
はじめに
こんにちは、電気通信大学大学院修士一年の梶凌太です。普段は動画生成に関する研究を行っています。
今回は6週間の就業型インターンシップに参加させていただき、Computer Vision Lab (CVL)チームで「ストーリーを考慮した料理動画要約」に関する研究活動に取り組みました。
ここでは、インターンシップ中での自分の取り組みとその成果について報告します。
背景
近年、動画メディアは爆発的に普及していますが、動画は画像と比較して冗長であり、ユーザーの求めるシーン以外のものを多く含みます。長い動画から重要なシーンのみを要約してダイジェスト動画を作るタスクであるVideo summarizationは、このような背景のもと需要が高まっています。
例えば料理動画などがその一例で、視聴するユーザの利便性を考えると、調理手順に関するところなどの見たいところ・気になるところのみを取り出したいという需要は高いです。ユーザーの欲しいシーンの描写をテキストで与えたときに、対応するシーンを抽出するタスクを考えると、料理動画はこのような観点で使いやすいため今回の研究対象としました。
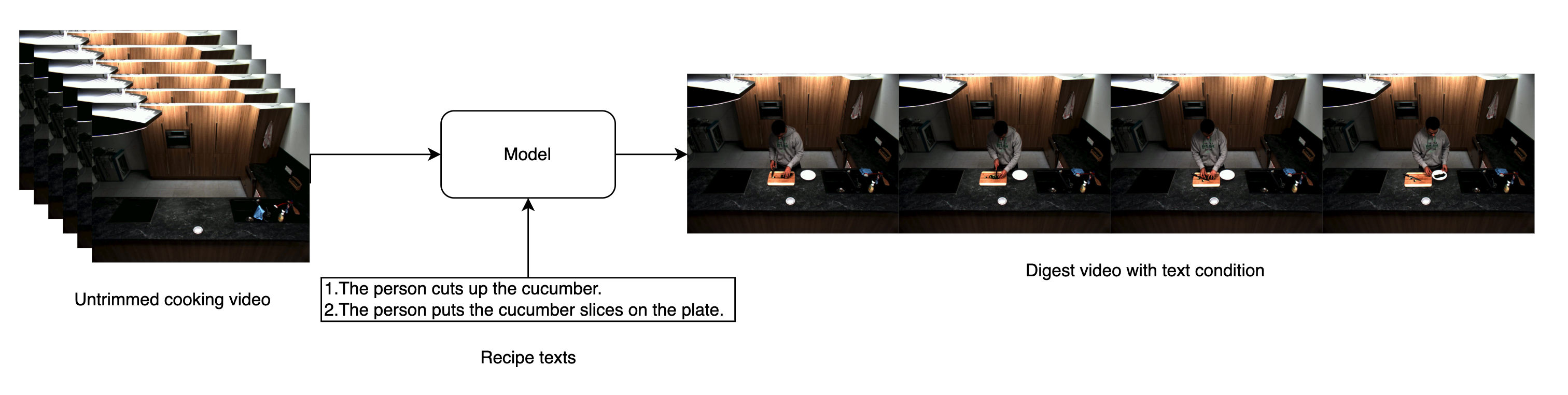
今回のインターンシップでは、1本の比較的長い料理動画からレシピの各調理手順テキスト(=ストーリー)を条件として対象の時間領域を抽出することを目的とします。
データの前処理
実験には料理動画データセットであるTACoS [2]を用います。TACoSは数分の動画127本から構成されるデータセットで、各動画に含まれるいくつかのシーンについて開始・終了フレームとその内容がアノテーションされています。総アノテーション数は98868ですが、そのうちシーンの説明となるテキストのアノテーションがついているのは18834個(18834/98868=19.0[%])になります。アノテーションテキストの文字数について可視化したものを以下に示します。文字数に注意しながら観察すると、長いアノテーションにはいくつか問題があることが分かりました。まず特徴抽出に用いるCLIPではトークン数(75+2)の制限があるため、極端に長いテキストはそのまま入力することができません。また、長いアノテーションテキストには複数の手順が含まれていることが多く、シーンとの紐付けにあまり適していません。そこで、150文字数以上のテキストアノテーション172個(172/18834=0.91[%])は除外して実験を行いました。
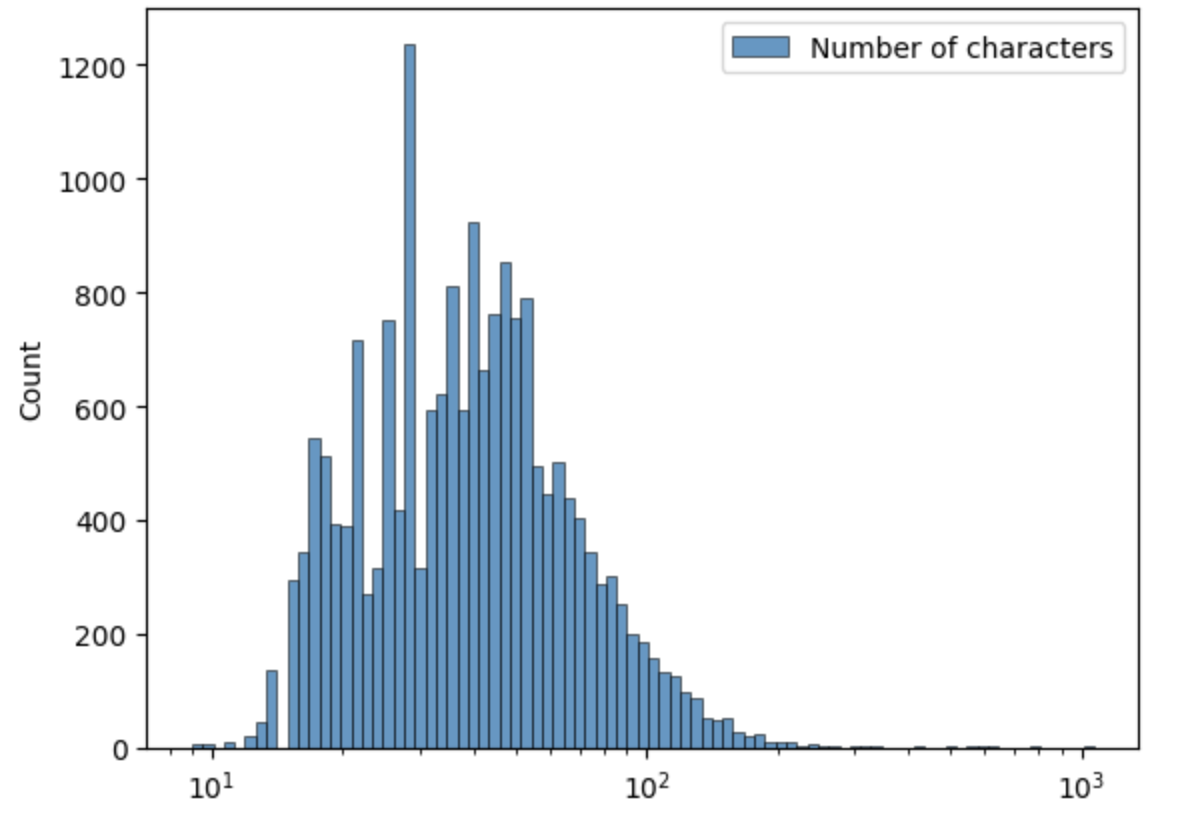
- 長いアノテーションの例
- 'He walks to the cupboard and opens it.. He takes out a peice of ginger and closes the cupboard.. He walks to the counter and places the ginger on the counter.. He opens the drawer.'
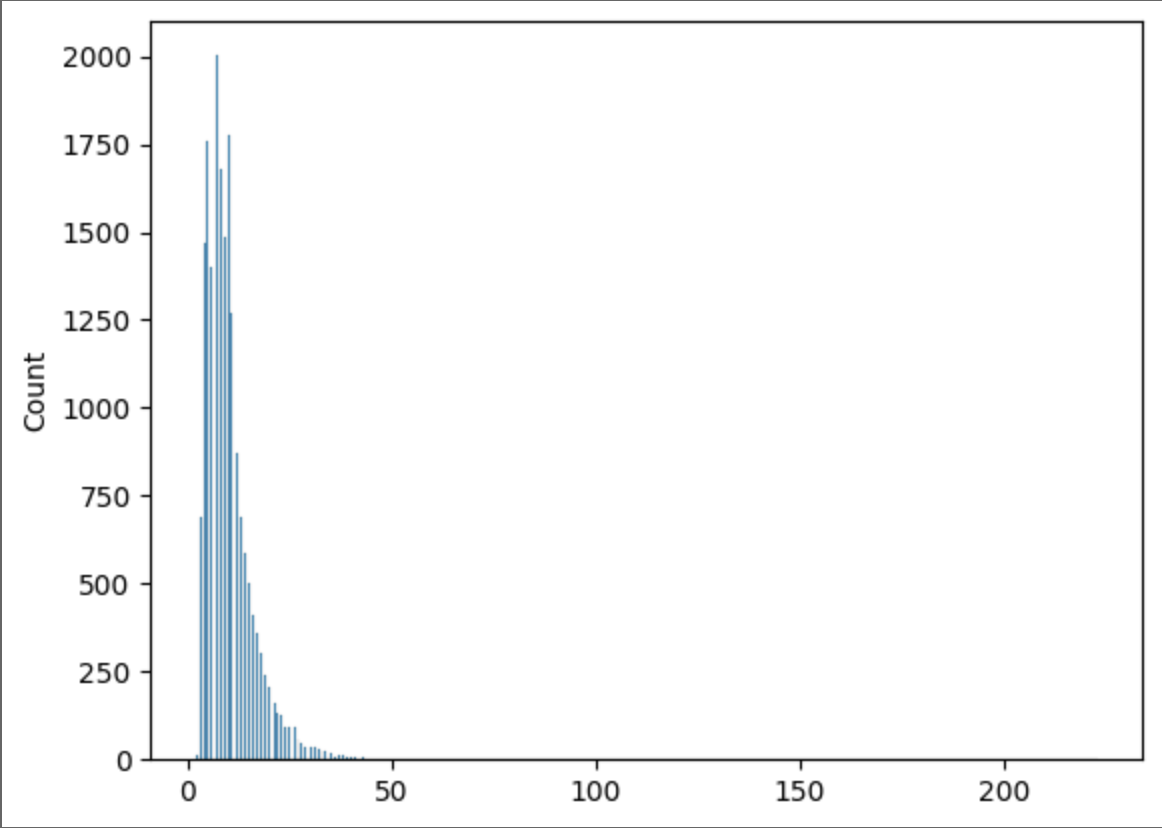
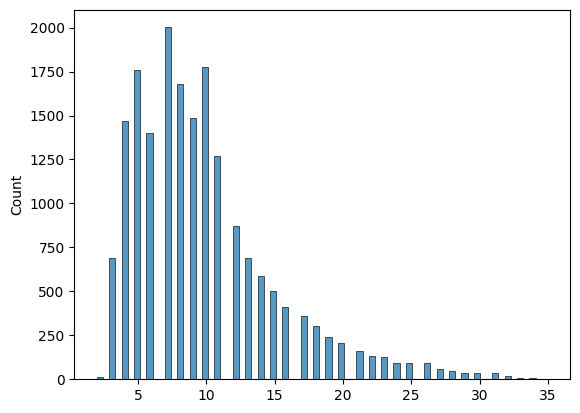
150文字数以上のアノテーションを除外する前(左)と後(右)のトークン数が以下になります。全て長さ75以下に収まり、かつ複数手順を含むテキストを多く除外できたことを確認しました。この時点で、各動画に対してのアノテーションは、最小5個、最大84個、平均25.79個のアノテーション数となりました。
|
|
次に動画の前処理についてです。データセット内の動画は29.4fpsで統一されていますが、学習には1fpsでサンプリングしたものを用います。その際、1秒前後の細かいアノテーションのシーンがサンプリングした動画内に含まれないことがあるため、5秒未満のアノテーションを除外することで対応しました。これにより、最終的に各動画に対してのアノテーションは最小2個、最大27個、平均8.26個のアノテーション数となりました。今回の実験では、これらの前処理をしたものを用いて行います。
また、全127個の動画に対してランダムに100個サンプリングしたものをTrainingデータセット、残りをValidationデータセットとして実験・評価を行いました。
問題設定
レシピ動画からレシピテキストを条件付けして動画を要約するためには、視覚情報と言語情報を紐付ける必要がありますが、これを行える代表的な大規模事前学習モデルとしてCLIP [1]が挙げられます。
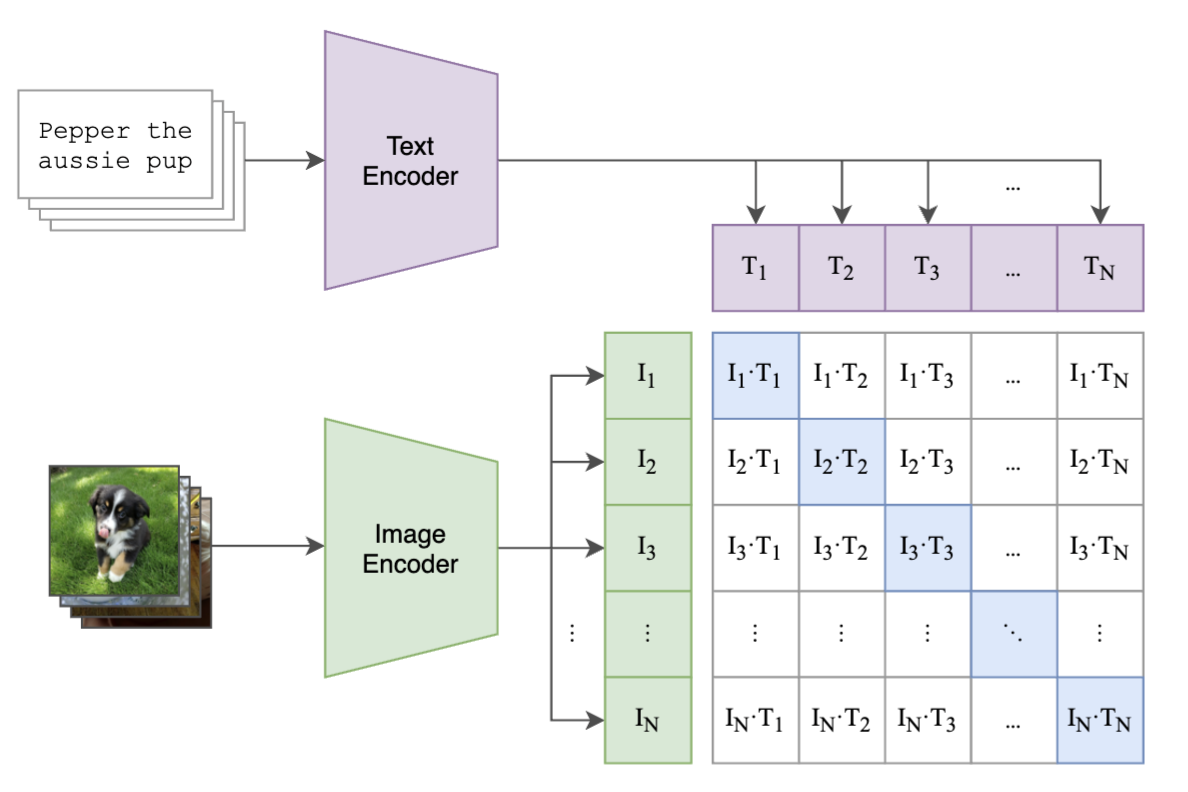
CLIP [1]はOpenAIによって開発された画像と言語のマルチモーダルモデルです。約4億の画像テキストペアで学習されているため、ゼロショットで画像テキスト間の類似度を計算することができます。
初めに、フレームレベルでどの程度条件テキストとマッチするか実験を行いました。実験では、料理動画と料理レシピ手順のテキストおよびそのフレーム区間がアノテーションされたデータセットTACoS [2]に対して、CLIP(ViT-B/32) モデルを用いて動画フレームとレシピ手順のテキスト間の類似度を計算し、分類結果の可視化を行いました。
Probabilityの計算では各モーダルのベクトルを正規化した後内積し、CLIPの学習済み温度係数を用いてSoftmaxで算出しています。以下に分類結果の例を示します。
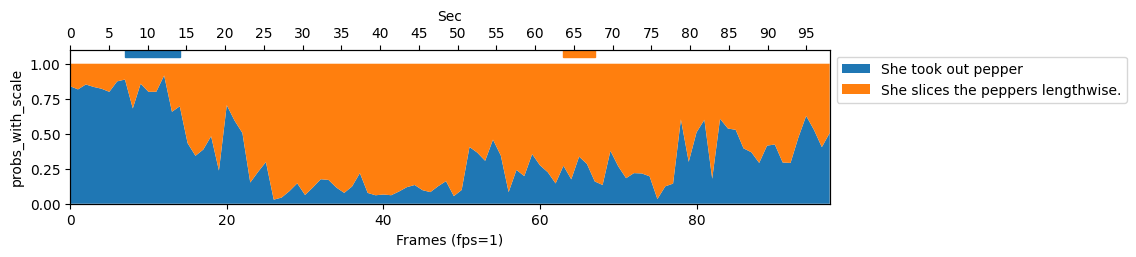
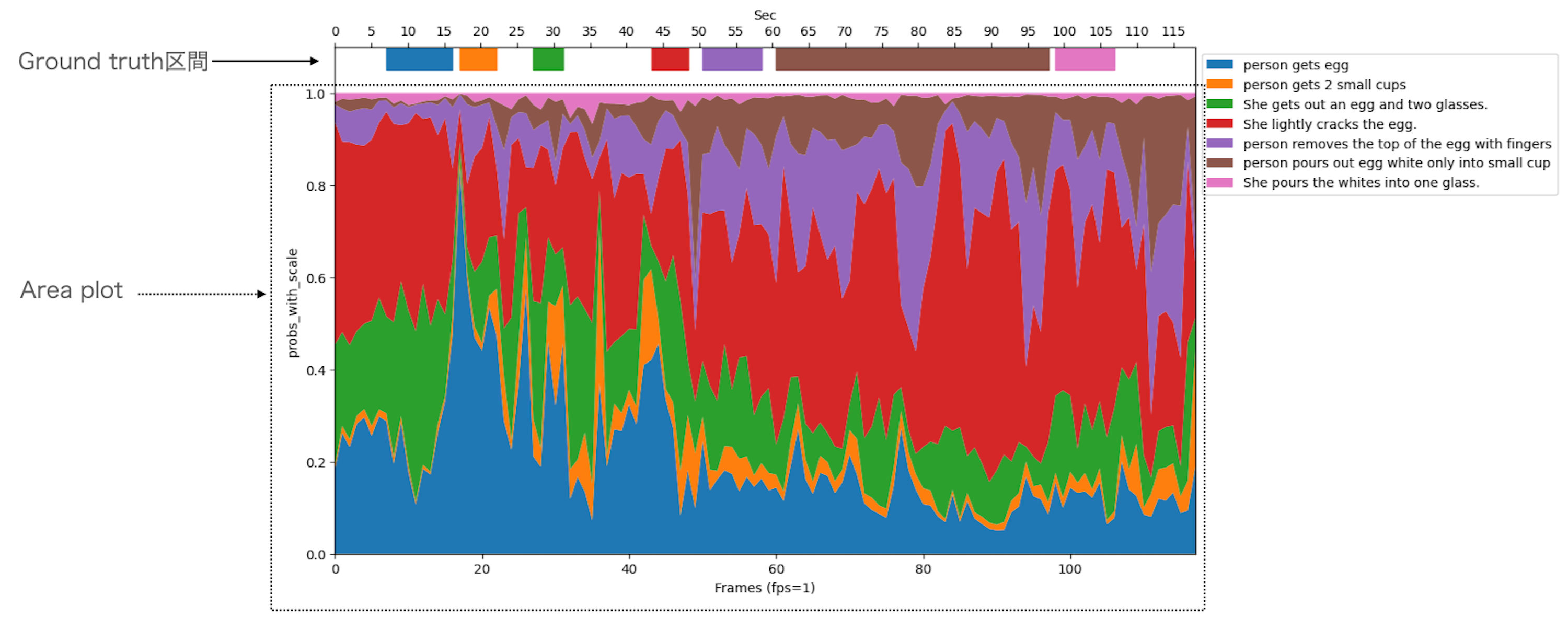
各図の横軸はフレーム、縦軸がCLIPでのProbabilityです。図中の上にある横線が各色のGround truth区間、図中のArea plotがCLIPによるProbabilityです。図4は、青と橙のGround truth区間のみ見るとそれぞれ正しい色がProbabilityを占めており、区間に対しては上手く分類できていることが分かります。
ですが、図5では橙区間に対して青色、茶色い区間に対して赤色が占めるなど、上手く分類できていないことが分かります。
これらの可視化をRecallの上位下位それぞれ数十サンプルに対して行った結果、いくつかの共通する問題点が見つかりました。
- フレーム中のモーションよりフレーム中を占める割合の大きいオブジェクトに反応する
- 例えば映像にミキサーが常に映っている場合、人の動作に関わらずミキサーに関するレシピ手順が支配的になる
- 加工された材料などのオブジェクトに反応するのは難しい
- 類似したレシピ手順の分離が難しい
- 1つのレシピ手順に複数の手順が含まれると難しい
- 調理で一貫して同じ材料を扱うレシピは手順への分類が難しい
- シーン中に別のカットインが入るとシーンが分かれてしまう
- 全フレームに対してテキストへの類似度が出るため、要約に用いるフレームを選択することができない
様々な課題がありますが、今回のインターンシップでは以下のように料理レシピ手順に対応したシーンを抽出することを目標にしました。
手法
手法の比較として以下の2つを実装します。
- CLIP-It(Baseline)
- 提案手法
CLIP-It
CLIP-It [3]はCLIPとテキストガイダンスを用いた動画要約モデルです。モデル概要図を以下に示します。
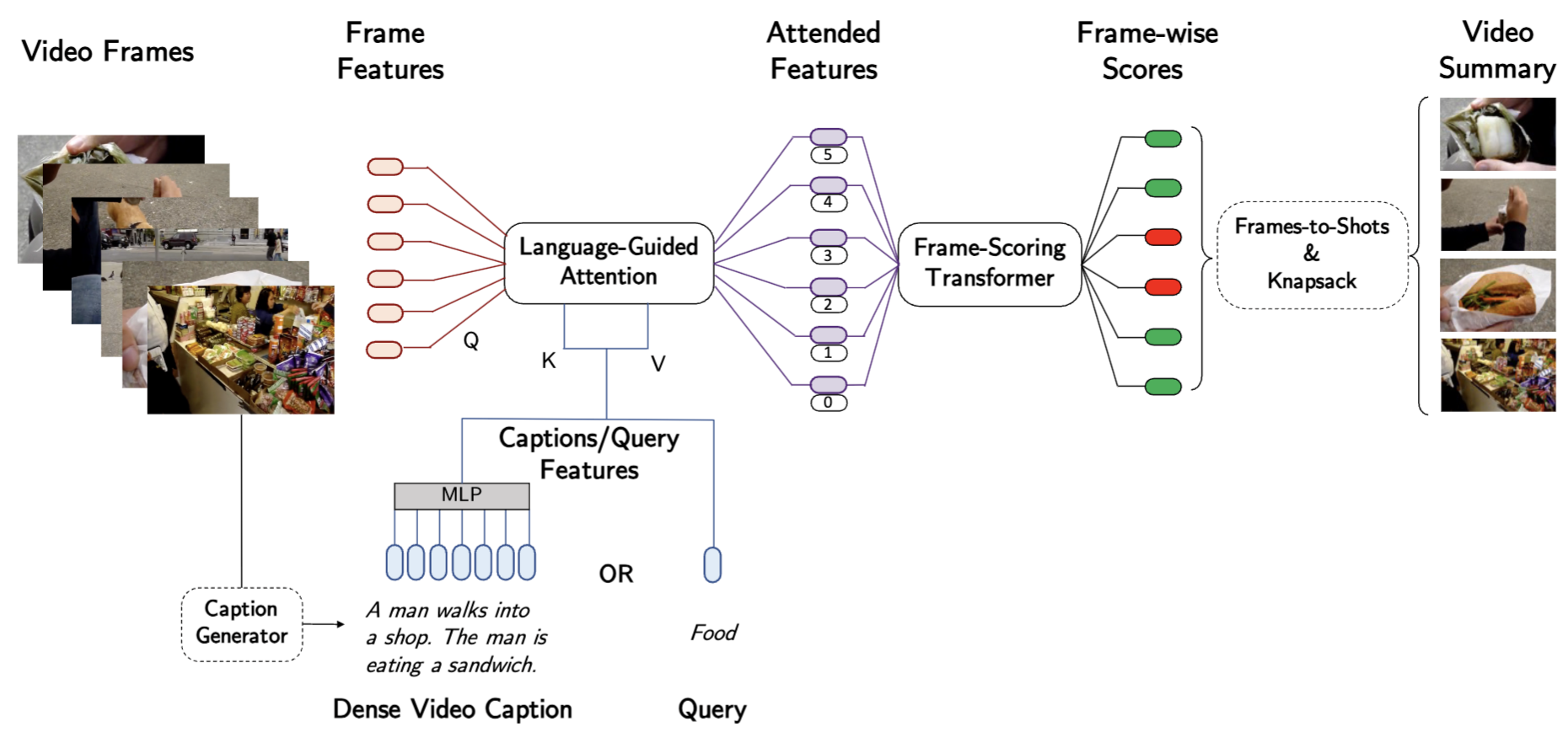
CLIP-Itは動画を入力として各フレームを要約に含めるかどうかのスコアを出力します。Language-Guided Attentionでは、CLIP-Vision Encoderなどで抽出されたvision featureと、事前学習されたDense video captioningモデル [4]とCLIP-Text Encoderから得られたtext featureを入力として、vision featureにtext featureを取り込みます。Frame-Scoring Transformerでは、Language-Guided Attentionから出力された特徴から、フレームごとの要約スコアを出力します。また、実際の要約動画を作成する際にはFrameからShotへの変換とShot集合をナップサック問題と捉えて要約に用いるShotを選択します。
本研究ではこの手法をベースラインとしました。実装が公開されていないので、再現実装の際いくつかの変更を加えました。Language-Guided Attentionについては、入力されたCaptions featuresについてConcat+MLPをせずにSequence length軸にスタックしてKey、Valueへ入力するようにしました。これにより、可変長な料理レシピテキストに対してもAttentionできるようになりました。また、今回用いるTACoSデータセットは動画数が少なく、過学習しやすいためTransformerのEncoder、Decoderレイヤー数は元実装の半分の3に設定しました。
提案手法
提案手法では、CLIP-Itと比較してよりシンプルな構造により効率的にVisionとTextの特徴を融合します。CLIP-ItのLanguage-Guided Attentionでは時系列情報を考慮せずにフレーム単位でTextを条件付けていますが、提案手法ではTransformer Decoder前の1次元畳込みおよび内部のAttention機構により、両特徴の系列情報を考慮しながらTextを多段階で条件付けます。これにより、前後のフレームを考慮したショットレベルでのマッチングを行うことが可能です。
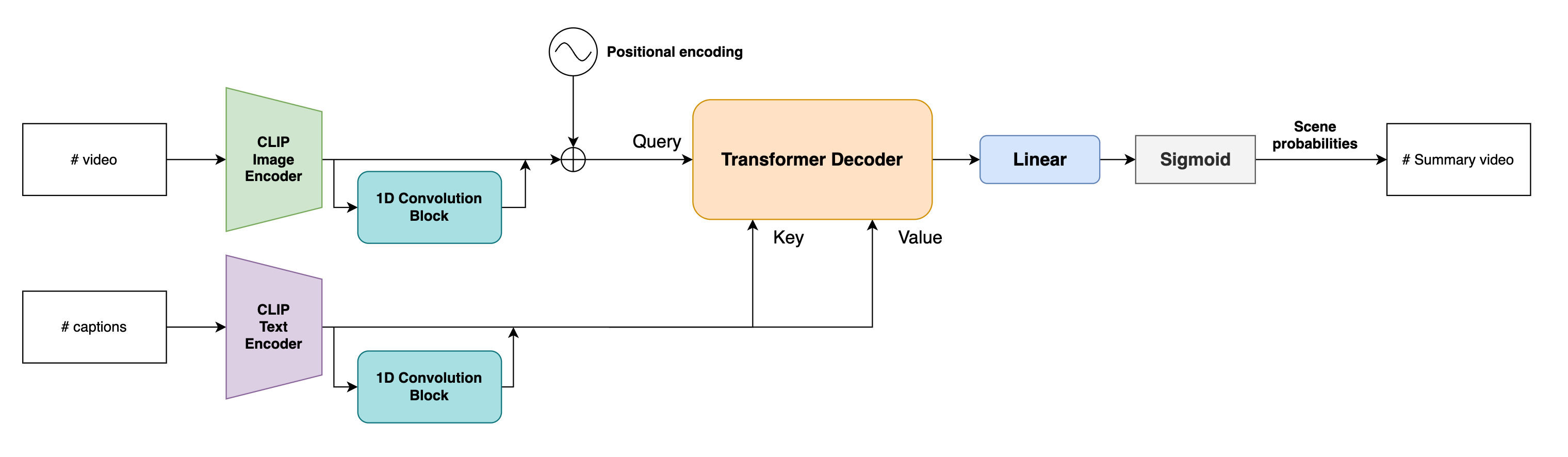
Scene probabilitiesは、入力された料理動画と料理レシピテキストから各フレームが要約に含まれる確率を示したものです。以下の手順によって出力されます。
- 入力動画は各フレーム独立にCLIP Image Encoderに入力され、(B, F, C)の特徴ベクトルを得ます。ここで、Bはバッチサイズ、Fはフレーム数、Cはチャネル数です。
- テキストもCLIP Text Encoderに入力され、(B, S, C)の特徴ベクトルを得ます。ここで、Bはバッチサイズ、Sはテキストクエリ数、Cはチャネル数です。
- 特徴ベクトルは1次元畳込みからなるResidual Blockに入力され、ローカルな時系列関係を抽出します。
- Positional Encoding [4] を加算後、3層のTransformer Decoderに入力され両特徴量から要約シーンに含まれるか否かのBinary classification taskを学習します。ここで、フレーム特徴はQuery、テキスト特徴はKey、Valueとしてdecoderに入力されます。
また、Trainingセットは動画数100本かつ各動画の背景が同一で非常に過学習しやすくなっています。したがって、学習時にはよりテキストー映像間のマッチングを高めるため各アノテーションを0.5の確率でドロップします。これにより、各エポックで動画に対してのラベルが変化することで過学習を抑制します。
結果
学習したCLIP-Itと提案手法について、アノテーション全体のBinary classification taskとして定量評価を行いました。それぞれのValidationデータに対するF1-Scoreを以下に示します。提案手法はCLIP-Itに対して上回るスコアを達成していることがわかります。
|
Method |
F1-Score |
|---|---|
|
CLIP-It |
0.488 |
|
Ours |
0.569 |
次に、8つのアノテーションがついたサンプルに対する推論結果を可視化したものを図8、9に示します。
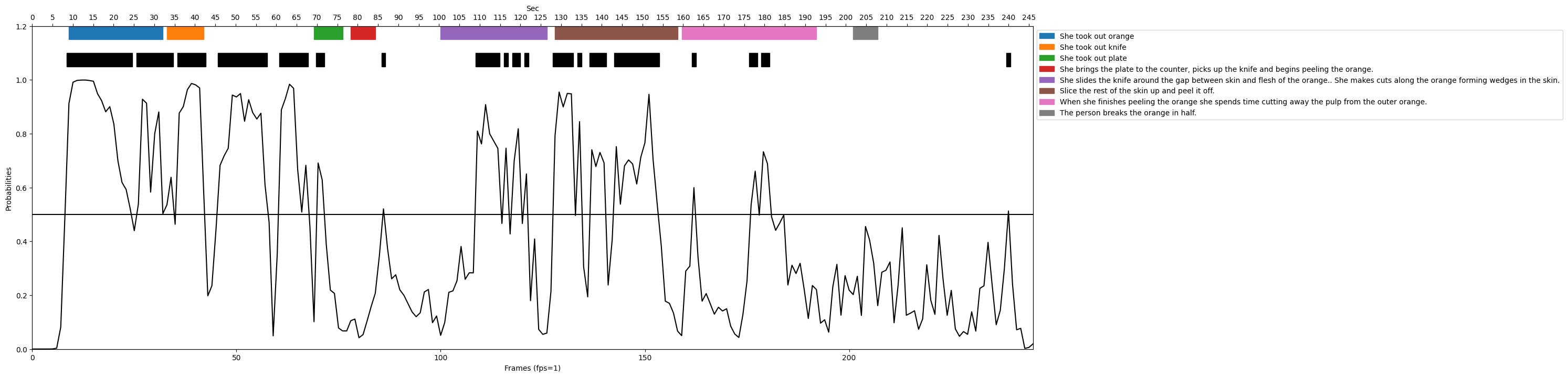
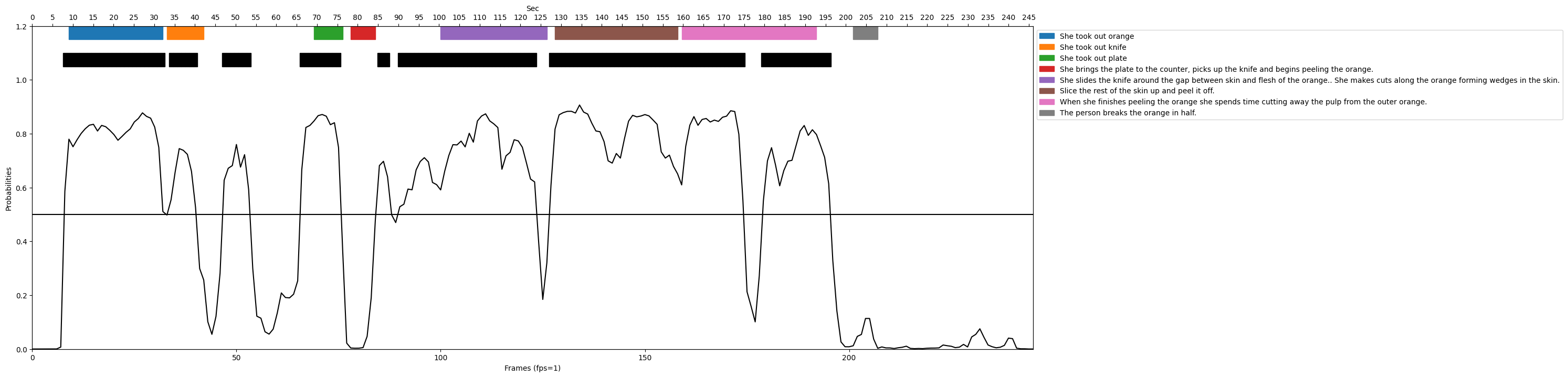
図8、図9より、CLIP-ItではProbabilitiesが細かく、かつ全体的に激しく上下しており、非常に短いシーンを複数推論してしまっていることがわかります。それに対して提案手法では、全体的に細かなProbabilitiesの変動はあまり見られず、ある程度まとまった区間を推論できていることがわかります。このことから、CLIP-ItがGround truth区間に対してまとまったマッチングができていないのに対し、提案手法ではシーン単位でのマッチングができていることがわかります。
図8、9の推論結果に基づいて実際に要約動画を作った結果が以下になります。
動画1 CLIP-Itによる要約動画
動画2 提案手法による要約動画
また、提案手法の推論においてあまり上手くいっていないサンプルを図10、動画3に示します。
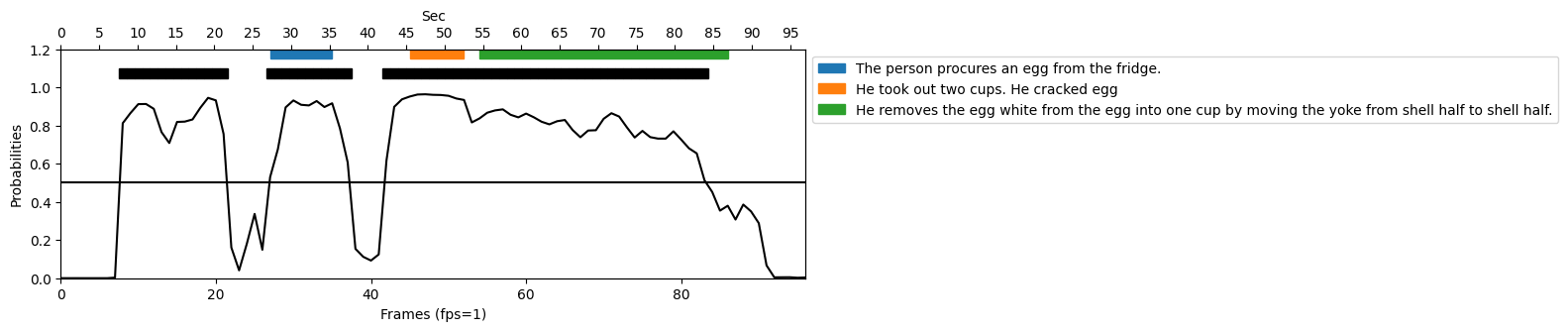
動画3 提案手法による要約動画
このようなあまり上手く推論できていないサンプルの結果を見てみると、調理者が何かを洗ったり後ろの棚に何かを取りに行ったりする際に間違った推論をしてしまっている場面が多く見られました。このサンプルでは、アノテーションに水を汲む動作は含まれいないにも関わらず、高いProbabilitiesを示してしまっています。これは、データセットの動画数が少なく視覚的な多様性が低いために、こういう視覚特徴はよくアノテーションされている、という一種の過学習が起きていると考えられます。これらのテキスト条件に頼らずに推論してしまう結果を改善するためには、よりテキストー映像間のマッチングに制約を設ける必要があると考えられます。
おわりに
今回6週間という期間でインターンシップをさせていただきましたが、振り返ってみれば非常に短く感じるほど集中して研究に取り組むことができました。インターンシップが始まる前は、自分の技術力不足や経験不足から不安なことだらけでしたが、インターンシップ中は分からないことがあるとメンターの方やCVLチームの方々がその都度丁寧に教えて下さったり議論したりなど、密にコミュニケーションが取れる環境で安心してインターンシップに取り組むことができました。本当にありがとうございました。
取り組みの中では、研究の進め方や考え方など一連の流れを通して勉強になることが多々あり、得られるものが非常に多いインターンシップとなりました。また、僅かではありますがインターンシップ前に考えていた企業としての視点から研究をとらえることもでき、それによる苦労もありましたが大学で研究しているだけでは得られなかった貴重なものだと思います。
お忙しい中毎日ミーティングをして下さったメンターの方々、温かくサポートしていただいたCVLチームの皆様、本当にありがとうございました!今回の経験を、これからの研究に生かしていきたいと思います。
参考文献
- Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. International Conference on Machine Learning.
- Rohrbach, A., Rohrbach, M., Qiu, W., Friedrich, A., Pinkal, M., & Schiele, B. (2014). Coherent Multi-sentence Video Description with Variable Level of Detail. ArXiv, abs/1403.6173.
- Narasimhan, M.G., Rohrbach, A., & Darrell, T. (2021). CLIP-It! Language-Guided Video Summarization. Neural Information Processing Systems.\
- Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. NIPS.