
はじめに
2022年9月から6週間の就業型インターンに参加しました、慶應義塾大学大学院 修士1年の長谷川麟太郎です。
今回のインターンではTrustworthy AIチームに配属され、ドキュメント画像に対する加工検知モデルの研究・開発に取り組みました。
ここでは、インターンシップ中での自分の取り組みとその成果について報告します。
テーマ背景
近年、深層学習モデルを用いた画像加工技術についての研究が多くなされており、例えば、顔画像を加工することが可能なDeepfakeでは、精巧な顔画像の合成などが加工になります。
一方、Deepfakeによる政治家や芸能人の成りすましという問題も起きています。以下の右側の画像は、Deepfakeによって生成された画像ですが、左側の本物の画像と見分けをつけることはかなり困難です。
こういった問題対処するために「顔画像が本物かDeepfakeによって作られた偽物か」を見抜くようなモデルについても盛んに研究されています。

このような画像の加工は顔画像だけではなく、パスポートや免許証などのドキュメント画像を対象とした研究も多く行われています。
その一方、ドキュメント画像に対して加工したかどうか見抜けるようなモデルに関する研究は少なく、更に加工を見抜くモデルのための学習データについても、プライバシーの観点から大量のサンプルを確保することが難しかったり、そもそも加工事例が少ないという問題があります。
この問題を解決するため、ドキュメント画像を対象とした、リアリスティックな画像加工技術の開発に取り組みました。
また、今回のインターンでは様々なドキュメントの中からレシートの画像を題材として調査を行いました。
問題設定
Semantic Segmentationを用いた加工検知
加工検知を行うモデルはSemantic Segmentationというタスクによって学習されたものになります。
Semantic Segmentationではこちらの画像のように、与えられた画像から一つ一つのピクセルがどういった属性を持っているかを予測します。
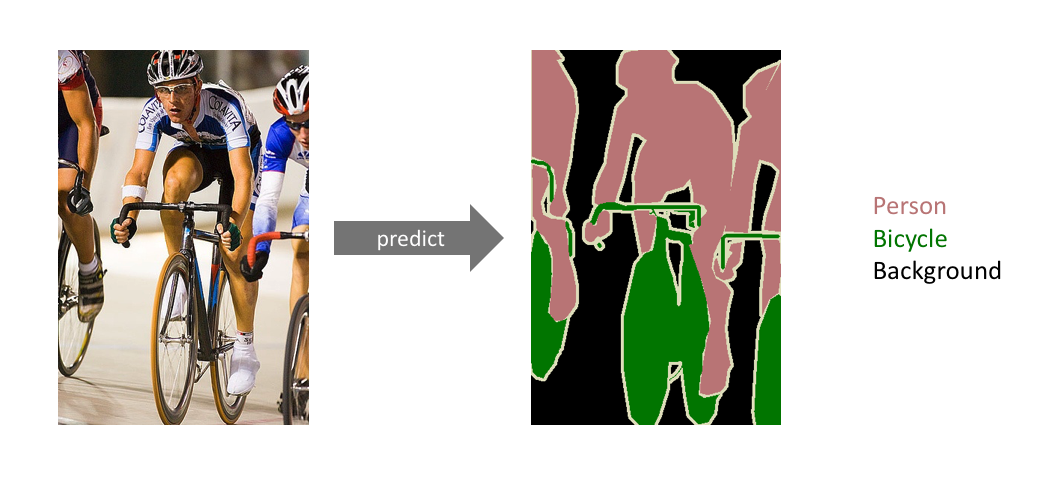
ドキュメントの加工検知を行うモデルはこの技術をベースとしたものになっており、入力画像の中でどの領域が加工箇所かを予測可能なものになっています。
以下の画像はドキュメント加工と検出結果の一例になります。
元画像と加工画像を比較すると、元画像の「WILLIAM JOHNSHON」の箇所が、加工画像では「Ward Smith」に置き換えられており、背景色などに違いがあることもわかります。
また、検知モデルは「検知モデルの出力」にあるように、ピクセル単位で加工と思われる箇所を予測することが可能です。
|
元画像 |
加工画像 |
検知モデルの出力 |
|---|---|---|
|
|
|
|



取り組む課題
しかしながら、既存の検知モデルでは上記のように人の目にも明らかな加工は検知できるものの、細かい加工であったり下図のような「文字自体を消す」という加工に対処できないという問題がありました。
|
元画像 |
加工画像 |
検知モデルの出力 |
|---|---|---|
|
|
 |
 |

検知モデルの性能を上げるためには、
- モデルのアーキテクチャを改善する
- レシート加工に有用な特徴料をとらえるため、pretrain時のデータセットを改善する
- 加工画像のデータセット自体を増やす
といった方法が考えられます。
今回のインターン期間では検知モデルの性能向上のため 3. 加工画像のデータセット自体を増やす という課題に取り組みました。
更に生成する画像については、これまで既存の検知モデルが見抜けなかったような精巧な画像であることを目標としました。
予備実験
ドキュメント画像を生成するためには、画像内のテキストを編集するような加工が必要となります。
そこで、そういった加工を目的とした技術であるDe-rendering[1]とSRNet[2]という手法について調査や評価を行いました。
De-rendering 概要
De-renderingは画像内のテキストを描画するためのパラメータを予測するための手法です。
例えばPower Point等でスライドにテキストを書き込む際には、テキストの内容・フォント・文字サイズ・エフェクト等、「描画に関するパラメータ」を指定する必要があります。
De-renderingでは、与えられたスライドの画像からテキストの内容・フォント・文字サイズ・エフェクトを逆に予測する、ということが可能になります。
更に、予測したパラメータを変化させて再びレンダリングすることで、元画像の一部を加工することもできます(下図)。

そして、今回対象としたレシート画像にDe-renderingによる編集をおこなった結果が以下のものになります。
「¥4,396」の箇所を「¥9,999」に変更する、という加工を行いました。
結果としては、本来一つのテキストを別々のテキストとして認識するケースが多いことが分かりました(「¥9,999」のカンマの前と後で微妙にフォントが違うことが見て取れると思います)。
De-renderingは内部にOCRを持っており、そのOCRの性能の問題で、テキストがうまく認識されないことがあることがわかりました。
|
元画像 |
加工画像 |
検知モデルの出力 |
|---|---|---|
|
|
|
|



SRNet 概要
SRNetは、画像に表示されているテキストの内容を編集するための手法です。
「元画像のテキスト」と「書き込みたいテキスト」の二つが入力となり、それらをもとに「書き込みたいテキストを元画像のスタイルに変換した画像」が出力されます。
以下の画像は左が元画像、右がSRNetによってテキスト内容を変換した画像です。どれも変換前のフォントや色などのスタイルを維持していることがわかると思います。

De-renderingと同様にSRNetでもレシート画像の一部について「¥4,396」を「¥6,789」にするという加工を行いました。
結果としては、以下のように該当箇所を丸ごと編集できたものの、エッジなどの角の部分が目立ってしまうという結果になりました。
|
元画像 |
加工画像 |
検知モデルの出力 |
|---|---|---|
 |
|
|


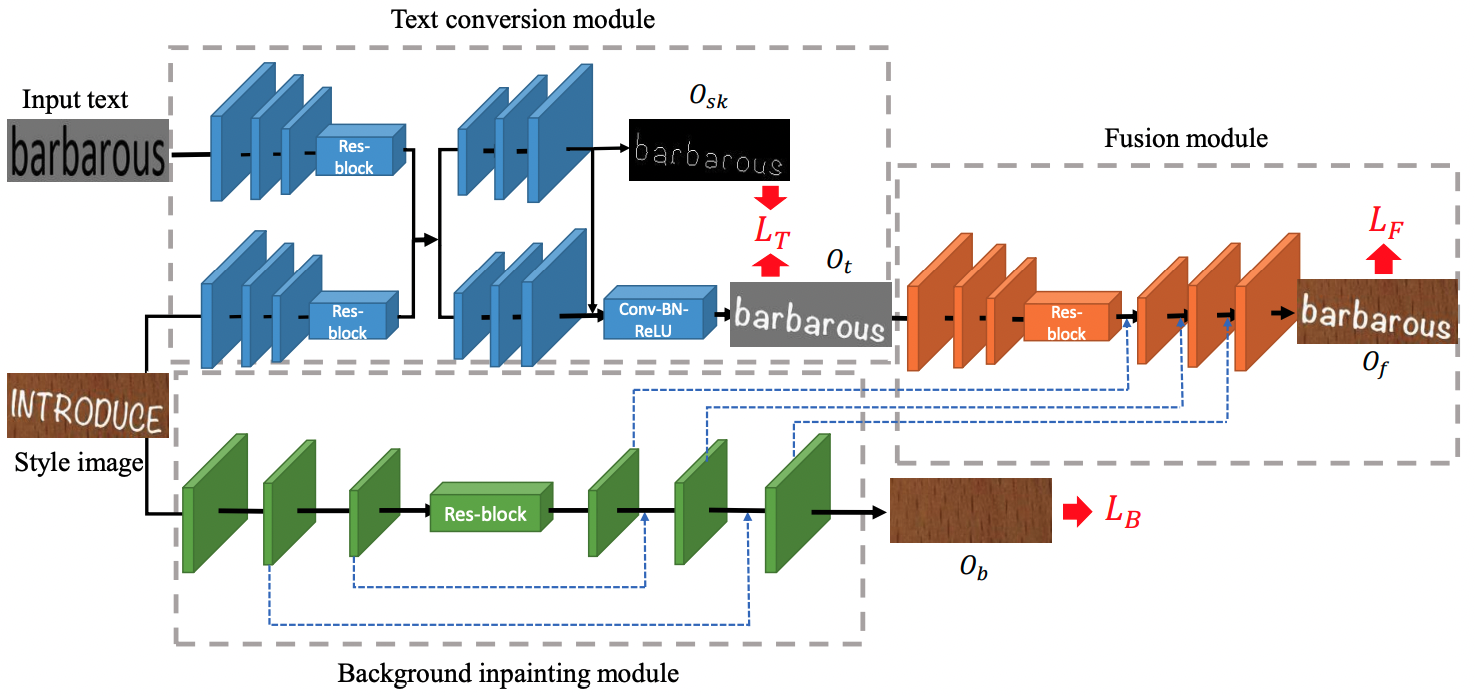
手法:SRNetの改良
予備実験の結果を踏まえて、「検知モデルに検知されず、様々な加工パターンの画像を生成する」ということを目標にSRNetの改良を行いました。
SRNetの問題点と対応方法
SRNetでは先ほどの図のようにエッジが目立ってしまい、検出モデルが反応する例を多く確認できました。
原因としては、SRNetではテキストの生成は可能なものの、テキストの背景に関してはうまく生成ができていないという点が考えられます。
ドキュメント画像を生成する場合、生成すべき画像は「テキスト」と「背景」の二つに分けることができ、自然な画像のためにはこれらの両方についてうまく生成する必要があります。
「テキスト」についてはSRNetで既に自然なテキスト画像ができているため、「背景」について、自然な背景画像を生成することが可能なInpaintingという技術を用いました。
このようにSRNetとInpaintingを組み合わせることで、自然なドキュメント画像の生成を目指しました。
生成画像の2値化
SRNetにより生成した画像について、Otsu's method[3]により2値化を行い、黒いピクセルの領域についてはSRNetの生成画像、白いピクセルの領域についてはInpaintingによって生成した背景画像のピクセルを利用して最終的な生成画像を生成しました。
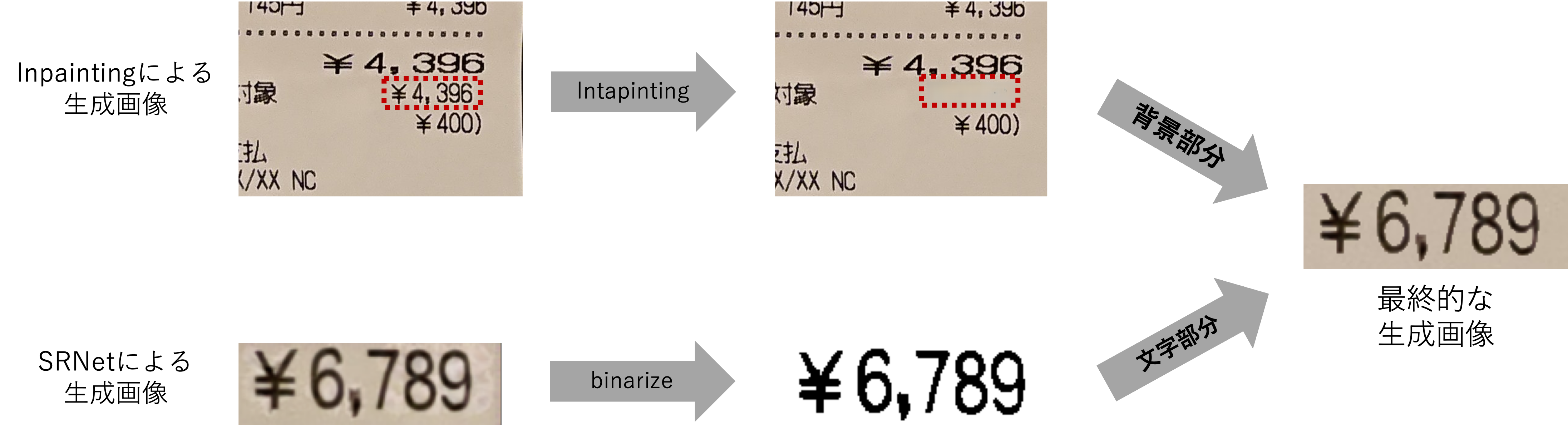
結果
2値化処理を行った結果(表上段)は以下のようになります。
両者について「加工画像」を比較すると、2値化処理を行なった生成結果の方が、背景色が自然でエッジの箇所も目立たず、検知モデルの出力についても検知領域が少なくなっていることが見て取れます。
|
元画像 |
加工画像 |
検知モデルの出力 |
|
|---|---|---|---|
|
2値化処理 あり |
|
|
 |
| 2値化処理 なし |  |
 |
 |


おわりに
今回のインターンでは、所属していたチームだけでなく、一緒に研究を進めたCV Labの方々のサポートもあったおかげで、スムーズに研究を進めることができました。
特にメンターの長田さんは頻繁に1on1をしてくださり、取り組むべきタスクや方向性に関して悩むことなく、充実した6週間を過ごせたと思っています。
また自身の研究だけでなくチーム全体のミーティングなどを通して、他のメンバーの方がどのような研究をどのようなサービスのために行なっているのか、ということも知ることができました。
企業での研究がサービスを通してどのように社会に役立つのか、というイメージを持つことができるのもこのインターンの良い面だと思います。
今回のインターンシップで得た経験を今後の大学での研究に活かしていければと思います。本当にありがとうございました!
参考文献
- [1] Shimoda, W., Haraguchi, D., Uchida, S. and Yamaguchi, K., 2021. De-rendering stylized texts. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 1076-1085).
- [2] Wu, L., Zhang, C., Liu, J., Han, J., Liu, J., Ding, E. and Bai, X., 2019, October. Editing text in the wild. In Proceedings of the 27th ACM international conference on multimedia (pp. 1500-1508).
- [3] Otsu, N., 1979. A threshold selection method from gray-level histograms. IEEE transactions on systems, man, and cybernetics, 9(1), pp.62-66.