
안녕하세요. LINE Data Labs에서 데이터 엔지니어로 일하고 있는 Keiji Yoshida입니다. 저는 이번 글에서 데이터 엔지니어링 관련 소프트웨어 장애 대응 사례를 몇 가지 소개하고자 합니다.
Apache Hadoop YARN 리소스 매니저 failover 발생 문제와 해결 방안
시스템 개요
LINE Data Labs가 관리하는 Hadoop 클러스터 가운데 각 LINE 서비스의 데이터를 수집하여 하나로 모아 관리하는 것이 있습니다. 각 LINE 서비스의 데이터는 Apache Sqoop 등을 사용하여 HDFS에 저장됩니다. YARN 클러스터에서는 MapReduce, TEZ, Spark 등의 애플리케이션이 실행되며 데이터 집계 및 가공 등을 처리합니다. 시스템 구성은 아래와 같습니다.
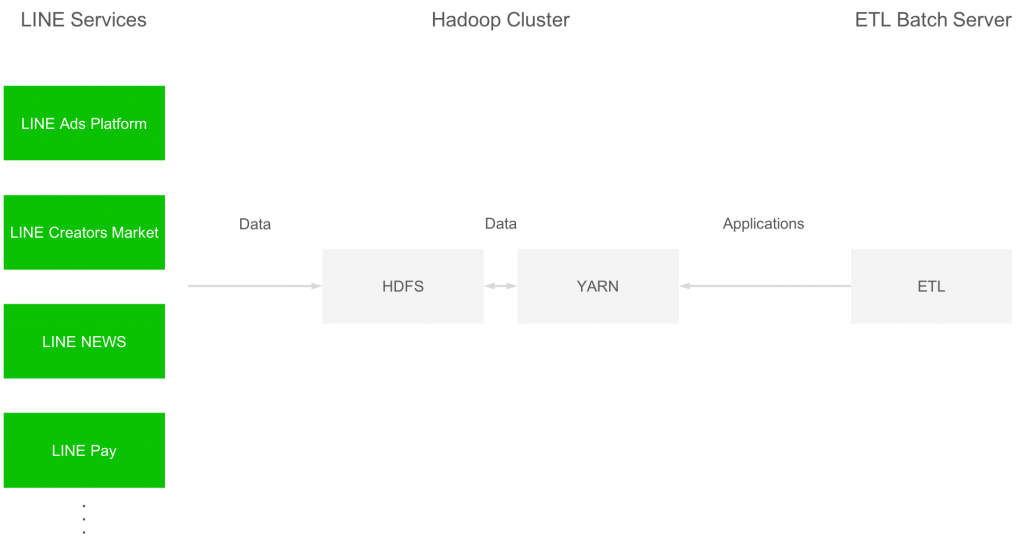
본 Hadoop 클러스터는 HDP-2.6.2.0(2.6.2.0-205)로 구축되었고, YARN 버전은 2.7.3입니다.
발생한 현상
Hadoop 클러스터를 구축, 가동한 후 Hadoop 클러스터에서 실행되는 애플리케이션 수가 늘어난 상태에서 HA(high availability)로 구성된 YARN 클러스터의 리소스 매니저에 여러 번 failover가 발생했습니다. Failover가 발생했을 때 액티브 리소스 매니저 로그에는 아래 정보가 출력되었습니다.
WARN resourcemanager.EmbeddedElectorService (EmbeddedElectorService.java:enterNeutralMode(175)) - Lost contact with Zookeeper. Transitioning to standby in 10000 ms if connection is not reestablished.
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1070)) - Transitioning to standby state
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1077)) - Transitioned to standby state
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1066)) - Already in standby state이 로그를 보면 액티브 리소스 매니저에서 heartbeat를 Apache ZooKeeper 클러스터로 규정 시간 내(본 Hadoop 클러스터에서는 yarn.resourcemanager.zk-timeout-ms = 10000으로 설정)에 전송하지 못했던 것이 failover의 직접적인 원인이 되었던 것 같았습니다. 그래서 액티브 리소스 매니저가 heartbeat를 ZooKeeper로 규정 시간 내에 전송하지 못한 이유를 조사하기로 했습니다.
원인 조사
로그 확인
액티브 리소스 매니저의 GC(Garbage Collector) 로그를 확인해보니 failover가 발생했을 때 JVM이 장시간 정지한 기록은 없어서 GC가 원인일 가능성은 없었습니다. 그리고 CPU 사용률 등 서버 자원 사용 현황도 평소와 큰 차이가 없는 것으로 미루어 보아 ZooKeeper로 heartbeat를 규정 시간 내에 전송할 수 없었던 이유가 리소스 매니저의 내부 처리에 있을 것이라고 생각했습니다.
Failover 발생 시의 액티브 리소스 매니저 로그를 살펴보니 아래와 같은 정보가 대량으로 출력되어 있었습니다.
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 1000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 2000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 3000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 4000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 5000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 6000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 7000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 8000
...이와 같은 로그 정보는 org.apache.hadoop.yarn.event.AsyncDispatcher의 내부 처리(참고)로 출력되었고 failover 발생 직전에는 출력되는 Size of event-queue의 값이 약 400,000까지 증가했습니다. 평소에는 거의 출력되지 않는 로그였습니다. 당시에는 이 로그가 failover와 관련이 있다고 확신할 수 없었기 때문에 이 event-queue가 무엇인지 파악하기 위해 리소스 매니저의 소스 코드를 조사하기로 했습니다.
리소스 매니저의 이벤트 처리 구조 확인
리소스 매니저의 AsyncDispatcher에서는 아래와 같이 YARN 애플리케이션에 관한 다양한 이벤트(애플리케이션의 시작, 종료나 컨테이너의 실행, 폐기 등)를 LinkedBlockingQueue를 이용하여 처리하고 있었습니다.

우선 애플리케이션의 시작, 종료나 컨테이너의 실행, 폐기 등이 발생하면 그 이벤트가 GenericEventHandler#handle 메서드로 전달되어 메서드 내에서 LinkedBlockingQueue에 등록(참고)되었습니다. 그리고 다른 스레드(thread)에서 이 LinkedBlockingQueue에 등록된 이벤트를 순차적으로 수집(참고)하고 해당 이벤트 종류에 맞는 이벤트 핸들러(EventHandler)의 처리 메서드를 실행(참고)하여 처리하고 있었습니다. 처리하는 이벤트 종류와 담당 이벤트 핸들러는 리소스 매니저의 로그를 확인한 결과 다음과 같았습니다.
처리하는 이벤트 종류와 담당 이벤트 핸들러
"Size of event-queue is 1000"과 같은 로그는 GenericEventHandler#handle에서 이벤트를 LinkedBlockingQueue에 등록하기 직전에 출력(참고)되었고, failover가 일어나기 직전에는 약 400,000개의 이벤트가 처리되지 않은 채로 LinkedBlockingQueue 내에 머물러 있었습니다.
리소스 매니저에서 ZooKeeper로 heartbeat를 전송하는 건 리소스 매니저 내의 ZooKeeper 클라이언트인 ClientCnxn이라는 클래스의 SendThread라는 스레드인데요(참고). 아직 이벤트가 이 스레드와 어떤 관련이 있는지 명확하게 파악된 게 아니기 때문에 '대량의 이벤트가 LinkedBlockingQueue 내에 머물러 있다'는 것이 '리소스 매니저에서 ZooKeeper로 heartbeat를 규정 시간 내에 전송할 수 없었다'는 것과 어떤 관련이 있는지 더 조사했습니다.
JMX metrics 모니터링
리소스 매니저의 JVM 내부 상태가 평소와 failover 발생 시에 차이가 있는지 확인하기 위해, Prometheus JMX Exporter를 도입하여 Grafana에서 각종 수치를 시계열로 그래프화하기로 했습니다.
Failover가 발생했을 때 리소스 매니저의 JVM 스레드 개수를 살펴보니 아래와 같이 평소와 비교해 급격하게 증가한 것을 알 수 있었습니다.
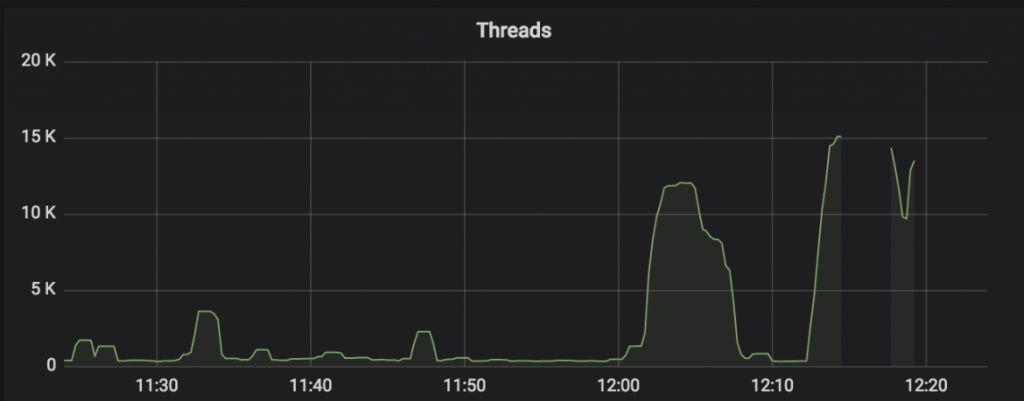
그래프의 오른쪽 끝에 해당하는 12:20 즈음 리소스 매니저에서 failover가 발생했는데요. 평소에는 스레드 개수가 1,000개 미만이었지만 failover 발생 직전에는 15,000개 정도까지 증가한 것을 볼 수 있습니다.
스레드 정보 확인
Failover 발생 전 어떤 스레드가 증가했는지 확인하기 위해 failover가 발생하기 직전(경험을 통해 Size of event-queue 값이 10,000을 넘으면 failover가 발생할 가능성이 있다는 것을 알고 있었음) 스레드 덤프를 수집하여 내용을 확인해봤습니다. 스레드의 이름별 개수는 아래와 같았습니다.
| 스레드명 | 개수 | 비율 |
|---|---|---|
| RegistryAdminService | 13,989 | 97.6 % |
| IPC Server handler | 155 | 1.1 % |
| ApplicationMasterLauncher | 50 | 0.3 % |
| AsyncDispatcher event handler | 13 | 0.1 % |
| 기타 | 127 | 0.9 % |
| 합계 | 14,334 | 100.0 % |
위와 같이 failover 발생 직전에는 RegistryAdminService라는 이름의 스레드가 전체 스레드 개수의 대부분(97.6 %)을 차지하고 있었습니다.
RegistryAdminService 스레드
이번에는 RegistryAdminService 스레드는 어떤 것인지 확인하기로 했습니다. 이 스레드는 RMRegistryService 클래스에서 아래 4가지 이벤트를 처리하기 위해 생성되었습니다.
RMStateStore에 애플리케이션 정보 등록 시(eventTypeRMStateStoreEventType.STORE_APP발생 시)RegistryAdminService스레드를 생성하고, ZooKeeper에 사용자 디렉터리/registry/users/{username}을 만든다.- 애플리케이션 Attempt 삭제 시(
eventTypeRMAppAttemptEventType.UNREGISTERED발생 시)RegistryAdminService스레드를 생성하고, ZooKeeper에서/registry아래에 있는 appattempt id(appattempt_1523336070074_12345_000001등)에 대응하는 기록을 삭제한다. - 애플리케이션 완료 시(
eventTypeRMAppManagerEventType.APP_COMPLETED발생 시)에RegistryAdminService스레드를 생성하고, ZooKeeper에서/registry아래에 있는 애플리케이션 id(application_1523336070074_12345등)에 대응하는 기록을 삭제한다. - 컨테이너 정지 시(
eventTypeRMAppAttemptEventType.CONTAINER_FINISHED혹은RMContainerEventType.FINISHED발생 시)에RegistryAdminService스레드를 생성하고, ZooKeeper에서/registry아래에 있는 컨테이너 id(container_e102_1523336070074_12346_01_000221등)에 대응하는 기록을 삭제한다.
실제 운용해보니 위 4가지 이벤트 처리 중 가장 많이 실행되는 것은 4번째 항목인 '컨테이너 정지 시의 이벤트 처리'입니다. 예를 들어 컨테이너 1,000개를 사용하는 MapReduce job이 종료되면 컨테이너 1,000개가 정지하면서 1,000개의 이벤트가 동시에 발생하여 '리소스 매니저의 이벤트 처리 구조'에서 언급한 LinkedBlockingQueue에 등록됩니다. 이 이벤트들이 순차적으로 AsyncDispatcher에 보내져 4번째 항목의 이벤트 처리가 실행되고, 이벤트별로 RegistryAdminService 스레드가 생성되어 ZooKeeper에 기록 삭제 요청이 전송됩니다. 그리고 리소스 매니저에서 ZooKeeper로 전송하는 요청은 ZooKeeper 클라이언트의 ClientCnxn에서 단일 스레드로 실행(참고)되기 때문에 대량의 컨테이너가 정지하면 컨테이너 수 만큼 RegistryAdminService 스레드가 생성됩니다. 이 때문에 ZooKeeper로 향하는 요청 전송에 병목현상이 일어나고 대량의 RegistryAdminService 스레드가 ZooKeeper 요청 전송 완료 대기 상태로 남아있게 됩니다.

조치 방안
리소스 매니저의 소스 코드를 보니 RegistryAdminService 스레드를 생성하는 RMRegistryService 클래스(참고)의 4가지 이벤트 핸들링 처리는 YARN 설정 hadoop.registry.rm.enabled 값이 true일 때만 수행된다는 것을 알 수 있었습니다(참고). 이 설정값이 true면 YARN Service Registry(YARN 애플리케이션끼리 서로 통신하기 위한 구조)를 사용하기 위해, 리소스 매니저의 이벤트 처리로 앞서 말한 4가지가 추가되는 것 같았습니다. Ambari를 이용하여 Hadoop 클러스터를 구축하면서 각종 컴포넌트를 설치할 때 자동으로 true로 설정된 것으로 보입니다. 우리 시스템에서는 YARN Service Registry를 이용할 필요가 없기 때문에 hadoop.registry.rm.enabled값을 false로 변경하여 대량의 컨테이너가 동시에 정지해도 RegistryAdminService 스레드가 생성되지 않도록 조치했고, 정말 리소스 매니저의 failover가 발생하지 않는지 검증하였습니다.
YARN의 hadoop.registry.rm.enabled 설정값을 false로 변경한 뒤 잠시 상황을 지켜보기도 하고, 컨테이너 수천 개를 사용하는 MapReduce job을 의도적으로 여러 번 실행해보기도 했습니다. 그 결과 아래 그래프와 같이 JVM 스레드 수는 항상 300 개 정도에 리소스 매니저의 failover도 발생하지 않고 안정적으로 실행되는 것을 확인했습니다.

이 사이트를 보면 이번에 경험한 것과 유사한 내용이 나오는데요. YARN Service Registry를 이용하다 보면 리소스 매니저와 ZooKeeper 간 통신에 문제가 발생해서 heartbeat가 타임아웃되고 리소스 매니저가 failover되는 것은 이미 알려진 현상이었습니다.
Apache Hadoop HDFS NameNode failover 발생 문제와 해결 방안
시스템 개요
LINE Data Labs가 관리하는 Hadoop 클러스터 중에 fluentd를 이용해서 각 서버의 접속 로그와 애플리케이션 로그를 수집하는 클러스터가 있습니다. 이 로그 데이터는 매 시간 ETL(extract, transform, load) 배치 처리로 Apache Hive 테이블에 등록됩니다. 시스템 구성은 아래와 같습니다.
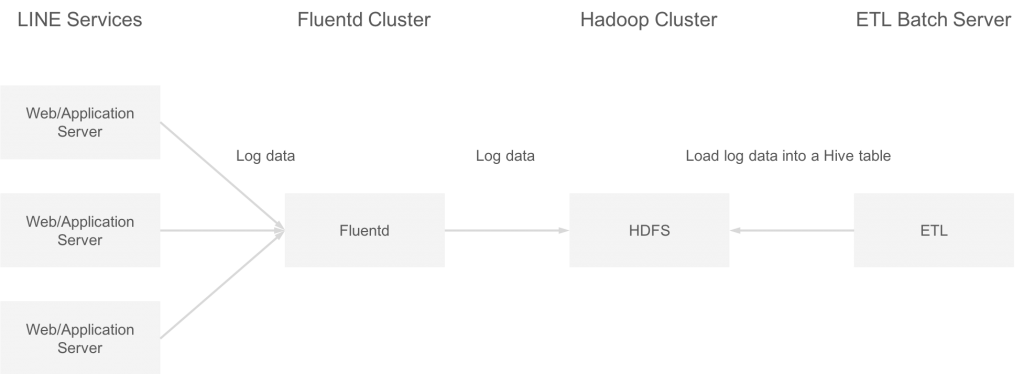
본 Hadoop 클러스터는 HDP-2.6.1.0 (2.6.1.0-129)로 구축되었고, HDFS 버전은 2.7.3입니다.
데이터 흐름
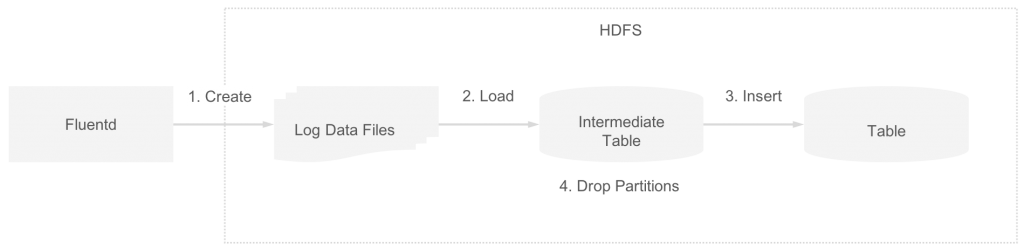
로그 데이터를 Hive 테이블에 등록할 때 데이터의 흐름은 다음과 같습니다.
- 로그 데이터 파일이 fluentd에서 HDFS의 디렉터리에 저장된다.
- Hive
LOAD DATA문을 실행하여 로그 데이터 파일을 중간(intermediate) 테이블 디렉터리로 이동시킨다. - Hive
INSERT ... SELECT문을 실행하여 중간 테이블의 데이터가 최종 테이블에 등록된다(파일 포맷을 변경). - Hive
ALTER TABLE ... DROP PARTITION문을 실행하여 중간 테이블에 로드된 로그 데이터 파일이 삭제된다.
발생한 현상
HA 구성에 속하는 HDFS의 NameNode에 특정 시간대(오전 9시쯤)에 가끔씩 failover가 발생했습니다. Failover 발생 시의 ZooKeeper Failover Controller 로그를 살펴보니 아래와 같은 로그가 출력되었습니다.
09:03:08,165 WARN ha.HealthMonitor (HealthMonitor.java:doHealthChecks(211)) - Transport-level exception trying to monitor health of NameNode at xxxx/xxx.xxx.xxx.xxx:xxxx: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/xxx.xxx.xxx.xxx:xxxx remote=xxxx/xxx.xxx.xxx.xxx:xxxx] Call From xxxx/xxx.xxx.xxx.xxx to xxxx:xxxx failed on socket timeout exception: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/xxx.xxx.xxx.xxx:xxxx remote=xxxx/xxx.xxx.xxx.xxx:xxxx]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout로그를 보면 ZooKeeper Failover Controller에서 NameNode 헬스 체크(health check)가 타임아웃(60초)되면서 failover가 발생한 것 같았습니다. 그래서 NameNode쪽 로그와 처리내용을 조사하여 ZooKeeper Failover Controller에서 실시하는 NameNode 헬스 체크가 타임아웃되는 원인을 밝혀내기로 했습니다.
원인 조사
Failover 발생 직전 NameNode 로그를 확인하니 아래와 같은 로그가 출력되었습니다. 이 로그를 보면 .Trash 디렉터리 하위의 각 서브 디렉터리 파일을 삭제하는 처리(참고)가 시작되었고(해당 Hadoop 클러스터에서는 삭제된 로그 데이터 파일이 .Trash 디렉터리로 이동), 그러다 어떤 디렉터리를 삭제(참고)하면서 FSNamesystem write lock이 장시간(약 36초 간) 걸려 있었습니다.
09:00:30,574 INFO fs.TrashPolicyDefault (TrashPolicyDefault.java:deleteCheckpoint(319)) - TrashPolicyDefault#deleteCheckpoint for trashRoot: hdfs://xxxx/user/hive/.Trash
09:01:06,673 INFO namenode.FSNamesystem (FSNamesystem.java:writeUnlock(1659)) - FSNamesystem write lock held for 36094 ms via
java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:945)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1659)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete(FSNamesystem.java:3975)
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.delete(NameNodeRpcServer.java:1078)
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.delete(ClientNamenodeProtocolServerSideTranslatorPB.java:622)
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
java.security.AccessController.doPrivileged(Native Method)
javax.security.auth.Subject.doAs(Subject.java:422)
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 36094그 후에도 아래와 같은 로그가 몇 개 더 출력되었는데요. 내용을 살펴보면 블록을 삭제하기(참고) 위해 1~7초 간 GC(Garbage Collection) pause가 발생하면서 FSNamesystem write lock이 계속해서 걸려 있게 되었습니다.
09:01:17,955 INFO util.JvmPauseMonitor (JvmPauseMonitor.java:run(196)) - Detected pause in JVM or host machine (eg GC): pause of approximately 1487ms
GC pool 'ParNew' had collection(s): count=1 time=1937ms
09:01:17,993 INFO namenode.FSNamesystem (FSNamesystem.java:writeUnlock(1659)) - FSNamesystem write lock held for 2038 ms via
java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:945)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1659)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.removeBlocks(FSNamesystem.java:4009)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete(FSNamesystem.java:3979)
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.delete(NameNodeRpcServer.java:1078)
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.delete(ClientNamenodeProtocolServerSideTranslatorPB.java:622)
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
java.security.AccessController.doPrivileged(Native Method)
javax.security.auth.Subject.doAs(Subject.java:422)
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 2038이런 상황에서 NameNode RPC Client Port 큐(Queue)의 길이를 확인해보았습니다. 파일 블록 삭제로 FSNamesystem write lock이 장시간 걸려 있었기 때문에 아래와 같이 처리 안 된 RPC 호출이 큐에 대량으로(3,500개 정도) 머물러 있는 상태였습니다.

그리고 ZooKeeper Failover Controller의 로그를 확인해보니 NameNode로 헬스 체크 요청을 전송할 때 접속 포트 번호가 RPC 호출이머물러 있는 큐의 포트 번호와 같았습니다. 그래서 헬스 체크 요청이 큐에서 장시간 처리 대기 상태가 되어 타임아웃이 발생하고 NameNode failover가 발생했던 것 같았습니다.
해결 방안
아래 2가지 방안으로 문제를 해결하기로 했습니다.
.Trash 디렉터리 하위 파일의 삭제 간격 단축
원래 fs.trash.interval 값이 4320(분 단위)이어서 3일 간격으로 .Trash 디렉터리 하위에 있는 파일이 삭제되었습니다. 그 값을 1440으로 변경하여 1일 간격으로 삭제되도록 변경했고, 이를 통해 .Trash 디렉터리 하위에 있는 파일 삭제에 수반되는 FSNamesystem의 write lock 잠금 시간이 단축되도록 조치하였습니다.
ZooKeeper에서 NameNode로 헬스 체크 요청하는 port 변경
이 사이트의 내용을 참고하여 Service RPC port라는 ZooKeeper Failover Controller와 DataNode의 헬스 체크(블록 report 포함) 전용 port를 설정할 수 있었습니다. 헬스 체크 전용 port를 사용하면 대량의 파일 삭제 등으로 설령 대량의 RPC 호출이 NameNode의 RPC Client Port 큐에 적체되어 있다고 하더라도, NameNode는 ZooKeeper Failover Controller의 헬스 체크에 지연 없이 정상 응답할 수 있습니다. 따라서 아래와 같은 설정을 추가하여 Service RPC port를 사용하기로 했습니다.
dfs.namenode.servicerpc-address.mycluster.nn1=mynamenode1:8040dfs.namenode.servicerpc-address.mycluster.nn2=mynamenode2:8040
Apache Zeppelin Notebook 스케줄러 작동 이상 문제와 해결 방안
발생한 현상
지금은 사내용 데이터 분석 애플리케이션으로 OASIS라는 것을 자체 개발하여 사용하고 있지만, 개발 전에는 Apache Zeppelin(버전 0.7.3)을 사내에서 제한적으로 제공하여 운용했었는데요. Apache Zeppelin을 운용할 때 각 Notebook의 스케줄이 실행되지 않는 현상이 자주 발생했습니다. 이 현상은 Apache Zeppelin을 재시작하면 해결되었지만, 또 얼마 지나지 않아 재발했습니다.
원인 조사
Apache Zeppelin 로그에서는 원인을 밝혀낼만한 정보를 얻을 수 없어서 Apache Zeppelin JVM 프로세스의 스레드 덤프를 살펴보았습니다. 아래와 같이 Notebook 스케줄을 실행하기 위한 Quartz Scheduler Worker 스레드가 모두 TIMED_WAITING(sleeping) 상태였습니다.
"DefaultQuartzScheduler_Worker-10" #76 prio=5 os_prio=0 tid=0x00007fb41d3b4000 nid=0x1b521 sleeping[0x00007fb3daef1000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7dbf0> (a java.lang.Object)
Locked ownable synchronizers:
- None
"DefaultQuartzScheduler_Worker-9" #75 prio=5 os_prio=0 tid=0x00007fb41d3b2000 nid=0x1b520 waiting on condition [0x00007fb3daff2000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7a470> (a java.lang.Object)
Locked ownable synchronizers:
- None
...
"DefaultQuartzScheduler_Worker-2" #68 prio=5 os_prio=0 tid=0x00007fb41d3c8800 nid=0x1b519 waiting on condition [0x00007fb3da473000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7a7b0> (a java.lang.Object)
Locked ownable synchronizers:
- None
"DefaultQuartzScheduler_Worker-1" #67 prio=5 os_prio=0 tid=0x00007fb41d3cc800 nid=0x1b518 waiting on condition [0x00007fb3da372000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7dd90> (a java.lang.Object)
Locked ownable synchronizers:
- None모든 스레드가 아래와 같이 org.apache.zeppelin.notebook.Notebook$CronJob.execute의 Thread.sleep(1000)에 결려 sleep 상태에 있었습니다.
String noteId = context.getJobDetail().getJobDataMap().getString("noteId");
Note note = notebook.getNote(noteId);
note.runAll();
while (!note.isTerminated()) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
logger.error(e.toString(), e);
}
}처리 내용을 보면, Notebook을 스케줄링했지만 어딘가의 paragraph에서 막혀 Notebook이 실행 완료 상태가 되지 못했고, 그 결과 Thread.sleep(1000)이 계속해서 반복 실행되었습니다. 실행 완료 상태로 가지 못하는 원인을 파악하기 위해 Notebook과 job의 실행 완료를 판정하는 코드를 살펴보았습니다.
Notebook이 실행 완료 상태가 되기 위한 조건은 '그 Notebook의 모든 paragraph가 ready, running, pending 중 어떠한 상태도 아님'이라는 것을 알게 되었습니다. Notebook에 disabled인(실행 불가로 설정되어 있음) paragraph가 존재하면 스케줄 실행 시 해당 paragraph 실행이 스킵(skip) 되어 ready상태로 남게 되는데요. 그래서 Notebook의 실행 완료 상태 조건이 충족되지 못하고 Thread.sleep(1000)구문으로 로직이 진행되어 sleep 상태인 채로 막혀버리게 되는 것입니다.
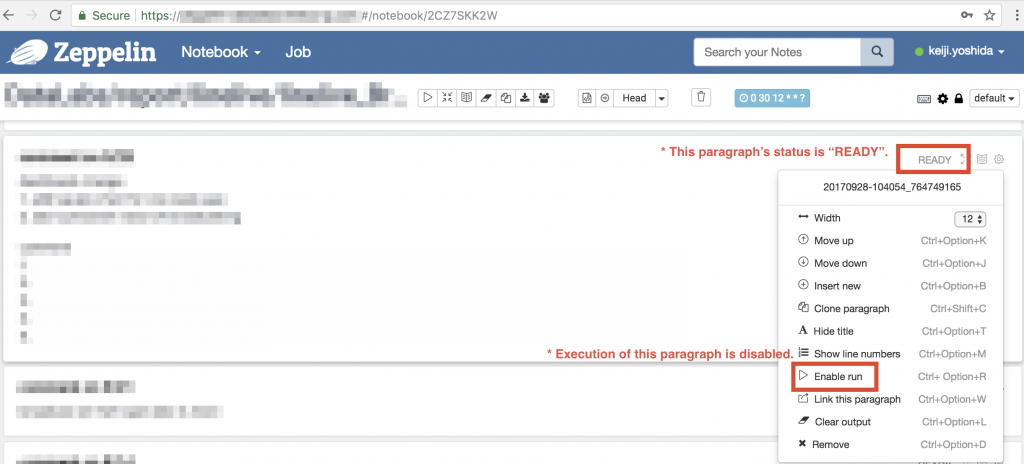
해결 방안
Apache Zeppelin의 GitHub 리포지토리에 이번 장애 발생을 해결하기 위한 풀리퀘스트를 보냈고, 같은 내용의 수정사항을 사내에서 관리하는 Apache Zeppelin 소스 코드에 적용하여 이 문제를 해결했습니다.
Apache Zeppelin deadlock 발생 문제와 해결 방안
발생한 현상
Apache Zeppelin(version 0.7.3)을 운용할 때 갑자기 아무런 응답을 하지 않고 다시 시작할 때까지 전혀 조작할 수 없는 현상이 여러 번 발생했습니다.
원인 조사
Apache Zeppelin 로그에서는 원인을 밝혀낼 만한 정보를 얻을 수 없어서 Apache Zeppelin JVM 프로세스의 스레드 덤프를 살펴봤는데요. 아래와 같이 내부 처리에서 deadlock이 발생한 것을 알 수 있었습니다.
Found one Java-level deadlock:
=============================
"pool-2-thread-63":
waiting to lock monitor 0x00007fd2fc0073e8 (object 0x00000000c04f9c50, a java.util.concurrent.ConcurrentHashMap),
which is held by "DefaultQuartzScheduler_Worker-2"
"DefaultQuartzScheduler_Worker-2":
waiting to lock monitor 0x00007fd28c0036c8 (object 0x00000000c16f4738, a org.apache.zeppelin.notebook.Note),
which is held by "DefaultQuartzScheduler_Worker-4"
"DefaultQuartzScheduler_Worker-4":
waiting to lock monitor 0x00007fd2fc0073e8 (object 0x00000000c04f9c50, a java.util.concurrent.ConcurrentHashMap),
which is held by "DefaultQuartzScheduler_Worker-2"
Java stack information for the threads listed above:
===================================================
"pool-2-thread-63":
at org.apache.zeppelin.interpreter.InterpreterSettingManager.get(InterpreterSettingManager.java:981)
- waiting to lock <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.getInterpreterSettings(InterpreterSettingManager.java:450)
at org.apache.zeppelin.interpreter.InterpreterFactory.getInterpreter(InterpreterFactory.java:382)
at org.apache.zeppelin.notebook.Paragraph.getRepl(Paragraph.java:255)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:361)
at org.apache.zeppelin.scheduler.Job.run(Job.java:175)
at org.apache.zeppelin.scheduler.RemoteScheduler$JobRunner.run(RemoteScheduler.java:329)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"DefaultQuartzScheduler_Worker-2":
at org.apache.zeppelin.notebook.Note.stopDelayedPersistTimer(Note.java:789)
- waiting to lock <0x00000000c16f4738> (a org.apache.zeppelin.notebook.Note)
at org.apache.zeppelin.notebook.Note.persist(Note.java:725)
at org.apache.zeppelin.socket.NotebookServer$ParagraphListenerImpl.afterStatusChange(NotebookServer.java:2070)
at org.apache.zeppelin.scheduler.Job.setStatus(Job.java:149)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.stopJobAllInterpreter(InterpreterSettingManager.java:966)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.restart(InterpreterSettingManager.java:942)
- locked <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.restart(InterpreterSettingManager.java:956)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:907)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0ef6190> (a java.lang.Object)
"DefaultQuartzScheduler_Worker-4":
at org.apache.zeppelin.interpreter.InterpreterSettingManager.get(InterpreterSettingManager.java:981)
- waiting to lock <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.getInterpreterSettings(InterpreterSettingManager.java:450)
at org.apache.zeppelin.interpreter.InterpreterFactory.getInterpreter(InterpreterFactory.java:382)
at org.apache.zeppelin.notebook.Paragraph.isValidInterpreter(Paragraph.java:701)
at org.apache.zeppelin.notebook.Paragraph.getMagic(Paragraph.java:690)
at org.apache.zeppelin.notebook.Paragraph.isBlankParagraph(Paragraph.java:354)
at org.apache.zeppelin.notebook.Note.run(Note.java:609)
at org.apache.zeppelin.notebook.Note.runAll(Note.java:596)
at org.apache.zeppelin.notebook.Note.runAll(Note.java:587)
- locked <0x00000000c16f4738> (a org.apache.zeppelin.notebook.Note)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:885)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0f4b800> (a java.lang.Object)
Found 1 deadlock.
Notebook 스케줄을 실행하는 2개의 스레드DefaultQuartzScheduler_Worker-2와 DefaultQuartzScheduler_Worker-4간에 아래와 같은 deadlock이 발생했던 것 같습니다.
DefaultQuartzScheduler_Worker-2가 Notebook 스케줄 실행 완료 후 인터프리터를 다시 시작한다(참고). 이때Map<String, InterpreterSetting> interpreterSettings에 lock을 건다.DefaultQuartzScheduler_Worker-4가 Notebook 스케줄을 실행한다(참고). 이때 대상Note인스턴스에 lock을 건다.DefaultQuartzScheduler_Worker-2가 인터프리터를 다시 시작하기 위해 실행 중인 Notebook을 정지하고, 이 Notebook의 상태를Abort로 변경하여 보존한다. 이때 두 번째 단계에서DefaultQuartzScheduler_Worker-4가 이미 lock을 걸어놓은Note인스턴스에 lock을 걸기 위해 잠금 대기 상태가 된다.DefaultQuartzScheduler_Worker-4가 Notebook을 실행하기 위해 연결된 인터프리터 정보를 수집할 때 이미 첫 번째 단계에서DefaultQuartzScheduler_Worker-2가 lock을 건Map<String, InterpreterSetting> interpreterSettings에 lock을 걸기 위해 잠금대기 상태가 된다.DefaultQuartzScheduler_Worker-2와DefaultQuartzScheduler_Worker-4사이에 deadlock이 발생한다.
위와 같이 '인터프리터 다시 시작'과 'Notebook 실행'에서 lock을 거는 순서가 반대로('인터프리터 다시 시작'에서는 interpreterSettings -> note 순서로 lock이 걸리고, 'Notebook 실행'에서는 note -> interpreterSettings 순서로 lock이 걸림) 되어 있어서 이 두 가지 처리가 같은 시점에 실행되면 Apache Zeppelin 스레드 간에 deadlock이 발생할 가능성이 있었습니다.
해결 방안
근본적인 대응을 하려면 Apache Zeppelin의 소스 코드를 대대적으로 수정해야 해서 Apache Zeppelin의 JIRA로 해당 현상을 보고하고, 사내에서 관리하는 Apache Zeppelin의 소스 코드에는 Notebook 스케줄 실행 후에 인터프리터를 다시 시작하는 "auto-restart interpreter on cron execution" 기능(아래 이미지에서 빨간 테두리 부분)을 사용 불가로 수정한 뒤 운용하기로 했습니다.

Apache Spark SQL 성능 이슈와 해결 방안
시스템 개요
사내용 데이터 분석 애플리케이션으로 OASIS라는 것을 자체 개발하여 운용하고 있습니다. 사용자는 OASIS에서 자유롭게 Apache Spark SQL을 실행하여 Hadoop 클러스터에서 데이터를 추출하고 분석할 수 있습니다. 본 Hadoop 클러스터는 HDP-2.6.2.0(2.6.2.0-205)에서 구축되었으며, Apache Spark 버전은 2.1.1입니다.
발생한 현상
사용자로부터 쿼리 실행이 완료되지 않는다는 문의가 들어와서 원인을 조사하기로 했습니다. 문제가 되는 쿼리를 분석하고 수정하며 검증했는데요. 그 결과 아래와 같이 파티션 키를 모두 지정한 단순한 쿼리를 실행해도 Spark 드라이버 프로세스의 CPU 사용률이 100%가 되어 쿼리 실행이 완료되지 않는다는 것을 알게 되었습니다.
select
max(log_hour)
from
event_log
where
log_date = '20181101'
and log_hour = '00'
and log_name = 'xxxx'칼럼(column) log_date, log_hour, log_name은 모두 event_log 테이블의 파티션 키고, 파티션 수는 약1,300*24*140=4,368,000 정도입니다.
원인 조사
Spark Web UI에는 실행되고 있는 job의 정보가 전혀 표시되지 않았고 job 실행 전 드라이버 프로그램의 쿼리 분석 및 최적화 단계에서 처리가 멈춰있는 것 같았습니다. 또한 드라이버 프로그램 로그에는 아무런 정보가 출력되지 않은 상태였습니다(로그 수준은 INFO로 설정). 드라이버 프로그램의 어떤 스레드가 CPU 사용률이 높은지를 알아보기 위해 아래 명령을 실행했습니다(아래 13300은 드라이버 프로그램 프로세스의 PID).
$ top -H -n 1 -p 13300
top - 00:32:28 up 96 days, 10:08, 1 user, load average: 3.33, 3.44, 2.83
Tasks: 71 total, 4 running, 67 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.5%us, 0.1%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8193180k total, 7893796k used, 299384k free, 186164k buffers
Swap: 4194300k total, 0k used, 4194300k free, 1460808k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13329 oasis 20 0 7961m 4.2g 25m R 96.6 53.7 25:32.43 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13331 oasis 20 0 7961m 4.2g 25m R 94.7 53.7 25:33.44 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13330 oasis 20 0 7961m 4.2g 25m R 92.7 53.7 25:33.37 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13332 oasis 20 0 7961m 4.2g 25m R 92.7 53.7 25:34.44 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13341 oasis 20 0 7961m 4.2g 25m S 2.0 53.7 0:00.73 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13300 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13328 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:06.24 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13333 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:21.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13334 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13335 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.02 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13336 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13337 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:07.10 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13338 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:06.49 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13339 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:03.08 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13340 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13347 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13358 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13359 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.11 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13360 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.07 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13361 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.14 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13362 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.07 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13363 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.24 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13364 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13365 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13366 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13367 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13368 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13369 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13370 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13371 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13377 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13378 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13379 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
```PID 13329, 13330, 13331, 13332(0x3411, 0x3412, 0x3413, 0x3414) 스레드가 CPU 사용률이 높았습니다. 스레드 덤프를 수집하여 확인해보니 아래와 같이 모두 GC 태스크 스레드였습니다.
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fe0a4024000 nid=0x3411 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fe0a4026000 nid=0x3412 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fe0a4028000 nid=0x3413 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fe0a4029800 nid=0x3414 runnable다음으로 힙을 덤프하여 드라이버 프로그램의 어떤 스레드가 메모리를 대량으로 사용하고 있는지를 Eclipse Memory Analyzer로 확인해보니, 아래와 같이 'Thread-62'이라는 스레드에서 메모리를 대량으로 사용하고 있다는 것을 알 수 있었습니다.

스레드 덤프 'Thread-62'의 내용은 다음과 같았습니다.
"Thread-62" #118 prio=5 os_prio=0 tid=0x00007fe024007800 nid=0x352c runnable [0x00007fdffdfe8000]
java.lang.Thread.State: RUNNABLE
at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:378)
at org.apache.thrift.protocol.TBinaryProtocol.readString(TBinaryProtocol.java:372)
at org.apache.hadoop.hive.metastore.api.Partition$PartitionStandardScheme.read(Partition.java:1009)
at org.apache.hadoop.hive.metastore.api.Partition$PartitionStandardScheme.read(Partition.java:929)
at org.apache.hadoop.hive.metastore.api.Partition.read(Partition.java:821)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result$get_partitions_resultStandardScheme.read(ThriftHiveMetastore.java:64423)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result$get_partitions_resultStandardScheme.read(ThriftHiveMetastore.java:64402)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result.read(ThriftHiveMetastore.java:64336)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:88)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_partitions(ThriftHiveMetastore.java:1994)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_partitions(ThriftHiveMetastore.java:1979)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.listPartitions(HiveMetaStoreClient.java:1050)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:156)
at com.sun.proxy.$Proxy30.listPartitions(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.getAllPartitionsOf(Hive.java:2096)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.hive.client.Shim_v0_13.getAllPartitions(HiveShim.scala:477)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$getPartitions$1.apply(HiveClientImpl.scala:561)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$getPartitions$1.apply(HiveClientImpl.scala:558)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$withHiveState$1.apply(HiveClientImpl.scala:279)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:226)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:225)
- locked <0x000000071665acc0> (a org.apache.spark.sql.hive.client.IsolatedClientLoader)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:268)
at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:558)
at org.apache.spark.sql.hive.client.HiveClient$class.getPartitions(HiveClient.scala:188)
at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:78)
at org.apache.spark.sql.hive.HiveExternalCatalog$anonfun$listPartitions$1.apply(HiveExternalCatalog.scala:995)
at org.apache.spark.sql.hive.HiveExternalCatalog$anonfun$listPartitions$1.apply(HiveExternalCatalog.scala:993)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
- locked <0x0000000716868228> (a org.apache.spark.sql.hive.HiveExternalCatalog)
at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:993)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:797)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:105)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:95)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$4.apply(TreeNode.scala:307)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$4.apply(TreeNode.scala:307)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:257)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata(OptimizeMetadataOnlyQuery.scala:95)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$apply$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:68)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$apply$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:49)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:257)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.apply(OptimizeMetadataOnlyQuery.scala:49)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.apply(OptimizeMetadataOnlyQuery.scala:40)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1$anonfun$apply$1.apply(RuleExecutor.scala:85)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1$anonfun$apply$1.apply(RuleExecutor.scala:82)
at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57)
at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66)
at scala.collection.mutable.WrappedArray.foldLeft(WrappedArray.scala:35)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1.apply(RuleExecutor.scala:82)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1.apply(RuleExecutor.scala:74)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:74)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan$lzycompute(QueryExecution.scala:78)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan(QueryExecution.scala:78)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:84)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:89)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:89)
at org.apache.spark.sql.execution.QueryExecution$anonfun$simpleString$1.apply(QueryExecution.scala:218)
at org.apache.spark.sql.execution.QueryExecution$anonfun$simpleString$1.apply(QueryExecution.scala:218)
at org.apache.spark.sql.execution.QueryExecution.stringOrError(QueryExecution.scala:112)
at org.apache.spark.sql.execution.QueryExecution.simpleString(QueryExecution.scala:218)
at org.apache.spark.sql.execution.command.ExplainCommand.run(commands.scala:117)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:58)
- locked <0x000000071de9cef8> (a org.apache.spark.sql.execution.command.ExecutedCommandExec)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:56)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:74)
at org.apache.spark.sql.execution.SparkPlan$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$anonfun$executeQuery$1.apply(SparkPlan.scala:138)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:135)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:116)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:92)
- locked <0x000000071de9cfa0> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:92)
at org.apache.spark.sql.Dataset.(Dataset.scala:185)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:64)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:600)
at com.linecorp.oasis.spark.SqlExecutor.run(SqlExecutor.java:54)
at java.lang.Thread.run(Thread.java:748)내용을 살펴보니 이 스레드는 쿼리를 분석하고 최적화하는 드라이버 프로그램의 주요 처리를 담당하고 있었습니다. 이 스레드 덤프 내용 중에 org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery라는 클래스가 궁금하여 소스 코드를 살펴보았습니다.
/**
* This rule optimizes the execution of queries that can be answered by looking only at
* partition-level metadata. This applies when all the columns scanned are partition columns, and
* the query has an aggregate operator that satisfies the following conditions:
* 1. aggregate expression is partition columns.
* e.g. SELECT col FROM tbl GROUP BY col.
* 2. aggregate function on partition columns with DISTINCT.
* e.g. SELECT col1, count(DISTINCT col2) FROM tbl GROUP BY col1.
* 3. aggregate function on partition columns which have same result w or w/o DISTINCT keyword.
* e.g. SELECT col1, Max(col2) FROM tbl GROUP BY col1.
*/
case class OptimizeMetadataOnlyQuery(
catalog: SessionCatalog,
conf: SQLConf) extends Rule[LogicalPlan] {참조 칼럼이 모두 파티션 키인데다가 집계가 실시되는 쿼리는 실제 데이터 파일에 접근하는 것이 아니라 파티션의 메타 데이터만을 사용해서 쿼리 검색 결과를 산출하도록 최적화가 진행되고 있었습니다. 그리고 클래스의 apply 메서드 처리(참고)를 보면, Spark SQL의 spark.sql.optimizer.metadataOnly 설정값이 true일 때 이 최적화가 진행됐습니다. Spark 문서에도 spark.sql.optimizer.metadataOnly에 관한 설명이 나와 있었는데요. 이 설정의 기본값이 true이기 때문에 따로 설정하지 않으면 이 최적화가 진행되도록 되어 있었습니다.
해결 방안
이번에 문제가 발생한 쿼리의 검색 대상 테이블은 파티션 수가 많아서(약 4,368,000개) 이와 같은 최적화가 진행되면 드라이버 프로그램에서 Apache Hive Metastore(Apache Hive의 메타데이터 중앙 저장소)로부터 파티션 정보를 수집하는 처리 부하가 늘어납니다. 그 결과 드라이버 프로그램에서 GC가 빈번히 일어나 쿼리를 실행하는데 많은 시간이 걸립니다.
이 테이블과 같이 파티션 수가 많은 테이블이 몇 개 있었기 때문에 OASIS에서 실행되는 Spark 애플리케이션에선 spark.sql.optimizer.metadataOnly=false로 설정하여 이런 방식의 최적화가 진행되지 않도록 조치했습니다.
마치며
대규모 분산 환경에서 발생하는 특유의 장애(테스트 환경에서 재현하는게 어려운 장애)를 처리하기 위해선 모니터링, 소스 코드 확인, 스레드 덤프와 힙 덤프 분석, OSS(open source software) 커뮤니티 활동 등이 중요합니다. 그 중에서 저는 특히 OSS 커뮤니티 활동을 강조하고 싶은데요. 더욱 많은 사람들이 OSS 커뮤니티에서 활동하면서 자신의 경험과 식견을 적극적으로 커뮤니티에 반영해 나갔으면 좋겠습니다.