
こんにちは、Developer Successチームの桃木です。
3月12日(土)の13時より、LINE/メルカリ/クックパッド/ディー・エヌ・エー/サイバーエージェント/リクルートの6社合同でSREに関するオンラインイベントを開催します。
- 詳細情報/Connpass : https://line.connpass.com/event/236497/
- Twitter : https://twitter.com/SRE_GodoBenkyo

この記事では、「6社合同 SRE勉強会」でLINEから発表を行う2つのセッションについて、講演の元となる課題背景や推しポイントを、Pre Blogとして登壇者にまとめてもらいました。
なお、Pre Blog公開から1週間の期間で各セッションで解説してほしいポイントや聞きたい質問などをSlidoで事前募集し、登壇者に連携してセッション中やAsk the Speakerで取り上げていきます。投稿されているものに対して投票・賛同することも可能です。たくさんの投稿や投票をお待ちしています。
【Track A / 11:15-12:00】約9倍のスパイクに備える取り組み(LINEスタンプのあけおめLINE) / Toshiya Kato
23時59分に10k rps、1分後に90k rpsを超える突負荷を記録した2022年のあけおめLINE。LINEスタンプでこのような負荷に「耐える技術」だけではなく、「備える」ために行った具体的な取り組みを紹介します。SRE本21章の「過負荷への対応」の実践が難しいと感じている方へのヒントになればと思っています。
自己紹介とLINEスタンプシステムの紹介
LINEのスタンプや着せかえ、ウォレットタブやホームタブ、LINE STOREのSREを担当している加藤です。Embedded SREとして働いていて、ドメインロジックまで含んだReliabilityの制御を行っています。
LINEスタンプは、主にJava/Kotlinを用いて開発されており、大小合わせて50を超えるマイクロサービス 、複数の種類のDBやバッチで構成されています。SREチームはそれら全体のReliabilityを対象にしています。
この記事と勉強会について
この記事では、2022年01月01の「あけおめLINE」を処理する際の課題を紹介し、3月に開催される6社合同SRE勉強会本番では、それらを私たちがどのように乗り換えたのかを説明、Ask the speakerでさらに質問にお答えできたらと思っています。
課題の紹介に移る前に、まず実際の負荷のグラフをご覧ください。このグラフはスタンプや絵文字を送信する際に、所有権を確認するマイクロサービス のrps/nodeのグラフです。
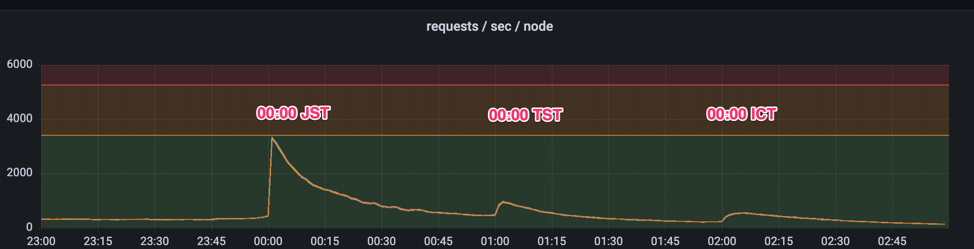
グラフにはスパイクが3つあり、それぞれ日本標準時(JST)・台湾標準時(TST)・タイ標準時(ICT)での「あけおめLINE」です。
このグラフの黄色いラインが事前に予測した最大アクセス数で、赤いラインが安定して処理できる限界値を表しています。今年はスタンプや絵文字の送信数について、事前の予測がかなり高い精度で的中することができました。
これら最大アクセス数の予測や処理できる限界値の設計などに様々な課題がありました。ここからは、その課題を紹介していきます。
2020年、2021年の「あけおめLINE」について
実は、前回や前々回の「あけおめLINE」では、残念ながらLINEスタンプのシステムでは過負荷による障害が発生しました。それぞれ直接的な原因は全く別のものでしたが、「あけおめLINE」の本質的な難しさを実感・説明できるものでした。
たとえば前々回の2020年では、新しく追加された機能で過負荷が発生しました。前回の2021年では、機能自体は新しくないものの、クライアントサイドの改修により呼び出し元が増えていました。
これらからわかるのは、「あけおめLINE」による過負荷を防ぐためには、下記の課題を乗り越える必要があるということです。
- 新しく追加された機能は、去年以前のデータの蓄積がないため、精度の高い負荷見積もりは難しい
- 1年間にあったサーバーサイド・クライアントサイドの変更の影響を把握し切ることは難しい
- 「あけおめLINE」に合わせて開催される公式/非公式なキャンペーンを把握し、負荷を見積もることは難しい
ちなみに今年は、2021年に送ったスタンプのトップ3を集計して共有できるLINE公式のキャンペーンを実施していました。このようなキャンペーンを毎年企画、実施しています。

さて、SRE本と呼ばれる『SRE サイトリライアビリティエンジニアリング』の21章には、まさに「過負荷への対応」という章が用意されています。
ここで、Google SRE本に記載のある過負荷への対応を参照してみます。
Google SRE本、21章 過負荷への対応
最初に記載があるのは、特定のリージョンで過負荷が発生した際に、空いているリージョンに負荷を分散させるといった手段です。これは『サイトリライアビリティワークブック』でも詳細が数ページに渡って説明されている重要かつ効果的な手段です。
しかし、私たちLINEは日本を中心としたアジアで主に展開しており、「あけおめLINE」を捌くだけのリソースを常に用意しているわけではありません。
また、単純さのためにCPUがボトルネックになるように設計するという指針も書いてあります。では、50を超えるマイクロサービス で、高負荷の際にCPUがボトルネックになっていることを事前にどのように確認すれば良いでしょうか?
さらに前回・前々回は障害が発生したため、クライアントやユーザー自身によるリトライによって、正確なアクセス需要を計測することができませんでした。このような状態で、アクセス数を見積もり、許容されるコストの範囲内でリソースを追加する必要がありました。
過負荷に対する課題
ここまでの内容で、私たちの課題を簡単に整理してみます。
- リージョンレベルのロードバランスの機能はない
- 事前のアクセス数予測とサーバーリソースの準備が必要
- 前回・前々回の障害のため、アクセス需要のデータが不十分
- 新規機能は前年のデータがない
- 1年間に蓄積された全ての変更内容の影響度を予測するのは難しい
- 様々なキャンペーンにより、ユーザー行動は平時と大きく異なる
- その他
- 50を超えるマイクロサービスで、CPUがボトルネックでないものを見つけたい
これらの課題はそれぞれが非常に難易度の高いものです。そのため、私たちはこれらの課題に真正面から挑みつつも、並行して「もし過負荷が発生してしまったら?」という前提のもとで対策も講じました。
その結果、2022年は前年以上のアクセス数を過負荷なしで乗り越えることができ、さらにサーバーリソースも30%以上削減することができました。
3月に開催される勉強会本番では、主に下記「予防・検知・対応」の3点について、苦労した点や費やした時間や人数も含めて、すべてご紹介したいと思います。
- 過負荷にならないようにするための予防
- 過負荷の予兆を検知するための準備
- 過負荷が発生した時のための即時的な対応の準備
Slidoで事前質問の募集も行っています。可能な範囲で当日の発表資料にも盛り込みたいと思いますので、当日こんな話も聞いてみたいというものがありましたら、お気軽に質問や要望をお願いします。
「約9倍のスパイクに備える取り組み(LINEスタンプのあけおめLINE)」への事前質問やリクエストの募集
https://app.sli.do/event/21NXKVUcbeBJyAvhGa9ov4 (質問受付 : 2/15(火)-2/21(月))
登壇者情報
Toshiya Kato (@maruloop)
LINE株式会社 Communication & Service Integration室 SRE / Tech Lead
LINEアプリのスタンプ、着せかえ、絵文字、ホームタブ、ウォレットタブのSREを担当。
過去の関連記事
【Track B / 14:15-15:00】Metrics集約のデータフローとシステムデザイン、監視について / Wataru Manji
大規模なシステムでよく使われるようになってきたPrometheusのagent化と大きなTSDBへのremote-writeによるデータ集約モデルについて紹介し、スケーラビリティのためにどのようなデザインを採用するべきか、そのシステムそのものの監視方法などについて解説します。
Verda室でSREチームのマネージャーをしている萬治です。
VerdaとはLINEが社内で運用しているIaaS/PaaSで、国内外の数万台のサーバや数百のk8sクラスタ、LBなどを管理しています。プライベートなクラウド基盤としては、国内どころか世界的にも最大級の規模を誇っています。
Verdaが提供しているサービスは両手の指に収まらない程度にあり、それらを開発するチームも国内外の拠点に分散して運営されています。日本語、英語、韓国語が飛び交うとても刺激的な職場です(笑)
発表内容について
今回の発表では、Verdaの監視システムの中からMetrics監視に焦点を当てて、複数のテーマについてテクニカルな視点でお話しするつもりです。
例えば、従来のVerdaのMetrics/Log監視は基本的に各開発チームが主体的に設計、運用していたのですが、サービス規模の拡大につれていくつかのチームで似たようなスケール問題に直面することになりました。それはどういったものだったのか? であったり。
また、LINEのインフラ規模の拡大ペースはおおよそ年ごとに30%くらいなんですが、これが日常的なMetrics監視のオペレーションにどう影響しているかという話。
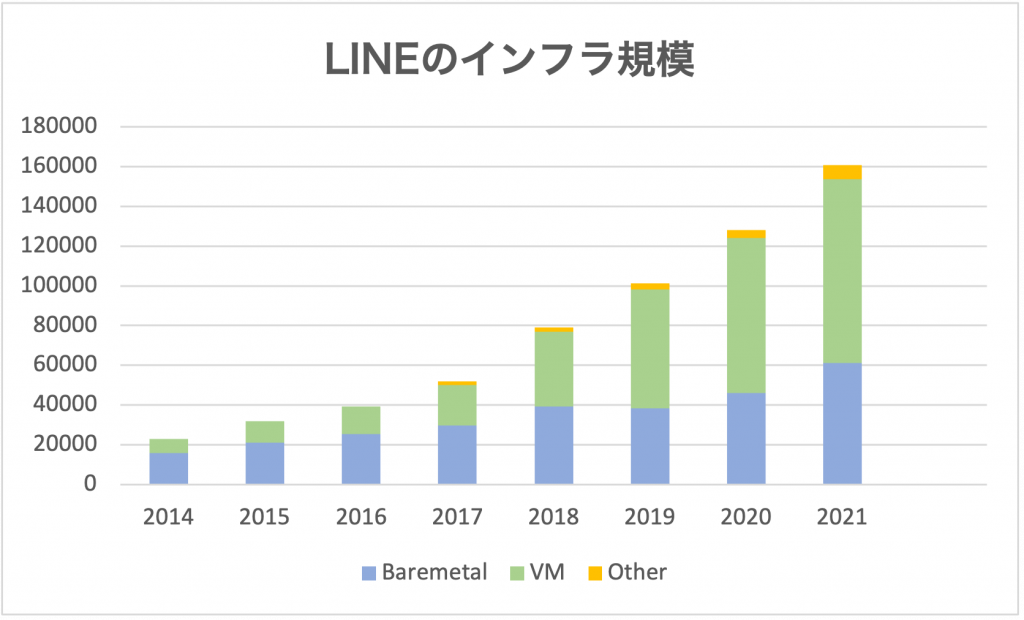
メインコンテンツとして、最近デザインと実装を進めている「Verdaの全サービスが乗ることができるMetrics監視システム」の目標、おおまかなデザインや具体的なデータフロー、検討した事項などをお話ししたいと思います。
「大変そうだな...」というより「面白そうだな!」って思ってもらえるような発表にするつもりなので、楽しみにしてもらえると嬉しいです。
こういう部分について深掘りしてほしい、みたいなリクエストがあったらなるべく盛り込むつもりです。事前に需要をキャッチできるとこちらとしてもやりがいが出てくるので、気軽にどしどしリクエストしてください。
「Metrics集約のデータフローとシステムデザイン、監視について」への事前質問やリクエストの募集
https://app.sli.do/event/gaAuwpqBcBBaLKn2acZCaT (質問受付 : 2/15(火)-2/21(月))
登壇者情報
Wataru Manji (@_manji0)
LINE株式会社 Verda室 Verda Reliability Engineeringチーム マネージャー
LINEのインフラプラットフォームの全てのサービスについて信頼性の定義と改善を考えたりしている。好きなゲームはウマ娘、苦手なゲームはスイカ割り
過去の関連記事
まとめ
このPre Blog企画は、本日2月15日から2月22日までにかけて平日毎日連続して公開され、各セッションへの事前質問・リクエストの募集企画も同様に実施されます。ぜひ、あわせてご確認ください。
- LINEの記事(本記事) : https://engineering.linecorp.com/ja/blog/sre-benkyokai-preblog/
- サイバーエージェントグループの記事 : https://developers.cyberagent.co.jp/blog/archives/34573/
- リクルートの記事 : https://blog.studysapuri.jp/entry/2022/02/17/sre-study-session
- ディー・エヌ・エーの記事 : https://engineering.dena.com/blog/2022/02/sre-joint-study-session/
- メルカリグループの記事 : https://mercan.mercari.com/articles/33154/
- クックパッドの記事 : https://techlife.cookpad.com/entry/2022/02/22/140204
現在SREという立場で業務に取り組む方、規模の大きい会社・サービスにおけるSREの事例や課題解決アプローチに興味がある方、今後のキャリアでSREという領域・役割を検討している方など、SREに興味のあるたくさんの方々のご参加をお待ちしています!
詳細情報/Connpass : https://line.connpass.com/event/236497/