよび Presto クエリの実行結果の格納先として Redis を、実行結果を含む Notebook の保存内容の格納先として MySQL をそれぞれ使用しています。簡略化のため省略していますが、この他にも LINE 社内の認証・シングルサインオンシステムと、 HDFS 操作を行うための API サーバを別途使用・構築しています。

なお、 LINE Data Labs で管理している Hadoop クラスタの、本記事執筆時点のスペックの概要は以下の通りです。
- DataNode/NodeManager 数: 500 台
- HDFS の使用容量: 約 20 PB
- Hive データベース数: 約 70 個(サービス単位でデータベースを作成)
- Hive テーブル数: 約 1,300 個
OASIS の利用状況・導入効果
今年 4 月から全社公開を開始して徐々に提供先サービス・部署を増やしており、本記事執筆時点で約 20 のサービス・部署で利用され、月間利用者数は約 200 人となっています。サービスの各種 KPI の可視化や、 AB テスト実施状況のダッシュボード構築、 Notebook スケジュール実行機能を利用した簡易 ETL の実施、特定のデータのモニタリング・異常検知(閾値を超えていれば社内 Slack へ通知)など、様々な用途で OASIS が利用されています。
リリース後 2 ヶ月程度ですでに活発に利用している部署もあり、自前でレポートを作成し運用に役立てています。
必要なものを必要な時に、各部署の手で作成できるため、サービス速度に合わせたスピーディなデータ活用、LINE Data Labs に頼むには微妙だが気になるデータの spot 分析などをより気軽に行える状態となりました。
各部署が主体となり、必要なデータをスピーディに活用できる文化がスタートしています。
最後に
本記事では、 LINE Data Labs で昨年末から行っていた LINE 全社員向けのデータ分析環境構築の取り組みをご紹介しました。今回の取り組みについては、以下の海外カンファレンスでも発表する予定でいます。
- DataEngConf Europe, 2018/09/25-26, バルセロナ
- Spark + AI Summit Europe, 2018/10/02-04, ロンドン
また、 LINE Data Labs では、 LINE の各サービスをデータの分析・活用という側面から支援することに興味・関心がある方を募集しています。 LINE では、新規サービス・プロジェクトが次々と立ち上がっており、それに応じてデータ分析・活用に関する取り組み・案件が増えている一方で、 LINE Data Labs の人手が全く足りていない状況です。少しでも興味・関心がある方は、以下よりご応募いただけましたら幸いです。「本申し込みの前に、まずはカジュアルにお話を聞いて、現場の雰囲気や仕事内容を知りたい」という方も大歓迎です。
- 機械学習エンジニア
- プロジェクトマネージャー(機械学習)
- データサイエンティスト・データアナリスト
- プロジェクトマネージャー(データ分析)
- データプランナー
- フロントエンドエンジニア
- サーバサイドエンジニア・データエンジニア
明日は keigohtr さんによる「Clovaにおける機械学習モジュールの管理運用基盤Druckerについて」です。お楽しみに!