
こんにちは、早稲田大学政治経済学経済学科 学部3年の滝田愛澄と申します。2023年8月7日から6週間、LINE株式会社のIU Data Connectチームにて、就業型インターンシップに参加させていただきました。本インターンでは、LINEの大規模ETL batch pipelineであるVinitusが現在抱えている課題を解決することを目的に、data build tool (dbt) の調査とdbtを用いた新たなworkflowのプロトタイプの設計・実装に取り組みました。このレポートでは、現在のVinitusが抱えている課題を確認し、dbtの導入によってどのようにそれらの課題を解決できるか、具体的にこのプロトタイプでは何をどう実装したのかについてを述べます。
背景
データが十分に蓄積され始めると、データ分析やBIツールによるダッシュボード化、機械学習による未来予測などのデータ活用を行う動きが一般となってきました。これらのデータ活用のために必ず必要とされるのがデータエンジニアリングです。データエンジニアリングというワードは広義な意味を持ちますが、データが蓄積されてから活用されるまでのworkflowやその基盤を構築・管理・運用することを指すことが多いでしょう。これらのデータエンジニアリングは、いまだに発展途上であり、多くの課題を抱えています。さらに、LINEのデータ規模は非常に大きく、400PB以上のデータを抱え、毎日10万以上のbatchジョブが実行されています。このworkflowの中でも、ETL batch pipelineに焦点を当て、まずは、一般的な課題とLINEの大規模なデータ基盤だからこそ発生する課題を確認していきます。
一般的なETL batch pipelineにおける課題
データが規模がそれなりに大きくなると、ただSQLクエリが実行できれば良い、という状況から、ファイルの管理やチームの権限管理などの課題が出てきます。LINEに限らず一般的なETL batch pipelineにおける課題を2つ紹介します。
- チームで共同開発がしづらい
- ビジネスユーザーがグラフや指標の定義を確認できない
チームで共同開発がしづらい
データ分析では基本的に複数のチームメンバーで行われます。これは普通のソフトウェア開発と同じで、複数の人が同じシステムを触ります。SQLファイルがGitHubやGitLabで管理されることは少ないと思います。
特にCloudで開発を行っている場合は、Cloudのサービス上のUIでファイルの作成や削除などを行います。本番環境と開発環境が分かれていない場合は、誤って本番環境のSQLクエリを消してしまうことがあるかもしれません。チームメンバーの中には、そのプラットフォームを長く使っている開発者だけでなく、初心者も入ってくるため、クエリのレビューも必要となってきます。また、使っているクエリをアップデートしたい場合にはバージョン管理をしたいこともありますが、データエンジニアリングでこれらのベストプラクティスは確立されていません。
ビジネスユーザーがグラフや指標の定義を確認できない
ビジネスユーザーは、ダッシュボードやグラフなどを用いてデータを活用します。しかし、そのダッシュボードがどのように作られたのか、この指標はどのように計算されているのかを調べることが難しいです。データカタログによって各データや指標の説明を見ることもできますが、開発者がデータカタログに文章を書いていないことも多く、その場合にはビジネスユーザーはSQLやPythonで書かれたコードを見るほかありません。データを開発する人や活用する人が増えれば増えるほど、この確認作業にかかるコストは大きくなります。開発者にとっても、コード書くプラットフォームと説明の文章を書くプラットフォームが異なる場合、それぞれもプラットフォームを往復する分、作業のコストが高くなります。
LINEの大規模ETL batch pipelineにおける課題
LINEでは、Cloudサービスを使わずに、オンプレミスでschedulingシステムを構築・運用しています。それが、Apache Airflowを元に構築されたVinitusです。全てLINEの開発者によって開発されているため、一般的な課題の一部はすでに解決されています。しかしながら、大規模であるが故の新たな課題も存在しています。ここでは、主に4つの課題を紹介します。
- SQLクエリの記述・運用に工夫が必要である
- DAGやtaskの依存関係をユーザーが定義する必要がある
- 開発環境と本番環境を分離させてのテストが難しい
- Data-aware schedulingができない
SQLクエリの記述・運用に工夫が必要である
Airflowでは、Jobの実行順序や依存関係がDAGとして定義されています。1つのDAGには複数のtaskが含まれており、SQLクエリはこのtaskに含まれます。Vinitusでは、1つのtaskを1つのYAMLファイルでこのように定義しています。
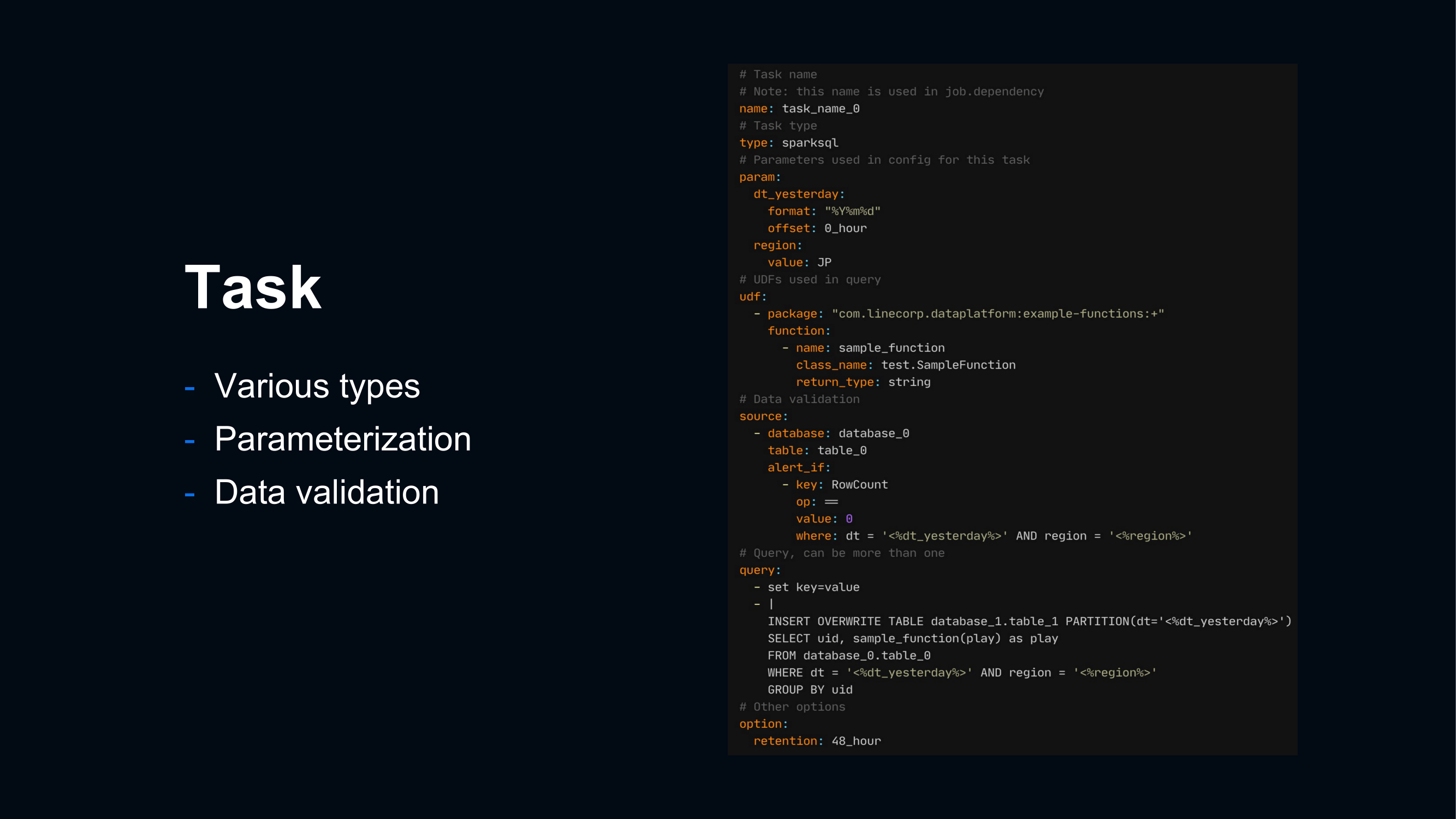
SQLクエリは、YAMLファイルの中に文字列として記述されています。これは文法ミスやtypoを引き起こす可能性があります。普通のプログラミングのようにcode editorで記述する場合、そのcode editorがある程度の文法ミスの指摘やカラーリングをしてくれるため、文法ミスやtypoの可能性を減らしてくれます。文字列として書く場合にはこれらのサポートを受けることができません。ユーザーは、そのクエリが正常に動作するか (文法的に正しいクエリかどうか) を確認するために、別のクエリエディタでSQLクエリを記述するしかありません。
DAGやtaskの依存関係をユーザーが定義する必要がある
1つのDAGを構築するためにtaskを定義した複数のYAMLファイルの依存関係を新たに定義する必要があります。
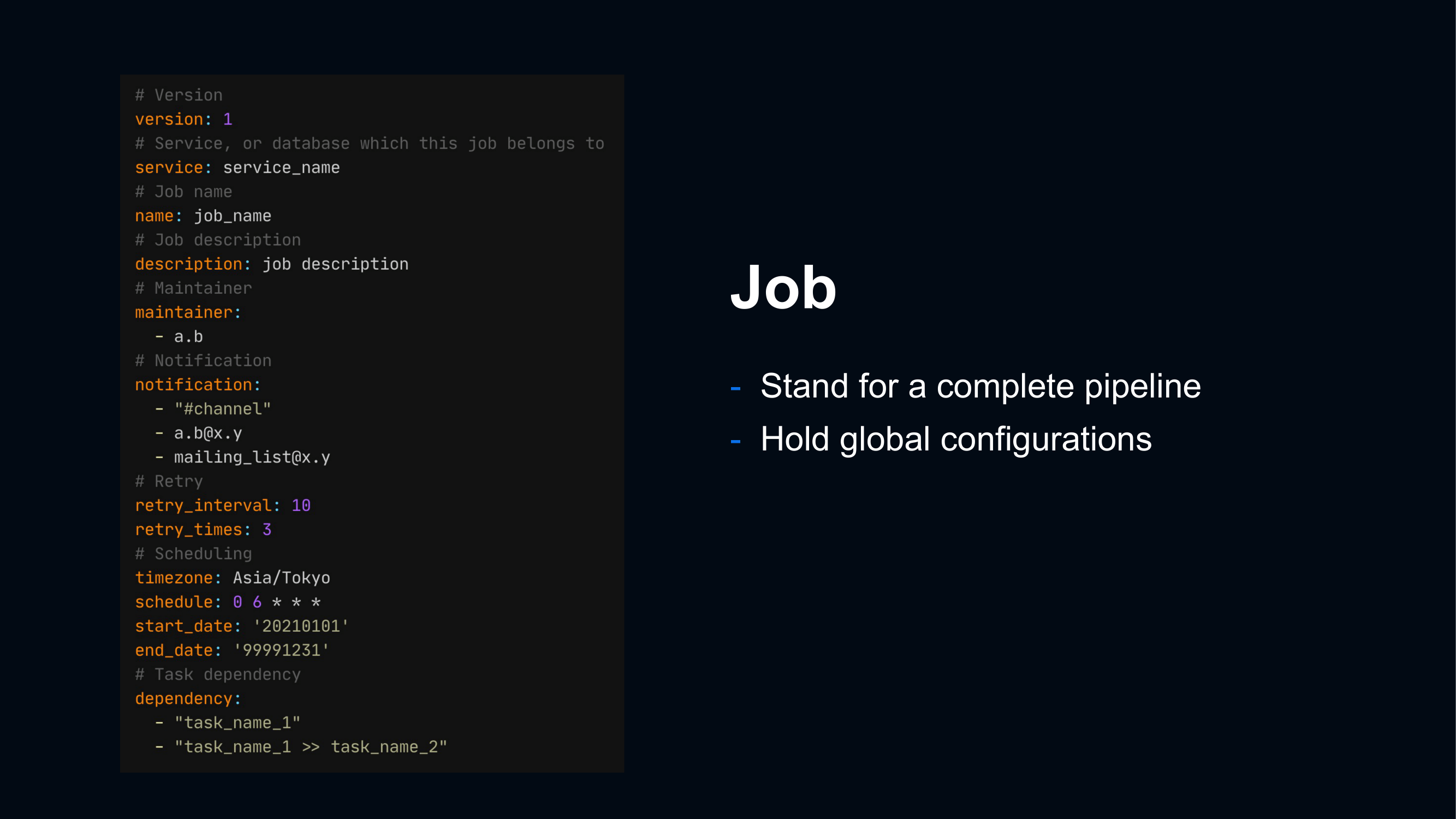
あるtableがどのtableに依存しているのかをユーザーが書く場合、そこにミスが生まれる可能性があります。例えば、table Zを作成したい場合には、tableZが依存するtable Xとtable Yを作成するtaskも依存関係に含める必要があります。現状では、この依存関係をクエリと設定ファイルの両方に書く必要があります。つまりに、SQLクエリには、「FROM tableY」と記述し、設定ファイルには「task_of_table_Y >> task_of_table_Z 」と2回書く必要があるということです。
複数のDAGの依存関係を構築することはtaskの依存関係よりも複雑です。VinitusでDAG同士の依存関係を構築するためにはAirflowのExternalTaskSensorを使用する必要があります。DAG同士の依存関係を定義するためにはこのExternalTaskSensorの挙動を理解する必要があります。しかし、Vinitusのユーザーにはデータ分析や機械学習などの開発者を想定しており、Airflowの開発者であるとは限りません。Airflowに馴染みのないユーザーにとっては、DAGの依存関係の構築は時間的なコストがかかる作業であり、ミスが生まれる可能性もあります。
開発環境と本番環境を分離させてのテストが難しい
Vinitusでは、SQLクエリを含むtaskやDAGのlocal環境でのテストはまだ実装されていません。SQLクエリが動作するか試すためには、gitで管理されているレポジトリに対してPull Requestを作成し、mergeした後にDAGを有効化して、そのDAGが動くかを確認するほかありません。これは、一般的なdata warehouseも抱えている課題です。Big Query (Google Cloud) や Redshift (Amazon Web Service), Snowflake (Snowflake) でも、1度クエリを実行するしかありません。一般的なsoftwareであれば、本番環境で実行する前に開発環境で動作するかを確認するのが普通です。しかし、SQLクエリには、そもそも開発環境と本番環境が分かれていることすら少ないです。テストなしで本番環境でSQLクエリを実行した場合、失敗した場合にも中間tableが残ってしまったり、既に利用されているtableを書き換えてしまったりなどをするリスクがあります。
Data-aware schedulingができない
「データAが作成されるのを待ってからデータBを作成したい」という状況があります。Vinitusでは、データAが作成される時間を予想して、予想された終了時間の後にデータBを作成し始めるというスケジューリングの方法を取っています。しかしこの方法では、予想が外れてしまい、データAが作成が終了するより前にデータBの作成が開始してしまう可能性があります。
理想的な方法は、「データAの作成が終了したことをトリガーにデータBの作成を開始する」ことです。
data build tool (dbt) とは
data build tool (dbt)とは、ETL/ELT処理における変換ワークフローで、データ分析プロセスをより良いものにします。dbtは1つのSQLファイルを1つのモデルとして扱い、data warehouse内でテーブルがどのように作成され、物理的にどのように存在しているかを確認することができます。
dbtは、ソフトウェアエンジニアリングのようにデータを扱うことをコンセプトとしています。システムをGitを用いてバージョン管理をする、開発環境で挙動を確認する、コメントを追加するなど、一般的なソフトウェアを開発する際には当たり前にやっていることをデータエンジニアリングにも取り入れようとしています。
dbtには、dbt cloudとdbt coreがあります。dbt cloudは、dbtを簡単に操作することができるcloudサービスです。dbt coreは、CLIで使えるdbtコマンドのことです。今回は、Airflowの内製システムに導入することを考えてdbt coreだけを用います。
dbtを用いたETL batch pipelineの実装
Airflowを使ってdbtのschedulingを効果的にするために新たにcosmosを含めたarchitectureを構築しました。それぞれのコンポーネントの役割を見ていきます。
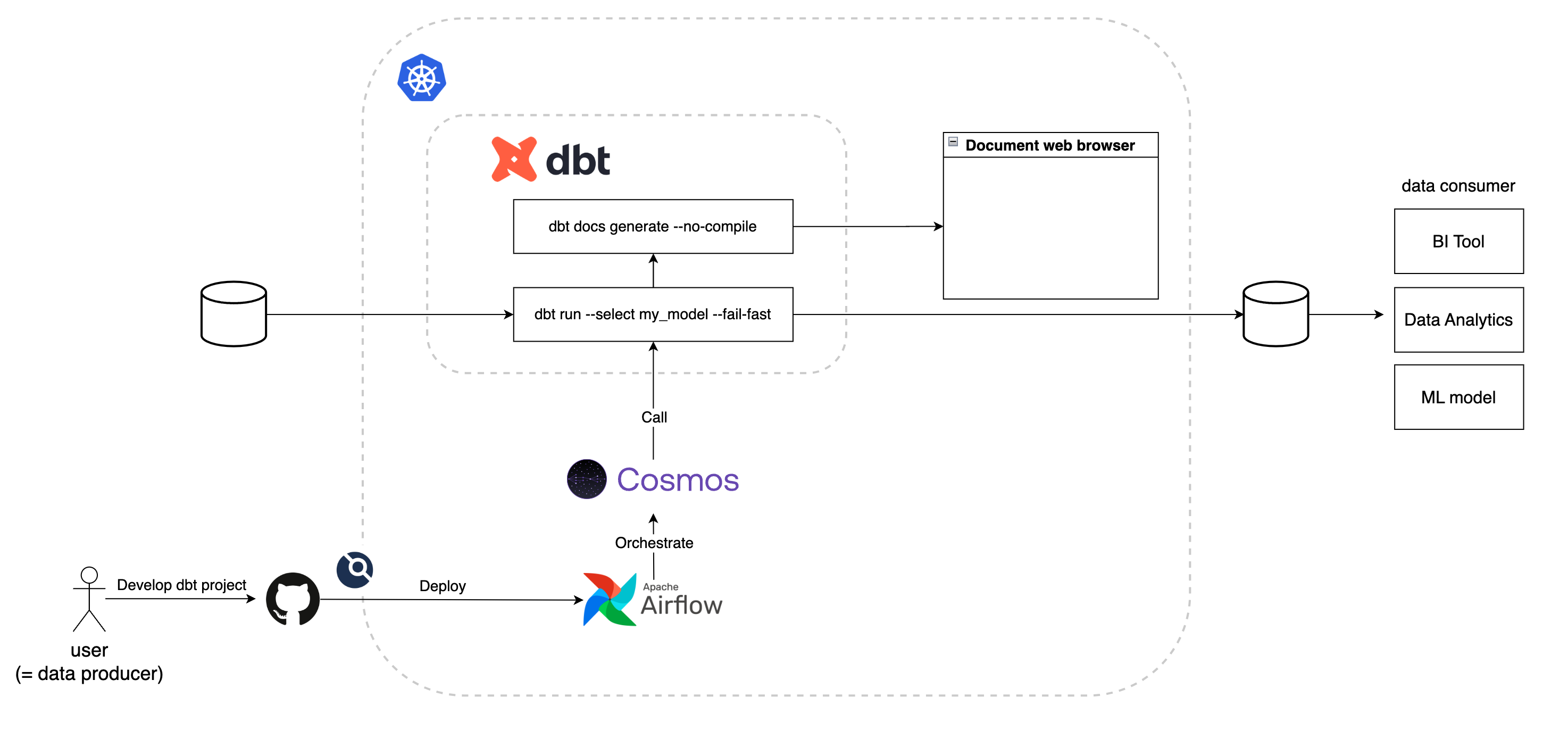
GitHub
このシステムで使われる設定ファイルやSQLクエリは全てGitHubのレポジトリとして管理されます。新しくSQLクエリを追加したい場合は、ユーザーはまずこのレポジトリをローカル環境にcloneします。モデルを構築するためのSQLファイルとモデルの設定ファイル、DAGの設定ファイルを特定のディレクトリに作成します。これらの変更を含めたPull Requestを作成し、codeownerによるレビューが完了されると、mainブランチにmergeされます。
CI/CDツールとしてdroneが使われているため、mainブランチにmergeされたタイミングでKubernetes上にあるclusterに対して自動でdeployされます。
この方法はVinitusと全く同じであり、一般的なsoftwareのようにコードのレビューやcode editor上での開発ができます。
Apache Airflow
DAGをschedulingするためのAirflowはKubernetes上にdeployされます。Airflowはユーザーによって定義されたモデルとDAGを元にdbtをschedulingします。
しかし、Airflowだけではdbtの効果を最大化することはできません。AirflowはPythonのツールであり、dbtはあくまでコマンドであるためです。AirflowはBashOperatorを用いてdbtコマンドを実行することも可能です。しかし、これだけだとAirflowはdbtをただのコマンドとして実行するため、Airflowはdbtを認識できていません。AirflowのUI上で確認できるlineageにも、ただのコマンドとしてtaskが実行されているとしか表示されません。そこで、Airflowとdbtを連携するためにcosmosを利用します。
Cosmos
Cosmos by astronomerは、Airflowとdbtを繋ぐためのPythonライブラリです。cosmosは、dbtのprojectやprofile情報を取得してAirflowのtaskに変換することができます。これにより、Airflowはdbtをdbtだと認識することができるようになります。
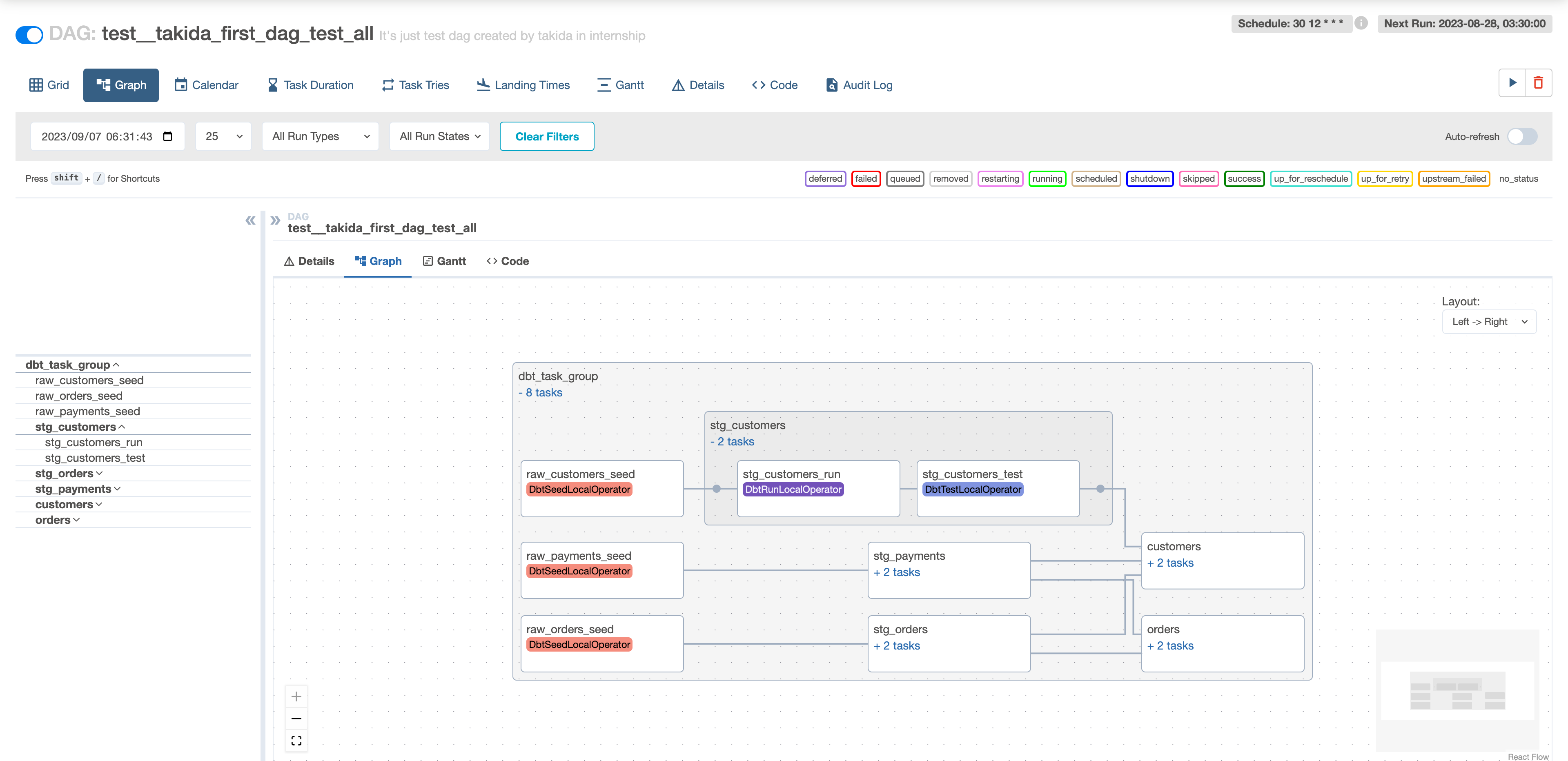
dbtが認識できるようになると、モデルの種類や依存関係もAirflowのUI上で確認することができるようになります。Airflowは、同じPythonのcosmosをtaskとして実行することで、cosmosがdbtをtaskに変換して実行することができるようになります。
dbt
dbtは、SQLクエリと設定ファイルをモデルに変換して、クエリのテストと実行を行います。基本的にはSQLとYAML, Markdownファイルを扱います。cosmosによってdbt runとdbt testが実行され、profiles.ymlを参照してDBに接続します。特定のモデルやテストだけを選択して実行することも可能です。このシステムでは、ユーザーにDAGの設定ファイルを記述してもらう際に、–select や --exclude を設定することができます。また、テーブル同士の依存関係についても、SQLファイルが自動で解析されることにより、依存関係が自動で作成され、依存元のクエリも自動で実行されます。
dbtによるETL batch pipelineの課題の解決
現状でのETL batch pipelineの課題とdbtのコアな機能を確認し、architectureが構成できたので、より具体的にdbtの機能とどう課題が解決されるかを見ていきます。
(テストのためにdbtの公式が提供しているjaffle_shopというプロジェクトを用いて実装していきます。)
SQLクエリをSQLファイルとして記述
先述した通り、Vinitusでは、SQLクエリをYAMLファイルに文字列として記載しているため、文法ミスやtypo残ったまま実行されるという課題がありました。このシステムではSQLクエリをSQLファイルに記述することができます。dbtのSQLクエリには2つの特徴があります。
1つは、SQLファイル内でデフォルトでJinjaとMacroを利用することができます。SQLはPythonなどのプログラミング言語と異なり、if文やfor文などの処理を直接記述することができず、幾つもの中間テーブルを作成することになるため、コードが冗長になりがちです。MacroとJinjaを使うことで、SQLにif文やfor文を使えるだけでなく、関数を定義して他の開発者と使いまわすことができます。これによって、コード量が減って簡潔になるだけでなく、開発者間で同じ関数を使うことで指標の定義が開発者間で異なることを防ぐことができます。
もう1つは、dbt特有のref関数やsource関数を用いてソースデータを指定できることです。一般的には、「FROM "database"."table"」と記述されるところを「FROM {{ ref("table") }}」と記述します。dbtはこれらの関数で書かれたSQLをコンパイルした後に実行します。後述しますが、この関数があることでデータの依存関係を簡単に定義できるようになります。
また、dbtでは、モデルのファイルを記述する際に典型的な Data Definition Language (DDL) や Data Manipulation Language (DML) を書く必要がありません (https://docs.getdbt.com/docs/introduction#dbt-optimizes-your-workflow)。単にSELECT文を書くだけでモデルを作成することができるため、開発者はモデルの定義に集中することができます。
SQLクエリをSQLファイルに記述できることは当たり前に聞こえるかもしれませんが、code editorと組み合わせることでさらに便利になります。例えば、code editorとしてVScodeを使うことにします。VScodeにはplugin機能があり、dbtのコーディングもサポートしてくれます。Wizard for dbt Coreでは、dbt特有の機能をサポートしています。dbt特有のref関数やsource関数を使った記述に対して、VSCode上で移動や参照ができます。
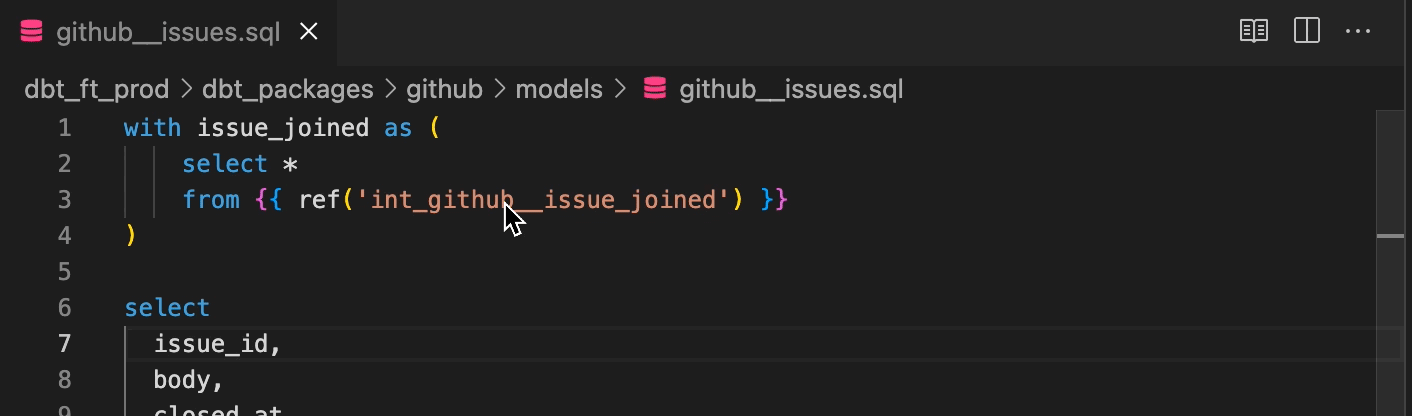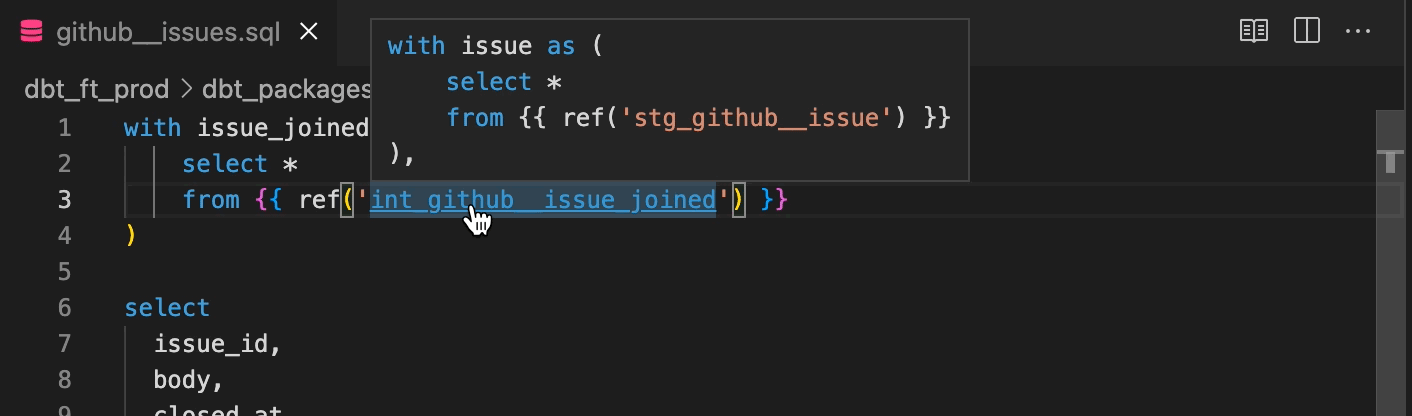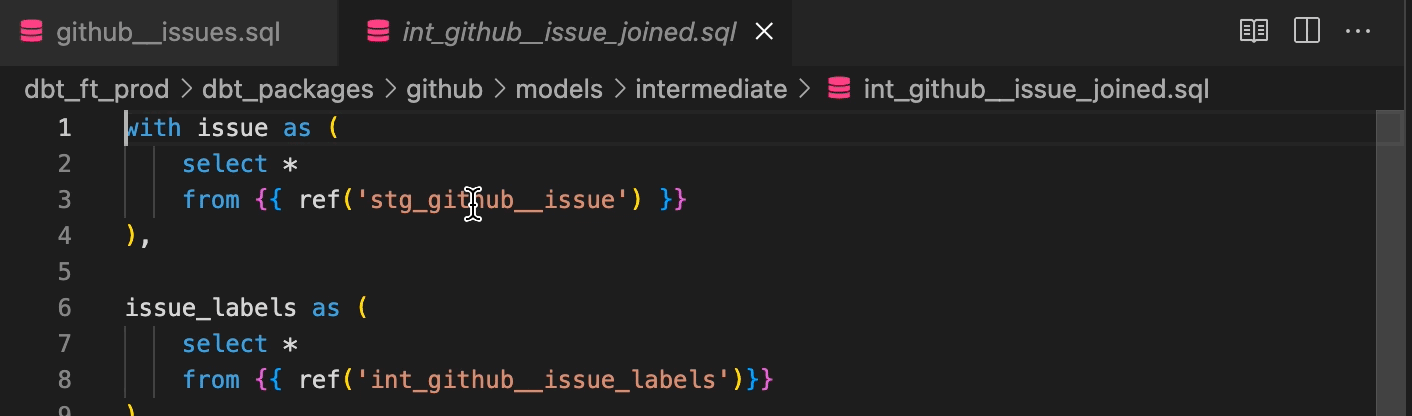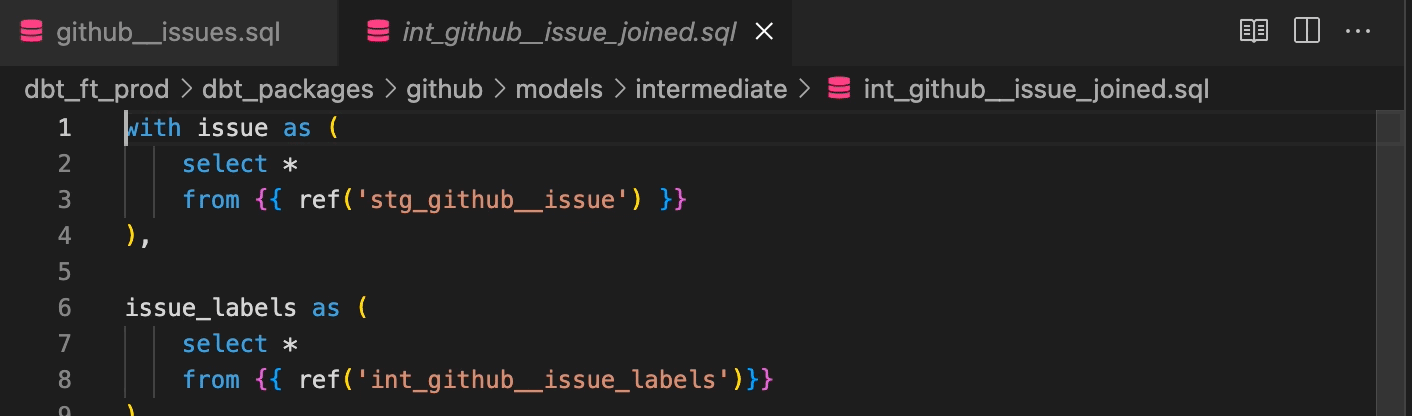
また、コンパイル前のクエリに対して、コンパイルの表示 (実際に実行されるクエリ) を表示することもできます。

このようなcode editorのpluginを活用できることもdbtでSQLを記述することのメリットです。
さらに、運用という面でもdbtはbest-practicesを用意しています。同じデータベースの中でも様々な用途のテーブルやビューが存在します。dbtは、2つのベクトルでデータの種類を分けており、これをディレクトリで分けることでSQLクエリの管理を容易にしています。
1つのベクトルが「staging」「intermediate」「marts」という3種類のレベルでの分類です。
- staging - 生のデータに対して、カラム名の変更など、少しの加工だけが加えられたデータ
- intermediate - 複数のテーブルがJOINされたり、ログデータが集計されたりなどしており、ある程度の成形がされて使い勝手の良いデータ
- marts - 実際にBIツールや機械学習などで読み込むための最終的なデータ
もう1つのベクトルが「finance」や「marketing」など、種類での分類です。これらは、レベルで分類されたディレクトリの下に作成されます。
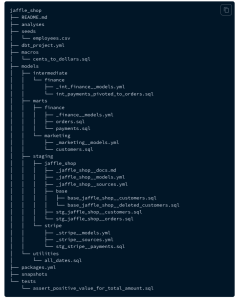
dbtはディレクトリ構成が重要だと考えられており、プロジェクトの管理者がbest-practicesに倣った適切な方法でディレクトリを管理することで、SQLクエリの開発者は、他の開発者が作成したクエリを簡単に探し出すことができます。
モデル同士の依存関係を自動で解決
先述したとおり、従来の方法ではtask同士の依存関係をユーザーがそれぞれ作る必要がありました。例えば、「task_of_table_X >> task_of_table_Y >> task_of_table_Z 」という依存関係でtable Zを作成したい場合には、これらのクエリに加えて依存関係を記述するDAGの設定ファイルが必要でした。しかし、重複した内容を記述することはユーザーのケアレスミスを招き、バグを発生させます。
dbtでは、これらの依存関係を設定するファイルは一切書く必要がありません。dbtにはSQLファイルをデータソースを指定する際にref関数やsource関数を利用します。これらの関数はdbtが実行される際にコンパイルされて実際に実行するSQLクエリを発行します。コンパイルする際に、これらの依存関係は自動で解決されるため、table Xとtable Yはクエリを書いておくだけで、自分で実行する必要もなく、また、設定ファイルも書く必要がなくなります。dbtがモデル同士の依存関係をデフォルトで解決する機能を持っている点もメリットの1つです。
本番環境に影響を与えずにクエリのテスト
Vinitusでは、SQLクエリが動作するか検証するためには、本番環境でクエリを実行してみるしかありませんでした。これは本番データを壊す恐れがあることや、データ規模が大きい場合はクエリの実行に多くの時間がかかるため開発者の生産性の低下にも繋がります。
dbtではprofiles.ymlを用いてデータベースの接続先を簡単に分けることができます。
jaffle_shop:
target: prod # default target
outputs:
prod: # for production env
type: postgres
host: postgres-service
user: airflow
password: {{ env_var("password") }}
port: 5432
dbname: jaffle_shop
schema: dbt_alice
threads: 4
test: # for test
type: postgres
host: vm-postgres-test.com
user: airflow
password: {{ env_var("password_for_test") }}
port: 5432
dbname: jaffle_shop
schema: dbt_aliceユーザーがlocal環境や開発環境でテストを実行したい場合は次のようにtargetを指定するだけでテスト用のデータベースにアクセスすることができます。
$ dbt test --target test --profiles-dir /path/to/jaffle_shop --project-dir /path/to/jaffle_shopdbt testコマンドは実際にクエリを実行することなく、そのクエリが正常に動作するかどうかを検証することができます。これによって、本番データを壊すことなくクエリのテストが実行できます。
クエリをローカルや開発環境でテスト
dbtを用いたETL batch pipelineのプロトタイプでは、3つのタイミングでテストが実行されることを想定しています。
- ユーザーが手動でdbt testを実行
- ブランチにpushされた際にCIとしてdroneがテストやモデルの変更箇所に対してだけdbt testを実行
- AirflowのUI上 (本番環境) でDAGが起動時にdbt run実行後に自動でdbt testも実行
ユーザーが手動でdbt testを実行
ユーザーはレポジトリをローカル環境にcloneすることで新たなモデルの作成やテストの追加に関する開発を行うことができます。この場合、profiles.ymlで本番環境と開発環境のコネクションの設定を分けることが推奨されます。ユーザーは本番環境にあるデータベースの構成に準拠した開発用のデータベースを事前に準備することで、本番データに対して影響を与えることなく、手軽にテストを行えます。また、本番データではデータ量が多いため、コンピューティングリソースや時間を割く必要があります。開発用のデータベースを作成することで、データの量を調整することができ、テストにかかるコストを削減することができます。開発環境であれば、データのコーナーケースや、あえて間違ったデータを挿入して正しくテストがされているかを確認することもできます。
ブランチにpushされた際にCIとしてdroneがテストやモデルの変更箇所に対してだけdbt testを実行
このシステムには、Continuous Integration (CI) としてdroneを利用しています。ユーザーはモデルやテストに変更を加えたい場合に、ブランチを切り、Pull Requestを作成します。このPull Request作成時とそのブランチにpushされたタイミングでdbt testを実行します。次のような流れでdroneの設定を行っています。
- mainブランチ (本番環境) をコンパイルしmanifest.jsonを含むtargetディレクトリを作成
- ユーザーが作成したブランチにmanifest.jsonを含むtargetディレクトリをコピー
- ユーザーが作成したブランチで、mainブランチで作成されたtargetを元にdbt testを実行
具体的には次のようなコマンドを最終的に実行します。
dbt test
--target dev
--profiles-dir /path/to/project
--project-dir /path/to/project
--defer
--state another-path/to/target # manifest.jsonを含む開発環境で作成されたmanifest.jsonを--stateオプションでdbtに渡し、--deferフラッグで差分検知を有効化することで、開発環境のモデルやテストと比べて変更された箇所に対してのみテストを実行するように設定できます。モデルを新規作成・修正した場合は、そのモデルが依存するテストのみを実行します。テストを新規作成・修正した場合は、そのテストが実行されるモデルに対してのみテストを実行します。これは、開発環境でのテストは全て成功しているという前提のもと、変更されたテストだけを行うこととでコンピューティングリソースや時間のコストを削減しています。
AirflowのUI上 (本番環境) でDAGが起動時にcosmosがクエリ実行後に自動でdbt testも実行
このテストは本番環境で実行されます。cosmosを用いてdbtプロジェクトをAirflowのDAGに変換する場合、cosmosはクエリの実行だけでなく、クエリのテストも自動で実行します。これは本番データに対して実行されるため、ユーザーはAirflowのUI上からクエリが期待通りに動作しているかどうかを確認することができます。
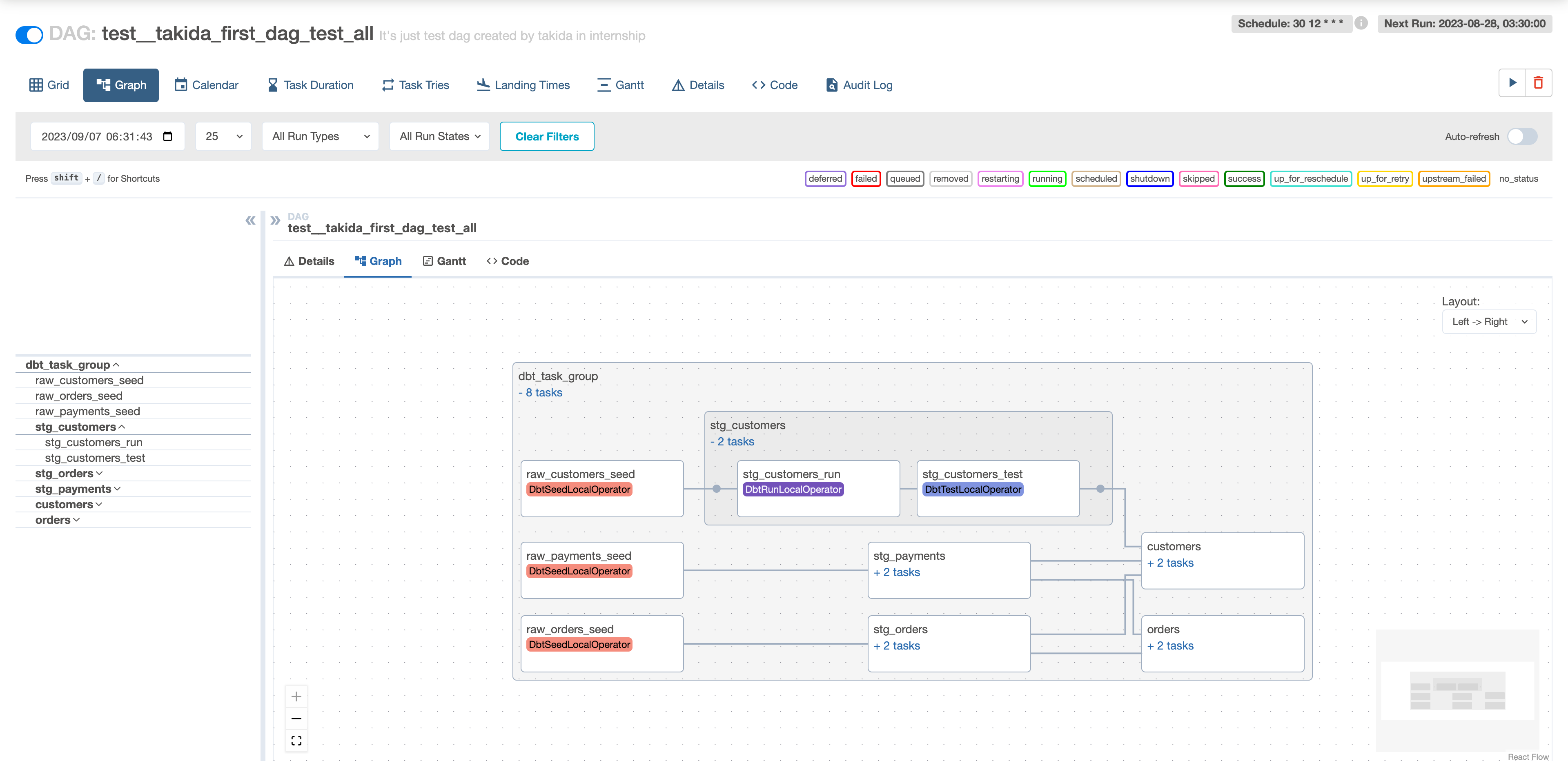
実際には下記のようにPythonでcosmosを利用します。
from cosmos import DbtTaskGroup
from cosmos.config import ProfileConfig, ProjectConfig, RenderConfig
profile_config = ProfileConfig(
profile_name=dbt_project_name,
target_name="prod",
profiles_yml_filepath=dbt_profile_path
)
render_config = RenderConfig(
select=conf["select"],
exclude=conf["exclude"],
)
dbt = DbtTaskGroup(
project_config=ProjectConfig(dbt_project_path),
profile_config=profile_config,
render_config=render_config
)cosmosはdbtプロジェクト全体をDbtTaskGroupとして作成します。別途でconfigの設定を加えることで、特定のモデルを選択・除外することができます。この1つのDbtTaskGroupに全てのモデルの実行とテストが含まれています。AirflowのUI上で確認できる依存関係も、全てdbtの中で自動で解決されます。
stateとselectによる差分検知
先ほどは本番環境のmanifest.jsonと比較することで、開発環境で新規作成・修正したモデルやテストに限定して実行できることを確認しました。これ以外にも、dbtにはstateメソッドを用いることで、テストの実行を効率化しています。
stateメソッドはselectオプションと使うことができ、文字通り状態を基準に実行対象の選択を行います。このstateメソッドは複雑であるため (State-based selection is a powerful, complex feature. from https://docs.getdbt.com/reference/node-selection/methods#the-state-method) 、実際にユーザーが使用する場合は、ドキュメントを熟読することをお勧めします。
例えば、dbt test に対して --select state:modified+ と指定すると、変更のあったモデルに対してのみテストを行うことができます。stateメソッドを使用することで、コンピューティングリソースと時間の削減をすることができます。
実はdbt Cloudには、Slim CI と呼ばれるCI機能がデフォルトで実装されています。dbt Cloudを用いる場合は、GitHubのレポジトリを連携するだけで、これと同じようなCIが自動で実行されます。dbt coreの場合は、dbt開発者が自分で実装する必要があります。
dbtの拡張性
今回のインターンでは時間の都合上で実装することはできなかったdbtの機能をいくつか紹介します。
dbt package
dbt packageは、dbtのプロジェクトに対して便利なマクロの関数やより複雑なテストを提供しています。一般的なプログラミング言語におけるライブラリのように、dbt でも dbt Hub に存在するパッケージを利用することで、ユーザーは関数で自分で作成する必要がなくなります。これらのpackageを利用するメリットは、一般的なプログラミング言語の開発でライブラリを使うメリットと同じです。ユーザーの時間コストを削減し、チーム間で共通のメソッドを使えるようになります。
ドキュメント作成
また、dbtの機能としてドキュメントの作成をすることが可能です。
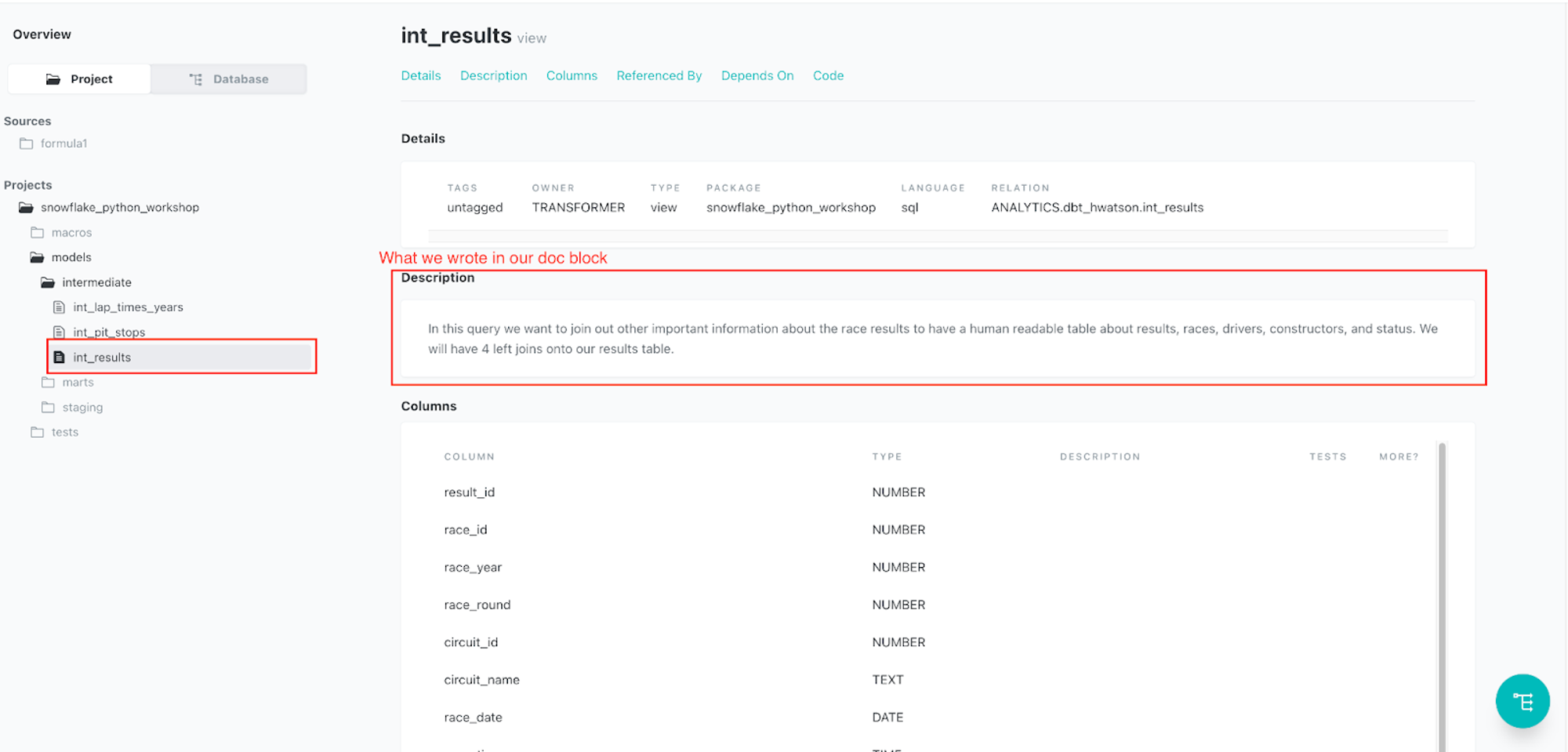
dbtは、プロジェクトやモデル、テスト、カラムの説明などをJSONファイルとして作成することができます。また、ドキュメント用のWeb UIも準備しているため、ユーザーはドキュメントを視覚的に確認することができます。
データの説明やドキュメントは、データウェアハウスやSQLクエリを記述している作業場所とは異なるサーバーに存在すること (esaやnotionなど) が多く、ユーザーがドキュメントを書かなくなることが課題として想定されます。しかし、dbtではモデルを定義するYAMLファイルと同じファイルに説明を記述することができるため、開発者は一般的なプログラミングでコメントアウトを残すようにドキュメントを書くことができます。
dbtのドキュメントはJSONフォーマットで作成されています。LINEのIU Webなど、既にデータカタログを持っている場合は、適切な形に変換することで、dbtのドキュメントをデータカタログに連携をすることができます。
LINEでのdbt導入にあたっての課題
dbtの導入によって、現在のLINEの大規模ETL batch pipelineの課題を解決しうることがわかりました。しかし、実際に導入するとなると、別の課題も出てきます。
最も大きな課題の1つとして、現在Vinitusを使っているユーザーにdbtを周知・理解してもらうことのコストが高いことです。LINEでは、多くのプロジェクト、チーム、開発者がVinitusでバッチ処理を作成しています。これを全てdbtで作成した新しいシステムに置き換えた場合、全ての開発者は新たにそのシステムの使い方やdbtの挙動を学び直さなければなりません。dbt特有の関数やコマンドの使い方は、ユーザーにとって必ずしも馴染みのあるものではありません。少なくともシステムの置き換え直後はユーザーは従来よりもモデルを作ることに時間がかかり、ストレスを感じることが想像できます。
この解決策としては、dbtの部分的な導入です。今回のインターンシップで作成したプロトタイプは、Vinitusの代替となるシステムでしたが、必ずしも全てを置き換える必要はありません。
例えば、内部的にdbt testだけを実装する、ユーザーの手動でのdbt testだけを実行できるようにする、などが考えられます。テストだけであれば、クエリが実際に実行されることはないため、事故で本番環境のデータが破壊されることはありません。現状でテストに対してストレスを抱えているユーザーは積極的にdbt testを使ってくれるはずです。これにより大規模な組織に対して少しずつdbtを周知させることが可能だと考えます。
また、プロジェクトやユーザーごとの環境の分離も課題として挙げられます。複数のプロジェクトが存在する場合、それぞれのプロジェクトでdbtやpackageのバージョンをどう管理するかが問題となります。例えば、1つのプロジェクトでdbt-mysqlとdbt-postgresを利用したい場合、dbt-coreのバージョンによってはpackageの依存関係に問題が生じます。package間の依存関係だけでなく、dbtとPythonのversionの関係にも考慮する必要があります。pipでdbtをインストールする場合は、仮想環境を使うことが推奨されています (https://docs.getdbt.com/faqs/core/install-pip-best-practices.md#using-virtual-environments)。さらに、データリソースにアクセスする認証の管理も問題となります。データベースへアクセスするためのユーザー名やパスワードをコードに直書きするべきではなく、それぞれのユーザーが環境変数を使って認証を利用するべきです。
プロジェクトごとの環境の分離に対する解決策の1つとして、プロジェクトごとに複数のレポジトリを作成することが挙げられます (https://docs.getdbt.com/blog/how-to-configure-your-dbt-repository-one-or-many#option-2-separate-team-repository-with-one-shared-repository)。レポジトリを複数に分け、異なる環境で実行することで、プロジェクトが複数あっても、それぞれを別々で管理することができます。
まとめ
dbtは、主にETL/ELT処理におけるデータ変換の役割を担います。ソフトウェアエンジニアリングのようにデータを管理することをコンセプトとしており、共同開発やテスト、ドキュメンテーション、モジュール化を可能にします。今回は、Apache Airflowを用いたETL batch pipelineに対してdbtを導入するプロトタイプを作成しました。データエンジニアリングの一般的な課題はもちろん、LINEの大規模データだからこそ発生する課題をも解消することができます。単にAirflowからdbtを実行するのではなく、cosmosによってdbtプロジェクトをDAGに変換することで、Airflowはdbtを認識することができ、AirflowのUI上でのグラフやlineageをより詳細なものにします。dbtには、シンプルな実行やテスト以外にも、状態に対する選択やパッケージの利用など、既存のbatch pipelineに対してワークフローを簡単にする機能を追加することができます。
インターン全体を振り返って
私にとって、Apache Airflowやdbtなどデータエンジニアリングと呼ばれる分野は、経験がほとんどなく、最初の2週間の全てを調査の時間に費やしました。さらに、プロトタイプをゼロから作るために必要な、kubernetesやCI/CD, 分散処理など、周辺知識も多く求められる開発でした。しかし、このインターンでは隔日で1on1を設定していただいたり、必要なときはチームのメンバーの方がすぐに相談に乗ってくださったりなど、手厚いサポートのおかげで目標を達成することもでき、学びの多い6週間となりました。直接の業務以外でも、対面・オンラインのランチイベントや、データエンジニアの勉強会にも参加させていただいて、LINEという大規模な組織でしか知ることができない知識や経験、雰囲気を体感することができました。
支えてくださったIU Data Connectチームの皆様、Vinitusチームの皆様、本当にありがとうございました。