
はじめまして、名古屋大学大学院情報学研究科修士1年の畔栁伊吹です。2021年の夏にLINEのAI開発室のリサーチャーインターンシップに6週間参加しました。今回のインターンはコロナの影響でフルリモートで参加しました。普段と異なる環境かつ限られた時間の中で成果を出せるか不安でしたが、メンターの方と毎日30分程度ミーティングの時間があったため、問題なく進めることができました。
インターンでは、「汎用的な音声表現のための複数のサンプリング戦略を用いた自己教師あり学習法」の開発、実験、論文執筆を行いました。論文は音声・音響・信号処理分野における世界最大規模の国際学会ICASSP2022に投稿し、採択されました[1]。以下では、インターンで取り組んだ研究の概要について書きます。
研究背景
音に関連するタスクには、音声認識、話者識別、コマンド認識、音響イベント検出、ピッチ推定、など様々な種類があります。ニューラルネットワークの発展に伴い様々な手法が高い性能を実現していますが、それぞれのタスクに対して専用の学習用データを収集し、教師ラベルを付与する必要があるため多くの労力が必要となります。コマンド認識や感情認識などタスクによっては、オーディオタグ付けなど大規模な教師ラベル付きデータが手に入る別のタスクの学習済みモデルをファインチューニングすることで、所望のタスクの教師ラベル付きデータが少なくとも高い性能を実現できることが確認されています[2]。しかし、10秒などの長い音データに対してラベルを付与するオーディオタグ付けタスクで得られる事前学習モデルは、時間変化に関する情報が圧縮されており、音声認識や音響イベント検出など細かい時間情報が必要なタスクの事前学習モデルとして使うことは難しいです。また、大規模な教師ラベルを持つデータセットの作成は困難なため、教師ありで事前学習を行えるタスクは少ないです。一方、教師ラベルの付与されていないデータは比較的容易に収集することができます。こうした背景から、教師ラベルの付与されていない大規模なデータセットから様々なタスクに適用可能な事前学習モデルを作成することが求められています。
教師ラベルの付与されていない大規模なデータセットから様々なタスクに適用可能な事前学習モデルを作成する手法として、自己教師あり学習が注目を集めています。音分野の分類タスクでは、2021年に提案されたCOLAが高い性能を実現しています[3]。COLAでは同じオーディオクリップからサンプリングされたオーディオセグメント(約1秒に切り取られた音データ)は似た性質を持つと仮定しています。この仮定に基づき、アンカーという基準となるオーディオセグメント、ポジティブサンプルというアンカーと同じオーディオクリップ内の異なるセグメント、ネガティブサンプルというアンカーと異なるオーディオクリップのオーディオセグメント、の3種のサンプルの組を大量に用意します。COLAはそれら3種のサンプルから得られる埋め込みベクトルそれぞれに対し、ポジティブサンプルはアンカーとの類似度が高くなるよう、ネガティブサンプルはアンカーとの類似度が低くなるような損失関数を導入することで、従来必要であった教師ラベルなしで大規模データでのニューラルネットワークの学習を可能としています。
COLAは様々なドメインの分類タスクで高い性能を収めていますが万能ではありません。例えば、COLAは入力の約1秒のセグメントに対して埋め込みベクトルを作成するため、音のクラス分類と同時に音の発生時間を検出する音響イベント検出は適しません。また、時間ごとに楽器の音階を推定するタスクも、同一のオーディオクリップからサンプルされたものであればアンカーとポジティブサンプルの音階が異なっていても埋め込みベクトルが類似したものになるように学習するため適しません。これらの課題を解決するために我々は新たな自己教師あり学習手法を提案しました。
提案手法
上記の問題は、COLAという単一のサンプリング戦略を採用しているため生じると考えられます。そこで、我々は複数のサンプリング戦略を用いて設計する損失関数に基づく自己教師あり学習法を提案します。複数のサンプリング戦略を用いることで、異なる下流タスクそれぞれに適した複数の損失関数を設定することが可能になり、より汎用的な音声表現を獲得できると考えられます。
提案手法では3種類のサンプリング戦略に基づいて設計した3種類の損失関数を組み合わせたマルチタスクな自己教師あり学習を行います。1つ目は、オーディオクリップ間の違いに着目するサンプリング戦略です。これは、COLAと同じサンプリング戦略および損失関数L_clipを用います。2つ目は、オーディオセグメントの時間変化に着目する戦略です。これは同じオーディオセグメントにおいて時間的に近い場合は類似度が高く、時間的に離れている場合は類似度が低くなるように損失関数L_frameを設計します。これにより、埋め込みベクトルの時間変化を捉えることができるため音響イベント検出などの下流タスクへの性能が向上すると考えられます。3つ目は、タスク特有のサンプリング戦略です。今回は、ピッチ推定タスクに着目してサンプリング戦略を設計します。具体的には、アンカーのオーディオセグメントと同じオーディオセグメントをある倍率でピッチシフトさせ、元の音源とピッチシフトした音源を比較し、ピッチシフトした倍率を推定する損失関数L_pitchを用います。これにより埋め込みベクトルにピッチを推定するための情報が含まれるようになり、音階推定などのタスクにも適用できるようになると考えられます。最後に、これら3種類の損失関数を加算することで最終的な損失関数とします。
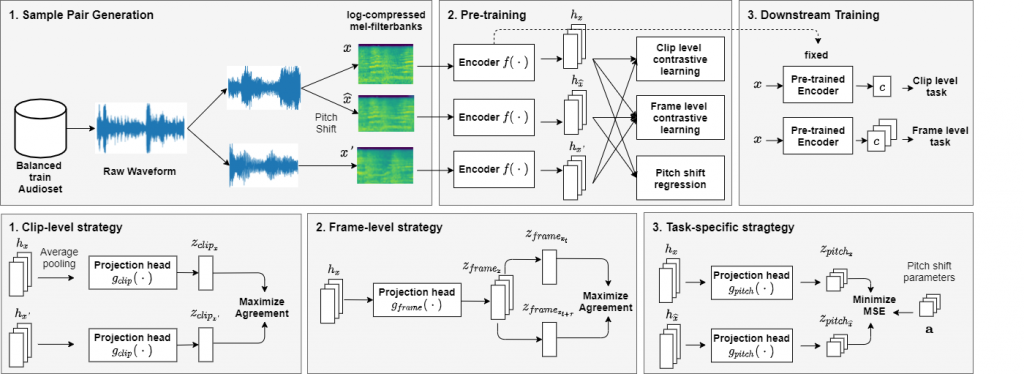
実験
実験では、モデルの事前学習にAudiosetのサブセット(500クラス10秒のオーディオクリップ18,939サンプル)を用いました。ただし、ラベル情報は用いていません。ネットワークの入力とする特徴量には、各オーディオセグメントから算出した対数メルスペクトルを使用しました。提案手法による事前学習に使用するモデルはCNNをベースとしたニューラルネットワークの一種 EfficientNet-b0を用い、推論の際は EfficientNet-b0の最終層に1層の全結合層を追加して各下流タスクに対して転移学習行いました。事前学習モデルの有効性は、3種類の下流タスクでの性能により評価しました。1つ目のタスクは クラス分類としてGoogleスピーチコマンド(SC)を用い、コマンド認識誤り率で評価を行いました。2つ目のタスクは、DCASE 2016のデータセットを用いた音響イベント検出を用いました。これはオフィス音のクラス分類と発生時間の推定を同時に行うもので、評価はDCASEの評価尺度に準じて、F1 scoreを用いました。3つ目のタスクは、NSynthデータセットを用いたピッチ検出を行いました。このタスクは標準的なMIDIピアノの音を88のピッチのうちの1つに分類するもので、評価尺度はピッチ精度とクロマ精度を用いました。
結果
実験では、提案手法との比較対象としてAudiosetのフルセット(サブセットの100倍のデータ量)を用いてオーディオタグ付けタスクで学習したモデルであるPANNs¹と、Audiosetのサブセットに対してCOLAによる自己教師あり学習を行ったモデルを用いました。Table 1にそれぞれの結果を示しています。
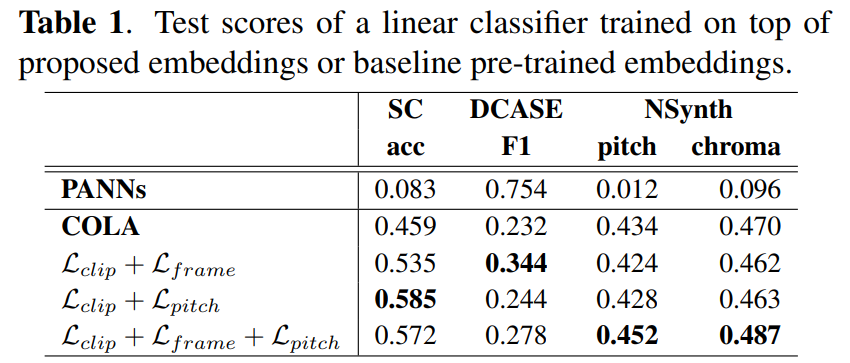
PANNsとその他の自己教師あり学習手法を比較すると、PANNsはAudiosetのフルセットで学習をしているにもかかわらず、SCやNSynthでは低い性能となりました。このことから学習手法によって適さないタスクがあることがわかりました。また、COLAと提案手法を比較すると3種類のサンプリング戦略を組み合わせた損失関数に適用することで全てのタスクにおいて性能が改善されることがわかりました。異なる視点から設計した戦略を組み合わせることによって、時間変化を捉えたこと、同一音源の特徴の変化を捉えたことが効果的だとわかりました。提案手法における各損失関数のアブレーションスタディをすると、 L_frameとL_pitchを組み合わせることで、NSynthの性能が向上することがわかりました。また、SC では L_frame、DCASE では L_pitch を用いた場合に最も性能向上が大きく、SC では L_pitch、DCASE では L_frame を用いた場合に最も性能向上が小さくなることがわかりました。ここで、L_pitch はフレームごとに計算されているため、フレームレベルの損失の変形と考えることができます。同じ音源でも時間が近ければ類似度を高めようとする L_frameと、同じ音源でもピッチが異なると埋め込みベクトルを変化させるL_pitchは、トレードオフの関係にあると考えることができます。これらの結果から、3種類の損失関数の組み合わせが重要であることがわかりました。
まとめ
本インターンでは、汎用的な音声表現の獲得のために複数のサンプリング戦略を用いて設計する損失関数に基づく自己教師あり学習法を提案しました。提案手法は、Audiosetのサブセットを用いた実験において、既存の手法と比較して全てのタスクの性能を向上させることがわかりました。結果からタスクに応じた損失関数の設計と組み合わせが重要だとわかりました。
また、インターンを通じて6週間という短い期間で、0から研究で成果を出すための方法を学ぶことができました。普段とは違う環境で研究することができる貴重な経験になりました。興味があればぜひ挑戦してみてください。
- I. Kuroyanagi and T. Komatsu, SELF-SUPERVISED LEARNING METHOD USING MULTIPLE SAMPLING STRATEGIES FOR GENERAL-PURPOSE AUDIO REPRESENTATION, in Proc. ICASSP, 2022, (accepted)
- Q. Kong, Y. Cao, T. Iqbal, et al., “PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020.
- A. Saeed, D. Grangier, and N. Zeghidour, “Contrastive learning of general-purpose audio representations,” in Proc. ICASSP, 2021, pp. 3875–3879.