
はじめに
法政大学情報科学部ディジタルメディア学科3年の伊藤 葵と申します。私は、LINEインターン(技術職就業型コース) 及びアルバイトとして2022年8月から8ヶ月間、音声認識の研究に携わりました。
インターン & アルバイトでは、実際に企業で行われている研究を進めるだけでなく、人生初の 学会発表 (題: 日本語音声認識における語彙集合分割とマルチタスク学習による目的語彙抽出)、さらには国際会議への論文投稿もさせていただきました!
本ブログでは、研究内容の紹介・人生初の学会・インターンの感想についてご紹介いたします。
研究内容の紹介
本インターンで進めた研究について、簡単にご説明します。詳しい仕組み等が気になった方は、ぜひ論文に目を通してみてください。
問題背景
現在、音声認識の技術は日々進歩し、さまざまなサービス(会議の文字起こしや音声検索etc.)で活用されています。多岐にわたる活用方法に伴い、認識結果の扱い方も目的に応じて変わってきます。例えば、文字起こしといった音声記録では”発話内容すべて”の正確な記録が望まれます。これに対し、音声検索や電話対応では、発話すべてではなく目的に応じた一部の情報が重要となります。

AI が注文対応をするケース。メニュー名(=カタカナ名詞で表現される情報)のみを必要としています。
本研究では、End-to-End 音声認識の中でも発話に登場する一部の欲しい情報・単語のみを認識するというタスクについて考えていきます。
提案手法 「目的+目的外の語彙によるマルチタスク学習」
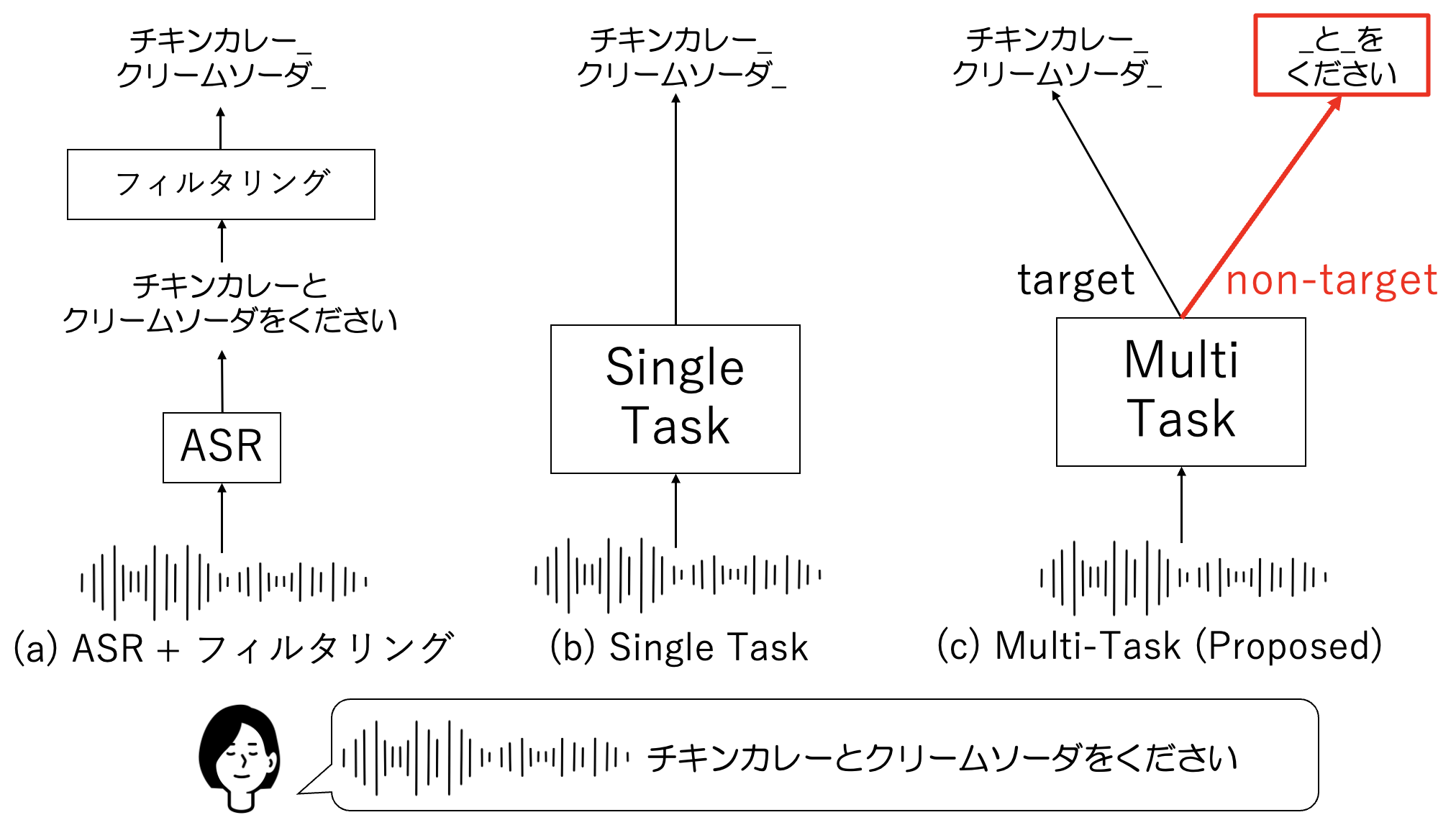
従来手法 (a)音声認識+フィルタリング, (b)Single-Task と本研究で提案する手法 (c)Multi-Task
発話から目的語彙を抽出するにあたり、従来では
- (a) 音声認識(ASR) + フィルタリング
- (b) 目的語彙のみの教師テキストを用いた Single-Task
といった手法がありました。例えば、「チキンカレーとクリームソーダをください」という電話注文からメニュー名を抽出するというタスクがあった場合、
- (a) 全発話内容(「チキンカレーとクリームソーダをください」)を認識した後、認識結果をフィルタリングすることで欲しい単語を取得
- (b) 目的語彙(メニュー名を表すカタカナ名詞)のみの教師テキスト(「チキンカレー, クリームソーダ」)で学習することで認識結果として欲しい単語のみを出力するモデルを生成
という手法になります。しかし、(a) の手法だと、前段の音声認識システムの認識誤りが後段のフィルタリング処理に悪い影響を及ぼします。
例) 「チキンかれーとくりーむソーダをください」
→メニュー名 = カタカナ名詞というルールでフィルタリング
→ チキン、ソーダ (違う!!!)
また、(b) の手法では、目的外の語彙(「__と__をください」)に対して認識誤りを起こす恐れがあります。そこで本研究では、これまで使用されていなかった「目的外の語彙」という情報に着目し、
- (c)目的+目的外の語彙の情報を用いたマルチタスク学習
という方法を提案しました。提案手法には、2つポイントがあります。
- 二種(目的語彙 + 目的外の語彙) の教師テキスト
- マルチタスクネットワーク
それぞれのポイントについてご説明します。
1. 二種(目的語彙 + 目的外の語彙) の教師テキスト
提案手法では、目的語彙の教師テキストに加え、目的の語彙と排反の関係である "目的外の語彙" のみの教師テキストも用いて学習をするようにしました。それぞれの教師テキストで、不要となる語彙の箇所は<oov> (Out Of Vocabulary) トークンで置換しました。

「チキンカレーとクリームソーダをください」という発話に対する二種の教師テキスト
2.マルチタスクネットワーク
提案手法では、目的語彙(target) だけでなく、目的外の語彙(non-target)の情報も含めた学習をするため、マルチタスクネットワークの構造をとりました。
赤枠・赤字で示した箇所が、提案手法で従来の学習(Single-Task)に追加した部分(目的外の語彙へのアプローチ)です。Encoder(入力された音声を特徴量へ変換)の出力に対し、従来扱ってきた目的語彙(target)だけでなく目的外の語彙(non-target)の損失(正解と認識結果の差)も学習に用いるようにしました。
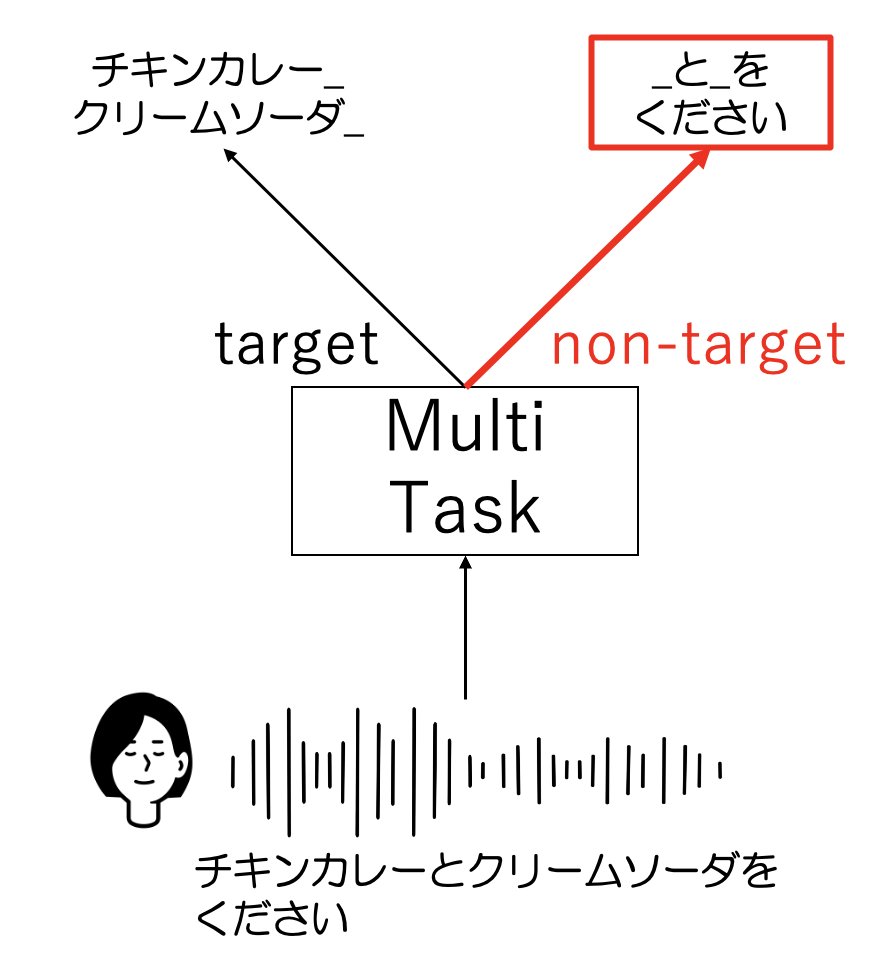
入力音声に対するマルチタスクネットワーク
実験(カタカナ名詞の抽出)
本研究では、目的語彙抽出タスクの一つとして、発話から「カタカナ名詞」に該当する語を抽出できるか実験しました。学習・検証・評価には、日本語話し言葉コーパス (Corpus of Spontaneous Japanese : CSJ)というデータセットを使用しました。評価用データセットに登場するカタカナ名詞のうち、25%は学習用データセットに登場しない未知語でした。カタカナ名詞抽出タスクということで、教師テキストは"カタカナ名詞"と"カタカナ名詞以外"の 2 つに分割しました。
実験結果
本実験では、従来手法 2 種(フィルタリング、シングルタスク)と提案手法それぞれによる目的語彙抽出の性能を以下の 2 つの観点から評価しました。
- 発話中のカタカナ名詞に対する文字誤り率
- 発話に登場するカタカナ名詞を正しく抽出できず誤って認識した割合
例「チキンカレーとクリームソーダをください」→ 認識結果: チキン、クリームサーダ、クダ
カレーを認識できていない(削除誤り)、ソーダをサーダと置換(置換誤り)、くださいのクダを余分に認識(挿入誤り)
- 発話に登場するカタカナ名詞を正しく抽出できず誤って認識した割合
- カタカナ名詞を含まない発話への挿入誤り率
- カタカナ名詞を含まない発話(例「今日は食堂で食べよう」)に対してカタカナ名詞が入っている(例「今日はショク堂で食べよう」→ ショク)と誤って認識した割合
今回計算したのは誤り率のため、値が小さいほど認識性能が良いモデルということになります。
各提案手法での認識結果は、以下の表の通りです。
|
Model |
発話中のカタカナ名詞に対する |
カタカナ名詞を含まない発話への |
||||||
|---|---|---|---|---|---|---|---|---|
|
Eval1 |
Eval2 |
Eval3 |
All |
Eval1 |
Eval2 |
Eval3 |
All |
|
|
音声認識+フィルタリング |
8.63 |
8.05 |
7.18 |
8.12 |
3.38 |
3.72 |
2.58 |
3.18 |
|
目的語彙のみでの学習(Single-Task) |
10.31 |
11.57 |
11.19 |
10.96 |
2.29 |
2.70 |
2.40 |
2.39 |
|
目的語彙+目的外の語彙(Multi-Task) |
7.20 |
9.20 |
8.26 |
8.16 |
0.97 |
2.37 |
2.12 |
1.86 |
|
中間層の出力もフィードバックした Multi-Task |
6.95 |
9.52 |
7.42 |
8.00 |
1.33 |
3.49 |
2.21 |
2.36 |
提案手法によって、従来手法よりも文字誤り率は 8%, 挿入誤り率 は 76% 改善した値を得ることができました。
認識結果の例
二種(目的語彙 + 目的外の語彙) の教師テキストを用いたマルチタスク学習によって、目的語彙と目的外の語彙の関係を学習することが可能となりました。これにより、削除誤りや挿入誤りの改善につながりました。
削除誤り改善の例
発話: 「会話文翻訳システムに適用いたして」
【Filtering】_シテム_ フィルタリング前の音声認識の性能に依存
【Single-Task】_ 削除誤り
【Multi-Task】_システム_
【Intermediate Multi-Task】_システム_
「システム」というカタカナ名詞に対し、フィルタリングによる目的語彙抽出では、前段の音声認識の性能に依存し誤字が見られます。目的語彙のみで学習した Single-Task では、そもそも目的語彙があると認識していません。これに対し、提案手法では正しく「システム」という目的語彙(カタカナ名詞)を抽出できていることが分かります。
挿入誤り改善の例
発話:「感じですねで札幌で買うよりもカニとか」
【Filtering】_カニ_
【Single】_サポール_カニ_ 挿入誤り
【Multi-Task】_カニ_
【Intermediate Multi-Task】_カニ_
「札幌」という名詞に対し、目的語彙のみで学習した Single-Task のモデルは「サポール」と誤認識しています。提案手法では、このような挿入誤りが改善されていることが分かります。
研究まとめ & 今後の課題
本研究では、End-to-End 音声認識における発話に登場する単語抽出というタスクについて取り扱いました。従来使われていなかった目的外の語彙情報も含めたマルチタスク学習によって、目的語彙と目的外の語彙の関係を学習することが可能となり、認識性能の向上につながりました。
本研究では"カタカナ名詞"を抽出しましたが、提案手法による単語抽出は他のケースにも応用が効くと考えられます。
今後の課題として、音声認識を活用したアプリケーションの需要に沿った目的語彙抽出(暗証番号を表す数詞など)や言い淀みといった一部の単語除去への応用が挙げられます。
人生初の学会
本研究内容は、2023年2月28日〜3月1日 沖縄県立博物館・美術館で開催された電子情報通信学会 音声研究会(SP)にてオーラル発表をしました!
人生初の学会という場で、聴講だけして帰るのではなく壇上に立って、これまでの研究成果を発表することができ本当に楽しかったです。

人生初の学会!!
はじめは「どういうことを研究したのかな〜」と様子を見ていた聴講者の目が発表をする内にどんどん真剣なものへと変わって、具体的な学習の仕組みや研究内容について興味を持ってくださったのをひしひしと感じ学会発表の楽しさを味わうことができました。質疑応答では、研究に関わっていない第三者の視点を得ることができ勉強になりました。
また、学会という場を通して多くの方と交流することができ、本当に貴重な経験をさせていただきました!!

人生初の沖縄!!
インターンの感想
今回の長期インターンを通して、貴重な経験を沢山させていただきました。
人生初のインターンではじめは緊張しましたが、所属するSpeechチームの社員の皆さんは気さくで優しい方が多く、暖かく迎えてくださったおかげで、すんなり組織に入っていくことができました。
インターンは基本リモートという形式でしたが、何度か四谷オフィスにも出社させていただき、社員の皆様ともたくさん交流をすることができて楽しかったです!

LINE Cafe も堪能させていただきました。スムージーおすすめです
LINE株式会社という最先端を進む企業に、インターンという形で実際に入って痛感したことは、日々の業務の進行スピードと、社員一人一人の能力の高さです。インターン用の短期課題ではなく、実際の研究に従事させていただき、さらにはグループミーティング等にも参加させていただいたことで、これから業界に足を踏み入れていくにあたり求められている力を、身をもって知ることができました。
おわりに
学部 3 年でインターン開始時は大学のゼミにも正式配属されておらず、研究のノウハウも分からない状態の私でしたが、ここまで研究を進め、人生初の論文投稿・学会発表・国際会議への投稿まですることができたのは、メンターの小松達也さんをはじめ、直属の上司であった木田祐介さん、Tech リーダーの藤田雄介さん、Speech チーム・ASP チームの皆様による強いお力添え、そして LINE株式会社という環境があったからだと痛感しております。ありがとうございました!
また、インターンの同期という形でご一緒した藤村拓弥さん・西川勇太さんは素敵な先輩方で、LINE のインターンという場で出会えて嬉しかったです。
8ヶ月という長い期間、本当にお世話になりました!

左から、同期のインターン生の藤村拓弥さん、西川勇太さん、私(伊藤 葵)
⭐︎お二方のインターンブログも公開されます!ぜひご覧ください。